embedded sql developer's guide - faircom · pdf file1.6 developing an embedded sql...
TRANSCRIPT

Developer's Guide
c-treeACE Embedded SQL

Copyright Notice
Copyright © 1992-2017 FairCom Corporation. All rights reserved. No part of this publication may be stored in a retrieval
system, or transmitted in any form or by any means, electronic, mechanical, photocopying, recording or otherwise without
the prior written permission of FairCom Corporation. Printed in the United States of America.
Information in this document is subject to change without notice.
Trademarks
c-treeACE, c-treeRTG, c-treeAMS, c-tree Plus, c-tree, r-tree, FairCom and FairCom’s circular disc logo are trademarks of
FairCom, registered in the United States and other countries.
The following are third-party trademarks: AMD and AMD Opteron are trademarks of Advanced Micro Devices, Inc.
Macintosh, Mac, Mac OS, and Xcode are trademarks of Apple Inc., registered in the U.S. and other countries.
Embarcadero, the Embarcadero Technologies logos and all other Embarcadero Technologies product or service names
are trademarks, service marks, and/or registered trademarks of Embarcadero Technologies, Inc. and are protected by the
laws of the United States and other countries. Business Objects and the Business Objects logo, BusinessObjects, Crystal
Reports, Crystal Decisions, Web Intelligence, Xcelsius, and other Business Objects products and services mentioned
herein as well as their respective logos are trademarks or registered trademarks of Business Objects Software Ltd.
Business Objects is an SAP company. HP and HP-UX are registered trademarks of the Hewlett-Packard Company. AIX,
IBM, POWER6, POWER7, and pSeries are trademarks or registered trademarks of International Business Machines
Corporation in the United States, other countries, or both. Intel, Intel Core, Itanium, Pentium and Xeon are trademarks or
registered trademarks of Intel Corporation or its subsidiaries in the United States and other countries. Microsoft, the .NET
logo, the Windows logo, Access, Excel, SQL Server, Visual Basic, Visual C++, Visual C#, Visual Studio, Windows,
Windows Server, and Windows Vista are either registered trademarks or trademarks of Microsoft Corporation in the
United States and/or other countries. Novell and SUSE are registered trademarks of Novell, Inc. in the United States and
other countries. Oracle and Java are registered trademarks of Oracle and/or its affiliates. QNX and Neutrino are
registered trademarks of QNX Software Systems Ltd. in certain jurisdictions. CentOS, Red Hat, and the Shadow Man logo
are registered trademarks of Red Hat, Inc. in the United States and other countries, used with permission. UNIX and
UnixWare are registered trademarks of The Open Group in the United States and other countries. Linux is a trademark of
Linus Torvalds in the United States, other countries, or both. Python and PyCon are trademarks or registered trademarks
of the Python Software Foundation. OpenServer is a trademark or registered trademark of Xinuos, Inc. in the U.S.A. and
other countries. Unicode and the Unicode Logo are registered trademarks of Unicode, Inc. in the United States and other
countries.
Btrieve is a registered trademark of Actian Corporation.
ACUCOBOL-GT, MICRO FOCUS, RM/COBOL, and Visual COBOL are trademarks or registered trademarks of Micro
Focus (IP) Limited or its subsidiaries in the United Kingdom, United States and other countries.
isCOBOL and Veryant are trademarks or registered trademarks of Veryant in the United States and other countries.
All other trademarks, trade names, company names, product names, and registered trademarks are the property of their
respective holders.
Portions Copyright © 1991-2016 Unicode, Inc. All rights reserved.
Portions Copyright © 1998-2016 The OpenSSL Project. All rights reserved. This product includes software developed by
the OpenSSL Project for use in the OpenSSL Toolkit (http://www.openssl.org/).
Portions Copyright © 1995-1998 Eric Young ([email protected]). All rights reserved. This product includes cryptographic
software written by Eric Young ([email protected]). This product includes software written by Tim Hudson
Portions © 1987-2017 Dharma Systems, Inc. All rights reserved. This software or web site utilizes or contains material
that is © 1994-2007 DUNDAS DATA VISUALIZATION, INC. and its licensors, all rights reserved.
Portions Copyright © 1995-2013 Jean-loup Gailly and Mark Adler.
4/6/2018

All Rights Reserved iii www.faircom.com
Contents
1. Introduction ........................................................................................................ 1
1.1 Overview .............................................................................................................. 1
1.2 The Relational View of Data ................................................................................. 1
1.3 Using c-treeSQL in a Host Language ................................................................... 2
1.4 Advantages of Using ESQL ................................................................................. 2
1.5 Components of an ESQL Application ................................................................... 3
1.6 Developing an Embedded SQL Application.......................................................... 3
2. Quick Tour .......................................................................................................... 4
2.1 Introductory Tutorial ............................................................................................. 5
Init 6
Define .................................................................................................................................. 7
Manage ............................................................................................................................... 8
Done .................................................................................................................................. 11
Additional Resources ........................................................................................................ 12
2.2 Relationships ..................................................................................................... 13
Init 15
Define ................................................................................................................................ 16
Manage ............................................................................................................................. 19
Done .................................................................................................................................. 24
Additional Resources ........................................................................................................ 25
2.3 Record/Row Locking .......................................................................................... 26
Init 27
Define ................................................................................................................................ 28
Manage ............................................................................................................................. 29
Done .................................................................................................................................. 32
Additional Resources ........................................................................................................ 33
2.4 Transaction Processing...................................................................................... 34
Init 35
Define ................................................................................................................................ 36
Manage ............................................................................................................................. 39
Done .................................................................................................................................. 44
Additional Resources ........................................................................................................ 45
3. Using the esqlc Command .............................................................................. 46
3.1 Introduction ........................................................................................................ 46
3.2 esqlc Command Line Reference ........................................................................ 46

Introduction
All Rights Reserved iv www.faircom.com
3.3 esqlc Command Examples ................................................................................ 48
Precompiling, Compiling, and Linking Multiple Files with esqlc ........................................ 48
Issuing Separate Commands for Precompiling, Compiling, and Linking .......................... 49
Mixing Precompiler/Compiler Options in the esqlc Command ......................................... 49
4. ESQL Program Structure ................................................................................. 50
4.1 Introduction ........................................................................................................ 50
4.2 ESQL Declare Statements ................................................................................. 50
Host Variables and their Usage ........................................................................................ 51
Indicator Variables and their Usage .................................................................................. 51
Limitations of the Declare Section .................................................................................... 53
4.3 ESQL Executable Statements ............................................................................ 54
Types of Executable Statements ...................................................................................... 54
4.4 The c-treeSQL Communications Area ................................................................ 54
The COMMIT WORK and ROLLBACK WORK Statements ............................................. 55
5. ESQL Application Development ..................................................................... 57
5.1 Introduction ........................................................................................................ 57
5.2 Guidelines .......................................................................................................... 57
5.3 Using c-treeSQL for Computation and Conversion ............................................. 58
5.4 Using c-treeSQL for Condition Evaluation .......................................................... 59
5.5 Using Indicator Variables ................................................................................... 60
5.6 Using Scalar Functions ...................................................................................... 60
5.7 Using Static and Dynamic Statements ............................................................... 61
6. Connection Management in ESQL .................................................................. 62
6.1 Introduction ........................................................................................................ 62
6.2 The CONNECT Statement ................................................................................. 62
Connection Using a Connection Name ............................................................................. 62
Connection by Default ....................................................................................................... 63
Connection to a Remote Database ................................................................................... 63
6.3 The SET CONNECTION Statement ................................................................... 64
6.4 The DISCONNECT Statement ........................................................................... 64
7. c-treeSQL Data Definition Statements ............................................................ 66
7.1 Introduction ........................................................................................................ 66
7.2 Creating/Dropping Tables .................................................................................. 66
Creating Tables ................................................................................................................. 66
Dropping Tables ................................................................................................................ 67

Introduction
All Rights Reserved v www.faircom.com
7.3 Creating/Dropping Indices .................................................................................. 68
Creating Indices ................................................................................................................ 68
Dropping Indices ............................................................................................................... 69
7.4 Creating/Dropping Views ................................................................................... 69
Creating Views .................................................................................................................. 69
Dropping Views ................................................................................................................. 70
7.5 Integrity Constraints ........................................................................................... 71
Need for Integrity Constraints ........................................................................................... 71
Types of Integrity Constraints ........................................................................................... 71
Check Constraints ............................................................................................................. 71
7.6 Primary Keys ..................................................................................................... 73
Column-Level Primary Key Constraint .............................................................................. 73
Table-Level Primary Key Constraint ................................................................................. 74
7.7 Candidate Keys ................................................................................................. 74
Column-Level Candidate Key Constraint .......................................................................... 75
Table-Level Candidate Key Constraint ............................................................................. 75
7.8 Referential Constraints....................................................................................... 75
Column-Level Foreign Key Constraint .............................................................................. 76
Table-Level Foreign Key Constraint ................................................................................. 77
7.9 Handling Cycles in Referential Integrity .............................................................. 77
Creation of Tables in Cycles ............................................................................................. 78
Insertion of Rows in Cycles ............................................................................................... 78
Dropping the Tables in Cycles .......................................................................................... 78
7.10 DDL Statements in Long Running Transactions ................................................. 79
8. c-treeSQL Data Manipulation Statements ...................................................... 80
8.1 Introduction ........................................................................................................ 80
8.2 Using DML Statements ...................................................................................... 80
Inserting Rows into a Table .............................................................................................. 80
Deleting Rows from a Table .............................................................................................. 82
Updating Rows in a Table ................................................................................................. 83
8.3 Input Host Variables in DML Statements ............................................................ 84
9. Query Statements ............................................................................................ 85
9.1 Introduction ........................................................................................................ 85
9.2 Elements of a Query .......................................................................................... 85
Input Host Variables in Query Statements ........................................................................ 86
Output Host Variables in Query Statements ..................................................................... 86
9.3 Queries Returning a Single Row ........................................................................ 86
9.4 Queries Returning Multiple Rows ....................................................................... 87

Introduction
All Rights Reserved vi www.faircom.com
Introduction to Cursors ...................................................................................................... 87
Associating a Cursor with a Query .................................................................................... 87
Opening a Cursor .............................................................................................................. 88
Retrieving Rows Using a Cursor ....................................................................................... 89
Closing a Cursor ............................................................................................................... 90
Deleting or Updating the Current Row .............................................................................. 90
Array Fetches: Retrieving Multiple Rows with One FETCH Statement .......................... 91
10. NULL Value Handling in ESQL ........................................................................ 94
10.1 Introduction ........................................................................................................ 94
10.2 Inserting NULL Values ....................................................................................... 94
Inserting NULL Values by Default ..................................................................................... 94
Using the NULL Keyword to Insert NULL Values ............................................................. 95
Using Indicator Variables to Insert NULL Values .............................................................. 95
10.3 Updating with NULL Values ............................................................................... 96
10.4 Retrieving NULL Values ..................................................................................... 97
Using Indicator Variables to Retrieve NULL Values ......................................................... 97
Using the Scalar Function NVL to Retrieve NULL values................................................. 97
10.5 Using NULL Values in Expressions .................................................................... 98
10.6 Using NULL Values in the WHERE Clause ........................................................ 98
10.7 Using NULL Values in GROUP BY Clause ........................................................ 99
10.8 Using NULL Values in ORDER BY Clause......................................................... 99
10.9 Using NULL Values in Scalar Functions ............................................................. 99
10.10 Using NULL Values in Aggregate Functions ...................................................... 99
11. Error Handling in ESQL ................................................................................. 100
11.1 Introduction ...................................................................................................... 100
11.2 Using SQLCA for Error Handling ...................................................................... 100
Fields of the SQLCA ....................................................................................................... 100
Using SQLCA for Checking Errors .................................................................................. 102
Using SQLCA for Checking Warnings ............................................................................ 104
Using the WHENEVER Statement for Error Handling .................................................... 105
Handling the SQL_NOT_FOUND Condition with WHENEVER ..................................... 107
Using WHENEVER Along With Explicit Error Checking ................................................. 107
Using Indicator Variables for Error Handling .................................................................. 107
12. Dynamic SQL Management in ESQL ............................................................ 109
12.1 Introduction ...................................................................................................... 109
12.2 Overview .......................................................................................................... 109
12.3 Preparing Statements ...................................................................................... 110

Introduction
All Rights Reserved vii www.faircom.com
Non-SELECT Statements ............................................................................................... 111
SELECT Statements ....................................................................................................... 112
12.4 ESQL Descriptor Statement ............................................................................. 114
ALLOCATE DESCRIPTOR ............................................................................................. 114
DEALLOCATE DESCRIPTOR ........................................................................................ 114
GET DESCRIPTOR ........................................................................................................ 115
SET DESCRIPTOR......................................................................................................... 117
12.5 The c-treeSQL Descriptor Area - SQLDA ......................................................... 118
The Components of SQLDA ........................................................................................... 119
The DESCRIBE Statement ............................................................................................. 127
Using SQLDA for Input Variables ................................................................................... 128
Using SQLDA for Output Variables ................................................................................. 129
13. Transaction Management in ESQL ............................................................... 131
13.1 Introduction ...................................................................................................... 131
13.2 Transaction Overview ...................................................................................... 131
Starting a Transaction ..................................................................................................... 131
Transaction Isolation Levels ........................................................................................... 134
Locking and Transactions ............................................................................................... 135
Abnormal Termination of an ESQL Application Program ............................................... 136
14. Data Type Handling in ESQL ......................................................................... 138
14.1 Introduction ...................................................................................................... 138
14.2 Data Type Descriptions .................................................................................... 138
CHARACTER Data Type ................................................................................................ 138
SMALLINT Data Type ..................................................................................................... 139
INTEGER Data Type....................................................................................................... 139
BIGINT ............................................................................................................................ 140
REAL Data Type ............................................................................................................. 140
FLOAT Data Type ........................................................................................................... 140
DOUBLE PRECISION..................................................................................................... 141
NUMERIC or DECIMAL Data Type ................................................................................ 141
DATE Data Type ............................................................................................................. 145
TIME Data Type .............................................................................................................. 145
TIMESTAMP ................................................................................................................... 146
BIT 146
BINARY [(length)] ............................................................................................................ 146
LVARBINARY | LONG VARBINARY .............................................................................. 146
Data Conversion ............................................................................................................. 146
Data Comparison ............................................................................................................ 150
15. ESQL Reference ............................................................................................. 153

Introduction
All Rights Reserved viii www.faircom.com
15.1 Introduction ...................................................................................................... 153
15.2 BEGIN-END DECLARE SECTION................................................................... 153
15.3 CLOSE ............................................................................................................ 155
15.4 DECLARE CURSOR ....................................................................................... 155
15.5 DESCRIBE ...................................................................................................... 156
15.6 END DECLARE SECTION ............................................................................... 159
15.7 EXEC SQL ....................................................................................................... 159
15.8 EXECUTE ........................................................................................................ 159
15.9 EXECUTE IMMEDIATE ................................................................................... 161
15.10 FETCH ............................................................................................................. 161
15.11 OPEN .............................................................................................................. 163
15.12 PREPARE........................................................................................................ 164
15.13 Query Expressions ........................................................................................... 166
15.14 Search Conditions ............................................................................................ 166
LIKE Predicate ................................................................................................................ 166
IN Predicate .................................................................................................................... 167
15.15 Single-Row SELECT Statement ....................................................................... 167
15.16 Type Specifications for Variable and Type Declarations................................... 169
Database Types .............................................................................................................. 170
Host Language Types ..................................................................................................... 171
Table-Column Types ....................................................................................................... 172
Static Array Types ........................................................................................................... 172
Record Types .................................................................................................................. 174
Table Record Types ........................................................................................................ 174
15.17 WHENEVER .................................................................................................... 175
15.18 Long Data Type Support .................................................................................. 176
DECLARE Section .......................................................................................................... 177
INSERT Operation .......................................................................................................... 177
SELECT Operation ......................................................................................................... 177
16. Programmatic Interfaces ............................................................................... 178
16.1 Introduction ...................................................................................................... 178
16.2 Programmatic Interfaces .................................................................................. 179
sqld_alloc ........................................................................................................................ 179
sqld_free ......................................................................................................................... 179
dh_alloc_sqlenv .............................................................................................................. 180
dh_compare_data ........................................................................................................... 181
dh_conv_data .................................................................................................................. 182
dh_dayofweek ................................................................................................................. 184

Introduction
All Rights Reserved ix www.faircom.com
dh_free_sqlenv ................................................................................................................ 184
dh_get_curdbhdl ............................................................................................................. 185
dh_get_curtmhdl ............................................................................................................. 185
dh_num_add ................................................................................................................... 186
dh_set_cursor ................................................................................................................. 187
dh_set_ptrs ..................................................................................................................... 188
dh_set_sqlda ................................................................................................................... 189
dh_sqlclose ..................................................................................................................... 190
dh_sqlconnect ................................................................................................................. 191
dh_sqldeclare .................................................................................................................. 192
dh_sqldescribe ................................................................................................................ 193
dh_sqldescribe_param .................................................................................................... 195
dh_sqldisconnect ............................................................................................................ 196
dh_sqlexecute ................................................................................................................. 197
dh_sqlfetch ...................................................................................................................... 198
dh_sqlgetdata .................................................................................................................. 199
dh_sqlopen ...................................................................................................................... 200
dh_sqlprepare ................................................................................................................. 202
dh_sqlselect .................................................................................................................... 203
dh_tm_alloc_handle ........................................................................................................ 204
dh_tm_begin_trans ......................................................................................................... 205
dh_tm_end_trans ............................................................................................................ 206
dh_tm_mark_abort .......................................................................................................... 206
dh_sqlputdata .................................................................................................................. 207
dh_sqlallocdesc ............................................................................................................... 209
dh_sqlgetsqldaptr ............................................................................................................ 209
dh_sqldeallocdesc........................................................................................................... 210
dh_sqlgetdesc ................................................................................................................. 211
dh_sqlsetdesc ................................................................................................................. 212
dh_sqlgetdiag .................................................................................................................. 213
dh_tm_set_level .............................................................................................................. 214
dh_sqltables .................................................................................................................... 215
dh_sqlcolumns ................................................................................................................ 215
dh_sqlstatistics ................................................................................................................ 215
dh_sqlprimarykeys .......................................................................................................... 215
dh_sqlforeignkeys ........................................................................................................... 215
17. Sample ESQL Programs ................................................................................ 216
17.1 Static Non-Select Statements .......................................................................... 216
Compiling and Running ................................................................................................... 216
Program Source Code .................................................................................................... 216
17.2 Static SELECT Statements .............................................................................. 218
Compiling and Running ................................................................................................... 218

Introduction
All Rights Reserved x www.faircom.com
Program Source Code .................................................................................................... 218
17.3 Dynamic Non-SELECT Statements ................................................................. 220
Compiling and Running ................................................................................................... 220
Program Source Code .................................................................................................... 221
17.4 Dynamic SELECT Statements ......................................................................... 223
Compiling and Running ................................................................................................... 223
Program Source code ..................................................................................................... 223
17.5 Long Data Type Support .................................................................................. 226
Sample ESQLC Program for lvarchar Data Type ........................................................... 226
Sample ESQLC Program for lvarbinary Data Type ........................................................ 230
18. Glossary ......................................................................................................... 234
19. Index ............................................................................................................... 239

FairCom Typographical Conventions
Before you begin using this guide, be sure to review the relevant terms and typographical
conventions used in the documentation.
The following formatted items identify special information.
Formatting convention Type of Information
Bold Used to emphasize a point or for variable expressions such as parameters
CAPITALS Names of keys on the keyboard. For example, SHIFT, CTRL, or ALT+F4
FairCom Terminology FairCom technology term
FunctionName() c-treeACE Function name
Parameter c-treeACE Function Parameter
Code Example Code example or Command line usage
utility c-treeACE executable or utility
filename c-treeACE file or path name
CONFIGURATION KEYWORD c-treeACE Configuration Keyword
CTREE_ERR c-treeACE Error Code

All Rights Reserved xii www.faircom.com

All Rights Reserved 1 www.faircom.com
1. Introduction
1.1 Overview
This chapter gives an introduction to Embedded c-treeSQL (ESQL) and discusses:
The concept of embedding c-treeSQL statements in a host language
The advantages of using ESQL
The components of an ESQL program
An introduction to the ESQL precompiler
1.2 The Relational View of Data
A relational database gives a perception of data as a collection of tables (also called relations).
Each table is an unordered collection of rows (also called tuples or records). Each row in a table
is a collection of column values.
Views are virtual tables derived from the real tables. Views are virtual tables because when a
view is created, the view data is not derived and stored in the database. Instead, just the view
definition is stored in the database. Once a view is created, it can be used in the same way as
using a table, for accessing the database.
A table column can optionally have an index associated with it. An index can be thought of as a
list of pointers to the rows of a table, ordered based on the values of the associated column.
Indices are created only for performance improvement.
SQL (Structured Query Language) is the most popular language for accessing relational
databases. Commands in SQL specify what is to be done and not how it is to be done, leaving all
the details of query processing to the language implementation. All these have made SQL the de
facto standard in the relational database world.
Most of the SQL implementations provide two types of interfaces for accessing the database. The
first interface is the Embedded SQL Interface. This interface supports embedding of SQL
statements in a third generation programming language like C or COBOL. The second interface is
the Interactive SQL Facility which enables ad hoc queries to be performed on the database in an
interactive fashion.
In addition to the language support for querying the database, SQL also supports constructs for
handling transactions. A transaction is a sequence of operations on the database that has the
properties of being atomic and durable. Atomicity refers to the property that either all the
operations in a transaction are done (if the transaction is committed) or none are done (if the
transaction is rolled back). Durability refers to the property that once a transaction is committed,
the changes done by the transaction are permanent.

Introduction
All Rights Reserved 2 www.faircom.com
1.3 Using c-treeSQL in a Host Language
The c-treeSQL data language is a non-procedural language that uses SQL statements for
defining, manipulating, and controlling data in a relational database.
The ESQL tool gives you the ability to embed c-treeSQL statements in a host language program.
Embedding c-treeSQL statements in a procedural language program lets you take advantage of
the flow-control and other features of the host language as well as the standardized query
capabilities of c-treeSQL.
ESQL supports C language host programs. It provides a precompiler, esqlc, that translates
each embedded SQL statements in a host program to the equivalent C calls to functions in the
c-treeSQL application programming interface (API).
The following example shows a brief C code fragment with embedded SQL statements.
Note that all embedded SQL statements start with the prefix EXEC SQL and end with a
semicolon character ( ; ). For more information on EXEC SQL statements, see “EXEC SQL (page
159)”.
Note also that, in addition to standard SQL statements, you use EXEC SQL to embed other
ESQL constructs in host programs, such as BEGIN DECLARE … END DECLARE blocks.
Example ESQL Code
EXEC SQL BEGIN DECLARE SECTION ;
long order_no_v ;
char order_date_v [10] ;
char product_v [5] ;
long qty_v ;
EXEC SQL END DECLARE SECTION ;
…
/* C code to get values for host variables */
order_no_v = 1001 ;
strcpy (order_date_v, "02/02/1993") ;
strcpy (product_v, "COG") ;
qty_v = 10000 ;
printf ("Registering the order…") ;
EXEC SQL
INSERT INTO orders
(order_no, order_date, product, qty)
VALUES
(:order_no_v, :order_date_v, :product_v, :qty_v) ;
1.4 Advantages of Using ESQL
The advantages of using ESQL as an application development tool are listed below:

Introduction
All Rights Reserved 3 www.faircom.com
One of the major advantages of using ESQL is that it allows the application developer to
combine the flexibility of a host language and the power of SQL for data access.
The ESQL constructs are simple and provide better readability when compared to the API
calls.
Using the ESQL constructs reduces the source code size and complexity of an application
without reducing the implementation flexibility.
1.5 Components of an ESQL Application
ESQL constructs fall into the following categories:
ESQL declare statements declare variables for use in other ESQL constructs. Such variables
are also available for use in host-language constructs.
ESQL executable statements result in the execution of instructions on a specified database at
runtime. The executable statements are typically standard SQL statements and include Data
Manipulation Language (DML) statements, Data Definition Language (DDL) statements and
Data Control Language (DCL) statements.
See “ESQL Program Structure (page 50)” for more details on ESQL program components.
1.6 Developing an Embedded SQL Application
The ESQL precompiler, esqlc, translates SQL statements embedded in a C host program and
generates a pure C program. The C program generated by the ESQL precompiler is used to build
the application program executable.
The general steps involved in building an ESQL program executable are as follows:
Write ESQL source-code files.
Use the ESQL precompiler, esqlc, to precompile ESQL files and generate corresponding C
source files.
Use a standard C compiler to generate object files from the C source files.
Link the object files the ESQL libraries to generate an executable application.
See “Using the esqlc Command” (page 46) for more details on invoking and using esqlc.

All Rights Reserved 4 www.faircom.com
2. Quick Tour

Quick Tour
All Rights Reserved 5 www.faircom.com
2.1 Introductory Tutorial
..\sdk\sql.embedded\tutorials\eSQL_Tutorial1.pc
This tutorial will take you through the basic use of the c-treeACE SQL ESQL - Embedded SQL
Interface
Like all other examples in the c-tree tutorial series, this tutorial simplifies the creation and use of a
database into four simple steps: Initialize(), Define(), Manage(), and You’re Done() !
Tutorial #1: Introductory - Simple Single Table
We wanted to keep this program as simple as possible. This program does the following:
Initialize() - Connects to the c-treeACE Database Engine.
Define() - Defines and creates a "customer master" (custmast) table/file.
Manage() - Adds a few rows/records; Reads the rows/records back from the database;
displays the column/field content; and then deletes the rows/records.
Done() - Disconnects from c-treeACE Database Engine.
Note our simple mainline:
/*
* main()
*
* The main() function implements the concept of "init, define, manage
* and you're done…"
*/
int main(int argc, char* argv[])
{
Initialize();
Define();
Manage();
Done();
printf(DH_STRING_LITERAL("\nPress <ENTER> key to exit . . .\n"));
getchar();
return(0);
}
We suggest opening the source code with your own editor.
Continue now to review these four steps.

Quick Tour
All Rights Reserved 6 www.faircom.com
Init
First we need to open a connection to a database by providing the c-treeACE Database Engine
with a user name, password and the database name.
Below is the code for Initialize():
/*
* Initialize()
*
* Perform the minimum requirement of logging onto the c-tree Server
*/
void Initialize(void)
{
os_printf(DH_STRING_LITERAL("INIT\n"));
os_setenv (DH_STRING_LITERAL("DH_USER"), DH_STRING_LITERAL("ADMIN"));
os_setenv (DH_STRING_LITERAL("DH_PASSWD"), DH_STRING_LITERAL("ADMIN"));
os_setenv (DH_STRING_LITERAL("DB_NAME"), DH_STRING_LITERAL("ctreeSQL"));
EXEC SQL CONNECT TO DEFAULT ;
if (sqlca.sqlcode)
Handle_Error(sqlca.sqlcode, sqlca.sqlerrm);
}
Quick Tour
All Rights Reserved 7 www.faircom.com
Define
The define step is where specific data definitions are established by your application and/or
process. This involves defining columns/fields and creating the tables/files with optional indices.
Below is the code for Define():
/*
* Define()
*
* Create the table for containing a list of existing customers
*/
void Define(void)
{
os_printf(DH_STRING_LITERAL("DEFINE\n"));
/* create table */
os_printf(DH_STRING_LITERAL("\tCreate table…\n"));
EXEC SQL CREATE TABLE custmast (
cm_custnumb CHAR(4),
cm_custzipc CHAR(9),
cm_custstat CHAR(2),
cm_custrtng CHAR(1),
cm_custname VARCHAR(47),
cm_custaddr VARCHAR(47),
cm_custcity VARCHAR(47)
) ;
if (sqlca.sqlcode)
Handle_Error(sqlca.sqlcode, sqlca.sqlerrm);
EXEC SQL COMMIT WORK;
}

Quick Tour
All Rights Reserved 8 www.faircom.com
Manage
The manage step provides data management functionality for your application and/or process.
Below is the code for Manage():
/*
* Manage()
*
* This function performs simple record functions of add, delete and gets
*/
void Manage(void)
{
os_printf(DH_STRING_LITERAL("MANAGE\n"));
/* delete any existing records */
Delete_Records();
/* populate the table with data */
Add_Records();
/* display contents of table */
Display_Records();
}
/*
* Add_Records()
*
* This function adds records to a table from an array of strings
*/
void Add_Records(void)
{
EXEC SQL BEGIN DECLARE SECTION ;
char sCommand[512];
EXEC SQL END DECLARE SECTION ;
dh_char_t *data[] = {
DH_STRING_LITERAL("('1000','92867','CA','1','Bryan Williams','2999 Regency','Orange')"),
DH_STRING_LITERAL("('1001','61434','CT','1','Michael Jordan','13 Main','Harford')"),
DH_STRING_LITERAL("('1002','73677','GA','1','Joshua Brown','4356
Cambridge','Atlanta')"),
DH_STRING_LITERAL("('1003','10034','MO','1','Keyon Dooling','19771 Park
Avenue','Columbia')")
};
int i;
int nRecords = sizeof(data) / sizeof(data[0]);
os_printf(DH_STRING_LITERAL("\tAdd records…\n"));
/* add one record at time to table */
for (i = 0; i < nRecords; i++)
{
os_sprintf (sCommand, DH_STRING_LITERAL("INSERT INTO custmast VALUES %s"), data[i]);

Quick Tour
All Rights Reserved 9 www.faircom.com
EXEC SQL EXECUTE IMMEDIATE :sCommand ;
if (sqlca.sqlcode)
Handle_Error(sqlca.sqlcode, sqlca.sqlerrm);
}
EXEC SQL COMMIT WORK;
}
/*
* Delete_Records()
*
* This function deletes all the records in the table
*/
void Delete_Records(void)
{
os_printf(DH_STRING_LITERAL("\tDelete records…\n"));
EXEC SQL DELETE FROM custmast ;
if (sqlca.sqlcode < 0)
Handle_Error(sqlca.sqlcode, sqlca.sqlerrm);
EXEC SQL COMMIT WORK ;
}
/*
* Display_Records()
*
* This function displays the contents of a table.
*/
void Display_Records(void)
{
EXEC SQL BEGIN DECLARE SECTION ;
CHAR custnumb[5+1];
CHAR custname[47+1];
EXEC SQL END DECLARE SECTION ;
os_printf(DH_STRING_LITERAL("\tDisplay records…"));
EXEC SQL DECLARE curs CURSOR FOR
SELECT custmast.cm_custnumb, custmast.cm_custname FROM custmast;
if (sqlca.sqlcode)
Handle_Error(sqlca.sqlcode, sqlca.sqlerrm);
EXEC SQL OPEN curs;
if (sqlca.sqlcode)
Handle_Error(sqlca.sqlcode, sqlca.sqlerrm);
EXEC SQL FETCH curs INTO :custnumb, :custname;
/* fetch and display each individual record */
while (!sqlca.sqlcode)
{
os_printf(DH_STRING_LITERAL("\n\t\t%-8s%10s\n"),custnumb, custname);
EXEC SQL FETCH curs INTO :custnumb, :custname;
}
EXEC SQL CLOSE curs ;

Quick Tour
All Rights Reserved 10 www.faircom.com
}

Quick Tour
All Rights Reserved 11 www.faircom.com
Done
When an application and/or process has completed operations with the database, it must release
resources by disconnecting from the database engine.
Below is the code for Done():
/*
* Done()
*
* This function handles the housekeeping of closing connection and
* freeing of associated memory
*/
void Done(void)
{
os_printf(DH_STRING_LITERAL("DONE\n"));
/* disconnect from server */
EXEC SQL DISCONNECT CURRENT ;
if (sqlca.sqlcode)
Handle_Error(sqlca.sqlcode, sqlca.sqlerrm);
}

Quick Tour
All Rights Reserved 12 www.faircom.com
Additional Resources
We encourage you to explore the additional resources listed here:
Complete source code for this tutorial can be found in eSQL_Tutorial1.pc in your installation
directory, within the 'sdk\sql.embedded\tutorials' directory for your platform.
Example for the Windows platform:
C:\FairCom\V*\win32\sdk\sql.embedded\tutorials\eSQL_Tutorial1.pc.
Additional documentation may be found on the FairCom Web site at: www.faircom.com

Quick Tour
All Rights Reserved 13 www.faircom.com
2.2 Relationships
..\sdk\sql.embedded\tutorials\eSQL_Tutorial2.pc
Now we will build some table/file relationships using the c-treeACE SQL ESQL - Embedded SQL
Interface
This tutorial will advance the concepts introduced in the first tutorial by expanding the number of
tables. We will define key columns/fields and create specific indices for each table to form a
relational model database.
Like all other examples in the c-tree tutorial series, this tutorial simplifies the creation and use of a
database into four simple steps: Initialize(), Define(), Manage(), and You’re Done() !
Tutorial #2: Relational Model and Indexing
Here we add a bit more complexity, introducing multiple tables, with related indices in order to
form a simple "relational" database simulating an Order Entry system. Here is an overview of
what will be created:
Initialize() - Connects to the c-treeACE Database Engine.
Define() - Defines and creates the "custmast", "custordr", "ordritem" and the
"itemmast" tables/files with related indices.
Manage() - Adds some related rows/records to all tables/files. Then queries the
database.
Done() - Disconnects from c-treeACE Database Engine.
Note our simple mainline:
/*
* main()
*
* The main() function implements the concept of "init, define, manage
* and you're done…"
*/
int main(int argc, char* argv[])
{

Quick Tour
All Rights Reserved 14 www.faircom.com
Initialize();
Define();
Manage();
Done();
os_printf(DH_STRING_LITERAL("\nPress <ENTER> key to exit . . .\n"));
getchar();
return(0);
}
We suggest opening the source code with your own editor.
Continue now to review these four steps.

Quick Tour
All Rights Reserved 15 www.faircom.com
Init
First we need to open a connection to a database by providing the c-treeACE Database Engine
with a user name, password and the database name.
Below is the code for Initialize():
/*
* Initialize()
*
* Perform the minimum requirement of logging onto the c-tree Server
*/
void Initialize(void)
{
os_printf(DH_STRING_LITERAL("INIT\n"));
os_setenv (DH_STRING_LITERAL("DH_USER"), DH_STRING_LITERAL("ADMIN"));
os_setenv (DH_STRING_LITERAL("DH_PASSWD"), DH_STRING_LITERAL("ADMIN"));
os_setenv (DH_STRING_LITERAL("DB_NAME"), DH_STRING_LITERAL("ctreeSQL"));
EXEC SQL CONNECT TO DEFAULT ;
if (sqlca.sqlcode)
Handle_Error(sqlca.sqlcode, sqlca.sqlerrm);
}

Quick Tour
All Rights Reserved 16 www.faircom.com
Define
The define step is where specific data definitions are established by your application and/or
process. This involves defining columns/fields and creating the tables/files with optional indices.
Below is the code for Define():
/*
* Define()
*
* Create the tables
*/
void Define(void)
{
os_printf(DH_STRING_LITERAL("DEFINE\n"));
Create_CustomerMaster_Table();
Create_CustomerOrders_Table();
Create_OrderItems_Table();
Create_ItemMaster_Table();
EXEC SQL COMMIT WORK ;
}
/*
* Create_CustomerMaster_Table()
*
* Create the CustomerMaster
*/
void Create_CustomerMaster_Table(void)
{
/* define table CustomerMaster */
os_printf(DH_STRING_LITERAL("\ttable CustomerMaster\n"));
EXEC SQL CREATE TABLE custmast (
cm_custnumb CHAR(4),
cm_custzipc CHAR(9),
cm_custstat CHAR(2),
cm_custrtng CHAR(1),
cm_custname VARCHAR(47),
cm_custaddr VARCHAR(47),
cm_custcity VARCHAR(47)
);
if (sqlca.sqlcode)
Handle_Error(sqlca.sqlcode, sqlca.sqlerrm);
EXEC SQL CREATE UNIQUE INDEX cm_custnumb_idx ON custmast (cm_custnumb) ;
if (sqlca.sqlcode)
Handle_Error(sqlca.sqlcode, sqlca.sqlerrm);
}

Quick Tour
All Rights Reserved 17 www.faircom.com
/*
* Create_CustomerOrders_Table()
*
* Create the CustomerOrders
*/
void Create_CustomerOrders_Table(void)
{
/* define table CustomerOrders */
os_printf(DH_STRING_LITERAL("\ttable CustomerOrders\n"));
EXEC SQL CREATE TABLE custordr (
co_ordrdate DATE,
co_promdate DATE,
co_ordrnumb CHAR(6),
co_custnumb CHAR(4)
) ;
if (sqlca.sqlcode)
Handle_Error(sqlca.sqlcode, sqlca.sqlerrm);
EXEC SQL CREATE UNIQUE INDEX co_ordrnumb_idx ON custordr (co_ordrnumb) ;
if (sqlca.sqlcode)
Handle_Error(sqlca.sqlcode, sqlca.sqlerrm);
EXEC SQL CREATE INDEX co_custnumb_idx ON custordr (co_custnumb) ;
if (sqlca.sqlcode)
Handle_Error(sqlca.sqlcode, sqlca.sqlerrm);
}
/*
* Create_OrderItems_Table()
*
* Create the OrderItems
*/
void Create_OrderItems_Table(void)
{
/* define table OrderItems */
os_printf(DH_STRING_LITERAL("\ttable OrderItems\n"));
EXEC SQL CREATE TABLE ordritem (
oi_sequnumb SMALLINT,
oi_quantity SMALLINT,
oi_ordrnumb CHAR(6),
oi_itemnumb CHAR(5)
) ;
if (sqlca.sqlcode)
Handle_Error(sqlca.sqlcode, sqlca.sqlerrm);
EXEC SQL CREATE UNIQUE INDEX oi_ordrnumb_idx ON ordritem (oi_ordrnumb, oi_sequnumb) ;
if (sqlca.sqlcode)
Handle_Error(sqlca.sqlcode, sqlca.sqlerrm);
EXEC SQL CREATE INDEX oi_itemnumb_idx ON ordritem (oi_itemnumb) ;
if (sqlca.sqlcode)
Handle_Error(sqlca.sqlcode, sqlca.sqlerrm);
}
/*
* Create_ItemMaster_Table()
*

Quick Tour
All Rights Reserved 18 www.faircom.com
* Create the ItemMaster
*/
void Create_ItemMaster_Table(void)
{
/* define table ItemMaster */
os_printf(DH_STRING_LITERAL("\ttable ItemMaster\n"));
EXEC SQL CREATE TABLE itemmast (
im_itemwght INTEGER,
im_itempric MONEY,
im_itemnumb CHAR(5),
im_itemdesc VARCHAR(47)
) ;
if (sqlca.sqlcode)
Handle_Error(sqlca.sqlcode, sqlca.sqlerrm);
EXEC SQL CREATE UNIQUE INDEX im_itemnumb_idx ON itemmast (im_itemnumb) ;
if (sqlca.sqlcode)
Handle_Error(sqlca.sqlcode, sqlca.sqlerrm);
}

Quick Tour
All Rights Reserved 19 www.faircom.com
Manage
The manage step provides data management functionality for your application and/or process.
Below is the code for Manage():
/*
* Manage()
*
* Populates table and perform a simple query
*
*/
void Manage(void)
{
EXEC SQL BEGIN DECLARE SECTION;
CHAR custname[47+1];
FLOAT total;
EXEC SQL END DECLARE SECTION;
os_printf(DH_STRING_LITERAL("MANAGE\n"));
/* populate the tables with data */
Add_CustomerMaster_Records();
Add_CustomerOrders_Records();
Add_OrderItems_Records();
Add_ItemMaster_Records();
/* perform a query:
list customer name and total amount per order
name total
@@@@@@@@@@@@@ $xx.xx
for each order in the CustomerOrders table
fetch order number
fetch customer number
fetch name from CustomerMaster table based on customer number
for each order item in OrderItems table
fetch item quantity
fetch item number
fetch item price from ItemMaster table based on item number
next
next
*/
os_printf(DH_STRING_LITERAL("\n\tQuery Results\n"));
/* declare cursor for fetching orders */
EXEC SQL DECLARE curs CURSOR FOR
SELECT cm_custname, SUM(im_itempric * oi_quantity)
FROM custmast, custordr, ordritem, itemmast
WHERE co_custnumb = cm_custnumb AND co_ordrnumb = oi_ordrnumb AND oi_itemnumb =
im_itemnumb
GROUP BY cm_custnumb, cm_custname;
if (sqlca.sqlcode)

Quick Tour
All Rights Reserved 20 www.faircom.com
Handle_Error(sqlca.sqlcode, sqlca.sqlerrm);
EXEC SQL OPEN curs;
if (sqlca.sqlcode)
Handle_Error(sqlca.sqlcode, sqlca.sqlerrm);
while (1)
{
/* for each order in the CustomerOrders table */
EXEC SQL FETCH curs INTO :custname, :total;
if (sqlca.sqlcode == SQL_NOT_FOUND)
break;
else if (sqlca.sqlcode)
Handle_Error(sqlca.sqlcode, sqlca.sqlerrm);
/* output data to stdout */
os_printf(DH_STRING_LITERAL("\t\t%-20s %.2f\n"), custname, total);
}
EXEC SQL CLOSE curs ;
}
/*
* Delete_Records()
*
* This function deletes all the records in the table
*/
void Delete_Records(dh_char_t* table)
{
EXEC SQL BEGIN DECLARE SECTION ;
char sCommand[512];
EXEC SQL END DECLARE SECTION ;
os_printf(DH_STRING_LITERAL("\tDelete records…\n"));
os_sprintf (sCommand, DH_STRING_LITERAL("DELETE FROM %s"), table);
EXEC SQL EXECUTE IMMEDIATE :sCommand ;
if (sqlca.sqlcode < 0)
Handle_Error(sqlca.sqlcode, sqlca.sqlerrm);
EXEC SQL COMMIT WORK ;
}
/*
* Add_CustomerMaster_Records()
*
* This function adds records to table CustomerMaster from an
* array of strings
*/
void Add_CustomerMaster_Records(void)
{
EXEC SQL BEGIN DECLARE SECTION ;
char sCommand[512];
EXEC SQL END DECLARE SECTION ;
dh_char_t *data[] = {
DH_STRING_LITERAL("('1000','92867','CA','1','Bryan Williams','2999 Regency','Orange')"),
DH_STRING_LITERAL("('1001','61434','CT','1','Michael Jordan','13 Main','Harford')"),
DH_STRING_LITERAL("('1002','73677','GA','1','Joshua Brown','4356
Cambridge','Atlanta')"),

Quick Tour
All Rights Reserved 21 www.faircom.com
DH_STRING_LITERAL("('1003','10034','MO','1','Keyon Dooling','19771 Park
Avenue','Columbia')")
};
int i;
int nRecords = sizeof(data) / sizeof(data[0]);
Delete_Records(DH_STRING_LITERAL("custmast"));
os_printf(DH_STRING_LITERAL("\tAdd records in table CustomerMaster…\n"));
/* add one record at time to table */
for (i = 0; i < nRecords; i++)
{
os_sprintf (sCommand, DH_STRING_LITERAL("INSERT INTO custmast VALUES %s"), data[i]);
EXEC SQL EXECUTE IMMEDIATE :sCommand ;
if (sqlca.sqlcode)
Handle_Error(sqlca.sqlcode, sqlca.sqlerrm);
}
EXEC SQL COMMIT WORK;
}
/*
* Add_CustomerOrders_Records()
*
* This function adds records to table CustomerOrders from an
* array of strings
*/
void Add_CustomerOrders_Records(void)
{
EXEC SQL BEGIN DECLARE SECTION ;
char sCommand[512];
EXEC SQL END DECLARE SECTION ;
dh_char_t *data[] = {
DH_STRING_LITERAL("('09/01/2002','09/05/2002','1','1001')"),
DH_STRING_LITERAL("('09/02/2002','09/06/2002','2','1002')")
};
int i;
int nRecords = sizeof(data) / sizeof(data[0]);
Delete_Records(DH_STRING_LITERAL("custordr"));
os_printf(DH_STRING_LITERAL("\tAdd records in table CustomerOrders…\n"));
/* add one record at time to table */
for (i = 0; i < nRecords; i++)
{
os_sprintf (sCommand, DH_STRING_LITERAL("INSERT INTO custordr VALUES %s"), data[i]);
EXEC SQL EXECUTE IMMEDIATE :sCommand ;
if (sqlca.sqlcode)
Handle_Error(sqlca.sqlcode, sqlca.sqlerrm);
}
EXEC SQL COMMIT WORK;
}
/*

Quick Tour
All Rights Reserved 22 www.faircom.com
* Add_OrderItems_Records()
*
* This function adds records to table OrderItems from an
* array of strings
*/
void Add_OrderItems_Records(void)
{
EXEC SQL BEGIN DECLARE SECTION ;
char sCommand[512];
EXEC SQL END DECLARE SECTION ;
dh_char_t *data[] = {
DH_STRING_LITERAL("(1,2,'1','1')"),
DH_STRING_LITERAL("(2,1,'1','2')"),
DH_STRING_LITERAL("(3,1,'1','3')"),
DH_STRING_LITERAL("(1,3,'2','3')")
};
int i;
int nRecords = sizeof(data) / sizeof(data[0]);
Delete_Records(DH_STRING_LITERAL("ordritem"));
os_printf(DH_STRING_LITERAL("\tAdd records in table OrderItems…\n"));
/* add one record at time to table */
for (i = 0; i < nRecords; i++)
{
os_sprintf (sCommand, DH_STRING_LITERAL("INSERT INTO ordritem VALUES %s"), data[i]);
EXEC SQL EXECUTE IMMEDIATE :sCommand ;
if (sqlca.sqlcode)
Handle_Error(sqlca.sqlcode, sqlca.sqlerrm);
}
EXEC SQL COMMIT WORK;
}
/*
* Add_ItemMaster_Records()
*
* This function adds records to table ItemMaster from an
* array of strings
*/
void Add_ItemMaster_Records(void)
{
EXEC SQL BEGIN DECLARE SECTION ;
char sCommand[512];
EXEC SQL END DECLARE SECTION ;
dh_char_t *data[] = {
DH_STRING_LITERAL("(10,19.95,'1','Hammer')"),
DH_STRING_LITERAL("(3, 9.99,'2','Wrench')"),
DH_STRING_LITERAL("(4, 16.59,'3','Saw')"),
DH_STRING_LITERAL("(1, 3.98,'4','Pliers')")
};
int i;
int nRecords = sizeof(data) / sizeof(data[0]);
Delete_Records(DH_STRING_LITERAL("itemmast"));
os_printf(DH_STRING_LITERAL("\tAdd records in table ItemMaster...\n"));

Quick Tour
All Rights Reserved 23 www.faircom.com
/* add one record at time to table */
for (i = 0; i < nRecords; i++)
{
os_sprintf (sCommand, DH_STRING_LITERAL("INSERT INTO itemmast VALUES %s"), data[i]);
EXEC SQL EXECUTE IMMEDIATE :sCommand ;
if (sqlca.sqlcode)
Handle_Error(sqlca.sqlcode, sqlca.sqlerrm);
}
EXEC SQL COMMIT WORK;
}

Quick Tour
All Rights Reserved 24 www.faircom.com
Done
When an application and/or process has completed operations with the database, it must release
resources by disconnecting from the database engine.
Below is the code for Done():
/*
* Done()
*
* This function handles the housekeeping of closing connection and
* freeing of associated memory
*/
void Done(void)
{
os_printf(DH_STRING_LITERAL("DONE\n"));
/* disconnect from server */
EXEC SQL DISCONNECT CURRENT ;
if (sqlca.sqlcode)
Handle_Error(sqlca.sqlcode, sqlca.sqlerrm);
}

Quick Tour
All Rights Reserved 25 www.faircom.com
Additional Resources
We encourage you to explore the additional resources listed here:
Complete source code for this tutorial can be found in eSQL_Tutorial2.pc in your installation
directory, within the 'sdk\sql.embedded\tutorials' directory for your platform.
Example for the Windows platform:
C:\FairCom\V*\win32\sdk\sql.embedded\tutorials\eSQL_Tutorial2.pc.
Additional documentation may be found on the FairCom Web site at: www.faircom.com

