dr. john donners [email protected] consultant high ... · consultant high performance computing...
TRANSCRIPT

PRACE Winter School, Athens | 10-2-2009SARA Computing and Networking Services
Dr. John [email protected]
High Performance Computing & VisualizationSARA Computing & Networking Services
Introduction to the Power6 system

PRACE Winter School, Athens | 10-2-2009SARA Computing and Networking Services
About SARA
> SARA is an independent not-for-profit company delivering a full service package in the areas of high-performance computing & networking, visualization and virtual reality, data storage, grid services and hosting
> SARA employs ~110 fte
> First supercomputer in The Netherlands at SARA in 1984 (Control Data CYBER 205)
> First CAVE in Europe in 1997

PRACE Winter School, Athens | 10-2-2009SARA Computing and Networking Services
The mission of SARA is two-fold:
> Providing high-performance computing,-networking and -visualization not-for-profit services to geographically dispersed education and research communities across the Netherlands sharing data, information and computation resources.
> Offering commercial ICT services based on the expertise built in the high-end activities
SARA mission
PRACE Winter School, Athens | 10-2-2009SARA Computing and Networking Services
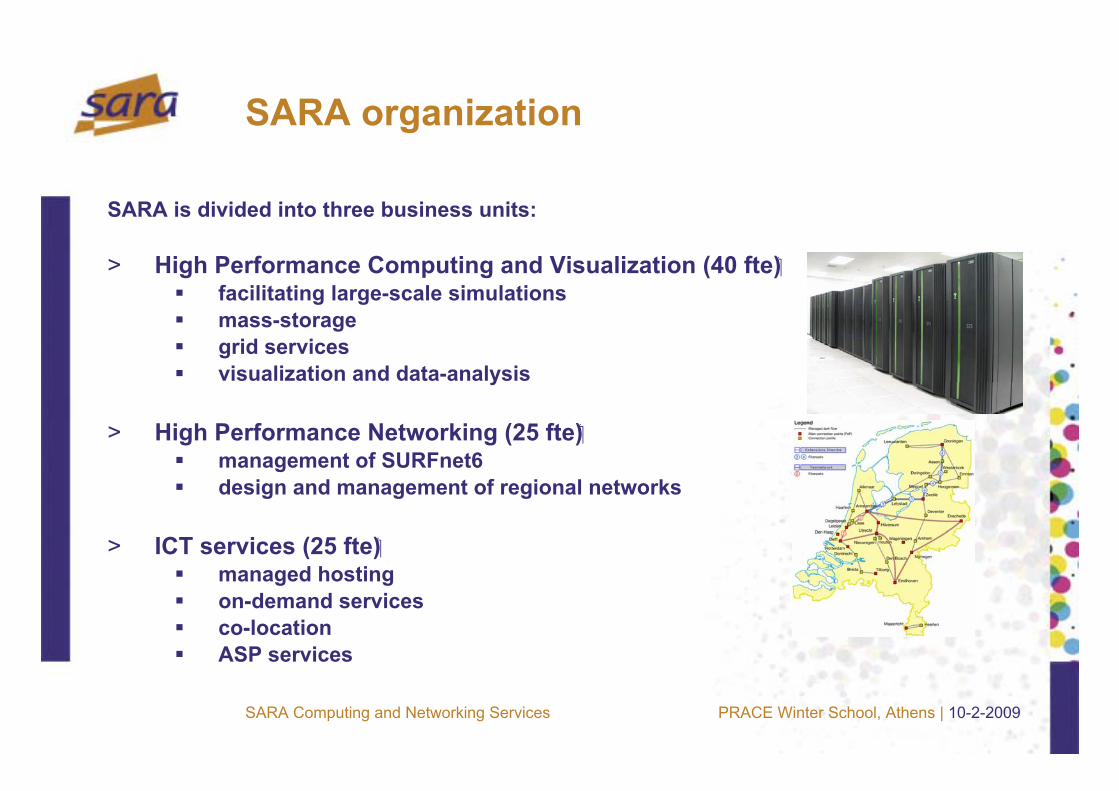
SARA organization
SARA is divided into three business units:
> High Performance Computing and Visualization (40 fte)facilitating large-scale simulationsmass-storagegrid servicesvisualization and data-analysis
> High Performance Networking (25 fte)management of SURFnet6design and management of regional networks
> ICT services (25 fte)managed hostingon-demand servicesco-locationASP services

