“efficient software-based fault isolation” (1993) by: robert wahbe, steven lucco, thomas e....
TRANSCRIPT

“Efficient Software-Based Fault Isolation” (1993)by: Robert Wahbe, Steven Lucco, Thomas E. Anderson, Susan L. GrahamPRESENTED BY DAVID KENNEDY

Software Fault Isolation We focus on using it to divide a monolithic OS into separate logical fault domains.
Many Other Uses: "device driver shouldn't compromise OS“ "codec shouldn't compromise media player" "plugin shouldn't compromise browser"

Microkernels Provide Fault Isolation by putting different OS modules in their own address space
Problem: L3 and L4 microkernels do have acceptable performance, but these have the OS server within a single address space. This does not provide the kind of fine-grained protection we need to separate different parts of an operating system from itself (ex. Device drivers) Solution in this and SPIN paper: Move back to the monolithic kernel, but modularize the kernel in ways other partitioning the address space
In Spin, protection provided by type-safe language In SFI, it is provided by software based fault domains

Two Methods of Fault Isolation 1. Traditional UNIX Approach with Virtual Memory and Context Switches
-Separate address space for each process
-Separate resource permission per process
-Processes communicate with other processes using RPC, Pipes
Problem: IPC is too expensive
2. Software Based “logical context switch” that switches between fault domains in in the same address space. Untrusted fault domains can only access certain parts of the address space because untrusted fault domains can only access memory on their own two segments
While communication was too expensive in the traditional approach, in this approach communication is cheap because it is through RPC-like communication between modules in the same address space. No Context Switches!

Safety Through Segmentation "The key idea was simple: adjust all memory accesses (including control flow references) to go through a dedicated register. Then by choosing a memory region whose size and alignment are the same power of two, it is very easy to guarantee that any memory access will lie within that region. Simply by requiring that certain bits of that register always remain constant, it is possible to ensure that memory accesses are safe. For static references, this can be checked offline. For indirect references, it is necessary to insert some instructions to test and set these bits.”
Each untrusted module is loaded at runtime into its own fault domain by a host module within the same address space.
Each untrusted module is given exclusive access of two memory segments where “all virtual addresses within a segment share a unique pattern of upper bits, the segment identifier (Wahbe, 205).”

Two Segments Per Untrusted Fault Domain
1. One holds the code segment of the distrusted module
CODE SEGMENT
2.The other holds the static data, heap, and stack
DATA SEGMENT
These segments are assigned at load time and then the code for an untrusted module is dynamically loaded by a trusted host module

Program TransformationProgram must be transformed at some point before execution into a program with equivalent properties, plus the additional property that …
all unsafe instructions within a module in an untrusted fault domain should be checked to ensure that they do not access parts of the address space they should not be able to access.
These unsafe instructions are…
1. Loads and Stores to parts of memory not in data segment
2. any Indirect Jumps from the code segment to somewhere not in the code segment

Transformation Can Occur During Compilation or Loading
In interpreted languages, sandboxing could be achieved when dynamically loading the program
This approach highly architecture independent, but no good solution given in paper…
Approach of Wahbe et. al….
1.modify GCC compiler to sandbox the code…
They sandbox for two RISC architectures, MIPS and Alpha (does this mean they are sandboxing assembly code?)
2.Verify at Load time that you are bringing in sandboxed code
This can be done many ways, one is by signing and using a public/private key

Sandboxing During compilationOne approach: (from http://www.cs.dartmouth.edu/reports/TR96-287.pdf)
Modify GCC so that sandboxing is done in the first optimization phase of compilation performed on an intermediate representation (IR) close to (but before) assembly code called…
Register Transfer Language (RTL)
A series of optimizations (ie loop unrolling, code motion) performed on RTL.
We add two:
1.Reserve 5 dedicated registers 2. add sandboxing instructions
RTL is like an “architecture-neutral assembly language (RTL Wikipedia).”
Could implement to modify assembly language, but then this would be tied to certain architectures…

Compile Time Sandboxing Needs Runtime Verification
In Wahbe et. al, a runtime verification application follows this algorithm this algorithm
--Divide the unsafe code into unsafe regions starting with instruction that modifies either the dedicated register to hold all stores or the dedicated register to hold all indirect jumps
--Unsafe Regions end in a few ways, an important one is…
a store or jump to the address stored in one of these two dedicated registers
The verifier ensures that all dedicated registers are valid when leaving an unsafe region.
All modifications to these two registers occur within an unsafe region…
Sort of like a lock.

