dynamic warp formation and scheduling for efficient gpu control flow
DESCRIPTION
Dynamic Warp Formation and Scheduling for Efficient GPU Control Flow. Wilson W. L. Fung Ivan Sham George Yuan Tor M. Aamodt Electrical and Computer Engineering University of British Columbia Micro-40 Dec 5, 2007. Motivation =. GPU: A massively parallel architecture - PowerPoint PPT PresentationTRANSCRIPT

Dynamic Warp Formation and Scheduling for Efficient GPU Control FlowWilson W. L. Fung
Ivan ShamGeorge YuanTor M. Aamodt
Electrical and Computer Engineering University of British Columbia
Micro-40 Dec 5, 2007

Wilson Fung, Ivan Sham, George Yuan, Tor Aamodt
Dynamic Warp Formation and Scheduling
for Efficient GPU Control Flow 2
Motivation = GPU: A massively parallel architecture
SIMD pipeline: Most computation out of least silicon/energy
Goal: Apply GPU to non-graphics computing Many challenges This talk: Hardware Mechanism for Efficient Control Flow
1
10
100
1000
2001 2002 2003 2004 2005 2006 2007 2008 Year
GF
LO
PS
GPUCPU-ScalarCPU-SSE

Wilson Fung, Ivan Sham, George Yuan, Tor Aamodt
Dynamic Warp Formation and Scheduling
for Efficient GPU Control Flow 3
Programming Model
Modern graphics pipeline
CUDA-like programming model Hide SIMD pipeline from programmer Single-Program-Multiple-Data (SPMD) Programmer expresses parallelism using threads ~Stream processing
VertexShader
PixelShaderOpenGL/
DirectX

Wilson Fung, Ivan Sham, George Yuan, Tor Aamodt
Dynamic Warp Formation and Scheduling
for Efficient GPU Control Flow 4
Programming Model
Warp = Threads grouped into a SIMD instruction From Oxford Dictionary:
Warp: In the textile industry, the term “warp” refers to “the threads stretched lengthwise in a loom to be crossed by the weft”.
Wilson Fung, Ivan Sham, George Yuan, Tor Aamodt
Dynamic Warp Formation and Scheduling
for Efficient GPU Control Flow 5
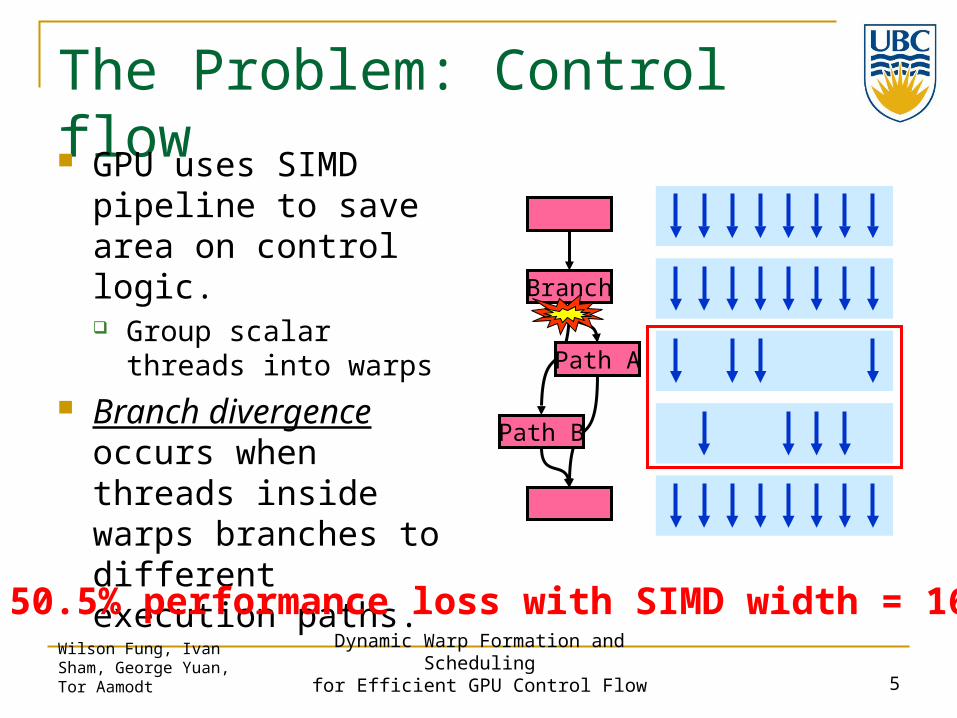
The Problem: Control flow GPU uses SIMD
pipeline to save area on control logic. Group scalar threads into
warps Branch divergence
occurs when threads inside warps branches to different execution paths.
Branch
Path A
Path B
Branch
Path A
Path B
50.5% performance loss with SIMD width = 16

