eeng449b/savvides lec 4.1 1/25/05 january 25 and 25, 2005 prof. andreas savvides spring 2005 g449b...
Post on 21-Dec-2015
217 views
TRANSCRIPT

EENG449b/SavvidesLec 4.1
1/25/05
January 25 and 25, 2005
Prof. Andreas Savvides
Spring 2005
http://www.eng.yale.edu/courses/2005s/eeng449b
EENG 449b/CPSC 439b Computer Systems
Lecture 4
Intro to Pipelining

EENG449b/SavvidesLec 4.2
1/25/05
Announcements
• Reading for this week– Appendix A
• Homework #1 (Due Feb 10)– Chapter 2: Problems 2.5, 2.11, 2.12, 2.19– Appendix A: Problems A.1, A.5, A.6, A.7, A.11
• Next week overview– Complete pipelining discussion– Different processor architectures– Requirements for simulator discussion

EENG449b/SavvidesLec 4.3
1/25/05
Fast, Pipelined Instruction Interpretation
Instruction Register
Operand Registers
Instruction Address
Result Registers
Next Instruction
Instruction Fetch
Decode &Operand Fetch
Execute
Store Results
NIIF
DE
W
NIIF
DE
W
NIIF
DE
W
NIIF
DE
W
NIIF
DE
W
Time
Registers or Mem

EENG449b/SavvidesLec 4.4
1/25/05
Sequential Laundry
• Sequential laundry takes 6 hours for 4 loads• If they learned pipelining, how long would laundry take?
A
B
C
D
30 40 2030 40 2030 40 2030 40 20
6 PM 7 8 9 10 11 Midnight
Task
Order
Time

EENG449b/SavvidesLec 4.5
1/25/05
Pipelined LaundryStart work ASAP
• Pipelined laundry takes 3.5 hours for 4 loads
A
B
C
D
6 PM 7 8 9 10 11 Midnight
Task
Order
Time
30 40 40 40 40 20

EENG449b/SavvidesLec 4.6
1/25/05
Pipelining Lessons
• Pipelining doesn’t help latency of single task, it helps throughput of entire workload
• Pipeline rate limited by slowest pipeline stage
• Multiple tasks operating simultaneously
• Potential speedup = Number pipe stages
• Unbalanced lengths of pipe stages reduces speedup
• Time to “fill” pipeline and time to “drain” it reduces speedup
A
B
C
D
6 PM 7 8 9
Task
Order
Time
30 40 40 40 40 20

EENG449b/SavvidesLec 4.7
1/25/05
Instruction Pipelining
• Execute billions of instructions, so throughput is what matters
– except when?
• What is desirable in instruction sets for pipelining?
– Variable length instructions vs. all instructions same length?
– Memory operands part of any operation vs. memory operands only in loads or stores?
– Register operand many places in instruction format vs. registers located in same place?

EENG449b/SavvidesLec 4.8
1/25/05
Requirements for Pipelining
Goal: Start a new instruction at every cycle
What are the hardware implications?• Two different tasks should not attempt to use the same
datapath resource on the same clock cycle.• Instructions should not interfere with each other• Need to have separate data and instruction memories• Need increased memory bandwidth
– A 5-stage pipeline operating at the same clock rate as pipelined version requires 5 times the bandwidth
• Need to introduce pipeline registers • Register file used in two places in the ID and WB stages
– Perform reads in the first half and writes in the second half.

EENG449b/SavvidesLec 4.9
1/25/05
Pipelining Limitations
• The CPU clock cannot run faster than the time needed for the slowest pipeline stage
• Imbalance of pipelining overhead• Time needed to fill up the pipeline
Pipelining speedup=avg. instruction time w/o pipelining/avg. instruction time w pipelining