Quick Tour
All Rights Reserved 26 www.faircom.com
2.3 Record/Row Locking
..\sdk\sql.embedded\tutorials\eSQL_Tutorial3.pc
Now we will explore row/record locks using the c-treeACE SQL ESQL - Embedded SQL Interface
The functionality for this tutorial focuses on inserting/adding rows/records, then updating a single
row/record in the customer master table under locking control. The application will pause after a
LOCK is placed on a row/record. Another instance of this application should then be launched,
which will block, waiting on the lock held by the first instance. Pressing the <Enter> key will
enable the first instance to proceed. This will result in removing the lock thereby allowing the
second instance to continue execution. Launching two processes provides a visual demonstration
of the effects of locking and a basis for experimentation on your own.
Like all other examples in the c-tree tutorial series, this tutorial simplifies the creation and use of a
database into four simple steps: Initialize(), Define(), Manage(), and you’re Done() !
Tutorial #3: Locking
Here we demonstrate the enforcement of data integrity by introducing record/row "locking".
Initialize() - Connects to the c-treeACE Database Engine.
Define() - Defines and creates a "customer master" (custmast) table/file.
Manage() - Adds a few rows/records; Reads the rows/records back from the database;
displays the column/field content. Then demonstrates an update operation under locking
control, and a scenario that shows a locking conflict.
Done() - Disconnects from c-treeACE Database Engine.
Note our simple mainline:
/*
* main()
*
* The main() function implements the concept of "init, define, manage
* and you're done..."
*/
int main(int argc, char* argv[])
{
Initialize();
Define();
Manage();
Done();
os_printf(DH_STRING_LITERAL("\nPress <ENTER> key to exit . . .\n"));
getchar();
return(0);
}
We suggest opening the source code with your own editor.
Continue now to review these four steps.
Quick Tour
All Rights Reserved 27 www.faircom.com
Init
First we need to open a connection to a database by providing the c-treeACE Database Engine
with a user name, password and the database name.
Below is the code for Initialize():
/*
* Initialize()
*
* Perform the minimum requirement of logging onto the c-tree Server
*/
void Initialize(void)
{
os_printf(DH_STRING_LITERAL("INIT\n"));
os_setenv (DH_STRING_LITERAL("DH_USER"), DH_STRING_LITERAL("ADMIN"));
os_setenv (DH_STRING_LITERAL("DH_PASSWD"), DH_STRING_LITERAL("ADMIN"));
os_setenv (DH_STRING_LITERAL("DB_NAME"), DH_STRING_LITERAL("ctreeSQL"));
EXEC SQL CONNECT TO DEFAULT ;
if (sqlca.sqlcode)
Handle_Error(sqlca.sqlcode, sqlca.sqlerrm);
}
Quick Tour
All Rights Reserved 28 www.faircom.com
Define
The define step is where specific data definitions are established by your application and/or
process. This involves defining columns/fields and creating the tables/files with optional indices.
Below is the code for Define():
/*
* Define()
*
* Create the table for containing a list of existing customers
*/
void Define(void)
{
os_printf(DH_STRING_LITERAL("DEFINE\n"));
/* create table */
os_printf(DH_STRING_LITERAL("\tCreate table...\n"));
EXEC SQL CREATE TABLE custmast (
cm_custnumb CHAR(4),
cm_custzipc CHAR(9),
cm_custstat CHAR(2),
cm_custrtng CHAR(1),
cm_custname VARCHAR(47),
cm_custaddr VARCHAR(47),
cm_custcity VARCHAR(47)
) ;
if (sqlca.sqlcode)
Handle_Error(sqlca.sqlcode, sqlca.sqlerrm);
EXEC SQL CREATE UNIQUE INDEX cm_custnumb_idx ON custmast (cm_custnumb) ;
if (sqlca.sqlcode)
Handle_Error(sqlca.sqlcode, sqlca.sqlerrm);
EXEC SQL COMMIT WORK;
}
Quick Tour
All Rights Reserved 29 www.faircom.com
Manage
The manage step provides data management functionality for your application and/or process.
Below is the code for Manage():
/*
* Manage()
*
* This function performs simple record functions of add, delete and gets
*/
void Manage(void)
{
os_printf(DH_STRING_LITERAL("MANAGE\n"));
/* delete any existing records */
Delete_Records();
/* populate the table with data */
Add_CustomerMaster_Records();
/* display contents of table */
Display_Records();
/* update a record under locking control */
Update_CustomerMaster_Record();
/* display again after update and effects of lock */
Display_Records();
}
/*
* Delete_Records()
*
* This function deletes all the records in the table
*/
void Delete_Records(void)
{
os_printf(DH_STRING_LITERAL("\tDelete records...\n"));
EXEC SQL DELETE FROM custmast ;
if (sqlca.sqlcode < 0)
Handle_Error(sqlca.sqlcode, sqlca.sqlerrm);
EXEC SQL COMMIT WORK ;
}
/*
* Add_CustomerMaster_Records()
*
* This function adds records to table CustomerMaster from an
* array of strings
*/

Quick Tour
All Rights Reserved 30 www.faircom.com
void Add_CustomerMaster_Records(void)
{
EXEC SQL BEGIN DECLARE SECTION ;
char sCommand[512];
EXEC SQL END DECLARE SECTION ;
dh_char_t *data[] = {
DH_STRING_LITERAL("('1000','92867','CA','1','Bryan Williams','2999 Regency','Orange')"),
DH_STRING_LITERAL("('1001','61434','CT','1','Michael Jordan','13 Main','Harford')"),
DH_STRING_LITERAL("('1002','73677','GA','1','Joshua Brown','4356
Cambridge','Atlanta')"),
DH_STRING_LITERAL("('1003','10034','MO','1','Keyon Dooling','19771 Park
Avenue','Columbia')")
};
int i;
int nRecords = sizeof(data) / sizeof(data[0]);
Delete_Records();
os_printf(DH_STRING_LITERAL("\tAdd records...\n"));
/* add one record at time to table */
for (i = 0; i < nRecords; i++)
{
os_sprintf (sCommand, DH_STRING_LITERAL("INSERT INTO custmast VALUES %s"), data[i]);
EXEC SQL EXECUTE IMMEDIATE :sCommand ;
if (sqlca.sqlcode)
Handle_Error(sqlca.sqlcode, sqlca.sqlerrm);
}
EXEC SQL COMMIT WORK;
}
/*
* Display_Records()
*
* This function displays the contents of a table.
*/
void Display_Records(void)
{
EXEC SQL BEGIN DECLARE SECTION ;
CHAR custnumb[5+1];
CHAR custname[47+1];
EXEC SQL END DECLARE SECTION ;
os_printf(DH_STRING_LITERAL("\tDisplay records..."));
EXEC SQL DECLARE curs CURSOR FOR
SELECT custmast.cm_custnumb, custmast.cm_custname FROM custmast;
if (sqlca.sqlcode)
Handle_Error(sqlca.sqlcode, sqlca.sqlerrm);
EXEC SQL OPEN curs;
if (sqlca.sqlcode)
Handle_Error(sqlca.sqlcode, sqlca.sqlerrm);
EXEC SQL FETCH curs INTO :custnumb, :custname;
/* fetch and display each individual record */
while (!sqlca.sqlcode)

Quick Tour
All Rights Reserved 31 www.faircom.com
{
os_printf(DH_STRING_LITERAL("\n\t\t%-8s%10s\n"),custnumb, custname);
EXEC SQL FETCH curs INTO :custnumb, :custname;
}
EXEC SQL CLOSE curs ;
}
/*
* Update_CustomerMaster_Records()
*
* Update one record under locking control to demonstrate the effects
* of locking
*/
void Update_CustomerMaster_Record(void)
{
os_printf(DH_STRING_LITERAL("\tUpdate record...\n"));
EXEC SQL UPDATE custmast SET cm_custname = 'KEYON DOOLING' WHERE cm_custnumb = '1003';
if (sqlca.sqlcode)
Handle_Error(sqlca.sqlcode, sqlca.sqlerrm);
os_printf(DH_STRING_LITERAL("\tPress <ENTER> key to unlock\n"));
getchar();
EXEC SQL COMMIT WORK;
}

Quick Tour
All Rights Reserved 32 www.faircom.com
Done
When an application and/or process has completed operations with the database, it must release
resources by disconnecting from the database engine.
Below is the code for Done():
/*
* Done()
*
* This function handles the housekeeping of closing connection and
* freeing of associated memory
*/
void Done(void)
{
os_printf(DH_STRING_LITERAL("DONE\n"));
/* disconnect from server */
EXEC SQL DISCONNECT CURRENT ;
if (sqlca.sqlcode)
Handle_Error(sqlca.sqlcode, sqlca.sqlerrm);
}

Quick Tour
All Rights Reserved 33 www.faircom.com
Additional Resources
We encourage you to explore the additional resources listed here:
Complete source code for this tutorial can be found in eSQL_Tutorial3.pc in your installation
directory, within the 'sdk\sql.embedded\tutorials' directory for your platform.
Example for the Windows platform:
C:\FairCom\V*\win32\sdk\sql.embedded\tutorials\eSQL_Tutorial3.pc.
Additional documentation may be found on the FairCom Web site at: www.faircom.com

Quick Tour
All Rights Reserved 34 www.faircom.com
2.4 Transaction Processing
..\sdk\sql.embedded\tutorials\eSQL_Tutorial4.pc
Now we will discuss transaction processing as it relates to the c-treeACE SQL ESQL -
Embedded SQL Interface
Transaction processing provides a safe method by which multiple database operations spread
across separate tables/files are guaranteed to be atomic. By atomic, we mean that, within a
transaction, either all of the operations succeed or none of the operations succeed. This "either
all or none" atomicity insures that the integrity of the data in related tables/files is secure.
Like all other examples in the c-tree tutorial series, this tutorial simplifies the creation and use of a
database into four simple steps: Initialize(), Define(), Manage(), and You’re Done() !
Tutorial #4: Transaction Processing
Here we demonstrate transaction control.
Initialize() - Connects to the c-treeACE Database Engine.
Define() - Defines and creates our four tables/files.
Manage() - Adds rows/records to multiple tables/files under transaction control.
Done() - Disconnects from c-treeACE Database Engine.
Note our simple mainline:
/*
* main()
*
* The main() function implements the concept of "init, define, manage
* and you're done..."
*/
int main(int argc, char* argv[])
{
Initialize();
Define();
Manage();
Done();
os_printf(DH_STRING_LITERAL("\nPress <ENTER> key to exit . . .\n"));
getchar();
return(0);
}
We suggest opening the source code with your own editor.
Continue now to review these four steps.

Quick Tour
All Rights Reserved 35 www.faircom.com
Init
First we need to open a connection to a database by providing the c-treeACE Database Engine
with a user name, password and the database name.
Below is the code for Initialize():
/*
* Initialize()
*
* Perform the minimum requirement of logging onto the c-tree Server
*/
void Initialize(void)
{
os_printf(DH_STRING_LITERAL("INIT\n"));
os_setenv (DH_STRING_LITERAL("DH_USER"), DH_STRING_LITERAL("ADMIN"));
os_setenv (DH_STRING_LITERAL("DH_PASSWD"), DH_STRING_LITERAL("ADMIN"));
os_setenv (DH_STRING_LITERAL("DB_NAME"), DH_STRING_LITERAL("ctreeSQL"));
EXEC SQL CONNECT TO DEFAULT ;
if (sqlca.sqlcode)
Handle_Error(sqlca.sqlcode, sqlca.sqlerrm);
}
Quick Tour
All Rights Reserved 36 www.faircom.com
Define
The define step is where specific data definitions are established by your application and/or
process. This involves defining columns/fields and creating the tables/files with optional indices.
Below is the code for Define():
/*
* Define()
*
* Create the tables
*/
void Define(void)
{
os_printf(DH_STRING_LITERAL("DEFINE\n"));
/* delete tables ... */
Delete_Tables();
/* ...and re-create them with constraints */
Create_CustomerMaster_Table();
Create_ItemMaster_Table();
Create_CustomerOrders_Table();
Create_OrderItems_Table();
EXEC SQL COMMIT WORK ;
}
/*
* Create_CustomerMaster_Table()
*
* Create the CustomerMaster
*/
void Create_CustomerMaster_Table(void)
{
EXEC SQL BEGIN DECLARE SECTION ;
char sCommand[512];
EXEC SQL END DECLARE SECTION ;
/* define table CustomerMaster */
os_printf(DH_STRING_LITERAL("\ttable CustomerMaster\n"));
os_sprintf (sCommand, DH_STRING_LITERAL("CREATE TABLE custmast ( \
cm_custnumb CHAR(4) PRIMARY KEY, \
cm_custzipc CHAR(9), \
cm_custstat CHAR(2), \
cm_custrtng CHAR(1), \
cm_custname VARCHAR(47), \
cm_custaddr VARCHAR(47), \
cm_custcity VARCHAR(47) \
)"));
EXEC SQL EXECUTE IMMEDIATE :sCommand ;

Quick Tour
All Rights Reserved 37 www.faircom.com
if (sqlca.sqlcode)
Handle_Error(sqlca.sqlcode, sqlca.sqlerrm);
}
/*
* Create_CustomerOrders_Table()
*
* Create the CustomerOrders
*/
void Create_CustomerOrders_Table(void)
{
EXEC SQL BEGIN DECLARE SECTION ;
char sCommand[512];
EXEC SQL END DECLARE SECTION ;
/* define table CustomerOrders */
os_printf(DH_STRING_LITERAL("\ttable CustomerOrders\n"));
os_sprintf (sCommand, DH_STRING_LITERAL("CREATE TABLE custordr ( \
co_ordrdate DATE, \
co_promdate DATE, \
co_ordrnumb CHAR(6) PRIMARY KEY, \
co_custnumb CHAR(4), \
FOREIGN KEY (co_custnumb) REFERENCES custmast \
)"));
EXEC SQL EXECUTE IMMEDIATE :sCommand ;
if (sqlca.sqlcode)
Handle_Error(sqlca.sqlcode, sqlca.sqlerrm);
}
/*
* Create_OrderItems_Table()
*
* Create the OrderItems
*/
void Create_OrderItems_Table(void)
{
EXEC SQL BEGIN DECLARE SECTION ;
char sCommand[512];
EXEC SQL END DECLARE SECTION ;
/* define table OrderItems */
os_printf(DH_STRING_LITERAL("\ttable OrderItems\n"));
os_sprintf (sCommand, DH_STRING_LITERAL("CREATE TABLE ordritem ( \
oi_sequnumb SMALLINT, \
oi_quantity SMALLINT, \
oi_ordrnumb CHAR(6), \
oi_itemnumb CHAR(5), \
FOREIGN KEY (oi_itemnumb) REFERENCES itemmast, \
FOREIGN KEY (oi_ordrnumb) REFERENCES custordr \
)"));
EXEC SQL EXECUTE IMMEDIATE :sCommand ;
if (sqlca.sqlcode)
Handle_Error(sqlca.sqlcode, sqlca.sqlerrm);
}

Quick Tour
All Rights Reserved 38 www.faircom.com
/*
* Create_ItemMaster_Table()
*
* Create the ItemMaster
*/
void Create_ItemMaster_Table(void)
{
EXEC SQL BEGIN DECLARE SECTION ;
char sCommand[512];
EXEC SQL END DECLARE SECTION ;
/* define table ItemMaster */
os_printf(DH_STRING_LITERAL("\ttable ItemMaster\n"));
os_sprintf (sCommand, DH_STRING_LITERAL("CREATE TABLE itemmast ( \
im_itemwght INTEGER, \
im_itempric MONEY, \
im_itemnumb CHAR(5) PRIMARY KEY, \
im_itemdesc VARCHAR(47) \
)"));
EXEC SQL EXECUTE IMMEDIATE :sCommand ;
if (sqlca.sqlcode)
Handle_Error(sqlca.sqlcode, sqlca.sqlerrm);
}

Quick Tour
All Rights Reserved 39 www.faircom.com
Manage
The manage step provides data management functionality for your application and/or process.
Below is the code for Manage():
/*
* Manage()
*
* Populates table and perform a simple query
*
*/
void Manage(void)
{
os_printf(DH_STRING_LITERAL("MANAGE\n"));
/* populate the tables with data */
Add_CustomerMaster_Records();
Add_ItemMaster_Records();
Add_Transactions();
/* display the orders and their items */
Display_CustomerOrders();
Display_OrderItems();
}
/*
* Delete_Tables()
*
* This function removes all existing tables
*/
void Delete_Tables(void)
{
EXEC SQL BEGIN DECLARE SECTION ;
char sCommand[512];
EXEC SQL END DECLARE SECTION ;
os_sprintf (sCommand, DH_STRING_LITERAL("DROP TABLE ordritem"));
EXEC SQL EXECUTE IMMEDIATE :sCommand ;
if (sqlca.sqlcode)
Handle_Error(sqlca.sqlcode, sqlca.sqlerrm);
os_sprintf (sCommand, DH_STRING_LITERAL("DROP TABLE custordr"));
EXEC SQL EXECUTE IMMEDIATE :sCommand ;
if (sqlca.sqlcode)
Handle_Error(sqlca.sqlcode, sqlca.sqlerrm);
os_sprintf (sCommand, DH_STRING_LITERAL("DROP TABLE itemmast"));
EXEC SQL EXECUTE IMMEDIATE :sCommand ;
if (sqlca.sqlcode)
Handle_Error(sqlca.sqlcode, sqlca.sqlerrm);
os_sprintf (sCommand, DH_STRING_LITERAL("DROP TABLE custmast"));
EXEC SQL EXECUTE IMMEDIATE :sCommand ;

Quick Tour
All Rights Reserved 40 www.faircom.com
if (sqlca.sqlcode)
Handle_Error(sqlca.sqlcode, sqlca.sqlerrm);
}
/*
* Add_CustomerMaster_Records()
*
* This function adds records to table CustomerMaster from an
* array of strings
*/
void Add_CustomerMaster_Records(void)
{
EXEC SQL BEGIN DECLARE SECTION ;
char sCommand[512];
EXEC SQL END DECLARE SECTION ;
dh_char_t *data[] = {
DH_STRING_LITERAL("('1000','92867','CA','1','Bryan Williams','2999 Regency','Orange')"),
DH_STRING_LITERAL("('1001','61434','CT','1','Michael Jordan','13 Main','Harford')"),
DH_STRING_LITERAL("('1002','73677','GA','1','Joshua Brown','4356
Cambridge','Atlanta')"),
DH_STRING_LITERAL("('1003','10034','MO','1','Keyon Dooling','19771 Park
Avenue','Columbia')")
};
int i;
int nRecords = sizeof(data) / sizeof(data[0]);
os_printf(DH_STRING_LITERAL("\tAdd records in table CustomerMaster...\n"));
/* add one record at time to table */
for (i = 0; i < nRecords; i++)
{
os_sprintf (sCommand, DH_STRING_LITERAL("INSERT INTO custmast VALUES %s"), data[i]);
EXEC SQL EXECUTE IMMEDIATE :sCommand ;
if (sqlca.sqlcode)
Handle_Error(sqlca.sqlcode, sqlca.sqlerrm);
}
EXEC SQL COMMIT WORK;
}
/*
* Add_ItemMaster_Records()
*
* This function adds records to table ItemMaster from an
* array of strings
*/
void Add_ItemMaster_Records(void)
{
EXEC SQL BEGIN DECLARE SECTION ;
char sCommand[512];
EXEC SQL END DECLARE SECTION ;
dh_char_t *data[] = {
DH_STRING_LITERAL("(10,19.95,'1','Hammer')"),
DH_STRING_LITERAL("(3, 9.99,'2','Wrench')"),
DH_STRING_LITERAL("(4, 16.59,'3','Saw')"),
DH_STRING_LITERAL("(1, 3.98,'4','Pliers')")
};

Quick Tour
All Rights Reserved 41 www.faircom.com
int i;
int nRecords = sizeof(data) / sizeof(data[0]);
os_printf(DH_STRING_LITERAL("\tAdd records in table ItemMaster...\n"));
/* add one record at time to table */
for (i = 0; i < nRecords; i++)
{
os_sprintf (sCommand, DH_STRING_LITERAL("INSERT INTO itemmast VALUES %s"), data[i]);
EXEC SQL EXECUTE IMMEDIATE :sCommand ;
if (sqlca.sqlcode)
Handle_Error(sqlca.sqlcode, sqlca.sqlerrm);
}
EXEC SQL COMMIT WORK;
}
/*
* Add_Transactions()
*
* Add an Order and associated Items "as a transaction" to their
* respective tables. A transaction is committed or aborted if the
* customer number on the order is confirmed valid. Likewise each
* item in the order is verified to be a valid item.
*/
typedef struct {
dh_char_t *ordrdate, *promdate, *ordrnumb, *custnumb;
} ORDER_DATA;
typedef struct {
dh_char_t* ordrnumb;
short sequnumb;
short quantity;
dh_char_t* itemnumb;
} ORDERITEM_DATA;
ORDER_DATA orders[] = {
{DH_STRING_LITERAL("09/01/2002"), DH_STRING_LITERAL("09/05/2002"), DH_STRING_LITERAL("1"),
DH_STRING_LITERAL("1001")},
{DH_STRING_LITERAL("09/02/2002"), DH_STRING_LITERAL("09/06/2002"), DH_STRING_LITERAL("2"),
DH_STRING_LITERAL("9999")}, /* bad customer number */
{DH_STRING_LITERAL("09/22/2002"), DH_STRING_LITERAL("09/26/2002"), DH_STRING_LITERAL("3"),
DH_STRING_LITERAL("1003")}
};
ORDERITEM_DATA items[] = {
{DH_STRING_LITERAL("1"), 1, 2, DH_STRING_LITERAL("1")},
{DH_STRING_LITERAL("1"), 2, 1, DH_STRING_LITERAL("2")},
{DH_STRING_LITERAL("2"), 1, 1, DH_STRING_LITERAL("3")},
{DH_STRING_LITERAL("2"), 2, 3, DH_STRING_LITERAL("4")},
{DH_STRING_LITERAL("3"), 1, 2, DH_STRING_LITERAL("3")},
{DH_STRING_LITERAL("3"), 2, 2, DH_STRING_LITERAL("99")} /* bad item number */
};
void Add_Transactions(void)
{
EXEC SQL BEGIN DECLARE SECTION ;
CHAR sCommand[512];
EXEC SQL END DECLARE SECTION ;

Quick Tour
All Rights Reserved 42 www.faircom.com
int i, j = 0;
int nOrders = sizeof(orders) / sizeof(ORDER_DATA);
int nItems = sizeof(items) / sizeof(ORDERITEM_DATA);
os_printf(DH_STRING_LITERAL("\tAdd transaction records... \n"));
for (i = 0; i < nOrders; i++)
{
/* add order record */
os_sprintf(sCommand, DH_STRING_LITERAL("INSERT INTO custordr VALUES ('%s', '%s', '%s',
'%s')"),
orders[i].ordrdate,
orders[i].promdate,
orders[i].ordrnumb,
orders[i].custnumb);
EXEC SQL EXECUTE IMMEDIATE :sCommand ;
if (sqlca.sqlcode)
Handle_Error(sqlca.sqlcode, sqlca.sqlerrm);
/* process order items */
while (!(strcmp(items[j].ordrnumb, orders[i].ordrnumb)))
{
/* add item record */
os_sprintf(sCommand, DH_STRING_LITERAL("INSERT INTO ordritem VALUES (%d, %d, '%s',
'%s')"),
items[j].sequnumb,
items[j].quantity,
items[j].ordrnumb,
items[j].itemnumb);
EXEC SQL EXECUTE IMMEDIATE :sCommand ;
if (sqlca.sqlcode)
Handle_Error(sqlca.sqlcode, sqlca.sqlerrm);
/* bump to next item */
j++;
/* exit the while loop on last item */
if (j >= nItems)
break;
}
EXEC SQL COMMIT WORK;
}
}
/*
* Display_CustomerOrders()
*
* This function displays the contents of CustomerOrders table
*/
void Display_CustomerOrders(void)
{
EXEC SQL BEGIN DECLARE SECTION ;
CHAR ordrnumb[6+1];
CHAR custnumb[4+1];
EXEC SQL END DECLARE SECTION ;
os_printf(DH_STRING_LITERAL("\n\tCustomerOrders Table...\n"));
EXEC SQL DECLARE curs CURSOR FOR

Quick Tour
All Rights Reserved 43 www.faircom.com
SELECT co_ordrnumb, co_custnumb FROM custordr;
if (sqlca.sqlcode)
Handle_Error(sqlca.sqlcode, sqlca.sqlerrm);
EXEC SQL OPEN curs;
if (sqlca.sqlcode)
Handle_Error(sqlca.sqlcode, sqlca.sqlerrm);
EXEC SQL FETCH curs INTO :ordrnumb, :custnumb;
/* fetch and display each individual record */
while (!sqlca.sqlcode)
{
os_printf(DH_STRING_LITERAL("\t %s %s\n"), ordrnumb, custnumb);
EXEC SQL FETCH curs INTO :ordrnumb, :custnumb;
}
EXEC SQL CLOSE curs ;
}
/*
* Display_OrderItems()
*
* This function displays the contents of OrderItems table
*/
void Display_OrderItems(void)
{
EXEC SQL BEGIN DECLARE SECTION ;
CHAR ordrnumb[6+1];
CHAR itemnumb[5+1];
EXEC SQL END DECLARE SECTION ;
os_printf(DH_STRING_LITERAL("\n\tOrderItems Table...\n"));
EXEC SQL DECLARE cur2 CURSOR FOR
SELECT oi_ordrnumb, oi_itemnumb FROM ordritem;
if (sqlca.sqlcode)
Handle_Error(sqlca.sqlcode, sqlca.sqlerrm);
EXEC SQL OPEN cur2;
if (sqlca.sqlcode)
Handle_Error(sqlca.sqlcode, sqlca.sqlerrm);
EXEC SQL FETCH cur2 INTO :ordrnumb, :itemnumb;
/* fetch and display each individual record */
while (!sqlca.sqlcode)
{
os_printf(DH_STRING_LITERAL("\t %s %s\n"), ordrnumb, itemnumb);
EXEC SQL FETCH cur2 INTO :ordrnumb, :itemnumb;
}
EXEC SQL CLOSE cur2 ;
}

Quick Tour
All Rights Reserved 44 www.faircom.com
Done
When an application and/or process has completed operations with the database, it must release
resources by disconnecting from the database engine.
Below is the code for Done():
/*
* Done()
*
* This function handles the housekeeping of closing connection and
* freeing of associated memory
*/
void Done(void)
{
os_printf(DH_STRING_LITERAL("DONE\n"));
Delete_Tables();
EXEC SQL COMMIT WORK ;
/* disconnect from server */
EXEC SQL DISCONNECT CURRENT ;
if (sqlca.sqlcode)
Handle_Error(sqlca.sqlcode, sqlca.sqlerrm);
}

Quick Tour
All Rights Reserved 45 www.faircom.com
Additional Resources
We encourage you to explore the additional resources listed here:
Complete source code for this tutorial can be found in eSQL_Tutorial4.pc in your installation
directory, within the 'sdk\sql.embedded\tutorials' directory for your platform.
Example for the Windows platform:
C:\FairCom\V*\win32\sdk\sql.embedded\tutorials\eSQL_Tutorial4.pc.
Additional documentation may be found on the FairCom Web site at: www.faircom.com

All Rights Reserved 46 www.faircom.com
3. Using the esqlc Command
3.1 Introduction
The esql command takes as input a set of esql source files (by convention, files with .pc as the
file name extension) and generates corresponding C source files (.c files). The C source files are
compiled and linked using the C compiler and linker to create and application executable ( .exe
file).
The following figure illustrates the sequence of using esql to create executable files.
ESQL Compilation Process
Equation 1: -1: ESQL Compilation Process
3.2 esqlc Command Line Reference
The esql command invokes the ESQL precompiler. Without any arguments, the esql command
displays a summary of the command syntax and options described here.
The esql command also accepts the following arguments, detailed in this section:
Options specific to the esql precompiler
Options to be passed to the C compiler and linker for processing
The names of esql source code files, and optionally, C-language source and object files
Depending on the options included in the esql command, the precompiler translates the esql
source files specified into C source files and then invokes the C compiler to compile and link them
into executable objects.

Using the esqlc Command
All Rights Reserved 47 www.faircom.com
Before invoking esql, make sure the PATH environment variable includes the directory that
contains the esql image (the default location is C:\FairCom\Vx.xx\c-treeServers\Utils\bin).
Syntax esqlc [ [ esql_option … ] [ c_option … ] file_name … ]
esql_option ::
+T
| +P
| +B
| +L
| +V
| +K
| +G
| +M
| +D connect_string
| +U user_name
| +A password
Arguments
esql_option
A list of precompiler-specific options. Precede esql-specific options with a plus sign ( + ) to
avoid confusion with C compiler and linker options. The esql command passes all command line
options that it does not recognize to the C compiler., providing the user a means to specify C
compiler options directly as options to the esql command.
+T - Translates the embedded SQL source code to C source code withinvoking the C
compiler to generate the object or executable files. If the command line omits this option, the
precompiler invokes the C compiler
+P - Runs the C preprocessor on the input file before translating the c-treeSQL statements in
the input file. This allows using #define symbols in ESQL declarations and statements. If the
command line omits this option, the precompiler does not run the C preprocessor.
+B - Specifies that the precompiler link with shared libraries instead of static libraries. The
effect of specifying the +B option is the same as setting the TPE_DLL environment variable to
Y. For either to work correctly, the c-treeSQL libraries and executables must have been built
specifying the USE_SHARED_LIBS directive through the TPE_ENV environment variable.
See the c-treeSQL Installation and Release Notes for details. If the esql command omits the
+B option, the default is to link with static libraries.
+L - Suppresses redefinition of source line numbers in the generated C code, to simplify
debugging of host language statements. If the command line omits this option, the
precompiler redefines source line numbers.
+V - Displays the commands the precompiler invokes as it processes the files.
+K - Keeps intermediate C source code and object files. If the command line omits this
option, the precompiler does not keep the intermediate files.
+G - Inserts debugging code.
+M - Produces an executable that links the front and back end of the c-treeSQL engine in a
single merged image. Specify this option with the -l C compiler option and the appropriate
object library in $TPEROOT/lib. For example:

Using the esqlc Command
All Rights Reserved 48 www.faircom.com
esqlc +M progname -l$TPEROOT/lib/libstubs.a
+D connect_string - A string that specifies which database to connect to at compile time. The
database is used for accessing the definition of tables used in the application code. The
connect string can be a simple database name or a complete connect string. See the
CONNECT statement in the c-treeSQL Reference Manual for details on how to specify a
complete connect string. If omitted, the default value depends on the environment (on UNIX,
the value of the DB_NAME environment variable specifies the default connect string).
+U user_name - The user name c-treeSQL uses to connect to the database specified in the
connect_string. c-treeSQL verifies the user name against a corresponding password before it
connects to the database. If omitted, the default value depends on the environment. (On Unix
the value of the DH_USER environment variable specifies the default user name. If
DH_USER is not set, the value of the USER environment variable specifies the default user
name.
+A password - The password c-treeSQL uses to connect to the database specified in the
connect_string. c-treeSQL verifies the password against a corresponding user name before it
connects to the database. If omitted, the default value depends on the environment (on Unix
the value of the DH_PASSWD environment variable specifies the default password).
c_option
C compiler options. The esql command passes any command line options that it does not
recognize to the C compiler. Typical C compiler options you might use include:
-o To specify the name of the output executable object
-c To suppress linking of object files generated by the C compiler
See the documentation for the C compiler in your environment for details on valid options.
file_name
A list of esql source files (by convention, with a .pc file-name extension) for the precompiler to
translate into C source files (which the precompiler generates with .c file-name extensions). The
file_name argument can include C source files and object files. The precompiler passes them to
the compiler and linker, respectively.
3.3 esqlc Command Examples
The following examples illustrate different ways of using the esql command.
Precompiling, Compiling, and Linking Multiple Files with esqlc
The most straightforward use of esql is to accept the various default values of both the
precompiler and compiler. These defaults result in the precompiler automatically invoking the
compiler, which in turn invokes the linker, generating an executable in one step.

Using the esqlc Command
All Rights Reserved 49 www.faircom.com
Consider a report-generating application with source code contained in two esql source files,
rep1.pc and rep2.pc. The following example accepts all the precompiler defaults but specifies the
-o C compiler option to specify the name of the output executable file as report.
Equation 2: -1: ESQL Compilation Process
Issuing Separate Commands for Precompiling, Compiling, and
Linking
Alternatively, the following sequence of commands generates the same executable and illustrates
how you can combine options and commands:
esqlc +T rep1.pc
cc -c rep1.c
esqlc +T rep2.pc
cc -c rep2.c
esqlc -o report rep1.o rep2.o
The esql +T commands specify a single embedded SQL source file. The +T precompiler
option generates the C source code but suppresses automatic invocation of the C compiler.
The cc -c commands explicitly invoke the C compiler and specify the C source-code file from
the corresponding esql +T command. The -c compiler option generates an object file but
suppresses linking.
Finally, the esql -o command specifies both the object files generated by the preceding cc -c
commands. It does not actually invoke the precompiler, but passes the object files to the C
compiler. The -o option is a C compiler option that names the executable.
Mixing Precompiler/Compiler Options in the esqlc Command
The esql command can include both precompiler and compiler options. For instance, the
following command uses the -o compiler option and the +P precompiler option:
esqlc -o report +P rep1.pc rep2.pc
The -o option names the executable generated by the compiler.
The +P option runs the C preprocessor before translating c-treeSQL statements. If c-treeSQL
statements embedded in the files rep1.pc and rep2.pc use symbolic names specified through
#define precompiler directives, then the esqlc command must include the +P option.

All Rights Reserved 50 www.faircom.com
4. ESQL Program Structure
4.1 Introduction
This chapter describes the overall program structure of an ESQL program and discusses:
The ESQL declare statements
ESQL executable statements
The c-treeSQL Communications Area
COMMIT and ROLLBACK statements
4.2 ESQL Declare Statements
The ESQL precompiler is used to parse and translate ESQL constructs, prefixed with EXEC SQL,
to C language statements. ESQL does not allow the use of host language defined variables in
ESQL constructs. To declare variables for use in the ESQL constructs, ESQL provides declare
statements. The ESQL constructs within which the variables can be declared for use in ESQL
statements are referred to as the declare section. For more information on the declare section,
see "BEGIN-END DECLARE SECTION" (page 153). The following ESQL constructs are used to
mark the beginning and end of a declare section:
EXEC SQL BEGIN DECLARE SECTION ;
...
EXEC SQL END DECLARE SECTION ;
The declare section should appear before any other ESQL constructs are used. Only C
statements can precede the declare section in an ESQL program. The variables appearing in the
declare section can either be declared as local variables or global variables. The following is an
example showing the declaration for variables that would be used in the order processing
application program:
...
EXEC SQL BEGIN DECLARE SECTION ;
long order_no_v ;
char order_date_v [10] ;
char product_v [5] ;
long qty_v ;
EXEC SQL END DECLARE SECTION ;
...

ESQL Program Structure
All Rights Reserved 51 www.faircom.com
The above ESQL constructs declare the variable order_no_v to be of type long, product_v to be
an array of char and qty_v to be a variable of type long. The ESQL precompiler generates the
corresponding host language declarations for these variables and hence these variables can be
used by the C language statements at the application developer’s convenience.
The variables that could be declared in the declare section are host variables and indicator
variables. These variables and their usage are discussed in more detail in the following sections.
Note: The ESQL precompiler does not check for or generate messages about unused variables in the declare section.
Host Variables and their Usage
The host language variables that are used in the ESQL statements appearing in an ESQL
program are called host variables. Host variables must be declared in the declare section prior to
its usage in an ESQL program. The data types used to declare the host variables can be the
same as database types. For example, to declare a host variable of type SHORT, the variable
can be declared as the database type SMALLINT.
The general format of using the host variable in an ESQL construct is shown below:
:host_variable_name
When a host variable is used in the ESQL constructs, the variable has to be prefixed with a colon.
The following sample ESQL code shows the usage of host variables:
...
EXEC SQL
INSERT INTO orders (order_no, order_date, product, qty)
VALUES (:order_no_v, :order_date_v, :product_v, :qty_v) ;
...
In the above example, it can be seen that whenever host variables are used, they are prefixed
with a colon. The host variables can also be used by C language statements as and when
desired. Keep the following points in mind while using host variables in ESQL. Host variables
must:
Explicitly declare the host variable in the ESQL declare section.
Precede the host variable by a colon (:) when used in an ESQL statement.
Do not precede the host variable by a colon when used in C statements.
Name of the host variable must not be an SQL reserved word.
Use the host variable in an ESQL statement only where a constant can be used.
The host variable can have an associated indicator variable.
Indicator variables are discussed in the following section.
Indicator Variables and their Usage
Indicator variables are optional variables used to handle null values. Each indicator variable is
associated with one host variable. Indicator variables should be of type short or SMALLINT.

ESQL Program Structure
All Rights Reserved 52 www.faircom.com
Programs use indicator variables to insert null values into the database. (There are other
techniques to do this; see "Inserting NULL Values" (page 94) and "Using NULL Values in
Expressions" (page 98) for more details.)
SQL uses indicator variables to indicate that it returned a null value from the database, or that
it returned a value that it was forced to truncate. (Again, there are other ways to check for null
values; see "Using NULL Values in the WHERE Clause" (page 98) for more details.)
Referring to Indicator Variables
The general format for referring to indicator variables in an ESQL program is shown below:
:host_variable_name [ INDICATOR ] :indicator_variable_name
Always use a host variable name when you use an indicator variable reference, and always
precede both references with a colon. The optional keyword INDICATOR clarifies the presence
and purpose of the indicator variable.
Valid values for an indicator variable and their meaning is as follows:
0 The associated host variable contains a non-null value. If set by c-treeSQL, a value of 0 also indicates the value in the host variable has not been truncated.
-1 The value of the associated host variable is null.
>0 The value in the associated host variable was truncated because the variable was too small. The value in the indicator variable is the actual length of the value before truncation.
Keep in mind the following points about indicator variables. Indicator variables must:
Be explicitly declared in the ESQL declare section.
Be declared as short or SMALLINT type.
Be preceded by a colon (:) when used in an ESQL statement.
Not be preceded by a colon when used in a C statement.
Not be named an c-treeSQL reserved word.
Must be preceded by its associated input host variable when used in an ESQL statement.
Inserting Null Values With Indicator Variables
To insert a null value in the table, the application program has to set the indicator variable to
negative one and then execute an INSERT or UPDATE c-treeSQL statement specifying the
indicator variable.
The following example shows the declaration and usage of an indicator variable (qty_i) to insert a
null value into the orders table.
Example Using Indicator Variables to Insert Null Values
...
EXEC SQL BEGIN DECLARE SECTION ;
long order_no_v ;
char order_date_v [10] ;
char product_v [5] ;
long qty_v ;
short qty_i ;

ESQL Program Structure
All Rights Reserved 53 www.faircom.com
EXEC SQL END DECLARE SECTION ;
/* set indicator variable for qty */
/* as -1 for inserting null */
qty_i = -1 ;
...
EXEC SQL
INSERT INTO orders (order_no, product, qty)
VALUES (:order_no_v, :product_v, :qty_v:qty_i) ;
...
Checking Indicator Variables to Test for Returned Null Values
Indicator variables can also be used to test whether a returned value is a null value. This is done
by using the indicator variables along with host variables used for output.
The following example shows how to use indicator variables in the INTO clause of a SELECT
statement to check for null values.
Example Using Indicator Variables to Check for Returned Null Values
EXEC SQL BEGIN DECLARE SECTION ;
long cust_no ;
char phone [13] ;
short i_phone ;
EXEC SQL END DECLARE SECTION ;
cust_no = 1001 ;
EXEC SQL
SELECT c_phone
INTO :phone:i_phone
FROM customer
WHERE cust_no = :cust_no ;
if (i_phone == -1)
printf ("No Phone Number\\n") ;
else
printf ("Phone Number is %s\\n", phone) ;
For more information on indicator variables, see "NULL Value Handling in ESQL" (page 94) and
"Error Handling in ESQL" (page 100).
Limitations of the Declare Section
The ESQL declare section does not allow some of the statements to declare variables as found in
the C language. The limitations of the declare section are listed below:
Referring to names declared in typedef statements is not allowed in the declare section. Such
names are unknown to the ESQL precompiler. Hence, their use would result in an error
condition.
Declaration of a variable to be of a STRUCTURE type is not allowed.

ESQL Program Structure
All Rights Reserved 54 www.faircom.com
Declaring pointers as host variables is not allowed.
Declaring the VARCHAR type in the declare section is not allowed. Instead, CHAR type is to be
used.
4.3 ESQL Executable Statements
The ESQL constructs that result in the execution of instructions on a specified database at
runtime are called the ESQL executable statements. The executable statements form the body of
an ESQL program and are used to access the database. The following example shows a sample
ESQL executable statement:
EXEC SQL
UPDATE orders
SET qty = qty + 1000
WHERE order_no = 1244 ;
The above SQL statement adds 1000 units to the existing quantity for the row in the orders table,
having order number 1244.
Types of Executable Statements
The ESQL executable statements can be categorized into the following types:
DML statements
These statements perform data manipulation operations that can be used to manipulate the
database. The DML operations are SELECT, INSERT, UPDATE and DELETE. The DML
statements are the most frequently used statements in ESQL programs.
DDL statements
These statements perform data definitions on a given database. The DDL statements include
statements for creating tables/views, dropping tables/views etc.
DCL statements
These statements are used basically for maintaining the security of a database.
Transaction management statements
The transaction statements are used for transaction management. The statements include
COMMIT WORK and ROLLBACK WORK.
4.4 The c-treeSQL Communications Area
The ESQL tool provides the error handling facility by returning the status code for every ESQL
executable statement. The status code is returned in the c-treeSQL Communications Area
(SQLCA). The SQLCA contains information about the status of the execution of the most recently
executed c-treeSQL statement. The SQLCA is a structure with components that give additional
information on the status of execution. The SQLCA includes information such as:

ESQL Program Structure
All Rights Reserved 55 www.faircom.com
Warning flags
Error code
Diagnostic text
Number of rows processed for INSERT, UPDATE, and DELETE statements
For example, the application can check to see whether an c-treeSQL statement executed
successfully, and if so, how many rows were inserted or updated. Hence, the SQLCA gives an
application developer the option of taking different actions, based on feedback obtained about the
work just attempted.
The two most frequently used SQLCA components are:
SQLCODE
This component holds a status code after the execution of every executable c-treeSQL
statement. The SQLCODE is of long type that indicates the success or failure of the statement
execution. A zero value returned in SQLCODE indicates a successful execution. A negative
SQLCODE indicates an error in the c-treeSQL statement execution. A positive SQLCODE
indicates a successful execution with a status code. Currently, the only positive status code is
SQL_NOT_FOUND which is returned when there are no more rows to be fetched.
SQLWARN
This component is a character array of size eight where each array element is set to the warning
flag, ‘W’ or a blank. The first element, SQLWARN[0], is set to ‘W’, if any of the other flags is set,
and so indicates that a warning has occurred during the execution.
An alternative way of handling errors is by using the WHENEVER statement. The WHENEVER
statement allows an application developer to take specific actions under cases of exceptions. The
exception cases could be, NOT FOUND, SQLERROR or SQLWARNING. The actions can
include stopping the program, branching, or continuing with the execution.
For more information on error handling refer to "Error Handling in ESQL" (page 100).
The COMMIT WORK and ROLLBACK WORK Statements
Whenever a c-treeSQL statement is executed by an ESQL program, there is an active transaction
associated with that ESQL program. The execution of the first ESQL executable statement in an
ESQL program starts a transaction. All subsequent c-treeSQL statements are executed as part of
this transaction until the transaction is committed or rolled back. After this, the first execution of a
c-treeSQL statement starts a new transaction.
The primary statements that are used for transaction management are COMMIT WORK and
ROLLBACK WORK.
The COMMIT WORK statement is used to make permanent, the changes made on a database. The
following example shows the usage of the COMMIT WORK statement:
...
EXEC SQL
UPDATE orders SET qty = 2000 WHERE order_no = 1001 ;
EXEC SQL COMMIT WORK ;

ESQL Program Structure
All Rights Reserved 56 www.faircom.com
...
The normal termination of a transaction occurs with the successful execution of the COMMIT
WORK statement.
In contrast, the ROLLBACK WORK statement means abnormal termination of a transaction. If a
transaction executes the ROLLBACK WORK statement, all changes made to the database in that
transaction are canceled. The usage of the ROLLBACK WORK statement is similar to the COMMIT
WORK statement and is shown below:
...
EXEC SQL
UPDATE orders
SET qty = 2000
WHERE order_no = 1001 ;
EXEC SQL ROLLBACK WORK ;
...
For more information on transaction statements refer to "Transaction Management in ESQL"
(page 131).

All Rights Reserved 57 www.faircom.com
5. ESQL Application Development
5.1 Introduction
This chapter contains hints and tips for developing ESQL applications:
General guidelines
SQL for computation
SQL for condition evaluation
Indicator variables
Scalar functions
Static and dynamic statements
5.2 Guidelines
Some general coding guidelines for an application developer using ESQL are listed below.
The character strings used in an ESQL program must be null terminated.
The WHENEVER statement can be used in an ESQL program to check for error conditions.
This statement provides more flexibility and reduces the code size of the application.
There will be problems if any of the c-treeSQL reserved words happen to have been used as
symbol names in #define directives in any included header file, and if the +P option is used
while executing esql. When the +P option is used in esqlc, the source files are passed
through the C preprocessor before the esql statements are translated. One frequent problem
is the reserved word NULL that is used as a symbol name in the standard header file stdio.h.
To work around the name conflict, use one of the following suggestions:
• Avoid using the +P option.
• Avoid the inclusion of the header file that contains the definition of the reserved word.
• Reverse the case of the reserved word when used in the ESQL statement, as shown
below. This would not affect esqlc since reserved words in ESQL statements are not
case sensitive.
EXEC SQL
SELECT ename
FROM employee
WHERE commission is null ;
It is recommended that the owner name of the table be used while referencing tables in an
ESQL program, instead of using a non-qualified table name. For example, to access the table
“customer” the SELECT statement could be:
EXEC SQL
SELECT CUST_NO, name

ESQL Application Development
All Rights Reserved 58 www.faircom.com
FROM john.customer ;
Here, john is the owner name of the table customer.
While declaring host variable arrays, expressions are not allowed within the array subscript.
For example, the following declaration in the declare section is not allowed:
#define MAXNAMELEN 18
EXEC SQL BEGIN DECLARE SECTION ;
char name [MAXNAMELEN + 1] ; /* not allowed */
EXEC SQL END DECLARE SECTION ;
Here, the symbol MAXNAMELEN is defined. To handle such cases, define a new symbol for
the required value and use that symbol, as shown below:
...
#define MAXNAMELEN_P1 19
EXEC SQL BEGIN DECLARE SECTION ;
char name [MAXNAMELEN_P1] ; /* allowed */
EXEC SQL END DECLARE SECTION ;
#define symbols can be used in c-treeSQL statements wherever constants can be used. The
following example shows the usage of the #define symbol, MAX_SALARY:
#define MAX_SALARY 10000
SELECT ename, salary
FROM employee
WHERE salary = MAX_SALARY ;
It is a good practice to specify all the columns in the SELECT list of a SELECT statement
instead of specifying a ‘*’. This improves the readability of the SELECT statement. In addition,
if the database table schema is changed later on, the ESQL statement need not be changed.
5.3 Using c-treeSQL for Computation and Conversion
The c-treeSQL SELECT statement can be used to make computations in an ESQL program. The
computations can be done using the SYSCALCTABLE table. The SYSCALCTABLE is a table
with owner as admin and contains exactly one row with a single column.
Programs can use c-treeSQL SELECT statements and scalar functions to perform a wide range of
computations and conversions. c-treeSQL provides a system table called SYSCALCTABLE to
facilitate such operations. The SYSCALCTABLE table contains a single row, which means
SELECT statements that specify SYSCALCTABLE will return at most a single row. This makes it
convenient to use SELECT INTO statements for computations and conversions.
(Of course, you don’t have to use the table SYSCALCTABLE but it is guaranteed to be available
in any c-treeSQL environment.)
In general, the format for using SYSCALCTABLE in this manner is as follows:
EXEC SQL
SELECT expression
INTO :host_var
FROM admin.syscalctable ;
The expression in the SELECT list can have constants or host variables and can include scalar
functions.

ESQL Application Development
All Rights Reserved 59 www.faircom.com
The following example shows some of the computations that can be done using the SELECT
statement:
Example Using c-treeSQL for Computation
...
EXEC SQL BEGIN DECLARE SECTION ;
long result ;
long num ;
long val ;
DATE dtval ;
EXEC SQL END DECLARE SECTION ;
...
EXEC SQL
SELECT (100 * 12 (1234 - 354))
INTO :result
FROM admin.syscalctable ;
EXEC SQL
SELECT (:num * 10 + ABS ((360 - :val)))
INTO :result
FROM admin.syscalctable ;
EXEC SQL
SELECT NEXT_DAY (TO_DATE (11/12/1992), WEDNESDAY)
INTO :dtval
FROM admin.syscalctable ;
...
5.4 Using c-treeSQL for Condition Evaluation
A c-treeSQL SELECT statement can be used for condition evaluation in an ESQL program. The
condition evaluation is done using the SYSCALCTABLE.
The following example shows the usage of the SELECT statement to check whether the ship_date
is valid:
Example Using c-treeSQL for Condition Evaluation
EXEC SQL
SELECT 1
INTO :result
FROM admin.syscalctable
WHERE :ship_date > SYSDATE
AND :ship_date < ADD_MONTHS (:order_date, 1) ;
if (sqlca.sqlcode == 0)
printf ("ship_date valid ") ;
else
if (sqlca.sqlcode == SQL_NOT_FOUND)
printf ("ship_date invalid ") ;
else
printf ("Error ") ;

ESQL Application Development
All Rights Reserved 60 www.faircom.com
The previous example returns the value 1 if the validation is successful. If not, the validation is
unsuccessful.
5.5 Using Indicator Variables
Programs can use indicator variables along with input and output host variables. With input host
variables, programs can insert a NULL value by setting the indicator variable is set to -1. With
output variables, programs check indicator variables for NULL values and other error conditions.
The value of an indicator variable is interpreted as given below:
0 The value has been placed in the host variable and is not NULL and has not been truncated.
-1 The returned value is NULL and the value of the host variable is not defined.
>0 The returned value was truncated since the host variable size was too small. The indicator value is the actual value length before truncation.
When a query is made, it is suggested that an indicator variable be used to check for NULL
values, on columns that can contain NULL values.
5.6 Using Scalar Functions
Scalar functions take as arguments a collection of values derived from one or more columns
corresponding to one row from either a database table or an intermediate result table and returns
one value.
Salar Functions used in c-treeSQL Statements
EXEC SQL
SELECT order_no, product
FROM orders
WHERE ABS (qty - :old_qty) > 10000 ;
EXEC SQL
SELECT order_no, product, qty
FROM orders
WHERE order_date = TO_DATE ('01/02/1993') ;
EXEC SQL
SELECT MONTHS_BETWEEN (SYSDATE, order_date)
FROM orders
WHERE order_no = 1005 ;
The DECODE function accepts the column name, column value and its substitute value.
Optionally, a default value can be specified.

ESQL Application Development
All Rights Reserved 61 www.faircom.com
DECODE Example
SELECT ename, DECODE (deptno,
10, 'ACCOUNTS ',
20, 'RESEARCH ',
30, 'SALES ',
40, 'SUPPORT ',
'NOT ASSIGNED'
)
FROM employee ;
In the above example, the column deptno is compared with the department code and the
corresponding department name is returned. If no match is found, the default value, NOT
ASSIGNED, is returned. The DECODE function is similar to the switch statement in C.
The NVL function can be used to check whether a column value is NULL. If NULL, a substitute
value can be returned. Consider the following example:
EXEC SQL
SELECT salary + NVL (commission, 0)
FROM employee ;
In the above example, a zero value is substituted if the column commission contains NULL value.
5.7 Using Static and Dynamic Statements
Static c-treeSQL statements are simple and easy to use relative to dynamic c-treeSQL
statements. Use static c-treeSQL statements wherever possible.