PRACE Winter School, Athens | 10-2-2009SARA Computing and Networking Services
Supernode@SARA
CAVETape storage
StorageSGI Altix 3700
Tiled-panel displays
IBM Power6
National Compute cluster
Netherlight SURFnet6
HUYGENS

Opening Huygens - 11 september 2008 - SARA Reken- en Netwerkdiensten
Christiaan Huygens(math, physics, astronomy and inventor)
> Centripetal force and collision laws
> Wave theory
> Titan, Saturn and its rings
> Pendulum clock and theory
> Acoustics
> Internal combustion engine
> Science fiction
> Optics
1629-1695

PRACE Winter School, Athens | 10-2-2009SARA Computing and Networking Services
Opening of the Huygens supercomputer
PRACE Winter School, Athens | 10-2-2009SARA Computing and Networking Services
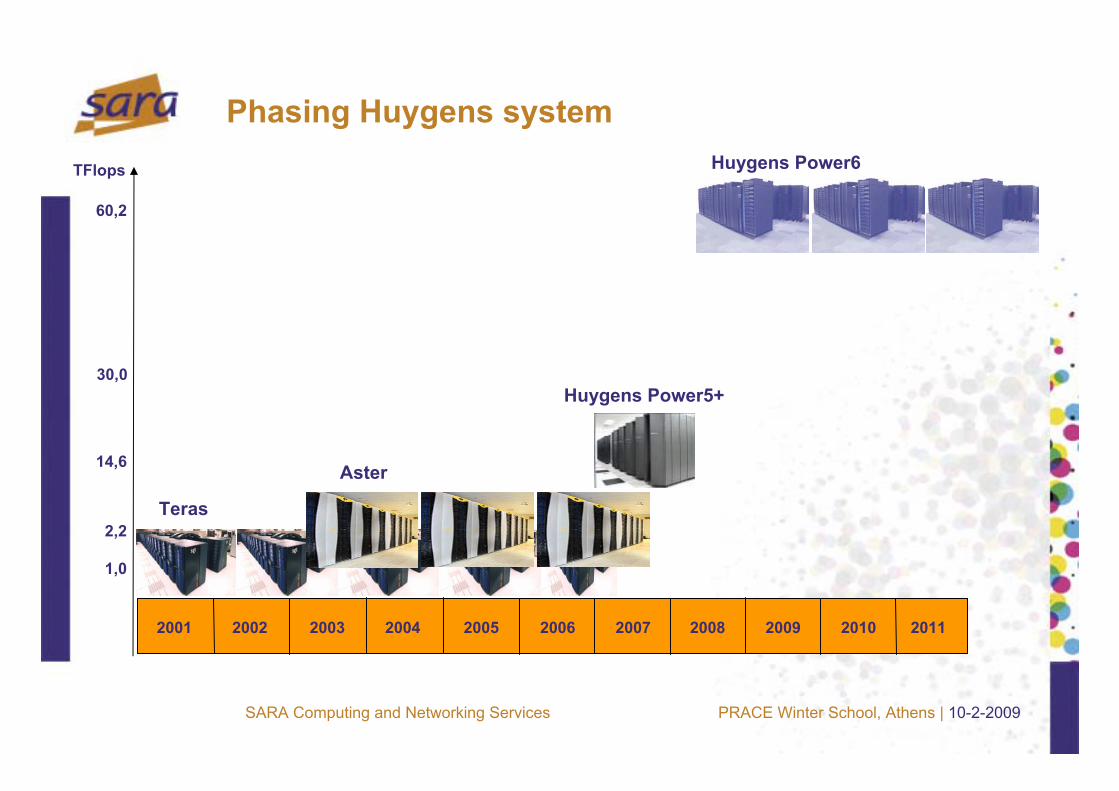
Phasing Huygens system
2001 2002 2003 2004 2005 2006 2007 2008 2009 2010 2011
1,0
14,6
2,2
60,2
TFlops
Teras
Aster
Huygens Power5+
Huygens Power6
30,0

PRACE Winter School, Athens | 10-2-2009SARA Computing and Networking Services
Huygens: IBM Power6 system
> Power6 processor: dual-core 4.7GHz (18.8 GFlops per core) > Total 104 nodes
SCN’s (standard compute nodes) en MCN’s (memory compute nodes) with each:
• 16 dual-core processors• 128-256 GB shared memory (4-8GB/core)• 2 quad-port Infiniband adapters
2 Front-end nodes, 2 Test nodes> Total nr cores: >3000> Total memory: 15,6 TB> Interconnect: 8 IB switches, non-blocking (160Gbit/s)> SAN disk storage: 972 TB raw, 711 TB usable> Energy usage: 715 kW> Operating system: SUSE Linux Enterprise Server 10

