
Why your PostgreSQL 9.0 clusterneeds pgpool-II
It works, but there are things you must know
Jean-Paul ArgudoDalibo
PostgreSQL Expertise CompanyParis, France
PgDay.Eu 6-8 december 2010

Agenda
1 About
2 Presentation of pgpool-II
3 Clustering PostgreSQL
4 Problems and solutions

Thanks...Tatsuo & SRA OSS guys
Special thanks to Tatsuo Ishii, lead developer of pgpool tools.Wrote lots of wonderful tools for PostgreSQLReviewed those slidesGave me some benchmark results I couldn’t prepare ontime
Thanks also to all others participating in this effort:Nozomi Anzai, Devrim Gunduz, Guillaume Lelarge, HarukaTakatsuka, Akio Ishida, Toshihiro Kitagawa, Yutaka Tanida, TomoakiSato and Yoshiharu MoriMost of them are from SRA OSS Incorporation, Japan.

About..me
Jean-Paul Argudo, owner of DaliboFounder of PostgreSQL.fr website (february 2004)Co-founder of PostgreSQL.fr non-profit (since february2005)Board member (treasurer) of PostgreSQL Europe (since2008)

About.....Dalibo
PostgreSQL expertise in France since 2005More than 200 customers, from dotcoms to real bigcompanies, including public institutionsParticipation in the CNAF migration to PostgreSQL(OMG! you’re in the wrong talk ?!)Consulting missions, trainings and support contractsSome logos of customers you may know ?

About..this PGDay
Thanks to all speakers, staff and sponsorsGround helpers are *AWESOME*, special thanks !

Presentation of pgpool-IIWhat it does
At first, developed for connection poolingReplicationMaster/Slave modeLoad balancingAutomatic failover on desync detectionOnline recoveryParallel Query
pgpool-II does *lots* of things

Presentation of pgpool-IIConnection Pooling
Acts as a pooler: whenever we receive M connections fromclients, only N connections will be used.Usefull to limit incoming connections **without** sendingerrors to the clients: exceeding connections will be queued.

Presentation of pgpool-IIConnection Pooling

Presentation of pgpool-IIReplication and Load-balancing of reads
Based on statements replication: writes queries are sent toall backends, read queries can be balancedCaveat: don’t let users access to backends directly!

Presentation of pgpool-IIReplication and Load-balancing of reads

Presentation of pgpool-IIMaster/Slave Mode and Load-balancing of reads
Works with any master/slave replication system (Slony-I,Londiste, Streaming replication, Bucardo, whichever youlike) (despite I didn’t test all)Write queries are sent to the master only, akabackend_*0
A new sub-mode in version 3 (september 2010) to handleStreaming Replication specifics

Presentation of pgpool-IIMaster/Slave Mode and Load-balancing of reads

Presentation of pgpool-IIFailover
A mechanism exists to verify the sync between backendsWhen a node is detected as down, a script is executed andarguments passed to it (failover.sh)Depending the mode pgpool-II runs in, the actions toperform in the script are different. We’ll focus on this later.

Presentation of pgpool-IIFailover

Presentation of pgpool-IIOnline recovery
Online recovery can be done without restarting pgpoolWhen a PostgreSQL backend needs to be restored, wecan execute one pgpool-II command to restore it(pcp_recovery_node)It uses pgpool local script (like basebackup.sh) to:
perform an hot backup of the master and send it to thenode to be restoredcreate remotely the recovery.conf script in the$PGDATA of the restored node
And then starts the remote restored node thanks to thepcp_remote_start scriptCaveats: basebackup.sh and pcp_remote_starthave to be located in the $PGDATA