All Rights Reserved 62 www.faircom.com
6. Connection Management in ESQL
6.1 Introduction
This chapter describes connection management statements in ESQL and discusses the following
statements that can be used in an ESQL program:
CONNECT
SET CONNECTION
DISCONNECT
The ESQL statements in an ESQL program are used to access and manipulate data in a
database. In order to access/manipulate the database, it is necessary to have a valid connection
with the database. This accessibility is managed by using the connection management
statements. Connection management statements can be used to make a connection to a
database, set an existing connection as current or to drop an existing connection. The following
are the connection management statements in ESQL:
CONNECT - Enables an ESQL application to establish a connection with a database. The
database specified by the CONNECT statement becomes the current connection.
SET CONNECTION - Allows the application to make a particular database connection current.
DISCONNECT - Terminates the connection between an application and the associated
database.
Note: The database must be started successfully before an ESQL program can connect to it.
6.2 The CONNECT Statement
The CONNECT statement establishes a valid connection with a database. There are several types
of database connections possible:
Using a connection name
By default connection
To a remote database
Connection Using a Connection Name
A simple CONNECT statement accepts the database name and the connection name as
arguments to make a valid connection. The format for this statement is as shown:
EXEC SQL
CONNECT TO database_name AS connection_name ;
Connection Management in ESQL
All Rights Reserved 63 www.faircom.com
For example, to connect to a database custdb using the connection name conn_1, the statement
would be:
EXEC SQL
CONNECT TO 'custdb' AS 'conn_1' ;
The connection name, conn_1, has to be unique. If the connection name is not specified, then the
database name is taken as the connection name. For example, consider the above example
without the connection name specification:
EXEC SQL
CONNECT TO 'custdb' ;
Here the connection name is taken to be custdb.
Connection by Default
The CONNECT statement allows connection to a default database using the DEFAULT keyword.
The default database is specified by the environment variable DB_NAME.
To connect to the default database the CONNECT statement would be:
EXEC SQL
CONNECT TO DEFAULT;
Note that no connection name is specified in the above statement. No connection is needed for
the default connection since this connection can always be referred to using the keyword
DEFAULT.
If an application executes an SQL statement before connecting to a database, an attempt is
made to connect to the environment defined database, if any. If the connection is successful, the
c-treeSQL statement is executed on that database.
Connection to a Remote Database
A connection to a database can be made either in the local mode or in the remote mode. At most
one connection could be in the local mode. For example, to connect to the custdb database in the
local mode and associate this connection with a connection name conn_1, the statement would
be:
EXEC SQL
CONNECT TO '6597@localhost:custdb' as 'conn_1' ;
Here the string “6597@localhost:custdb” is referred to as the connect string. The connect string
specifies the port, the target host for the database, and the database name.
To connect to a database in the remote mode, the statement would be:
EXEC SQL
CONNECT TO '6597@remotehost:salesdb' as 'conn_2' ;
Here “6597@remotehost:salesdb” is the connect string that has the database name, salesdb, to
be connected to and conn_2 is the connection name associated with this connection. remotehost
is the name of the remote machine having the database salesdb.

Connection Management in ESQL
All Rights Reserved 64 www.faircom.com
6.3 The SET CONNECTION Statement
The SET CONNECTION statement lets the application switch between one valid connection to
another. It resumes the connection associated with the connection name, restoring the context of
that database to its exact state that prevailed at the time of suspension. For example, to set the
database associated with the connection name conn_1 as the current database, the statement
would be:
EXEC SQL
SET CONNECTION 'conn_1' ;
Here, conn_1 is the connection name associated with a connection. The connection name must
have been previously established by a CONNECT statement and must not have been terminated
by a DISCONNECT statement.
To set the default connection as current, the statement would be:
EXEC SQL
SET CONNECTION DEFAULT;
6.4 The DISCONNECT Statement
The DISCONNECT statement terminates the connection between an application and a database.
For example, to disconnect the connection associated with the connection name conn_1, the
c-treeSQL statement would be:
EXEC SQL
DISCONNECT 'conn_1' ;
If the DISCONNECT statement specifies the current connection, then c-treeSQL makes the
connection to the default database (made through an earlier CONNECT TO DEFAULT statement)
the current connection. Otherwise, there is no current connection.
To disconnect all connections, the statement would be:
EXEC SQL
DISCONNECT ALL;
When the option ALL is specified, all established connections are disconnected. After the
execution of this statement, a current connection does not exist.
To disconnect the current connection, the statement would be:
EXEC SQL
DISCONNECT CURRENT;
When the option CURRENT is specified, the current connection, if any, is disconnected. Here too,
the connection to the default database, if any, is made the current connection; otherwise, no
current connection exists.
To disconnect the default connection, the statement would be:
EXEC SQL
DISCONNECT DEFAULT;
If the default connection happens to be the current connection, there is no current connection
after a DISCONNECT DEFAULT statement.

Connection Management in ESQL
All Rights Reserved 65 www.faircom.com

All Rights Reserved 66 www.faircom.com
7. c-treeSQL Data Definition Statements
7.1 Introduction
This chapter introduces the data definition statements (DDL) that can be used in an ESQL
program and discusses:
Statements to create/drop tables, views, and indices
Integrity constraints
Long running transactions
7.2 Creating/Dropping Tables
This section describes creating and dropping tables in ESQL.
Creating Tables
The CREATE TABLE statement allows creation of a new table and definition of its columns and
their data types in an existing database. A sample code using CREATE TABLE statement in an
ESQL program is shown below:
Example Creating Tables
...
/* connect to a default database */
EXEC SQL CONNECT TO DEFAULT ;
/* create a table named customer in the database */
EXEC SQL
CREATE TABLE customer (
CUST_NO INTEGER NOT NULL,
cstname CHAR (30),
street CHAR (30),
city CHAR (20),
state CHAR (2)
) ;
if (sqlca.sqlcode)
{
fprintf (stderr,
"Create table statement failed (%ld : %s) \n",
sqlca.sqlcode, sqlca.sqlerrm);
EXEC SQL ROLLBACK WORK ;
EXEC SQL DISCONNECT DEFAULT ;
exit (1);
}

c-treeSQL Data Definition Statements
All Rights Reserved 67 www.faircom.com
/* Commit changes */
EXEC SQL COMMIT WORK ;
printf ("Table customer created. \n");
/* Disconnect from the database */
EXEC SQL DISCONNECT DEFAULT ;
...
The CREATE TABLE statement shown above specifies the table name, customer, for the table to
be created. In addition, the statement specifies the column definitions such as the column name
and the column type. The integer column, CUST_NO, specified as NOT NULL indicates that no
row in the table customer can have a NULL value in the column, CUST_NO.
The CREATE TABLE statement allows specification of DEFAULT clause along with a column
definition. The DEFAULT clause specifies the default value to be used for a column, if the value
for the same is not supplied while inserting the row. The following CREATE TABLE statement
shows the usage of the DEFAULT clause:
CREATE TABLE employee (
empno INTEGER NOT NULL,
deptno INTEGER DEFAULT 10
) ;
In this example, a default value of 10 is specified for the column deptno.
Dropping Tables
The DROP TABLE statement deletes all data and indices for a table and erases its entry in the
system catalog.
The following example uses the DROP TABLE statement to drop the table tmp_customer.
Example Dropping Tables
...
/* connect to a default database */
EXEC SQL CONNECT TO DEFAULT ;
/* drop the table tmp_customer from the database */
EXEC SQL DROP TABLE tmp_customer ;
if (sqlca.sqlcode) {
fprintf (stderr,
"Drop table statement failed (%ld : %s) \n",
sqlca.sqlcode, sqlca.sqlerrm);
EXEC SQL ROLLBACK WORK ;
EXEC SQL DISCONNECT DEFAULT ;
exit (1);
}
/* Commit changes */
EXEC SQL COMMIT WORK ;
printf ("Table dropped. \n");

c-treeSQL Data Definition Statements
All Rights Reserved 68 www.faircom.com
/* Disconnect from the database */
EXEC SQL DISCONNECT DEFAULT ;
...
7.3 Creating/Dropping Indices
This section discusses creating and dropping indices in ESQL.
Creating Indices
The CREATE INDEX statement creates an index on one or more columns of a table. The
existence of an index improves the accessing speed for rows in a table. The following example
shows how to use the CREATE INDEX statement in an ESQL program:
Example Creating Indices
...
/* connect to a default database */
EXEC SQL CONNECT TO DEFAULT ;
EXEC SQL
CREATE INDEX idx_cust
ON customer (CUST_NO ASC) ;
if (sqlca.sqlcode)
{
fprintf (stderr,
"Create index statement failed (%ld : %s) \n",
sqlca.sqlcode, sqlca.sqlerrm);
EXEC SQL ROLLBACK WORK ;
EXEC SQL DISCONNECT DEFAULT ;
exit (1);
}
/* Commit changes */
EXEC SQL COMMIT WORK ;
printf ("Index idx_cust created. \n");
/* Disconnect from the database */
EXEC SQL DISCONNECT DEFAULT ;
...
The index in the previous example is specified on only one column, CUST_NO, and the index is
specified to be of ascending order on the value of the CUST_NO column. The index can also be
specified to be descending on a column value using the keyword DESC.

c-treeSQL Data Definition Statements
All Rights Reserved 69 www.faircom.com
Dropping Indices
The DROP INDEX statement is used to delete a table index. The following example uses the DROP
INDEX statement to drop the index idx_cust, on the table customer.
Example Dropping Indices
...
/* connect to a default database */
EXEC SQL CONNECT TO DEFAULT ;
/* drop the index idx_cust from the database */
EXEC SQL
DROP INDEX idx_cust ON customer ;
if (sqlca.sqlcode)
{
fprintf (stderr,
"Drop index statement failed (%ld : %s) \n",
sqlca.sqlcode, sqlca.sqlerrm);
EXEC SQL ROLLBACK WORK ;
EXEC SQL DISCONNECT DEFAULT ;
exit (1);
}
/* Commit changes */
EXEC SQL COMMIT WORK ;
printf ("Index dropped. \n");
/* Disconnect from the database */
EXEC SQL DISCONNECT DEFAULT ;
...
7.4 Creating/Dropping Views
This section discusses creating and dropping views in ESQL.
Creating Views
The CREATE VIEW statement allows creation of a view with the specified name on existing tables
or views. The following example shows the usage of CREATE VIEW statement in ESQL programs:
Example Creating Views
...
/* connect to a default database */
EXEC SQL CONNECT TO DEFAULT ;
/* create a view ne_customer in the database */
EXEC SQL
CREATE VIEW ne_customer AS
SELECT CUST_NO, name, street, city, state

c-treeSQL Data Definition Statements
All Rights Reserved 70 www.faircom.com
FROM customer
WHERE state IN ('NH', 'MA', 'NY', 'ME', 'VT') ;
if (sqlca.sqlcode)
{
fprintf (stderr,
"Create view statement failed (%ld : %s) \n",
sqlca.sqlcode, sqlca.sqlerrm);
EXEC SQL ROLLBACK WORK ;
EXEC SQL DISCONNECT DEFAULT ;
exit (1);
}
/* Commit changes */
EXEC SQL COMMIT WORK ;
printf ("View ne_customer created. \n");
/* Disconnect from the database */
EXEC SQL DISCONNECT DEFAULT ;
...
The previous example shows creation of a view ne_customer on the table customer.
Dropping Views
The DROP VIEW statement deletes an existing view from the database. The following example
shows the use of a DROP VIEW statement to drop the view, ne_customer on the table customer.
Example Dropping Views
...
/* connect to a default database */
EXEC SQL CONNECT TO DEFAULT ;
/* drop a view, newcust, from the database */
EXEC SQL DROP VIEW ne_customer ;
if (sqlca.sqlcode)
{
fprintf (stderr,
"Drop view statement failed (%ld : %s). \n",
sqlca.sqlcode, sqlca.sqlerrm);
EXEC SQL ROLLBACK WORK ;
EXEC SQL DISCONNECT DEFAULT ;
exit (1);
}
/* Commit changes */
EXEC SQL COMMIT WORK ;
printf ("View dropped. \n");
/* Disconnect from the database */
EXEC SQL DISCONNECT DEFAULT ;
...

c-treeSQL Data Definition Statements
All Rights Reserved 71 www.faircom.com
7.5 Integrity Constraints
Integrity constraints are the constraints defined on base tables in order to ensure the data
integrity in a database. Integrity constraints could either be a specification of uniqueness for
values of a column, validation for values of a column, or referential integrity constraints.
Referential integrity ensures that the relationships among different rows of the same or different
tables are valid. For example, the referential integrity ensures that a master row is inserted before
a detail row and a detail row is deleted before the master row.
Need for Integrity Constraints
The need for integrity constraints arises because of the necessity that the data in a database
must be valid and consistent at any point of time.
For example, in the table containing employee information, it is to be ensured that the employee
numbers be unique. This can be ensured by specifying a constraint on the column containing the
employee number. Similarly, for each order entry made in the orders table, it is to be ensured that
the associated item entry be present in the items table. This can be ensured by specifying a
referential integrity constraint on the column containing the item code in the orders table.
Types of Integrity Constraints
Integrity constraints can be of the following types:
Check constraints
Primary key specification
Candidate key specification
Referential constraints
An integrity constraint can optionally be referred to by its name. The following example shows the
specification of the constraint name, prim_constr, on the supplier_item table:
CREATE TABLE supplier_item (
supp_no INTEGER NOT NULL,
item_no INTEGER NOT NULL,
qty INTEGER NOT NULL DEFAULT 0
CONSTRAINT prim_constr
PRIMARY KEY (supp_no, item_no)
) ;
In the above example, note that the constraint name is specified using the keyword,
CONSTRAINT.
The following sections give more information on various types of constraints.
Check Constraints
It is necessary that the values entered for a row be valid, so that the data in the database remains
consistent. For example, while entering city names into the supplier table, the value must
correspond to one of the cities where the suppliers are located. Hence, whenever city name is
entered, a check has to be made so that the value corresponds to one of the valid city names.

c-treeSQL Data Definition Statements
All Rights Reserved 72 www.faircom.com
These sorts of validations can be achieved by specifying CHECK constraints during the definition
of the table schema for which validation is required.
Check constraints are used where a column has to be restricted to contain only a set of valid
values. The following example shows the specification of check constraint on the supplier table:
CREATE TABLE supplier (
supp_no INTEGER NOT NULL,
name CHAR (30),
status SMALLINT,
city CHAR (20) CHECK (
supplier.city IN ('NEWYORK', 'BOSTON', 'DALLAS'))
) ;
In the above example, the column city has a check constraint that validates whether the city is
one of NEWYORK, BOSTON, or DALLAS.
A check constraint on a table specifies a condition on the column values of a row in that table.
Whenever an INSERT/UPDATE operation is done on a table containing check constraints, the
column values are validated. The INSERT/UPDATE operation would be successful only if the
validation is successful. A check constraint can be specified at the column level or at the table
level. The following sections discuss the column level and table level check constraints.
Column-Level Check Constraint
In an application, it might be necessary that a particular column be checked for valid data
whenever an attempt is made to insert or update values for that column. For example, it might be
necessary that the city name entered for the supplier table is not MOSCOW. A column-level
check constraint is used for such validations.
The column level check constraint on the table supplier could be specified as:
CREATE TABLE supplier (
supp_no INTEGER NOT NULL,
name CHAR (30),
status SMALLINT,
city CHAR (20) CHECK (
supplier.city <> 'MOSCOW')
) ;
In the above example, the specification of the check constraint involves only the city column.
Whenever an INSERT/UPDATE operation is done on the supplier table involving the city column, a
validation is done on that column so that the column does not contain the value MOSCOW. If the
INSERT/UPDATE statement is given such that it violates the check condition, then a constraint
violation error is indicated. For example, the following INSERT statement results in an error and
the corresponding row is not inserted into the table.
INSERT INTO supplier VALUES (1001, 'Alexander', 20, 'MOSCOW') ;
Table-Level Check Constraint
Some applications might have a need to specify a constraint on more than one column of a table.
For example, if a validation check has to be made on the supplier status along with the supplier
city, the check constraint could be specified as:
CREATE TABLE supplier (
supp_no INTEGER NOT NULL,
name CHAR (30),

c-treeSQL Data Definition Statements
All Rights Reserved 73 www.faircom.com
status SMALLINT CHECK (supplier.status BETWEEN 1 AND 100 ),
city CHAR (20) CHECK (supplier.city IN
('NEWYORK', 'BOSTON', 'CHICAGO')),
CHECK (supplier.city <> 'CHICAGO' OR supplier.status = 20)
) ;
A check constraint is defined at table level if the check condition involves one or more columns. In
the above example, the table-level check constraint validates such that if city is CHICAGO then
the status should be 20.
Since the check constraint specification involves more than one column, it has to be specified at
the table level.
If the INSERT/UPDATE statement is given such that it violates the check condition then an error is
indicated. For example, the following are invalid INSERT statements for the table supplier shown
above:
INSERT INTO supplier VALUES (1001, 'John', 40,
'CHICAGO') ;
7.6 Primary Keys
An application might require that database table contain one or more columns that can uniquely
identify a row. For example, in a supplier table, it is necessary that the column supp_no uniquely
identify a row. Every row of the table is uniquely identified by this column value.
A single column or a group of columns that is the principal unique identifier of the table is referred
to as the primary key. A table can contain only one primary key constraint.
The following example shows the creation of a primary key column on the table supplier.
CREATE TABLE supplier (
supp_no INTEGER NOT NULL PRIMARY KEY,
name CHAR (30),
status SMALLINT,
city CHAR (20)
) ;
During an INSERT operation, if a duplicate value is given for a primary key column, the INSERT
operation results in an error.
Column-Level Primary Key Constraint
In a database table, there might be only one column that distinguishes the given row from other
rows. That is, a single column is the unique identifier of the table. For example, the column
supp_no is a column level primary key of the table supplier.
Column-level primary key constraints are defined in the column definitions of a table. The
following example shows the creation of the column-level primary key on the supplier table.
CREATE TABLE supplier (
supp_no INTEGER NOT NULL PRIMARY KEY,
name CHAR (30),
status SMALLINT,
city CHAR (20)
) ;

c-treeSQL Data Definition Statements
All Rights Reserved 74 www.faircom.com
In the above example, the column supp_no is a unique identifier of the table supplier and the key
consists of only one column. Hence it is defined at column level.
Table-Level Primary Key Constraint
In some database tables, it might not be possible to uniquely identify a row with just one column.
But there might exist a combination of columns that when taken together, can uniquely identify a
row. For example, the columns supp_no, item_no uniquely identify a row of the table
supplier_item. Hence, a combination of columns that form a primary key should be specified at
the table level.
The following example shows the table level primary key specification:
CREATE TABLE supplier_item (
supp_no INTEGER NOT NULL,
item_no INTEGER NOT NULL,
qty INTEGER NOT NULL DEFAULT 0
CONSTRAINT prim_constr
PRIMARY KEY (supp_no, item_no)
) ;
Since more than one column (supp_no, item_no) are contained in the primary key, the constraint
is defined at the table level. In the above example, the constraint prim_constr is the primary key
of table supplier_item.
7.7 Candidate Keys
A column or a set of columns from a table are to be declared as a candidate key, if it is to be
enforced that the values for the column or the set of columns be distinct for each row of the table.
For example, in an employee table,the employee number uniquely identifies the row, and is
usually the primary key of the employee table. But there exists another column containing the
social security number for the employee. Since it is to be enforced that the values for this column
be distinct for each row in the table, this column can be declared as a candidate key.
The following example shows the specification of a candidate key on the employee table:
CREATE TABLE employee (
empno INTEGER NOT NULL PRIMARY KEY,
ss_no INTEGER NOT NULL UNIQUE,
ename CHAR (19),
sal NUMERIC (10, 2),
deptno INTEGER NOT NULL
) ;
A column is declared as a candidate key using the keyword UNIQUE. It can be noted that the
UNIQUE specification has to be preceded by a NOT NULL specification for that column.
Like a primary key, a candidate key also uniquely identifies a row in a table. But, whereas a table
can have at most one primary key, there could be any number of candidate keys on a table.
During the INSERT/UPDATE operation, if a duplicate value is given for a candidate key, the
INSERT/UPDATE operation results in an error.

c-treeSQL Data Definition Statements
All Rights Reserved 75 www.faircom.com
Column-Level Candidate Key Constraint
In an application, it might be necessary that a column be specified as the unique column. For
example, the column ss_no in table employee must be unique, since it contains an employee’s
Social Security number. Such a unique column can be specified using the column level candidate
key constraint.
A column-level candidate key constraint contains only one column as a candidate key. It is
specified in the column definition. Consider the following example:
CREATE TABLE employee (
empno INTEGER NOT NULL PRIMARY KEY,
ss_no INTEGER NOT NULL UNIQUE,
ename CHAR (19),
sal NUMERIC (10, 2),
deptno INTEGER NOT NULL
) ;
In the above example, the column ss_no is the candidate key of the table employee.
Table-Level Candidate Key Constraint
If an application requires that the values for a combination of columns be unique, then the
candidate key specification is to be done at the table level. For example, in an order_item table
the columns order_no and item_no together form a unique key.
Consider the following example:
CREATE TABLE order_item (
order_no INTEGER NOT NULL,
item_no INTEGER NOT NULL,
qty INTEGER,
price MONEY
UNIQUE (order_no, item_no)
) ;
In the above example, the combination of columns order_no and item_no is the unique identifier
of the table order_item.
7.8 Referential Constraints
For some applications, a table might require that each row’s values for a column, or for a group of
columns taken together (provided none are null), be identical to a corresponding set of columns in
some other table in the database. The requirement that a matching row exist in the referenced
table for each referencing row is called a referential constraint. For example, an employee
number in the employee table might be within a valid range, but the employee number might no
longer exist in the master employee table because the employee has resigned. Referential
constraints are used for such validation of data in the database.
Consider the following example:
CREATE TABLE supplier_item (
suppl_no INTEGER NOT NULL PRIMARY KEY,
item_no INTEGER REFERENCES item (item_no),
quantity INTEGER,

c-treeSQL Data Definition Statements
All Rights Reserved 76 www.faircom.com
price MONEY
) ;
In the above example, the REFERENCES clause in the supplier_item table definition means that
values in the column supplier_item. item_no must either be NULL or be equal to some value in
the column item_no in another table, item. The column item_no is called the foreign key of table
supplier_item.
A foreign key is a column or combination of columns that references a primary or a candidate key
of some other table. A foreign key value is either NULL or exists as a primary key value.
The table that contains a foreign key is called the referencing table and the table that contains the
primary or the candidate key is called the referenced table. A referential constraint can be
specified at the column level or at the table level.
During INSERT/UPDATE operations on a table containing a foreign key, a check is made to see if
the foreign key value matches with a corresponding primary key value. If it does not match, the
INSERT/UPDATE operation results in an error.
During INSERT/UPDATE operations on a table containing a primary/candidate key, if the values to
be deleted/updated match the foreign key of the referencing table, the INSERT/UPDATE operation
results in an error. Hence, a value corresponding to a primary/candidate key cannot be
updated/deleted if there are references to it.
When a table containing a primary/candidate key is to be dropped, a check is made as to whether
the table has any references to it. If there are tables containing foreign keys that reference the
primary/candidate key of the table to be dropped, the drop operation results in an error.
Column-Level Foreign Key Constraint
If a foreign key constraint specification involves only one column, then the foreign key constraint
can be specified at the column level.
Consider the following example:
CREATE TABLE supplier_item (
supp_no INTEGER NOT NULL PRIMARY KEY,
item_no INTEGER NOT NULL REFERENCES item,
qty INTEGER
) ;
In the above example, item_no is the foreign key, referencing the table item. Since the foreign
key involves only one column, they are defined at the column level. If a foreign key references a
candidate key, then the specification of the referenced column list is mandatory. If a foreign key
references a primary key, then the referenced column list is optional.
Consider the following example:
CREATE TABLE invoice (
inv_no INTEGER NOT NULL PRIMARY KEY,
item_no INTEGER REFERENCES item,
part_no CHAR (3) NOT NULL
REFERENCES parts (part_no),
qty INTEGER NOT NULL,
amount MONEY NOT NULL,
balance MONEY NOT NULL
) ;

c-treeSQL Data Definition Statements
All Rights Reserved 77 www.faircom.com
In the above example, item_no references the primary key of table item. The column part_no
references primary or candidate key of table parts depending on whether part_no is the primary
key or the candidate key of the table parts.
Table-Level Foreign Key Constraint
If a foreign key constraint specification involves more than one column, then the constraint is to
be specified at the table level.
Consider the following example:
CREATE TABLE hours_worked (
empno INTEGER NOT NULL,
projno INTEGER NOT NULL,
date DATE,
hours TIME
FOREIGN KEY (empno, projno)
REFERENCES assignments (empno, projno)
) ;
In this example, the foreign key (empno, projno) of table hours_worked, references the
primary/candidate key (empno, projno) of table assignments. Since the foreign key involves more
than one column, it is defined at the table level.
7.9 Handling Cycles in Referential Integrity
A cycle is formed when there are a list of base tables, where the first table has a foreign key that
references the second table, the second table has a foreign key that references the third table
and so on and the last table has a foreign key that references the first table.
Consider the following examples.
Example Creating Tables in “Cycles” CREATE TABLE parts (
part_no INTEGER NOT NULL PRIMARY KEY,
part_name CHAR (19),
distrib_no INTEGER
REFERENCES distributor
) ;
CREATE TABLE distributor (
distrib_no INTEGER NOT NULL
PRIMARY KEY,
distrib_name CHAR (19),
address CHAR (30),
phone_no CHAR (10),
part_no INTEGER
REFERENCES parts
) ;
In the above example, the column distrib_no of table parts references the primary key of the table
distributor and the column part_no of table distributor references the primary key of table parts.
That is, each of the two tables is referencing the other. Hence a cycle is formed.
A special case of the cycle in referential integrity is when a foreign key of a table references the
primary key of the same table. The following example shows an example of such a cycle:

c-treeSQL Data Definition Statements
All Rights Reserved 78 www.faircom.com
Example Foreign Key Referring to Same Table CREATE TABLE employee (
empno INTEGER NOT NULL PRIMARY KEY,
ename CHAR (30) NOT NULL,
deptno INTEGER NOT NULL,
mgr_code INTEGER REFERENCES employee(empno)
) ;
Creation of Tables in Cycles
Creation of tables in cycles involves the following steps:
First, a table is created with a reference to a table that is not yet created. The table creation is
done, but is marked incomplete. No operations (INSERT/UPDATE/SELECT/DELETE) are
allowed on an incomplete table.
Next, when the table with a primary/candidate key is created, the previous table definition
becomes complete. If this table also contains the foreign key referencing a table that is not
yet created, this table also is marked incomplete. This procedure follows till the last table is
created.
Insertion of Rows in Cycles
Insertion of rows into tables where cycles are defined involves two steps.
Insert the rows into one of the tables that forms the cycle with NULL value in the foreign key
column(s). If the foreign key is NULL, no check is made to match the foreign key to the
corresponding primary key. Hence the insertion would be successful.
After the value corresponding to the primary key is inserted, update the foreign key values of
the referencing table.
The following example shows insertion/updating of values into the employee table:
CREATE TABLE employee (
empno INTEGER NOT NULL PRIMARY KEY,
ename CHAR (30) NOT NULL,
deptno INTEGER NOT NULL,
mgr_code INTEGER REFERENCES employee (empno)
) ;
INSERT INTO employee VALUES (100, 'JOHN', 10, NULL) ;
INSERT INTO employee VALUES (500, 'MARY', 30, NULL) ;
INSERT INTO employee VALUES (101, 'ANITA', 10, NULL) ;
INSERT INTO employee VALUES (501, 'ROBERT', 30, NULL) ;
UPDATE employee set mgr_code = 101 where empno = 100 ;
UPDATE employee set mgr_code = 501 where empno = 500 ;
In this example, the column mgr_code references the column empno of the same table that forms
the special case of a cycle. As shown above, the NULL values are inserted in column mgr_code
and after all the rows are entered, the values of the column mgr_code are updated.
Dropping the Tables in Cycles
Dropping a table in a cycle involves the following steps:

c-treeSQL Data Definition Statements
All Rights Reserved 79 www.faircom.com
Drop the foreign key constraints that are referencing the table.
Drop the table.
Consider the following table definitions:
CREATE TABLE parts (
part_no INTEGER NOT NULL PRIMARY KEY,
part_name CHAR (19),
distrib_no INTEGER CONSTRAINT parts_constr
REFERENCES distributor
) ;
CREATE TABLE distributor (
distrib_no INTEGER NOT NULL PRIMARY KEY,
distrib_name CHAR (19),
address CHAR (30),
phone_no CHAR (10),
part_no INTEGER
REFERENCES parts
) ;
The following example shows dropping these tables in cycles:
ALTER TABLE parts DROP CONSTRAINT parts_constr ;
DROP TABLE distributor ;
DROP TABLE parts ;
1. First the constraint parts_constr of table parts is dropped.
2. Next, since there are no references to table distributor, the table can be dropped.
After table distributor is dropped, there are no references to table parts and hence table parts can
also be dropped.
7.10 DDL Statements in Long Running Transactions
In an ESQL program, Data Definition Language (DDL) statements have the same transaction
semantics as other c-treeSQL statements. DDL statements must be explicitly committed or rolled
back in an ESQL application.
DDL statements can be executed as part of a long running transaction, but it is better to commit
the DDL statements. This will avoid locking of database resources like tables or views for a longer
period. This also increases the concurrency of database operations.

All Rights Reserved 80 www.faircom.com
8. c-treeSQL Data Manipulation Statements
8.1 Introduction
This chapter describes the usage of Data Manipulation statements (DML) in ESQL programs and
discusses:
Types of DML statements:
• SELECT
• INSERT
• DELETE
• UPDATE
Input host variables that can be used in DML statements
8.2 Using DML Statements
Data Manipulation Language (DML) statements are the most frequently used statements in an
ESQL program. The SELECT statement (also called query statement) is one type of DML
statement and is discussed in detail in the next chapter.
DML statements are used to change data in a database in one of the three ways:
INSERT - Adds one or more rows to a table.
UPDATE - Modifies the data in one or more rows of a table.
DELETE - Deletes one or more rows from a table.
DML statements are used to modify only one table at a time. Host variable references can be
made in a DML statement.
The INSERT, UPDATE, and DELETE statements are discussed in more detail in the following
sections.
Inserting Rows into a Table
An INSERT statement adds one or more rows to an existing table. The following INSERT
statement adds a new customer ‘LEVIEN’ to the customer table:
INSERT INTO customer
(CUST_NO, name, street, city, state)
VALUES
(1006, 'LEVIEN', '15 Heath Street', 'Scotia', 'NY') ;

c-treeSQL Data Manipulation Statements
All Rights Reserved 81 www.faircom.com
When an INSERT statement is used in an ESQL program, host variables can be used to supply
the values, as shown in the following example.
Example Inserting A Row
EXEC SQL BEGIN DECLARE SECTION ;
long cust_no_v ;
char name_v [20] ;
char street_v [40] ;
char city_v [10] ;
char state_v [2] ;
EXEC SQL END DECLARE SECTION ;
/* connect to a default database */
EXEC SQL CONNECT TO DEFAULT ;
/* Get values for input host variables */
cust_no_v = 1006 ;
strcpy (name_v, "LEVIEN") ;
strcpy (street_v, "15 Heath street") ;
strcpy (city_v, "Scotia") ;
strcpy (state_v, "NY") ;
EXEC SQL
INSERT INTO customer
(CUST_NO, name, street, city, state)
VALUES
(:cust_no_v, :name_v, :street_v, :city_v, :state_v) ;
if (sqlca.sqlcode)
{
fprintf (stderr,
"Insert statement failed (%ld : %s). \n",
sqlca.sqlcode, sqlca.sqlerrm);
EXEC SQL ROLLBACK WORK ;
EXEC SQL DISCONNECT DEFAULT ;
exit (1);
}
/* Commit changes */
EXEC SQL COMMIT WORK ;
printf ("Inserted one row \n\n");
/* Disconnect from the database */
EXEC SQL DISCONNECT DEFAULT ;
...
In the previous example, the values for the host variables are assigned and then inserted into the
customer table using the INSERT statement.
The columns of the table customer listed in the INSERT statement are referred to as the column
list. The list of host variables specified in the VALUES clause of the INSERT statement is referred
to as the value list.
To insert more than one row, an insert statement with a subquery must be executed. The
following sample code shows insertion of rows from the table customer into a table ny_customer.
...

c-treeSQL Data Manipulation Statements
All Rights Reserved 82 www.faircom.com
EXEC SQL
CREATE TABLE ny_customer (
CUST_NO INTEGER,
name CHAR (20),
street CHAR(40),
city CHAR(15),
state CHAR(2)
);
EXEC SQL
INSERT INTO ny_customer
(CUST_NO, name, street, city, state)
SELECT CUST_NO, name, street, city, state
FROM customer
WHERE state = 'NY' ;
...
It is necessary that the table ny_customer be created first before insertion is done. The above
query expression option allows for insertion of multiple rows at a time. All the column values in
the INSERT statement must be returned by the query expression.
Deleting Rows from a Table
A DELETE statement deletes one or more rows from an existing table, depending on the selection
criteria used in the WHERE clause. The following example shows the use of a DELETE statement
to delete a row in the customer table:
Example Deleting a Row
...
/* connect to a default database */
EXEC SQL CONNECT TO DEFAULT ;
/* Get value for cust_no_v */
cust_no_v = 1005 ;
EXEC SQL
DELETE
FROM customer
WHERE CUST_NO = :cust_no_v;
if (sqlca.sqlcode)
{
fprintf (stderr,
"Delete statement failed (%ld : %s)\n",
sqlca.sqlcode, sqlca.sqlerrm);
EXEC SQL ROLLBACK WORK ;
EXEC SQL DISCONNECT DEFAULT ;
exit (1);
}
/* Commit changes */
EXEC SQL COMMIT WORK ;
printf ("Deleted one row \n\n");

c-treeSQL Data Manipulation Statements
All Rights Reserved 83 www.faircom.com
/* Disconnect from the database */
EXEC SQL DISCONNECT DEFAULT ;
...
In the previous example, the host variable cust_no_v is used to delete the row with CUST_NO
1005 from the customer table.
The deletion can be on more than one row if the WHERE clause selects multiple rows. The
following example shows the deletion of all orders from the orders table where order_date is less
than 2/2/1993.
EXEC SQL
DELETE
FROM orders
WHERE order_date < TO_DATE ('02/02/1993') ;
Updating Rows in a Table
An UPDATE statement modifies data in one or more rows of a table. The following UPDATE
statement updates the phone number of a row in the customer table.
Example Updating a Row
...
/* connect to a default database */
EXEC SQL CONNECT TO DEFAULT ;
cust_no_v = 1004 ;
EXEC SQL
UPDATE customer
SET phone = '(203)-465-2703'
WHERE CUST_NO = :cust_no_v ;
if (sqlca.sqlcode)
{
fprintf (stderr,
"Update statement failed (%ld : %s)\n",
sqlca.sqlcode, sqlca.sqlerrm);
EXEC SQL ROLLBACK WORK ;
EXEC SQL DISCONNECT DEFAULT ;
exit (1);
}
/* Commit changes */
EXEC SQL COMMIT WORK ;
printf ("Update Successful\n\n");
/* Disconnect from the database */
EXEC SQL D
The following UPDATE statement gives a 10 percent increase in salary to all employees of
department 10. Note that multiple rows are updated here by one statement.
EXEC SQL

c-treeSQL Data Manipulation Statements
All Rights Reserved 84 www.faircom.com
UPDATE employee
SET sal = sal * 1.1
WHERE deptno = 10 ;
8.3 Input Host Variables in DML Statements
The host variables that are used for input in a c-treeSQL statement are referred to as input host
variables. These variables must be declared in the declare section prior to their usage in the
ESQL program. They can be used in an ESQL statement, wherever a constant can be used. DML
statements can have only input host variable references. The following are some examples
showing input host variable references in DML statements:
EXEC SQL
INSERT INTO customer
(CUST_NO, name, street, city, state)
VALUES
(:cust_no_v, :name_v, :street_v, :city_v, :state_v) ;
EXEC SQL
UPDATE customer
SET phone = '(203)-465-2703'
WHERE CUST_NO = :cust_no_v ;
All the host variable references, as can be seen, must be prefixed with a colon while using them
in the c-treeSQL statements.

All Rights Reserved 85 www.faircom.com
9. Query Statements
9.1 Introduction
This chapter describes c-treeSQL queries and their usage in ESQL programs, introduces the
SELECT statement and discusses:
Query statements with host variables
Queries returning single row
Queries returning multiple rows
Cursors and their usage
Array fetches
9.2 Elements of a Query
ESQL supports SELECT statements for performing queries. A SELECT statement could return one
or more rows. The following example shows a SELECT statement that retrieves the customer
name and city values for a given customer number.
Example Basic Query Elements
EXEC SQL BEGIN DECLARE SECTION ;
CHAR name_v [30] ;
CHAR city_v [20] ;
LONG cust_no_v ;
EXEC SQL END DECLARE SECTION ;
...
EXEC SQL
SELECT name, city
INTO :name_v, :city_v
FROM customer
WHERE CUST_NO = :cust_no_v;
The previous example uses the following four clauses of the SELECT statement:
SELECT clause
INTO clause
FROM clause

Query Statements
All Rights Reserved 86 www.faircom.com
WHERE clause
The column names specified in the SELECT clause is referred to as the SELECT list. In the above
example, the columns named name and city form the SELECT list. Based on the selection criteria,
specified in the WHERE clause, values are returned into the host variables name_v and city_v.
Queries can return multiple rows depending on the selection criteria.
Note: If a query returns more than one row, the INTO clause is not used in the SELECT
statement; instead a cursor is used to return the results of a query.
Input Host Variables in Query Statements
The host variables that are used as input variables in the c-treeSQL statement are referred to as
input host variables. In a SELECT statement, input host variables can be used in the WHERE
clause. In the previous example, the host variable, cust_no_v used in the WHERE clause is an
input host variable.
Output Host Variables in Query Statements
The host variables that are used for receiving the query results, are referred to as output host
variables. In a query statement the output host variables are specified in the INTO clause. In the
example given in “Elements of a Query (page 85)” the host variables, name_v and city_v
specified in the INTO clause are output host variables. Whenever the output host variables are
used in a SELECT statement, the number of output host variables specified must equal the
number of columns specified in the SELECT list.
9.3 Queries Returning a Single Row
Queries returning a single row are the simplest of queries. When a query is known to return a
single row, then the INTO clause can be used to obtain the result of the query. The following
example shows a query on the customer table to retrieve the columns name, city, and state.
Example Query Returning a Single Row
...
/* connect to a default database */
EXEC SQL CONNECT TO DEFAULT ;
EXEC SQL
SELECT name, city, state
INTO :name_v, :city_v, :state_v
FROM customer
WHERE CUST_NO = 1001 ;
if (sqlca.sqlcode)
{
fprintf (stderr,
"Select statement failed (%ld : %s)\n",
sqlca.sqlcode, sqlca.sqlerrm);

Query Statements
All Rights Reserved 87 www.faircom.com
EXEC SQL ROLLBACK WORK ;
EXEC SQL DISCONNECT DEFAULT ;
exit (1);
}
printf ("name : %s, city : %s, state : %s\n",
name_v, city_v, state_v);
/* Commit changes */
EXEC SQL COMMIT WORK ;
/* Disconnect from the database */
EXEC SQL DISCONNECT DEFAULT ;
...
Note that the statement execution would fail if the above form of SELECT statement is used for
statements that return more than one row.
9.4 Queries Returning Multiple Rows
When a query returns more than one row, you must use a cursor in association with a SELECT
statement.
The following sections discuss the use of cursors.
Introduction to Cursors
A cursor is a c-treeSQL object that is associated with a specific SELECT statement. A named
cursor is associated with a SELECT operation by declaring the cursor. To access the rows
corresponding to the SELECT operation, the user must:
Associate a cursor with a query with the DECLARE CURSOR statement.
Open the cursor with the OPEN statement.
Execute a loop on the opened cursor to retrieve all the rows in the result set with FETCH
statements.
Close the cursor with the CLOSE statement.
A cursor can be in one of the two states: open or closed. When a cursor is in open state, it is
associated with an active set and points to the current row, before the first row, or after the last
row. When the query operation is completed, the cursor is closed using the CLOSE statement.
When a cursor is in the closed state, the cursor no longer is associated with an active set,
although it remains associated with the SELECT statement.
The following sections explain the use of cursors to process rows returned by a SELECT
statement.
Associating a Cursor with a Query
The DECLARE CURSOR statement is used to associate a cursor with a SELECT statement. The
DECLARE CURSOR statement declares a cursor, by assigning it a name and associating it with a

Query Statements
All Rights Reserved 88 www.faircom.com
query (SELECT statement). For more information on the DECLARE CURSOR statement, see
"DECLARE CURSOR" (page 155).
The syntax for DECLARE cursor is as shown below:
EXEC SQL
DECLARE cursor_name CURSOR FOR
SELECT ... FROM ...
The following example shows the declaration of a cursor, cust_cur, for a SELECT statement:
EXEC SQL
DECLARE cust_cur CURSOR FOR
SELECT name, city, state
FROM customer
WHERE CUST_NO = :cust_no_v;
The DECLARE CURSOR statement is a declarative c-treeSQL statement. The DECLARE CURSOR
statement for a cursor must occur before any other c-treeSQL statement referencing that cursor.
ESQL cannot interpret a reference to a cursor that is not declared. A cursor declared in one esqlc
source file can not be referred to in another esqlc source file.
The cursor name used in the DECLARE CURSOR statement must be unique.
Opening a Cursor
A cursor is opened using the OPEN statement. When a cursor is opened, the SELECT statement
associated with the cursor is executed and the result set is identified. Such a result set is referred
to as the active set. The cursor always points to a row in the active set. This row is referred to as
the current row. The rows that are retrieved as a result of the execution form the active set. For
more information on the OPEN statement, see "OPEN" (page 163).
The syntax for the OPEN statement is shown below:
EXEC SQL OPEN cursor_name ;
The following sample code shows the usage of the OPEN statement:
...
EXEC SQL
DECLARE cust_cur CURSOR FOR
SELECT name, city, state
FROM customer
WHERE CUST_NO = :cust_no_v;
EXEC SQL OPEN cust_cur ;
...
The OPEN statement puts the cursor in the open state. The OPEN statement causes the SELECT
statement to be processed with the current program variables and leaves the cursor pointing just
before the first row of the resulting active set. While the cursor is in the open state, subsequent
changes to any program variables that appear in the SELECT statement associated with the
cursor, do not affect the active set.
The input host variable values are not used while the cursor is opened. Hence the result of the
query is not affected if the variable values are changed after the cursor is opened. For these
changes to be reflected in the results of the query, the cursor must be closed and reopened.

Query Statements
All Rights Reserved 89 www.faircom.com
Retrieving Rows Using a Cursor
The FETCH statement is used to read the rows of the active set and return the values in host
variables. The SELECT statement associated with the cursor does not include the INTO clause;
rather, the INTO clause with the list of output host variables is included in the FETCH statement.
For more information on the FETCH statement, see "FETCH" (page 161).
The syntax of the FETCH statement is:
EXEC SQL
FETCH cursor_name
INTO :hostvar1, :hostvar2 ... ;
The following example shows fetching of rows opened by the cursor, cust_cur:
Example Query Returning Multiple Rows
...
/* connect to a default database */
EXEC SQL CONNECT TO DEFAULT ;
/* Declare the cursor for retrieving */
/* customer information. */
EXEC SQL
DECLARE cust_cur CURSOR FOR
SELECT name, city, state
FROM customer
WHERE CUST_NO = :cust_no_v;
/* Open cursor */
EXEC SQL OPEN cust_cur ;
/* Fetch the query results into host variables */
for (;;)
{
EXEC SQL
FETCH cust_cur
INTO :cust_no_v, :name_v, :city_v ;
if (sqlca.sqlcode) break ;
}
EXEC SQL CLOSE cust_cur ;
...
Before issuing a FETCH statement, the cursor named in the FETCH statement must have been
previously declared and opened. The first time the FETCH statement is executed, the cursor is
positioned on the first row of the active set. This row becomes the current row. Each subsequent
execution of FETCH advances the cursor to the next row in the active set. The only way to return
to a row that has been previously fetched is to close and reopen the cursor.
If the cursor is positioned on the last row of the active set or if the active set does not contain any
rows, then the execution of the FETCH statement will return the status code SQL_NOT_FOUND
in the SQLCA. In this case, to do any further operations with the cursor, the cursor has to be
closed and reopened.