PRACE Winter School, Athens | 10-2-2009SARA Computing and Networking Services
Huygens is located above sea level

PRACE Winter School, Athens | 10-2-2009SARA Computing and Networking Services
Water cooling

PRACE Winter School, Athens | 10-2-2009SARA Computing and Networking Services
One open node with 16 dual-core cpus

PRACE Winter School, Athens | 10-2-2009SARA Computing and Networking Services
One rack has 12 nodes

PRACE Winter School, Athens | 10-2-2009SARA Computing and Networking Services
InfiniBand switches

PRACE Winter School, Athens | 10-2-2009SARA Computing and Networking Services
Storage area network

PRACE Winter School, Athens | 10-2-2009SARA Computing and Networking Services
Overview
PRACE Winter School, Athens | 10-2-2009SARA Computing and Networking Services
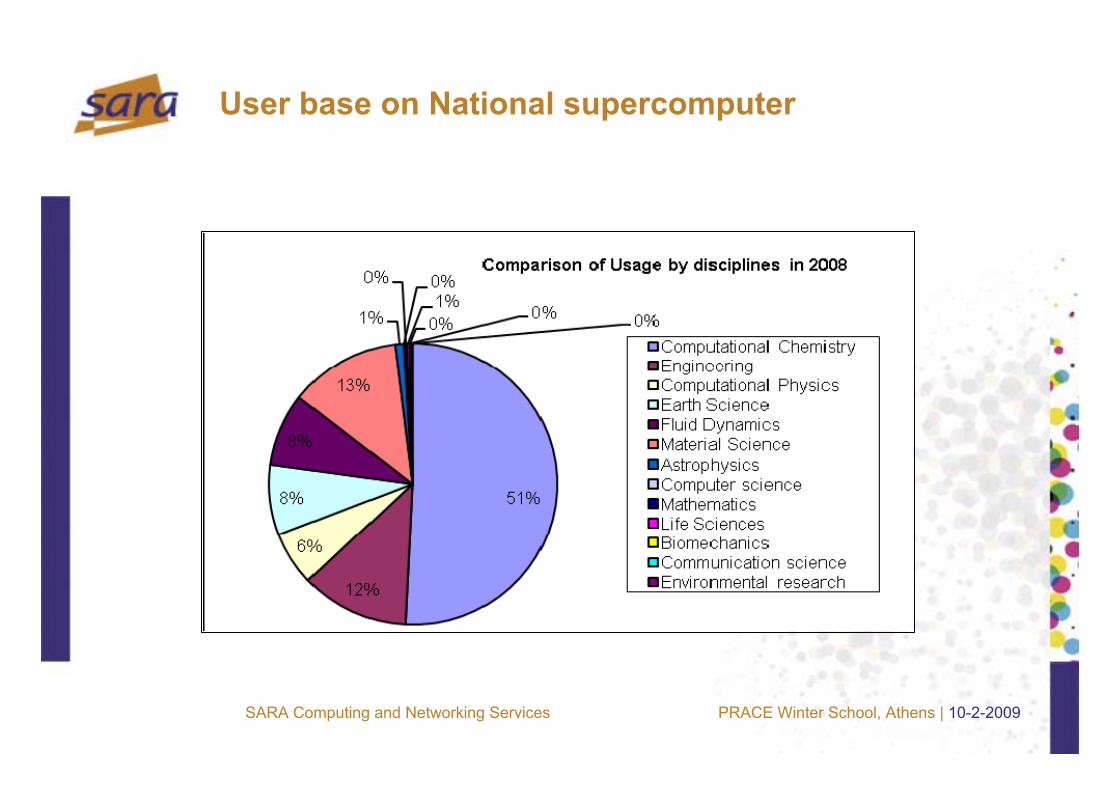
User base on National supercomputer

© 2006 IBM Corporation
Introduction to IBM POWER6
Luigi BrochardDistinguished EngineerIBM Deep Computing

