
University of MichiganElectrical Engineering and Computer Science
1
Transparent CPU-GPU Collaboration forData-Parallel Kernels on Heterogeneous Systems
Janghaeng LeeMehrzad Samadi
Yongjun Parkand Scott Mahlke
University of Michigan - Ann Arbor

University of MichiganElectrical Engineering and Computer Science
2
Heterogeneity• Computer systems have
become heterogeneous– Laptops, Servers– Mobile devices
• GPUs integrated with CPUs• Discrete GPUs added for
– Gaming– Supercomputing
• Co-processors for massive data-parallel workload – Intel Xeon PHI
University of MichiganElectrical Engineering and Computer Science
3
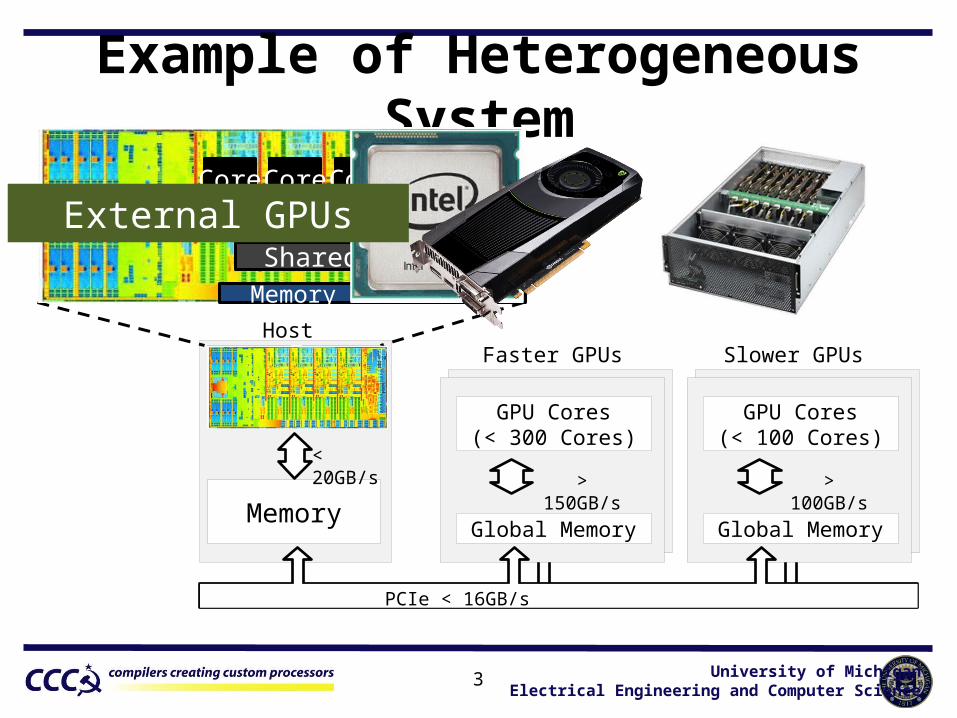
HostMulti Core
CPU (4-16 cores)
Memory
< 20GB/s
GPU Cores(> 16 cores)
Example of Heterogeneous System
Faster GPUs
> 150GB/s
GPU Cores(< 300 Cores)
Global Memory
Slower GPUs
> 100GB/s
GPU Cores(< 100 Cores)
Global Memory
PCIe < 16GB/s
GPUCore Core Core Core
Memory ControllerShared L3
External GPUs

University of MichiganElectrical Engineering and Computer Science
4
Typical Heterogeneous ExecutionGPU 1CPU
Seq.Code
TransferOutput
KernelRun onGPU 1
TransferInput
IDLE
Time
GPU 0
IDLE

University of MichiganElectrical Engineering and Computer Science
5
Collaborative Heterogeneous ExecutionGPU 1CPU
TransferOutput
TransferInput
Seq.Code
IDLE
Time
GPU 0
IDLE
TransferInput
Seq.Code
Run onGPU 1
TransferOutput
Merge
GPU 1CPUGPU 0
Run onGPU 0
Seq.Code
Run onCPU
Speedup
KernelRun onGPU 1
• 3 Issues- How to transform the kernel
- How to merge output efficiently
- How to partition