Query Statements
All Rights Reserved 90 www.faircom.com
Closing a Cursor
The CLOSE cursor statement puts the cursor in the closed state. Once the cursor is closed, no
FETCH calls can be issued on the cursor until it is reopened. For more information on the CLOSE
statement, see "CLOSE" (page 155).
The syntax of the CLOSE cursor statement would be:
EXEC SQL CLOSE cursor_name ;
The following example shows the usage of the CLOSE cursor statement to close the cursor
cust_cur.
EXEC SQL CLOSE cust_cur ;
No fetches can be executed against a closed cursor, as its active set becomes undefined. After
the cursor is closed, no statements referring to the cursor, other than open cursor, are operative.
Deleting or Updating the Current Row
ESQL allows operations such as UPDATE and DELETE on the row that a cursor is currently
pointing to in the active set. This is possible with the usage of the CURRENT OF cursor construct,
in the WHERE clause of either the UPDATE or the DELETE statement. The format of such a WHERE
clause is shown below:
WHERE CURRENT OF cursor_name
Note the following:
Upon successful execution, the number of rows deleted/updated will be returned in
sqlca.sqlerrd [2].
sqlca.sqlwarn [4] is set to ‘W’ if the DELETE/UPDATE statement does not have a WHERE
clause so that unconditional deletes can be noted and the action either confirmed or rolled
back.
Use of the WHERE CURRENT OF clause is called to positioned DELETE/UPDATE operation:
• The positioned DELETE can be used only if the cursor has been declared with the FOR
UPDATE clause. The positioned DELETE operation can be specified only on an opened
cursor. The cursor is first positioned on the desired row to be deleted and then the
positioned DELETE operation executed.
• The positioned UPDATE can only be specified on an open cursor where the cursor has
been declared for a SELECT statement with a FOR UPDATE clause.
The following example shows the usage of the CURRENT OF cursor construct, in an UPDATE
statement:
...
EXEC SQL
DECLARE ord_cur CURSOR FOR
SELECT product, qty
FROM orders
WHERE order_no = :order_no_v
FOR UPDATE OF qty ;

Query Statements
All Rights Reserved 91 www.faircom.com
EXEC SQL OPEN ord_cur ;
EXEC SQL FETCH ord_cur INTO :product_v, :qty_v ;
EXEC SQL
UPDATE orders
SET qty = :qty_v + 1000
WHERE CURRENT OF ord_cur ;
...
The above example shows the updating of qty on the current row where the cursor is positioned
in the active set.
The positioned update can be performed only on an open cursor where the cursor has been
declared for the SELECT statement with a FOR UPDATE clause.
The positioned delete operation deletes the row that the cursor is currently positioned to in the
active set. After the positioned delete operation, the cursor is positioned before the row
immediately following the row just deleted, or after the last row if no such immediately following
row exists. The following sample code shows positioned delete, to delete the current row from the
orders table.
...
EXEC SQL
DECLARE ord_cur CURSOR FOR
SELECT product, qty
FROM orders
WHERE order_no = :order_no_v ;
EXEC SQL OPEN ord_cur ;
EXEC SQL FETCH ord_cur INTO :product_v, :qty_v ;
EXEC SQL
DELETE
FROM orders
WHERE CURRENT OF ord_cur ;
...
Array Fetches: Retrieving Multiple Rows with One FETCH
Statement
As discussed in the previous sections, the FETCH statement would return one row at a time from
the active set selected by the OPEN statement.
ESQL also provides support for fetching multiple rows at a time from the active set. This is more
efficient for fetching a large number of rows since it reduces the number of calls made to the
database. This section describes using explicitly-declared esqlcarrays to retrieve multiple rows in
one fetch operation. (Refer to "Using SQLDA for Array Fetches" (page 125) for information on
using the SQLDA for array fetches in dynamic c-treeSQL.)
Query Statements
All Rights Reserved 92 www.faircom.com
Note: Array fetches are an extension to the SQL standard.
All esqlc arrays (excluding character arrays) are mapped into a host language structure
consisting of both the actual array and the current size of the array. The C language structure is
of the following form:
struct new_type_name {
long tpe_size;
element_type_name tpe_array[constant_id];
};
Host language statements can manipulate the array assuming that it is a structure with the same
name as the array name and having two components tpe_array and tpe_size. The tpe_array
component contains the actual array and the tpe_size component contains the current size of the
array. (See "ESQL Reference" (page 153) for details on declaring esqlc arrays.)
When esqlc executes the FETCH statement, it sets tpe_size to the actual number of rows
returned.
The following sample code shows the use of two arrays, customer_name_array and
customer_id_array to select up to fifty rows in one fetch call.
Example
/* Fetch up to 50 rows in one fetch call */
#define ARRAYSZ 50
#define NAMESZ 30
EXEC SQL BEGIN DECLARE SECTION;
TYPE customer_name_t IS AN ARRAY OF CHAR WITH SIZE NAMESZ ;
TYPE customer_id_t IS OF TYPE LONG INTEGER ;
customer_name_array IS AN ARRAY OF customer_name_t
WITH SIZE ARRAYSZ ;
customer_id_array IS AN ARRAY OF customer_id_t
WITH SIZE ARRAYSZ ;
EXEC SQL END DECLARE SECTION;
...
EXEC SQL
DECLARE customer_cursor CURSOR FOR
SELECT name, CUST_NO
FROM customer ;
if (sqlca.sqlcode) goto err ;
EXEC SQL OPEN customer_cursor ;
if (sqlca.sqlcode) goto err ;
for (;;)
{
int i ;
EXEC SQL FETCH customer_cursor
INTO :customer_name_array, :customer_id_array;
/*
Note that in case of array fetches, one or
more rows could have been returned by the

Query Statements
All Rights Reserved 93 www.faircom.com
current execution of FETCH statement even if
the status code returned is SQL_NOT_FOUND.
*/
if (sqlca.sqlcode && sqlca.sqlcode !=
SQL_NOT_FOUND)
break ;
for (i = 0 ; i < customer_name_array.tpe_size ; i++)
{
printf ("Customer id = %ld Customer Name :
%s\n",
customer_id_array.tpe_array [i],
customer_name_array.tpe_array [i]) ;
}
if (sqlca.sqlcode) break ;
}
if (sqlca.sqlcode != SQL_NOT_FOUND) goto err ;
EXEC SQL CLOSE customer_cursor ;
if (sqlca.sqlcode) goto err ;
EXEC SQL COMMIT WORK ;
if (sqlca.sqlcode)
fprintf (stderr,
"COMMIT WORK returned error %ld\n", sqlca.sqlcode) ;
return ;
err:
EXEC SQL ROLLBACK WORK ;
return ;

All Rights Reserved 94 www.faircom.com
10. NULL Value Handling in ESQL
10.1 Introduction
This chapter describes the handling of NULL values in ESQL and discusses:
Inserting NULL values
Retrieving NULL values
Using NULL values in different clauses of a SELECT statement
NULL values are used in a database when the value of a column is not known or when the value
is not applicable. For example, when an employee has not been assigned to a department, the
department number in the corresponding row could be set to a NULL value. As another example,
the column commission of the employee table would be applicable only to sales persons and
hence, for employees of all other departments, this column would contain a NULL value. Note
that, a column value is distinguished between a numeric zero and a NULL value. Similarly, a
distinction is made between a string of blanks and a NULL value.
In c-treeSQL, the default value for a column is NULL, provided the column definition does not
contain the DEFAULT clause. A column of any data type can have a NULL value. It can be
specified that a column of any type not have NULL values using the NOT NULL clause in the
CREATE TABLE statement.
The usage of NULL values is discussed in the following sections.
10.2 Inserting NULL Values
A NULL value can be inserted into a column when a column value is not known or not applicable.
A NULL value can be inserted into a column:
By default
Using the NULL keyword
Using indicator variables
The following sections discuss each of these methods.
Inserting NULL Values by Default
In c-treeSQL, the default value for a column is NULL, if the column definition does not contain the
DEFAULT clause. For example, consider the employee table with the following schema:
CREATE TABLE employee

NULL Value Handling in ESQL
All Rights Reserved 95 www.faircom.com
(empno INTEGER NOT NULL,
ename CHAR(10),
job CHAR(10),
hiredate DATE,
sal NUMERIC (10,2),
commission NUMERIC(10,2),
deptno INTEGER NOT NULL,
projno INTEGER) ;
The following statement inserts a row in the employee table, but omits values for some of the
columns:
EXEC SQL
INSERT INTO employee
(empno, ename, job, hiredate, sal, deptno)
VALUES
(8585, 'RALPH', 'CLERK', '02/02/1992', 2000, 10) ;
When the above INSERT statement is executed, a null value is inserted into the columns
commission and projno.
A column of any type can be restricted not to have a NULL value by specifying NOT NULL in the
CREATE TABLE statement for that particular column.
A column for which a unique index is created can have at most one NULL value.
Using the NULL Keyword to Insert NULL Values
The keyword NULL can be used in the value list to indicate that a column in the column list
should be assigned a NULL value. The following example shows insertion of NULL for the
columns commission and projno using the NULL keyword:
EXEC SQL
INSERT INTO employee
VALUES (8585, 'RALPH', 'CLERK', '02/02/1992',
2000, NULL, 10, NULL) ;
Using Indicator Variables to Insert NULL Values
Indicator variables are special variables (declared as short or SMALLINT) associated with host
variables for the purpose of handling NULL values.
Indicator variables can be used to insert NULL values into a column. Set the indicator variable for
a particular column to be -1 and use the indicator variable along with the corresponding host
variable in the value list of the INSERT statement. The following example shows insertion of
NULL values for the columns commission and projno in the employee table using indicator
variables:
Example Using Indicator Variables to Insert NULL Values
...
EXEC SQL BEGIN DECLARE SECTION ;
long empno_v ;
char ename_v [10] ;
char job_v [10] ;
char hiredate_v [20] ;

NULL Value Handling in ESQL
All Rights Reserved 96 www.faircom.com
long sal_v ;
long commission_v ;
short commission_i ;
long deptno_v ;
long projno_v ;
short projno_i ;
EXEC SQL END DECLARE SECTION ;
...
empno_v = 2402 ;
strcpy (ename_v, 'RALPH') ;
strcpy (job_v, 'CLERK') ;
strcpy (hiredate_v, '02/02/1992') ;
sal_v = 2000 ;
commission_i = -1 ;
deptno_v = 10 ;
projno_i = -1 ;
EXEC SQL
INSERT INTO employee
VALUES (:empno_v, :ename_v, :job_v, :hiredate_v,
:sal_v, :commission_v:commission_i,
:deptno_v, :projno_v:projno_i) ;
...
This is a better programming alternative than hard coding NULL in the insert statement. Here, the
indicator variable is preset to -1 so that a NULL value is used instead of the value of the host
variable.
10.3 Updating with NULL Values
A column value can be modified to contain a NULL value by using the UPDATE statement. This
can be done by setting the desired column with the keyword NULL in the UPDATE statement.
The following example shows the updating of the column projno since there is no project currently
assigned to the employee with empno 2040.
EXEC SQL
UPDATE employee
SET projno = NULL
WHERE empno = 2040 ;
Alternatively, a column value can be modified to contain NULL values by using indicator
variables. The indicator variable can be set to -1 and used along with the host variable to set a
value to NULL. The following example shows the employee table being updated using an
indicator variable:
projno_i = -1 ;
EXEC SQL
UPDATE employee
SET projno = projno_v:projno_i
WHERE empno = 2040 ;

NULL Value Handling in ESQL
All Rights Reserved 97 www.faircom.com
10.4 Retrieving NULL Values
NULL values can be handled while retrieving the rows in the following ways using a SELECT
statement with:
An indicator variable
The scalar function NVL
The following sections discuss each of these methods.
Using Indicator Variables to Retrieve NULL Values
Indicator variables are special variables (declared as short or SMALLINT) associated with host
variables for the purpose of handling NULL values.
During a query, NULL values can be identified using the indicator variables along with the output
host variables in the INTO clause. The following example shows how to identify NULL values
while retrieving rows.
Example Using Indicator Variables to Retrieve NULL Values
...
EXEC SQL BEGIN DECLARE SECTION ;
long empno_v ;
char ename_v [10] ;
char job_v [10] ;
char hiredate_v [20] ;
long sal_v ;
long commission_v ;
short commission_i ;
long deptno_v ;
long projno_v ;
short projno_i ;
...
EXEC SQL END DECLARE SECTION ;
EXEC SQL
SELECT ename, job, deptno, projno
INTO :ename_v, :job_v, :deptno_v,
:projno_v:projno_i
FROM employee
WHERE empno = 1250 ;
if (projno_i == -1)
printf ("project number is NULL\n") ;
...
Using the Scalar Function NVL to Retrieve NULL values
The scalar function NVL, can be used to identify NULL values in a column.
The syntax of the NVL function is as shown below:

NULL Value Handling in ESQL
All Rights Reserved 98 www.faircom.com
NVL (expression, expression) ;
The NVL function returns the value of the first expression, if the first expression value is not
NULL. If the first expression value is NULL, the value of the second expression is returned. The
following example shows the usage of NVL to identify NULL values in the column commission of
the employee table.
EXEC SQL
SELECT sal + NVL (commission, 0) 'Total Salary'
FROM employee
If the column commission is NULL, then a zero is added to the salary of the employee and
returned as Total Salary.
10.5 Using NULL Values in Expressions
Expressions can be used in the SELECT list for retrieving NULL values. If any value that
participates in an arithmetic expression is NULL, the value of the entire expression is NULL.
Consider the following example:
EXEC SQL
SELECT ename, sal, sal + commission
FROM employee
WHERE empno = 2452 ;
In the above example if the commission for empno 2452 is NULL, then the value of the
expression sal + commission in the SELECT list would evaluate to NULL.
10.6 Using NULL Values in the WHERE Clause
A row gets selected if the search condition specified using the WHERE clause evaluates to TRUE
and not if evaluated to FALSE or unknown.
Consider the following WHERE clause:
WHERE ((sal + commission) < 5000)
AND empno = 2004 ;
In the above example, if commission is NULL for empno 2004, then the search condition is not
satisfied. Instead, the following search condition with an OR would evaluate to TRUE:
WHERE ((sal + commission) < 5000)
OR empno = 2004 ;
A row containing NULL values can be selected or rejected using the search condition:
column IS [NOT] NULL
The following example shows the selection of employee names and department numbers for
employees who have not been assigned to any project.
EXEC SQL
SELECT ename, deptno
FROM employee
WHERE projno IS NULL ;
If a join is performed between two tables using the WHERE clause:

NULL Value Handling in ESQL
All Rights Reserved 99 www.faircom.com
WHERE column1 = column2
Rows will not be selected if either of the columns column1 or column2 is NULL. Also, rows will not
be selected if both column1 and column2 are NULL.
10.7 Using NULL Values in GROUP BY Clause
If a GROUP BY clause is applied on a column containing NULL values, then all NULL values are
grouped as a separate group. The following is an example showing the grouping of employees
based on the project numbers:
EXEC SQL
SELECT ename, COUNT (*)
FROM employee
GROUP BY projno ;
10.8 Using NULL Values in ORDER BY Clause
When an ORDER BY clause is applied on a column containing NULL values, the NULL value is
treated as being less than any non-NULL value. Hence, when the ordering is ascending, the
NULL values come first; and when the ordering is descending, the NULL values come last. The
following example shows the selection of employees ordered by the project numbers:
EXEC SQL
SELECT ename, deptno
FROM employee
ORDER BY projno ;
10.9 Using NULL Values in Scalar Functions
Except with scalar functions like NVL, that specifically check for NULL value, most of the scalar
functions return NULL value if any of the arguments evaluate to NULL.
10.10 Using NULL Values in Aggregate Functions
The aggregate functions ignore rows with NULL values for their argument and return the value
based on the rest of the rows. The function COUNT can also have an expression as the
argument. For example, to count all the columns including NULL values in the commission
column, the SELECT statement would be:
EXEC SQL
SELECT COUNT (NVL (commission, 0))
FROM employee ;
If the column contains only NULL values, the COUNT (DISTINCT column_name) returns zero
and the rest of the aggregate functions return NULL for that column.
An exception is the usage COUNT(*). Irrespective of the column values this would get the
number of rows.

All Rights Reserved 100 www.faircom.com
11. Error Handling in ESQL
11.1 Introduction
This chapter describes the handling of errors in ESQL and discusses the use of:
SQLCA
The WHENEVER statement
Indicator variables
11.2 Using SQLCA for Error Handling
The c-treeSQL Communication Area (SQLCA) is used to return the status of a c-treeSQL
statement’s execution in an ESQL program. For example, SQLCA indicates an error if a SELECT
statement has a reference to a table that does not exist in the database.
In esqlc, SQLCA is implemented as a structure. The precompiler automatically declares and
defines a global SQLCA structure. Fields of the SQLCA structure give details on the status of the
execution of a c-treeSQL statement.
Fields of the SQLCA
SQLCA Structure
struct sqlca {
char sqlcaid[8] ;
long sqlcabc ;
long sqlcode ;
unsigned short sqlerrml ;
char sqlerrm[72] ;
char sqlerrp[8] ;
long sqlerrd[6] ;
char sqlwarn[8] ;
char sqlext[8] ;
cost_val_t estimated_cost, actual_cost;
} ;
Fields of the SQLCA
sqlcaid
Contains the string “SQLCA”.

Error Handling in ESQL
All Rights Reserved 101 www.faircom.com
sqlcabc
Contains the size of the structure SQLCA.
sqlcode
Summarizes the results of a c-treeSQL statement’s execution.
sqlcode Description
zero Indicates successful execution.
positive Indicates successful execution with a status code. The only positive error code c-treeSQL returns is SQL_NOT_FOUND.
negative Indicates an error in the SQL statement or a system failure.
See Appendix B in the c-treeSQL Reference Manual for valid values of error codes.
sqlerrml
Contains the length of the error message contained in sqlerrm.
sqlerrm
A null terminated character string that is the error text corresponding to the code returned in the
field sqlcode.
sqlerrp
Currently unused.
sqlerrd
An array of six 4 byte integers used to describe the internal state of the c-treeSQL kernel.
Currently, only the third integer sqlerrd[2] is used and indicates the number of rows processed for
INSERT, UPDATE and DELETE statements. sqlerrd[2] is set to the cumulative number of rows for
a FETCH call associated with a cursor.
sqlwarn
A character array of size eight where each character position can either be a blank or a ‘W’. ‘W’
indicates a warning during the execution of an c-treeSQL statement. Currently, only elements [0],
[1], [2], [3], [4], and [6] of the array are used.
sqlwarn[0] If this field is set to ‘W’, then one or more of the other sqlwarn fields have been set. If this field is blank, then it can be assumed that no warning has been set.
sqlwarn[1] If this field is set to ‘W’, it indicates that one or more of the returned character string fields have been truncated. The indicator variables can be used to determine which of the character strings have been truncated.
sqlwarn[2] If this field is set to ‘W’, then one or more null values were ignored in the computation of an aggregate function such as SUM, AVG, MIN, and MAX.
sqlwarn[3] If this field is set to ‘W’, it indicates that the number of items in the SELECT list does not equal the number of host variables in the INTO clause. The data is returned with the number of elements being returned being the least of the two numbers.
sqlwarn[4] This field is set to ‘W’ after a successful execution of an UPDATE or a DELETE statement that does not have a WHERE clause.

Error Handling in ESQL
All Rights Reserved 102 www.faircom.com
sqlwarn[6] This field is set to ‘W’ if the SQLkernel had to perform an implicit rollback due to a system failure and/or due to a deadlock situation.
sqlext
Not used.
estimated_cost
The cost estimated by the optimizer for executing the statement. The type cost_val_t is defined
as follows:
typedef struct {
long cost;
long card;
long treesize;
long rss_calls;
} cost_val_t ;
actual_cost
The actual cost of executing the statement.
Using SQLCA for Checking Errors
The execution of an ESQL statement can either be a success or failure. In case of failure, the
SQLCA can be used to check for the error code and the corresponding error message. The
following components of the SQLCA structure are used to get the error codes and error
messages:
sqlcode indicates the return status of the execution of an ESQL statement. sqlcode is set to
zero for a successful execution and is negative for an unsuccessful execution. Also sqlcode
can be set to SQL_NOT_FOUND which is set while using a FETCH call and when there are
no more rows to be fetched.
sqlerrm is a null terminated character string which is the diagnostic text corresponding to the
sqlcode.
sqlerrml contains the length of the error message contained in sqlerrm.
sqlerrd is an array of six variables of type integer.
The following example shows the use of the SQLCA components sqlcode and sqlerrm:
Example Using SQLCA
...
< connect to a default database >
EXEC SQL BEGIN DECLARE SECTION ;
long deptno_v ;
char dname_v [20] ;
char loc_v [10] ;
EXEC SQL END DECLARE SECTION ;
/* Get values for input host variables */
deptno_v = 30 ;
strcpy (dname_v, "ACCOUNTS") ;
strcpy (loc_v, "BOSTON") ;

Error Handling in ESQL
All Rights Reserved 103 www.faircom.com
EXEC SQL
INSERT INTO department (deptno, dname, loc)
VALUES (:deptno_v, :dname_v, :loc_v) ;
if (sqlca.sqlcode)
{
fprintf (stderr,
"Insert statement failed (%ld : %s)\n",
sqlca.sqlcode, sqlca.sqlerrm);
EXEC SQL
ROLLBACK WORK ;
< disconnect from the database >
exit (1);
}
/* Commit changes */
EXEC SQL
COMMIT WORK ;
printf ("Inserted one row \n\n");
< disconnect from the database >
...
The following example shows how to check for SQL_NOT_FOUND status code while using the
FETCH call:
Example Checking for SQL_NOT_FOUND
...
EXEC SQL CONNECT TO DEFAULT ;
/* Declare cursor for retrieving customer information */
EXEC SQL
DECLARE cust_cur CURSOR FOR
SELECT name, city, state
FROM customer
WHERE CUST_NO = :cust_no_v;
if (sqlca.sqlcode)
{
fprintf (stderr,
"Declare cursor statement failed (%ld : %s)\n",
sqlca.sqlcode, sqlca.sqlerrm);
EXEC SQL ROLLBACK WORK ;
EXEC SQL DISCONNECT DEFAULT ;
exit (1);
}
/* Open cursor */
EXEC SQL OPEN cust_cur ;
if (sqlca.sqlcode)
{
fprintf (stderr,
"Open cursor statement failed (%ld : %s)\n",

Error Handling in ESQL
All Rights Reserved 104 www.faircom.com
sqlca.sqlcode, sqlca.sqlerrm);
EXEC SQL ROLLBACK WORK ;
EXEC SQL DISCONNECT DEFAULT ;
exit (1);
}
/* Fetch rows and return result values into host variables */
for (;;)
{
EXEC SQL FETCH cust_cur INTO :cust_no_v,
:name_v, :city_v ;
if (sqlca.sqlcode == SQL_NOT_FOUND) break ;
if (sqlca.sqlcode)
{
fprintf (stderr,
"FETCH cursor statement failed (%ld :
%s)\n",
sqlca.sqlcode, sqlca.sqlerrm);
EXEC SQL CLOSE cust_cur ;
EXEC SQL ROLLBACK WORK ;
EXEC SQL DISCONNECT DEFAULT ;
exit (1);
}
printf ("CUST_NO : %d, name : %s, city : %s\n",
cust_no_v, name_v, city_v) ;
}
EXEC SQL CLOSE cust_cur ;
EXEC SQL COMMIT WORK ;
EXEC SQL DISCONNECT DEFAULT ;
...
Using SQLCA for Checking Warnings
Warnings that occur during the execution of an ESQL statement can be checked using SQLCA.
The component sqlwarn of SQLCA is an array of eight characters. Each element of the array can
either be a blank or ‘W’. Currently, only the elements [0], [1], [2], [3], [4], and [6] of the array are
used.
The warning flags could be set:
If one or more string values returned by a query are truncated.
If one or more NULL values were ignored in a computation of an aggregate function.
If the number of items in the SELECT list does not equal the number of host variables in the
INTO clause.
If the database implicitly marks the transaction for rollback.
The following example shows the computation of the average commission for employees in the
sales department.

Error Handling in ESQL
All Rights Reserved 105 www.faircom.com
Example Using sqlwarn Component of SQLCA
...
EXEC SQL BEGIN DECLARE SECTION ;
FLOAT comm_v ;
EXEC SQL END DECLARE SECTION ;
...
EXEC SQL CONNECT TO DEFAULT ;
EXEC SQL
SELECT AVG (commission)
INTO :comm_v
FROM employee
WHERE deptno = 20 ;
if (sqlcode == 0)
{
printf ("commission : %d\n", comm_v) ;
/* Check for SQLCA warnings */
if (sqlca.sqlwarn[2] == 'W')
printf ("(One or more NULL values ignored\n") ;
printf (" in the computation of average commission !)\n") ;
}
...
In the previous example, the sqlwarn[2] component of SQLCA is used to determine whether
some null values were ignored in the computation of the average commission.
Using the WHENEVER Statement for Error Handling
The WHENEVER statement specifies an action (stop, continue, or branch) for the host program to
take when one of three common c-treeSQL runtime exceptions arises. The syntax for the
WHENEVER statement is as follows:
WHENEVER
{ NOT FOUND | SQLERROR | SQLWARNING }
{ STOP | CONTINUE | { GOTO | GO TO } host_language_label } ;
See "WHENEVER" (page 175) for details on the WHENEVER statement.
The scope of a WHENEVER statement starts from the point where the statement appears until
another WHENEVER statement for the same exception encountered or until the end of the esqlc
source file.
The specification of the action GOTO host_language_label causes control to pass to the
statement at the specified label. The specification of the action STOP results in program
termination. The specification of the action CONTINUE ignores the SQLCA status and causes the
next statement to be executed in the program.

Error Handling in ESQL
All Rights Reserved 106 www.faircom.com
Use the CONTINUE action in a WHENEVER statement within exception handling code. This
prevents the WHENEVER statement from passing control to the same label (which would result in a
program loop), if any of the ESQL statements within the label fails.
Avoid use of the action STOP. Though valid, using it means that the program will terminate
without any final reporting.
The following example shows the use of WHENEVER statement for exception handling in an ESQL
program that deletes a row:
Example Using the WHENEVER Statement
...
/* code to connect to a database */
EXEC SQL CONNECT TO DEFAULT ;
/* Upon error branch to label do_rollback */
EXEC SQL WHENEVER SQLERROR GOTO do_rollback ;
EXEC SQL WHENEVER NOT FOUND GOTO do_rollback ;
/* Get value for cust_no_v */
cust_no_v = 1002 ;
EXEC SQL
DELETE
FROM customer
WHERE CUST_NO = :cust_no_v ;
/* Commit work and disconnect from database */
EXEC SQL COMMIT WORK ;
EXEC SQL DISCONNECT DEFAULT ;
exit (0) ;
do_rollback:
if (sqlca.sqlcode == SQL_NOT_FOUND)
fprintf (stderr,
"Customer number not found in table\n");
else
if (sqlca.sqlcode < 0)
{
strncpy (errmesg, sqlca.sqlerrm, sqlca.sqlerrml);
errmesg [sqlca.sqlerrml] = '\0' ;
fprintf (stderr, "Error : %s\n", errmesg);
}
EXEC SQL WHENEVER SQLERROR CONTINUE ;
EXEC SQL ROLLBACK WORK ;
EXEC SQL DISCONNECT DEFAULT ;
exit (1) ;
...

Error Handling in ESQL
All Rights Reserved 107 www.faircom.com
Handling the SQL_NOT_FOUND Condition with WHENEVER
When the FETCH call is made, SQL_NOT_FOUND is set in the SQLCA if there are no more rows
to be fetched that satisfy the query. Hence, when a FETCH call returns SQL_NOT_FOUND, the
application can close the cursor.
The SQL_NOT_FOUND status could also be returned by the execution of UPDATE/DELETE
statements. These statements return SQL_NOT_FOUND when no rows are updated/deleted
because none satisfied the condition specified.
Using WHENEVER Along With Explicit Error Checking
In addition to using WHENEVER statements, the SQLCA can also be explicitly checked in an ESQL
program.
Consider the following example:
...
EXEC SQL
WHENEVER SQLERROR GOTO do_rollback ;
...
/* Fetch rows and return result values into host
variables */
for (;;)
{
EXEC SQL FETCH cust_cur INTO :cust_no_v,
:name_v, :city_v ;
if (sqlca.sqlcode == SQL_NOT_FOUND)
break ;
}
...
In the above example, explicit SQLCA check is done in addition to having a WHENEVER
statement.
Using Indicator Variables for Error Handling
Indicator variables can be used in the ESQL application program to detect whether the retrieved
value is null or whether the value is truncated. The value would be truncated if the size of the
returned value is larger than the size of the host variable used to retrieve the value.
The value of an indicator variable is interpreted as shown below:
-1 The returned value is NULL and the value of the corresponding host variable is not defined.
>0 The returned value was truncated because the host variable size was too small. The value contained in the indicator variable is the actual length before truncation.

Error Handling in ESQL
All Rights Reserved 108 www.faircom.com
The following example shows the usage of indicator variables to detect null:
...
EXEC SQL
SELECT ename, deptno, commission
INTO :ename_v, :deptno_v,
:commission_v:commission_i
FROM employee
WHERE empno = 2002 ;
if (commission_i == -1)
printf ("Commission is NULL\n") ;
...
In the above example, the indicator variable commission_i is used to detect whether the retrieved
value for commission is NULL.

All Rights Reserved 109 www.faircom.com
12. Dynamic SQL Management in ESQL
12.1 Introduction
Dynamic SQL provides a set of special statements and a structure that lets programs accept or
generate c-treeSQL statements at run time. Unlike conventional precompiled programs, in which
c-treeSQL statements are embedded in the source code, dynamic SQL programs can accept
input (from a user or another application) and formulate c-treeSQL statements at run time.
Dynamic SQL is useful when programs cannot predict before they execute the type of c-treeSQL
statement they will need to process. Interactive SQL is an example of dynamic SQL program that
executes c-treeSQL statements dynamically.
This chapter describes how to use the special statements (PREPARE, DESCRIBE, EXECUTE, and
EXECUTE IMMEDIATE) and structure (the SQLDA). See "ESQL Reference" (page 153) for
detailed reference material on the statements.
12.2 Overview
It is assumed that the c-treeSQL statements are known when an ESQL program is written. Such
statements are called static SQL statements. However, there are several applications where the
c-treeSQL statement is not known at compile time. Such c-treeSQL statements are called
dynamic SQL statements.
For example, the c-treeSQL statements issued in Interactive SQL (ISQL) are not known
beforehand. Any ISQL statement could be a SELECT or a non-SELECT statement. These
statements are processed by ISQL as dynamic SQL statements.
While dynamic SQL statements provide much more flexibility in what their programs can
accomplish, the cost of this flexibility is increased complexity.
The following steps are involved in the execution of a dynamic SELECT statement:
1. PREPARE statement
2. DECLARE cursor
3. OPEN cursor
4. FETCH rows using cursor
5. CLOSE cursor
The following are the steps involved in the execution of a dynamic non-SELECT statement:
1. PREPARE statement
2. EXECUTE statement

Dynamic SQL Management in ESQL
All Rights Reserved 110 www.faircom.com
12.3 Preparing Statements
The PREPARE statement is used by the application programs to prepare a c-treeSQL statement
for execution. When a c-treeSQL statement is prepared using PREPARE, the c-treeSQL statement
is parsed to check for syntax errors. Then a statement identifier is assigned to the c-treeSQL
statement.
The c-treeSQL statement used in the PREPARE statement can be specified either as a character
string or a reference to a host variable. If the c-treeSQL statement is specified through a host
variable reference, the host variable must be a character array.
PREPARE statements can be used for both SELECT as well as non-SELECT statements. The
c-treeSQL statement is prepared once but is executed as often as necessary, within the same
transaction. If the current transaction is committed or rolled back, and the c-treeSQL statement is
to be re-executed, the statement must be prepared again. For more information on the PREPARE
statement, see "PREPARE" (page 164).
The following example shows the usage of the PREPARE statement:
...
EXEC SQL BEGIN DECLARE SECTION ;
char sql_str [256] ;
EXEC SQL END DECLARE SECTION ;
...
strcpy (sql_str, "delete from customer where CUST_NO = :p1") ;
EXEC SQL PREPARE delstmt FROM :sql_str ;
...
The statement identifier used in the PREPARE statement is delstmt. This identifier is for further
referencing of the statement by ESQL statements. It can also be seen that the host variable,
sql_str, is declared in the declare section.
The host variable reference made in the c-treeSQL statement, such as p1, is just a marker. The
name of the host variable reference marker used in the prepared c-treeSQL statement is in no
way related to the name of the host variable that would contain the corresponding value. For
example, in the prepared c-treeSQL statement string, the name p1 could be used where as the
name of the host variable used to supply the value could be cust_no_v.
The following is an example showing the usage of a character string in the PREPARE statement:
EXEC SQL
PREPARE selstmt FROM select * from customer ;
Note: The dynamic SQL statements must not contain the terminating semicolon.
The ESQL statements that cannot be prepared include:
CLOSE
DECLARE

Dynamic SQL Management in ESQL
All Rights Reserved 111 www.faircom.com
EXECUTE
FETCH
OPEN
PREPARE
SELECT with an INTO clause
Non-SELECT Statements
A non-SELECT dynamic SQL statement can be executed using a two step process. The
statement should be first prepared using the PREPARE statement. The second step is to execute
the prepared statement by supplying values, if any, to the input host variables specified in the
PREPARE statement. This execution is done using the EXECUTE statement. For more information
on the PREPARE or EXECUTE statement, see "ESQL Reference" (page 153).
Executing a Non-SELECT Statement
The EXECUTE statement takes the statement identifier of a prepared statement and executes the
statement.
The following example shows the usage of the EXECUTE statement in an ESQL program:
Example Dynamic non-SELECT Statement
EXEC SQL BEGIN DECLARE SECTION ;
char sql_str [256] ;
long cust_no_v ;
EXEC SQL END DECLARE SECTION ;
/* connect to a default database */
EXEC SQL CONNECT TO DEFAULT ;
strcpy (sql_str, "delete from customer where CUST_NO = :p1") ;
EXEC SQL PREPARE stmt FROM :sql_str ;
cust_no_v = 1001 ;
EXEC SQL EXECUTE stmt USING :cust_no_v ;
/* Commit changes */
EXEC SQL COMMIT WORK ;
/* Disconnect from the database */
EXEC SQL DISCONNECT DEFAULT ;
The EXECUTE statement executes the prepared statement using the values supplied for each
host variable. In the above example, the host variable supplied is cust_no_v.
The c-treeSQL statement is prepared just once, but is executed as often as necessary, within the
same transaction. If the current transaction is committed or rolled back, and the c-treeSQL
statement is to be re-executed, the statement must be prepared again.

Dynamic SQL Management in ESQL
All Rights Reserved 112 www.faircom.com
The EXECUTE IMMEDIATE Statement
The c-treeSQL executable statement, EXECUTE IMMEDIATE, is similar to using PREPARE and
EXECUTE. The EXECUTE IMMEDIATE statement accepts as input, a character string or a host
variable of character array type. For more information on the EXECUTE IMMEDIATE statement,
see "ESQL Reference" (page 153).
The following example shows the usage of EXECUTE IMMEDIATE statement:
Example Using EXECUTE IMMEDIATE Statement
...
EXEC SQL BEGIN DECLARE SECTION ;
char sql_str [256] ;
EXEC SQL END DECLARE SECTION ;
gets (sql_str) ;
EXEC SQL EXECUTE IMMEDIATE :sql_str ;
...
A character string can be used in the place of a host variable reference as shown below:
EXEC SQL EXECUTE IMMEDIATE
"delete from customer where CUST_NO = 1001" ;
It can be noted that the c-treeSQL string given to a EXECUTE IMMEDIATE statement should not
have host variable references.
Note:The EXECUTE IMMEDIATE statement is a non-ANSI feature.
SELECT Statements
Dynamic SELECT statements have to be executed differently since they return information as
compared to non-SELECT statements where the return information is restricted to the SQLCA.
The statements used for dynamic SELECT include OPEN, FETCH, and CLOSE. A simple form of a
dynamic SELECT statement is the one that allows queries whose SELECT list is known but whose
search criteria (as in the WHERE clause) or ordering (as in the ORDER BY clause) might vary. The
processing of a dynamic SELECT statement involves the following steps:
1. PREPARE statement
2. DECLARE cursor
3. OPEN cursor
4. FETCH rows using a cursor
5. CLOSE cursor
Opening a Cursor
The OPEN statement puts a cursor in an open state. When a cursor is opened, the SELECT
statement associated with the cursor is executed and the result set is obtained. Such a result set
is referred to as the active set. The execution of the SELECT statement uses the current program

Dynamic SQL Management in ESQL
All Rights Reserved 113 www.faircom.com
variables and leaves the cursor positioned just before the first row in the active set. When the
cursor is in the open state, any changes to the program variables of the SELECT statement do not
change the rows retrieved in the active set.
The following example shows the opening of the cursor, custcur.
/* Open the cursor */
EXEC SQL
OPEN custcur ;
Fetching Rows Using a Cursor
The FETCH statement advances the cursor to the next row in the active set and retrieves the
values from that row. If the FETCH statement is executed for the first time, the cursor is positioned
on the first row and all the values of the first row are retrieved. Subsequent calls to FETCH
retrieve rows one by one from the active set. When all the rows in the active set are retrieved,
SQL_NOT_FOUND is set in the SQLCA to indicate that all rows have been retrieved. The
following example code shows the usage of the FETCH statement:
Example Dynamic SELECT Statement
...
/* connect to a default database */
EXEC SQL CONNECT TO DEFAULT ;
EXEC SQL
PREPARE cust_sel_stmt
FROM SELECT CUST_NO, name, city FROM customer ;
EXEC SQL
DECLARE cust_cursor CURSOR FOR cust_sel_stmt ;
/* Open the cursor declared */
EXEC SQL OPEN custcur ;
/* fetch rows and print them */
for (;;)
{
EXEC SQL
FETCH cust_cursor
INTO :cust_no_v, :name_v, :city_v ;
if (sqlca.sqlcode)
break;
printf ("%d, %s, %s\n",
cust_no_v, name_v, city_v) ;
}
EXEC SQL CLOSE cust_cursor ;
/* Commit changes */
EXEC SQL COMMIT WORK ;
/* Disconnect from the database */
EXEC SQL DISCONNECT DEFAULT ;
...
Dynamic SQL Management in ESQL
All Rights Reserved 114 www.faircom.com
Closing a Cursor
The CLOSE statement puts the cursor that is in an open state to a closed state. After a cursor is
closed the cursor becomes invalid unless it is opened using the OPEN statement.
The following statement closes the cursor, cust_cursor.
EXEC SQL CLOSE cust_cursor ;
12.4 ESQL Descriptor Statement
c-treeSQL statements for dynamic SQL specify the DESCRIPTOR keyword to use the SQL-92
descriptor area instead of the SQLDA.
ALLOCATE DESCRIPTOR
Description
Use this statement to allocate a c-treeSQL descriptor area.
Syntax
The syntax for this non-preparable statement is:
ALLOCATE DESCRIPTOR desc_name
[ WITH MAX occurrences ]
Arguments
desc_name
Literal/host variable/parameter containing the name of the SQL Descriptor Area.
Occurrences
The integer value that gives the number of items for which the descriptor area is allocated. If the
WITH MAX clause is not mentioned, then a default value of 10 number of items are allocated in
the c-treeSQL Descriptor Area.
Example
EXEC SQL ALLOCATE DESCRIPTOR dn 15;
DEALLOCATE DESCRIPTOR
Description
Use this statement to deallocate a c-treeSQL descriptor area that has been previously allocated,
to free memory.
Syntax
The syntax for this non-preparable statement is :
Dynamic SQL Management in ESQL
All Rights Reserved 115 www.faircom.com
DEALLOCATE DESCRIPTOR desc_name
Arguments
desc_name
Literal/host variable/parameter containing the name of a previously allocated c-treeSQL
Descriptor Area.
Example
EXEC SQL DEALLOCATE DESCRIPTOR dn;
GET DESCRIPTOR
Description
Use to obtain Information from the c-treeSQL Descriptor Area. There are two variations of the Get
Descriptor statement.
Syntax 1 GET DESCRIPTOR descriptor_name
target = COUNT
This returns the number of filled-in items in the Descriptor Area.
Arguments
descriptor_name
The name of the Descriptor Area.
target
Host variable that is specified to receive the number of items that are in use in the Descriptor
Area.
Syntax 2 GET DESCRIPTOR descriptor_name
VALUE item_number
{ :hv0 = COUNT | VALUE item_number :hv1 = item_name1
[ {, :hvN = item_nameN}] } ;
This retrieves information from a specific item in the Descriptor Area.
Arguments
descriptor_name
The name of the Descriptor Area.
target
Host variable/parameter of the appropriate data type that is specified to receive the number of
items that are in use in the Descriptor Area.

Dynamic SQL Management in ESQL
All Rights Reserved 116 www.faircom.com
item_number
The position of the item in the SQL statement. item_number can be a variable or a constant. If
item_number is greater than COUNT, the “no data found” condition is returned. item_number must
be greater than 0.
hv1 .. hvN
These are host variables to which values are transferred.
item_name1 .. item_nameN
The descriptor item names corresponding to the host variables
Descriptor Item Name
Descriptor Item Name Meaning
TYPE Data Type of the Field.
LENGTH Length of data in the column: in characters for NCHAR; in bytes
otherwise. Set by the DESCRIBE OUTPUT.
OCTET_LENGTH Length of data in bytes.
RETURNED_LENGTH The actual data length after a FETCH.
PRECISION The number of digits.
SCALE For exact numeric types, the number of digits to the right of the decimal point.
DATETIME_INTERVAL_CODE Code for datetime/interval substrings.
DATETIME_INTERVAL_PRECISION Precision for interval’s leading field.
NULLABLE If 1, the column can have NULL values. If 0, the column cannot have NULL values.
INDICATOR The associated indicator value.
DATA The data value.
NAME Column name.
COLLATION_NAME Character string with character set SQL_TEXT.
CHARACTER_SET_NAME Column’s character set.
TABLE_NAME Contains the table name of the result set column.
BASE_TABLE_NAME Contains the base table name for the result set column.
BASE_COLUMN_NAME Contains the base column name for the result set column.
GET DESCRIPTOR Example
EXEC SQL GET DESCRIPTOR dn
:h1 = COUNT ;
Dynamic SQL Management in ESQL
All Rights Reserved 117 www.faircom.com
EXEC SQL GET DESCRIPTOR dn
VALUE 1
:h1 = TYPE, :h2 = LENGTH, :h3 = PRECISION, :h4 = SCALE, :h5 =
OCTET_LENGTH,:h6=RETURNED_LENGTH,:h7= DATETIME_INTERVAL_CODE,:h8=DATETIME_INTERVAL_PRECISION,
:h9 = NULLABLE, :h10 = UPDATABLE, :h11 = SEARCHABLE, :h12 = PARAMETER_TYPE, :h13 = VERBOSE_TYPE,:h14
= CASE_SENSITIVE, :h15 = INDICATOR, :h16 = AUTO_UNIQUE_VALUE,:h17 = UNSIGNED, :h18 = UNNAMED, :c1
= NAME, :c2 = DATA,:c3 = COLLATION_NAME, :c4 = CHARACTER_SET_NAME, :c5 = TABLE_NAME,:c6 =
BASE_COLUMN_NAME, :c7 = BASE_TABLE_NAME;
SET DESCRIPTOR
Description
Use this statement to set information in the descriptor area from host variables. The SET
DESCRIPTOR statement supports only host variables for the item names.
Example
If the host variable or parameter has a slightly different type than what the c-treeACE SQL Server
has written into the c-treeSQL Descriptor Area, then this statement can be used to set certain
fields in the c-treeSQL Descriptor Area. This forces the c-treeACE SQL Server to cast the Data
field in the c-treeSQL Descriptor Area to the type of the host variable/parameter. The end-user
doesn’t have to explicitly cast the data from the c-treeSQL Descriptor Area.
There are two variants of this statement as in GET DESCRIPTOR.
Syntax 1 SET DESCRIPTOR desc_name
COUNT = value
Arguments
desc_name
Name of a valid c-treeSQL Descriptor Area.
Value
Integer value for the no. of items in the c-treeSQL Descriptor Area.
if ( value>occurrences || value<1 )
Syntax 2 SET DESCRIPTOR desc_name
VALUE item_number
item_name1 = value1 [ , item_nameN = valueN ]
Arguments
descriptor_name
The name of the Descriptor Area.
item_number
Integer that identifies a specific item in the Descriptor Area.

Dynamic SQL Management in ESQL
All Rights Reserved 118 www.faircom.com
item_name1 .. item_nameN
The descriptor item names corresponding to the host variables.
value1.. valueN
These are host variables that you set.
SET DESCRIPTOR Example
EXEC SQL SET DESCRIPTOR dn
COUNT = 10 ;
EXEC SQL SET DESCRIPTOR dn
VALUE 1
TYPE = 5, LENGTH = 20, DATETIME_INTERVAL_CODE = 3, DATETIME_INTERVAL_PRECISION = 4, UPDATABLE =
1, UNNAMED = 1,PARAMETER_TYPE = 1, VERBOSE_TYPE = 5, PRECISION = 10,SCALE = 7, NULLABLE = 1,
SEARCHABLE = 2, UNSIGNED = 1,CASE_SENSITIVE = 1, AUTO_UNIQUE_VALUE = 1, INDICATOR = 0,NULLABLE
= 1, AUTO_UNIQUE_VALUE = 1, NAME = :c1,DATA = :c2, COLLATION_NAME = :c3, CHARACTER_SET_NAME = :c4,
TABLE_NAME = :c5, COLUMN_NAME=:c6, TABLE_NAME = :c7;
12.5 The c-treeSQL Descriptor Area - SQLDA
A c-treeSQL Descriptor Area (SQLDA) is a storage area for descriptive information pertaining to
dynamic SQL statements. An SQLDA can be used while passing parameter values for the
execution of a dynamic SQL statement and while retrieving results of a dynamic SELECT
statement.
Dynamic SELECT statements have to be executed differently since they return information as
compared to non-SELECT statements where the return information is restricted to the SQLCA. A
program executing a dynamic SELECT statement needs to know the lengths and types of values
being returned. Similarly, a program executing a dynamic non-SELECT statement needs to know
the input values that must be supplied to the parameters referenced in the statement. This can be
achieved using the DESCRIBE statement. The DESCRIBE statement obtains information about a
prepared statement. For more information on the DESCRIBE statement, refer to "The DESCRIBE
Statement" (page 127).
The SQLDA can be used to hold information about the input host variables:
That contain input values for a dynamic SELECT/non-SELECT statement. The SQLDA used
for this purpose is an input SQLDA. An input SQLDA can be used in the following statements:
• EXECUTE statement
• OPEN cursor statement corresponding to a dynamic SELECT statement.
Where the values are to be returned by a dynamic SELECT statement. The SQLDA used for
this purpose is an output SQLDA. An output SQLDA can be used in the following statements:
• DESCRIBE statement associated with a dynamic SELECT statement.
• FETCH statement associated with a dynamic SELECT statement.
In esqlc, SQLDA is implemented as a structure. An SQLDA must be explicitly declared before its
usage in the ESQL program.

Dynamic SQL Management in ESQL
All Rights Reserved 119 www.faircom.com
The Components of SQLDA
Structure
struct sqlda {
short sqld_size ;
short sqld_nvars ;
char **sqld_varptrs ;
short *sqld_lengths ;
short *sqld_types ;
short *sqld_precision;
short *sqld_scale ;
short *sqld_flags ;
short **sqld_ivarptrs;
short sqld_varnmsize ;
short sqld_indvarnmsz;
char **sqld_varnames;
char **sqld_indvarnames;
short sqld_arraysz ;
/***For the support of SQL_92 descriptor area*/
short * sqld_date_int_code ;
short * sqld_date_int_prec;
char ** sqld_collat_name ;
char ** sqld_charset_name;
short sqld_max_size;
/*** For the support of ODBC 3.0 interfaces ***/
long * sqld_clengths;
long * sqld_retruned_lengths ;
char ** sqld_base_column_name;
char ** sqld_base_table_name ;
short * sqld_updatable;
short * sqld_searchable;
short * sqld_param_type;
char ** sqld_table_name;
short * sqld_verbose_types;
} ;
/* function for allocating a descriptor area */
extern sqlda *sqld_alloc (size, varnmsize)
short size ;
short varnmsize ;
/* function for freeing a descriptor area */
extern void sqld_free (sqldaptr)
sqlda *sqldaptr ;
Description
The c-treeSQL Descriptor Area (SQLDA) is used in the DESCRIBE statement to hold information
about input host variables and/or to hold information corresponding to returned values of a
dynamic SQL statement.
Fields of the SQLDA
sqld_size

Dynamic SQL Management in ESQL
All Rights Reserved 120 www.faircom.com
Number of entries in the SQLDA. c-treeSQL expects that with OPEN or FETCH statements that
refer to an SQLDA, there will be sqld_size variables and indicator variables.
sqld_nvars
Number of variables found by the DESCRIBE statement.
sqld_varptrs
Array of pointers to host variables. The application sets elements in sqld_varptrs to point to
memory it allocates. While executing the FETCH statement, c-treeSQL assumes that sqld_varptrs
[i] points to a buffer of size (sqld_lengths [i] * sqld_arraysz).
sqld_lengths
Array of lengths of host variables or retrieved data.
sqld_types
Array containing the data types of host variables or retrieved data.
sqld_precision
Array containing the precision for applicable data types.
sqld_scale
Array containing the scale for applicable data types.
sqld_flags
Array containing a code that specifies whether a column accepts null values. A value of [1] (true)
indicates the column accepts null values, [0] (false) indicates it does not, and [2] indicates
unknown.
sqld_ivarptrs
Array of pointers to indicator variables. The application sets elements in sqld_ivarptrs to point to
memory it allocates. c-treeSQL assumes that sqld_ivarptrs [i], if not a null pointer, points to a
buffer of size (sizeof (short) * sqld_arraysz).
sqld_varnmsize
Maximum size of variable names.
sqld_indvarnmsz
Maximum size of indicator variable names. Not currently used.
sqld_varnames
Array of pointers to host variable names.
sqld_indvarnames
Array of pointers to indicator variable names. Not currently used.
sqld_arraysz
Size of arrays allocated by application. If multiple tuples are to be fetched in single FETCH
statement execution, then application must set the field sqld_arraysz accordingly.
sqld_date_int_code
Dynamic SQL Management in ESQL
All Rights Reserved 121 www.faircom.com
Code for Datetime/interval subtypes(SQL92 ODBC)
sqld_date_int_prec
Precision for Datetime/interval subtypes(SQL92 ODBC)
sqld_collat_name
Array of Collation name of column’s collation(SQL92)
sqld_charset_name
Array of Collation name for column’s char. set(SQL92)
sqld_max_size
Size of SQLDA in number of entries while allocating the descriptor
sqld_clengths
Character length for strings
sqld_retruned_lengths
Length retruned by dBMS
sqld_base_column_name
Base column name (ODBC)
sqld_base_table_name
Base table name (ODBC)
sqld_catalog_name
Base table catalog name(ODBC)
sqld_schema_name
Base table schema name(ODBC)
sqld_searchable
Whether column is searchable(ODBC)
sqld_updatable
Whether column is updatable(ODBC)
sqld_param_type
Parameter type
sqld_verbose_types
Parameter type
sqld_table_name
Table/View name

Dynamic SQL Management in ESQL
All Rights Reserved 122 www.faircom.com
Notes
An SQLDA structure should always be allocated by calling the function sqld_alloc() rather
than declaring it statically. The sqld_alloc() function takes a size argument that specifies the
maximum number of variables for which the structure should be allocated.
An SQLDA structure can be reused as long as the two dynamic SQL statements using the
descriptor area are not active simultaneously and the maximum SQLDA size required is the
same for both the c-treeSQL statements.
An SQLDA structure should be freed by calling the sqld_free() routine that takes a pointer to
the SQLDA structure.
The esqlc application must allocate memory for holding the data values returned by the
c-treeSQL statement and for holding the indicator variables. The application sets the
elements of the pointer arrays sqld_varptrs and sqld_ivarptrs appropriately.
If multiple tuples are to be fetched in a single FETCH statement execution, then the
application must set the field sqld_arraysz accordingly. While executing the FETCH
statement, it is assumed that sqld_varptrs [i] points to a buffer of size (sqld_lengths [i] *
sqld_arraysz). It is also assumed that sqld_ivarptrs [i], if not a null pointer, points to a buffer of
size (sizeof (short) * sqld_arraysz).

Dynamic SQL Management in ESQL
All Rights Reserved 123 www.faircom.com
The following figure shows the structure of SQLDA. Note that only the relevant fields are shown.
Also note that the field sqld_varnames would be a null pointer if the second argument to the API
call sqld_alloc() is 0.
Figure 1: SQLDA Structure
Allocating an SQLDA
The SQLDA structure should be allocated by calling the function sqld_alloc() (not by declaring it
statically). A pointer to SQLDA must be declared. The following is a valid declaration:
struct sqlda *sqldaptr ;
...
sqldaptr = sqld_alloc (...) ;
...
The following example shows an invalid declaration of the SQLDA structure:
struct sqlda sqlda1 ; /* not correct */
Dynamic SQL Management in ESQL
All Rights Reserved 124 www.faircom.com
The sqld_alloc() function takes a size argument that specifies the maximum number of variables
for which the structure should be allocated. The syntax for the function sqld_alloc() is:
#include "sqlda.h"
struct sqlda *sqld_alloc (size, varnmsz)
short size ;
short varnmsz ;
The sqld_alloc() function allocates an SQLDA from heap. size specifies the maximum number of
variables for which SQLDA would be allocated. varnmsz is the maximum number of characters
for the name of the column in the result table corresponding to the SQL statement.
If names of the columns in the result table are not of interest, zero can be passed for varnmsz.
The following example shows the allocation of the SQLDA.
Allocating an SQLDA Example
...
#define MAXVARS 20
#define MAXVARNAMELEN 20
/* declare the pointer to SQLDA */
struct sqlda *sqldaptr = (struct sqlda *)0 ;
...
if (!(sqldaptr = sqld_alloc (MAXVARS,
MAXVARNAMELEN)))
{
fprintf (stderr, "sqld_alloc returned error\n") ;
exit (1) ;
}
...
Note
The sqld_alloc() function does not allocate for the data buffers and the indicator variable buffers.
Allocation for data buffers and indicator variables must be done by the application separately and
the pointers to these data buffers and indicator variables must be set in the SQLDA.
Setting the SQLDA Types and Lengths
As discussed earlier, SQLDA can be used for both input host variables as well as output host
variables. These variables are used to hold the values that are not known beforehand.
When an SQLDA is used to supply values to input host variables referenced in a dynamic
non-SELECT statement, it is necessary to set the type and length of the values in the SQLDA.
The SQLDA components sqld_lengths and sqld_types must be set appropriately.
In the case of dynamic SELECT statements, a DESCRIBE call can be issued to obtain the types
and lengths of the values returned by a SELECT statement.

Dynamic SQL Management in ESQL
All Rights Reserved 125 www.faircom.com
Allocating for SQLDA Data Buffers and Indicator Variables
The sqld_alloc() function does not allocate space for data buffers and indicator variable buffers.
These allocations should be done by the application program and the pointers in SQLDA must be
set to point to these allocations.
The program must set the SQLDA components sqld_lengths and sqld_types before the it
allocates the data buffers and indicator variable buffers.
The following example shows the allocation of data buffers and indicator variable buffers, and
setting SQLDA elements to point to the allocations:
SQLDA Setup Example
...
/*
* Allocate for sqld_varptrs and sqld_ivarptrs and
* set these pointers to point to the allocation.
*/
for (colindex = 0 ;
colindex < sqldaptr->sqld_size ; colindex++)
{
if (!( sqldaptr->sqld_varptrs [colindex] =
(char *) calloc (
sqldaptr->sqld_lengths [colindex],
sizeof (char) ))
|| ! ( sqldaptr->sqld_ivarptrs [colindex] =
(short *) calloc (
sizeof (short),
sizeof (char) )))
{
fprintf (stderr, "No memory !\n") ;
exit (1) ;
}
}
...
Using SQLDA for Array Fetches
As mentioned in "Query Statements" (page 85), esqlc supports multiple-row fetch statements
through the use of explicitly-declared esqlc arrays. Programs can use the same technique using
the SQLDA and dynamically-allocated arrays.
When more than one row is to be fetched in one execution of the FETCH statement, the SQLDA
component, sqld_arraysz must be set to the maximum number of rows that could be fetched. The
allocation done for the data buffers and indicator variable buffers should be of appropriate size
such that the buffers can hold the values retrieved by the query statement. Hence when an array
fetch is done using SQLDA, care must be taken to set the SQLDA components, sqld_varptrs and
sqld_ivarptrs, to the correct size.
The following example shows the allocation done for sqld_varptrs and sqld_ivarptrs for array
fetches.

