
Ufuk Celebi
Hadoop Summit Dublin April 13, 2016
Unified Stream & Batch Processing
with Apache Flink

What is Apache Flink?
2
Apache Flink is an open source stream processing framework.
• Event Time Handling • State & Fault Tolerance • Low Latency • High Throughput
Developed at the Apache Software Foundation.
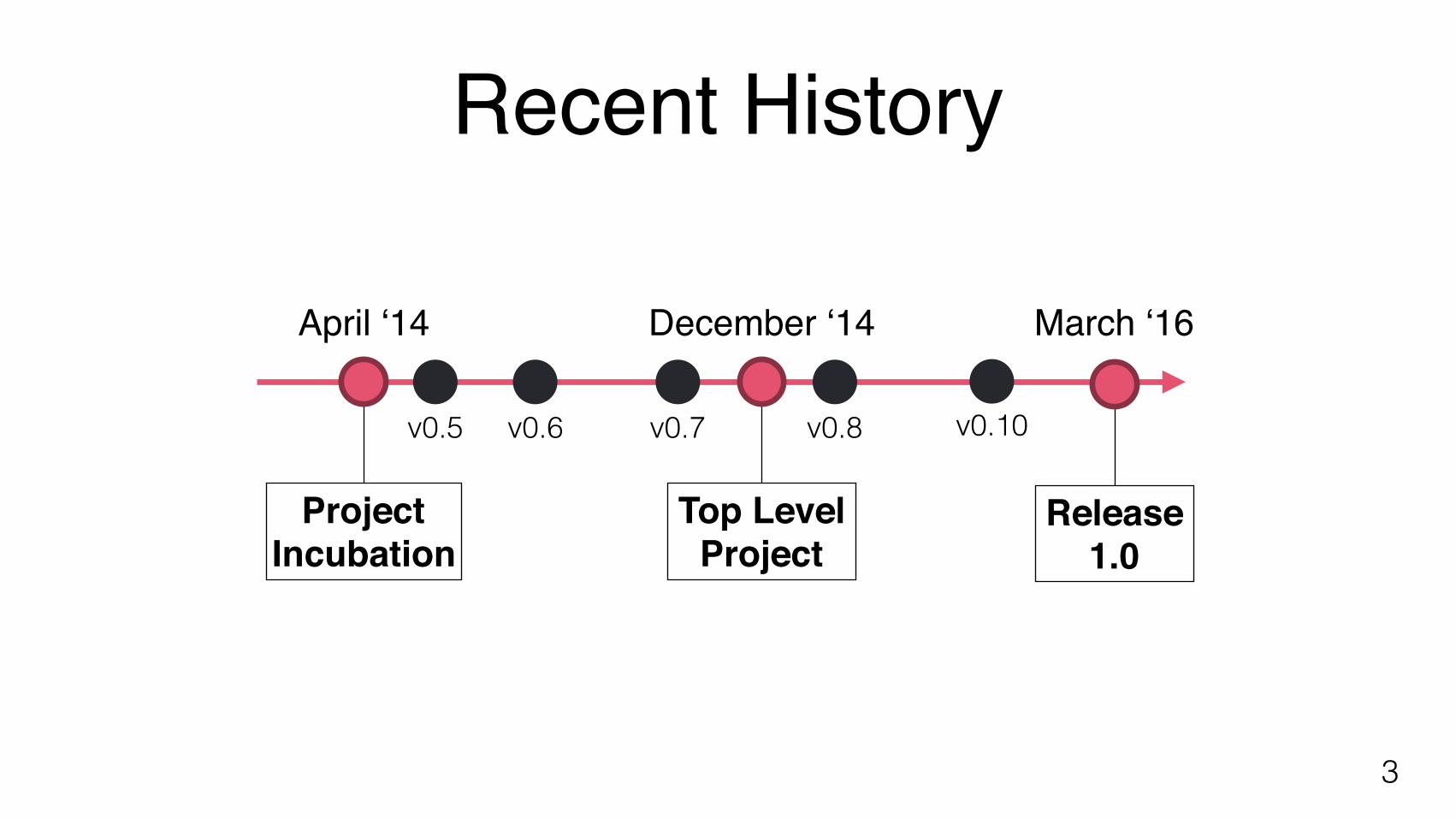