University of MichiganElectrical Engineering and Computer Science
6
OpenCL Execution ModelOpenCL Data Parallel Kernel
Work-item
Work-group
Compute Device 1 Compute Unit (CU)
PE PE PE PE…
Global Memory
Shared Memory Constant Memory
…Compute Unit (CU)
PE PE PE PE…
Compute Unit (CU)
PE PE PE PE…Compute Unit (CU)
PE PE PE PE…
… …
…
University of MichiganElectrical Engineering and Computer Science
7
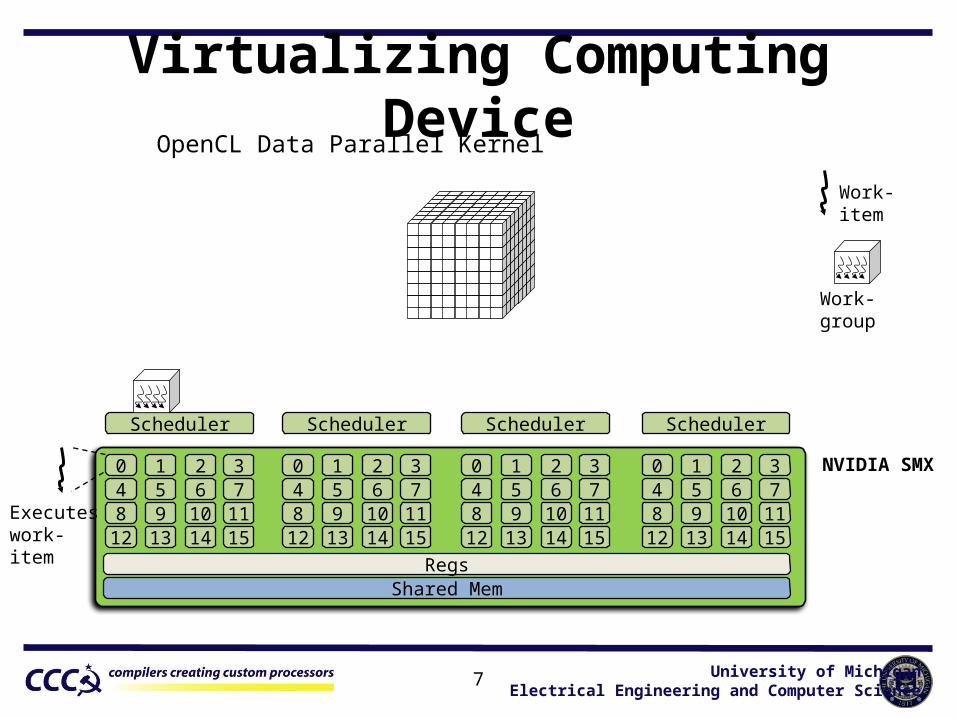
Virtualizing Computing DeviceOpenCL Data Parallel Kernel
Work-item
Work-group
NVIDIA SMX
Executeswork-item
RegsShared Mem
048
12
159
13
26
1014
371115
Scheduler Scheduler Scheduler Scheduler
048
12
159
13
26
1014
371115
048
12
159
13
26
1014
371115
048
12
159
13
26
1014
371115

University of MichiganElectrical Engineering and Computer Science
8
Virtualization on CPU
Executesa work-item
Core 0
Cache
Control
Register
Core 1 Core 3
ALU
Cache
Control
Register
ALU
ALU ALU
ALU ALU
ALU ALU
ALU
Cache
Control
Register
ALU
ALU ALU
Work-item
Work-group
Core 2
ALU
Cache
Control
Register
ALU
ALU ALU
University of MichiganElectrical Engineering and Computer Science
9
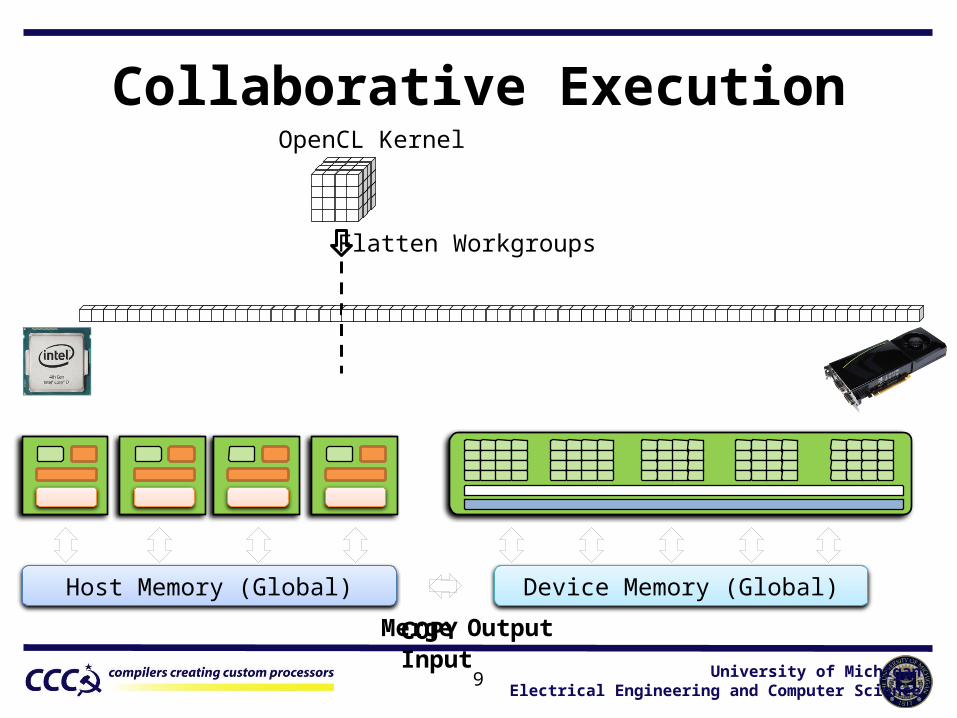
Collaborative ExecutionOpenCL Kernel
Host Memory (Global) Device Memory (Global)
COPY Input
Flatten Workgroups
Merge Output