Dynamic SQL Management in ESQL
All Rights Reserved 126 www.faircom.com
Array Fetch Example
...
short arraysz = 10 ; /* array size for array fetches */
/* set the array size in sqlda */
sqldaptr->sqld_arraysz = arraysz ;
/*
* Allocate for sqld_varptrs and sqld_ivarptrs and
* set these pointers to point to the allocation.
*/
for (colindex = 0 ;
colindex < sqldaptr->sqld_size ; colindex++)
{
if (!( sqldaptr->sqld_varptrs [colindex] =
(char *) calloc (
sqldaptr->sqld_lengths [colindex] * arraysz,
sizeof (char) ))
|| !(sqldaptr->sqld_ivarptrs [colindex] =
(short *) calloc (
sizeof (short) * arraysz,
sizeof (char) )))
{
fprintf (stderr, "No memory !\n") ;
exit (1) ;
}
}
...
Here, sqld_varptrs [colindex] points to a buffer of size (sqld_lengths [colindex] * sqld_arraysz).
Also, sqld_ivarptrs [colindex], if not a null pointer, points to a buffer of size (sizeof (short) *
sqld_arraysz).
Freeing an SQLDA
A previously allocated SQLDA can be freed using the sqld_free() function call.
The syntax for the sqld_free() function is:
#include "sqlda.h"
void sqld_free (sqldaptr)
struct sqlda *sqldaptr ;
The following sample code shows the freeing of SQLDA:
sqld_free (sqldaptr) ;
The allocations made for the data buffers and the indicator variable buffers should be freed
before calling the sqld_free() function.
Note: Passing an invalid argument to sqld_free() or freeing an already-freed SQLDA generates unpredictable results. One possible result is a fatal error.

Dynamic SQL Management in ESQL
All Rights Reserved 127 www.faircom.com
The DESCRIBE Statement
The DESCRIBE statement is used to obtain information about a prepared statement. This is an
executable statement that can only be embedded in an ESQL program and cannot be
dynamically prepared. The DESCRIBE statement can be used to describe input host variables as
well as output host variables. For more information on the DESCRIBE statement, see
"DESCRIBE" (page 156). The DESCRIBE statement has the following format:
EXEC SQL
DESCRIBE BIND VARIABLES FOR statement_name
INTO input_sqlda_name;
EXEC SQL
DESCRIBE SELECT LIST FOR statement_name
INTO output_sqlda_name;
The DESCRIBE BIND statement should be executed after the c-treeSQL statement has been
prepared and before the OPEN statement has been executed for the cursor. The input SQLDA
should be specified in the OPEN cursor statement with the USING DESCRIPTOR clause as shown:
EXEC SQL
OPEN cursor_name USING DESCRIPTOR input_sqlda_name ;
A sample DESCRIBE statement that gets information from a prepared c-treeSQL statement into
an SQLDA is shown in the following example:
DESCRIBE Statement Example
...
EXEC SQL BEGIN DECLARE SECTION ;
CHAR stmt_str [256] ;
EXEC SQL END DECLARE SECTION ;
struct sqlda *sqldaptr ;
...
EXEC SQL
PREPARE sel_stmt FROM :stmt_str ;
EXEC SQL
DECLARE sel_cur CURSOR FOR sel_stmt ;
EXEC SQL
OPEN sel_cur ;
/* Allocate for SQLDA */
if (!(sqldaptr = sqld_alloc (20, 30)))
{
fprintf (stderr, "No memory !\n") ;
exit (1) ;
}
EXEC SQL
DESCRIBE SELECT LIST FOR sel_stmt INTO sqldaptr ;
...

Dynamic SQL Management in ESQL
All Rights Reserved 128 www.faircom.com
Here sel_stmt is a prepared statement obtained from the PREPARE statement. When the
DESCRIBE statement is executed, values are assigned to the variables in the SQLDA as follows:
sqld_nvars would contain the number of outputs returned.
• If the size of the SQLDA passed is not enough to return information about all the result
columns of the SELECT statement, the value of sqld_nvars would be negative. In this
case, the absolute value of sqld_nvars gives the actual number of result columns of
SELECT statement. The application can use this to deallocate the SQLDA, allocate a new
SQLDA for the required size, and then execute the DESCRIBE statement again.
sqld_types would contain the data types of each column specified in the SELECT list.
sqld_lengths would contain the lengths of each column depending on the data type of the
column.
Using SQLDA for Input Variables
The input SQLDA is used to store the values for input host variables used in evaluating the
c-treeSQL statement. The DESCRIBE BIND statement is used for input SQLDA and the syntax is:
EXEC SQL DESCRIBE BIND VARIABLES FOR statement_name
INTO input_sqlda_name ;
The DESCRIBE BIND statement must appear after the PREPARE statement and before the OPEN
statement.
The following example shows the usage of DESCRIBE BIND statement to get the number of input
host variable references in an c-treeSQL statement.
DESCRIBE BIND: Using the SQLDA for Input Variables Example
...
struct sqlda *isqlda ;
EXEC SQL BEGIN DECLARE SECTION ;
char stmt_str [100] ;
EXEC SQL END DECLARE SECTION ;
strcpy (stmt_str,
"insert into dept (deptno, dname, loc) values (:p1, :p2, :p3)") ;
EXEC SQL
PREPARE ins_stmt FROM :stmt_str ;
EXEC SQL
DECLARE ins_cur CURSOR FOR ins_stmt ;
/* Allocate for SQLDA */
if (!(isqlda = sqld_alloc (20, 0)))
{
fprintf (stderr, "No memory !\n") ;
exit (1) ;
}
/* Call DESCRIBE to get number of host variable references */
EXEC SQL
DESCRIBE BIND VARIABLES FOR ins_stmt INTO isqlda ;

Dynamic SQL Management in ESQL
All Rights Reserved 129 www.faircom.com
nvars = isqlda->sqld_nvars ;
if (nvars < 0) nvars = -nvars ;
/* Free SQLDA */
sqld_free (isqlda) ;
/* Allocate SQLDA for exact number of host variable references */
if (!(isqlda = sqld_alloc (nvars, 0)))
{
fprintf (stderr, "No memory !\n") ;
exit (1) ;
}
EXEC SQL
OPEN ins_cur USING DESCRIPTOR isqlda ;
...
In the previous example, SQLDA is first allocated for 20. After the DESCRIBE is done on the
prepared statement, the SQLDA is once again allocated for the exact number of host variable
references. It can be noted that the second argument for sqld_alloc is zero while allocating for
input SQLDA.
Using SQLDA for Output Variables
For a dynamic SQL query, a DESCRIBE statement is required to associate items in the SELECT
list with an output SQLDA. The DESCRIBE SELECT statement is used for the output SQLDA and
the syntax is as shown:
EXEC SQL DESCRIBE SELECT LIST FOR statement_name
INTO output_sqlda_name ;
The DESCRIBE SELECT must occur after PREPARE, DESCRIBE BIND and OPEN statements, and
before the FETCH statement.
The following example shows the usage of DESCRIBE SELECT statement
DESCRIBE SELECT: Using the SQLDA for Select List Items Example
struct sqlda *osqlda = (struct sqlda *)0 ;
strcpy (stmt,
"select qty, product from orders where order_no < :p1") ;
EXEC SQL PREPARE stmtid FROM :stmt ;
EXEC SQL DECLARE dyncur CURSOR FOR stmtid ;
for (order_no_v = 1002 ; order_no_v <= 1004 ; order_no_v++)
{
EXEC SQL OPEN dyncur USING :order_no_v ;
/* maxvars = 2, varnmsz = 20 */
if (!(osqlda = sqld_alloc (2, 20)))
{
fprintf (stderr, "sqld_alloc returned err\n") ;
goto err ;

Dynamic SQL Management in ESQL
All Rights Reserved 130 www.faircom.com
}
for (;;)
{
short nvars ;
EXEC SQL DESCRIBE SELECT LIST FOR stmtid INTO osqlda ;
if ((nvars = osqlda->sqld_nvars) < 0)
{
sqld_free (osqlda) ;
if (!(osqlda = sqld_alloc (-(nvars), 20)))
{
fprintf (stderr,
"sqld_alloc returned err\n") ;
goto err ;
}
continue ;
}
break ;
}
}
In the previous example, the SQLDA is allocated again because, if the size (first argument)
provided in the sqld_alloc() function is not enough, then the SQLDA component, sqld_nvars
would contain a negative number equal to the negative of the actual number of outputs found.

All Rights Reserved 131 www.faircom.com
13. Transaction Management in ESQL
13.1 Introduction
This chapter describes the transaction management in ESQL and explains:
Starting and ending a transaction
Using transaction isolation levels
Locking in transactions.
13.2 Transaction Overview
A transaction is a sequence of operations on the database that has the properties of being atomic
and durable. Atomicity refers to the property that either all the operations in a transaction are
done (if the transaction is committed) or none are done (if the transaction is rolled back).
Durability refers to the property that once a transaction is committed, the changes done by the
transaction are permanent.
Any executable statement is executed as part of a transaction. In an ESQL program, when a
statement is executed, if there already exists an active transaction for that ESQL program, this
statement would execute as part of that transaction. If an active transaction does not exist, the
execution of the c-treeSQL statement would start a new transaction. This transaction would be
the active transaction for that ESQL program. All subsequent c-treeSQL statements would
execute as part of this transaction until the application ends the transaction by explicitly
committing or rolling back the transaction.
Starting a Transaction
A transaction is implicitly started by the first executable c-treeSQL statement in an ESQL
program.
...
EXEC SQL
CONNECT TO DEFAULT ;
/* Create table, customer, in the database.
* Since this is the first executable statement
* a new transaction is started implicitly.
*/
EXEC SQL
CREATE TABLE customer (
CUST_NO INTEGER NOT NULL,
name CHAR (30),

Transaction Management in ESQL
All Rights Reserved 132 www.faircom.com
street CHAR (30),
city CHAR (20),
state CHAR (2)
) ;
/* Insert values in the customer table */
EXEC SQL
INSERT INTO customer
(CUST_NO, name, street, city, state)
VALUES
(:cust_no_v, :name_v, :street_v, :city_v, :state_v) ;
EXEC SQL
COMMIT WORK ;
EXEC SQL
DISCONNECT DEFAULT ;
...
In the above example, the execution of the CREATE TABLE statement starts a new transaction.
The execution of the INSERT statement would not start a new transaction since an active
transaction already exists (the one started by the execution of the CREATE TABLE statement).
Note: Declarative statements do not start a transaction.
The COMMIT WORK Statement
A transaction can be successfully terminated in an application using the COMMIT WORK statement.
When a COMMIT WORK statement is executed, all the changes made to the database by the
transaction are made permanent.
Depending on the isolation level of the transaction, changes made by one transaction may or may
not be visible to other transactions before the transaction is committed. The default behavior is
that database changes made by one transaction are not visible to any other transaction until and
unless the transaction is committed.
Once committed, changes made to the database are guaranteed never to be canceled. The
following example shows the usage of the COMMIT WORK statement:
/* End Transaction */
EXEC SQL COMMIT WORK ;
The COMMIT WORK statement has no effect on the contents of the host variables or on the control
flow of the ESQL program.
The following example shows conditionally executing a COMMIT WORK statement based on the
result of the sqlcode in the SQLCA.
COMMIT WORK Statement Example
< Code for connecting to the database >
EXEC SQL INSERT INTO customer (cust_no, name)
VALUES (:cust_no, :name) ;
if (sqlca.sqlcode)
end_prog () ;

Transaction Management in ESQL
All Rights Reserved 133 www.faircom.com
<perform input/output to the user>
EXEC SQL INSERT INTO orders (order_no, cust_no)
VALUES (:order_no, :cust_no) ;
if (sqlca.sqlcode)
end_prog () ;
EXEC SQL COMMIT WORK ;
The ROLLBACK WORK Statement
The ROLLBACK WORK statement undoes all the changes made to the database within a
transaction. The following example shows the usage of the ROLLBACK WORK statement:
/* Undo transaction changes */
EXEC SQL ROLLBACK WORK ;
The ROLLBACK WORK statement has no effect on the contents of the host variables or the control
flow of the ESQL program.
c-treeSQL automatically executes a rollback operation when there is an abnormal termination of
an application program. c-treeSQL closes all cursors opened within the transaction and releases
all locks held by the transaction.
Usually, the ROLLBACK WORK statement is used in exception handlers.
The following example illustrates conditionally executing a ROLLBACK WORK statement based on
the result of the sqlcode in the SQLCA.
ROLLBACK WORK Statement Example
EXEC SQL BEGIN DECLARE SECTION ;
long cust_no ;
EXEC SQL END DECLARE SECTION ;
void drop_customer ()
{
EXEC SQL
DELETE
FROM customer
WHERE cust_no = :cust_no ;
if (sqlca.sqlcode) {
status = sqlca.sqlcode ;
/* roll back the transaction */
EXEC SQL ROLLBACK WORK ;
return ;
}
EXEC SQL
DELETE
FROM orders
WHERE cust_no = :cust_no ;
if (sqlca.sqlcode) {
status = sqlca.sqlcode ;
/* roll back the transaction */
EXEC SQL ROLLBACK WORK ;
return ;
}

Transaction Management in ESQL
All Rights Reserved 134 www.faircom.com
status = STATUS_OK;
EXEC SQL COMMIT WORK ;
return ;
}
...
Transaction Isolation Levels
The degree to which one transaction can interfere with other transactions by accessing the same
rows concurrently can be specified by setting the transaction isolation level in the ESQL program.
The syntax for SET TRANSACTION ISOLATION LEVEL statement is:
SET TRANSACTION ISOLATION LEVEL { 0 | 1 | 2 | 3 };
The SET TRANSACTION ISOLATION LEVEL statement is used to set the isolation level explicitly
in an ESQL program.
The scope of the isolation level set is the current transaction. The isolation_level is specified as
an integer with the value being 0, 1, 2, or 3.
The following table shows how the isolation level integers correspond to ANSI/ISO standard
isolation level keywords.
Number Isolation Level
0 UNCOMMITTED READ
1 COMMITTED READ
2 REPEATABLE READ
3 SERIALIZABLE
The isolation level SERIALIZABLE guarantees the highest consistency and is the default. The
isolation level READ UNCOMMITTED guarantees the least consistency. For details of the
definitions of the different isolation levels, see the SET TRANSACTION ISOLATION LEVEL
statement in the c-treeSQL Reference Manual.
Note: c-treeSQL only supports transaction isolation levels 1 (COMMITTED READ) and 2
(REPEATABLE READ).
The following example executes a query in the COMMITTED READ isolation level.
Setting Transaction Isolation Level Example
...
EXEC SQL CONNECT TO DEFAULT ;
EXEC SQL WHENEVER SQLERROR GOTO do_rollback ;
EXEC SQL SET TRANSACTION ISOLATION LEVEL 0 ;
EXEC SQL
SELECT name, city

Transaction Management in ESQL
All Rights Reserved 135 www.faircom.com
INTO :cust_no_v, :name_v
FROM customer
WHERE CUST_NO = 1024 ;
...
EXEC SQL COMMIT WORK ;
EXEC SQL DISCONNECT DEFAULT ;
exit (0) ;
do_rollback:
if (sqlca.sqlcode)
{
strncpy (errmesg, sqlca.sqlerrm, sqlca.sqlerrml);
errmesg [sqlca.sqlerrml] = '\0' ;
fprintf (stderr, "Error : %s\n", errmesg);
}
EXEC SQL WHENEVER SQLERROR CONTINUE ;
EXEC SQL ROLLBACK WORK ;
EXEC SQL DISCONNECT DEFAULT ;
exit (1) ;
...
Locking and Transactions
During the execution of an ESQL program, transactions implicitly lock tables in a database. This
is done so that the data in the database remains consistent. The implicit locks are released by
committing the transaction or by disconnecting from the database.
c-treeSQL supports two types of implicit locks:
SHARE locks are acquired on rows that have been read by a transaction. A SHARE lock allows
other transactions to read the row but prevents others from modifying the row until this
transaction either commits or performs a rollback.
EXCLUSIVE locks are acquired on rows that have been modified by a transaction.
EXCLUSIVE locks prevent other transactions from either reading or modifying the rows until
this transaction either commits or performs a rollback.
In applications where a large number of rows will be accessed for either reading or modifying,
ESQL provides an explicit locking construct for locking all the rows of a table. The LOCK TABLE
statement explicitly locks a table in either SHARE or EXCLUSIVE mode. The following example
shows acquiring a lock in the EXCLUSIVE mode for a table called customer:
EXEC SQL
LOCK TABLE customer IN EXCLUSIVE MODE;
The above statement will prevent other transactions from either reading or modifying the table
customer until the transaction either commits or performs a rollback.
The following example shows acquiring lock in the SHARE mode for a table called orders:
EXEC SQL
LOCK TABLE orders IN SHARE MODE;

Transaction Management in ESQL
All Rights Reserved 136 www.faircom.com
The above statement will prevent other transactions from modifying the orders table until the
transaction either commits or performs a rollback.
Explicit locking can be used to improve the performance of a single transaction at the cost of
decreasing the concurrency of the system and potentially blocking other transactions. The
increased performance comes from reducing the overhead imposed by the implicit locking
mechanism, along with eliminating any potential waits for acquiring row level locks for the table.
Abnormal Termination of an ESQL Application Program
If an active transaction exists when an ESQL application disconnects from a database, then the
transaction is rolled back automatically. The behavior is similar when an ESQL application
terminates abnormally. In this case, disconnecting from the database is also automatic.
Forced Rollback of a Transaction
As mentioned in the previous section, a forced rollback of the transaction, if an active transaction
exists, is done when an ESQL program disconnects or makes an abnormal exit. This forced
rollback is performed to keep the database consistent.
When some serious errors occur, a transaction might be implicitly marked for rollback. This can
be detected by the information in the SQLCA. If a transaction is marked for rollback, no
c-treeSQL statement can be executed on behalf of that transaction. In such a case, the
application must rollback the current transaction before proceeding with execution of the next
c-treeSQL statement.
Interrupting the Execution of an SQL Statement
An interruption to the database could be issued during the execution of an c-treeSQL statement.
When an interruption occurs, the statement that is getting executed fails and an error code is
returned in the SQLCA. The changes made by this particular statement are rolled back and the
database gets back to the state that it was before execution of the c-treeSQL statement.
Consider the following example:
...
EXEC SQL CONNECT TO DEFAULT ;
...
EXEC SQL
INSERT INTO orders
VALUES (:no_v, :date_v, :prod_v, :qty_v) ;
/*
* If the following statement execution is
* interrupted, any database modifications that
* might have been done by the UPDATE statement up to
* the point of interruption are undone. But all
* database modifications done by the
* application on behalf of this transaction up
* to the previous statement are not undone.
*
*/
EXEC SQL
UPDATE orders

Transaction Management in ESQL
All Rights Reserved 137 www.faircom.com
SET product = :prod_x
WHERE order_date > :ord_date ;
/* End Transaction */
EXEC SQL COMMIT WORK ;
EXEC SQL DISCONNECT DEFAULT ;
...
In the sequence of operations shown above, if the interruption occurs during the execution of the
UPDATE statement, then the UPDATE statement returns an error and all the changes made by the
UPDATE statement are undone. But the changes done by the INSERT statement are retained. If
the statement execution proceeds to the COMMIT WORK statement, then only the INSERT
operation is made permanent.

All Rights Reserved 138 www.faircom.com
14. Data Type Handling in ESQL
14.1 Introduction
This chapter describes the data types that can be used in an ESQL application program. It also
discusses the converting and comparing data of different types.
The database types allowed in c-treeSQL have two representations:
A database storage representation
A host language representation
The database storage representation refers to the way a value is stored in the database and the
host language representation refers to the way a value is represented in the host language (C
language). Necessary data conversions from one form to another are taken care of by c-treeSQL
and therefore the application does not have to deal with the database storage representation.
14.2 Data Type Descriptions
This section discusses the different data types supported by c-treeSQL and how they can be
used in ESQL programs as input and output host variables. The material supplements the
description of data types in the c-treeSQL Reference Manual.
CHARACTER Data Type CHARACTER [(length)]
Type CHARACTER (abbreviated as CHAR) corresponds to a null terminated character string with
the maximum length specified. The default length is 1.
The maximum length is 2000.
The c-treeSQL engine representation is a variable length string. The host language
representation is equivalent to the C language character string.
As an input host variable, a literal character string or a host variable declared as a character array
can be used. String constants or literals are enclosed within single/double quotes. In the following
example, the SELECT statement uses both input and output character type host variables:
Example: Using CHAR Data Type
EXEC SQL BEGIN DECLARE SECTION ;
CHAR city_v [19] ;
CHAR name_v [19] ;

Data Type Handling in ESQL
All Rights Reserved 139 www.faircom.com
EXEC SQL END DECLARE SECTION ;
...
EXEC SQL
SELECT city
INTO :city_v
FROM customer
WHERE name = :name_v ;
Here city_v is an output host variable and name_v is an input host variable, both declared as
character arrays in the declare section. The input host variable can also be a character literal as
shown:
WHERE name = 'JOHN' ;
Use scalar functions like SUBSTR, INSTR, LENGTH, LOWER, and UPPER for manipulating
character strings.
VARCHAR [(length)]
Embedded c-treeSQL does not support the VARCHAR type. Use CHARACTER instead.
LVARCHAR | LONG VARCHAR
Refer to "Long Data Type Support" (page 176) for more information.
SMALLINT Data Type
The SMALLINT data type corresponds to an integer value of length two bytes. The database
representation as well as the host language representation is a signed short INTEGER. The range
of values corresponding to a column of this type is -32768 to +32767. The following example
shows the declaration and usage of the SMALLINT data type:
EXEC SQL BEGIN DECLARE SECTION ;
SHORT deptno_v ;
CHAR ename_v [19] ;
EXEC SQL END DECLARE SECTION ;
...
EXEC SQL
SELECT ename, deptno
INTO :ename_v, :deptno_v
FROM employee
WHERE empno = 2828 ;
INTEGER Data Type
The INTEGER data type corresponds to an integer of length 4 bytes. The database representation
as well as host language representation is a long INTEGER. Integer constants must be expressed
in decimal notation without embedded commas and without a decimal point. The INTEGER data
may be preceded with an optional plus or minus sign. The range of values for a column of this
type is -2147483648 to +2147483647. The following example shows the usage of the INTEGER
data type:

Data Type Handling in ESQL
All Rights Reserved 140 www.faircom.com
EXEC SQL BEGIN DECLARE SECTION ;
LONG qty_v ;
EXEC SQL END DECLARE SECTION ;
EXEC SQL
SELECT qty
INTO :qty_v
FROM orders
WHERE order_no = 1002 ;
BIGINT
The BIGINT data type corresponds to an integer of length 8 bytes. The range of values for
BIGINT columns is -2 ** 63 to 2 ** 63 -1. Both the c-treeSQL engine representation and the host
language representation are equivalent to the following C structure:
typedef struct {
long ll ;
long hl ;
} tpe_bigint_t ;
REAL Data Type
The REAL data type corresponds to a single precision floating point number. The database
representation and the host language representation are the same as the C language float type.
The following example shows the usage of the REAL data type:
EXEC SQL BEGIN DECLARE SECTION ;
FLOAT val ;
EXEC SQL END DECLARE SECTION ;
EXEC SQL
SELECT 120.00 + 100.50
INTO :val
FROM syscalctable ;
FLOAT Data Type
The FLOAT data type corresponds to a double precision floating point number. The database
representation and the host language representation are the same as the C language double
type. The following example shows the usage of the FLOAT data type:
EXEC SQL BEGIN DECLARE SECTION ;
DOUBLE salary_v ;
CHAR ename_v [19] ;
EXEC SQL END DECLARE SECTION ;
EXEC SQL
SELECT ename, salary
INTO :ename_v, :salary_v
FROM employee
WHERE empno = 2040 ;

Data Type Handling in ESQL
All Rights Reserved 141 www.faircom.com
DOUBLE PRECISION
The DOUBLE PRECISION data type corresponds to a double precision floating point number
equivalent to the C language double type. Both the c-treeSQL engine representation and the host
language representation are equivalent to the C language double type.
V11 and later releases support DOUBLE as an alias for DOUBLE PRECISION.
NUMERIC or DECIMAL Data Type
Type NUMERIC corresponds to a number with the given precision (maximum number of digits)
and scale (the number of digits to the right of the decimal point). By default, NUMERIC columns
have a precision of 32 and scale of 0.
In c-treeSQL, the format for specifying a NUMERIC column is as follows:
{ NUMERIC | NUMBER | DECIMAL } [ ( precision [ , scale ] ) ]
See the c-treeSQL Reference Manual for details on storing NUMERIC values using c-treeSQL.
Internally, c-treeSQL uses the tpe_num_t structure to store and return values of NUMERIC type.
Host programs can access tpe_num_t to directly store and retrieve NUMERIC values, as
discussed in the rest of this section. However, programs can avoid the complexities of dealing
with the NUMERIC storage format directly by using the tpe_conv_data() function or c-treeSQL
scalar conversion functions.
Internal Storage Format for NUMERIC Data
The tpe_num_t structure is as follows:
typedef struct {
short dec_num ;
char dec_digits [17] ;
} tpe_num_t ;
dec_num
The dec_num field of the structure contains the number of valid bytes in the dec_digits array.
dec_digits [17]
The dec_digits array contains the actual numeric data, stored in two parts:
The first byte of dec_digits (dec_digits[0]) contains a sign bit and the exponent for the value,
stored in “excess-64” notation.
The second and subsequent valid bytes of dec_digits (dec_digits[1] through
dec_digits[dec_num - 1]) contain base-100 values each representing two digits.
The following figure shows the format for the dec_digits array.

Data Type Handling in ESQL
All Rights Reserved 142 www.faircom.com
Figure: Format for NUMERIC Data Stored in the tpe_num_t Structure
The following section describes in detail how to interpret data in the dec_digits array.
Interpreting the Sign/Exponent Byte of dec_digits
The high-order bit of dec_digits[0] specifies the sign of the NUMERIC data: 1 means positive and 0
means negative.
The 7 lower-order bits of dec_digits[0] contain the exponent, stored in excess 64 notation. In
excess-64 notation, you subtract 64 from the stored value to determine the actual value.
For dec_digits[0], this means you subtract 64 from the value stored in the 7 lower-order bits to
determine the value of the exponent. However, if the sign bit of dec_digits[0] is 0 (indicating a
negative value), you must first perform a one’s complement of the 7 lower-order bits before
subtracting 64. (To perform a one’s complement, swap zeroes with ones and ones with zeroes.)
The following example shows how to determine the sign of the NUMERIC data and the value of its
exponent when dec_digits[0] contains a base-10 value of 223.
Example: Determining Sign and Exponent of NUMERIC Values
Decimal value in dec_digits[0] 223
Binary equivalent 11011111
Sign bit 1 (Positive)
One’s complement of exponent bits Not necessary, since sign bit is positive
Binary value of exponent bits (excess-64 notation) 1011111
Decimal value of exponent bits (excess-64 notation) 95
Actual value of exponent 95 -64 = 31
The following example shows another example of dec_digits[0], containing the base-10 value of
100, which represents a negative data value and a negative exponent value.
Example: Determining Sign and Exponent of NUMERIC Values
Decimal value in dec_digits[0] 100
Binary equivalent 01100100
Sign bit 0 (Negative)
One’s complement of exponent bits 0011011
Binary value of exponent bits (excess-64 notation) 0011011

Data Type Handling in ESQL
All Rights Reserved 143 www.faircom.com
Decimal value of exponent bits (excess-64 notation) 27
Actual value of exponent 27 - 64 + -37
Interpreting the Data Values Bytes of dec_digits
The rest of the bytes in the dec_digits array contain the base-100 digits of the NUMERIC data, two
digits in each byte. To extract the values from each data byte:
1. Convert the binary value to decimal.
2. If the sign bit indicated a negative number:
• Perform a 99’s complement on the value (subtract the value from 99) for all but the last
data value in the dec_digits array (dec_digits[1] to dec_digits[dec_num-2]).
• Perform a 100’s complement on the value (subtract the value from 100) for the last data
value in the f array (dec_digits[dec_num-1]). If the sign bit indicated a negative number,
perform a 100’s complement on the value (subtract the value from 100).
The resulting base-100 digits represent a number between 0 and 1. Multiply that result by 100
raised to the value of the exponent to get the final NUMERIC value.
Complete Examples: Interpreting Sign/Exponent and Data Bytes of dec_digits
The following examples detail how to extract base-10 values from dec_digits. Use them as a
guide for interpreting values returned by c-treeSQL in tpe_num_t or to store values in the
database using tpe_num_t.
Example: Interpreting NUMERIC Storage: Positive Exponent and Data
This example shows how the (base-10) value 123456 is stored in dec_digits.
11000011 1101 100011 111001
dec_digits[0] dec_digits[1] dec_digits[2] dec_digits[3]
Sign/Exponent Byte
Binary value in desc_digits[0] 11000011
Sign bit 1 (Positive)
One’s complement of exponent bits Not necessary, since sign bit is positive
Binary value of exponent bits (excess-64 notation) 1000011
Decimal value of exponent bits (excess-64 notation) 67
Actual value of exponent 67 - 64 = 3

Data Type Handling in ESQL
All Rights Reserved 144 www.faircom.com
Data Value Bytes 1 2 3
Binary value 1100 100010 111000
Decimal equivalent 12 34 56
99’s complement of all but last value N/A N/A N/A
100’s complement of all but last value N/A N/A N/A
Base-100 digits 12 34 56
The resulting numeric value is 0.123456 x 1003, or 123456.
Example: Interpreting NUMERIC Storage: Negative Exponent and Data
This example shows how the (base-10) value -123456.789 is stored in dec_digits.
00111100 01010111 01000001 00101011 00010101 00001010
dec_digits[0] dec_digits[1] dec_digits[2] dec_digits[3] dec_digits[4] dec_digits[5]
Sign/Exponent Byte
Binary value in desc_digits[0] 00111100
Sign bit 0 (Negative)
One’s complement of exponent bits 11000011
Binary value of exponent bits (excess-64 notation) 1000011
Decimal value of exponent bits (excess-64 notation) 67
Actual value of exponent 67 - 64 = 3
Data Value Bytes 1 2 3 4 5
Binary value 1010111
1000001 101011 10101 1010
Decimal equivalent 87 65 43 21 10
99’s complement of all but last value 12 34 56 78 N/A
100’s complement of all but last value N/A N/A N/A N/A 90
Base-100 digits 12 34 56 78 90
The resulting numeric value is - 0.1234567890 x 1003, or 123456.789

Data Type Handling in ESQL
All Rights Reserved 145 www.faircom.com
DATE Data Type
The DATE data type corresponds to a DATE value with three parts namely, day-of-month, month
and year. The database representation is a long INTEGER. The host language representation is
equivalent to the following C structure:
typedef struct {
short year ;
unsigned char month ;
unsigned char day ;
} tpe_date_t ;
The range for the year part is 1 to 9999. The range for the month part is 1 to 12. The lower limit
for the day part is 1 and the upper limit depends on the month and the year.
The following example shows the usage of the DATE data type:
EXEC SQL BEGIN DECLARE SECTION ;
DATE date_v ;
EXEC SQL END DECLARE SECTION ;
EXEC SQL
SELECT order_date
INTO :date_v
FROM orders
WHERE CUST_NO = 2002 ;
The DATE data type can also be used in the WHERE clause as shown:
WHERE order_date = :date_v ;
Some of the scalar functions used to manipulate date values are ADD_MONTHS,
MONTHS_BETWEEN, and TO_DATE.
TIME Data Type
The TIME data type corresponds to the time value with four parts: hours, minutes, seconds, and
milliseconds. The database representation is a long integer. The host language representation is
equivalent to the following C structure:
typedef struct {
unsigned char hours ;
unsigned char mins ;
unsigned char secs ;
unsigned short msecs ;
} tpe_time_t ;
The range for the hours part is 0 to 23.
The range for the minutes part is 0 to 59.
The range for the seconds part is 0 to 59.
The range for the milliseconds part is 0 to 999.
The following example shows the usage of TIME data type:

Data Type Handling in ESQL
All Rights Reserved 146 www.faircom.com
EXEC SQL BEGIN DECLARE SECTION ;
TIME time_v ;
EXEC SQL END DECLARE SECTION ;
EXEC SQL
SELECT arrival_time
INTO :time_v
FROM arrivals
WHERE train_no = 230 ;
Some of the scalar functions used to manipulate TIME data are TO_TIME, HOUR, MINUTE,
SECOND, etc.
TIMESTAMP
The TIMESTAMP data type combines the parts of DATE and TIME. The c-treeSQL engine
representation and the host language representation is equivalent to the following C structure:
typedef struct {
tpe_date_t ts_date ;
tpe_time_t ts_time ;
} tpe_timestamp_t ;
BIT
Type BIT corresponds to a single bit value of 0 or 1. The host language representation is
unsigned CHAR.
BINARY [(length)]
The BINARY data type corresponds to a bit field of the specified length of bytes. The default
length is 1 byte. The maximum length is 900 bytes. The host language representation of a BIT
column is equivalent to the following structure:
typedef struct {
long tb_len ;
unsigned char tb_data [TPE_MAX_FLDLEN+1] ;
} tpe_binary_t ;
LVARBINARY | LONG VARBINARY
Refer to "Long Data Type Support" (page 176) for more information.
Data Conversion
This section discusses various methods that ESQL programs can use to convert data from one
type to another:
Implicit conversion through c-treeSQL
Explicit conversion using the c-treeSQL API function tpe_conv_data()
Explicit conversion using c-treeSQL scalar functions

Data Type Handling in ESQL
All Rights Reserved 147 www.faircom.com
Note: For better portability, use implicit conversion or c-treeSQL scalar functions for data type conversion in ESQL programs. Use the c-treeSQL API call tpe_conv()_data for best
performance.
Implicit Data Type Conversion
c-treeSQL performs the required data conversions between data types wherever possible. For
example, while delivering each SELECT list value to the host variables in the INTO clause,
c-treeSQL implicitly converts the data value, if necessary, from the database representation to the
host language representation. If the database column is of type SMALLINT, while retrieving the
value of that column into a host variable of type long, the value is automatically converted from
SMALLINT to long INTEGER type.
Implicit type conversions between all data types are not allowed. For example, using an INTEGER
host variable to hold a character value will generate an error.
The following example shows the implicit conversion of the MONEY data type to DOUBLE data
type.
Using c-treeSQL for Implicit Data Type Conversion
EXEC SQL BEGIN DECLARE SECTION ;
MONEY amount_v ;
DOUBLE double_val ;
EXEC SQL END DECLARE SECTION ;
EXEC SQL
SELECT :amount_v
INTO :double_val
FROM admin.syscalctable ;
Using the SQL API Function tpe_conv_data for Data Type Conversion
Host programs can use the c-treeESQL API call tpe_conv_data() to explicitly convert data from
one type to the desired type.
Unlike implicit type conversion, tpe_conv_data() performs type conversions between character
and NUMERIC types.
Syntax #include "sql_lib.h"
tpe_status_t
tpe_conv_data (dtype, bufl, buf, fmt, odtype, obufl, obuf)
int dtype;
int bufl;
void *buf;
char *fmt;
int odtype;
int obufl;
void *obuf;
Returns
A negative error code on failure and a zero value on success.

Data Type Handling in ESQL
All Rights Reserved 148 www.faircom.com
Parameters
dtype
The data type of the input value in buf. dtype must be one the following data-type symbolic
names specified in #define directives in $TPEROOT/include/sql_lib.h:
TPE_DT_ERR TPE_DT_CHAR TPE_DT_NUMERIC
TPE_DT_SMALLINT_ TPE_DT_INTEGER TPE_DT_SMALLFLOAT
TPE_DT_REAL TPE_DT_FLOAT TPE_DT_DATE
TPE_DT_MONEY TPE_DT_TIME TPE_DT_TIMESTAMP
TPE_DT_TINYINT TPE_DT_BINARY TPE_DT_BIT
TPE_DT_LVC TPE_DT_LVB TPE_DT_BIGINT
bufl
The length of buf.
buf
The buffer containing the input data.
fmt
A format string that specifies the output format. Valid only if dtype is TPE_DT_DATE and odtype
is TPE_DT_CHAR. See the discussion of date-time format strings in the c-treeSQL Reference
Manual for details.
odtype
The data type of the output required after conversion.
obufl
The length of obuf.
obuf
The output buffer that receives the converted data.
The following example shows the conversion from character data to INTEGER data. In the
example, data is the buffer containing input data and outval is the output data returned.
Using tpe_conv_data to Convert Character to Integer Data
EXEC SQL BEGIN DECLARE SECTION ;
CHAR data [20] ;
LONG outval ;
EXEC SQL END DECLARE SECTION ;
strcpy (data, "1234") ;
status = tpe_conv_data (TPE_DT_CHAR, strlen (data), data, "",
TPE_DT_INTEGER, sizeof (long), &outval) ;

Data Type Handling in ESQL
All Rights Reserved 149 www.faircom.com
The following example shows using tpe_conv_data() to convert NUMERIC data retrieved from the
database into character data for use by the host program. In the example, var7 is the buffer
containing input data and var0 is the output data returned.
Using tpe_conv_data to Convert Numeric to Character Data
EXEC SQL BEGIN DECLARE SECTION;
char var0[50];
numeric var7;
EXEC SQL END DECLARE SECTION;
...
EXEC SQL
SELECT fld2
INTO :var7
FROM compt
WHERE fld1='10';
tpe_conv_data(
TPE_DT_NUMERIC,sizeof(tpe_num_t),&var7,
" ",
TPE_DT_CHAR,50,var0);
fprintf(stdout,"var0 = %s\n",var0);
...
Using SQL Scalar Functions for Data Type Conversion
Alternatively, one data value can be converted to another data value of a data type using scalar
functions. The following example shows some of conversions that can be done using scalar
functions.
Using Scalar Functions for Data Type Conversion
EXEC SQL BEGIN DECLARE SECTION ;
NUMERIC num_val ;
DATE date_val ;
EXEC SQL END DECLARE SECTION ;
EXEC SQL
SELECT TO_DATE ('10/10/1992')
INTO :date_val
FROM admin.syscalctable ;
EXEC SQL
SELECT TO_NUMBER ('1234')
INTO :num_val
FROM admin.syscalctable ;
In the first example, the character expression is converted to DATE type using the TO_DATE
scalar function and the result is fetched into date_val. In the second example, the character
expression is converted to the NUMERIC type using the TO_NUMBER scalar function and the result
is fetched into num_val.
Some of the other scalar functions available for conversion are TO_CHAR and TO_TIME.
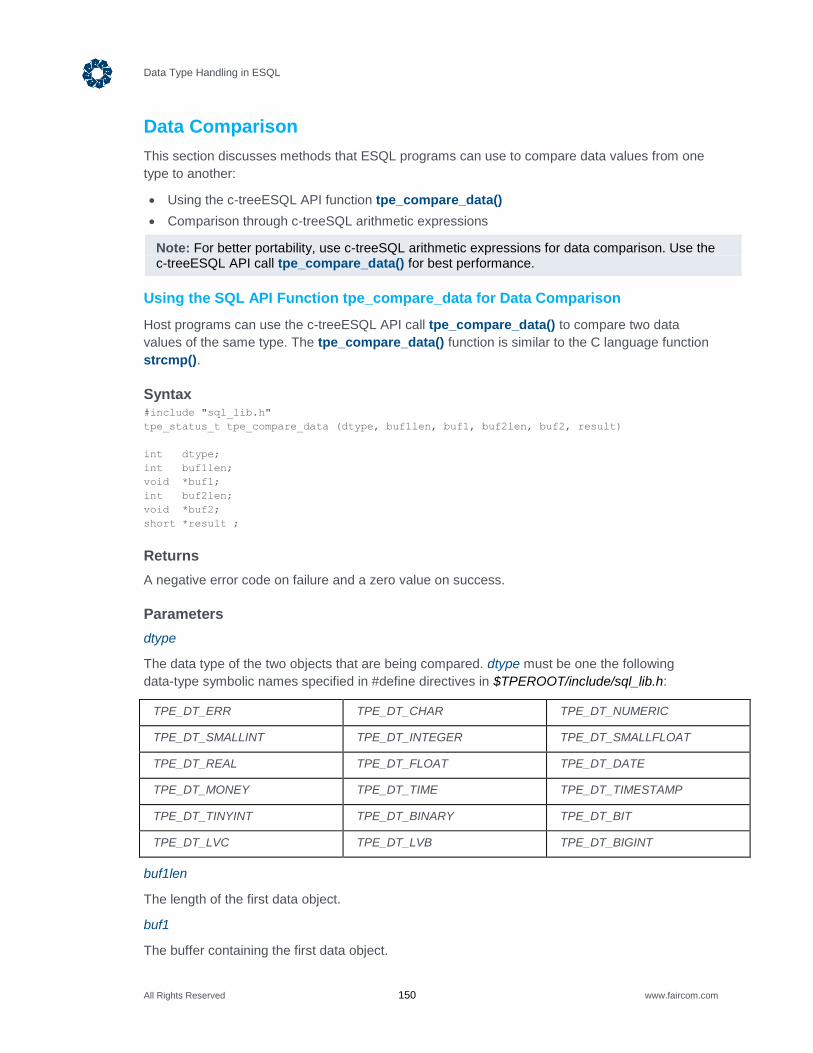
Data Type Handling in ESQL
All Rights Reserved 150 www.faircom.com
Data Comparison
This section discusses methods that ESQL programs can use to compare data values from one
type to another:
Using the c-treeESQL API function tpe_compare_data()
Comparison through c-treeSQL arithmetic expressions
Note: For better portability, use c-treeSQL arithmetic expressions for data comparison. Use the c-treeESQL API call tpe_compare_data() for best performance.
Using the SQL API Function tpe_compare_data for Data Comparison
Host programs can use the c-treeESQL API call tpe_compare_data() to compare two data
values of the same type. The tpe_compare_data() function is similar to the C language function
strcmp().
Syntax #include "sql_lib.h"
tpe_status_t tpe_compare_data (dtype, buf1len, buf1, buf2len, buf2, result)
int dtype;
int buf1len;
void *buf1;
int buf2len;
void *buf2;
short *result ;
Returns
A negative error code on failure and a zero value on success.
Parameters
dtype
The data type of the two objects that are being compared. dtype must be one the following
data-type symbolic names specified in #define directives in $TPEROOT/include/sql_lib.h:
TPE_DT_ERR TPE_DT_CHAR TPE_DT_NUMERIC
TPE_DT_SMALLINT TPE_DT_INTEGER TPE_DT_SMALLFLOAT
TPE_DT_REAL TPE_DT_FLOAT TPE_DT_DATE
TPE_DT_MONEY TPE_DT_TIME TPE_DT_TIMESTAMP
TPE_DT_TINYINT TPE_DT_BINARY TPE_DT_BIT
TPE_DT_LVC TPE_DT_LVB TPE_DT_BIGINT
buf1len
The length of the first data object.
buf1
The buffer containing the first data object.

Data Type Handling in ESQL
All Rights Reserved 151 www.faircom.com
buf2len
The length of the second data object.
buf2
The buffer containing the second data object.
result
Pointer to a location for returning the result. result is a short integer with one of the following
values:
1 First data object is greater than second data object.
-1 First data object is less than second data object.
0 The two data objects are equal.
tpe_compare_data() returns 0 if the comparison is successful, a non zero error code, otherwise.
The following example shows the comparison of two NUMERIC data elements. The examples
compares the values in val1 and val2 while tpe_compare_data() stores the result in result.
Using the tpe_compare_data API Function for Data Comparison
EXEC SQL BEGIN DECLARE SECTION ;
NUMERIC val1 ;
NUMERIC val2 ;
SHORT result ;
EXEC SQL END DECLARE SECTION ;
...
status = tpe_compare_data (TPE_DT_NUMERIC, sizeof (tpe_num_t),
(void *)&val1, sizeof (tpe_num_t), (void *)&val2, &result) ;
if (status == 0)
{
if (result > 0)
printf ("val1 > val2 ") ;
else
if (result < 0)
printf ("val1 < val2 ") ;
else
printf ("val1 = val2 ") ;
}
Using SQL Arithmetic Expressions for Data Comparison
Two data values can be also compared using c-treeSQL arithmetic expressions. The following
example shows using date arithmetic to compare two dates, date1 and date2. c-treeSQL returns
the difference, as the number of days between the two dates, in result.
Using SQL for Data Comparison
EXEC SQL BEGIN DECLARE SECTION ;
DATE date1 ;
DATE date2 ;
SHORT result ;

Data Type Handling in ESQL
All Rights Reserved 152 www.faircom.com
EXEC SQL END DECLARE SECTION ;
...
EXEC SQL
SELECT :date1 - :date2
INTO :result
FROM admin.syscalctable ;
if (sqlca.sqlcode == 0)
{
if (result > 0)
printf ("date1 > date2 ") ;
else
if (result < 0)
printf ("date1 < date2 ") ;
else
printf ("date1 = date2 ") ;
}

All Rights Reserved 153 www.faircom.com
15. ESQL Reference
15.1 Introduction
This chapter contains reference material on c-treeSQL statements specific to ESQL. For
reference information on all other c-treeSQL statements, see the c-treeSQL Reference Manual.
15.2 BEGIN-END DECLARE SECTION
Declares variables and types for use in: Variables referred to in an embedded c-treeSQL
statement must be declared in a BEGIN-END DECLARE SECTION. Variables must be declared as
a host language type or as a type previously declared in a BEGIN-END DECLARE SECTION.
Syntax EXEC SQL BEGIN DECLARE SECTION
variable_or_type_declaration
[...]
EXEC SQL END DECLARE SECTION
variable_or_type_declaration ::
{ host_language_type variable_name [ , … ] ;
| { variable_name [ , … ] | TYPE new_type_name } type_spec ;
}
Arguments
host_language_type variable_name [ , … ] esqlc
A conventional C-language variable declaration. This form of variable declaration conforms to
ANSI standards.
The following host language C types are supported by ESQL:
host_language_type ::
{ [unsigned] char
| [unsigned] short
| [unsigned] long
| float
| double
}
The host language C type int is not supported in ESQL. Type int maps to 16- or 32-bits
depending on the machine architecture. This has the potential of creating rounding errors at
runtime in shipping values in the transaction execution calls across different machine
architectures.
{ variable_name [ , … ] | TYPE new_type_name } type_spec

ESQL Reference
All Rights Reserved 154 www.faircom.com
A variable or type declaration that uses ESQL-specific TYPE syntax. This form of declaration is an
extension to the SQL standard:
The variable_name clause declares one or more variables of the type specified in type_spec.
The TYPE new_type_name clause declares a user-defined type of the type specified in
type_spec. Type declarations inherit all the properties of a host language type or a
previously-declared type. The new type can be used to declare variables or other types in
either ESQL or in the host language.
Notes
Variables can be used in host language statements as if they had been declared directly in
the host language with the same name.
The scope of variables follow host-language scoping rules. ESQL variables are not visible
outside the file in which they are declared.
DECLARE sections are permissible only where host language declarations are permissible in
the host language syntax. This restriction is due to the translation of DECLARE SECTION
blocks into host language declarations.
Avoid DECLARE sections in header files that are included in more than one file. They might
cause creation of duplicate variables with the same name.
The form of the variable created by ESQL for each type is specified so that it can be
manipulated from host language statements. Declaration of variables in ESQL provides for
their use in both host language and ESQL statements.
Example
EXEC SQL BEGIN DECLARE SECTION ;
long cust_id ;
short i_cust_id ;
char cust_name [30] ;
short i_custname ;
EXEC SQL END DECLARE SECTION ;
EXEC SQL BEGIN DECLARE SECTION;
long cust_no ;
char name [30] ;
EXEC SQL END DECLARE SECTION;
Authorization
None.
SQL Compliance Declarations that use host-language types are SQL-92 compliant. Other declarations are c-treeSQL extensions.
Related Statements TYPE

ESQL Reference
All Rights Reserved 155 www.faircom.com
15.3 CLOSE
Description
Closing a cursor sets the state of the cursor to be closed.
Syntax EXEC SQL CLOSE cursor_name ;
Notes
A cursor can be closed only if it is in the open state.
A cursor is automatically closed when the transaction ends.
Once a cursor is closed, FETCH, DELETE, or UPDATE operations cannot be performed on the
cursor.
It is a good practice to close cursors explicitly.
Example
EXEC SQL OPEN cust_cur ;
EXEC SQL
FETCH cust_cur INTO ... ;
EXEC SQL CLOSE cust_cur ;
Authorization
None (see Authorization for "OPEN" (page 163)).
SQL Compliance SQL-92
Related Statements DECLARE, OPEN, FETCH, positioned UPDATE, positioned DELETE
15.4 DECLARE CURSOR
Description
Associates a cursor with a static query or a prepared dynamic query statement. The query and/or
the prepared statement can have references to host variables.
Syntax EXEC SQL
DECLARE cursor_name CURSOR FOR
{ query_expression [ORDER BY clause] [ FOR UPDATE clause]
| prepared_statement_name
} ;

ESQL Reference
All Rights Reserved 156 www.faircom.com
Notes
Declare a cursor before any OPEN, FETCH, or CLOSE statements.
The scope of the cursor declaration is the entire source file in which it is declared. The
operations on the cursor such as OPEN, CLOSE, and FETCH can occur only within the same
compilation unit as the cursor declaration.
The use of a cursor allows the execution of the positioned forms of the update and delete
statements.
If the declare corresponds to a static c-treeSQL statement containing parameter references
then, the DECLARE statement must be executed before each execution of OPEN statement for
the same cursor. Also, the DECLARE statement and the following OPEN statement for the
same cursor must occur within the same transaction definition (within the same task). In
addition, if the statement contains parameter references to stack variables (auto variables or
function arguments) the DECLARE statement and the following OPEN statement for the same
cursor must occur within the same C function.
See "Single-Row SELECT Statement" (page 167) for descriptions of ORDER BY and FOR
UPDATE clauses.
Example
EXEC SQL
DECLARE custcur CURSOR FOR
SELECT cust_no, name, street, city, state FROM customer ;
Authorization
None (See Authorization for "OPEN" (page 163)).
SQL Compliance SQL-92. c-treeSQL extensions: support for prepared_statement_name.
Related Statements PREPARE, OPEN, FETCH, CLOSE, Select Statement, Query Expression
15.5 DESCRIBE
Description
Writes information about a prepared statement to the c-treeSQL Descriptor Area (SQLDA). The
DESCRIBE statement is one of several dynamic SQL statements that allow programs to accept or
generate c-treeSQL statements at run time. Such dynamically generated statements are not
necessarily part of a program’s source code, but can be generated at run time.
There are two forms of the DESCRIBE statement:
The DESCRIBE BIND VARIABLES statement writes information about input variables (either
substitution names or parameter markers) in expressions to an SQLDA.