Another Verification Approach (used in http://www.cs.dartmouth.edu/reports/TR96-287.pdf)
A trusted compiler cryptographically signs an untrusted module.
At load time, verify this signature.

Is This Language Independent? One drawback of the SPIN approach is that it means that all OS programs must be written in the same high-level language
Wahbe et. al. claim SFI is language-independent.
But their SFI uses GCC, which has front ends for only certain languages and is mostly used on UNIX devices
IN THEORY, it is language independent. Still limited by the environments in which GCC operates (which are many)

Segment Matching
Below is from: http://www.cs.dartmouth.edu/reports/TR96-287.pdf
Uses 4 dedicated registers

4 Dedicated Registers for Segment Matching 1. holds all addresses in code segment 2.holds all addresses in data segment 3. holds the segment shift amount 4. holds the segment identifier (Code or data)

uses 5 dedicated registers
Sandboxing

5 Dedicated Registers for Sandboxing 1. holds the segment mask 2. holds the code segment identifier 3.holds the data segment identifier 4. holds all address references in code segment 5.holds all address references in data segment

cmp x 0300 if less Error cmp x 03FF if greater Error write x
Version with 5x Instruction overhead (Segment Matching)
Writes are much more frequent than IPC5X the code on any write
Maybe we should just accept cost of context switch??
Example from: http://www.cs.cornell.edu/courses/cs513/2000sp/L13.html

tmp := x & FF00 //copy segment id of ‘x’ into tmp
cmp tmp 0300 //compare segment id to dedicated register //value ‘0300’
if not equal Error //trap to OS
write x
Version with 4x instruction overhead

tmp : = x & 00FF tmp : = tmp | 0300 write tmp
Two Versions with 3x Instruction Overhead(Sandboxing)
‘tmp’ is a dedicated register
x : = x & 00FF x : = tmp | 0300 write x
‘x’ is NOT a dedicated register

Difference Between Two Versions on Last Slide
Imagine a malicious program that realizes sandboxing is three instructions, and skips to the third instruction….
On version without a dedicated register, if malicious program goes to third instruction, it could write to a region that was not in its data segment.
On version with a dedicated register ‘tmp’, if malicious program goes to third instruction, ‘tmp’ will always still be an address in its own data segment (assuming the segment id mask is also dedicated)
‘TMP’ Dedicated Register Invariant
“the register 'tmp' always contains a valid address unless the program is in the midst of an SFI (Software Fault Isolation) sequence” (from http://www.cs.cornell.edu/courses/cs513/2000sp/L13.html)

Segment Matching vs. Sandboxing If we want the address of the offending instruction for debugging, we need to use segment matching
Sandboxing is more efficient

Why do we need dedicated registers?
On last two slides, a difference in each of these two coding approaches. The ones on bottom do not use dedicated registers, the ones on the right do.
A malicious program could detect it is sandboxed, skip over the first two checking instructions and perform the unsafe load (in this case).
However, in sandboxing pseudocode from Wahbe, using a dedicated register makes it so even if we skip the first two instructions the dedicated register will contain a valid address

Cost of Reserving Dedicated Registers
If we reserve too many dedicated registers, performance will suffer when executing untrusted code.
But on both DEC-Alpha and DEC-MIPS, at least 32 registers are usable, and reducing by 5 has no noticeable effect.
If we are on an architecture with less registers (8 for example), performance might suffer too much

Cross Domain RPC Inspired by LRPC
Same thread runs in caller and callee
Stubs are as simple as possible
Call stub sends call directly to exported procedure, no dispatch procedure

When the call stub is invoked, it 1.saves trusted register context 2.set up dedicated registers with correct values for untrusted 3.change the stack pointer to untrusted stack 4.copy arguments not passed to
untrusted using registers onto untrusted stack
5.Jump to function call in untrusted
When the return stub is invoked, it 1.restore trusted register context 2.change the stack pointer to trusted stack 3.transfer any arguments or return
values not in registers back to
trusted stack

Call and Return Stubs “For each pair of fault domains a customized call and return stub is created for each exported procedure (Wahbe, 209).”
The previous diagram shows a trusted module calling into an untrusted module.
Q1: Can an untrusted module call into a trusted module? NO! Only return via jump table
Q2: Can an untrusted module call into another untrusted module? YES!

