efficient spmv on gpus - camjclub - home cient spmv on gpus gaurish telang suny stony brook december...
TRANSCRIPT

Efficient SpMV on GPUs
Gaurish Telang
SUNY Stony Brook
December 4th,2012
Gaurish Telang (SUNY Stony Brook) Efficient SpMV on GPUs December 4th,2012 1 / 51

Table Of Contents
1 The CUDA model
2 The CUDA C/C++ API
3 Sparse Matrix Formats
4 Sparse-Matrix Vector Multiplication
5 Performance
Gaurish Telang (SUNY Stony Brook) Efficient SpMV on GPUs December 4th,2012 2 / 51

The CUDA model
Gaurish Telang (SUNY Stony Brook) Efficient SpMV on GPUs December 4th,2012 3 / 51

Host and Device
Host
Device
Gaurish Telang (SUNY Stony Brook) Efficient SpMV on GPUs December 4th,2012 4 / 51

The CUDA model: Introduction
An application consists of a sequential CPU program that mayexecute parallel programs known as kernels on a GPU.
A kernel is a computation that is executed by a potentially largenumber (1000’s) of parallel threads.
Gaurish Telang (SUNY Stony Brook) Efficient SpMV on GPUs December 4th,2012 5 / 51

The CUDA model: Introduction
Each thread runs the same scalar sequential program.
Threads are organized into a grid of thread-blocks
Threads of a given block can co-operate amongst themselves using
I Barrier Synchronization.
I Atomic operations
I Per-block shared memory space private to each block.
Each block can execute in any order relative to other blocks.
Threads in different blocks cannot co-operate.
Gaurish Telang (SUNY Stony Brook) Efficient SpMV on GPUs December 4th,2012 6 / 51

The CUDA model: Introduction
Each thread runs the same scalar sequential program.
Threads are organized into a grid of thread-blocks
Threads of a given block can co-operate amongst themselves using
I Barrier Synchronization.
I Atomic operations
I Per-block shared memory space private to each block.
Each block can execute in any order relative to other blocks.
Threads in different blocks cannot co-operate.
Gaurish Telang (SUNY Stony Brook) Efficient SpMV on GPUs December 4th,2012 6 / 51

The CUDA model: Introduction
Program Execution Memory Hierarchy
Gaurish Telang (SUNY Stony Brook) Efficient SpMV on GPUs December 4th,2012 7 / 51

The CUDA model: Scalability
Hardware is free to assign blocks to any processor at any time.I A kernel scales across any number of parallel processors.
Gaurish Telang (SUNY Stony Brook) Efficient SpMV on GPUs December 4th,2012 8 / 51

The CUDA C/C++ API
Gaurish Telang (SUNY Stony Brook) Efficient SpMV on GPUs December 4th,2012 9 / 51

Allocating and Releasing Device Memory
Memory Allocation
int* ptr = 0 ;
int N = 5000;
int num_bytes = N * sizeof( int );
cudaMalloc( &ptr , num_bytes );
Memory transfer
int* h = new int [5000]; //Fill the h array as needed
cudaMemcpy(d , h , num_bytes , cudaMemcpyHostToDevice );
// Do Computation on the device
// ...
cudaMemcpy(h , d , num_bytes , cudaMemcpyDeviceToHost );
Releasing Device Memory
cudaFree(d);
Gaurish Telang (SUNY Stony Brook) Efficient SpMV on GPUs December 4th,2012 10 / 51

Example CUDA Code: Simple SAXPY
Note: Calls to kernels are asynchronous by default.
Gaurish Telang (SUNY Stony Brook) Efficient SpMV on GPUs December 4th,2012 11 / 51

The CUDA model: SIMT nature
Thread creation, scheduling and management is performed entirely inhardware.
To manage this large population of threads efficiently, the GPUemploys a SIMT (Single Instruction Multiple Thread) architecture.
Threads of a block are executed in groups of 32 called warps
Gaurish Telang (SUNY Stony Brook) Efficient SpMV on GPUs December 4th,2012 12 / 51

The CUDA model: Warps
A warp executes a single instruction at a time across all its threads.
Threads of a warp are free to follow their own execution path and allsuch execution divergence is handled automatically in hardware.
However it is substantially more efficient for threads to follow thesame execution path for the bulk of the computation.
Gaurish Telang (SUNY Stony Brook) Efficient SpMV on GPUs December 4th,2012 13 / 51

The CUDA model: Warps
Threads of a warp are free to use arbitrary addresses when accessingoff-chip memory with load/store operations.
Accessing scattered locations results in memory-divergence andrequires the processor to perform one memory transaction per-thread.
Gaurish Telang (SUNY Stony Brook) Efficient SpMV on GPUs December 4th,2012 14 / 51

The CUDA model: Warps
Non-contiguous access to memory is detrimental to memorybandwidth efficiency and to memory-bound computations.
Gaurish Telang (SUNY Stony Brook) Efficient SpMV on GPUs December 4th,2012 15 / 51