EENG449b/SavvidesLec 4.10
1/25/05
Recap: 5 Steps of MIPS Datapath
MemoryAccess
Write
Back
InstructionFetch
Instr. DecodeReg. Fetch
ExecuteAddr. Calc
LMD
ALU
MU
X
Mem
ory
Reg File
MU
XM
UX
Data
Mem
ory
MU
X
SignExtend
4
Ad
der Zero?
Next SEQ PC
Addre
ss
Next PC
WB Data
Inst
RD
RS1
RS2
Imm
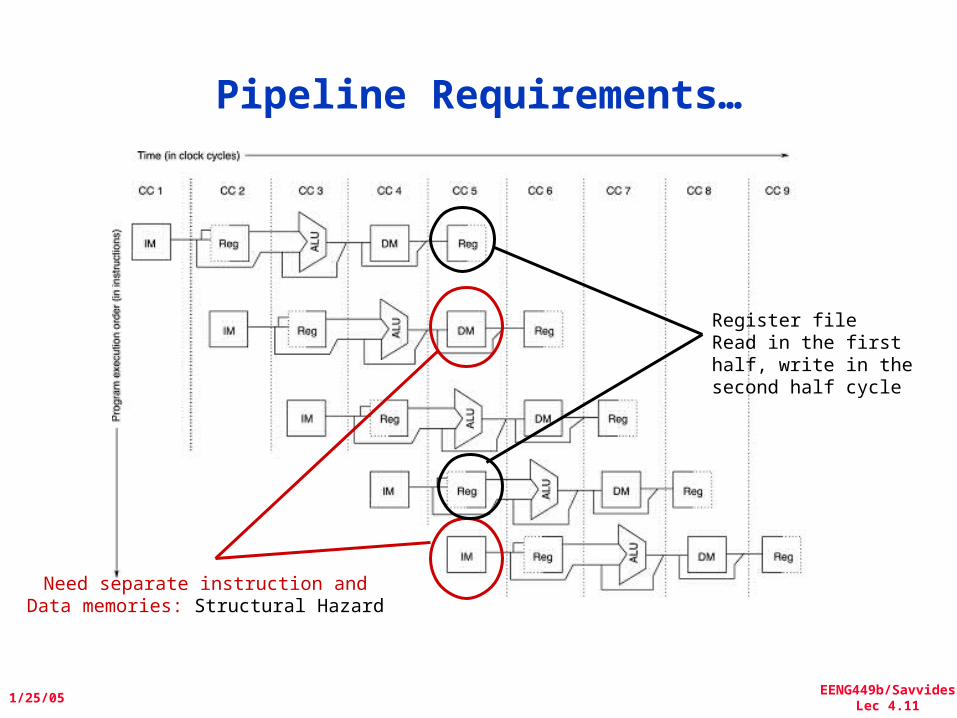
EENG449b/SavvidesLec 4.11
1/25/05
Pipeline Requirements…
Need separate instruction andData memories: Structural Hazard
Register fileRead in the first half, write in the second half cycle

EENG449b/SavvidesLec 4.12
1/25/05
Add registers between pipeline stages
• Prevent interference between 2 instructions• Carry data from one stage to the next• Edge triggered

EENG449b/SavvidesLec 4.13
1/25/05
Pipelining Hazards
Hazards: circumstances that would cause incorrect execution if next instruction where launched
Structural Hazards:Attempting to use the same hardware to do two different things at the same time
Data Hazards:Instruction depends on result of prior instruction still in the pipeline
Control Hazards:Caused by delay between the fetching of instructions and decisions about changes in control flow (branches and jumps)
Common Solution: “Stall” the pipeline, until the hazard is resolved by inserting one or more “bubbles” in the pipeline

EENG449b/SavvidesLec 4.14
1/25/05
Data Hazards
Occurs when the relative timing of instructions is altered because of pipelining
Consider the following code:DADD R1, R2, R3
DSUB R4, R1, R5AND R6, R1, R7OR R8, R1, R9XOR R10, R1, R11
What is the problem here?

EENG449b/SavvidesLec 4.15
1/25/05
Data Hazard

EENG449b/SavvidesLec 4.16
1/25/05
Data Hazards: Data Forwarding

EENG449b/SavvidesLec 4.17
1/25/05
Data Hazards Requiring StallsLD R1,0(R2)DSUB R4,R1,R5AND R6,R1,R7OR R8,R1,R9
HAVE to stall for 1 cycle…

EENG449b/SavvidesLec 4.18
1/25/05
Implementing Stalls for Data Hazard
• Pipeline Interlock– Hardware: detects a hazard and stall the
pipeline until the hazard is detected
• Interlock function– Stall the pipeline at the instruction that wants
to use the result of a hazard– Stall time: from beginning of instruction until
the end of the stall

EENG449b/SavvidesLec 4.19
1/25/05
Stall Introduces Bubbles in the Pipeline

EENG449b/SavvidesLec 4.20
1/25/05
Branch Hazards
• A branch hazard is a control hazard• Branch execution
– PC=PC+4 (branch not taken) or Something else (branch taken)
• Simple solution – Redo an instruction fetch– BUT even a 1 cycle stall may cause 10 – 30%
program execution overhead
• Some branch prediction can easily help with performance

EENG449b/SavvidesLec 4.21
1/25/05
Four Branch Hazard Alternatives
#1: Stall until branch direction is clear#2: Predict Branch Not Taken
– Execute successor instructions in sequence– “Squash” instructions in pipeline if branch actually taken– Advantage of late pipeline state update– 47% MIPS branches not taken on average– PC+4 already calculated, so use it to get next instruction
#3: Predict Branch Taken– 53% MIPS branches taken on average– But haven’t calculated branch target address in MIPS
» MIPS still incurs 1 cycle branch penalty» Other machines: branch target known before outcome

EENG449b/SavvidesLec 4.22
1/25/05
Four Branch Hazard Alternatives
#4: Delayed Branch– Define branch to take place AFTER a following
instruction
branch instructionsequential successor1
sequential successor2
........sequential successorn
........
branch target if taken
– 1 slot delay allows proper decision and branch target address in 5 stage pipeline
– MIPS uses this
Branch delay of length n