So if we have 2 trusted modules and 4 untrusted modules, and 1 exported procedure in each module, we need 20 sets of call and return stubs…
1)1t -> 1u 2)1t -> 2u3)1t -> 3u4)1t -> 4u5)2t -> 1u6)2t -> 2u7)2t -> 3u8)2t -> 4u9)1u -> 2u10)1u -> 3u
11)1u -> 4u12)2u -> 1u13)2u -> 3u14)2u -> 4u15)3u -> 1u16)3u -> 2u17)3u -> 4u18)4u -> 1u19)4u -> 2u20)4u -> 3u
Where 1t-> 1u means…
Trusted Module #1 calls Untrusted Module #1

But doesn’t our jump table to exit untrusted code violate sandboxing?
According to our rules, all indirect jump instructions must be sandboxed
However, our jump table contains direct jumps, these can be verified at compile time
Jump table placed on an unwritable page (in the code segment)
Jump Table holds target addresses as “immediate encoded in the instruction (Wahbe, 209).”
Usually, if we are compiling the code segment and there is a direct jump, we can check to be sure that this instruction refers to the correct segment at compile time.
Exception to this rule for jump table which does need to be checked at compile time, but does not need to refer to addresses in its own fault domain.
“The only way for control to escape a fault domain is via a jump table (Wahbe, 209).”

We Only Sandbox Indirect Jumps http://en.wikipedia.org/wiki/Indirect_branch:
Rather than specifying the address of the next instruction to execute, as in a direct branch, the argument specifies where the address is located. Thus an example could be to 'jump indirect on the r1 register', which would mean that the next instruction to be executed would be at the address whose value is in register r1. The address to be jumped to is not known until the instruction is executed.
Indirect Jumps are sandboxed because their address is not known until execution time

Sandbox System Calls from Untrusted Domains All domains in an address space would have access to system calls to change per-address space state, such as open file descriptors One Solution: the kernel knows about untrusted domains
will treat system calls from untrusted domains differently PROBLEM: not portable to different OSBetter Solution: reroute system calls through a trusted module in same address space

Claim: Cross fault-domain RPC cost of copying arguments is very low Most of the cost is in saving and restoring register context
Compared to Procedure Calls and IPC
All 5 columns are versions of a NULL procedure call.Why can we ignore time for argument copying?
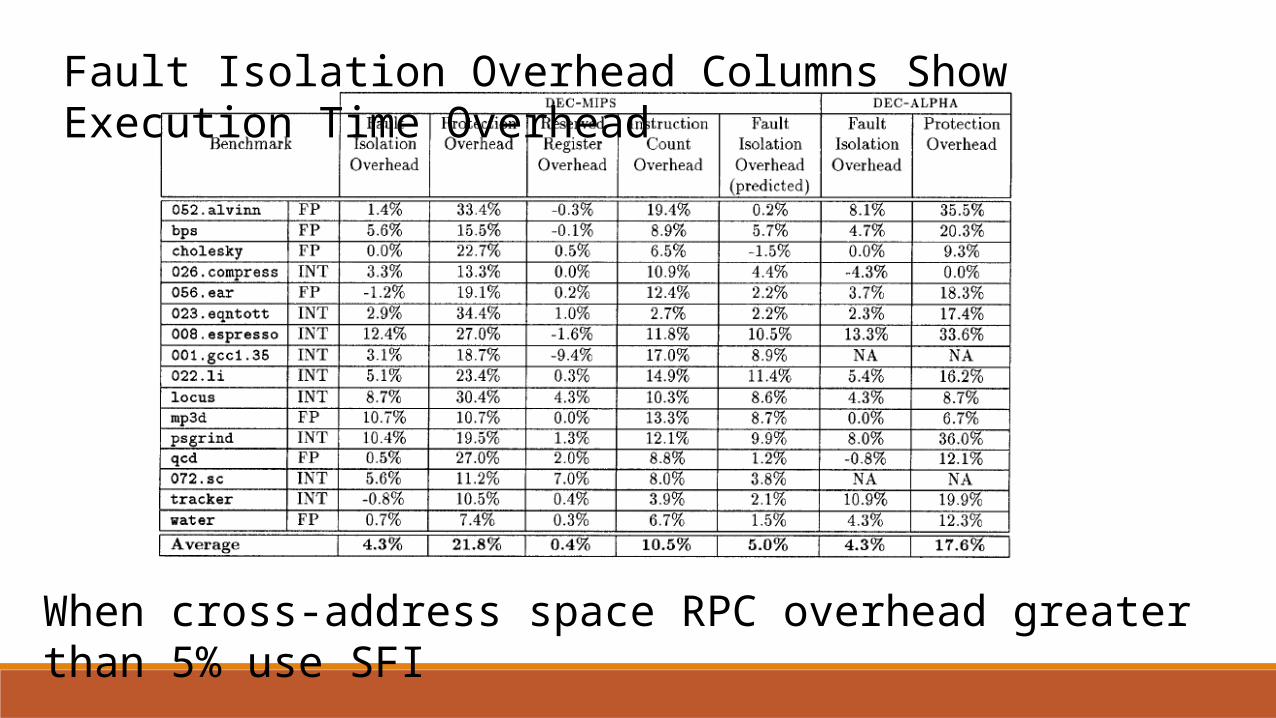
Fault Isolation Overhead Columns Show Execution Time Overhead
When cross-address space RPC overhead greater than 5% use SFI