Sparse Matrix Formats
Gaurish Telang (SUNY Stony Brook) Efficient SpMV on GPUs December 4th,2012 16 / 51

Sparse Matrix Formats
Main Idea: Encode the non-zero entries along with the positioninformation.
The encoding’s efficiency depends on the sparsity pattern.
Examples:I Diagonal (DIA)
I ELLPACK (ELL)
I Coordinate (COO)
I Compressed Sparse Row (CSR)
I Hybrid (ELL+COO)
I Packet (PKT)
and others (including hybrids) . . .
Gaurish Telang (SUNY Stony Brook) Efficient SpMV on GPUs December 4th,2012 17 / 51

Diagonal Format: Introduction
Appropriate when non-zerovalues arerestricted to a small number ofmatrix diagonals,
Efficiently encodes matricesarisingfrom application of stencils toregular grids.
Gaurish Telang (SUNY Stony Brook) Efficient SpMV on GPUs December 4th,2012 18 / 51

Diagonal Format: An Example
Gaurish Telang (SUNY Stony Brook) Efficient SpMV on GPUs December 4th,2012 19 / 51

Diagonal Format: + and -’s
Advantages:
Row and column indices of each non-zero are defined implicitly.This reduces memory footprint and data-transfer during an SpMVoperation.
Good for stencils applied to regular grids.
Disadvantages:
Allocates storage of values’outside’ the matrixand explicitly stores zero valuesalong the diagonal.
Not good for matrices witharbitrary sparsity patterns.
Gaurish Telang (SUNY Stony Brook) Efficient SpMV on GPUs December 4th,2012 20 / 51

ELLPACK format: Introduction
Appropriate for an M-by-Nmatrix with a maximum of Knon-zeros per row where K issmall.
Efficiently encodes sparsematrices which have roughly thesame number of non-zeros perrow.
Gaurish Telang (SUNY Stony Brook) Efficient SpMV on GPUs December 4th,2012 21 / 51

ELLPACK Format: An Example
Gaurish Telang (SUNY Stony Brook) Efficient SpMV on GPUs December 4th,2012 22 / 51

ELLPACK Format: + and -’s
Advantages:
More general than DIA
Good for matrices obtained from semi-structured and well-behavedunstructured meshes .
Disadvantages:
For unstructured meshes, theratio between max number ofnon-zeros per row and theaverage might be arbitrarilylarge.
Hence a vast majority of theentries in the data and indicesarray will be wasted.
Gaurish Telang (SUNY Stony Brook) Efficient SpMV on GPUs December 4th,2012 23 / 51

COO format
Consists of three separatearrays:
I row row-indicesI col column-indicesI data non-zero values
Required storage alwaysproportional to the number ofnon-zeros. unlike DIA and ELL
Row-array is kept sortedensuring entries with the samerow-index are storedcontiguously
Gaurish Telang (SUNY Stony Brook) Efficient SpMV on GPUs December 4th,2012 24 / 51

CSR format
A popular and general purposesparse matrix representation
Can be viewed as a naturalextension of the (sorted) COOrepresentation with a simplecompression scheme applied tothe (oft-repeated) row indices
Consists of three separatearrays:
I ptr new-row start pointersI indices column-indicesI data non-zero values
Required storage alwaysproportional to the number ofnon-zeros. like the COO
Gaurish Telang (SUNY Stony Brook) Efficient SpMV on GPUs December 4th,2012 25 / 51

CSR format
A popular and general purposesparse matrix representation
Can be viewed as a naturalextension of the (sorted) COOrepresentation with a simplecompression scheme applied tothe (oft-repeated) row indices
Consists of three separatearrays:
I ptr new-row start pointersI indices column-indicesI data non-zero values
Required storage alwaysproportional to the number ofnon-zeros. like the COO
Gaurish Telang (SUNY Stony Brook) Efficient SpMV on GPUs December 4th,2012 25 / 51

HYB ( = ELL + COO) format
ELL format is suited for vector machines, but its efficiency rapidlydegrades when the number of non-zeros per matrix varies a lot.
Storage efficiency of COO is invariant to the distribution of non-zerosper row. This invariance extends to the cost of a SpMV productusing COO.
Split A = B + C where
I B contains the typical number of non-zeros per row and is stored inELL.
I C contains the remaining entries of the exceptional rows and is storedin COO
Gaurish Telang (SUNY Stony Brook) Efficient SpMV on GPUs December 4th,2012 26 / 51

Packet(PKT) format
Tailored for symmetric mesh-based matrices such as those in FEM.
Idea
I Reorder the non-zeros in the matrix such that non-zeros are’concentrated’ near the main diagonal.
I Decompose this reordered matrix into a given number of fixed sizepartitions
I Each partition is then stored in a packet data-structure. and eachpacket is assigned to a thread-block.
Gaurish Telang (SUNY Stony Brook) Efficient SpMV on GPUs December 4th,2012 27 / 51