ESQL Reference
All Rights Reserved 157 www.faircom.com
The DESCRIBE SELECT LIST statement writes information about select list items in a
prepared SELECT statement to an SQLDA.
The SQLDA is a host-language data structure used in dynamic SQL. DESCRIBE statements write
information about the number, data types, and sizes of input variables or select-list items to
SQLDA structures. Programs read that information in the SQLDA structures to allocate storage.
OPEN, EXECUTE, and FETCH statements read SQLDA structures for the addresses of the
allocated storage.
For more information on the SQLDA, see "Dynamic SQL Management in ESQL" (page 109).
Syntax EXEC SQL
DESCRIBE BIND VARIABLES FOR statement_name
INTO input_sqlda_name ;
EXEC SQL
DESCRIBE SELECT LIST FOR statement_name
INTO output_sqlda_name ;
Arguments
BIND VARIABLES
Specifies that the DESCRIBE statement should write information about any input variables in the
prepared statement to an input SQLDA structure. Input variables represent values supplied at run
time by the program to S and UPDATE statements, and to predicates in DELETE, UPDATE, and
SELECT statements.
The DESCRIBE BIND VARIABLES statement writes the number of input variables to the
sqld_nvars field of the SQLDA. If the sqld_size field of the SQLDA is not equal to or greater than
this number, DESCRIBE writes the value as a negative number to sqld_nvars. Programs should
check sqld_nvars for a negative number to determine if they allocated enough storage for a
particular SQLDA.
Programs supply input variables to the PREPARE statement either as substitution names or as
parameter markers. See "PREPARE" (page 164) for more information.
Programs must issue a DESCRIBE BIND VARIABLES statement after the PREPARE statement but
before the corresponding EXECUTE or OPEN statement for the dynamic SQL statement.
statement_name
The name of a c-treeSQL statement to be dynamically executed. Use the name supplied in the
corresponding PREPARE statement.
input_sqlda_name
The name of the SQLDA structure to which DESCRIBE will write information about input
variables.
SELECT LIST
Specifies that the DESCRIBE statement should write information about select-list items in a
prepared SELECT statement to an output SQLDA structure. Select list items are column names
and expressions in a SELECT statement. A FETCH statement writes the values returned by the
SELECT statement to the addresses stored in the output SQLDA.
ESQL Reference
All Rights Reserved 158 www.faircom.com
The DESCRIBE SELECT LIST statement writes the number of select list items to the sqld_nvars
field of the SQLDA. If the sqld_size field of the SQLDA is not equal to or greater than this number,
DESCRIBE writes the value as a negative number to sqld_nvars. Programs should check
sqld_nvars for a negative number to determine if they allocated enough storage for a particular
SQLDA.
Programs must issue a DESCRIBE SELECT LIST statement after the DECLARE CURSOR,
PREPARE, and OPEN statements for a dynamic SELECT statement, but before the first
corresponding FETCH statement for the cursor.
statement_name
The name of a SELECT statement to be dynamically executed. Use the name supplied in the
corresponding PREPARE statement.
output_sqlda_name
The name of the SQLDA structure to which DESCRIBE will write information about select list
items.
This example shows a series of embedded c-treeSQL statements that process a dynamic
SELECT statement. It omits intervening host language source code:
Example
EXEC SQL
DECLARE CURSOR dyn_cursor FOR dyn_select
EXEC SQL
PREPARE dyn_select FROM :sql_string
EXEC SQL
DESCRIBE SELECT LIST FOR dyn_select INTO outputsqlda ;
EXEC SQL
DESCRIBE BIND VARIABLES FOR dyn_select INTO inputsqlda ;
EXEC SQL
OPEN dyn_cursor USING DESCRIPTOR inputsqlda ;
EXEC SQL
FETCH dyn_cursor USING DESCRIPTOR outputsqlda ;
Authorization
None.
SQL Compliance SQL-92
Related Statements PREPARE, DECLARE, OPEN, FETCH, CLOSE

ESQL Reference
All Rights Reserved 159 www.faircom.com
15.6 END DECLARE SECTION
See the discussion on "BEGIN-END DECLARE SECTION" (page 153).
15.7 EXEC SQL
Description
In programs, precede embedded c-treeSQL statements with EXEC SQL so that they can be
distinguished from the host language statements. (Do not use EXEC SQL prefixes for constructs
within a BEGIN-END DECLARE section, such as type or variable declarations.) Terminate
c-treeSQL statements with a semicolon to denote the end of the statement.
Syntax EXEC SQL sql_statement;
Example
EXEC SQL BEGIN DECLARE SECTION;
long cust_no ;
char name [30] ;
EXEC SQL END DECLARE SECTION;
EXEC SQL
DELETE FROM customer
WHERE customer.name = 'Ralph' ;
Notes
The esqlc compiler does not, in general, parse host language statements and therefore does not
detect any syntax or semantic errors of the host language statements. The exceptions to this rule
are the recognition of host language blocks and #define constants. Host language blocks are
recognized to determine the scope of variables and types declared in esqlc constructs. #define
constants are evaluated by calling the C preprocessor, before the esqlc compilation process as
they can occur in ESQL constructs.
SQL Compliance SQL-92
Related Statements BEGIN-END DECLARE, TYPE
15.8 EXECUTE
Description
Executes the prepared statement specified in statement_name.

ESQL Reference
All Rights Reserved 160 www.faircom.com
If there are any host variable references in the prepared statement, then the actual host variables
have to be specified in the optional USING clause in the order they are encountered in the
prepared statement.
Syntax EXEC SQL
EXECUTE statement_name
[ USING { :host_variable [:indicator_variable] } [ , … ]
| USING DESCRIPTOR descriptor_name
] ;
Notes
The statement to be executed must be prepared within the same transaction.
A prepared statement can be executed one or more times with different host variables by
repeated calls to the EXECUTE statement within the same transaction.
EXECUTE can specify only host variables which are input arguments to the c-treeSQL
statement. All c-treeSQL statements except SELECT statements can be prepared and
executed in this manner.
If a descriptor is not used in the USING clause, EXECUTE is restricted in that the number of
host variable references and the types have to be known when the program is compiled. This
is necessary since they have to be declared in the DECLARE SECTION before they can be
used in the USING clause of the EXECUTE statement. If a descriptor is used, the allocation for
the input variables can be done at runtime.
Example
EXEC SQL BEGIN DECLARE SECTION ;
char sql_string [256] ;
long cust_no ;
EXEC SQL END DECLARE SECTION ;
...
strcpy (sql_string, "DELETE FROM customer WHERE
cust_no = :cust_no_marker") ;
EXEC SQL PREPARE stmt1 FROM :sql_string ;
EXEC SQL EXECUTE stmt1 USING :cust_no ;
...
The following example shows the usage of the USING DESCRIPTOR clause in the EXECUTE statement.
EXEC SQL BEGIN DECLARE SECTION ;
char stmt [256] ;
EXEC SQL END DECLARE SECTION ;
...
EXEC SQL PREPARE stmtid FROM :stmt ;
EXEC SQL EXECUTE stmt USING DESCRIPTOR sqldaptr ;
...
Authorization
The user executing this statement must have authorization for the c-treeSQL statement that is
being executed (see Authorization of the relevant statement).
SQL Compliance SQL-92

ESQL Reference
All Rights Reserved 161 www.faircom.com
Related Statements EXECUTE IMMEDIATE, PREPARE, SQLCA structure
15.9 EXECUTE IMMEDIATE
Description
Executes the SQL statement specified in statement_string or host_variable.
Syntax EXEC SQL
EXECUTE IMMEDIATE { host_variable | statement_string } ;
Example EXEC SQL
EXECUTE IMMEDIATE
"DELETE FROM customer WHERE cust_no = 1404 " ;
Notes
The character string form of the statement is referred to as a statement string. The EXECUTE
IMMEDIATE statement accepts either a statement string or a host variable.
The statement string must not contain host variable references or parameter markers.
The statement string must not start with EXEC SQL and must not terminate with a semicolon.
When an EXECUTE IMMEDIATE statement is executed, the specified statement string is
parsed and checked for errors. Any error in the statement execution is reported in the
SQLCA.
If the same c-treeSQL statement is to be executed more than once, it is more efficient to use
PREPARE and EXECUTE statements, rather than the EXECUTE IMMEDIATE statement.
Authorization
The user executing this statement must have authorization for the c-treeSQL statement that is
being executed (see Authorization of the relevant statement).
SQL Compliance SQL-92
Related Statements EXECUTE, SQLCA structure
15.10 FETCH
Description
Moves the position of the cursor to the next row of the active set and fetches the column values of
the current row into the specified host variables.

ESQL Reference
All Rights Reserved 162 www.faircom.com
Syntax EXEC SQL
FETCH cursor_name
{ INTO { :host_variable [:indicator_variable] } [ , ... ]
| USING DESCRIPTOR descriptor_name
} ;
Notes
The cursor should be open for the FETCH operation to succeed.
The positioning of the cursor on each FETCH operation is as follows:
• Execution of the FETCH statement the first time after the cursor has been opened
positions the cursor to the first row of the active set.
• Subsequent FETCH operations advance the cursor position in the active set making the
next row the current row.
• When the current row is deleted using the positioned DELETE statement, the cursor will
be positioned before the next row of the deleted row in the active set.
The cursor can only be moved forward in the active set by executing FETCH statements. The
cursor can be moved to the beginning of the active set only by closing the cursor and
reopening the cursor.
If the cursor is positioned on the last row of the active set or if the active set does not contain
any rows, then the execution of a FETCH will return the status code SQL_NOT_FOUND in
SQLCA.
Upon successful execution, the cumulative number of rows fetched so far for this cursor after
the last open, is returned in sqlca.sqlerrd [2].
Multiple rows can be fetched in one fetch call by using esqlc array variables in the INTO
clause. In this case, SQL_NOT_FOUND status code is returned in SQLCA when the end of
the active set is reached even if one or more rows are returned by the current execution of
FETCH statement.
If esqlc array variables are used in a fetch statement, the array sizes are set to the number of
tuples fetched after an execution of the FETCH statement.
Example
EXEC SQL BEGIN DECLARE SECTION ;
long cust_no_v ;
char name_v [20] ;
char street_v [40] ;
char city_v [10] ;
char state_v [2] ;
EXEC SQL END DECLARE SECTION ;
...
EXEC SQL OPEN cust_cur ;
for (;;)
{
EXEC SQL
FETCH cust_cur INTO
:cust_no_v, :name_v, :street_v, :city_v, :state_v ;
...
}
...

ESQL Reference
All Rights Reserved 163 www.faircom.com
The usage of the DESCRIPTOR clause in the FETCH statement is shown below:
...
EXEC SQL
FETCH cust_cur USING DESCRIPTOR sqldaptr ;
...
Authorization
None. (See Authorization for "OPEN" (page 163).)
SQL Compliance SQL-92. c-treeSQL extensions: USING DESCRIPTOR clause
Related Statements DECLARE, OPEN, CLOSE
15.11 OPEN
Description
Executes the prepared c-treeSQL query associated with the cursor and creates a result set
composed of the rows that satisfy the query. The collection of rows identified is called the active
set.
The optional USING clause specifies the location of values that c-treeSQL uses to substitute for
input variables in the prepared c-treeSQL query. (See the discussion on "PREPARE" (page 164)
for more detail.)
Syntax EXEC SQL
OPEN cursor_name
[ USING { :host_variable [:indicator_variable] } [ , … ]
| USING DESCRIPTOR descriptor_name
] ;
Notes
The cursor is placed in an open state and the cursor positioned just before the first row of the
active set.
Once the cursor is opened the active set does not change and the host variables are not
reexamined.
If a host variable value is changed and a new active set is to be determined, then the cursor
should be closed and reopened.
Execution of the COMMIT or ROLLBACK statement implicitly closes the cursors which have
been opened within the transaction. It is always better to close an OPEN cursor explicitly.
An OPEN statement is not allowed on a cursor which is already in the open state.
If the declare corresponds to a static c-treeSQL statement and contains parameter
references then, the DECLARE statement must be executed before each execution of OPEN
statement for the same cursor.

ESQL Reference
All Rights Reserved 164 www.faircom.com
Also, the DECLARE statement and the following OPEN statement for the same cursor must occur
within the same transaction definition (within the same task, if tasking is supported).
In addition, if the statement contains parameter references to stack variables (auto variables or
function arguments) the DECLARE statement and the following OPEN statement for the same
cursor must occur within the same C function.
Example
EXEC SQL
OPEN cust_cur ;
EXEC SQL
OPEN ord_cur USING :order_no_v ;
EXEC SQL
OPEN dyn_cur USING DESCRIPTOR sqldaptr ;
Authorization
The user executing this statement must have any of the following privileges:
DBA privilege
SELECT privilege on all the tables/views referred to in the SELECT statement associated with
the cursor.
SQL Compliance SQL-92. c-treeSQL extensions: USING DESCRIPTOR clause
Related Statements DECLARE, CLOSE, FETCH, UPDATE positioned, DELETE positioned
15.12 PREPARE
Description
Parses and assigns a name to a dynamically-generated c-treeSQL statement for execution. The
PREPARE statement is one of several dynamic SQL statements that allow programs to accept or
generate c-treeSQL statements at run time. Such dynamically-generated statements are not
necessarily part of a program’s source code, but can be generated at run time.
Syntax EXEC SQL
PREPARE statement_name FROM { :variable_name | statement_string } ;
Arguments
statement_name
A name for the dynamically-generated statement. DESCRIBE, EXECUTE, and DECLARE CURSOR
statements refer to the statement name. Statement names must be unique within a program file.

ESQL Reference
All Rights Reserved 165 www.faircom.com
:variable_name | statement_string
Specifies the c-treeSQL statement to be prepared for dynamic execution. Use either the name of
a host-language string variable that contains the statement string, or specify the string directly,
enclosed in quotes.
Either way, the statement string must be a character string that is a dynamically executable
c-treeSQL statement. If it contains a syntax error, the PREPARE statement returns an error in the
SQLCA.
The statement string can have one or more references to input variables. Input variables
represent values supplied at run time by the program to INSERT and UPDATE statements, and to
predicates in DELETE, UPDATE, and SELECT statements. Programs supply input variables to the
PREPARE statement either as substitution names or as parameter markers:
Substitution names are names preceded by a colon ( : ) in the statement strings. They do not
refer to host-language variable names, but act only as placeholders for input variables.
Parameter markers are question marks (?) in the statement string, and also act as
placeholders for input variables.
The USING clauses of EXECUTE (for non-SELECT statements) and OPEN (for SELECT
statements) statements specify host-language storage for values to substitute for substitution
names and parameter markers. Programs can execute the same prepared statement many times
within a transaction and supply different values for input variables each time. However, a
statement string must be prepared again if the transaction commits or rolls back.
The following example shows embedded c-treeSQL statements for preparing a DELETE
statement. It uses the statement name del_cust_stmt and specifies a substitution name of
:cust_no_marker. The USING clause of the EXECUTE statement specifies a host variable,
:cust_no, to supply the value at run time.
Example
...
EXEC SQL BEGIN DECLARE SECTION ;
char sql_string [256] ;
long cust_no ;
EXEC SQL END DECLARE SECTION ;
strcpy ( sql_string, "DELETE FROM cust WHERE cust_no = :cust_no_marker") ;
EXEC SQL PREPARE del_cust_stmt FROM :sql_string ;
EXEC SQL EXECUTE del_cust_stmt USING :cust_no ;
...
Authorization
The user executing this statement must have any of the following privileges:
DBA privilege
Authorization for the c-treeSQL statement that is being executed. (See Authorization for the
relevant statement)
SQL Compliance SQL-92

ESQL Reference
All Rights Reserved 166 www.faircom.com
Related Statements EXECUTE, OPEN, CLOSE, FETCH, and SQLCA structure
15.13 Query Expressions
Note: The following information is specific to ESQL. For more detail on query expressions, see the c-treeSQL Reference Manual.
SELECT expr [ ' column_title ' ] [, expr [ ' column_title ' ] ] ...
Specifies a list of expressions, called a select list, whose results will form columns of the result
table. Typically, the expression is a column name from a table named in the FROM clause. The
expression can also be any supported mathematical expression, scalar function, or aggregate
function that returns a value.
The optional 'column_title' argument specifies a new heading for the associated column in the
result table. Enclose the new title in single quotation marks:
SELECT customer_id 'Number',
customer_name 'Name'
FROM customer ;
column_title is also the column name returned when a DESCRIBE SELECT LIST statement is
executed for a cursor associated with the SELECT statement.
15.14 Search Conditions
Note: This section pertains to ESQL specifically and supplements the discussion of search conditions in the c-treeSQL Reference Manual.
LIKE Predicate
Description
The LIKE predicate searches for strings that have a certain pattern. The pattern is specified after
the LIKE keyword in either a host variable or as a string constant. The pattern can be specified
by a string in which the underscore ( _ ) and percent sign ( % ) characters have special
semantics.
The ESCAPE clause can be used to disable the special semantics given to characters ‘ _ ’ and ‘ %
’. The escape character specified must precede the special characters in order to disable their
special semantics.
Syntax like_predicate ::
column_name [ NOT ] LIKE { host_variable | string_constant }
[ ESCAPE escape-character ]

ESQL Reference
All Rights Reserved 167 www.faircom.com
Notes
The column name specified in the LIKE predicate must refer to a character string column.
If a host variable is specified then it must be a character string type variable.
IN Predicate
Description
The IN predicate can be used to compare a value with a set of values. If an IN predicate
specifies a query expression, then the result table it returns can contain only a single column.
Syntax in_predicate ::
expr [ NOT ] IN
{ ( query_expression )
| ( { host_variable | constant } [ , … ] ) }
Example
address.state IN ('MA', 'NH')
15.15 Single-Row SELECT Statement
Description
The single-row form of the SELECT statement can return at most one row in a result table. Use it
in embedded c-treeSQL programs to assign the values of a one-row result table directly to host
variables. The syntax for the single-row form is similar to the general form, with the following
differences:
The single-row form cannot specify SELECT *.
The single-row form must include an INTO clause.
The single-row form cannot use set operators.
Syntax single_row_select_statement ::
SELECT [ALL | DISTINCT]
{ expr [column_title] [, expr [column_title], ...] }
INTO :parameter, :parameter, ...
FROM table_name[alias_name], table_name[alias_name], ...
[WHERE search_condition]
[GROUP BY clause]
[HAVING clause]
[ORDER BY clause]
[FOR UPDATE clause]
;
Arguments
SELECT [ ALL | DISTINCT ]

ESQL Reference
All Rights Reserved 168 www.faircom.com
If the DISTINCT keyword is specified then duplicate rows will be automatically eliminated from
the rows retrieved by the system. The default action corresponds to the ALL keyword where all
the selected rows including duplicates are returned.
INTO
In the single-row form of the SELECT statement, the selected values are assigned to the host
variables specified in the INTO clause. The INTO clause must precede the FROM clause. If no
rows are selected, the condition SQL_NOT_FOUND is returned in the SQLCA structure.
FROM
If the selected column name appears in more than one table specified in the FROM clause then
the column name should be prefixed by the optional table name, or an alias, to resolve ambiguity.
WHERE
The WHERE clause specifies the conditions to be satisfied for row selection. If the WHERE clause is
not specified then all the rows of the specified table or the Cartesian product of all the tables
specified in the FROM clause are returned. For more detail, see the discussion of query
expressions and search conditions in the c-treeSQL Reference Manual.
GROUP BY
The GROUP BY clause specifies the grouping of rows returned by the SELECT statement. For
more detail, see the discussion of query expressions in the c-treeSQL Reference Manual.
HAVING
The HAVING clause allows conditions to be set on the groups returned by the SELECT statement.
For more detail, see the discussion of query expressions in the c-treeSQL Reference Manual.
ORDER BY
The ORDER BY clause allows the specification of the ordering in which rows are returned by the
SELECT statement. For more detail, see the reference section on the SELECT statement in the
c-treeSQL Reference Manual.
FOR UPDATE
The FOR UPDATE clause specifies the update intention on the selected rows. For more detail, see
the reference section on the SELECT statement in the c-treeSQL Reference Manual.
Example SELECT cust_no
INTO :cust_v
FROM customer
WHERE name = :cust_name ;
Authorization
The user executing this statement must have either DBA privilege or SELECT privilege on all the
tables referred to in the statement.

ESQL Reference
All Rights Reserved 169 www.faircom.com
15.16 Type Specifications for Variable and Type Declarations
Description
In addition to standard host-language variable declarations, ESQL supports several forms for
declaring variables and user-defined types. All ESQL variable and type declarations must be
within a BEGIN-END DECLARE SECTION.
This section summarizes the type-specification syntax, and subsequent sections detail syntax
and usage for the various type specifications.
Syntax { variable_name [ , … ] | TYPE new_type_name } type_spec
type_spec ::
{ IS OF TYPE database_type;
| IS OF TYPE host_language_type ;
| IS LIKE table_name.table_column_name ;
| IS AN ARRAY OF type_name WITH SIZE constant_id;
| IS A RECORD OF
field_name IS OF TYPE type_name;
[ ... ]
END OF RECORD ;
| IS A RECORD LIKE table_name [ WITH ( table_column_name [ , ... ] ) ] ;
}
Arguments
{ variable_name [ , … ] | TYPE new_type_name }
If the declaration omits the TYPE keyword at the beginning, esqlc declares one or more variables
of the type specified in type_spec. Such variables can be used in embedded SQL statements.
They can also be used in host language statements as if they had been declared directly in the
host language.
If the declaration begins with the TYPE keyword, esqlc declares a user-defined type.
User-defined types inherit all the properties of a host language type or a previously-declared type.
The new type introduced by the declaration can be used to declare variables or other types in
either esqlc or in the host language.
IS OF TYPE database_type
Specifies a type supported by c-treeSQL. See "Database Types" (page 170).
IS OF TYPE host_language_type
Specifies a type supported by the host language.
IS LIKE table_name.table_column_name
Specifies a type that corresponds to the type of a table column in the database.
IS AN ARRAY OF type_name WITH SIZE constant_id
Specifies a static-sized array type consisting of elements of any type. See "Static Array Types"
(page 172) for details.
IS A RECORD OF …END OF RECORD ;

ESQL Reference
All Rights Reserved 170 www.faircom.com
Specifies a record that consists of one or more fields of the specified types.
IS A RECORD LIKE table_name [ WITH ( table_column_name [ , ... ] ) ]
Specifies record consisting of all the columns or a subset of the columns of the specified table.
This specification is a shortcut for declaring a RECORD and then using the table field type
declarations.
Authorization
None.
SQL Compliance c-treeSQL extension
Related Statements BEGIN-END DECLARE SECTION
Database Types
Description
Declares a variable or type that corresponds to a data type supported by c-treeSQL. This
declaration must be within a BEGIN-END DECLARE SECTION (see "BEGIN-END DECLARE
SECTION" (page 153) for details).
Syntax { variable_name [ , … ] | TYPE new_type_name } IS OF TYPE database_type;
Arguments
{ variable_name [ , … ] | TYPE new_type_name }
If the declaration omits the TYPE keyword at the beginning, esqlc declares one or more variables
of the specified type. If the declaration begins with the TYPE keyword, esqlc declares a
user-defined type.
database_type
Name of a data type supported by the c-treeACE SQL Server. See "Data Type Descriptions"
(page 138) for a description of supported database data types.
Notes
It is not necessary to have a type declaration for a database type to declare a variable in esqlc.
The following variable declaration can also be used with the same effect:
variable_name IS OF TYPE NUMERIC;
For convenience, users can define new types that inherit all the properties of a database type or a
previously declared type. The new type introduced by the declaration can be used to declare
variables or other types in either ESQL or in the host language.
Example
...

ESQL Reference
All Rights Reserved 171 www.faircom.com
EXEC SQL BEGIN DECLARE SECTION ;
TYPE customer_id IS OF TYPE NUMERIC;
EXEC SQL END DECLARE SECTION ;
...
Host Language Types
Description
Declares a variable or type that corresponds to a type supported by the host language. This
declaration must be within a BEGIN-END DECLARE SECTION.
Syntax { variable_name [ , … ] | TYPE new_type_name } IS OF TYPE host_language_type ;
Notes
The following host language C types are supported by esqlc:
host_language_type ::
{ [unsigned] char
| [unsigned] short
| [unsigned] long
| float
| double
}
The host language C type int is not supported in esqlc. Type int maps to 16 or 32 bits depending
on the machine architecture. This has the potential of creating rounding errors at runtime in
shipping values in the transaction execution calls across different machine architectures.
It is not necessary to have a type declaration for a host language type to declare a variable in
esqlc. The following variable declaration can also be used with the same effect:
variable_name IS OF TYPE unsigned long;
For convenience, users can define new types which inherit all the properties of a host
language type or a previously-declared type. The new type introduced by the declaration can
be used to declare variables or other types in either esqlc or in the host language.
esqlc variables of host types can also be declared in C syntax in the following form:
host_language_type variable_name ;
For example, the following declaration declares cust_no to be a variable of type long (as in C
language):
long cust_no ;
Example
EXEC SQL BEGIN DECLARE SECTION ;
TYPE customer_no IS OF TYPE unsigned long;
EXEC SQL END DECLARE SECTION ;
...
ESQL Reference
All Rights Reserved 172 www.faircom.com
Table-Column Types
Description
Declares a variable or type that corresponds to a table column in the database. This declaration
must be within a BEGIN-END DECLARE SECTION.
Syntax { variable_name [ , … ] | TYPE new_type_name }
IS LIKE table_name.table_column_name ;
Notes
Modification of the database schema would automatically change (on recompilation) the
program types if the type is inherited using the above form of the type declaration. This
makes the user programs more manageable.
The host language type into which the type is mapped is as specified for database types.
Example
EXEC SQL BEGIN DECLARE SECTION ;
TYPE customer_name_type IS LIKE
customer_relation.customer_name;
EXEC SQL END DECLARE SECTION ;
Static Array Types
Description
Declares a static-sized array or array type consisting of elements of any type. This declaration
must be within a BEGIN-END DECLARE SECTION.
Syntax { variable_name [ , … ] | TYPE new_type_name }
IS AN ARRAY OF type_name WITH SIZE constant_id;
Notes
esqlc does not allow the definition of open size arrays.
All esqlc arrays (excluding character arrays) are mapped into a host language structure
consisting of both the actual array and the current size of the array. The C language structure
is of the following form:
struct new_type_name {
long tpe_size;
element_type_name tpe_array[constant_id];
};
Host language statements can manipulate the array assuming that it is a structure with the same
name as the array name and having two components tpe_array and tpe_size. The tpe_array
component contains the actual array and the tpe_size component contains the current size of the
array.

ESQL Reference
All Rights Reserved 173 www.faircom.com
All esqlc statements that manipulate the array will update the current size associated with the
array. The host language statements that manipulate the array are expected to update the
current size.
Character arrays are treated as a special case by esqlc. They are not mapped to a record
but rather as a null terminated string. This simplifies their manipulation from C and their use
with system provided functions. When a character array is manipulated by esqlc statements
the null termination is always guaranteed.
While referring to an array element in a c-treeSQL statement, the array name followed by the
element index within square brackets should be specified, even though esqlc generates a
structure for an array type.
This is illustrated in the following example:
EXEC SQL BEGIN DECLARE SECTION ;
#define NAMESZ 20
#define ARRAYSZ 10
cust_name_t IS AN ARRAY OF char WITH SIZE NAMESZ ;
cust_name IS AN ARRAY OF cust_name_t WITH SIZE ARRAYSZ ;
EXEC SQL END DECLARE SECTION ;
...
for (i = 0 ; i < ARRAYSZ ; i++)
{
EXEC SQL FETCH cust_cursor INTO
:cust_name[i] ;
if (sqlca.sqlcode) break ;
printf ("Customer Name : %s\\n",
cust_name.tpe_array [i]) ; }
...
If array variables are specified in the INTO clause of a FETCH statement, esqlc retrieves
multiple rows . For example:
EXEC SQL BEGIN DECLARE SECTION ;
cust_name_t IS AN ARRAY OF char WITH SIZE 20 ;
cust_name IS AN ARRAY OF cust_name_t WITH SIZE 10 ;
EXEC SQL END DECLARE SECTION ;
...
EXEC SQL FETCH cust_cursor INTO :cust_name ;
...
When arrays are used for multiple-row-fetch, the sizes of all array variables and indicator array
variables must be the same. If they are different, esqlc will use the minimum of the array sizes.
If the FETCH statement is used to fetch multiple rows by using array variables, the array sizes are
set appropriately after the fetch.
Example
EXEC SQL BEGIN DECLARE SECTION ;
TYPE customer_array_type
IS AN ARRAY OF customer_record WITH SIZE 50;
EXEC SQL END DECLARE SECTION ;
...

ESQL Reference
All Rights Reserved 174 www.faircom.com
Record Types
Description
Declares a RECORD variable or type that consists of one or more fields of the same or of different
types. This declaration must be within a BEGIN-END DECLARE SECTION (see "BEGIN-END
DECLARE SECTION" (page 153) for details).
Syntax { variable_name [ , … ] | TYPE new_type_name }
IS A RECORD OF
field_name IS OF TYPE type_name;
[ ... ]
END OF RECORD ;
Notes
A RECORD is equivalent to a structure in C or a record in Pascal. A record is directly mapped
into the appropriate type in the host language with the same user defined name.
A component of a RECORD is called a field and can be denoted by using the dot ( . ) operator,
as in record_variable_name.field_name.
Example
EXEC SQL BEGIN DECLARE SECTION ;
TYPE customer_type IS A RECORD OF
customer_id IS OF TYPE long;
customer_name IS AN ARRAY OF CHAR WITH SIZE 20;
END OF RECORD;
EXEC SQL END DECLARE SECTION ;
...
Table Record Types
Description
Declares a variable or type that is a RECORD consisting of all the columns or a subset of the
columns of the specified table. This form of declaration is a shortcut to declaring a RECORD and
then using the table field type declarations. This declaration must be within a BEGIN-END
DECLARE SECTION (see "BEGIN-END DECLARE SECTION" (page 153) for details).
Syntax { variable_name [ , … ] | TYPE new_type_name }
IS A RECORD LIKE table_name [ WITH ( table_column_name [ , ... ] ) ] ;
Notes
If the table column list is not specified, then by default the record will contain all the columns
of the specified table.
When the database schema for the table is changed, the program (on recompilation) will
automatically reflect the new types simplifying the maintenance of the program.

ESQL Reference
All Rights Reserved 175 www.faircom.com
The types created in the host programming language are the same as specified for database
types.
The esqlc command line must include the +D connect_string option for the program to
declare table records. (See "esqlc Command Line Reference" (page 46) for more detail.)
Example
...
EXEC SQL BEGIN DECLARE SECTION ;
TYPE customer_record IS A RECORD LIKE customer_table;
EXEC SQL END DECLARE SECTION ;
...
15.17 WHENEVER
Description
Specifies actions for three c-treeSQL runtime exceptions.
Syntax WHENEVER
{ NOT FOUND | SQLERROR | SQLWARNING }
{ STOP | CONTINUE | { GOTO | GO TO } host_language_label } ;
Arguments
{ NOT FOUND | SQLERROR | SQLWARNING }
The exception NOT FOUND is set when sqlca.sqlcode is set to SQL_NOT_FOUND.
The exception SQLERROR is set when sqlca.sqlcode is set to a negative value after a
statement execution.
The exception SQLWARNING is set when sqlca.sqlwarn [0] is set to ‘W’ after a statement
execution.
{ STOP | CONTINUE | { GOTO | GO TO } host_language_label }
STOP results in the esqlc program stopping execution whenever the specified exception is
raised.
CONTINUE results in the esqlc program ignoring the specified exception and continuing
execution.
GOTO | GO TO host_language_label results in the esqlc program execution to branch to
the statement corresponding to the host_language_label.
The default action for each exception is CONTINUE.
Notes
There can be multiple WHENEVER statements in an esqlc file for the same exception. Each
WHENEVER statement overrides the previous WHENEVER statement specified for the same
exception.

ESQL Reference
All Rights Reserved 176 www.faircom.com
Correctness of a WHENEVER statement with GOTO | GO TO host_language_label action is
subject to the scoping rules of the host language. The host_language_label must be within
the scope of all c-treeSQL statements for which the GOTO | GO TO host_language_label
action is active. The GOTO | GO TO host_language_label action is active starting from
the corresponding WHENEVER statement until another WHENEVER statement for the same
exception or until end of (esqlc) source file.
Example
EXEC SQL
WHENEVER SQLERROR GOTO err ;
...
EXEC SQL
UPDATE customer
SET name = 'RALPH'
WHERE cust_no = 1001 ;
...
err:
EXEC SQL
WHENEVER SQLERROR CONTINUE ;
EXEC SQL
ROLLBACK WORK ;
return ;
Authorization
None.
SQL Compliance SQL-92. c-treeSQL extensions: SQLWARNING exception condition and STOP
action
Related Statements FETCH
15.18 Long Data Type Support
In the esqlc, the long data select operation is done using the c-treeESQL programmatic interface
tpe_sqlgetdata() and the insert operation is done using the interface tpe_sqlputdata(). These C
interfaces require the field handle as their argument. Two field handle types have been
introduced for this purpose. They are:
lvc_fld_hdl_t : Field handle type for LVARCHAR column.
lvb_fld_hdl_t : Field handle type for LVARBINARY column.
The above field handles type host variable need to be used in the EXEC SQL statement to get the
field handle of the long column.
The LVARCHAR data type is recommended for CLOB support.
The LVARBINARY data type is recommended for BLOB support.

ESQL Reference
All Rights Reserved 177 www.faircom.com
DECLARE Section
The field handle type variable can be declared in DECLARE section as follows:
EXEC SQL BEGIN DECLARE SECTION;
lvc_fld_hdl_t fld_hdl_buffer ;
........
........
EXEC SQL END DECLARE SECTION;
INSERT Operation
While performing the insert operation, the field handle is obtained through the USING clause of
the EXECUTE statement.
EXEC SQL EXECUTE S1 USING: fld_hdl_buffer;
This field handle is used in the tpe_sqlputdata () call.
tpe_sqlputdata (
tpe_get_curtmhdl(), /* IN transaction handle */
tpe_get_curdbhdl(), /* IN db handle */
tpe_pcur0, /* IN cursor */
TPE_DT_CHAR, /* htypeid */
(void *)fld_hdl_buffer, /* hdl to field */
data_buflen, /* IN bufferlen */
fe_offset, /* IN offset into field */
data_buf, /* IN buffer */
&sqlca /* OUT sqlca pointer */
);
SELECT Operation
For the select from long column, the field handle is obtained using FETCH statement.
EXEC SQL FETCH long_cursor INTO: fld_hdl_buffer;
This field handle is used in the tpe_sqlgetdata () call.
tpe_sqlgetdata (
tpe_get_curtmhdl(),
tpe_get_curdbhdl(),
tpe_pcur0,
TPE_DT_CHAR,
(void *)fld_hdl_buffer,
101,
fe_offset,
buffer,
&fe_val_len,
&sqlca
);
Refer to "Long Data Type Support" (page 176) for sample programs that demonstrate the Long
data type support in ESQL.

All Rights Reserved 178 www.faircom.com
16. Programmatic Interfaces
16.1 Introduction
c-treeSQL Interfaces are the programming language interfaces for c-treeSQL database
connectivity. c-treeSQL database capabilities are exposed through these interfaces. ESQL is
layered over these interfaces. When an ESQL program is precompiled with esqlc, it generates a
program in C Language wherein all the c-treeSQL statements are converted into the
corresponding programming language interface calls. These c-treeSQL Interfaces are exported
from the c-treeSQL libraries. Database applications written using these interfaces need to link
with the libraries.
Note: As of c-treeACE SQL Server V8.14, the c-treeSQL programmatic interface is thread safe and can be used in multi-threaded applications. Because of this modification, new functions have been added while others have been deprecated.
The programmatic interfaces described in this chapter can be used in conjunction and/or as a
substitute to the statements provided by the ESQL environment.
The programmatic interfaces provide the following functionality.
Functionality provided by the programmatic interfaces
Programmatic Interface Functionality
SQL Functions Provide functionality for connecting to a database and disconnecting from a database and executing static and dynamic SQL statements.
Transaction Functions Provide functionality for beginning and ending transactions.
Type Conversion Functions Provide functionality for converting values in one database type form to another compatible database type form.
The programmatic interfaces provide the developer the option of using the c-treeSQL functionality
either through the esqlc compiler and/or through programmatic interfaces. The advantage of the
programmatic interfaces is that they can be easily integrated into existing code without a major
rewrite of the application. The programmatic interfaces are also more flexible in applications
which are being developed in languages other than C and applications being developed using
RPC code generators.
If the library functions are used in a C program that is not compiled using esqlc, then appropriate
C preprocessor symbols are to be defined for indicating the environment. For example the
following are the preprocessor options used on the SCO UNIX platform.
-DDH_OS_UNIX -DDH_OS_UNIX_SCO

Programmatic Interfaces
All Rights Reserved 179 www.faircom.com
The following pages include the descriptions for the programmatic interfaces and are arranged
alphabetically.
16.2 Programmatic Interfaces
sqld_alloc
Syntax #include “sql_lib.h”
struct sqlda *sqld_alloc(size, varnmsz)
short size;
short varnmsz;
Description
The sqld_alloc() function allocates an SQLDA from the heap.
Parameters
size
Size of the SQLDA (number of output columns in the result table corresponding to a c-treeSQL
statement).
varnmsz
The maximum number of characters in the name of the column of the result table corresponding
to the c-treeSQL statement. If names of columns in the result table are not of interest, a zero
value can be passed for varnmsz.
Note
The allocation for buffers for the results of a FETCH statement and allocation for indicator
variables are not done by sqld_alloc(). These allocations are to be done by the application
program and the SQLDA should be set to point to these buffers.
Returns
None.
Related Functions
sqld_free(), dh_set_sqlda()
sqld_free
Syntax #include “sql_lib.h”
void sqld_free (sqldaptr)
struct sqlda *sqldaptr;

Programmatic Interfaces
All Rights Reserved 180 www.faircom.com
Description
The sqld_free() function frees the memory occupied by an SQLDA, allocated using the
sql_alloc() function.
Parameters
sqldaptr
Points to SQLDA, that was returned by sqld_alloc() call.
Notes
The buffers that receive the results of a FETCH statement and indicator variable buffers are
not freed by sqld_free(). These buffers are to be freed by the application program before
freeing the SQLDA using the sqld_free() call.
Returns
None.
Related Functions
sql_alloc(), dh_set_sqlda()
dh_alloc_sqlenv
Syntax #include "sql_lib.h"
typedef void *dh_sqlenv_hdl_t;.
void dh_alloc_sqlenv(sqlenv_hdl)
dh_sqlenv_hdl_t *sqlenv_hdl;
Description
The function dh_alloc_sqlenv() allocates the c-treeSQL environment required for containing the
context for use by the C programmatic interfaces and returns a handle to the allocated c-treeSQL
environment. This environment handle cannot be shared across multiple connections, hence
each connection should allocate a separate sql_env_t handle.
Parameters
sqlenv_hdl
This is the address of a variable of type dh_sqlenv_hdl_t. After successful completion, this
function returns the variable pointed to by this parameter would contain the allocated c-treeSQL
environment handle.
Returns
None

Programmatic Interfaces
All Rights Reserved 181 www.faircom.com
Related Functions
dh_free_sqlenv()
dh_compare_data
Syntax #include “sql_lib.h”
tpe_status_t dh_compare_data(dtype, buf1len, buf1, buf2len, buf2, result)
int dtype;
int buf1len;
void *buf1;
int buf2len;
void *buf2;
short *result;
Description
Compares two data objects of a given type.
Parameters
dtype
The data type of the two objects that are being compared.
buf1len
The length of the first data object.
buf1
The buffer containing the first data object.
buf2len
The length of the second data object.
buf2
The buffer containing the second data object.
result
Should point to a location for returning the result. result is a short integer with the following
values:
1 first data object is greater than second data object.
-1 first data object is less than second data object.
0 the two data objects are equal.
Returns
A negative error code on failure and a zero value on success.
Notes
The data types supported are defined in the include file sql_lib.h and are listed below:
Programmatic Interfaces
All Rights Reserved 182 www.faircom.com
• TPE_DT_CHAR
• TPE_DT_NUMERIC
• TPE_DT_SMALLINT
• TPE_DT_INTEGER
• TPE_DT_SMALLFLOAT
• TPE_DT_REAL
• TPE_DT_FLOAT
• TPE_DT_DATE
• TPE_DT_MONEY
• TPE_DT_TIME
• TPE_DT_TIMESTAMP
• TPE_DT_TINYINT
• TPE_DT_BINARY
• TPE_DT_BIT
• TPE_DT_LVC
• TPE_DT_LVB
• TPE_DT_BIGINT
Related Functions
dh_conv_data()
dh_conv_data
Syntax #include “sql_lib.h”
tpe_status_t dh_conv_data(dtype, buf1, buf, fmt, odtype, obuf1, obuf)
int dtype;
int buf1;
void *buf;
char *fmt;
int odtype;
int obuf1
void *obuf;
Description
Converts data from one type representation to the desired type representation.
Parameters
dtype
The data type of the input buffer which is being converted.
buf1
The length of the input buffer being converted.
buf
The buffer containing the input data and whose type is specified in dtype.

Programmatic Interfaces
All Rights Reserved 183 www.faircom.com
fmt
A format string to be used for formatting the output if the desired data output data type is a
character string type.
odtype
The data type of the output required after conversion.
obuf1
The length of the buffer reserved for the output type.
obuf
The output data is returned in this buffer.
Returns
Returns a negative error code on failure and a zero value on success.
Notes
The data types supported are defined in the include file sql_lib.h and are listed below:
• TPE_DT_CHAR
• TPE_DT_NUMERIC
• TPE_DT_SMALLINT
• TPE_DT_INTEGER
• TPE_DT_SMALLFLOAT
• TPE_DT_REAL
• TPE_DT_FLOAT
• TPE_DT_DATE
• TPE_DT_MONEY
• TPE_DT_TIME
• TPE_DT_TIMESTAMP
• TPE_DT_TINYINT
• TPE_DT_BINARY
• TPE_DT_BIT
• TPE_DT_LVC
• TPE_DT_LVB
• TPE_DT_BIGINT
Currently a format string can be specified only if the input is of type TPE_DT_DATE and the
output is of type TPE_DT_CHAR.
Related Functions
dh_dayofweek()

Programmatic Interfaces
All Rights Reserved 184 www.faircom.com
dh_dayofweek
Syntax #include “sql_lib.h”
int dh_dayofweek(date)
tpe_date_t date;
Description
Returns the day of the week of the specified date.
Arguments
date
The date for which the day of the week is required.
Returns
The day of the week is returned as an integer value ranging from 0 to 6 where 0 represents a
Sunday and 6 represents a Saturday.
Related Functions
dh_conv_data()
dh_free_sqlenv
Syntax #include "sql_lib.h"
void dh_free_sqlenv(sqlenv_hdl)
dh_sqlenv_hdl_t sqlenv_hdl;
Description
The dh_free_sqlenv() function frees c-treeSQL environment allocated using the
dh_alloc_sqlenv() function.
Parameters
sqlenv_hdl
This is the c-treeSQL environment handle.
Returns
None
Related Functions
dh_alloc_sqlenv()
Programmatic Interfaces
All Rights Reserved 185 www.faircom.com
dh_get_curdbhdl
Syntax #include “sql_lib.h”
tpe_db_hdl_t dh_get_curdbhdl(sqlenv_hdl);
dh_sqlenv_hdl_t sqlenv_hdl;
Description
The dh_get_curdbhdl() function gets the current database handle.
Parameters
sqlenv_hdl
c-treeSQL environment handle.
Returns
A null handle is returned if no database is attached to.
Notes
The current database handle.
All the c-treeSQL statements in a program by default use the current database handle.
Related Functions
dh_sqlattach(), dh_set_curdbhdl()
dh_get_curtmhdl
Syntax #include “sql_lib.h”
tpe_tm_hdl_t dh_get_curtmhdl(sqlenv_hdl);
dh_sqlenv_hdl_t sqlenv_hdl;
Description
The dh_get_curtmhdl() function gets the current transaction handle.
Parameters
sqlenv_hdl
c-treeSQL environment handle.
Returns
Returns the current transaction handle.
Notes
The very first call into this function, results in allocation of a transaction handle. This handle is
set as the current transaction handle and the same handle is returned.

Programmatic Interfaces
All Rights Reserved 186 www.faircom.com
All the c-treeSQL statements and transaction statements in a program by default use the
current transaction handle.
Related Functions
dh_tm_alloc_handle(), dh_set_curtmhdl()
dh_num_add
Syntax #include “sql_lib.h”
tpe_status_t dh_get_num_add(num1,num2, num3)
tpe_num_t *num1;
tpe_num_t *num2;
tpe_num_t *num3;
tpe_status_t dh_get_num_sub(num1,num2, num3)
tpe_num_t *num1;
tpe_num_t *num2;
tpe_num_t *num3;
tpe_status_t dh_get_num_mul(num1,num2, num3)
tpe_num_t *num1;
tpe_num_t *num2;
tpe_num_t *num3;
tpe_status_t dh_get_num_add(num1,num2, num3)
tpe_num_t *num1;
tpe_num_t *num2;
tpe_num_t *num3;
Description
Implements the addition, subtraction, multiplication and division operations on numeric types.
Arguments
num1
The first operand to the specified operation. If the operation is division this is the divisor.
num2
The second operand to the specified operation. If the operation is division this is the dividend.
num3
The result of the operation is returned here with the maximum precision possible.
Returns
A value 0 is returned on success and a value -1 on failure.
Related Functions
dh_conv_data()

Programmatic Interfaces
All Rights Reserved 187 www.faircom.com
dh_set_cursor
Syntax #include “sql_lib.h”
void dh_set_cursor(sqlenv_hdl,tmhdl, dbhdl, cursorptr, stmtuid,
isdynamic, statement, ca)
dh_sqlenv_hdl_t sqlenv_hdl;
tpe_tm_hdl_t tmhdl;
tpe_db_hdl_t dbhdl;
tpe_cursor_t *cursorptr;
tpe_uuid_t *stmtuid;
int isdynamic;
char *statement;
struct sqlca *ca;
Description
The dh_set_cursor() function sets information in a cursor structure. This information is used by
other c-treeSQL calls.
Parameters
sqlenv_hdl
c-treeSQL environment handle.
tmhdl
Transaction handle.
dbhdl
Database handle.
cursorptr
Pointer to a variable of the type tpe_cursor_t. This variable is expected to be NULL at the time of
the very first call to this function for this cursor in a program.
stmtuid
Pointer to a buffer containing the universal unique identifier for the c-treeSQL statement.
isdynamic
An integer flag, if nonzero, indicates that the statement is a dynamic c-treeSQL statement.
statement
A pointer to the statement string.
ca
A pointer to SQLCA structure for returning the status.
Returns
A negative error code on failure and a zero value on success is returned in the sqlcode field of
the SQLCA structure.
Programmatic Interfaces
All Rights Reserved 188 www.faircom.com
Notes
The argument tmhdl should have been obtained through a successful call to either
dh_get_curtmhdl() or dh_tm_alloc_handle().
The argument dbhdl should have been obtained through a successful call to dh_sqlattach().
Each call to any of the functions dh_sqlexecute(), dh_sqlprepare(), dh_sqldescribe() and
dh_sqlclose() should be preceded by a dh_set_cursor_call().
Related Functions
dh_sqlattach(), dh_get_curdbhdl(), dh_get_curtmhdl(), dh_sqlexecute(), dh_sqldeclare(),
dh_sqlselect(), dh_sqlopen(), dh_sqlfetch(), dh_sqlprepare(), dh_sqldescribe(),
dh_sqlclose()
dh_set_ptrs
Syntax #include “sql_lib.h”
void dh_set_ptrs(ptrarray, nptrs, ptr1, ptr2,.......)
void *ptrarray[];
int nptrs;
void *ptr1;
void *ptr2;
Description
The dh_set_ptrs() function sets pointer values in the given pointer list. This function call is useful
if the SQLDA is being allocated on the stack.
Parameters
ptrarray
Pointer to the array in which the pointer values are to be set.
nptrs
Number of pointers being passed.
ptr1, ptr2, ...
Pointer values to be set in the ptrarray.
Returns
None.
Related Functions
dh_set_sqlda()

Programmatic Interfaces
All Rights Reserved 189 www.faircom.com
dh_set_sqlda
Syntax #include “sql_lib.h”
void dh_set_sqlda(sqldaptr, sqldsz, arraysz, types,
lengths, varptrs, ivarptrs)
struct sqlda *sqldaptr;
int sqldsz;
int arraysz;
short types[];
short lengths[];
char *varptrs[];
short *ivarptrs[];
Description
The dh_set_sqlda() function sets the fields of the given SQLDA with the values passed. This
function call is useful if the SQLDA is being allocated on the stack.
Parameters
sqldaptr
Pointer to the SQLDA structure whose fields are to be set.
sqldsz
Size of the SQLDA.
arraysz
Array size (>1 for multiple tuple fetch in a single call).
types
Points to an array (of size sqldsz) of short integers representing the types of values contained in
the SQLDA.
lengths
Points to an array (of size sqldsz) of short integers representing the lengths of values contained in
the SQLDA.
varptrs
Points to an array (of size sqldsz) of pointers, each pointer pointing to an array (of size arraysz) of
variables. The type of the variable is given by the corresponding entry in the types array.
ivarptrs
Points to an array (of size sqldsz) of pointers, each pointer pointing to an array (of size arraysz) of
variables. The variable is of type short integer.
Returns
None
Related Functions
dh_set_ptrs()

Programmatic Interfaces
All Rights Reserved 190 www.faircom.com
dh_sqlclose
Syntax #include “sql_lib.h”
void dh_sqlclose(sqlenv_hdl,tmhdl, dbhdl, cursor, ca)
dh_sqlenv_hdl_t sqlenv_hdl;
tpe_tm_hdl_t tmhdl;
tpe_db_hdl_t dbhdl;
tpe_cursor_t cursor;
struct sqlca *ca;
Description
The dh_set_sqlclose() function closes a cursor. The function call corresponds to the CLOSE
statement of ESQL.
Parameters
sqlenv_hdl
c-treeSQL environment handle
tmhdl
Transaction handle.
sqldsz
Database handle returned by a prior successful call to dh_get_curdbhdl().
cursor
A variable of the type tpe_cursor_t(). This variable is expected to be NULL at the time of the very
first call to dh_set_cursor() function in a program for this cursor.
ca
A pointer to SQLCA structure for returning the status.
Notes
The argument tmhdl should have been obtained through a successful call to either
dh_get_curtmhdl() or dh_tm_alloc_handle().
The argument dbhdl should have been obtained through a successful call to
dh_get_curdbhdl().
The cursor should have been successfully opened using the dh_sqlopen() call.
All open cursors are closed automatically when a transaction is committed.
This call to dh_sqlclose() function should be preceded by a dh_set_cursor(). For example,
see the code generated by the esqlc compiler for a CLOSE statement.
Returns
A negative error code on failure and a zero value on success is returned in the sqlcode field of
the SQLCA structure.
Programmatic Interfaces
All Rights Reserved 191 www.faircom.com
Related Functions
dh_sqlconnect(), dh_get_curdbhdl(), dh_get_curtmhdl(), dh_set_cursor(), dh_sqldeclare(),
dh_sql_open(), dh_sqlfetch(), dh_sqlprepare()
dh_sqlconnect
Syntax #include “sql_lib.h”
void dh_sqlconnect(sqlenv_hdl,dbname, connection_name,
user_identifier, user_authentication, ca)
dh_sqlenv_hdl_t sqlenv_hdl;
char *dbname;
char *connection_name;
char *user_identifier;
char *user_authentication;
struct sqlca *ca;
Description
Connects to the database specified, for performing database operations. The database handle
associated with the connection name is obtained.
Parameters
sqlenv_hdl
c-treeSQL environment handle.
dbname
The name of the database to which the process invoking the operation needs to connect to.
connection_name
The optional connection_name is a unique identifier the application can use to reference the
connection in subsequent connection management statements. If the application does not
provide a connection_name, the database name itself becomes the connection_name.
user_identifier
Optional user name for the connection. If supplied, it will be matched with a password for
authentication. If omitted, the default value depends on the environment. (On UNIX, the value of
the DH_USER environment variable specifies the default user name.)
user_authentication
Optional password for the connection. If supplied, it will be matched with a user name for
authentication. If omitted, the default value depends on the environment. (On UNIX, the value of
the DH_PASSWD environment variable specifies the default password.)
ca
The pointer to sqlca for returning status.