What explains variation in last Table? Data cache alignment not a factor Instruction cache alignment is a factor --changes mapping of instructions to cache lines Instruction cache conflicts hurt performance more than data cache conflicts Also, floating point intensive programs do better…

PostGres with User-Defined Polygon Data Types
First Column: code in unsafe language, like C, is dynamically loaded into database manager
Second Column: cost of sandboxing PostGres polygonsThird Column: auto-generated count of cross-domain RPC calls used to calculate fourth columnFourth Column: estimated cost of code using traditional hardware address spaces
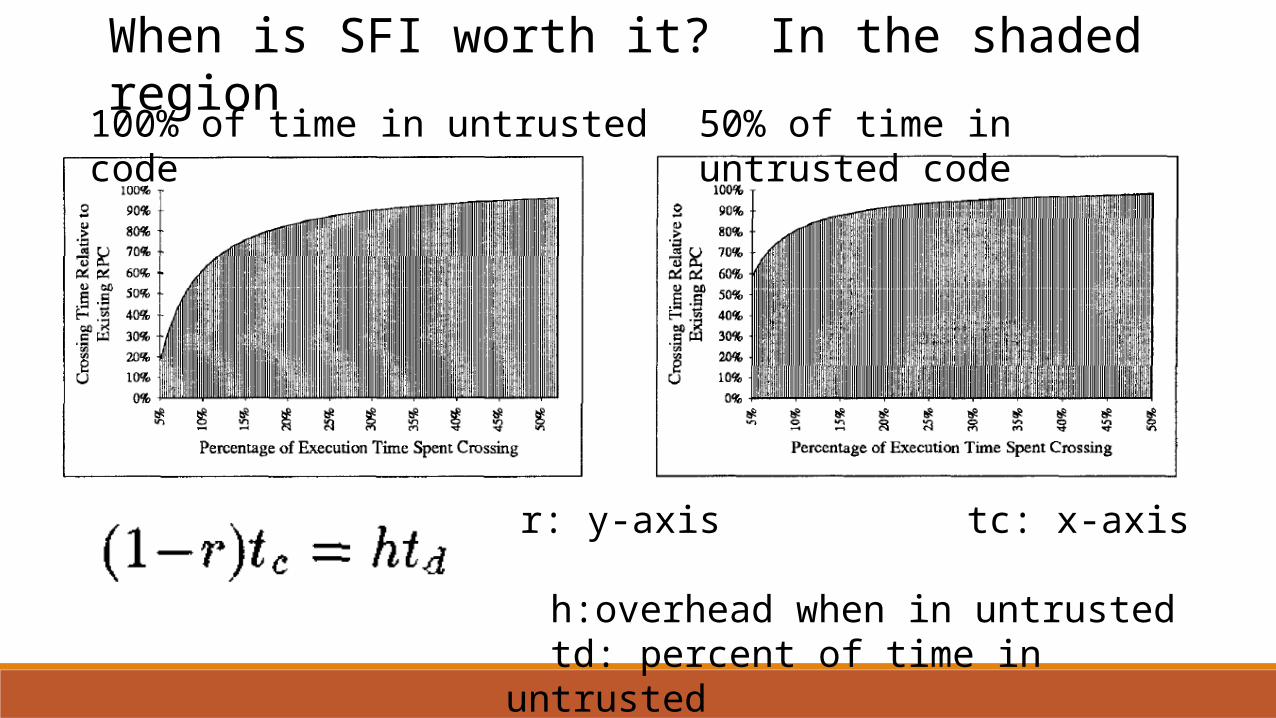
50% of time in untrusted code100% of time in untrusted code
r: y-axis tc: x-axis h:overhead when in untrusted td: percent of time in untrusted
When is SFI worth it? In the shaded region

SFI sounds TOO good, are there downsides?
While authors say advantage is that it works in theory for any programming language, it depends on certain kinds of machine architectures. Should the application really care about architecture?
Made for RISC, open question if it would work on CISC architectures. Other papers have shown it can, but still will not work on architectures without enough registers to assign as dedicated registers