Recent History
3
April ‘14 December ‘14
v0.5 v0.6 v0.7
March ‘16
ProjectIncubation
Top LevelProject
v0.8 v0.10
Release1.0
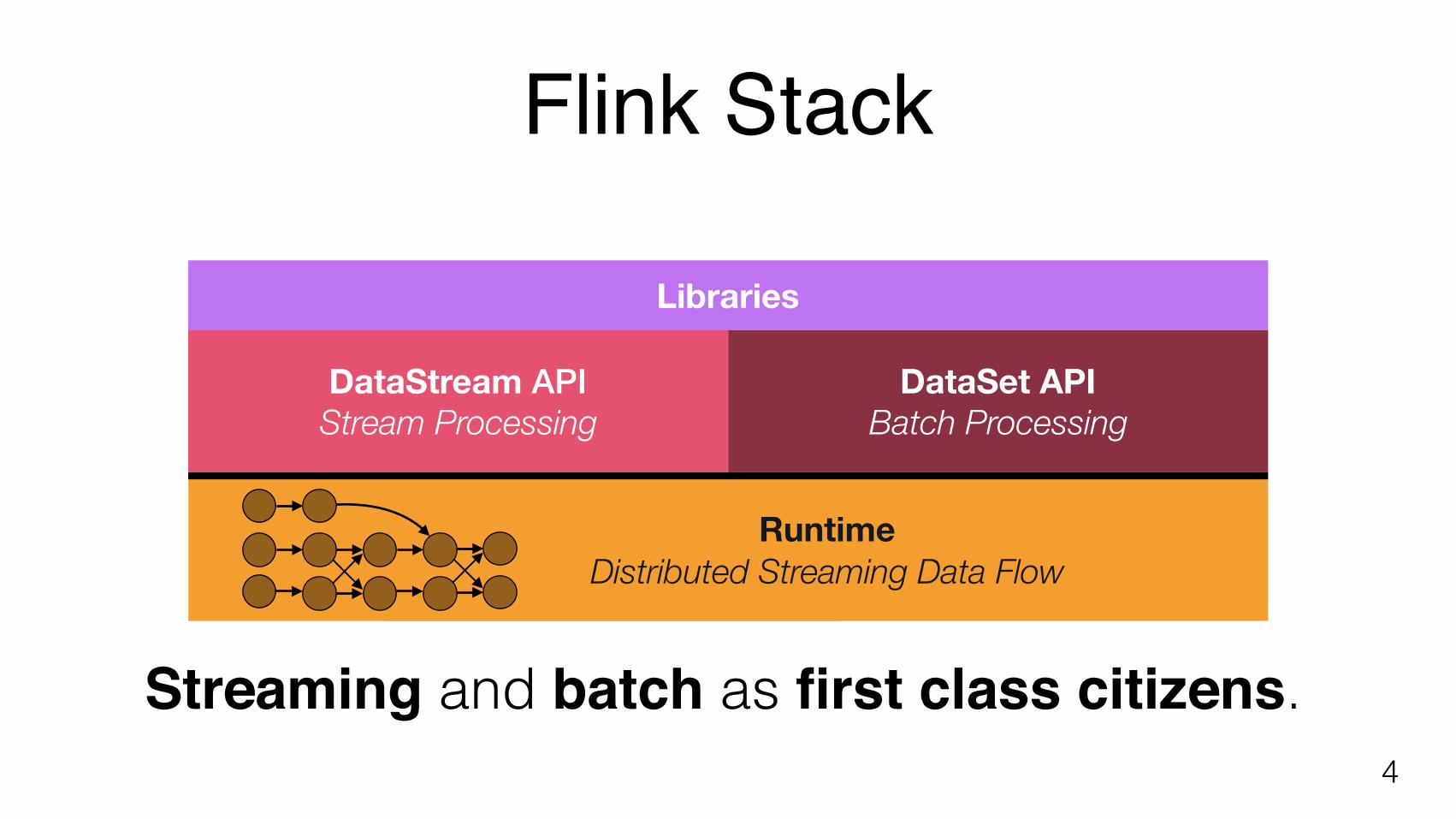
Flink Stack
4
DataStream API Stream Processing
DataSet API Batch Processing
Runtime Distributed Streaming Data Flow
Libraries
Streaming and batch as first class citizens.