University of MichiganElectrical Engineering and Computer Science
10
OpenCL - Single Kernel Multiple Devices (SKMD)
OpenCL APIApplication Binary
Launch Kernel
CPU Device (Host)Faster GPUs Slower GPUs
GPU Cores(< 300 Cores)
GPU Cores(< 100 Cores)
PCIe < 16GB/s
WG-VariantProfile DataPartitioner
BufferManager
KernelTransformer
WorkGroups Dev 0 Dev 1 Dev2
16 22.42 14.21 42.1132 22.34 34.39 55.12… … … …
512 22.41 39.21 120.23
num_groups(0)num_groups(1)
num_groups(2)
SKMD Framework
• Key Ideas– Kernel Transform• Work on subset of WGs• Efficiently merge outputs
in different address spaces– Buffer Management• Manages working set
for each device– Partition• Assign optimal workload
for each device
Multi CoreCPU (4-16 cores)
GPU Cores(> 16 cores)
University of MichiganElectrical Engineering and Computer Science
11
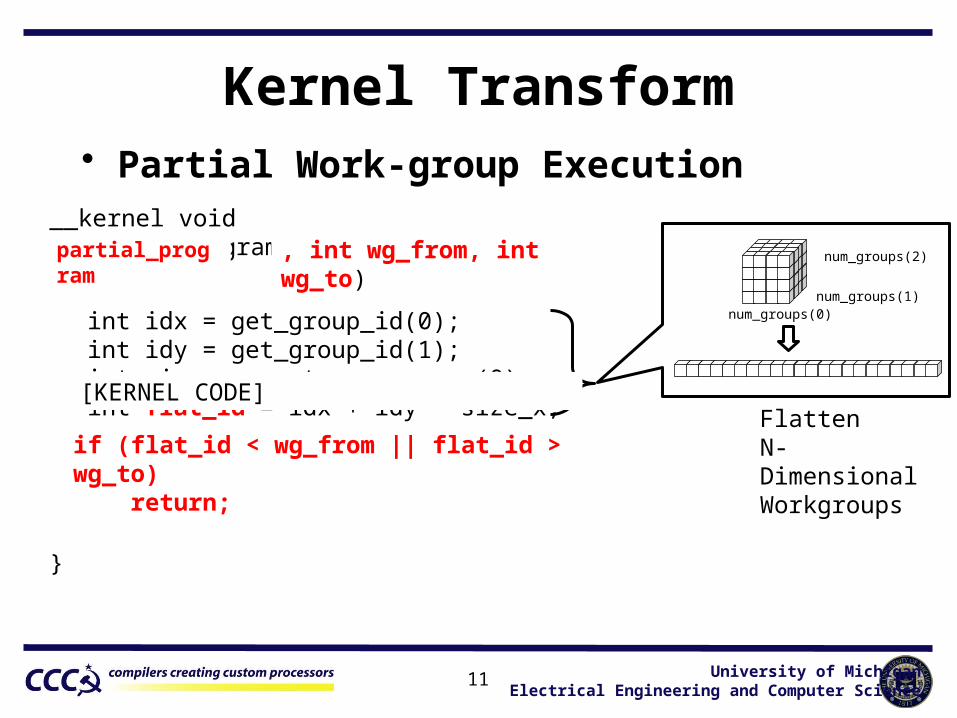
Kernel Transform• Partial Work-group Execution
__kernel voidoriginal_program( ... ){
}
num_groups(0)num_groups(1)
num_groups(2)
FlattenN-DimensionalWorkgroups
partial_program , int wg_from, int wg_to)
int idx = get_group_id(0); int idy = get_group_id(1); int size_x = get_num_groups(0); int flat_id = idx + idy * size_x;
if (flat_id < wg_from || flat_id > wg_to) return;
[KERNEL CODE]