PKT format
Gaurish Telang (SUNY Stony Brook) Efficient SpMV on GPUs December 4th,2012 28 / 51

PKT format
Gaurish Telang (SUNY Stony Brook) Efficient SpMV on GPUs December 4th,2012 29 / 51

Sparse-Matrix Vector Multiplication
Gaurish Telang (SUNY Stony Brook) Efficient SpMV on GPUs December 4th,2012 30 / 51

Sparse Matrix Vector multiplication
We consider the operation y ← Ax + y
Central ideaMinimize the number of independent paths of execution and use thecoalescing of threads whenever possible.
Gaurish Telang (SUNY Stony Brook) Efficient SpMV on GPUs December 4th,2012 31 / 51

SpMV for the DIA format
Gaurish Telang (SUNY Stony Brook) Efficient SpMV on GPUs December 4th,2012 32 / 51

SpMV for the ELL format
Gaurish Telang (SUNY Stony Brook) Efficient SpMV on GPUs December 4th,2012 33 / 51

SpMV for the CSR format(first-version)
Gaurish Telang (SUNY Stony Brook) Efficient SpMV on GPUs December 4th,2012 34 / 51

SpMV for the CSR format(second-version)
Gaurish Telang (SUNY Stony Brook) Efficient SpMV on GPUs December 4th,2012 35 / 51

SpMV for the PKT format
Gaurish Telang (SUNY Stony Brook) Efficient SpMV on GPUs December 4th,2012 36 / 51

Performance
Gaurish Telang (SUNY Stony Brook) Efficient SpMV on GPUs December 4th,2012 37 / 51

Performance
Different classes of matrices highlight the strength and weaknesses ofthe sparse formats and their associated SpMV algorithms.
Performance data are measured in terms ofI Speed of execution (GFLOP/s)I Memory bandwidth utilization (GBytes/s)
Measurements do not include time spent transferring data betweenthe CPU and the GPU since we are trying to measure just the SpMVperformance.
The reported figures represent an average (arithmetic-mean) of 500SpMV operations.
Gaurish Telang (SUNY Stony Brook) Efficient SpMV on GPUs December 4th,2012 38 / 51

Structured Matrices
Gaurish Telang (SUNY Stony Brook) Efficient SpMV on GPUs December 4th,2012 39 / 51

Performance: Structured Matrices
Gaurish Telang (SUNY Stony Brook) Efficient SpMV on GPUs December 4th,2012 40 / 51

Performance: Structured Matrices: Execution Speed
Gaurish Telang (SUNY Stony Brook) Efficient SpMV on GPUs December 4th,2012 41 / 51

Performance: Structured Matrices: Memory Bandwidth
Gaurish Telang (SUNY Stony Brook) Efficient SpMV on GPUs December 4th,2012 42 / 51

Unstructured Matrices
Gaurish Telang (SUNY Stony Brook) Efficient SpMV on GPUs December 4th,2012 43 / 51
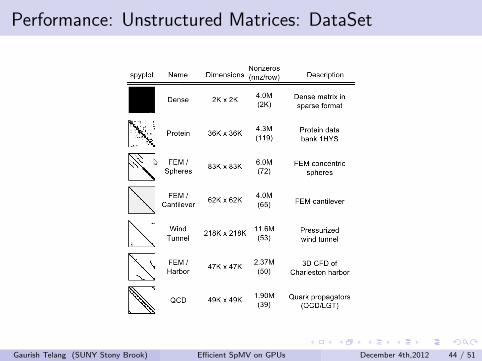
Performance: Unstructured Matrices: DataSet
Gaurish Telang (SUNY Stony Brook) Efficient SpMV on GPUs December 4th,2012 44 / 51

Performance: Unstructured Matrices: DataSet (ctd...)
Gaurish Telang (SUNY Stony Brook) Efficient SpMV on GPUs December 4th,2012 45 / 51

Performance: Unstructured Matrices: Speed Of Execution
Gaurish Telang (SUNY Stony Brook) Efficient SpMV on GPUs December 4th,2012 46 / 51

Performace: Unstructured Matrices: Memory Bandwidth
Gaurish Telang (SUNY Stony Brook) Efficient SpMV on GPUs December 4th,2012 47 / 51

Performance: Comparisons With Multicore
Platform Specifications
Gaurish Telang (SUNY Stony Brook) Efficient SpMV on GPUs December 4th,2012 48 / 51

Performance: Comparison With Single Socket
Gaurish Telang (SUNY Stony Brook) Efficient SpMV on GPUs December 4th,2012 49 / 51

Performance: Comparison With Double Socket
Gaurish Telang (SUNY Stony Brook) Efficient SpMV on GPUs December 4th,2012 50 / 51

Questions?
Gaurish Telang (SUNY Stony Brook) Efficient SpMV on GPUs December 4th,2012 51 / 51