EENG449b/SavvidesLec 4.23
1/25/05
Delayed Branch• Where to get instructions to fill branch delay slot?
– Before branch instruction– From the target address: only valuable when branch taken– From fall through: only valuable when branch not taken– Canceling branches allow more slots to be filled
• Compiler effectiveness for single branch delay slot:– Fills about 60% of branch delay slots– About 80% of instructions executed in branch delay slots
useful in computation– About 50% (60% x 80%) of slots usefully filled
• Delayed Branch downside: 7-8 stage pipelines, multiple instructions issued per clock (superscalar)
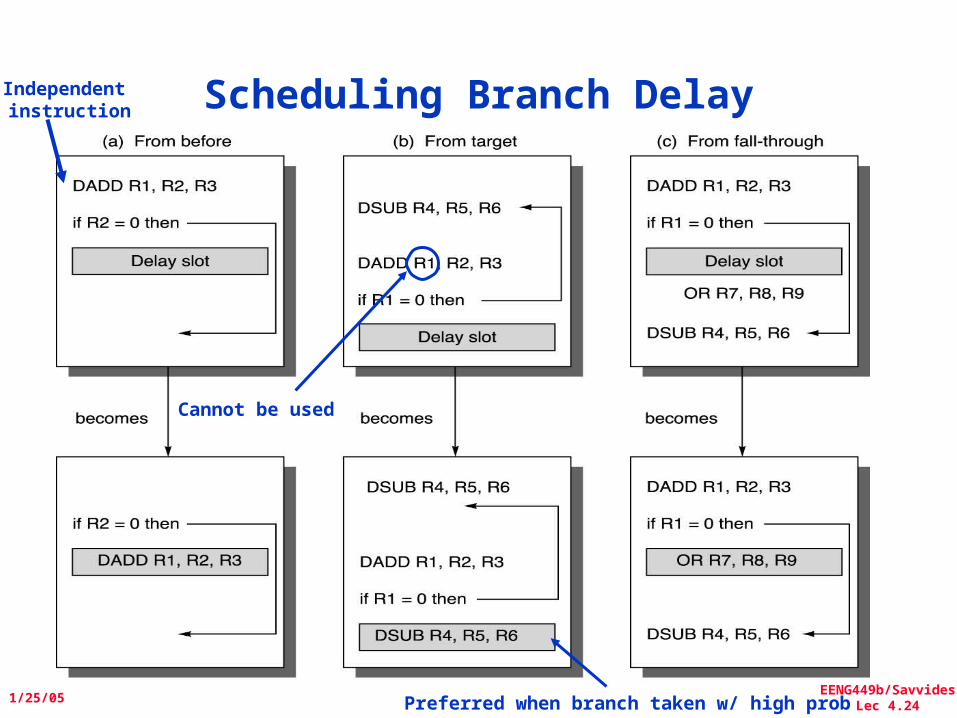
EENG449b/SavvidesLec 4.24
1/25/05
Scheduling Branch DelayIndependent instruction
Cannot be used
Preferred when branch taken w/ high prob

EENG449b/SavvidesLec 4.25
1/25/05
Pipelining Performance Issues
Consider an unpipelined processor
1ns/instruction cycle Frequency
4 cycles for ALU operations 40%
4 cycles for branches 20%
5 cycles for memory operations 40%
Pipelining overhead 0.2ns
For the unpipelined processor
ns 4.4 5 40% 4 x20%) ((40% ns 1
CPI average cycleClock time execution ninstructio Average

EENG449b/SavvidesLec 4.26
1/25/05
Speedup from Pipelining
Now if we had a pipelined processor, we assume that each instruction takes 1 cycle BUT we also have overhead so instructions take 1ns + 0.2 ns = 1.2ns
pipelined time ninstructio Averagedunpipeline time ninstructio Average
pipelining from Speedup
times3.7 ns 1.2ns 4.4

EENG449b/SavvidesLec 4.27
1/25/05
Considering the stall overhead
pipelined time ninstructio Averagedunpipeline time ninstructio Average
pipelining from Speedup
pipelined cycleClock pipelined CPIunpiplined cycleClock dunpipeline CPI
Instper cycles Stall Average CPI Ideal pipelined CPI
ninstructioper cycles stall Pipeline 1dunpipeline CPI
Speedup
pipelined TimeCycledunpipeline TimeCycle
CPI stall Pipeline 1
depth Pipeline Speedup

