effective use of openmp in games
DESCRIPTION
Effective Use of OpenMP in Games. Pete Isensee Lead Developer Xbox Advanced Technology Group. Agenda. Why OpenMP Examples How it really works Performance, common problems, debugging and more Best practices. Today: Games & Multithreading. - PowerPoint PPT PresentationTRANSCRIPT

Effective Use ofEffective Use ofOpenMP in GamesOpenMP in Games
Pete IsenseePete IsenseeLead DeveloperLead Developer
Xbox Advanced Technology Xbox Advanced Technology GroupGroup

AgendaAgenda• Why OpenMPWhy OpenMP• ExamplesExamples• How it really worksHow it really works• Performance, common Performance, common
problems, debugging and problems, debugging and moremore
• Best practicesBest practices

Today: Games & Today: Games & MultithreadingMultithreading• Few current game platforms Few current game platforms
have multiple-core have multiple-core architecturesarchitectures
• Multithreading pain often not Multithreading pain often not worth performance gainworth performance gain
• Most games are single-Most games are single-threaded (or mostly single-threaded (or mostly single-threaded)threaded)

The Future of CPUsThe Future of CPUs• CPU design factors: die size, CPU design factors: die size,
frequency, power, features, yieldfrequency, power, features, yield• Historically, MIPS valued over wattsHistorically, MIPS valued over watts• Vendors have hit the “power wall”Vendors have hit the “power wall”• Architectures changing to adjustArchitectures changing to adjust
– Simpler (e.g. in order instead of OOO)Simpler (e.g. in order instead of OOO)– Multiple coresMultiple cores

Two Things are CertainTwo Things are Certain• Future game platforms will Future game platforms will
have multi-core architectureshave multi-core architectures– PCsPCs– Game consolesGame consoles
• Games wanting to maximize Games wanting to maximize performance will be performance will be multithreadedmultithreaded

Addressing the ProblemAddressing the Problem• Ignore it: write unthreaded Ignore it: write unthreaded
codecode• Use an MT-enabled languageUse an MT-enabled language• Use MT middlewareUse MT middleware• Thread libraries (e.g. Pthreads)Thread libraries (e.g. Pthreads)• Write OS-specific MT codeWrite OS-specific MT code• Lock-free programmingLock-free programming• OpenMPOpenMP

OpenMP DefinedOpenMP Defined• Interface for parallelizing codeInterface for parallelizing code
– PortablePortable– ScalableScalable– High-levelHigh-level– FlexibleFlexible– StandardizedStandardized– Performance-orientedPerformance-oriented
• Assumes shared-memory modelAssumes shared-memory model

Brief BackgrounderBrief Backgrounder• 10-year history10-year history• Created primarily for research Created primarily for research
and supercomputing and supercomputing communitiescommunities
• Some relevant game compilersSome relevant game compilers– Intel C++ 8.1Intel C++ 8.1– Microsoft Visual Studio 2005Microsoft Visual Studio 2005– GCC (see GOMP)GCC (see GOMP)

OpenMP for C/C++OpenMP for C/C++• Directives activate OpenMPDirectives activate OpenMP
– #pragma omp <directive> [clauses]#pragma omp <directive> [clauses]– Define parallelizable sectionsDefine parallelizable sections– Ignored if compiler doesn’t grok Ignored if compiler doesn’t grok
OMPOMP• APIsAPIs
– Configuration (e.g. # threads)Configuration (e.g. # threads)– Synchronization primitivesSynchronization primitives

0.0 0.0 0.0 0.0 0.0 0.0 0.0
Canonical ExampleCanonical Examplefor( i=1; i < n; ++i ) b[i] = (a[i] + a[i-1]) / 2.0;
0.1
0.0
2.1 4.3 0.7 0.1 5.2 8.8 0.2
1.1 3.2 2.5 0.4 2.7 6.7 4.5
a
b
...
...