Programmatic Interfaces
All Rights Reserved 192 www.faircom.com
Notes
In the event of the database environment being DEFAULT, an attempt is made to connect to
the environment defined database, if any; if not successful, an error message is given and
the execution terminates.
A connection to a database can be made either in the local mode or in the remote mode. At
most one connection is allowed in the local mode. The parameter dbname must be a connect
string to connect in the remote mode. The connect string specifies the port, the target host for
the database, and the database name. To connect to a database salesdb in the remote
mode, the connect string could be:
6597@remotehost:salesdb
An application process can make a particular connection a current connection by calling the
dh_sql_setconnection() call.
The operation will fail if the database is not started.
An application can disconnect itself from a database by calling the dh_sqldisconnect() call.
The sqlcode in the returned SQLCA structure contains the success/failure status.
Returns
On successful connect, a zero value is returned in ca->sqlcode.
On failure, a negative error code is returned in ca->sqlcode.
Related Functions
dh_sql_setconnection(), dh_sql_disconnect()
dh_sqldeclare
Syntax #include “sql_lib.h”
void dh_sqldeclare(sqlenv_hdl,tmhdl, dbhdl, cursor, i_sqlda, ca)
dh_sqlenv_hdl_t sqlenv_hdl;
tpe_tm_hdl_t tmhdl;
tpe_db_hdl_t dbhdl;
tpe_cursor_t cursor;
struct sqlda *i_sqlda;
struct sqlca *ca;
Description
The dh_sqldeclare() function declares a cursor. This function call corresponds to the DECLARE
CURSOR statement of ESQL.
Parameters
sqlenv_hdl
c-treeSQL environment handle.
tmhdl
Transaction handle.

Programmatic Interfaces
All Rights Reserved 193 www.faircom.com
dbhdl
Database handle.
cursor
A variable of the type tpe_cursor_t. This variable initially is expected to be NULL.
i_sqlda
A pointer to the SQLDA structure containing input parameters for the ESQL statements. A NULL
pointer is expected if there are no parameter references in the c-treeSQL statement. A NULL
pointer is expected also when the corresponding c-treeSQL statement is a dynamic statement in
which case the parameters are passed to the dh_sqlopen() call.
ca
A pointer to SQLCA structure for returning the status.
Notes
The argument tmhdl should have been obtained through a successful call to either
dh_get_curtmhdl() or dh_tm_alloc_handle().
The argument dbhdl should have been obtained through a successful call to
dh_get_curdbhdl().
This call to dh_sqldeclare() function should be preceded by a dh_set_cursor(). For
example, see the code generated by the esqlc compiler for a DECLARE CURSOR statement.
Returns
A negative error code on failure and a zero value on success is returned in the sqlcode field of
the SQLCA structure.
Related Functions
dh_sqlconnect(), dh_get_curdbhdl(), dh_get_curtmhdl(), dh_set_cursor(), dh_sqlexecute(),
dh_sqlselect(), dh_sqlopen(), dh_sqlfetch(), dh_sqlprepare(), dh_sqldescribe(),
dh_sqlclose()
dh_sqldescribe
Syntax #include “sql_lib.h”
void dh_sqldescribe(sqlenv_hdl,tmhdl, dbhdl, cursor, o_sqlda, ca)
dh_sqlenv_hdl_t sqlenv_hdl;
tpe_tm_hdl_t tmhdl;
tpe_db_hdl_t dbhdl;
tpe_cursor_t cursor;
struct sqlda *o_sqlda;
struct sqlca *ca;
Description
The dh_sqldescribe() function returns the number, types and lengths of the outputs of dynamic
select c-treeSQL statement. This function call corresponds to the DESCRIBE statement of ESQL.

Programmatic Interfaces
All Rights Reserved 194 www.faircom.com
Parameters
sqlenv_hdl
c-treeSQL environment handle.
tmhdl
Transaction handle.
dbhdl
Database handle.
cursor
A variable of the type tpe_cursor_t. This variable initially is expected to be NULL.
o_sqlda
The SQLDA structure for returning the number, types and lengths of the outputs of the select
statement.
ca
A pointer to SQLCA structure for returning the status.
Notes
The argument tmhdl should have been obtained through a successful call to either
dh_get_curtmhdl() or dh_tm_alloc_handle().
The argument dbhdl should have been obtained through a successful call to
dh_get_curdbhdl().
Describe call can be issued only for a dynamic select statement after the corresponding
cursor has been successfully opened. The call to dh_sqldescribe() function should be
preceded by a dh_set_cursor(). For example, see the code generated by the esqlc compiler
for a DESCRIBE statement.
If the size of the SQLDA s not sufficient, then the field sqld_nvars is set to negative of the
actual number of outputs found.
If the sqld_varnmsize field is nonzero, then the output names are returned in the buffers
pointed by pointers in sqld_varnames.
Returns
A negative error code on failure and a zero value on success is returned in the sqlcode field of
the SQLCA structure. If the call is successful, the field sqld_nvars of o_sqlda contains the number
of outputs.
Related Functions
dh_sqlconnect(), dh_get_curdbhdl(), dh_get_curtmhdl(), dh_set_cursor(), dh_sqlexecute(),
dh_sqlselect(), dh_sqlopen(), dh_sqlfetch(), dh_sqlprepare(), dh_sqldeclare(),
dh_sqlclose()

Programmatic Interfaces
All Rights Reserved 195 www.faircom.com
dh_sqldescribe_param
Syntax #include “sql_lib.h”
void dh_sqldescribe_param(sqlenv_hdl,tmhdl, dbhdl, cursor, i_sqlda, ca)
dh_sqlenv_hdl_t sqlenv_hdl;
tpe_tm_hdl_t tmhdl;
tpe_db_hdl_t dbhdl;
tpe_cursor_t cursor;
struct sqlda *i_sqlda;
struct sqlca *ca;
Description
Returns the number, types and lengths of the input variables in expressions of a dynamic SQL
statement. This function call corresponds to the DESCRIBE BIND VARIABLES statement of
ESQL. Before calling the dh_sqldescribeparam() function, programs must first call the
dh_set_cursor() function.
Parameters
sqlenv_hdl
c-treeSQL environment handle.
tmhdl
Transaction handle. Get this value through a successful call to either dh_get_curtmhdl() or
dh_tm_alloc_handle().
dbhdl
Database handle. Get this value through a successful call to dh_get_curdbhdl().
cursor
A variable of the type tpe_cursor_t. This variable is expected to be NULL at the time of very first
call to dh_set_cursor() function in a program for the cursor.
i_sqlda
The SQLDA structure for returning the number, types and lengths of the input variable.
If the size of the SQLDA is not sufficient, then the field sqld_nvars is set to negative of the actual
number of input variables found. If the sqld_varnmsize field is nonzero, then the input variable
names are returned in the buffers pointed by pointers in sqld_varnames.
ca
A pointer to SQLCA structure for returning the status.
Returns
A negative error code on failure and a zero value on success is returned in the sqlcode field of
the SQLCA structure. If the call is successful, the field sqld_nvars of i_sqlda contains the number
of outputs.
Programmatic Interfaces
All Rights Reserved 196 www.faircom.com
Related Functions
dh_sqlconnect(), dh_get_curdbhdl(), dh_get_curtmhdl(), dh_set_cursor(), dh_sqlexecute(),
dh_sqlselect(), dh_sqlopen(), dh_sqlfetch(), dh_sqlprepare(), dh_sqlclose()
dh_sqldisconnect
Syntax #include “sql_lib.h”
void dh_sql_disconnect(sqlenv_hdl,format_sp, connection_name, ca)
dh_sqlenv_hdl_t sqlenv_hdl;
tpe_formattype_t format_sp;
char *connection_name;
struct sqlca *ca;
Description
Terminates the connection between an application and a database environment.
Parameters
sqlenv_hdl
c-treeSQL environment handle.
format_sp
The format specification is a #defined entity that could have any of the following four values:
SQL_DISCONNECT_CONNECTION
SQL_DISCONNECT_CURRENT
SQL_DISCONNECT_ALL
SQL_DISCONNECT_DEFAULT
connection_name
connection_name is a unique identifier, used by the application to reference the connection to a
database.
ca
The pointer to SQLCA for returning status.
Returns
On successful disconnect, a zero value is returned in ca->sqlcode.
On failure, a negative error code is returned in ca->sqlcode.
Related Functions
dh_sqlconnect(), dh_sql_setconnection()
Programmatic Interfaces
All Rights Reserved 197 www.faircom.com
dh_sqlexecute
Syntax #include “sql_lib.h”
void dh_sqlexecute(sqlenv_hdl,tmhdl, dbhdl, cursor, i_sqlda, ca)
dh_sqlenv_hdl_t sqlenv_hdl;
tpe_tm_hdl_t tmhdl;
tpe_db_hdl_t dbhdl;
tpe_cursor_t cursor;
struct sqlda *i_sqlda;
struct sqlca *ca;
Description
The dh_sqlexecute() function executes a non-select c-treeSQL statement.
Parameters
sqlenv_hdl
c-treeSQL environment handle.
tmhdl
Transaction handle.
dbhdl
Database handle.
cursor
A variable of the type tpe_cursor_t. This variable initially is expected to be NULL at the time of the
very first call to dh_set_cursor() function in a program for this cursor.
i_sqlda
A pointer to SQLDA structure containing input parameters for the c-treeSQL statement. A NULL
pointer is expected if there are no parameter references in the c-treeSQL statement.
ca
A pointer to SQLCA structure for returning the status.
Notes
The argument tmhdl should have been obtained through a successful call to either
dh_get_curtmhdl() or dh_tm_alloc_handle().
The argument dbhdl should have been obtained through a successful call to
dh_sqlconnect().
This call to dh_sqlexecute() function should be preceded by a dh_set_cursor(). For
example, see the code generated by the esqlc compiler for a non-SELECT statement.
Returns
A negative error code on failure and a zero value on success is returned in the sqlcode field of
the SQLCA structure.

Programmatic Interfaces
All Rights Reserved 198 www.faircom.com
Related Functions
dh_sqlconnect(), dh_get_curdbhdl(), dh_get_curtmhdl(), dh_set_cursor(), dh_sqldeclare(),
dh_sqlselect(), dh_sqlopen(), dh_sqlfetch(), dh_sqlprepare(), dh_sql_describe(),
dh_sqlclose()
dh_sqlfetch
Syntax #include “sql_lib.h”
void dh_sqlfetch(sqlenv_hdl,tmhdl, dbhdl, cursor, o_sqlda, ca)
dh_sqlenv_hdl_t sqlenv_hdl;
tpe_tm_hdl_t tmhdl;
tpe_db_hdl_t dbhdl;
tpe_cursor_t cursor;
struct sqlda *o_sqlda;
struct sqlca *ca;
Description
The dh_sqlfetch() function fetches one or more tuples corresponding to an open cursor. This
function call corresponds to the FETCH statement of ESQL.
Parameters
sqlenv_hdl
c-treeSQL environment handle.
tmhdl
Transaction handle.
dbhdl
Database handle.
cursor
A variable of the type tpe_cursor_t. This variable initially is expected to be NULL at the time of the
very first call to dh_set_cursor() function in a program for this cursor.
o_sqlda
A pointer to SQLDA structure containing information about the variables in which the output
parameters of the c-treeSQL statements are returned.
ca
A pointer to SQLCA structure for returning the status.
Notes
The argument tmhdl should have been obtained through a successful call to either
dh_get_curtmhdl() or dh_tm_alloc_handle().
The argument dbhdl should have been obtained through a successful call to
dh_get_curdbhdl().
Programmatic Interfaces
All Rights Reserved 199 www.faircom.com
This call to dh_sqlfetch() function should be preceded by a dh_set_cursor(). For example,
see the code generated by the esqlc compiler for a FETCH statement.
The sqld_arraysz field should be set to 1 for single tuple fetches and to the appropriate array
size (>1) for doing multiple tuple fetches in a single call. If the specified array size is greater
than one, all the variables and the non-null indicator variables are assumed to be arrays of
size greater than or equal to the specified array size.
For a multiple tuple fetch call, tuples may have been returned even if the status code returned
is SQL_NOT_FOUND. The number of tuples returned for this call is returned in
sqlca.sqlerrd[3].
Returns
A negative error code on failure and a zero value on success is returned in the sqlcode field of
the SQLCA structure. A positive status code SQL_NOT_FOUND is returned in the sqlcode field if
there are no more tuples to be fetched.
Related Functions
dh_sqlconnect(), dh_get_curdbhdl(), dh_get_curtmhdl(), dh_set_cursor(), dh_sqlexecute(),
dh_sqldeclare(), dh_sqlselect(), dh_sqlopen(), dh_sqlprepare(), dh_sql_describe(),
dh_sqlclose()
dh_sqlgetdata
Syntax #include “sql_lib.h”
void dh_sqlgetdata(sqlenv_hdl,tmhdl, dbhdl, cursor, typeid,
colhdl, buflen, offset, buf, colbal, ca)
dh_sqlenv_hdl_t sqlenv_hdl;
tpe_tm_hdl_t tmhdl;
tpe_db_hdl_t dbhdl;
tpe_cursor_t cursor;
long typeid;
void *colhdl;
long buflen;
long offset;
void *buf;
long *colbal;
struct sqlca *ca;
Description
Reads a portion of a LONGVARCHAR or LONGVARBINARY column and writes it to a buffer, and
returns the length of data remaining to be retrieved. Programs must call the dh_sqlfetch()
function before calling dh_sqlgetdata() to get the data for the column.
Parameters
sqlenv_hdl
c-treeSQL environment handle.
tmhdl
Programmatic Interfaces
All Rights Reserved 200 www.faircom.com
Transaction handle. Get this value through a successful call to dh_get_curtmhdl() or
dh_tm_alloc_handle().
dbhdl
Database handle. Get this value through a successful call to dh_get_curdbhdl().
cursor
A variable of the type tpe_cursor_t. This variable initially is expected to be NULL at the time of the
very first call to dh_set_cursor() function in a program for this cursor.
typeid
The column type. The program must set this variable to either TPE_DT_LVC or TPE_DT_LVB.
colhdl
The handle for the LONG_VARCHAR or LONG_VARBINARY column. The program must set this
variable to the value in sqlda.sqld_varptrs, which itself is set by a call to the dh_sqlfetch()
function.
buflen
The length of the portion of the column that dh_sqlgetdata() writes to the buffer.
offset
The offset, in bytes from the beginning of the VARCHAR or LONG VARBINARY column, to the
portion that dh_sqlgetdata() writes to the buffer.
buf
A pointer to the buffer containing the portion of the column that dh_sqlgetdata() writes.
colbal
The length, in bytes, of remaining data in the column from the end of the offset to the end of the
column.
ca
A pointer to SQLCA structure for returning the status.
Returns
A negative error code on failure and a zero value on success is returned in the sqlcode field of
the SQLCA structure.
Related Functions
dh_sqldeclare(), dh_sqlopen(), dh_sqlprepare(), dh_sql_describe(), dh_sqlclose(),
dh_sqlfetch()
dh_sqlopen
Syntax #include “sql_lib.h”
void dh_sqlopen(sqlenv_hdl,tmhdl, dbhdl, cursor, i_sqlda, ca)
Programmatic Interfaces
All Rights Reserved 201 www.faircom.com
dh_sqlenv_hdl_t sqlenv_hdl;
tpe_tm_hdl_t tmhdl;
tpe_db_hdl_t dbhdl;
tpe_cursor_t cursor;
struct sqlda *i_sqlda;
struct sqlca *ca;
Description
The dh_sqlopen() function opens a cursor. This function call corresponds to the OPEN statement
of ESQL.
Parameters
sqlenv_hdl
c-treeSQL environment handle.
tmhdl
Transaction handle.
dbhdl
Database handle.
cursor
A variable of the type tpe_cursor_t. This variable initially is expected to be NULL at the time of the
first call to dh_set_cursor() function in a program for this cursor.
i_sqlda
A pointer to SQLDA structure containing input parameters for the c-treeSQL statements. A NULL
pointer is expected if there are no parameter references in the c-treeSQL statement or if the
statement is static. For a static c-treeSQL statement, the input parameters are specified in the call
to dh_sql_declare() function.
ca
A pointer to SQLCA structure for returning the status.
Notes
The argument tmhdl should have been obtained through a successful call to either
dh_get_curtmhdl() or dh_tm_alloc_handle().
The argument dbhdl should have been obtained through a successful call to
dh_get_curdbhdl().
This call to dh_sqlopen() function should be preceded by a dh_set_cursor(). For example,
see the code generated by the esqlc compiler for an OPEN statement.
Returns
A negative error code on failure and a zero value on success is returned in the sqlcode field of
the SQLCA structure.

Programmatic Interfaces
All Rights Reserved 202 www.faircom.com
Related Functions
dh_sqlconnect(), dh_get_curdbhdl(), dh_get_curtmhdl(), dh_set_cursor(), dh_sqldeclare(),
dh_sqlselect(), dh_sqlexecute(), dh_sqlfetch(), dh_sqlprepare(), dh_sql_describe(),
dh_sqlclose()
dh_sqlprepare
Syntax #include “sql_lib.h”
void dh_sqlprepare(sqlenv_hdl,tmhdl, dbhdl, cursor, ca)
dh_sqlenv_hdl_t sqlenv_hdl;
tpe_tm_hdl_t tmhdl;
tpe_db_hdl_t dbhdl;
tpe_cursor_t cursor;
struct sqlca *ca;
Description
The dh_sqlprepare() function prepares a dynamic select/non-select c-treeSQL statement. This
function call corresponds to the PREPARE statement of ESQL.
Parameters
sqlenv_hdl
c-treeSQL environment handle.
tmhdl
Transaction handle.
dbhdl
Database handle.
cursor
A variable of the type tpe_cursor_t. This variable initially is expected to be NULL at the time of the
first call to dh_set_cursor() function in a program for this cursor.
ca
A pointer to SQLCA structure for returning the status.
Notes
The argument tmhdl should have been obtained through a successful call to either
dh_get_curtmhdl() or dh_tm_alloc_handle().
The argument dbhdl should have been obtained through a successful call to
dh_get_curdbhdl().
A dynamic non-select statement has to be prepared before it can be executed. A dynamic
select statement has to be prepared before the corresponding cursor can be opened.
This call to dh_sqlprepare() function should be preceded by a dh_set_cursor(). For
example, see the code generated by the esqlc compiler for a PREPARE statement.

Programmatic Interfaces
All Rights Reserved 203 www.faircom.com
Returns
A negative error code on failure and a zero value on success is returned in the sqlcode field of
the SQLCA structure.
Related Functions
dh_sqlconnect(), dh_get_curdbhdl(), dh_get_curtmhdl(), dh_set_cursor(), dh_sqldeclare(),
dh_sqlselect(), dh_sqlexecute(), dh_sqlfetch(), dh_sqlprepare(), dh_sql_describe(),
dh_sqlclose()
dh_sqlselect
Syntax #include “sql_lib.h”
void dh_sqlselect(sqlenv_hdl,tmhdl, dbhdl, cursor, i_sqlda, o_sqlda, ca)
dh_sqlenv_hdl_t sqlenv_hdl;
tpe_tm_hdl_t tmhdl;
tpe_db_hdl_t dbhdl;
tpe_cursor_t cursor;
struct sqlda *i_sqlda;
struct sqlda *o_sqlda;
struct sqlca *ca;
Description
The dh_sqlselect() function performs a single-tuple select. This function call corresponds to the
SELECT .... INTO ... statement of ESQL.
Parameters
sqlenv_hdl
c-treeSQL environment handle.
tmhdl
Transaction handle.
dbhdl
Database handle.
cursor
A variable of the type tpe_cursor_t. This variable is expected to be NULL at the time of the first
call to dh_set_cursor() function in a program for this cursor.
i_sqlda
A pointer to SQLDA structure containing input parameters for the c-treeSQL statements. A NULL
pointer is expected if there are no parameter references in the c-treeSQL statement.
o_sqlda
A pointer to SQLCA structure containing information about output parameters for the c-treeSQL
statement.

Programmatic Interfaces
All Rights Reserved 204 www.faircom.com
ca
A pointer to SQLCA structure for returning the status.
Notes
The argument tmhdl should have been obtained through a successful call to either
dh_get_curtmhdl() or dh_tm_alloc_handle().
The argument dbhdl should have been obtained through a successful call to
dh_sqlconnect().
This call to dh_sqlselect() function should be preceded by a dh_set_cursor(). For example,
see the code generated by the esqlc compiler for a SELECT .... INTO ... statement.
Returns
A negative error code on failure and a zero value on success is returned in the sqlcode field of
the SQLCA structure.
Related Functions
dh_sqlconnect(), dh_get_curdbhdl(), dh_get_curtmhdl(), dh_sqlopen(), dh_set_cursor(),
dh_sqldeclare(), dh_sqlselect(), dh_sqlexecute(), dh_sqlfetch(), dh_sqlprepare(),
dh_sql_describe(), dh_sqlclose()
dh_tm_alloc_handle
Syntax #include “sql_lib.h”
tpe_tm_hdl_t dh_tm_alloc_handle();
Description
Allocates and initializes a transaction handle that can be used to start a transaction. The
transaction handle maintains the current state of the transaction and the transaction can be
passed across clients and servers to execute database operations as a single atomic transaction.
Notes
The transaction handle is initialized to contain the identification of the user on whose behalf
the transaction handle has been created. The identification is used when executing database
operations on behalf of the user on the database.
A transaction/sub-transaction can be started by invoking the dh_tm_begin_trans() with the
allocated transaction handle.
A transaction/sub-transaction can be committed by invoking the dh_tm_end_trans() with the
transaction handle.
Returns
Returns an initialized transaction handle.
Related Functions
dh_get_curtmhdl(), dh_tm_begin_trans(), dh_tm_end_trans(), dh_tm_mark_abort()

Programmatic Interfaces
All Rights Reserved 205 www.faircom.com
dh_tm_begin_trans
Syntax #include “sql_lib.h”
void dh_tm_begin_trans(sqlenv_hdl,trans_level, tmhdl, ca)
dh_sqlenv_hdl_t sqlenv_hdl;
tpe_tm_trans_level_t trans_level;
tpe_tm_hdl_t tmhdl;
struct sqlca *ca;
Description
Starts a transaction/sub-transaction in the ESQL program. The transaction handle is modified by
the function to reflect the current state of the transaction.
Parameters
sqlenv_hdl
c-treeSQL environment handle.
trans_level
Specifies the transaction level. The only valid value for this parameter currently is
TR_LVL_STRICT.
tmhdl
The transaction handle.
ca
Points to SQLCA structure for returning the status.
Notes
The argument tmhdl should have been obtained through a successful call to either
dh_get_curtmhdl() or dh_tm_alloc_handle().
For every dh_tm_begin_trans() a corresponding dh_tm_end_trans() should be executed to
preserve the consistency of the transaction handle.
The calls to dh_tm_begin_trans() can be nested to start sub-transactions within the same
and/or different processes but the transaction will be committed only when the outer most
dh_tm_end_trans() is executed.
A c-treeSQL statement can be executed successfully only if there is a current transaction,
started by the dh_tm_begin_trans() function, associated with the current transaction handle.
Returns
A negative error code on failure or a value zero on success is returned in ca->sqlcode.
Related Functions
dh_tm_alloc_handle(), dh_tm_end_trans(), dh_tm_mark_abort()
Programmatic Interfaces
All Rights Reserved 206 www.faircom.com
dh_tm_end_trans
Syntax #include “sql_lib.h”
void dh_tm_end_trans(sqlenv_hdl,tmhdl, ca)
dh_sqlenv_hdl_t sqlenv_hdl;
tpe_tm_hdl_t tmhdl;
struct sqlca *ca;
Description
The dh_tm_end_trans() has a different behavior depending on the state of the transaction which
is maintained in the transaction handle. The following list describes the behavior when the
function is executed:
If this corresponds to the end of a transaction which has not been marked for abort then it is
equivalent to committing the transaction.
If this corresponds to the end of a transaction which has been marked for abort then it is
equivalent to rolling back the transaction.
Parameters
sqlenv_hdl
c-treeSQL environment handle.
tmhdl
A transaction handle associated with the transaction.
ca
Points to SQLCA structure for returning the status.
Notes
For each call to the dh_tm_begin_trans() there should be a corresponding call to the
dh_tm_end_trans() function in the same process to preserve the consistency of the
transaction handle.
The dh_tm_end_trans() function call modifies the transaction handle to set the correct state
of the transaction.
Returns
A negative error code on failure or a value zero on success is returned in ca->sqlcode.
Related Functions dh_tm_begin_trans, dh_tm_mark_abort
dh_tm_mark_abort
Syntax #include “sql_lib.h”
void dh_tm_mark_abort(sqlenv_hdl,tmhdl, ca)
dh_sqlenv_hdl_t sqlenv_hdl;

Programmatic Interfaces
All Rights Reserved 207 www.faircom.com
tpe_tm_hdl_t *tmhdl;
struct sqlca *ca;
Description
Marks a transaction for abortion but does not perform the rollback of the database modifications
at this point. The database is rolled back when the appropriate dh_tm_end_trans() is executed.
Parameters
sqlenv_hdl
c-treeSQL environment handle.
tmhdl
The transaction handle.
Notes
The transaction handle is updated to reflect that the transaction has been marked for
abortion.
Modification on a database are rolled back when the outer most transaction/sub-transaction
on that database executes the dh_tm_end_trans() function.
No c-treeSQL statements can be executed successfully on behalf of a transaction that has
been marked for abort.
Returns
A negative error code on failure or a value zero on success is returned in ca->sqlcode.
Related Functions
dh_tm_begin_trans(), dh_tm_end_trans()
dh_sqlputdata
Syntax #include "sql_lib.h"
void dh_sqlputdata (sqlenv_hdl,tmhdl, dbhdl, cursor, typeid,
colhdl, buflen, buflen, offset, buf, ca);
dh_sqlenv_hdl_t sqlenv_hdl;
tpe_tm_hdl_t tmhdl;
tpe_db_hdl_t dbhdl;
tpe_cursor_t cursor;
dh_i32_t typeid;
void *colhdl;
dh_i32_t buflen;
dh_i32_t offset;
void *buf;
struct sqlca * ca;
Programmatic Interfaces
All Rights Reserved 208 www.faircom.com
Description
Put a piece of data into a field of LONG type. Assumed that an insertion/update was done
previous to this call.
Parameters
sqlenv_hdl
c-treeSQL environment handle.
tmhdl
Transaction handle. Get this value through a successful call to dh_get_curtmhdl() or
dh_tm_alloc_handle().
dbhdl
Database handle. Get this value through a successful call to dh_get_curdbhdl().
cursor
A variable of the type tpe_cursor_t. This variable initially is expected to be NULL at the time of the
very first call to dh_set_cursor() function in a program for this cursor.
typeid
The column type. The program must set this variable to either TPE_DT_LVC or TPE_DT_LVB.
colhdl
The handle for the LONG_VARCHAR or LONG_VARBINARY column. The program must set this
variable to the value in sqlda.sqld_varptrs, which itself is set by a call to the dh_sqlfetch()
function.
buflen
The length of the portion of the column that dh_sqlputdata() writes to the buffer.
offset
The offset, in bytes from the beginning of the VARCHAR or LONG VARBINARY column, to the
portion that dh_sqlputdata() writes to the buffer.
buf
A pointer to the buffer containing the portion of the column that dh_sqlputdata() writes.
ca
A pointer to SQLCA structure for returning the status.
Returns
A negative error code on failure and a zero value on success is returned in the sqlcode field of
the SQLCA structure.
Related Functions
dh_cancel(), dh_sqlexecute()

Programmatic Interfaces
All Rights Reserved 209 www.faircom.com
dh_sqlallocdesc
Syntax void dh_sqlallocdesc(sqlenv_hdl,desc_name, num_item , sqlca )
dh_sqlenv_hdl_t sqlenv_hdl;
dh_char_t *desc_name;
dh_i32_t num_item;
struct sqlca *sqlca;
Description
The dh_sqlallocdesc() function allocates memory for a new c-treeSQL Descriptor Area. Before
allocation this function checks whether the list exists. If yes check whether the desc_name is
already allocated. If yes return error. If no allocate using sqld_alloc() (use sqlda_t). If no list,
create the list and allocate.
Before allocating check whether the size exceeds the maximum. This function corresponds to the
ALLOCATE DESCRIPTOR function of ESQL.
Parameters
sqlenv_hdl
c-treeSQL environment handle.
desc_name
Descriptor name.
num_item
Number of item.
sqlca
A pointer to SQLCA structure for returning the status.
Returns
A negative error code on failure and a zero value on success is returned in the sqlcode field of
the SQLCA structure.
dh_sqlgetsqldaptr
Syntax struct sqlda *sqlda_ptr =
dh_sqlgetsqldaptr(sqlenv_hdl,desc_name,&sqlca)
dh_sqlenv_hdl_t sqlenv_hdl;
dh_char_t *desc_name;
struct sqlca *sqlca;
Description
The dh_sqlgetsqldaptr() function returns the c-treeSQL Descriptor Area Pointer, given the
descriptor name that was allocated before.
Programmatic Interfaces
All Rights Reserved 210 www.faircom.com
Parameters
sqlenv_hdl
c-treeSQL environment handle.
desc_name
Descriptor name.
sqlca
A pointer to SQLCA structure for returning the status.
sqlda_ptr
Pointer to SQLDA .
Returns
A negative error code on failure and a zero value on success is returned in the sqlcode field of
the SQLCA structure.
dh_sqldeallocdesc
Syntax void dh_sqldeallocdesc(sqlenv_hdl,desc_name , sqlca)
dh_sqlenv_hdl_t sqlenv_hdl;
dh_char_t *desc_name;
struct sqlca *sqlca;
Description
The dh_sqldeallocdesc() function deallocates the already allocated c-treeSQL Descriptor Area.
Before deallocation this function checks whether the list exists. If not returns error. If yes checks
whether the desc_name is allocated. If yes deallocates using sqld_free() and
sqld_dealloc_buffer(). This function corresponds to the DEALLOCATE DESCRIPTOR function of
ESQL.
Parameters
sqlenv_hdl
c-treeSQL environment handle.
desc_name
Descriptor name.
sqlca
A pointer to SQLCA structure for returning the status.
Returns
A negative error code on failure and a zero value on success is returned in the sqlcode field of
the SQLCA structure.

Programmatic Interfaces
All Rights Reserved 211 www.faircom.com
dh_sqlgetdesc
Syntax void dh_sqlgetdesc (sqlenv_hdl,sqlda_ptr, item_num, tgt_lst,
lst_length,sqlca)
dh_sqlenv_hdl_t sqlenv_hdl;
struct sqlda *sqlda_ptr;
dh_i32_t item_num;
item_lst *tgt_lst;
dh_i32_t lst_length;
struct sqlca *sqlca;
Description
The dh_sqlgetdesc() function gets the information about the particular item in a particular
c-treeSQL Descriptor Area. This function corresponds to the GET DESCRIPTOR function of ESQL.
Parameter
sqlenv_hdl
c-treeSQL environment handle.
sqlda_ptr
A pointer to SQLDA structure.
item_num
Integer that identifies a specific item in the Descriptor Area.
tgt_lst
Pointer to structure containing the field and host variable information. Following is the structure.
item_lst
typedef struct {
descr_kwd_t field_info[DESC_MAX_VAR];
dh_char_t ** host_info;
dh_boolean is_const[DESC_MAX_VAR];
}item_lst;
field_info
An array of enumerated field type descr_kwd_t. Following is the structure for Enumerated data
type descr_kwd_t:
typedef enum {
COUNT_T,
TYPE_T,
LEN_T,
OCT_LEN_T,
RET_LEN_T,
PREC_T,
SCALE_T,
DATE_INT_CODE_T,
DATE_INT_PREC_T,
NULL_T,
NAME_T,
UNNAMED_T,

Programmatic Interfaces
All Rights Reserved 212 www.faircom.com
COLLAT_NAME_T,
CHAR_SET_NAME_T,
DAT_T,
IND_T,
COL_NAME_T,
TBL_NAME_T,
CS_T,
SEARCH_T,
UNSIGN_T,
UPD_T,
PARAM_T,
TBL_T,
AUTO_T,
VERBOSE_T
}descr_kwd_t;
For more details on the elements of descr_kwd_t data type, refer to the table Descriptor Item
Name.
host_info
An array of host variables.
is_const
Array of boolean to store the constant information for the related field of field_info.
lst_length
Number of fields.
sqlca
A negative error code on failure and a zero value on success is returned in the sqlcode field of
the SQLCA structure.
Returns
A negative error code on failure and a zero value on success is returned in the sqlcode field of
the SQLCA structure.
dh_sqlsetdesc
Syntax void dh_sqlsetdesc(sqlenv_hdl,sqlda_ptr, item_num, &it_lst,
num_of_tgt, &sqlca)
dh_sqlenv_hdl_t sqlenv_hdl;
struct sqlda *sqlda_ptr;
dh_i32_t item_num;
item_lst it_lst;
dh_i32_t num_of_tgt;
struct sqlca sqlca;
Description
The dh_sqlsetdesc() function sets the information about a particular item in a particular SQL
Descriptor Area. This function corresponds to the SET DESCRIPTOR function of ESQL.

Programmatic Interfaces
All Rights Reserved 213 www.faircom.com
Parameter
sqlenv_hdl
c-treeSQL environment handle.
sqlda_ptr
A pointer to SQLDA structure.
item_num
Integer that identifies a specific item in the Descriptor Area.
tgt_lst
Pointer to structure containing the field and host variable information. Refer to the parameter
“item_1st” in "dh_sqlgetdesc" (page 211).
lst_length
Number of fields.
sqlca
A negative error code on failure and a zero value on success is returned in the sqlcode field of
the SQLCA structure.
Returns
A negative error code on failure and a zero value on success is returned in the sqlcode field of
the SQLCA structure.
dh_sqlgetdiag
Syntax void dh_sqlgetdiag (sqlenv_hdl,arg_sqlca, fld_arr, arr_length,
status_recnum, diagstate, o_sqlda);
dh_sqlenv_hdl_t sqlenv_hdl;
struct sqlca *arg_sqlca;
diag_kwd_t *fld_arr;
dh_i16_t arr_length;
dh_i32_t status_recnum;
dh_char_t *diagstate;
struct sqlda *o_sqlda;
Description
The dh_sqlgetdiag() function returns the current value of a field of a record of the diagnostic
data structure that contains error, warning, and status information.
The contents of the diagnostics structure data members are copied to the osqlda, after making
some validation on the data types and diagnostics field names.
Parameter
sqlenv_hdl
Programmatic Interfaces
All Rights Reserved 214 www.faircom.com
c-treeSQL environment handle.
arg_sqlca
Diagnostics struct pointer.
fld_arr
Array of diagnostics fields.
arr_length
Length of the diag_kwd_t.
status_recnum
Detail area number.
diagstate
Sqlstate for this statement.
o_sqlda
Output SQLDA.
Returns
A negative error code on failure and a zero value on success is returned in the sqlcode field of
the o_sqlda structure.
dh_tm_set_level
Syntax dh_tm_set_level(sqlenv_hdl,isln_lvl, sqlca);
dh_sqlenv_hdl_t sqlenv_hdl;
tpe_tm_isolation_lvl_t sln_lvl;
struct sqlca sqlca;
Description
The dh_tm_set_level() function sets the degree to which one transaction can interfere with other
transactions while accessing the same rows concurrently. This function corresponds to the SET
TRANSLATION ISOLATION LEVEL function of ESQL.
Parameter
sqlenv_hdl
c-treeSQL environment handle.
isln_lvl
Isolation level.
sqlca
A negative error code on failure and a zero value on success is returned in the sqlcode field of
the SQLCA structure.

Programmatic Interfaces
All Rights Reserved 215 www.faircom.com
dh_sqltables
Description
The dh_sqltables() returns the list of table, catalog, or schema names, and table types, stored in
a specific data source. The corresponding c-treeSQL ODBC API is SQLTables().
dh_sqlcolumns
Description
The dh_sqlcolumns() returns the list of column names in specified tables. The corresponding
c-treeSQL ODBC API is SQLColumns().
dh_sqlstatistics
Description
The dh_sqlstatistics() retrieves a list of statistics about a single table and the indices associated
with the table. The corresponding c-treeSQL ODBC API is SQLStatistics().
dh_sqlprimarykeys
Description
The dh_sqlprimarykeys() returns the column names that make up the primary key for a table.
The corresponding c-treeSQL ODBC API is SQLPrimaryKeys().
dh_sqlforeignkeys
Description
The dh_sqlforeignkeys() returns a list of foreign keys in the specified table. The corresponding
c-treeSQL ODBC API is SQLForeignKeys().

All Rights Reserved 216 www.faircom.com
17. Sample ESQL Programs
17.1 Static Non-Select Statements
Compiling and Running E:\v621\esql_samples> esqlc -o dynamic_select dynamic_select.pc
FairCom/esqlc
1 file(s) copied.
Microsoft (R) 32-bit C/C++ Optimizing Compiler Version 11.00.7022 for 80x86
Copyright (C) Microsoft Corp 1984-1997. All rights reserved.
static_non_select.c
Creating library static_non_select.lib and object static_non_select.exp
E:\v621\esql_samples> static_non_select
Static non-select statement executed successfully
E:\v621\esql_samples>
Program Source Code
The following is the complete code listing of an ESQL program for demonstrating the use of static
non-SELECT statements.
/*
* Copyright (C) Dharma Systems Inc. 1988-97.
* Copyright (C) Dharma Computers (P) Ltd. 1988-97.
*
* This Module contains Proprietary Information of
* Dharma Systems Inc. and Dharma Computers (P) Ltd.
* and should be treated as Confidential.
*/
/*
* Example program showing usage of static non-select statements.
*/
#include "stdio.h"
#include "sql_lib.h"
#include "string.h"
#include "stdlib.h"
static void static_update () ;
main ()
{
/* Connect to the default database */

Sample ESQL Programs
All Rights Reserved 217 www.faircom.com
EXEC SQL CONNECT TO DEFAULT USER 'hum';
/* Call function to execute a static non-select statement */
static_update () ;
/* Disconnect from the database */
EXEC SQL
DISCONNECT DEFAULT ;
exit (0) ;
err:
if (sqlca.sqlcode)
{
printf ("SQL Error (%ld) %s\\n",
sqlca.sqlcode, sqlca.sqlerrm) ;
exit (1) ;
}
}
/*
* static_update : demonstrates the usage of
* a static non-select statement.
* Updates quantity in orders table.
*/
static void static_update ()
{
char errmesg[80];
EXEC SQL BEGIN DECLARE SECTION ;
short order_no_v ;
EXEC SQL END DECLARE SECTION ;
/* Handle error conditions when SQLERROR or when SQL_NOT_FOUND */
EXEC SQL
WHENEVER SQLERROR GOTO err ;
EXEC SQL
WHENEVER NOT FOUND GOTO err ;
/* Set order number */
order_no_v = 341 ;
/* Update Orders table */
EXEC SQL
UPDATE orders
SET cust_no = 100011
WHERE order_no = :order_no_v ;
EXEC SQL COMMIT WORK ;
printf ("\nStatic non-select statement executed successfully\n") ;
return ;
err:
if (sqlca.sqlcode == SQL_NOT_FOUND)
{
fprintf (stderr, "Order entry not found in table\\n\\n");
}
else
if (sqlca.sqlcode < 0)
{

Sample ESQL Programs
All Rights Reserved 218 www.faircom.com
strncpy (errmesg, sqlca.sqlerrm, sqlca.sqlerrml);
errmesg [sqlca.sqlerrml] = '\\0' ;
fprintf (stderr, "SQL Error : %s\\n", errmesg);
}
EXEC SQL
WHENEVER SQLERROR CONTINUE;
EXEC SQL
ROLLBACK WORK ;
exit (1);
}
17.2 Static SELECT Statements
Compiling and Running E:\v621\esql_samples> esqlc -o dynamic_select dynamic_select.pc
FairCom/esqlc
1 file(s) copied.
Microsoft (R) 32-bit C/C++ Optimizing Compiler Version 11.00.7022 for 80x86
Copyright (C) Microsoft Corp 1984-1997. All rights reserved.
static_select.c
Creating library static_select.lib and object static_select.exp
E:\v621\esql_samples> static_select
orders
orders
Static select statement executed successfully
E:\v621\esql_samples>
Program Source Code
The following is the complete code listing of an ESQL program for demonstrating the use of static
SELECT statements.
/*
* Copyright (C) Dharma Systems Inc. 1988-97.
* Copyright (C) Dharma Computers (P) Ltd. 1988-97.
*
* This Module contains Proprietary Information of
* Dharma Systems Inc. and Dharma Computers (P) Ltd.
* and should be treated as Confidential.
*/
/*
* Example program showing usage of static select statements.
*
*/
#include "stdio.h"
#include "sql_lib.h"

Sample ESQL Programs
All Rights Reserved 219 www.faircom.com
#include "string.h"
#include "stdlib.h"
static void static_select () ;
main ()
{
/* Connect to the default database */
EXEC SQL CONNECT TO DEFAULT USER 'hum';
/* Handle error conditions */
EXEC SQL
WHENEVER SQLERROR GOTO err ;
/* Call function to execute a static select statement */
static_select () ;
/* Disconnect from the database */
EXEC SQL
DISCONNECT DEFAULT ;
exit (0) ;
err:
if (sqlca.sqlcode)
{
printf ("SQL Error (%ld) %s\\n",
sqlca.sqlcode, sqlca.sqlerrm) ;
exit (1) ;
}
}
/*
* static_select : demonstrates the usage of
* a static select statement.
* Gets the list of tables whose names do not have a prefix 'sys'.
*/
static void static_select ()
{
char errmesg[80];
EXEC SQL BEGIN DECLARE SECTION ;
char tname [20] ;
EXEC SQL END DECLARE SECTION ;
/* Handle error conditions when SQLERROR */
EXEC SQL
WHENEVER SQLERROR GOTO err ;
EXEC SQL
DECLARE stcur CURSOR FOR
SELECT tbl
FROM admin.systables
WHERE TBL NOT LIKE :tname ;
/* Note: the input parameter value should be set
* before the cursor is opened.
*/
strcpy (tname, "sys%") ;

Sample ESQL Programs
All Rights Reserved 220 www.faircom.com
/* Note: For static statements, if the declare cursor
* statement contains references to auto variables,
* OPEN statement should be in the same C function.
*/
EXEC SQL OPEN stcur ;
EXEC SQL WHENEVER NOT FOUND GOTO over ;
for (;;)
{
tname [0] = '\0' ;
EXEC SQL FETCH stcur INTO :tname ;
printf ("%s \n", tname) ;
}
over:
EXEC SQL CLOSE stcur ;
EXEC SQL COMMIT WORK ;
printf ("Static select statement executed successfully\n") ;
return ;
err:
if (sqlca.sqlcode < 0)
{
strncpy (errmesg, sqlca.sqlerrm, sqlca.sqlerrml);
errmesg [sqlca.sqlerrml] = '\\0' ;
fprintf (stderr, "SQL Error : %s\\n", errmesg);
}
EXEC SQL
WHENEVER SQLERROR CONTINUE;
EXEC SQL
ROLLBACK WORK ;
exit (1);
}
/* end */
17.3 Dynamic Non-SELECT Statements
Compiling and Running E:\v621\esql_samples> esqlc -o dynamic_select dynamic_select.pc
FairCom/esqlc
1 file(s) copied.
Microsoft (R) 32-bit C/C++ Optimizing Compiler Version 11.00.7022 for 80x86
Copyright (C) Microsoft Corp 1984-1997. All rights reserved.
dynamic_non_select.c

Sample ESQL Programs
All Rights Reserved 221 www.faircom.com
Creating library dynamic_non_select.lib and object dynamic_non_select.exp
E:\v621\esql_samples> dynamic_non_select
Current cust_no for order number = 342 is 342
Order number 342 updated
Current cust_no for order number = 343 is 343
Order number 343 updated
Dynamic non-select statement executed successfully
Program Source Code
The following is the complete code listing of an ESQL program for demonstrating the use of
dynamic non-SELECT statements.
/*
* Copyright (C) Dharma Systems Inc. 1988-97.
* Copyright (C) Dharma Computers (P) Ltd. 1988-97.
*
* This Module contains Proprietary Information of
* Dharma Systems Inc. and Dharma Computers (P) Ltd.
* and should be treated as Confidential.
*/
/*
* Example program showing usage of dynamic non-select statements.
*
*/
#include "stdio.h"
#include "sql_lib.h"
#include "string.h"
#include "stdlib.h"
static void dynamic_update () ;
main ()
{
/* Connect to the default database */
EXEC SQL CONNECT TO DEFAULT USER 'hum';
/* Call function to execute a dynamic non-select statement */
dynamic_update () ;
/* Disconnect from the database */
EXEC SQL
DISCONNECT DEFAULT ;
exit (0) ;
err:
if (sqlca.sqlcode)
{
printf ("SQL Error (%ld) %s\\n",
sqlca.sqlcode, sqlca.sqlerrm) ;
exit (1) ;
}
}
/*
* dynamic_update : demonstrates the use of a dynamic non-select statement.
* updates the orders table.

Sample ESQL Programs
All Rights Reserved 222 www.faircom.com
*/
static void dynamic_update ()
{
char errmesg[80];
EXEC SQL BEGIN DECLARE SECTION ;
char stmt[1024] ;
long cust_no;
long qty_v ;
short order_no_v ;
EXEC SQL END DECLARE SECTION ;
order_no_v = 341;
qty_v = 10001;
strcpy (stmt,
"update orders set cust_no = qty_v where order_no = :order_no_v ") ;
/* Prepare the SQL statement */
EXEC SQL PREPARE stmtid FROM :stmt ;
for (order_no_v = 342 ; order_no_v <= 343 ; order_no_v++)
{
EXEC SQL
SELECT order_no
INTO :cust_no
FROM orders
WHERE order_no = :order_no_v ;
printf ("Current cust_no for order number = %d is %d\n",
order_no_v, cust_no) ;
/* Execute the prepared statement with values */
EXEC SQL EXECUTE stmtid USING :cust_no, :order_no_v ;
printf ("Order number %d updated\n", order_no_v) ;
}
EXEC SQL COMMIT WORK ;
printf ("Dynamic non-select statement executed successfully\n") ;
return ;
err:
if (sqlca.sqlcode == SQL_NOT_FOUND)
{
fprintf (stderr, "Order entry not found in table\\n\\n");
}
else
if (sqlca.sqlcode < 0)
{
strncpy (errmesg, sqlca.sqlerrm, sqlca.sqlerrml);
errmesg [sqlca.sqlerrml] = '\\0' ;
fprintf (stderr, "SQL Error : %s\\n", errmesg);
}
EXEC SQL
WHENEVER SQLERROR CONTINUE;
EXEC SQL
ROLLBACK WORK ;
exit (1);
}

Sample ESQL Programs
All Rights Reserved 223 www.faircom.com
17.4 Dynamic SELECT Statements
Compiling and Running E:\v621\esql_samples> esqlc -o dynamic_select dynamic_select.pc
FairCom/esqlc
1 file(s) copied.
Microsoft (R) 32-bit C/C++ Optimizing Compiler Version 11.00.7022 for 80x86
Copyright (C) Microsoft Corp 1984-1997. All rights reserved.
dynamic_select.c
Creating library dynamic_select.lib and object dynamic_select.exp
E:\v621\esql_samples> dynamic_select
nflds = 2 ;
fldnames : order_no cust_no
types : [4, 4] ; lengths : [4, 4]
order_no =341 cust_no =10001
order_no =342 cust_no =10001
order_no =343 cust_no =10001
order_no =344 cust_no =10002
order_no =345 cust_no =10002
order_no =346 cust_no =10002
order_no =347 cust_no =10009
nflds = 2 ;
fldnames : order_no cust_no
types : [4, 4] ; lengths : [4, 4]
order_no =341 cust_no =10001
order_no =342 cust_no =10001
order_no =343 cust_no =10001
order_no =344 cust_no =10002
order_no =345 cust_no =10002
order_no =346 cust_no =10002
order_no =347 cust_no =10009
nflds = 2 ;
fldnames : order_no cust_no
types : [4, 4] ; lengths : [4, 4]
order_no =341 cust_no =10001
order_no =342 cust_no =10001
order_no =343 cust_no =10001
order_no =344 cust_no =10002
order_no =345 cust_no =10002
order_no =346 cust_no =10002
order_no =347 cust_no =10009
Dynamic select statement executed successfully
E:\v621\esql_samples>
Program Source code
The following is the complete code listing of an ESQL program for demonstrating the use of
dynamic SELECT statements.