EENG449b/SavvidesLec 4.28
1/25/05
Performance of Branch Schemes
branches from cycles stall Pipelinedepth Pipeline
speedup Pipeline
1
penalty Branch frequency Branch branches from cycles stall Pipeline
penalty Branchfrequency Branch1depth Pipeline
speedup Pipeline
Assuming an ideal CPI of 1:
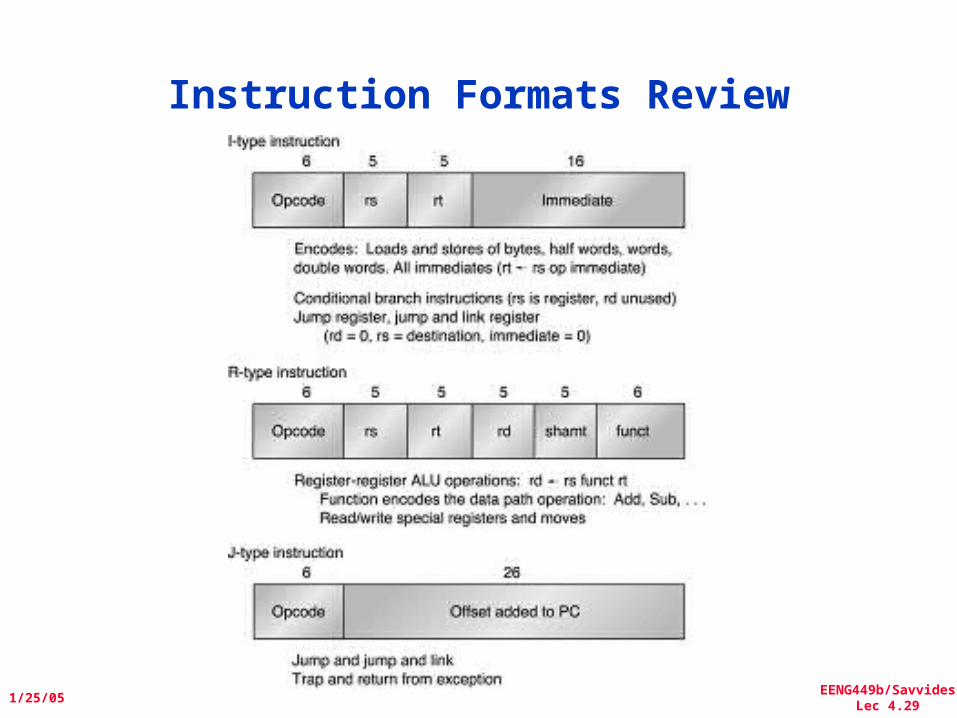
EENG449b/SavvidesLec 4.29
1/25/05
Instruction Formats Review