0.0 0.0 0.0 0.0 0.0 0.0 0.0
Thread TeamsThread Teams#pragma omp parallel forfor( i=1; i < n; ++i ) b[i] = (a[i] + a[i-1]) / 2.0;
0.1
0.0
2.1 4.3 0.7 0.1 5.2 8.8 0.2
1.1 3.2 2.5 0.4 2.7 6.7 4.5
a
b
...
...
Thread0 Thread1

Performance Performance MeasurementsMeasurements• Compiler: Visual C++ 2005 Compiler: Visual C++ 2005
derivativederivative• Max threads/team: 2Max threads/team: 2• HardwareHardware
– Dual core 2.0 GHz PowerPC G5Dual core 2.0 GHz PowerPC G5– 64K L1, 512K L264K L1, 512K L2– FSB: 8GB/s per coreFSB: 8GB/s per core– 512 MB512 MB

Performance of ExamplePerformance of Example#pragma omp parallel forfor( i=1; i < n; ++i ) b[i] = (a[i] + a[i-1]) / 2.0;
• Performance on test hardwarePerformance on test hardware– n = 1,000,000n = 1,000,000– 1.6X faster1.6X faster– OpenMP library/code added 55KOpenMP library/code added 55K

Compare with Windows Compare with Windows ThreadsThreadsDWORD ThreadFn( VOID* pData ) { // Primary function for( int i = pData->Start; i < pData->Stop; ++i ) b[i] = (a[i] + a[i-1]) / 2.0; return 0; }
for( int i=0; i < n; ++i ) // Create thread team hTeam[i] = CreateThread( 0, 0, ThreadFn, pDataN, 0, 0 );
// Wait for completion WaitForMultipleObjects( n, hTeam, TRUE, INFINITE );
for( int i=0; i < n; ++i ) // Clean up CloseHandle( hTeam[i] );

Performance of Native Performance of Native ThreadsThreads• n = 1,000,000n = 1,000,000• 1.6X faster1.6X faster• Same performance as OpenMPSame performance as OpenMP
– But 10X more code to writeBut 10X more code to write– Not cross platformNot cross platform– Doesn’t scaleDoesn’t scale
• Which would you choose?Which would you choose?

What’s the Catch?What’s the Catch?•Performance gains depend Performance gains depend
on on nn and the work in the and the work in the looploop
•Usage restrictedUsage restricted– Simple for loopsSimple for loops– Parallel code sectionsParallel code sections
•Operations must be order-Operations must be order-independentindependent
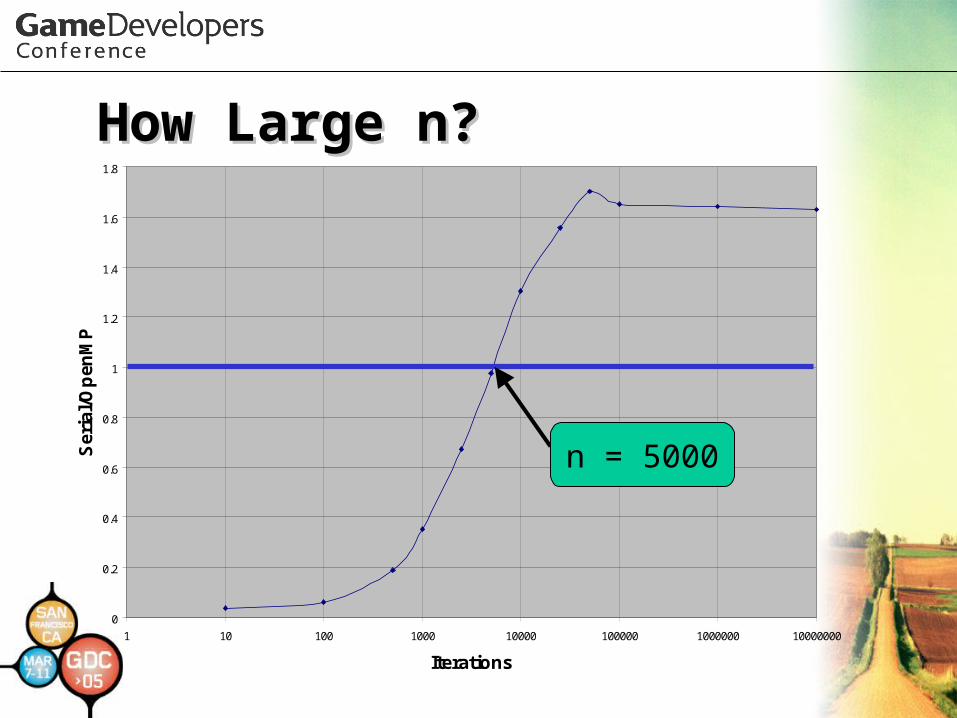
How Large n?How Large n?
0
0.2
0.4
0.6
0.8
1
1.2
1.4
1.6
1.8
1 10 100 1000 10000 100000 1000000 10000000
Iterations
Serial/OpenMP
n = 5000