©
2006
IBM
Corporation
2004-6
130 nm
2007-9
POWER5 / 5+
90 nm
2010-13POWER6 / 6+POWER4 / 4+
180 nm
Distributed Switch
Shared L2
1+ GHzCore
1+ GHzCore
2001-4
130 nm
POWER Processor Roadmap
1.65+GHz
Core
Distributed Switch
Shared L2
1.5+GHz
Core Shared L2
1.9GHzCore
Distributed Switch
1.9GHzCore
Cache
Advanced MultiCore Design
AdvancedSystem Features
POWER7/7+
1.5+ GHzCore
Distributed Switch
Shared L2
1.5+ GHzCore
Enhanced ScalingSimultaneous Multi-Threading (SMT)Enhanced Distributed SwitchEnhanced Core ParallelismImproved FP PerformanceIncreased memory bandwidthReduced memory latenciesVirtualization
Enhanced VirtualizationAdvanced Memory SubsystemDecimal Floating PointCheck Point RestartEnhanced architecture for higher
frequencies
Chip Multi Processing- Distributed Switch- Shared L2Dynamic LPARs (32)
Design phaseRequirements definitions
BINARY COMPATIBILITY
CacheAdvanced
System Features
AltiVec
≥3.5GHzCores
≥3.5GHzCores
CacheAltiVec
CacheAdvanced
System Features
AltiVec
≥3.5GHzCore
≥3.5GHzCore
CacheAltiVec
65 nm 45/32 nm
©
2006
IBM
Corporation
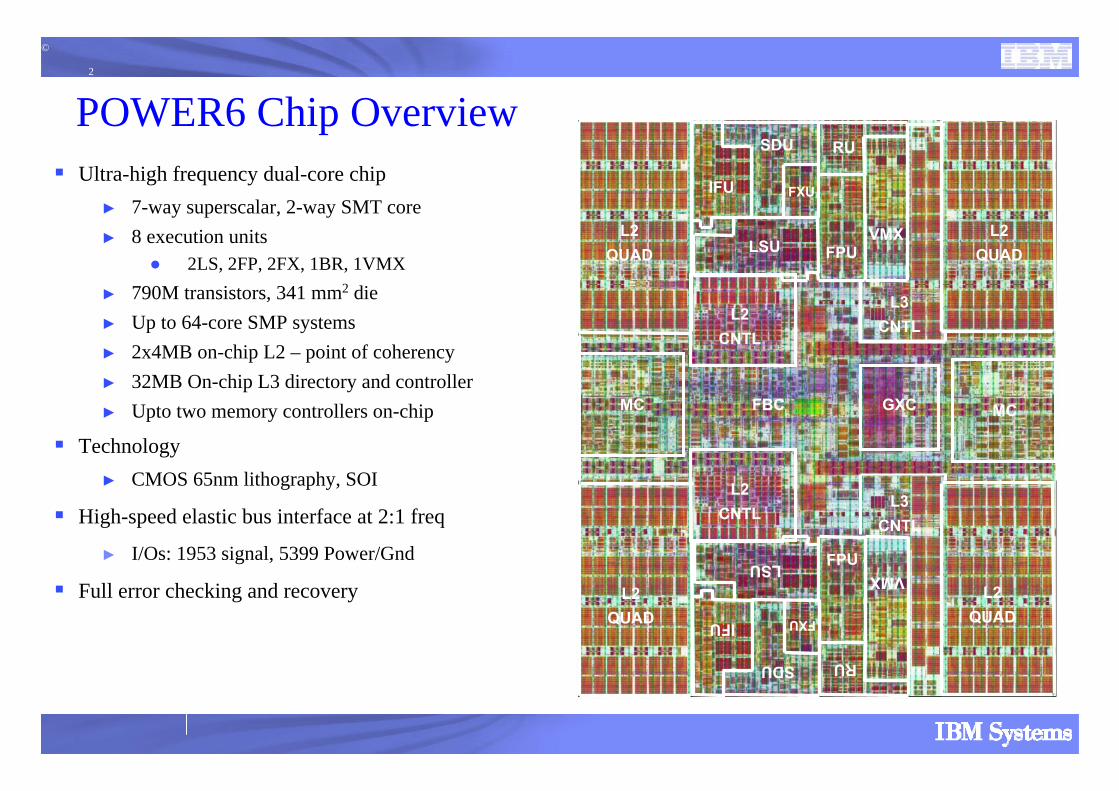
POWER6 Chip OverviewUltra-high frequency dual-core chip
► 7-way superscalar, 2-way SMT core► 8 execution units
● 2LS, 2FP, 2FX, 1BR, 1VMX► 790M transistors, 341 mm2 die► Up to 64-core SMP systems► 2x4MB on-chip L2 – point of coherency► 32MB On-chip L3 directory and controller► Upto two memory controllers on-chip
Technology► CMOS 65nm lithography, SOI
High-speed elastic bus interface at 2:1 freq
► I/Os: 1953 signal, 5399 Power/Gnd
Full error checking and recovery
IFU
LSU
SDU
FXU
RU
VMXFPU
L2QUAD
L2QUAD
L2QUAD
L2QUADIFU
LSU
SDU
FXU
RU
VMX
FPU
L2CNTL
L2CNTL
MC MC
L3CNTL
L3CNTL
GXCFBC