EENG449b/SavvidesLec 4.30
1/25/05
Implementing a MIPS Pipeline
We are developing a subset of the MIPS pipeline supporting
– Load store word– Branch equal zero– Integer ALU Operations
• Remember MIPS has register-register ALU instructions (e.g Add R1, R2, R3)
• Attention: In the homework you will have to redesign the pipeline for register-memory instructions for ALU operations (e.g Add R1,R2,(R3)!!!
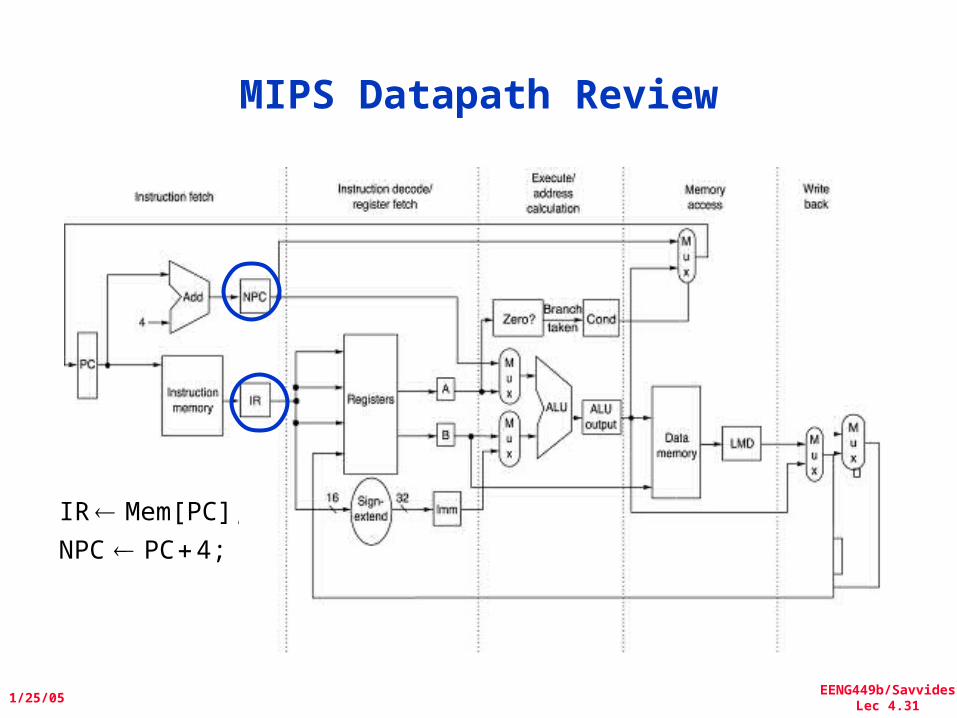
EENG449b/SavvidesLec 4.31
1/25/05
MIPS Datapath Review
4;PCNPC
Mem[PC];IR
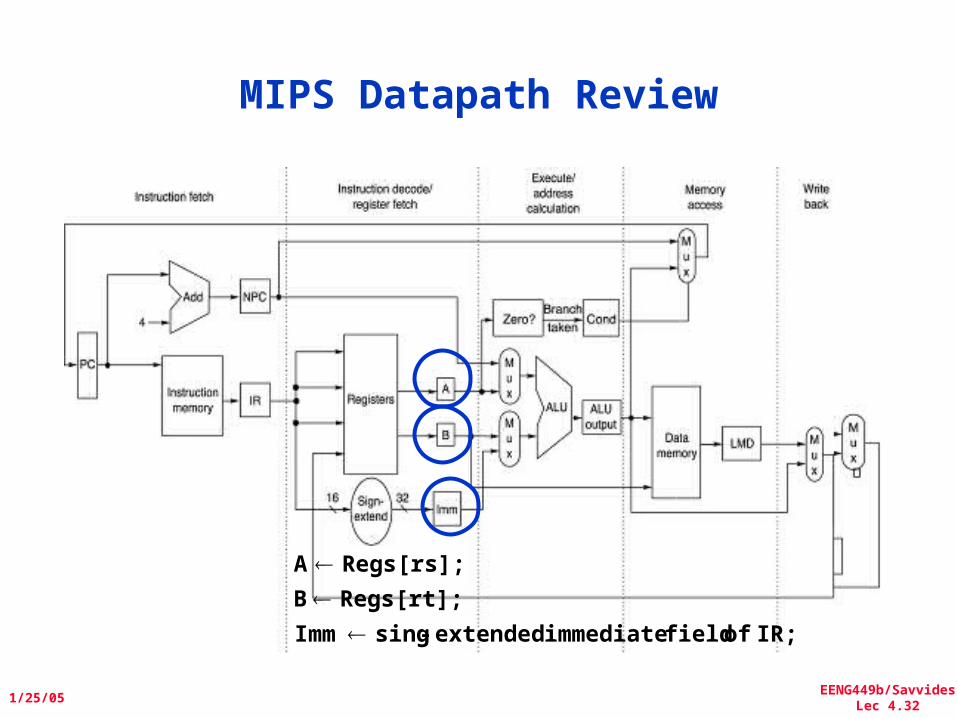
EENG449b/SavvidesLec 4.32
1/25/05
MIPS Datapath Review
IR; of field immediate extended-singImm
Regs[rt];B
Regs[rs];A

EENG449b/SavvidesLec 4.33
1/25/05
MIPS Datapath Review
0)(ACond
2) (Imm NPC ALUOutput :Branch
or Imm; op AALUOutput :Imm-Reg
or B; func A ALUOutput :ALU Reg-Reg
or Imm; AALUOutput :Ref Memory

EENG449b/SavvidesLec 4.34
1/25/05
MIPS Datapath Review
ALUOutputPC if(cond) :Branch
B;put]Mem[ALUOut
or put];Mem[ALUOutLMD :ref Mem

EENG449b/SavvidesLec 4.35
1/25/05
MIPS Basic Pipeline
Data needs to be written in the registers at the end of each cycle
Depend on instruction type
Load or ALUoperation
LMD
ALUOut

EENG449b/SavvidesLec 4.36
1/25/05
Events at every pipe stage

EENG449b/SavvidesLec 4.37
1/25/05
Events at every pipe stage

EENG449b/SavvidesLec 4.38
1/25/05
Controlling the Pipeline

EENG449b/SavvidesLec 4.39
1/25/05
Hazards Review
From previous lecture we know the situations that would cause incorrect execution
• Structural Hazards -• Data Hazards -• Control Hazards -

EENG449b/SavvidesLec 4.40
1/25/05
• Read After Write (RAW) InstrJ tries to read operand before InstrI writes it
• Caused by a “Data Dependence” (in compiler nomenclature). This hazard results from an actual need for communication.
Three Generic Data Hazards
I: add r1,r2,r3J: sub r4,r1,r3

EENG449b/SavvidesLec 4.41
1/25/05
• Write After Read (WAR) InstrJ writes operand before InstrI reads it
• Called an “anti-dependence” by compiler writers.This results from reuse of the name “r1”.
• Can’t happen in MIPS 5 stage pipeline because:– All instructions take 5 stages, and– Reads are always in stage 2, and – Writes are always in stage 5
I: sub r4,r1,r3 J: add r1,r2,r3K: mul r6,r1,r7
Three Generic Data Hazards