Sample ESQL Programs
All Rights Reserved 224 www.faircom.com
/*
* Copyright (C) Dharma Systems Inc. 1988-97.
* Copyright (C) Dharma Computers (P) Ltd. 1988-97.
*
* This Module contains Proprietary Information of
* Dharma Systems Inc. and Dharma Computers (P) Ltd.
* and should be treated as Confidential.
*/
/*
* Example program showing usage of dynamic select statements.
*
*/
#include"stdio.h"
#include"sql_lib.h"
#include "string.h"
#include "stdlib.h"
static void dynamic_select () ;
static void usage (prog)
char *prog ;
{
fprintf (stderr, "Usage: %s <dbname>\\n\\n", prog) ;
exit (1) ;
}
main()
{
/* Connect to the default database */
EXEC SQL CONNECT TO DEFAULT USER 'hum';
/* Call function to execute a dynamic select statement */
dynamic_select () ;
/* Disconnect from the database */
EXEC SQL
DISCONNECT DEFAULT ;
exit (0) ;
err:
if (sqlca.sqlcode)
{
printf ("SQL Error (%ld) %s\\n", sqlca.sqlcode, sqlca.sqlerrm) ;
exit (1) ;
}
}
/*
* dynamic_select : demonstrates the use of
* a dynamic select statement.
* Gets quantity and product name from orders
* table for order numbers less than x.
* x is 1002 in the first iteration
* and 1004 in the last iteration.
*/
static void dynamic_select ()
{
char errmesg[80];
struct sqlda *sqldaptr ;

Sample ESQL Programs
All Rights Reserved 225 www.faircom.com
EXEC SQL BEGIN DECLARE SECTION ;
char stmt [1024] ;
short order_no_v ;
long qty_v ;
char cust_v [30] ;
EXEC SQL END DECLARE SECTION ;
order_no_v = 342;
strcpy (stmt,
"select order_no, cust_no from orders where order_no < :order_no_v") ;
/* Handle error conditions when SQLERROR */
EXEC SQL
WHENEVER SQLERROR GOTO err ;
EXEC SQL PREPARE stmtid FROM :stmt ;
EXEC SQL DECLARE dyncur CURSOR FOR stmtid ;
for (order_no_v = 1002 ; order_no_v <= 1004 ; order_no_v++)
{
EXEC SQL OPEN dyncur USING :order_no_v ;
/* maxvars = 2, varnmsz = 20 */
if (!(sqldaptr = sqld_alloc (2, 20)))
{
fprintf (stderr, "sqld_alloc returned err\\n") ;
goto err ;
}
/* Note: sqldaptr in the following statement is not
* declared ESQL DECLARE section.
*/
for (;;)
{
short nvars ;
EXEC SQL DESCRIBE SELECT LIST FOR stmtid INTO sqldaptr ;
if ((nvars = sqldaptr->sqld_nvars) < 0)
{
sqld_free (sqldaptr) ;
if (!(sqldaptr = sqld_alloc (-(nvars), 20)))
{
fprintf (stderr, "sqld_alloc returned err\\n") ;
goto err ;
}
continue ;
}
break ;
}
printf ("\n nflds = %d ;\n fldnames : %s %s \n",
sqldaptr->sqld_nvars,
sqldaptr->sqld_varnames [0],
sqldaptr->sqld_varnames [1]) ;
printf ("types : [%d, %d] ; lengths : [%d, %d]\n",
sqldaptr->sqld_types [0],
sqldaptr->sqld_types [1],
sqldaptr->sqld_lengths [0],
sqldaptr->sqld_lengths [1]) ;
fflush (stdout);

Sample ESQL Programs
All Rights Reserved 226 www.faircom.com
sqldaptr->sqld_varptrs [0] = (char *) &qty_v ;
sqldaptr->sqld_varptrs [1] = (char *) &cust_v [0] ;
EXEC SQL
WHENEVER NOT FOUND GOTO over ;
for (;;)
{
EXEC SQL FETCH dyncur INTO :qty_v, :cust_v ;
printf ("order_no =%d cust_no =%s\n", qty_v, cust_v) ;
fflush (stdout);
}
over:
printf ("\n") ; fflush (stdout);
EXEC SQL CLOSE dyncur ;
sqld_free (sqldaptr) ; sqldaptr = (struct sqlda *)0 ;
}
EXEC SQL COMMIT WORK ;
printf ("Dynamic select statement executed successfully\n") ;
return ;
err:
if (sqlca.sqlcode < 0)
{
strncpy (errmesg, sqlca.sqlerrm, sqlca.sqlerrml);
errmesg [sqlca.sqlerrml] = '\\0' ;
fprintf (stderr, "SQL Error : %s\\n", errmesg);
}
if (sqldaptr) sqld_free (sqldaptr) ;
EXEC SQL
WHENEVER SQLERROR CONTINUE;
EXEC SQL
ROLLBACK WORK ;
exit (1);
}
17.5 Long Data Type Support
Sample ESQLC Program for lvarchar Data Type
The following is the complete code listing of an ESQL program for demonstrating the use of
tpe_sqlgetdata() and tpe_sqlputdata() for LVARCHAR column.
/*
* Copyright (C) Dharma Systems Inc. 1988-2003.
* Copyright (C) Dharma Systems (P) Ltd. 1988-2003.
*
* This Module contains Proprietary Information of
* Dharma Systems Inc. and Dharma Systems (P) Ltd.
* and should be treated as Confidential.

Sample ESQL Programs
All Rights Reserved 227 www.faircom.com
*/
/*
* Purpose :
* Example program showing the usage long varchar
* data type of Dharma/SQL.
*
* The following functionalities are covered in this test :
* # Insert using tpe_sqlputdata().
* # Fetch using tpe_sqlgetdata().
*
*/
#include "stdio.h"
#include "string.h"
#include "stdlib.h"
#include "sql_lib.h"
/*
* Inserting the data using tpe_sqlputdata().
*/
void insert_part()
{
dh_i32_t fe_offset;
int i, data_buflen;
EXEC SQL BEGIN DECLARE SECTION;
/* New handle of lvarchar is declared. */
lvc_fld_hdl_t fld_hdl_buffer;
char data_buf[101];
char stmt[100];
EXEC SQL END DECLARE SECTION;
/* Prepare insert statement. */
printf("Inserting into table longvar by parts ...\n");
/* Set 50 bytes data. */
memset(data_buf, 'A', 50);
data_buflen = strlen(data_buf);
strcpy ( stmt, "INSERT INTO longvar VALUES (?)");
EXEC SQL prepare S1 from :stmt;
/* Handle returned from server is stored in fld_hdl_buffer. */
EXEC SQL execute S1 USING :fld_hdl_buffer;
if ( sqlca.sqlcode == 0 )
printf ("Got the field handle value." );
else
{
printf ("Error in getting the field handle value.");
exec sql rollback work;
exit(0);
}
printf("\nExecuting tpe_sqlputdata ...\n");
fe_offset = 0;
/* Insert 150 characters. */
for(i=0; i<3; i++)
{
tpe_sqlputdata( tpe_get_curtmhdl(), /* IN transaction handle */
tpe_get_curdbhdl(), /* IN db handle */
tpe_pcur0, /* IN cursor */
TPE_DT_CHAR, /* htypeid */
(void *)fld_hdl_buffer,/* hdl to field */

Sample ESQL Programs
All Rights Reserved 228 www.faircom.com
data_buflen, /* IN bufferlen */
fe_offset, /* IN offset into field */
data_buf, /* IN buffer */
&sqlca /* OUT sqlca pointer */
);
fe_offset += data_buflen;
}
if ( sqlca.sqlcode == 0 )
{
printf("Inserting into table longvar by parts successful ...\n");
EXEC SQL commit work;
}
else
{
printf("Inserting into table longvar by parts failed ...\n");
EXEC SQL rollback work;
}
}
/* Fetch the inserted record using tpe_sqlgetdata(). */
void fetch_part()
{
dh_i32_t fe_offset;
dh_i32_t fe_val_len;
EXEC SQL BEGIN DECLARE SECTION;
/* New handle of lvarchar is declared. */
lvc_fld_hdl_t fld_hdl_buffer;
char data_buf[101];
char stmt[100];
EXEC SQL END DECLARE SECTION;
/* Prepare select statement. */
strcpy ( stmt, "SELECT * FROM longvar");
printf (" STMT STRING : %s \n", stmt);
EXEC SQL prepare S1 from:stmt;
if (sqlca.sqlcode)
{
printf("Prepare failed (%ld : %s)\n",sqlca.sqlcode,sqlca.sqlerrm);
exit(0);
}
/* Declare cursor for the select statement. */
printf("Declaring cursor ...\n");
EXEC SQL declare long_cursor cursor for S1;
if (sqlca.sqlcode)
{
printf("Declare failed (%ld : %s)\n",sqlca.sqlcode,sqlca.sqlerrm);
exit(0);
}
printf("Opening cursor ... \n");
EXEC SQL open long_cursor;
if (sqlca.sqlcode)
{
printf("Open failed (%ld : %s)\n",sqlca.sqlcode,sqlca.sqlerrm);
exit(0);
}
/* Fetch the rows and display the same. */
printf("Fetching rows ...\n");
for (;;)
{
EXEC SQL fetch long_cursor INTO :fld_hdl_buffer;

Sample ESQL Programs
All Rights Reserved 229 www.faircom.com
if (sqlca.sqlcode && sqlca.sqlcode == SQL_NOT_FOUND)
{
printf("\nNo more data present.\n");
break;
}
fe_offset = 0;
printf("\nExecuting tpe_sqlgetdata ...\n");
for (;;)
{
tpe_sqlgetdata (tpe_get_curtmhdl(),
tpe_get_curdbhdl(),
tpe_pcur0,
TPE_DT_CHAR,
(void *)fld_hdl_buffer,
101,
fe_offset,
data_buf,
&fe_val_len,
&sqlca);
/* Print the data. */
printf ( "%s", data_buf);
fe_offset += 100;
if ( fe_val_len <= 0 )
break;
}
}
if (sqlca.sqlcode && sqlca.sqlcode != SQL_NOT_FOUND)
exec sql rollback work;
/* Close the cursor. */
EXEC SQL close long_cursor;
if (sqlca.sqlcode)
exec sql commit work;
}
/* Connect to the default database. */
void
attach_db()
{
/* Connect to the default database. */
EXEC SQL CONNECT TO DEFAULT USER 'systpe';
if (sqlca.sqlcode)
{
printf("Connect failed (%ld : %s )\n", sqlca.sqlcode,
sqlca.sqlerrm);
exit(0);
}
}
/* Disconnect from the database. */
detach_db()
{
EXEC SQL DISCONNECT DEFAULT ;
if (sqlca.sqlcode)
{
printf("Disconnect failed (%ld : %s )\n",
sqlca.sqlcode, sqlca.sqlerrm);
exit(0);
}
}
main()

Sample ESQL Programs
All Rights Reserved 230 www.faircom.com
{
/* Connect to default database. */
attach_db();
/* Insert using tpe_sqlputdata(). */
insert_part();
/* Select using tpe_sqlputdata(). */
fetch_part();
/* Disconnect from default database. */
detach_db();
exit(0);
}
Sample ESQLC Program for lvarbinary Data Type
The following is the complete code listing of an ESQL program for demonstrating the use of
tpe_sqlgetdata() and tpe_sqlputdata() for LVARBINARY column.
/*
* Copyright (C) Dharma Systems Inc. 1988-2003.
* Copyright (C) Dharma Systems (P) Ltd. 1988-2003.
*
* This Module contains Proprietary Information of
* Dharma Systems Inc. and Dharma Systems (P) Ltd.
* and should be treated as Confidential.
*/
/*
* Purpose :
* Example program showing the usage of long varbinary data
* type of Dharma/SQL.
*
* The following functionalities are covered in this test :
* # Insert using tpe_sqlputdata().
* # Fetch using tpe_sqlgetdata().
*
*/
#include "stdio.h"
#include "sql_lib.h"
#include "string.h"
#include "stdlib.h"
/*
* Inserting the data using tpe_sqlputdata().
*/
void insert_part()
{
dh_i32_t fe_offset;
tpe_binary_t binary_buf;
int i;
EXEC SQL BEGIN DECLARE SECTION;
/* New handle of type lvarbinary is declared. */
lvb_fld_hdl_t fld_hdl_buffer;
static char stmt[100];
EXEC SQL END DECLARE SECTION;
/* Prepare insert statement. */

Sample ESQL Programs
All Rights Reserved 231 www.faircom.com
printf("\nInserting into table longvarbin by parts ...\n");
/* Set 80 bytes of binary data. */
memset(binary_buf.tb_data,0xff,80);
/* Set binary data length. */
binary_buf.tb_len = 80;
strcpy ( stmt, "INSERT INTO longvarbin VALUES (?)");
EXEC SQL prepare S1 from :stmt;
EXEC SQL execute S1 USING :fld_hdl_buffer;
if ( sqlca.sqlcode == 0 )
printf ("Got the field handle value." );
else
{
printf ("Error in getting the field handle value.");
exit(0);
}
printf("\nExecuting tpe_sqlputdata ...\n");
fe_offset = 0;
/* Insert 240 bytes of data. */
for(i=0; i<3; i++)
{
tpe_sqlputdata( tpe_get_curtmhdl(), /* IN transaction handle.*/
tpe_get_curdbhdl(), /* IN db handle. */
tpe_pcur0, /* IN cursor. */
TPE_DT_BINARY, /* htypeid. */
(void *)fld_hdl_buffer,/* hdl to field. */
binary_buf.tb_len, /* bufferlen. */
fe_offset, /* offset into field. */
&binary_buf, /* buffer. */
&sqlca /* OUT sqlca pointer. */
);
fe_offset += 80;
}
exec sql commit work;
printf("Inserting into table longvarbin by parts successful ...\n");
}
/* Fetch the inserted record using tpe_sqlgetdata(). */
void fetch_part()
{
dh_i32_t fe_offset;
dh_i32_t fe_val_len;
dh_i32_t i;
tpe_binary_t binary_buf;
EXEC SQL BEGIN DECLARE SECTION;
/* New handle of type lvarbinary is declared. */
lvb_fld_hdl_t fld_hdl_buffer;
char stmt[100];
EXEC SQL END DECLARE SECTION;
printf("Selecting from table longvarbin (fetch_part) ...\n");
/* Prepare select statement. */
strcpy ( stmt, "SELECT * FROM longvarbin");
printf (" STMT STRING : %s \n", stmt);
EXEC SQL prepare S1 from:stmt;
if (sqlca.sqlcode)
{
printf("Prepare failed (%ld : %s )\n", sqlca.sqlcode, sqlca.sqlerrm);
exit(0);
}
/* Declare cursor for the select statement. */
printf("Declaring cursor ...\n");
EXEC SQL declare long_cursor cursor for S1;

Sample ESQL Programs
All Rights Reserved 232 www.faircom.com
if (sqlca.sqlcode)
{
printf("Declare cursor failed(%ld: %s)\n",sqlca.sqlcode,sqlca.sqlerrm);
exit(0);
}
printf("Opening cursor ... \n");
EXEC SQL open long_cursor;
if (sqlca.sqlcode)
{
printf("Open cursor failed(%ld: %s)\n",sqlca.sqlcode,sqlca.sqlerrm);
exit(0);
}
/* Fetch the rows and display the same. */
printf("Fetching rows ...\n");
for (;;)
{
/* Server returns handle in fld_hdl_buffer. */
EXEC SQL fetch long_cursor INTO :fld_hdl_buffer;
if (sqlca.sqlcode && sqlca.sqlcode == SQL_NOT_FOUND)
{
printf("\nNo more data present.\n");
break;
}
fe_offset = 0;
printf("\nExecuting tpe_sqlgetdata ...\n");
for (;;)
{
tpe_sqlgetdata (tpe_get_curtmhdl(), /* IN transaction handle */
tpe_get_curdbhdl(), /* IN db handle */
tpe_pcur0, /* IN cursor */
TPE_DT_BINARY, /* htypeid */
(void *)fld_hdl_buffer,/* hdl to field */
80, /* bufferlen */
fe_offset, /* offset into field */
&binary_buf, /* buffer */
&fe_val_len, /* balance data from offset */
&sqlca); /* OUT sqlca pointer */
for(i = 0; i<binary_buf.tb_len ; i++)
printf ("%x", binary_buf.tb_data[i]);
fe_offset += 80;
if ( fe_val_len <= 0 )
break;
}
}
if (sqlca.sqlcode && sqlca.sqlcode != SQL_NOT_FOUND)
exec sql rollback work;
/* Close the cursor. */
EXEC SQL close long_cursor;
}
/* Connect to the default database. */
void
attach_db()
{
/* Connect to the default database. */
EXEC SQL CONNECT TO DEFAULT USER 'systpe';
if (sqlca.sqlcode)
{
printf("Connect failed (%ld : %s )\n", sqlca.sqlcode, sqlca.sqlerrm);
exit(0);

Sample ESQL Programs
All Rights Reserved 233 www.faircom.com
}
}
/* Disconnect from the database. */
detach_db()
{
EXEC SQL DISCONNECT DEFAULT ;
if (sqlca.sqlcode)
{
printf("Disconnect failed (%ld : %s )\n",
sqlca.sqlcode, sqlca.sqlerrm);
exit(0);
}
}
main()
{
/* Connect to default database. */
attach_db();
/* Insert using tpe_sqlputdata(). */
insert_part();
/* Select using tpe_sqlputdata(). */
fetch_part();
/* Disconnect from default database. */
detach_db();
exit(0);
}

Glossary
All Rights Reserved 234 www.faircom.com
18. Glossary
active set
The collection of rows that SQL identifies when it opens a cursor and executes the query
associated with the cursor. Also called result set.
atomicity
A property of transactions that either all the operations in a transaction are done (if the
transaction is committed) or none are done (if the transaction is rolled back).
candidate key
Another term for unique key.
commit
Make permanent all changes made during a transaction.
constraint
Part of an SQL table definition that restricts the values that can be stored in a table. When you
insert, delete, or update column values, the constraint checks the new values against the
conditions specified by the constraint. If the value violates the constraint, it generates an error.
Constraints enforce referential integrity by insuring that a value stored in the foreign key of a table
must either be null or be equal to some value in the matching unique or primary key of another
table.
current row
The current row of the active set of an open cursor. After an OPEN statement, the cursor is
positioned just before the first row of the active set. The first FETCH statement advances the
cursor position and makes the first row the current row. Subsequent FETCH statements make
subsequent rows the current row.
cursor
The active set defined by the query in a DECLARE CURSOR statement. Host programs use
cursors to retrieve multiple rows of data returned by queries.
cycle
The process of creating database tables when the first table has a foreign key that references the
second table, the second table has a foreign key that references the third table and so on, and
the last table has a foreign key that references the first table.
Data Control Language (DCL) statements
SQL GRANT and REVOKE statements. DCL statements control access to data and the rights to
issue DCL statements.
Data Definition Language (DDL) statements

Glossary
All Rights Reserved 235 www.faircom.com
SQL CREATE, ALTER, and DROP statements used to manage tables, views, indices, and other
database objects.
Data Manipulation Language (DML) statements
SQL SELECT, INSERT, UPDATE, and DELETE statements that access or modify data.
database storage representation
The format used by c-treeSQL to store value in the database. This format is different than host
language representation for some data types.
durability
A characteristic of transactions that requires that all changes made during a transaction be
permanent after the transaction is committed.
dynamic SQL
A set of special SQL statements (PREPARE, DESCRIBE, EXECUTE, and EXECUTE
IMMEDIATE) and data structures (SQLCA and SQLDA) that let programs accept or generate
SQL statements at run time. Such dynamically-generated statements are not necessarily part of a
program’s source code, but can be generated at run time.
embedded SQL
SQL statements that are embedded within a host language program. The esqlc precompiler
translates embedded SQL statements to equivalent C-language calls to routines in the c-treeSQL
application programming interface.
esqlc
The c-treeSQL precompiler for C host programs, and the command-line syntax to invoke it.
exception handler
Host program code that tests for a variety of possible errors and specifies what action will be
taken if they arise.
EXCLUSIVE locks
Locks that SQL acquires on rows that have been modified by a transaction. EXCLUSIVE locks
prevent other transactions from either reading or modifying the rows until the transaction either
commits or performs a rollback.
foreign key
A column or columns in a table whose values must either be null or equal to some value in a
corresponding columns (called the primary key) in another table. Use the REFERENCES clause
in the SQL CREATE TABLE statement to create foreign keys.
host language
Any programming language in which SQL statements can be embedded for database access.
The esqlc precompiler supports embedding SQL statements in C-language programs.
host language representation
The format used by a host language to represented values. This format is different from the
database storage representation used by c-treeSQL for some data types. In some cases,

Glossary
All Rights Reserved 236 www.faircom.com
applications must explicitly convert between data types to insert data or manipulate data retrieved
from the database.
host program
An application program in which SQL statements are embedded.
host variable
Any host language variable that is used in embedded SQL statements. Programs must declare
host variables in the BEGIN-END DECLARE SECTION. Host variables can be declared as a
database, host-language, or user-defined types. Depending on how they are used in an SQL
statement, host variables are either input (where values stored by the program are used as an
expression in an SQL statement) or output (where SQL stores values returned by queries for use
by the program).
index
A database structure that speeds access to particular rows in a table. Indices specify one or more
columns as an index key. Queries that use the index key retrieve data faster than those that do
not take advantage of an index.
indicator variable
A variable that is used to represent null values in an application program. Indicator variables must
be associated with a host variable. If the value retrieved by a query is null, SQL stores a negative
in the indicator variable. Programs set indicator variables to -1 to specify a null value for insertion
into the database. Programs declare indicator variables as short or SMALLINT.
input host variable
A host variable that is used as input to an embedded SQL statement. Embedded SQL statements
can refer to host variables anywhere they can refer to an expression. Host programs use input
variables to provide values to insert and update data in the database, and as arguments to
search conditions.
input SQLDA
An SQLDA used by a dynamic SQL program to determine the number and data type of input
parameters of an SQL statement, and to store values for those input parameters. DESCRIBE
BIND VARIABLES, EXECUTE and OPEN statements can specify an input SQLDA that SQL uses
to store information about input parameters.
integrity constraint
Another term for constraint.
isolation level
The degree by which a transaction is isolated from the database modification operations of other
concurrently active transactions.
null value
The absence of a value. Host programs use indicator variables or SQL constructs to specify null
values and retrieve null values from the database.
output host variable

Glossary
All Rights Reserved 237 www.faircom.com
A host variable that SQL uses to store results from a query.
output SQLDA
An SQLDA used by a dynamic SQL program to determine the number and data type of columns
in the result set returned by a query, and to retrieve values of that result set. DESCRIBE SELECT
LIST and FETCH statements can specify an output SQLDA that SQL uses to store the column
information and data.
parameter marker
Question marks (?) in the statement string of a PREPARE statement. Parameter markers act as
placeholders for input variables in dynamic SQL statements.
precompiler
A translator that translates embedded SQL statements in a host program to the equivalent C calls
to functions in the c-treeSQL application programming interface (API).
primary key
A subset of the fields in a table, characterized by the constraint that no two records in a table may
have the same primary key value, and that no fields of the primary key may have a null value.
Primary keys are specified in a CREATE TABLE statement.
referential constraint
Another term for constraint.
referential integrity
The condition where the value stored in a database table’s foreign key must either be null or be
equal to some value in another table’s the matching unique or primary key. Constraints specified
as part of CREATE TABLE statements prevent updates that violate referential integrity.
relation
Another term for table.
result set
Another term for active set.
result table
A temporary table of values returned by a query.
rollback
Undo all changes made during a transaction.
SHARE locks
Locks that SQL acquires on rows that have been read by a transaction. SHARE locks allow other
transactions to read the row but prevent them from modifying the row until this transaction either
commits or performs a rollback.
SQLCA
A host structure that SQL uses to store information about the execution of an SQL statement. The
SQLCA contains information about the most recently executed SQL statement.

Glossary
All Rights Reserved 238 www.faircom.com
SQLCODE
One of the components of the SQLCA that contains a long INTEGER indicating the status of the
execution of an SQL statement.
SQLDA
A host structure used in dynamic SQL programs. The host program uses the SQLDA to
determine the number and data type of input and output parameters of a dynamically-generated
SQL statement. SQL uses the SQLDA to determine where to retrieve input parameter values or
to store query results.
statement string
In dynamic SQL, the SQL statement used as an argument to the EXECUTE IMMEDIATE and
PREPARE statements.
static SQL statement
An SQL statements that is known to the application at compile time, as opposed to a
dynamically-generated SQL statement.
substitution name
In the statement string of a PREPARE statement, a name preceded by a colon ( : ). Substitution
names do not refer to host-language variable names, but act only as placeholders for input
variables in dynamic SQL statements.
table
The representation of data in a relational database as a collection of columns and rows. Also
called relation.
transaction
A group of database operations whose changes can be made permanent or undone only as a
unit.
transaction isolation level
Another term for isolation level.
unique key
A column or columns in a table whose value (or combination of values) must be unique. Use the
UNIQUE clause of the SQL CREATE TABLE statement to create unique keys. Unique keys are
also called candidate keys.
view
A virtual table that recreates the result table specified by a SELECT statement. No data is stored
in a view, but other queries can refer to it as if it were a table containing data corresponding to the
result table it specifies.

All Rights Reserved 239 www.faircom.com
19. Index
A Abnormal Termination of an ESQL Application
Program ............................................................ 136 Additional Resources ............................12, 25, 33, 45 Advantages of Using ESQL ...................................... 2 Aggregate functions
NULL values ....................................................... 99 ALLOCATE DESCRIPTOR .................................. 114 Allocating an SQLDA ............................................ 123 Allocating for SQLDA Data Buffers and Indicator
Variables ........................................................... 125 Application development ........................................ 57 Array Fetches ......................................................... 91
Retrieving Multiple Rows with One FETCH Statement ........................................................ 91
Associating a Cursor with a Query ......................... 87
B BEGIN-END DECLARE SECTION ....................... 153 BIGINT .................................................................. 140 BIGINT data type .................................................. 140 BINARY [(length)] ................................................. 146 BINARY data type ................................................. 146 BIT ........................................................................ 146 BIT data type ........................................................ 146
C C programs using ESQL ........................................... 3 Candidate Keys ...................................................... 74 CHARACTER data type ....................................... 138 CHARACTER Data Type ...................................... 138 Check constraints ................................................... 71 Check Constraints .................................................. 71 Checking Indicator Variables to Test for
Returned Null Values .......................................... 53 CLOSE .................................................................. 155 Closing a Cursor ............................................. 90, 114 Coding guidelines ................................................... 57 Column-level candidate key constraint ................... 75 Column-Level Candidate Key Constraint ............... 75 Column-Level Check Constraint ............................. 72 Column-level check constraints .............................. 72 Column-level foreign key constraint ....................... 76 Column-Level Foreign Key Constraint.................... 76 Column-level primary key constraint ...................... 73 Column-Level Primary Key Constraint ................... 73 Command
ESQL .................................................................. 46 ESQL example commands ................................. 54 ESQL syntax ....................................................... 46
COMMIT WORK ............................................. 55, 132 Compiling and Running ............... 216, 218, 220, 223
Compiling, ESQL ................................................... 48 Complete Examples
Interpreting Sign/Exponent and Data Bytes of dec_digits ..................................................... 143
Components of an ESQL Application .......................3 Computations, ESQL ............................................. 58 Condition evaluation, ESQL ................................... 59 CONNECT ............................................................. 62
example.............................................................. 62 Connecting to a remote database .......................... 63 Connection by Default ........................................... 63 Connection management ....................................... 62 Connection Management in ESQL ........................ 62 Connection name ................................................... 62 Connection to a Remote Database........................ 63 Connection Using a Connection Name ................. 62 Copyright Notice ....................................................... ii Creating Indices ..................................................... 68 Creating tables ....................................................... 66 Creating Tables ...................................................... 66 Creating tables in cycles ........................................ 78 Creating views ....................................................... 69 Creating Views ....................................................... 69 Creating/Dropping Indices ..................................... 68 Creating/Dropping Tables ...................................... 66 Creating/Dropping Views ....................................... 69 Creation of Tables in Cycles .................................. 78 c-treeSQL Data Definition Statements .................. 66 c-treeSQL Data Manipulation Statements ............. 80 Cursors .................................................................. 87
associating with a query ..................................... 87 closing ........................................................ 90, 114 fetching rows .................................................... 113 opening ...................................................... 88, 112 retrieving ............................................................ 89
D Data comparison .................................................. 150
using arithmetic expressions ........................... 151 using dh_compare_data .................................. 150
Data Comparison ................................................. 150 Data conversion ................................................... 146
implicit .............................................................. 147 using dh_conv_data ......................................... 147 using scalar functions ...................................... 149
Data Conversion .................................................. 146 Data Type Descriptions ....................................... 138 Data Type Handling in ESQL ............................... 138 Data type handling, ESQL ................................... 138 Data types
BIGINT ............................................................. 140 BINARY ............................................................ 146 BIT .................................................................... 146 CHARACTER ................................................... 138 DATE ................................................................ 145 DECIMAL ......................................................... 141

Index
All Rights Reserved 240 www.faircom.com
DOUBLE PRECISION ...................................... 141 FLOAT .............................................................. 140 INTEGER .......................................................... 139 LVARBINARY (not supported).......................... 146 NUMERIC ......................................................... 141 NUMERIC internal storage format .................... 141 REAL ................................................................. 140 SMALLINT ........................................................ 139 TIME ................................................................. 145 TIMESTAMP ..................................................... 146
Data types, ESQL ................................................. 138 Database types ..................................................... 170 Database Types .................................................... 170 DATE data type .................................................... 145 DATE Data Type ................................................... 145 DCL statements ...................................................... 54 DDL statements ................................................ 54, 66
examples............................................................. 66 long running transactions .................................... 79
DDL Statements in Long Running Transactions .... 79 DEALLOCATE DESCRIPTOR ............................. 114 DECIMAL data type .............................................. 141 DECLARE CURSOR ............................................ 155 DECLARE Section ................................................ 177 Declare section limitations ...................................... 53 Declare statements in ESQL .................................... 3
example .............................................................. 50 Define ..................................................... 7, 16, 28, 36 Deleting or Updating the Current Row.................... 90 Deleting Rows from a Table ................................... 82 Deleting rows in tables............................................ 82 DESCRIBE ................................................... 127, 156 Developing an Embedded SQL Application ............. 3 dh_alloc_sqlenv .................................................... 180 dh_compare_data ......................................... 150, 181 dh_conv_data ............................................... 147, 182 dh_dayofweek ....................................................... 184 dh_free_sqlenv ..................................................... 184 dh_get_curdbhdl ................................................... 185 dh_get_curtmhdl ................................................... 185 dh_num_add ......................................................... 186 dh_set_cursor ....................................................... 187 dh_set_ptrs ........................................................... 188 dh_set_sqlda ........................................................ 189 dh_sqlallocdesc .................................................... 209 dh_sqlclose ........................................................... 190 dh_sqlcolumns ...................................................... 215 dh_sqlconnect ....................................................... 191 dh_sqldeallocdesc ................................................ 210 dh_sqldeclare ....................................................... 192 dh_sqldescribe ...................................................... 193 dh_sqldescribe_param ......................................... 195 dh_sqldisconnect .................................................. 196 dh_sqlexecute ....................................................... 197 dh_sqlfetch ........................................................... 198 dh_sqlforeignkeys ................................................. 215
dh_sqlgetdata ...................................................... 199 dh_sqlgetdesc ...................................................... 211 dh_sqlgetdiag ....................................................... 213 dh_sqlgetsqldaptr................................................. 209 dh_sqlopen .......................................................... 200 dh_sqlprepare ...................................................... 202 dh_sqlprimarykeys ............................................... 215 dh_sqlputdata ...................................................... 207 dh_sqlselect ......................................................... 203 dh_sqlsetdesc ...................................................... 212 dh_sqlstatistics ..................................................... 215 dh_sqltables ......................................................... 215 dh_tm_alloc_handle ............................................. 204 dh_tm_begin_trans .............................................. 205 dh_tm_end_trans ................................................. 206 dh_tm_mark_abort ............................................... 206 dh_tm_set_level ................................................... 214 DISCONNECT ....................................................... 62
example.............................................................. 64 DML statement host variables ............................... 84 DML statements ............................................... 54, 80
types of............................................................... 80 Done .................................................... 11, 24, 32, 44 DOUBLE PRECISION ......................................... 141 DOUBLE PRECISION data type ......................... 141 Dropping indices .................................................... 69 Dropping Indices .................................................... 69 Dropping tables ...................................................... 67 Dropping Tables ..................................................... 67 Dropping tables in cycles ....................................... 78 Dropping the Tables in Cycles ............................... 78 Dropping views ...................................................... 70 Dropping Views ...................................................... 70 Dynamic non-SELECT statements ...................... 220 Dynamic Non-SELECT Statements ..................... 220 Dynamic SELECT statements ............................. 223 Dynamic SELECT Statements ............................. 223 Dynamic SQL Management in ESQL .................. 109
E Elements of a Query .............................................. 85 END DECLARE SECTION .................................. 159 Error checking
SQLCA ............................................................. 102 Error handling ...................................................... 100
indicator variables ............................................ 107 SQLCA ............................................................. 100 WHENEVER statement ................................... 105
Error Handling in ESQL ....................................... 100 ESQL
abnormal termination ....................................... 136 advantages ...........................................................2 application development .................................... 57 command ........................................................... 46 command examples ........................................... 48 compiling ............................................................ 48

Index
All Rights Reserved 241 www.faircom.com
compiling, running .................... 216, 218, 220, 223 components .......................................................... 3 computation ........................................................ 58 condition evaluation ............................................ 59 connection management .................................... 62 data comparison ............................................... 150 data conversion ................................................ 146 data type ........................................................... 138 data type handling ............................................ 138 declare section limitations ................................... 53 declare statements definition ................................ 3 declare statements example ............................... 50 DML .................................................................... 80 error handling .................................................... 100 executable statement definition ............................ 3 executable statement examples ......................... 54 host program development ................................... 3 host variables ...................................................... 51 implicit data conversion .................................... 147 indicator variables, definition .............................. 51 indicator variables, using .................................... 60 null value handling .............................................. 94 overview ................................................................ 1 precompile ............................................................ 3 precompiling........................................................ 48 program structure ............................................... 50 sample programs .............................................. 216 scalar functions ................................................... 60 SQL management ............................................. 109 SQL statements ................................................ 153 statement types .................................................. 54 status codes ........................................................ 54 syntax .................................................................. 46 transaction management .................................. 131 types of executable statements .......................... 54
ESQL Application Development ............................. 57 ESQL Declare Statements ..................................... 50 ESQL descriptor statement .................................. 114 ESQL Descriptor Statement ................................. 114 ESQL Executable Statements ................................ 54 ESQL Program Structure ........................................ 50 ESQL Reference ................................................... 153 esqlc Command Examples ..................................... 48 esqlc Command Line Reference ............................ 46 EXEC .................................................................... 159 EXEC SQL ............................................................ 159 Executable statement types ................................... 54 Executable statements in ESQL
examples............................................................. 54 Executable statements, ESQL .................................. 3 EXECUTE ............................................................. 159 EXECUTE IMMEDIATE ................................ 112, 161 Executing a Non-SELECT Statement................... 111
F FairCom Typographical Conventions ...................... xi
FETCH ................................................................. 161 Fetches
arrays ................................................................. 91 SQLDA array fetches ....................................... 125 using a cursor .................................................. 113
Fetching Rows Using a Cursor ............................ 113 Fields of the SQLCA ............................................ 100 FLOAT Data Type ................................................ 140 FLOAT data types ................................................ 140 Forced Rollback of a Transaction ........................ 136 Freeing an SQLDA............................................... 126 Functions
NVL .................................................................... 97 scalar .................................................................. 60
G GET DESCRIPTOR ............................................. 115 Glossary ............................................................... 234 GROUP BY clause NULL values ........................... 99 Guidelines .............................................................. 57
H Handling Cycles in Referential Integrity ................. 77 Handling the SQL_NOT_FOUND Condition with
WHENEVER .................................................... 107 Host language types ............................................ 171 Host Language Types .......................................... 171 Host variables ........................................................ 51
in DML statements ............................................. 84 Host Variables and their Usage ............................. 51
I Implicit Data Type Conversion ............................. 147 IN predicate .......................................................... 167 IN Predicate ......................................................... 167 Indicator variables
definition ............................................................. 51 error handling ................................................... 107 insert NULL values ............................................. 95 retrieve NULL value ........................................... 97 using ................................................................... 60
Indicator Variables and their Usage....................... 51 Indices
creating/dropping ............................................... 68 Init .......................................................... 6, 15, 27, 35 Input host variables
in query statements ............................................ 86 Input Host Variables in DML Statements ............... 84 Input Host Variables in Query Statements ............ 86 Input variables
SQLDA ............................................................. 128 INSERT Operation ............................................... 177 Inserting NULL values ........................................... 94 Inserting NULL Values ........................................... 94 Inserting NULL Values by Default .......................... 94 Inserting Null Values With Indicator Variables ....... 52 Inserting rows in tables .......................................... 80

Index
All Rights Reserved 242 www.faircom.com
Inserting rows in tables in cycles ............................ 78 Inserting Rows into a Table .................................... 80 Insertion of Rows in Cycles .................................... 78 INTEGER data type .............................................. 139 INTEGER Data Type ............................................ 139 Integrity constraints................................................. 71
check constraints ................................................ 71 column-level candidate key constraints .............. 75 column-level check constraint............................. 72 column-level foreign key constraints .................. 76 column-level primary key constraints ................. 73 table-level candidate key constraints .................. 75 table-level check constraints............................... 72 table-level foreign key constraints ...................... 77 table-level primary key constraints ..................... 74 types of ............................................................... 71
Integrity Constraints ................................................ 71 Internal Storage Format for NUMERIC Data ........ 141 Interpreting the Data Values Bytes of dec_digits . 143 Interpreting the Sign/Exponent Byte of
dec_digits .......................................................... 142 Interrupting the Execution of an SQL Statement .. 136 Introduction1, 46, 50, 57, 62, 66, 80, 85, 94, 100, 109, 131, 138, 153, 178 Introduction to Cursors ........................................... 87 Introductory Tutorial .................................................. 5 Isolation levels ...................................................... 134 Issuing Separate Commands for Precompiling,
Compiling, and Linking ....................................... 49
K Keys
candidate ............................................................ 74 primary ................................................................ 73
L LIKE predicate ...................................................... 166 LIKE Predicate ...................................................... 166 Limitations of the Declare Section .......................... 53 Locking and Transactions ..................................... 135 Long data type support ......................................... 226 Long Data Type Support .............................. 176, 226 Long running transactions ...................................... 79 LVARBINARY | LONG VARBINARY .................... 146 LVARBINARY data type (not supported).............. 146
M Manage ................................................... 8, 19, 29, 39 Mixing Precompiler/Compiler Options in the
esqlc Command .................................................. 49 Multiple row queries ................................................ 87
N Need for Integrity Constraints ................................. 71 non-SELECT ......................................................... 111 Non-SELECT Statements ..................................... 111 NULL Value Handling in ESQL ............................... 94 NULL values ........................................................... 94
in aggregate functions ........................................ 99 in expressions .................................................... 98 in GROUP BY clause ......................................... 99 in ORDER BY clause ......................................... 99 in scalar functions .............................................. 99 in WHERE clause .............................................. 98 inserting.............................................................. 94 retrieving ............................................................ 97 updating ............................................................. 96
NUMERIC data type ............................................ 141 internal storage format ..................................... 141
NUMERIC or DECIMAL Data Type ..................... 141 NVL function .......................................................... 97
O OPEN ........................................................... 112, 163 Opening a cursor ................................................... 88 Opening a Cursor........................................... 88, 112 ORDER BY clause NULL values ........................... 99 Output host variables
in query statements ............................................ 86 Output Host Variables in Query Statements .......... 86 Output variables
SQLDA ............................................................. 129 Overview .......................................................... 1, 109 Overview of ESQL ....................................................1
P Precompiling, Compiling, and Linking Multiple
Files with esqlc ................................................... 48 Precompiling, ESQL............................................... 48 Predicates
IN 167 LIKE ................................................................. 166
PREPARE .................................................... 110, 164 Preparing Statements .......................................... 110 Primary keys .......................................................... 73 Primary Keys .......................................................... 73 Program Source code .......................................... 223 Program Source Code ......................... 216, 218, 221 Programmatic Interfaces .............................. 178, 179
Q Queries
multiple row ........................................................ 87 single row ........................................................... 86
Queries Returning a Single Row ........................... 86 Queries Returning Multiple Rows .......................... 87 Query Expressions............................................... 166 Query statements................................................... 85 Query Statements .................................................. 85 Quick Tour ................................................................4
R REAL data type .................................................... 140 REAL Data Type .................................................. 140 Record types ........................................................ 174

Index
All Rights Reserved 243 www.faircom.com
Record Types ....................................................... 174 Record/Row Locking............................................... 26 Referential constraints ............................................ 75 Referential Constraints ........................................... 75 Referential integrity ................................................. 77 Referring to Indicator Variables .............................. 52 Relational views ........................................................ 1 Relationships .......................................................... 13 Retrieving a cursor .................................................. 89 Retrieving NULL values .......................................... 97 Retrieving NULL Values ......................................... 97 Retrieving Rows Using a Cursor ............................ 89 Rollback transaction ............................................. 136 ROLLBACK WORK ........................................ 55, 133
S Sample ESQL programs ....................................... 216 Sample ESQL Programs ...................................... 216 Sample ESQLC Program for lvarbinary Data
Type .................................................................. 230 Sample ESQLC Program for lvarchar Data Type . 226 Scalar functions ...................................................... 60
data type conversions ....................................... 149 NULL values ....................................................... 99 NVL ..................................................................... 97
Search Conditions ................................................ 166 SELECT ................................................................ 112 SELECT Operation ............................................... 177 SELECT Statements............................................. 112 SET CONNECTION ................................................ 62
example .............................................................. 64 SET DESCRIPTOR .............................................. 117 Setting the SQLDA Types and Lengths................ 124 SINGLE-ROW SELECT........................................ 167 Single-Row SELECT Statement ........................... 167 SMALLINT data type ............................................ 139 SMALLINT Data Type........................................... 139 SQL
Management ..................................................... 109 queries ................................................................ 85 statements ........................................................ 153
SQL communication area ....................................... 54 SQLCODE .......................................................... 54 SQLWARN .......................................................... 54
SQL Descriptor Area............................................. 118 allocating ........................................................... 123 array fetches ..................................................... 125 components ...................................................... 119 diagram ............................................................. 123 fields .................................................................. 119 freeing ............................................................... 126 input variables ................................................... 128 output variables ................................................ 129 types and lengths .............................................. 124
SQL in a host language ............................................ 2 SQL statement input host variables ........................ 86
SQL statement output host variables .................... 86 SQL statements
BEGIN-END DECLARE SECTION .................. 153 CLOSE ............................................................. 155 DECLARE CURSOR ....................................... 155 DESCRIBE ....................................................... 156 END DECLARE SECTION .............................. 159 EXEC SQL ....................................................... 159 EXECUTE ........................................................ 159 EXECUTE IMMEDIATE ................................... 161 FETCH ............................................................. 161 OPEN ............................................................... 163 PREPARE ........................................................ 164 QUERY EXPRESSIONS ................................. 166 SEARCH CONDITIONS .................................. 166 SINGLE-ROW SELECT ................................... 167 TYPE DECLARATIONS ................................... 169 TYPE SPECIFICATIONS ................................. 169 WHENEVER .................................................... 175
SQL_NOT_FOUND ............................................. 107 SQLCA ................................................................... 54
error checking .................................................. 102 error handling ................................................... 100 SQLCODE ......................................................... 54 SQLWARN ......................................................... 54 warning checking ............................................. 104
SQLCODE ............................................................. 54 sqld_alloc ............................................................. 179 sqld_free .............................................................. 179 SQLDA ................................................................. 118
allocating .......................................................... 123 array fetches .................................................... 125 components ..................................................... 119 diagram ............................................................ 123 fields ................................................................. 119 freeing .............................................................. 126 input variables .................................................. 128 output variables ................................................ 129 types and lengths ............................................. 124
SQLWARN ............................................................. 54 Starting a Transaction .......................................... 131 Statements ........................................................... 153
BEGIN-END DECLARE SECTION .................. 153 CLOSE ............................................................. 155 COMMIT WORK ........................................ 55, 132 CONNECT ......................................................... 62 CONNECT, example .......................................... 62 DDL .................................................................... 66 DECLARE CURSOR ....................................... 155 DESCRIBE ............................................... 127, 156 DISCONNECT ................................................... 62 DISCONNECT, example .................................... 64 DML .................................................................... 80 dynamic non-SELECT ..................................... 220 dynamic SELECT ............................................. 223 END DECLARE SECTION .............................. 159

Index
All Rights Reserved 244 www.faircom.com
EXEC SQL ........................................................ 159 EXECUTE ......................................................... 159 EXECUTE IMMEDIATE ............................ 112, 161 FETCH .............................................................. 161 non-SELECT ..................................................... 111 OPEN ........................................................ 112, 163 PREPARE ................................................. 110, 164 QUERY EXPRESSIONS .................................. 166 ROLLBACK WORK .......................................... 133 SEARCH CONDITIONS ................................... 166 SELECT ............................................................ 112 SET CONNECTION ............................................ 62 SET CONNECTION, example ............................ 64 SINGLE-ROW SELECT .................................... 167 SQL SELECT ...................................................... 58 static non-SELECT ........................................... 216 static SELECT .................................................. 218 TYPE DECLARATIONS ................................... 169 TYPE SPECIFICATIONS ................................. 169 WHENEVER ............................................. 105, 175
Static array types .................................................. 172 Static Array Types ................................................ 172 Static non-SELECT statements ............................ 216 Static Non-Select Statements ............................... 216 Static SELECT statements ................................... 218 Static SELECT Statements .................................. 218 Syntax, ESQL ......................................................... 46
T Table record types ................................................ 174 Table Record Types ............................................. 174 Table-column types .............................................. 172 Table-Column Types ............................................ 172 Table-level candidate key constraint ...................... 75 Table-Level Candidate Key Constraint ................... 75 Table-level check constraint ................................... 72 Table-Level Check Constraint ................................ 72 Table-level foreign key constraint ........................... 77 Table-Level Foreign Key Constraint ....................... 77 Table-level primary key constraint .......................... 74 Table-Level Primary Key Constraint ....................... 74 Tables
creating in cycles ................................................ 78 creating/dropping ................................................ 66 deleting rows ....................................................... 82 dropping in cycles ............................................... 78 inserting rows ...................................................... 80 inserting rows in cycles ....................................... 78 updating rows ..................................................... 83
The COMMIT WORK and ROLLBACK WORK Statements .......................................................... 55
The COMMIT WORK Statement .......................... 132 The Components of SQLDA ................................. 119 The CONNECT Statement ..................................... 62 The c-treeSQL Communications Area .................... 54 The c-treeSQL Descriptor Area - SQLDA ............ 118
The DESCRIBE Statement .................................. 127 The DISCONNECT Statement .............................. 64 The EXECUTE IMMEDIATE Statement .............. 112 The Relational View of Data .....................................1 The ROLLBACK WORK Statement ..................... 133 The SET CONNECTION Statement ...................... 64 TIME data type ..................................................... 145 TIME Data Type ................................................... 145 TIMESTAMP ........................................................ 146 TIMESTAMP data type ........................................ 146 Transaction Isolation Levels ................................ 134 Transaction management .................................... 131
forced rollback .................................................. 136 isolation levels .................................................. 134 locking .............................................................. 135 statements ......................................................... 54
Transaction Management in ESQL...................... 131 Transaction Overview .......................................... 131 Transaction Processing ......................................... 34 Transactions
long running ....................................................... 79 TYPE DECLARATIONS ...................................... 169 TYPE SPECIFICATIONS .................................... 169 Type Specifications for Variable and Type
Declarations ..................................................... 169 Types of ESQL executable statements ................. 54 Types of Executable Statements ........................... 54 Types of Integrity Constraints ................................ 71
U Updating NULL values ........................................... 96 Updating Rows in a Table ...................................... 83 Updating rows in tables ......................................... 83 Updating with NULL Values ................................... 96 Using c-treeSQL for Computation and
Conversion ......................................................... 58 Using c-treeSQL for Condition Evaluation ............. 59 Using c-treeSQL in a Host Language .......................2 Using DML Statements .......................................... 80 Using Indicator Variables ....................................... 60 Using Indicator Variables for Error Handling ....... 107 Using Indicator Variables to Insert NULL Values .. 95 Using Indicator Variables to Retrieve NULL
Values ................................................................ 97 Using NULL Values................................................ 98 Using NULL Values in Aggregate Functions ......... 99 Using NULL Values in Expressions ....................... 98 Using NULL Values in GROUP BY Clause ........... 99 Using NULL Values in ORDER BY Clause ........... 99 Using NULL Values in Scalar Functions ................ 99 Using NULL Values in the WHERE Clause ........... 98 Using Scalar Functions .......................................... 60 Using SQL Arithmetic Expressions for Data
Comparison ...................................................... 151 Using SQL Scalar Functions for Data Type
Conversion ....................................................... 149

Index
All Rights Reserved 245 www.faircom.com
Using SQLCA for Checking Errors ....................... 102 Using SQLCA for Checking Warnings .................. 104 Using SQLCA for Error Handling .......................... 100 Using SQLDA for Array Fetches ........................... 125 Using SQLDA for Input Variables ......................... 128 Using SQLDA for Output Variables ...................... 129 Using Static and Dynamic Statements ................... 61 Using the esqlc Command ..................................... 46 Using the NULL Keyword to Insert NULL Values ... 95 Using the Scalar Function NVL to Retrieve
NULL values ....................................................... 97 Using the SQL API Function tpe_compare_data
for Data Comparison ......................................... 150 Using the SQL API Function tpe_conv_data for
Data Type Conversion ...................................... 147 Using the WHENEVER Statement for Error
Handling ............................................................ 105 Using WHENEVER Along With Explicit Error
Checking ........................................................... 107
V Variables
indicator .............................................................. 97 input host ...................................................... 84, 86 output host .......................................................... 86
Views ........................................................................ 1 creating/dropping ................................................ 69
W Warning checking
SQLCA .............................................................. 104 WHENEVER ......................................................... 175 WHERE clause NULL values ................................. 98