for Loop Restrictionsfor Loop Restrictions• Let’s try parallelizing an STL loopLet’s try parallelizing an STL loop
#pragma omp parallel forfor( itr i = v.begin(); i != v.end(); ++i ) // ...
• OpenMP limitationsOpenMP limitations– i must be an integeri must be an integer– Initialization expression: i = invariantInitialization expression: i = invariant– Compare with invariantCompare with invariant– Logical comparison only: <,<=,>,>=Logical comparison only: <,<=,>,>=– Increment: ++, --, +=, -=, +/- invariantIncrement: ++, --, +=, -=, +/- invariant– No breaks allowedNo breaks allowed

2.0 3.0 1.0
Independent Independent CalculationsCalculations• This is evil:This is evil:
#pragma omp parallel forfor( i=1; i < n; ++i ) a[i] = a[i-1] * 0.5;
4.0
4.0
2.0 3.0 1.0
2.0 1.0 1.5
a
a
Thread0 Thread1
Oh no!Should be 0.5

You Bear the BurdenYou Bear the Burden• Verify performance gainVerify performance gain• Loops must be order-independentLoops must be order-independent
– Compiler cannot usually help youCompiler cannot usually help you– Validate resultsValidate results
• Assertions or other checksAssertions or other checks• Be able to toggle OpenMPBe able to toggle OpenMP
– Set thread teams to max 1Set thread teams to max 1– #ifdef USE_OPENMP #pragma omp parallel for #endif

Configuration APIsConfiguration APIs#include <omp.h>
// examplesint n = omp_get_num_threads();omp_set_num_threads( 4 );int c = omp_get_num_procs();omp_set_dynamic( 16 );

OMP Synchronization OMP Synchronization APIsAPIsOpenMP nameOpenMP name Wraps Windows:Wraps Windows:omp_lock_t CRITICAL_SECTION
omp_init_lock InitializeCriticalSection
omp_destroy_lock DeleteCriticalSection
omp_set_lock EnterCriticalSection
omp_unset_lock LeaveCriticalSection
omp_test_lock TryEnterCriticalSection

Synchronization Synchronization ExampleExampleomp_lock_t lk;omp_init_lock( &lk );#pragma omp parallel{ int id = omp_get_thread_num(); omp_set_lock( &lk ); printf( “Thread %d”, id ); omp_unset_lock( &lk );}omp_destroy_lock( &lk );

OpenMP: UnpluggedOpenMP: Unplugged• Compiler checks OpenMP conformanceCompiler checks OpenMP conformance• Injects code for #pragma omp blocksInjects code for #pragma omp blocks• Debugging runtime checks for Debugging runtime checks for
deadlocksdeadlocks• Thread team created at app startupThread team created at app startup• Per-thread data allocated when Per-thread data allocated when
#pragma entered#pragma entered• Work divided into coherent chunksWork divided into coherent chunks