EENG449b/SavvidesLec 4.42
1/25/05
Three Generic Data Hazards
• Write After Write (WAW) InstrJ writes operand before InstrI writes it.
• Called an “output dependence” by compiler writersThis also results from the reuse of name “r1”.
• Can’t happen in MIPS 5 stage pipeline because: – All instructions take 5 stages, and – Writes are always in stage 5
• Will see WAR and WAW in later more complicated pipes
I: sub r1,r4,r3 J: add r1,r2,r3K: mul r6,r1,r7

EENG449b/SavvidesLec 4.43
1/25/05
MIPS Basic Pipeline
Instruction issued
IF ID EX IF WB
Data Hazards can be detected here
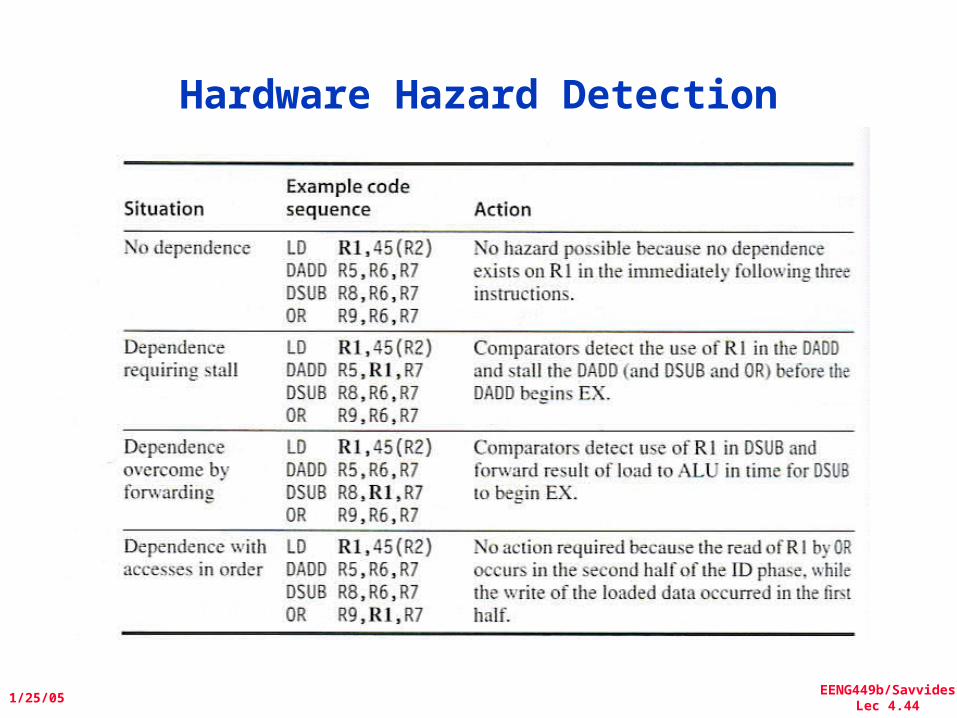
EENG449b/SavvidesLec 4.44
1/25/05
Hardware Hazard Detection

EENG449b/SavvidesLec 4.45
1/25/05
Logic to Detect Load Interlocks

EENG449b/SavvidesLec 4.46
1/25/05
Forwarding of Results to the ALU
Mem output
ALU output

EENG449b/SavvidesLec 4.47
1/25/05
Control Hazards Revisited
A branch causes a 3-cycle stall in the 5-stage pipeline
Branch Instruction IF ID EX MEM WB
Branch Successor+1 IF stall stall IF ID EX MEM WB
Branch Successor+2 IF ID EX MEM WB
Branch Successor+3 IF ID EX MEM WB
Higher overhead than data hazards…
Can HW changes improve that? YES!• Try to make an early decision whether a branch is taken or not.
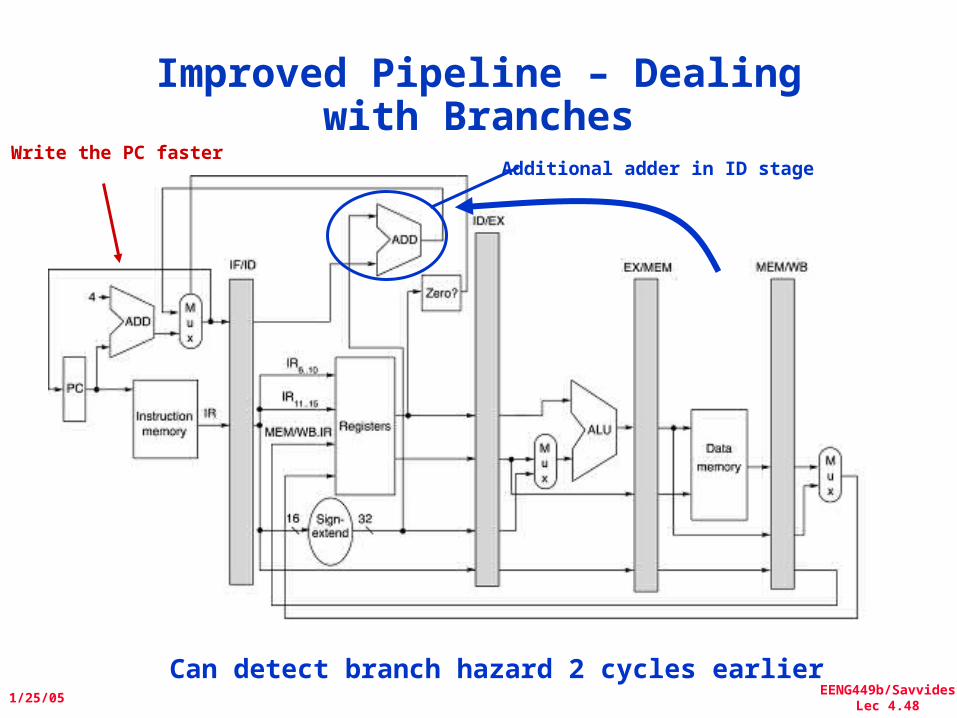
EENG449b/SavvidesLec 4.48
1/25/05
Improved Pipeline – Dealing with Branches
Additional adder in ID stageWrite the PC faster
Can detect branch hazard 2 cycles earlier