University of MichiganElectrical Engineering and Computer Science
12
Buffer Management – Classifying Kernel
Work-groups 33% 50% 17%
Input Address
Read
Output Address
Write
33% 50% 17%Work-groups
Input Address
Read
Output Address
Write
CPU Device (Host) Faster GPUs Slower GPUs
Contiguous Memory Access Kernel
Discontiguous Memory Access Kernel
Easy to merge output in separate address space
Hard to Merge
University of MichiganElectrical Engineering and Computer Science
13
Merging Outputs
• Intuition– CPU would produce the same as GPU’s if it executed rest of work-groups– Already has rest of results from GPU
• Simple solution for merging kernel– Enable work-groups that were enabled in GPUs– Replace global store value with copy (load from GPU result)
• Log output location &check log locationwhen merging– BAD idea– Additional overhead

University of MichiganElectrical Engineering and Computer Science
14
Merge Kernel Transformationkernel voidpartial_program ( ... , __global float *output,
int wg_from, int wg_to ) {
int flat_id = idx + idy * size_x;if (flat_id < wg_from || flat_id > wg_to) return;
// kernel bodyfor (){
...sum += ...;
}
output[tid] = sum;}
Removed by Dead Code Elimination
Store to global memory
, float *gpu_out )
gpu_out[tid];
merge_program
Merging CostDone in Memory B/W
≈ 20 GB /s
< 0.1 ms in most applications

University of MichiganElectrical Engineering and Computer Science
15
Partitioning• Uses profile data• Done in Runtime
– Must be fast• Uses Decision Tree Heuristics (Greedy)
– Start from the root node assuming• All workgroups are assigned to the fastest device
– Fixed # of workgroups are offloaded from the fastest device to another from the parent’s node
University of MichiganElectrical Engineering and Computer Science
16
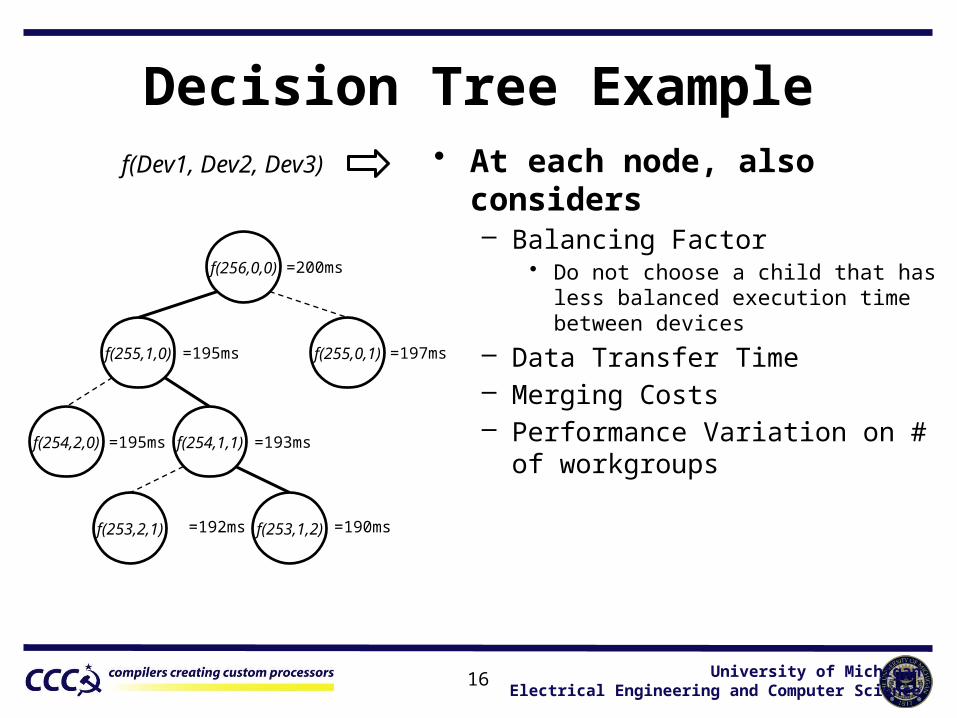
Decision Tree Example
f(256,0,0)
f(255,1,0) f(255,0,1)
f(254,2,0) f(254,1,1)
f(253,1,2)f(253,2,1)
=197ms=195ms
=195ms =193ms
=192ms =190ms
=200ms
• At each node, also considers– Balancing Factor
• Do not choose a child that has less balanced execution time between devices
– Data Transfer Time– Merging Costs– Performance Variation on # of work-
groups
f(Dev1, Dev2, Dev3)