DebuggingDebugging• Thread debugging is hardThread debugging is hard• OpenMP OpenMP →→ black box black box
– Presents even more challengesPresents even more challenges• Much depends on compiler/IDEMuch depends on compiler/IDE• Visual Studio 2005Visual Studio 2005
– Allows breakpoints in parallel sectionsAllows breakpoints in parallel sections– omp_get_thread_num() to get thread omp_get_thread_num() to get thread
IDID
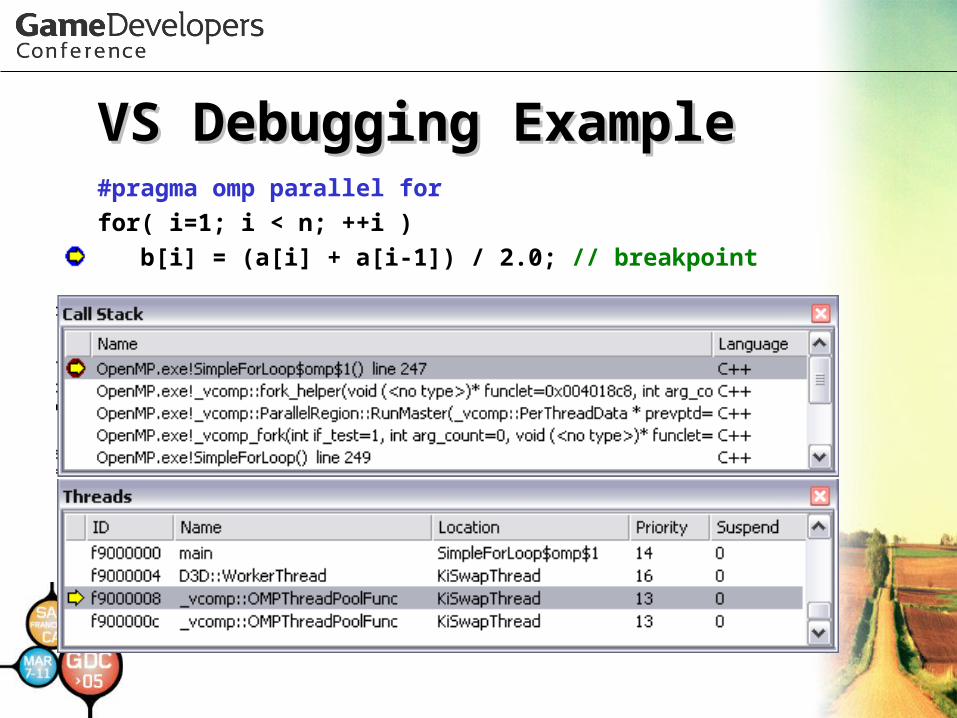
VS Debugging ExampleVS Debugging Example#pragma omp parallel forfor( i=1; i < n; ++i ) b[i] = (a[i] + a[i-1]) / 2.0; // breakpoint

OpenMP SectionsOpenMP Sections• Executing concurrent Executing concurrent
functionsfunctions#pragma omp parallel sections{ #pragma omp section Xaxis(); #pragma omp section Yaxis(); #pragma omp section Zaxis();}

Common ProblemsCommon Problems• Parallelizing STL loopsParallelizing STL loops• Parallelizing pointer-chasing Parallelizing pointer-chasing
loopsloops• The early-out problemThe early-out problem• Scheduling unpredictable Scheduling unpredictable
workwork

STL LoopsSTL Loops• For STL vector/dequeFor STL vector/deque
#pragma omp parallel forfor( size_type i = 0; i < v.size(); ++i ) // use v[i]
• In theory, possible to write In theory, possible to write parallelized STL algorithmsparallelized STL algorithms// examplesomp::transform( v.begin(), v.end(), w.begin(), tfx );omp::accumulate( v.begin(), v.end(), 0 );
• In practice, it’s a Hard ProblemIn practice, it’s a Hard Problem

Pointer-chasing loopsPointer-chasing loops• SingleSingle: executed by only 1 : executed by only 1
threadthread• NowaitNowait: removes implied barrier: removes implied barrier• Looping over a linked list:Looping over a linked list:
#pragma omp parallelfor( p = list; p != NULL; p = p->next ) #pragma omp single nowait process( p ); // efficient if mucho work here