©
2006
IBM
Corporation
Cache details
Level Size Latency(clock cycles)
L1 (I+D) 2x64KB <5L2 2x4MB 22L3 32MB 160Memory 256GB 400

©
2006
IBM
Corporation
This comparison of Air- and Water-cooled systems* demonstrates tangible benefits of Water coolingtechnology
33% reduction in system size - right from the start! Less to buy, install, run, maintain...
* Comparison of water cooled system versus a comparable air cooled system providing equivalent system performance
An 82% reduction in heat load that your data center needs to address...
... Reducing the required number of Computer Room AC units from 18 down to 2!
Bottom LineA 19% reduction in total powerconsumption – along with space
and system size efficiencies!
Why use Water?

©
2006
IBM
Corporation
0
5
10
15
20
25
30
35
1 2 4 8 16
Physical Cores
Elap
sed
Tim
e (S
econ
ds)
IBM Power 575 4.7 GHz POWER6IBM p5-575 1.9 GHZ POWER5+ 16-coreHP Superdome 1.6 GHz Itanium2SGI Altix 4700 1.6 GHz Itanium2Cray XT3 2.6 GHz Opteron
WRF V2.1.1 Standard Benchmark12km CONUS
Seconds per step averaged over 149 time steps : A lower number is better
> Simultaneous multithreading used on the POWER6 575 and p5-575 platforms where appropriate.> IBM data current as of March 10, 2008. Other data as posted on March 10, 2008.> Source of benchmark information: http://www.mmm.ucar.edu/wrf/WG2/bench/results_20060515.html

©
2006
IBM
Corporation
Abaqus V6.6-7S4b Benchmark: 5,236,958 degrees of freedom (direct solver)
(Elapsed Time in seconds – A lower number indicates better performance)
0
4000
8000
12000
16000
20000
24000
1 2 4 8 16
Physical Cores
Ela
psed
Tim
e (S
econ
ds)
IBM Power 575 4.7 GHz POWER6
IBM System p5 570 2.2 GHz POWER5+
HP RX8640 1.6 GHz Itanium 2
SGI Altix 4700 1.6 GHz Itanium 2
HP XC3000 3.0 GHz Intel Xeon DC
Supermicro 7045B-8R+ 3.0 GHz Intel Xeon DC
HP XC4000 2.6 GHz AMD Opteron
IBM data current as of March 05, 2008. Other data as posted on March 05, 2008.
Source: http://www.simulia.com/support/v66/v66_performance.html

PRACE Winter School, Athens | 10-2-2009SARA Computing and Networking Services
4 File systems
> /home: source code, input files
> /scratch/shared: the same on all nodes, temporary files, output files (for transfer)
> /scratch/local: different on every node, temporary files
> /archive: output files (for keeping)

PRACE Winter School, Athens | 10-2-2009SARA Computing and Networking Services
4 File systems
Quota Speed backup/home small fast yes/scratch/shared large fast no, temporary/scratch/local large fast no, temporary/archive very large slow yes

PRACE Winter School, Athens | 10-2-2009SARA Computing and Networking Services
Compiling
> Default compilation is 64-bits mode> Fortran
xlf_r or f77: Fortran 77xlf90_r, xlf95_r: Fortran 90/95mpfort: Fortran MPI programs
> Cxlc_r: Cmpcc: C MPI programs
> C++xlC_r:C++mpCC: C++ MPI programs
> -qsmp=omp: OpenMP

PRACE Winter School, Athens | 10-2-2009SARA Computing and Networking Services
Extra software: modules
> Advantage: no complicated compilation command
> module avail> module list> module load [package]
> Some packages:> NAMD, CPMD, GROMACS, R, ncl, netcdf, hdf5,
scalapack, valgrind, upc, chapel, ..
> See also: https://subtrac.sara.nl/userdoc/wiki/huygens/usage/progavail