EENG449b/SavvidesLec 4.49
1/25/05
Improved Pipeline – Dealing with Branches
Additional adder in ID stageWrite the PC faster
Note change of order in text!Figure A.11 says a branch hazard would stall for 1 cycle. This is after the optimization in
Figure A.24!!!Note the change of order…

EENG449b/SavvidesLec 4.50
1/25/05
Challenges in Pipeline Implementation
Exceptions: Situations that can disrupt the in-order execution of instructions (interrupt, fault, exception)
• I/O device request• Invoking an OS service from a user
program• Breakpoint• Integer arithmetic overflow or FP
arithmetic anomaly• Page fault (not in main memory)• Misaligned memory access • Hardware failure• Power loss etc…

EENG449b/SavvidesLec 4.51
1/25/05
Exceptions Requirements
• Synchronous vs. Asynchronous– Synchronous: Always at the same memory and
time– What is asynchronous?
• User requested vs. coerced– User requested – not really exceptions– Coerced: not under the control of user program
• User maskable vs. user non-maskable• With vs. between instructions• Resume vs. terminate

EENG449b/SavvidesLec 4.52
1/25/05
Exception Types & Classification

EENG449b/SavvidesLec 4.53
1/25/05
Exception Challenges
• Exceptions happening within instructions
• Exceptions that need to be restarted – as in the case of a page fault
• Need to make sure that the occurrence of an exception does not influence the correct execution of a program
• Pipeline design should ensure that the processor is in a predictable state after the occurrence of an exception
– Block writing to pipeline registers

EENG449b/SavvidesLec 4.54
1/25/05
Exceptions in MIPS Pipeline
Pipeline State Problem Exceptions
IF Page fault on instruction fetch misaligned memory access memory protection violation
ID Undefined or illegal opcode
EX Arithmetic exception
MEM Page fault on data fetch; misaligned
memory access; memory protection violation
WB None

EENG449b/SavvidesLec 4.55
1/25/05
Floating-Point Support in Pipelines
• Floating point operations will take more than 1 or 2 cycles to complete
– Structural hazards– Data hazards
• Multiple functional units required– Loads, stores and integer ALUs– FP and integer multiplier– FP adder that handles FP add, subtract and
conversion– FP and integer divider
• Initiation interval – number of cycles that must elapse before issuing two operations of a given type

EENG449b/SavvidesLec 4.56
1/25/05
Multiple FUs and Latencies
Functional Unit Latency
Initiation Interval
Integer ALU 0 1
Data memory
(integer and FP Loads)
1 1
FP add 3 1
FP Multiply 6 1
FP Divide 24 25

EENG449b/SavvidesLec 4.57
1/25/05
Support for Multiple Outstanding Operations
Additional pipeline registers needed

EENG449b/SavvidesLec 4.58
1/25/05
Hazards in Longer Pipelines
1. Divide unit is not fully pipelined - structural hazards can occur
2. Instructions have varying running times so the number of register writes required in a cycle can be larger than 1.
3. WAW hazards are possible, since instructions don’t reach WB in order
4. Instructions can complete in different order than the one they were issued causing problems with exceptions
5. Because of longer latency of operations, stalls for RAW hazards will be more frequent

EENG449b/SavvidesLec 4.59
1/25/05
FP Pipeline Hazards Example
Figure A.34
Simultaneous writeback
• Stall an instruction in the ID stage• Stall the instruction when it tries to enter WB

EENG449b/SavvidesLec 4.60
1/25/05
Checks for Detecting Hazards
Three checks to be performed before a multicycle instruction can issue in the ID stage:
• Check for structural hazards– A structural unit is not busy and a write register
port is available when needed
• Check for a RAW data hazard– Wait until the source registers are not listed as
pending destinations
• Check for WAW data hazard– Determine an instruction that already issued
has the same destination as this instruction. If so stall the instruction issue in ID.