Wilson Fung, Ivan Sham, George Yuan, Tor Aamodt
Dynamic Warp Formation and Scheduling
for Efficient GPU Control Flow 6
Dynamic Warp Formation
Consider multiple warps
Branch
Path A
Path B
Opportunity?Branch
Path A
20.7% Speedup with 4.7% Area Increase

Wilson Fung, Ivan Sham, George Yuan, Tor Aamodt
Dynamic Warp Formation and Scheduling
for Efficient GPU Control Flow 7
Outline
Introduction Baseline Architecture Branch Divergence Dynamic Warp Formation and Scheduling Experimental Result Related Work Conclusion

Wilson Fung, Ivan Sham, George Yuan, Tor Aamodt
Dynamic Warp Formation and Scheduling
for Efficient GPU Control Flow 8
Baseline Architecture
ShaderCore
Interconnection Network
MemoryController
GDDR3
MemoryController
GDDR3
MemoryController
GDDR3
ShaderCore
ShaderCore
CPU spawn
done
GPU
CPU
Tim
e
CPU spawn
GPU

Wilson Fung, Ivan Sham, George Yuan, Tor Aamodt
Dynamic Warp Formation and Scheduling
for Efficient GPU Control Flow 9
SIMD Execution of Scalar Threads All threads run the same kernel Warp = Threads grouped into a SIMD instruction
Thread Warp 3Thread Warp 8
Thread Warp 7Thread Warp
ScalarThread
W
ScalarThread
X
ScalarThread
Y
ScalarThread
Z
Common PC
SIMD Pipeline