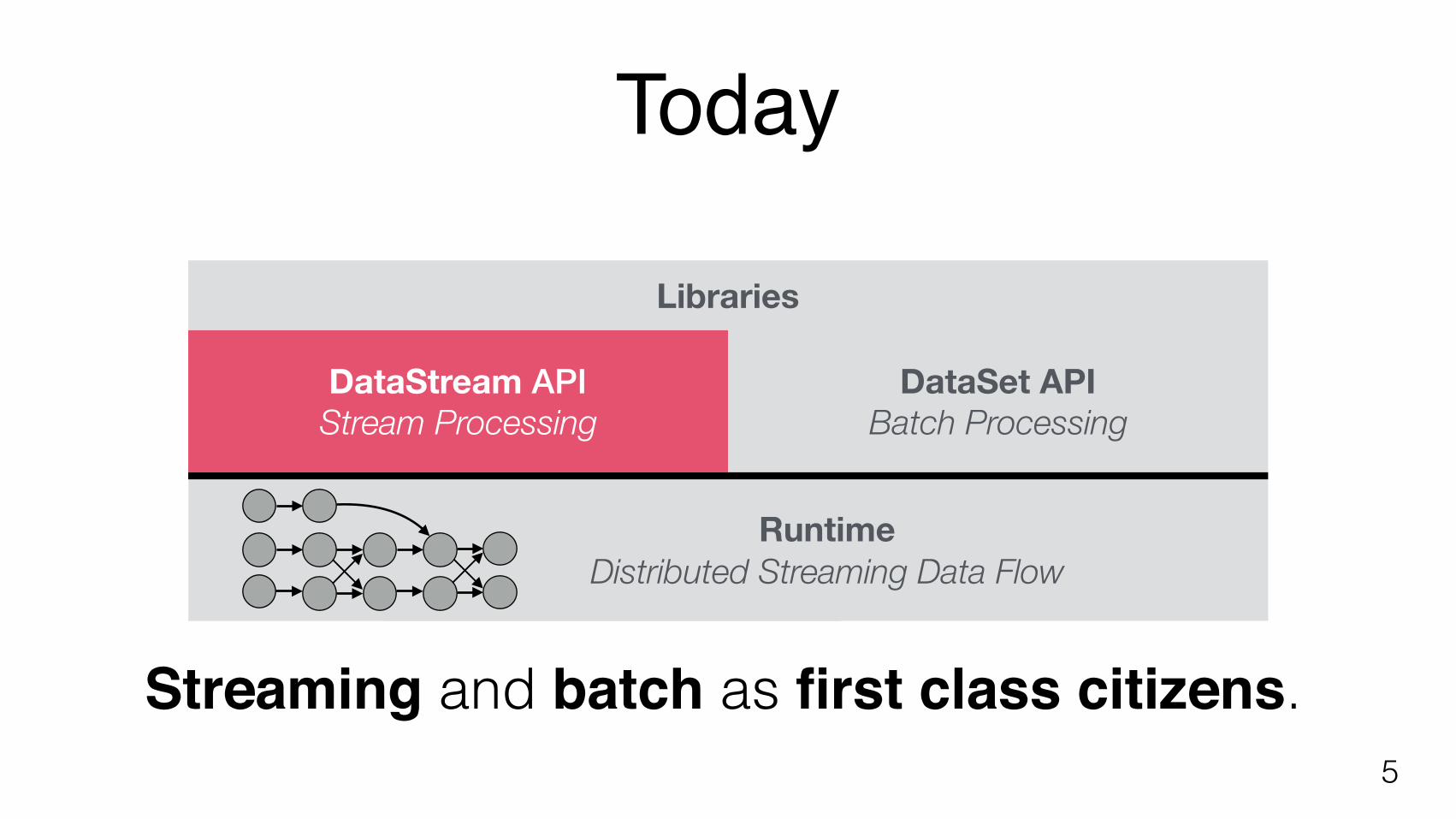
Today
5
DataStream API Stream Processing
DataSet API Batch Processing
Runtime Distributed Streaming Data Flow
Libraries
Streaming and batch as first class citizens.