PRACE Winter School, Athens | 10-2-2009SARA Computing and Networking Services
Optimization
> always add '-qarch=auto -qtune=auto'
> -O0 to verify correctness> -O2 low optimization> -O3 -qstrict medium optimization> -O3 -qstrict -qhot high optimization> -O3 -qhot very high optimization, uses
IBM specific library calls> -O5 maximum optimization> -qenablevmx when using single precision

PRACE Winter School, Athens | 10-2-2009SARA Computing and Networking Services
ESSL: Eng. and sci. subroutine libraryMASS: Math. acceleration subsystem> ESSL Functionality:
Linear algebra (BLAS, LAPACK) Eigensystem analysisFourier transform
> Usage, see: https://subtrac.sara.nl/userdoc/wiki/huygens/usage/progavail/essl
> MASS Functionality:Faster versions of intrinsics (sin, sqrt, exp, etc.)Vector routines (needs source modifications)
> Usage: -lmass_64

PRACE Winter School, Athens | 10-2-2009SARA Computing and Networking Services
LoadLeveler
> Facilities for building, submitting and processing batch jobs.
> Matches job requirements with best available machine resources.
> Job steps can depend on each other.
> Basic use: submit, display and cancel your jobs.

PRACE Winter School, Athens | 10-2-2009SARA Computing and Networking Services
Job Command File: Example
# @ class = spec_training# @ wall_clock_limit = 00:10:00# @ job_type = parallel# @ node = 4# @ tasks_per_node = 16# @ network.mpi = sn_all,shared,US# @ queueecho “Hello world”cd workdir./ParallelProgram

PRACE Winter School, Athens | 10-2-2009SARA Computing and Networking Services
Debugging
> optimization can interfere with debugging!
> -g -qfullpath: for debug info in executable
> -qcheck: array boundary checking in Fortran and C++
> -qflttrap: floating point exception trapping
> export XLFRTEOPTS=buffering=disable_allfor unbuffered output (at runtime)

PRACE Winter School, Athens | 10-2-2009SARA Computing and Networking Services
Debugging: totalview (debugger)
> module load totalview> when running or crashed

PRACE Winter School, Athens | 10-2-2009SARA Computing and Networking Services
Debugging: valgrind (memory checking)
> 'out of memory after 5 hours!'> find memory leaks> special command for parallel programs, see web
45,000,000 bytes in 9 blocks are definitely lost in loss record 4 of 4at 0x404EF24: malloc (vg_replace_malloc.c:207)by 0x10000CAC: allocmem (test.f90:20)by 0x100009B0: hi (test.f90:6)by 0x4920128: (below main) (in /lib64/power6/libc-2.4.so)
LEAK SUMMARY:definitely lost: 45,000,000 bytes in 9 blocks.possibly lost: 0 bytes in 0 blocks.still reachable: 5,000,088 bytes in 3 blocks.suppressed: 0 bytes in 0 blocks.