Wilson Fung, Ivan Sham, George Yuan, Tor Aamodt
Dynamic Warp Formation and Scheduling
for Efficient GPU Control Flow 10
Latency Hiding via Fine Grain Multithreading Interleave warp
execution to hide latencies
Register values of all threads stays in register file
Need 100~1000 threads Graphics has millions
of pixels
Decode
RF
RFRF
AL U
AL U
AL U
D-Cache
Thread Warp 6
Thread Warp 1Thread Warp 2DataAll Hit?
Miss?
Threads accessingmemory hierarchy
Thread Warp 3Thread Warp 8
Writeback
Threads availablefor scheduling
Thread Warp 7
I-Fetch
SIMD Pipeline
Wilson Fung, Ivan Sham, George Yuan, Tor Aamodt
Dynamic Warp Formation and Scheduling
for Efficient GPU Control Flow 11
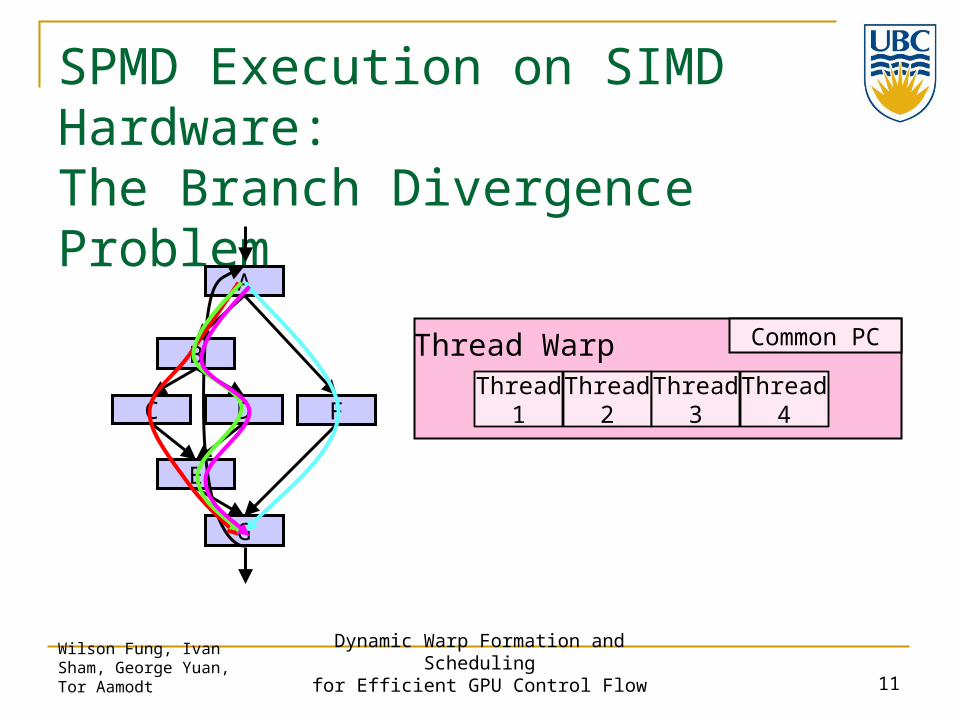
Thread Warp Common PC
SPMD Execution on SIMD Hardware:The Branch Divergence Problem
Thread2
Thread3
Thread4
Thread1
B
C D
E
F
A
G
Wilson Fung, Ivan Sham, George Yuan, Tor Aamodt
Dynamic Warp Formation and Scheduling
for Efficient GPU Control Flow 12
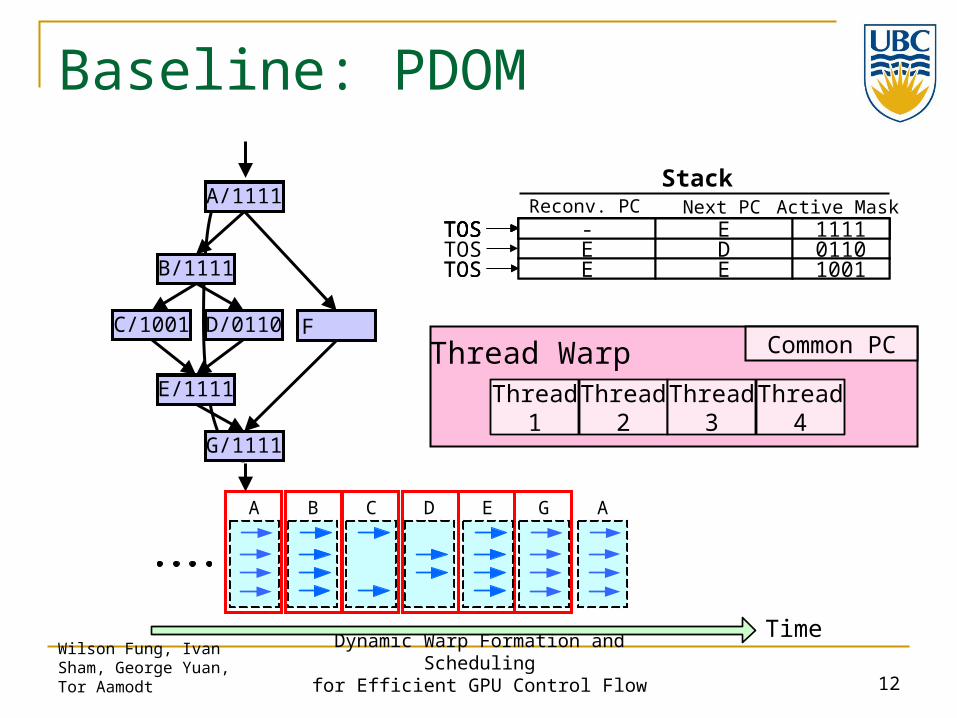
- G 1111TOS
B
C D
E
F
A
G
Baseline: PDOM
Thread Warp Common PC
Thread2
Thread3
Thread4
Thread1
B/1111
C/1001 D/0110
E/1111
A/1111
G/1111
- A 1111TOSE D 0110E C 1001TOS
- E 1111E D 0110TOS- E 1111
A D G A
Time
CB E
- B 1111TOS - E 1111TOSReconv. PC Next PC Active Mask
Stack
E D 0110E E 1001TOS
- E 1111
Wilson Fung, Ivan Sham, George Yuan, Tor Aamodt
Dynamic Warp Formation and Scheduling
for Efficient GPU Control Flow 13
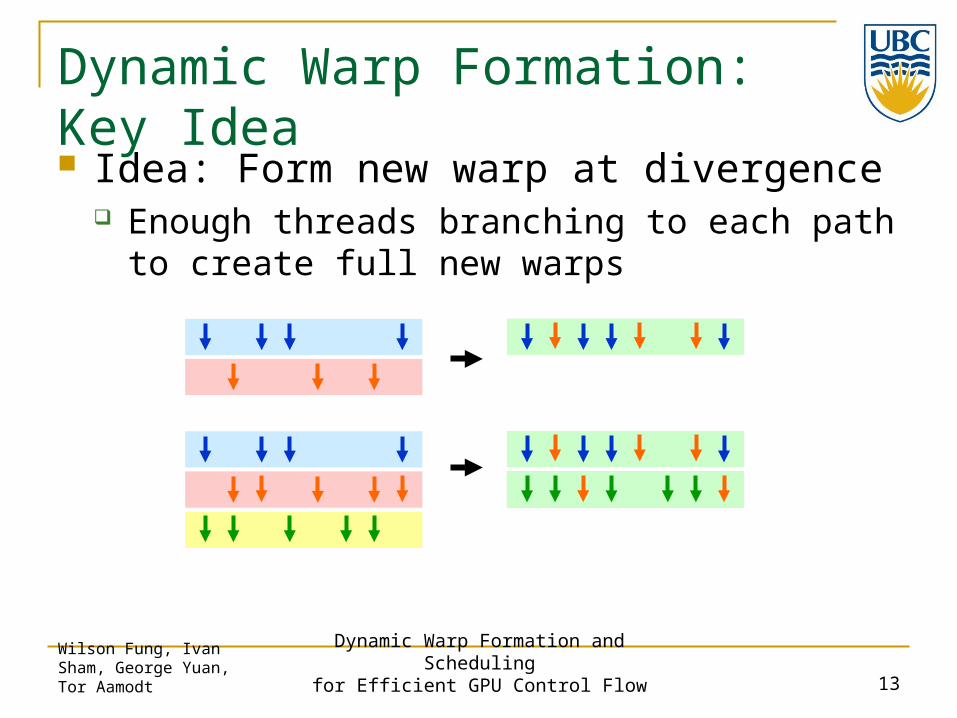
Dynamic Warp Formation: Key Idea Idea: Form new warp at divergence
Enough threads branching to each path to create full new warps