Presentation of pgpool-IIParallel Query
Allows to virtually cut your data among multiples serversNeeds a system database, called systemdb for pgpool-IIto store information about your dataPartitioning your data is based on simple functions ofpgpool-II to know where to ask forCREATE OR REPLACE FUNCTION pgpool_catalog.dist_def_accounts (valANYELEMENT)RETURNS INTEGER AS ’SELECT CASE WHEN $1 >= 1 and $1 <= 30000 THEN 0WHEN $1 > 30000 and $1 <= 60000 THEN 1
ELSE 2
To be used with quite large data sets

Presentation of pgpool-IIThis talk ?
We’ll focus on those features on pgpool-IIMaster/Slave modeLoad balancingFailoverOnline recovery

Clustering PostgreSQL with Slony-ISchema

Clustering PostgreSQL with Slony-IPros/Cons
ProsWrite performance is good (10 to 20% overhead)Automatic failover of slavesConnection pooling and load-balancing: boost readperformance
ConsAsynchronous replication, with a large delayNo DDL replication, not easy to propagate DDL changes(slonik)No large objects replicationNot that easy to configure and maintain

Clustering PostgreSQL with Slony-IReplication delay with Slony-I
Courtesy of Tatsuo Ishii, SRA OSS Japan

Clustering PostgreSQL with Slony-IDon’t think I wanna throw Slony-I
At least for four reasonsSlony-I can interact between PostgreSQL versions (samedoes Londiste and Burcardo). SR cannot. Evenarchitectures have to be identical (32/64 bits)Slony-I can replicate parts of database. SR cannot, itreplicates the whole PostgreSQL "server" (aka "cluster"aka "$PGDATA")Slony-I has cascading replication. SR doesn’t (yet (I hope))Because Slony-I is cool!
I think Slony-I will be used more specificaly in the future, forwhat it does
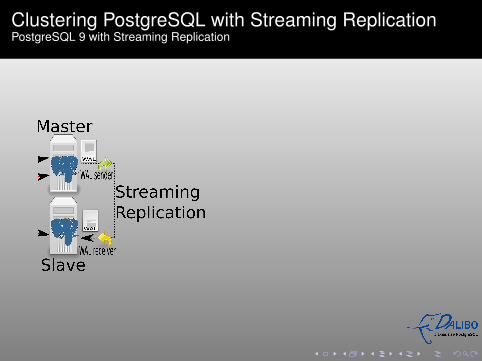
Clustering PostgreSQL with Streaming ReplicationPostgreSQL 9 with Streaming Replication

Clustering PostgreSQL with Streaming ReplicationLow write overhead
Courtesy of Tatsuo Ishii, SRA OSS Japan

Clustering PostgreSQL with Streaming ReplicationLow replication delay
Courtesy of Tatsuo Ishii, SRA OSS Japan

Clustering PostgreSQL with Streaming ReplicationPros
Low write overheadLow replication delayTransparent replication : even DDL and large objects arereplicatedEasy to manage

Clustering PostgreSQL with Streaming ReplicationCons
No automatic failoverNo connection pooling, no balancingThe standby dislikes all write attempts and some otherSQL commands, you’ll need to filter things sent to thestandby

A good solutionMaster/Slave with Streaming Replication and pgpool-II

pgpool-II Master/Slave with Streaming ReplicationPros
Write performance is good (10 to 20% overhead)Automatic failover of slavesConnection pooling and load-balancing: boost readperformanceDDL and large-objects replication

pgpool-II Master/Slave with Streaming ReplicationNew features of version 3.0 (sept 2010)
New master/slave "sub_mode" dedicated for StreamingReplication and Hot StandbyIntelligent load-balancing": if the slave is far "more thandelay_threshold bytes, then read queries are sent tothe master onlyAdding standby servers without stopping pgpool-II(pcp_attach_node new method)Scales very well adding slaves!