Early outEarly out• The problemThe problem
#pragma omp parallel forfor( int i = 0; i < n; ++i ) if( FindPath( i ) ) break;
• SolutionsSolutions– May be faster to process all May be faster to process all
paths anywaypaths anyway– Process in multiple chunksProcess in multiple chunks

Scheduling unpredictable Scheduling unpredictable workwork• The problemThe problem
#pragma omp parallel forfor( int i = 0; i < n; ++i ) f( i ); // f takes variable time
• SolutionSolution#pragma omp parallel for schedule(dynamic)for( int i = 0; i < n; ++i ) f( i ); // f takes variable time

When to choose OpenMPWhen to choose OpenMP• Platform is multi-corePlatform is multi-core• Profiling shows a need: 1 core is Profiling shows a need: 1 core is
peggedpegged• Inner loops where:Inner loops where:
– N or loop work is significantly largeN or loop work is significantly large– Processing is order-independentProcessing is order-independent– Loops follow OpenMP canonical formLoops follow OpenMP canonical form
• Cross-platform importantCross-platform important• Last-minute optimizationsLast-minute optimizations

Game ApplicationsGame Applications• Particle systemsParticle systems• SkinningSkinning• Collision detectionCollision detection• Simulations (e.g. pathfinding)Simulations (e.g. pathfinding)• Transforms (e.g. vertex transforms)Transforms (e.g. vertex transforms)• Signal processingSignal processing• Procedural synthesis (e.g. clouds, Procedural synthesis (e.g. clouds,
trees)trees)• FractalsFractals

Getting Your Feet WetGetting Your Feet Wet• Add #pragma ompAdd #pragma omp• Inform your build toolsInform your build tools
– Set compiler flag; e.g. /openmpSet compiler flag; e.g. /openmp– Link with library; e.g. vcomp[d].libLink with library; e.g. vcomp[d].lib
• Verify compiler supportVerify compiler support#ifdef _OPENMP printf( “OpenMP enabled” );#endif
• Include omp.h to use any Include omp.h to use any structs/APIsstructs/APIs#include <omp.h>

Best PracticesBest Practices• RTFM: Read the specRTFM: Read the spec• Use OMP only where you need Use OMP only where you need
itit• Understand when it’s usefulUnderstand when it’s useful• Measure performanceMeasure performance• Validate results in debug modeValidate results in debug mode• Be able to turn it offBe able to turn it off

QuestionsQuestions• Me: [email protected]: [email protected]• This presentation: This presentation:
gdconf.comgdconf.com

ReferencesReferences• OpenMPOpenMP
– www.openmp.orgwww.openmp.org• The Free Lunch Is OverThe Free Lunch Is Over
– www.gotw.ca/publications/concurrency-ddj.htmwww.gotw.ca/publications/concurrency-ddj.htm• Designing for PowerDesigning for Power
– ftp://download.intel.com/technology/silicon/power/download/ftp://download.intel.com/technology/silicon/power/download/design4power05.pdfdesign4power05.pdf
• No Exponential Is ForeverNo Exponential Is Forever– ftp://download.intel.com/research/silicon/ftp://download.intel.com/research/silicon/
Gordon_Moore_ISSCC_021003.pdfGordon_Moore_ISSCC_021003.pdf• Why Threads Are a Bad IdeaWhy Threads Are a Bad Idea
– home.pacbell.net/ouster/threads.pdfhome.pacbell.net/ouster/threads.pdf• Adaptive Parallel STLAdaptive Parallel STL
– parasol.tamu.edu/compilers/research/STAPL/parasol.tamu.edu/compilers/research/STAPL/• Parallel STLParallel STL
– www.extreme.indiana.edu/hpc++/docs/overview/class-lib/www.extreme.indiana.edu/hpc++/docs/overview/class-lib/PSTLPSTL
• GOMPGOMP– gcc.gnu.org/projects/gompgcc.gnu.org/projects/gomp