Wilson Fung, Ivan Sham, George Yuan, Tor Aamodt
Dynamic Warp Formation and Scheduling
for Efficient GPU Control Flow 14
Dynamic Warp Formation: Example
A A B B G G A AC C D D E E F F
Time
A A B B G G A AC D E E F
Time
A x/1111y/1111
B x/1110y/0011
C x/1000y/0010 D x/0110
y/0001 F x/0001y/1100
E x/1110y/0011
G x/1111y/1111
A new warp created from scalar threads of both Warp x and y executing at Basic Block D
D
Execution of Warp xat Basic Block A
Execution of Warp yat Basic Block A
LegendAA
Baseline
DynamicWarpFormation

Wilson Fung, Ivan Sham, George Yuan, Tor Aamodt
Dynamic Warp Formation and Scheduling
for Efficient GPU Control Flow 15
I-Cache
Decode
Com
mit/
Writeback
RF 2
RF 1
ALU 2
ALU 1 (TID, Reg#)
(TID, Reg#)
RF 3ALU 3 (TID, Reg#)
RF 4ALU 4 (TID, Reg#)
Thread SchedulerPC-Warp LUT Warp Pool
Issue
Log
ic
Warp Allocator
TID x N PC A
TID x N PC B
H
H
TID x NPC Prio
TID x NPC Prio
OCCPC IDX
OCCPC IDX
Warp Update Register T
Warp Update Register NT
REQ
REQTID x N
PC PrioA 5 6 7 8
A 1 2 3 4
Dynamic Warp Formation: Hardware Implementation5 7 8
6
B
C
1011
0100
B 2 30110B 0 B 5 2 3 8
B
0010B 2
71
3
4
2 B
C
0110
1001
C 11001C 1 4C 61101C 1
No Lane Conflict
A: BEQ R2, BC: …
X
1234
Y
5678
X
1234
X
1234
X
1234
X
1234
Y
5678
Y
5678
Y
5678
Y
5678
Z
5238
Z
5238
Z
5238