PRACE Winter School, Athens | 10-2-2009SARA Computing and Networking Services
Debugging: marmot (MPI checker)
> Generates a webpage at runtime with warnings, errors and explanations.
PRACE Winter School, Athens | 10-2-2009SARA Computing and Networking Services
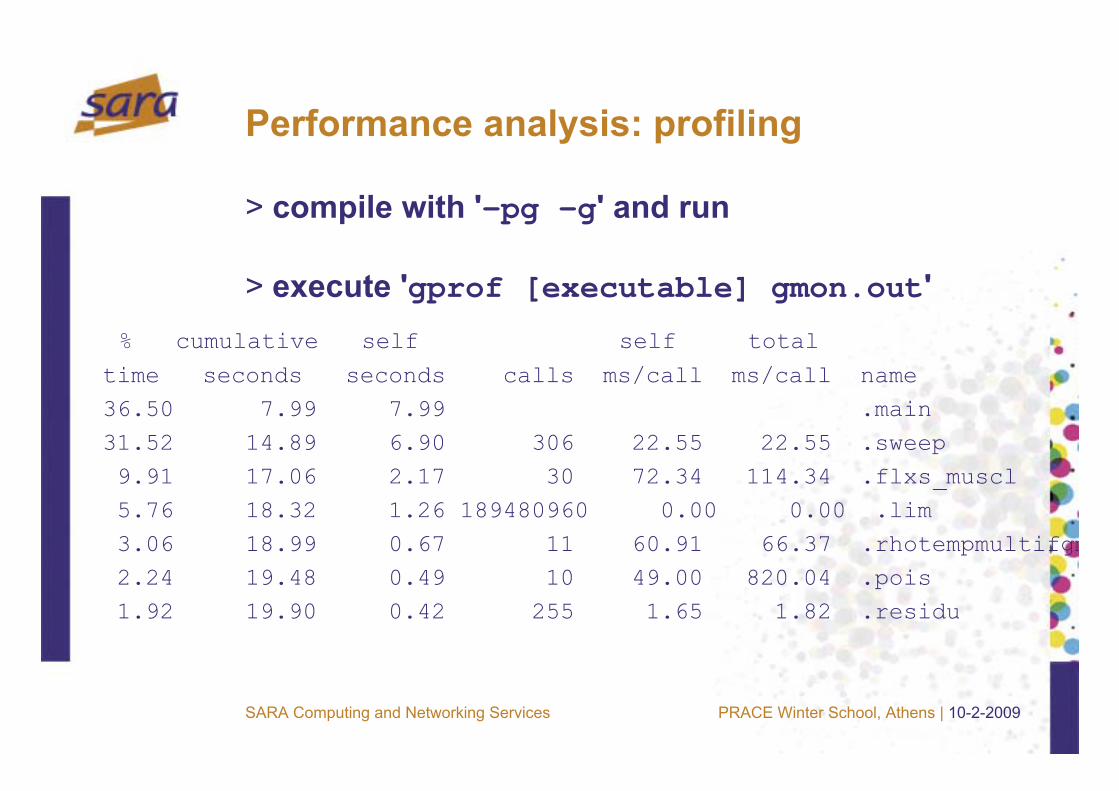
Performance analysis: profiling
> compile with '-pg -g' and run
> execute 'gprof [executable] gmon.out'% cumulative self self total
time seconds seconds calls ms/call ms/call name 36.50 7.99 7.99 .main31.52 14.89 6.90 306 22.55 22.55 .sweep9.91 17.06 2.17 30 72.34 114.34 .flxs_muscl5.76 18.32 1.26 189480960 0.00 0.00 .lim3.06 18.99 0.67 11 60.91 66.37 .rhotempmultifgm2.24 19.48 0.49 10 49.00 820.04 .pois1.92 19.90 0.42 255 1.65 1.82 .residu