EENG449b/SavvidesLec 4.61
1/25/05
MIPS R4000 Pipeline
• Decompose the 5-stage pipeline to a deeper 8-stage pipeline(superpipeline)
– achieve higher clock rates => better performance
• Extra stages come from decomposing memory accesses
• Longer pipelines increase the amount of forwarding and branch delays

EENG449b/SavvidesLec 4.62
1/25/05
Branch Delay Cycles
Branch outcome needs 3 cycles

EENG449b/SavvidesLec 4.63
1/25/05
Dynamic Scheduled Pipelines
• Simple pipelines result in hazards that require stalling.
• Static scheduling – compilers rearrange instructions to avoid stalls.
• Dynamic scheduling – processor executes instructions out-of-order to minimize stalls
• Dynamic scheduling requires splitting the ID stage into stages:
– Issue – Decode instructions, check for structural hazards
– Read operands – Wait until there are no data hazards, then read operands
– Also need to know when each instruction begins and ends execution
• Requires a lot more bookkeeping! More when we discuss Tomasulo’s algorithm in chapter 3…

EENG449b/SavvidesLec 4.64
1/25/05
Scoreboarding
Scoreboarding – a technique that allows out-of-order execution when resources are available and there are no data dependencies – originated in CDC6600 in the mid 60s.
• Scoreboard fully responsible for instruction execution and hazard detection
– Requires changes in # of functional units and latency of operations
– Needs to keep track of status of all instructions in execution

EENG449b/SavvidesLec 4.65
1/25/05
Scoreboarding II
EENG449b/SavvidesLec 4.66
1/25/05
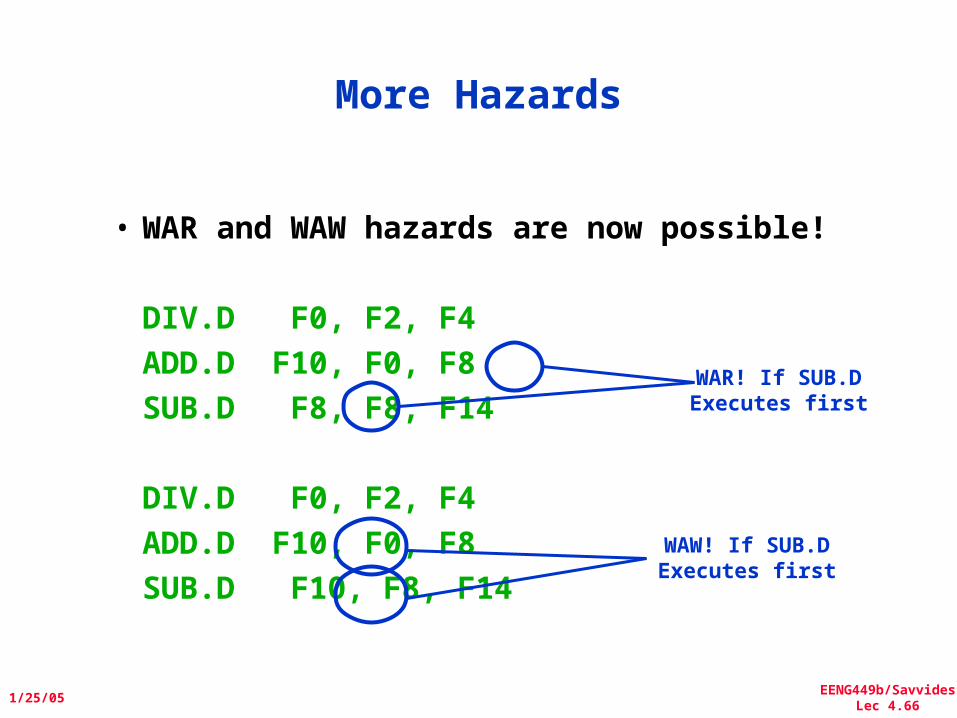
More Hazards
• WAR and WAW hazards are now possible!
DIV.D F0, F2, F4ADD.D F10, F0, F8SUB.D F8, F8, F14
DIV.D F0, F2, F4ADD.D F10, F0, F8SUB.D F10, F8, F14
WAR! If SUB.DExecutes first
WAW! If SUB.DExecutes first

EENG449b/SavvidesLec 4.67
1/25/05
Refer to figures A.52 – A.54 for example scoreboard tables
Scoreboarding is limited by:• Amount of parallelism among
instructions• The number of scoreboard entries• The number and types of functional
units• Presence of antidependencies and
output dependencies