Wilson Fung, Ivan Sham, George Yuan, Tor Aamodt
Dynamic Warp Formation and Scheduling
for Efficient GPU Control Flow 16
Methodology Created new cycle-accurate simulator from
SimpleScalar (version 3.0d) Selected benchmarks from SPEC CPU2006,
SPLASH2, CUDA Demo Manually parallelized Similar programming model to CUDA
Wilson Fung, Ivan Sham, George Yuan, Tor Aamodt
Dynamic Warp Formation and Scheduling
for Efficient GPU Control Flow 17
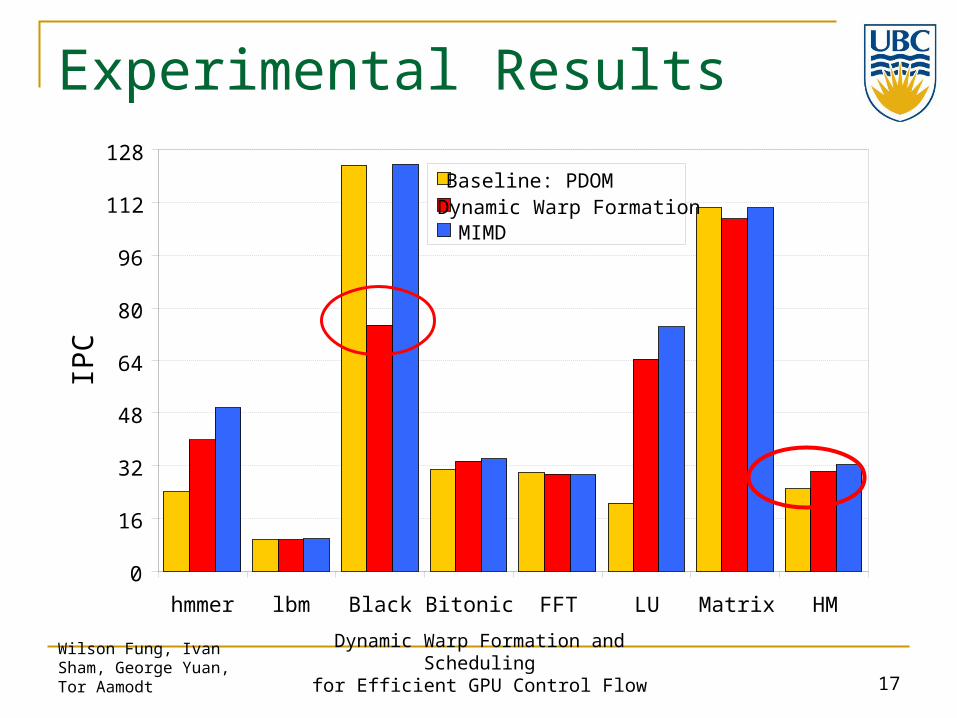
Experimental Results
0
16
32
48
64
80
96
112
128
hmmer lbm Black Bitonic FFT LU Matrix HM
IPC
Baseline: PDOMDynamic Warp FormationMIMD

Wilson Fung, Ivan Sham, George Yuan, Tor Aamodt
Dynamic Warp Formation and Scheduling
for Efficient GPU Control Flow 18
0
16
32
48
64
80
96
112
128
hmmer lbm Black Bitonic FFT LU Matrix HM
IPC
BaselineDMajDMinDTimeDPdPriDPC
Dynamic Warp Scheduling
Lane Conflict Ignored (~5% difference)

Wilson Fung, Ivan Sham, George Yuan, Tor Aamodt
Dynamic Warp Formation and Scheduling
for Efficient GPU Control Flow 19
Area Estimation CACTI 4.2 (90nm process) Size of scheduler = 2.471mm2 8 x 2.471mm2 + 2.628mm2 = 22.39mm2
4.7% of Geforce 8800GTX (~480mm2)

Wilson Fung, Ivan Sham, George Yuan, Tor Aamodt
Dynamic Warp Formation and Scheduling
for Efficient GPU Control Flow 20
Related Works Predication
Convert control dependency into data dependency Lorie and Strong
JOIN and ELSE instruction at the beginning of divergence Cervini
Abstract/software proposal for “regrouping” SMT processor
Liquid SIMD (Clark et al.) Form SIMD instructions from scalar instructions
Conditional Routing (Kapasi) Code transform into multiple kernels to eliminate branches

Wilson Fung, Ivan Sham, George Yuan, Tor Aamodt
Dynamic Warp Formation and Scheduling
for Efficient GPU Control Flow 21
Conclusion
Branch divergence can significantly degrade a GPU’s performance. 50.5% performance loss with SIMD width = 16
Dynamic Warp Formation & Scheduling 20.7% on average better than reconvergence 4.7% area cost
Future Work Warp scheduling – Area and Performance
Tradeoff

Wilson Fung, Ivan Sham, George Yuan, Tor Aamodt
Dynamic Warp Formation and Scheduling
for Efficient GPU Control Flow 22
Thank You.
Questions?

Wilson Fung, Ivan Sham, George Yuan, Tor Aamodt
Dynamic Warp Formation and Scheduling
for Efficient GPU Control Flow 23
Shared Memory
Banked local memory accessible by all threads within a shader core (a block)
Idea: Break Ld/St into 2 micro-code: Address Calculation Memory Access
After address calculation, use bit vector to track bank access just like lane conflict in the scheduler