PRACE Winter School, Athens | 10-2-2009SARA Computing and Networking Services
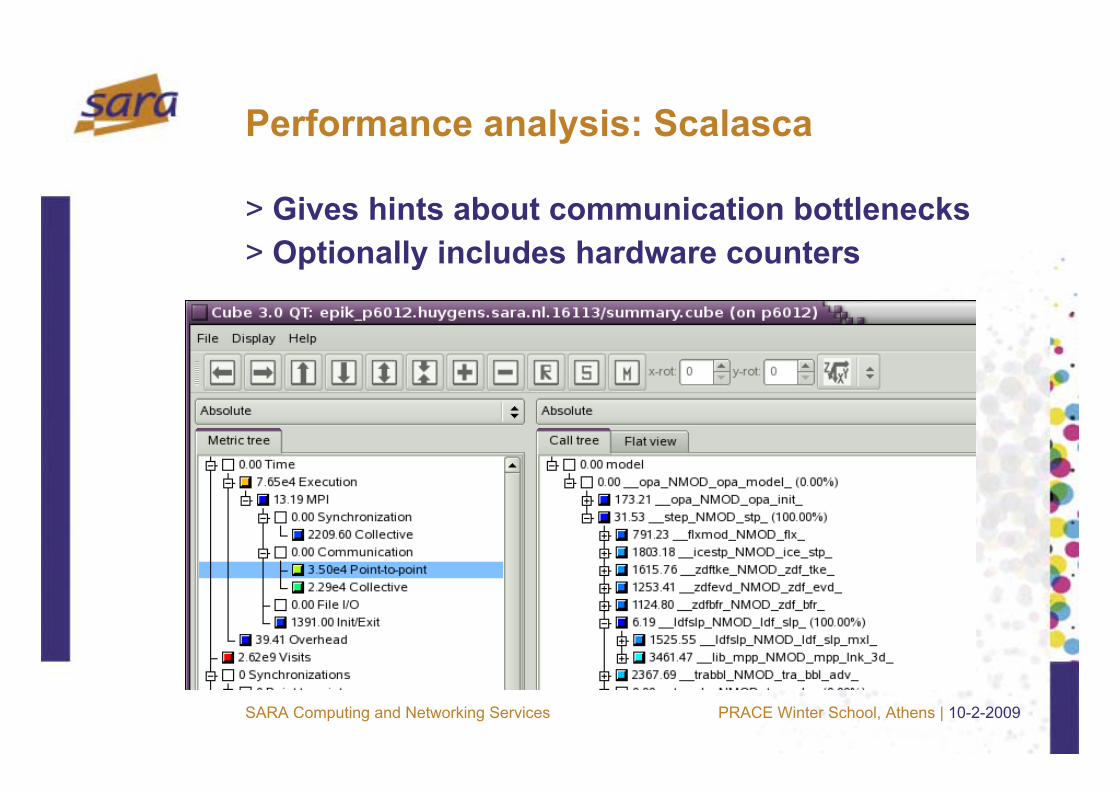
Performance analysis: Scalasca
> Gives hints about communication bottlenecks> Optionally includes hardware counters
PRACE Winter School, Athens | 10-2-2009SARA Computing and Networking Services
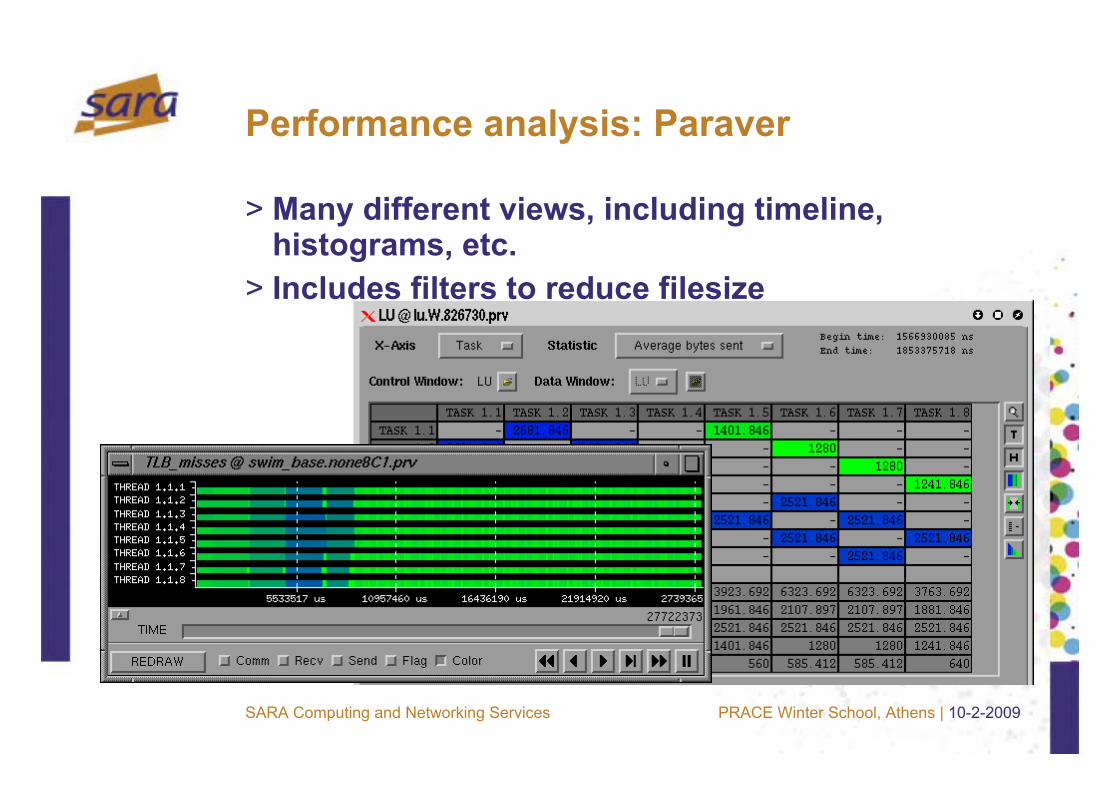
Performance analysis: Paraver
> Many different views, including timeline, histograms, etc.
> Includes filters to reduce filesize

PRACE Winter School, Athens | 10-2-2009SARA Computing and Networking Services
Thank you for yourattention
SARA Computing & Networking Services