Problems and solutionsDocumentation
Problempgpool-II documentation is sometimes hard to understandthe documentation exists only in japaneese and english
SolutionA patch for the english version of the documentationcomes from DaliboI’m translating it to french (status 70%)Maybe I’ll translate it to spanish too

Problems and solutionsIndustrialization
ProblemExamples on the net are often too simpleLeads to headaches when the architecture to implementbecomes complex
SolutionCustomer’s projects feedback from Dalibo to come: scriptsand HOWTO’sSome patches (sent & currently in progress) toindustrialize pgpool-II easierWe shall study how to use repmgr maybe in our scripts

Problems and solutionsHow to not balance
ProblemYou may need to *NOT* balance queries
SolutionAdd a specific tag anywhere in the query not to bebalanced: /*NO REPLICATE*/ (poor)and/or use explicit transactions likeBEGIN [..]my SQL transaction[..] COMMIT;(better!)

Problems and solutionsJAVA app servers & autocommit on
ProblemMost JAVA app servers are in autocommit to on
pgpool-II won’t then balance anything, since we’re onimplicit transactions
SolutionFirst, set autocommit to off
Second, learn to code transactions in SQL
Third, don’t be transactional if your SELECT can be readanywhere

Problems and solutionsWrite functions
ProblemAny function could create writes. Like SELECTcreate_user(’jpargudo’);
Those functions will be balanced by default because of theSELECT... Even on the standby server(s)
SolutionDeclare any write function into black_function_list
OR declare functions that can be balanced inwhite_function_list
**NEVER** use both at the same timeIf you want any function NOT to be balanced put anyunexisting function name into white_function_listand nothing in black_function_list

Problems and solutionsAutomatic failover
ProblemIf pgpool-II detects anything wrong on a node, it executesfailover.sh (or any script you configured)A non-reachable node is not a down node sometimes
SolutionAVOID automatic failover. Prefer sending messages inyour failover.sh script to admins, Nagios or whateverAnyway, the node won’t be used by pgpool-II... Yes, thatsproblematic if it is the MASTER node that is down

Problems and solutionsFailover’s darkest moment
ProblemDuring the slave’s weaking up, there’s no system to lockanything. So write queries could be sent to a read-onlybackend
SolutionKnown problem, devs currently working on it:
The obvious idea would be add a config directivewhich allow pgpool to wait N seconds before the newprimary server is ready for accepting connections fromclients. More smart idea would be that pgpool checksnew primary is available or not before accepting newconnections. Better idea? – Tatsuo Ishii SRA OSS,Inc. Japan

Problems and solutionsFailover in a complex architecture with multiple slaves
ProblemIf a failover of the MASTER is done on the PRIMARY, andyou have many slaves, only the NEW MASTER (one of theslaves) will be up-to-dateBecause all the slaves are fed by the SR from the formerMASTERYou could then pass from an architecture with MASTER +4 SLAVES to "ONE MASTER ONLY" architecture: ouch
SolutionWe need CASCADING streaming replication, where aslave can also feed another slave.Any PostgreSQL Hacker in the room to state on this ? :-)New per Simon’s talk about SR yesterday:We shall allfocus on the "Replication manager" tool (repmgr)1
1http://projects.2ndquadrant.com/repmgr

Conclusionpgpool-II + PostgreSQL SR/HS : a good compromise
A good solution for most cases, even on complexarchitectures with multiple nodesWill be better soon with patches on code anddocumentationReliable, even more with new repmgr (to be tested soon!)

Stay tuned!Some URLS
Main project pagehttp://pgpool.projects.postgresql.org/pgFoundry pagehttp://pgfoundry.org/projects/pgpool/General mailing-listhttp://pgfoundry.org/mailman/listinfo/pgpool-generalHackers mailing-listhttp://pgfoundry.org/mailman/listinfo/pgpool-hackersThis talk PDFcheck http://www.dalibo.org/ under "Conferences" soon!Twitter @jpargudohttp://www.dalibo.(com|org)[email protected]

Any question?Feel free to ask
There’s no stupid questionsBut my answers shall be :-/Sorry guys, I really tried to have 42 slides