University of MichiganElectrical Engineering and Computer Science
17
Experimental SetupDevice
Intel XeonE3-1230
(SandyBridge)
NVIDIAGTX 560(Fermi)
NVIDIAQuadro(Fermi)
# of Cores 4 (8 Threads) 336 96
Clock Freq. 3.2 GHz 1.62 GHz 1.28 GHz
Memory 8 GB DDR3 1 GB GDDR5 1 GB GDDR 3
Peak Perf. 409 GFlops 1,088 GFlops 245 GFlops
OpenCL DriverEnhanced
Intel SDK 1.5NVIDIASDK 4.0
PCIe N/A 2.0 x16
OS Ubuntu Linux 12.04 LTS
Benchmarks AMDAPP SDK, NVIDIA SDK

University of MichiganElectrical Engineering and Computer Science
18
ResultsIntel Xeon Only
Redu
ction
His
togr
am
Mat
rixM
ultip
licati
on
Mat
rixTr
ansp
ose
Qua
siRa
ndom
Sequ
ence
AES
Encr
ypt
AES
Dec
rypt
Vec
torA
dd
Blac
kSch
oles
Bino
mia
lOpti
on
Scan
Larg
eArr
ays
GEO
MEA
N
DiscontiguousKernels
ContiguousKernels
-
0
0.2
0.4
0.6
0.8
1
1.2
1.4
1.6
1.8
2
GTX 560 Only Linear Partition Transfer Cost &Perf. Variance-Aware
Spee
dup

University of MichiganElectrical Engineering and Computer Science
19
Redu
ction
His
togr
am
Mat
rixM
ultip
licati
on
Mat
rixTr
ansp
ose
Qua
siRa
ndom
Sequ
ence
AES
Encr
ypt
AES
Dec
rypt
Vec
torA
dd
Blac
kSch
oles
Bino
mia
lOpti
on
Scan
Larg
eArr
ays
GEO
MEA
N
DiscontiguousKernels
ContiguousKernels
-
0
0.2
0.4
0.6
0.8
1
1.2
1.4
1.6
1.8
2
GTX 560 Only Linear Partition Transfer Cost &Perf. Variance-Aware
Spee
dup
ResultsIntel Xeon Only
29%

University of MichiganElectrical Engineering and Computer Science
20
Results (Break Down)
Vector Add
MatrixMultiplication
Intel Xeon
GTX 560
Quadro600
Only
GT
X 5
60
0 2 4 6 8 10 12 14 16 18
Time(ms)
Intel Xeon
GTX 560
Quadro600
OnlyIn
tel X
eon
0 0.5 1 1.5 2 2.5 3 3.5 4
Series1 Input Transfer Kernel Execution Series4Output Transfer Series6 Merge Time
Time(ms)

University of MichiganElectrical Engineering and Computer Science
21
Summary• Systems have been become more heterogeneous
– Configured with several types of devices• Existing CPU + GPU heterogeneous
– Single device executes a single kernel• Single Kernel Multiple Devices (SKMD)
– CPUs and GPUs working on a single kernel– Transparent Framework– Partial kernel execution– Merging partial output– Optimal partitioning– Performance improvement of 29% over single device execution

University of MichiganElectrical Engineering and Computer Science
22
Q & A



![GPU Kernels for Block-Sparse Weights...GPU Kernels for Block-Sparse Weights Scott Gray, Alec Radford and Diederik P. Kingma OpenAI [scott,alec,dpkingma]@openai.com Abstract We’re](https://cdn.vdocuments.us/doc/165x107/5e995d9ef045240d9a1be14c/gpu-kernels-for-block-sparse-weights-gpu-kernels-for-block-sparse-weights-scott.jpg)