Counting
6
Seemingly simple application: Count visitors, ad impressions, etc.
But generalizes well to other problems.

Batch Processing
7
All Input
Batch Job
All OutputHadoop, Spark, Flink

Batch Processing
8
DataSet<ColorEvent>counts=env.readFile("MM-dd.csv").groupBy("color").count();
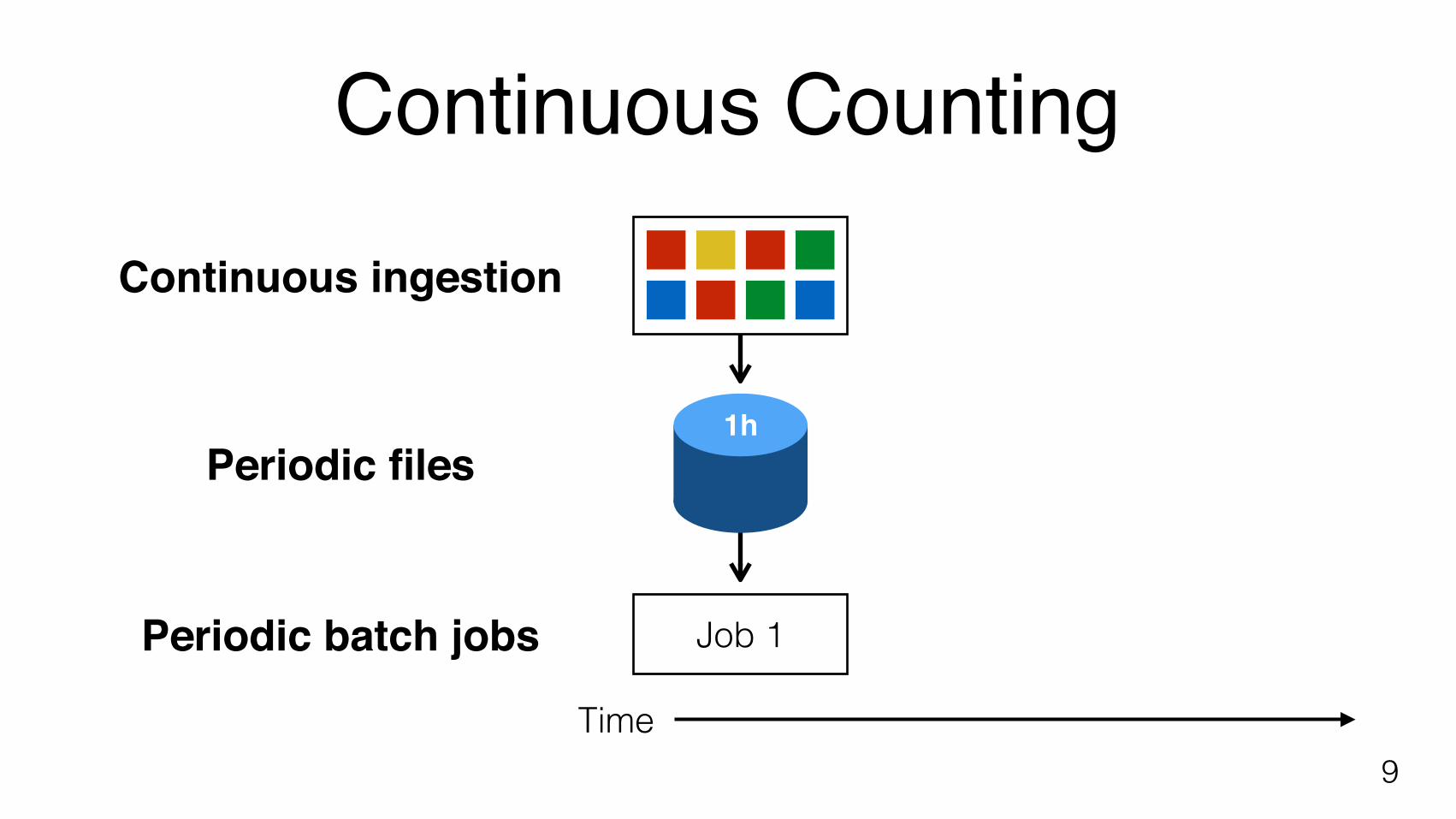
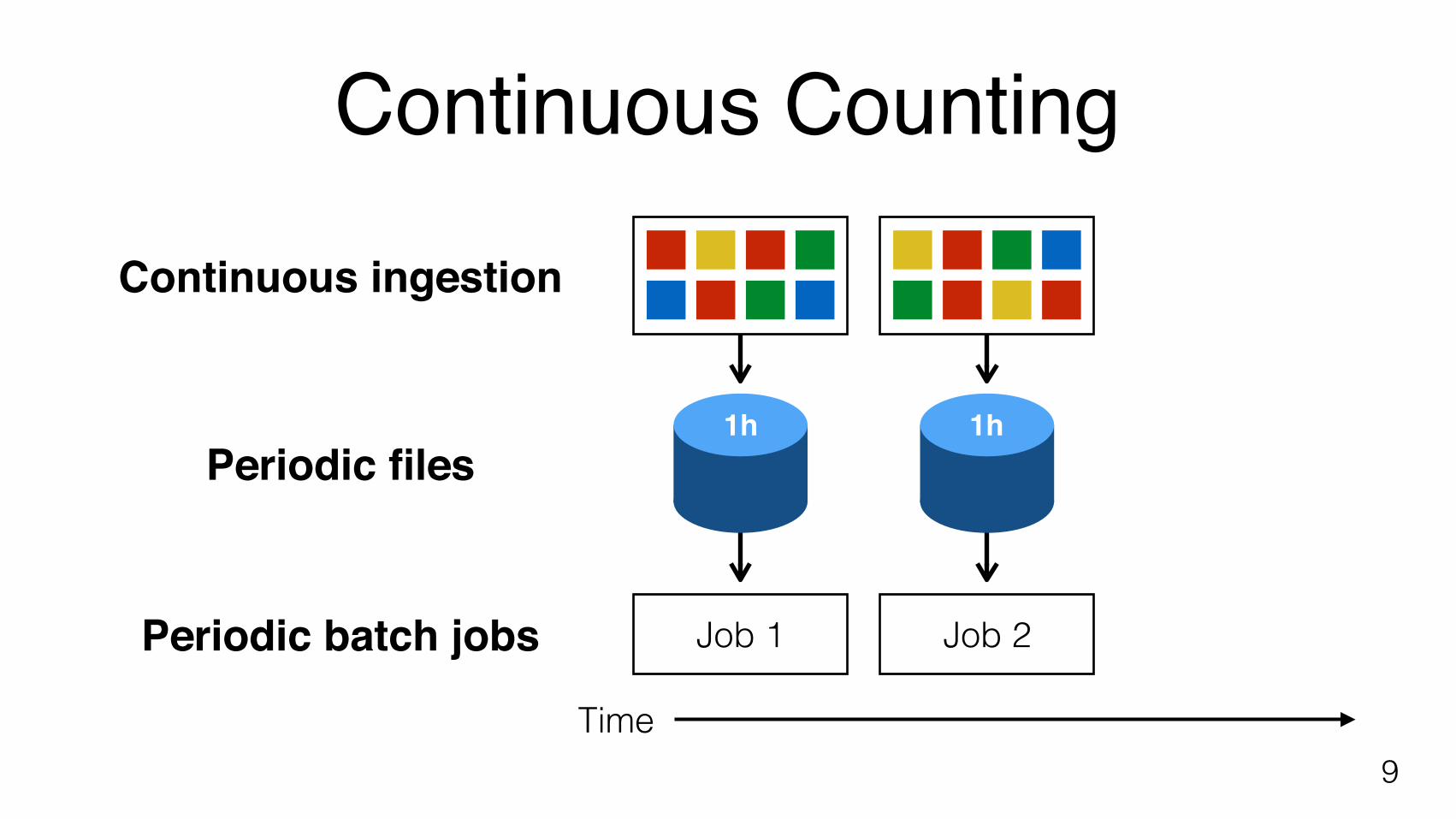
Continuous Counting
9Time
1h
Job 1
Continuous ingestion
Periodic files
Periodic batch jobs
Continuous Counting
9Time
1h
Job 1
Continuous ingestion
Periodic files
Periodic batch jobs
1h
Job 2
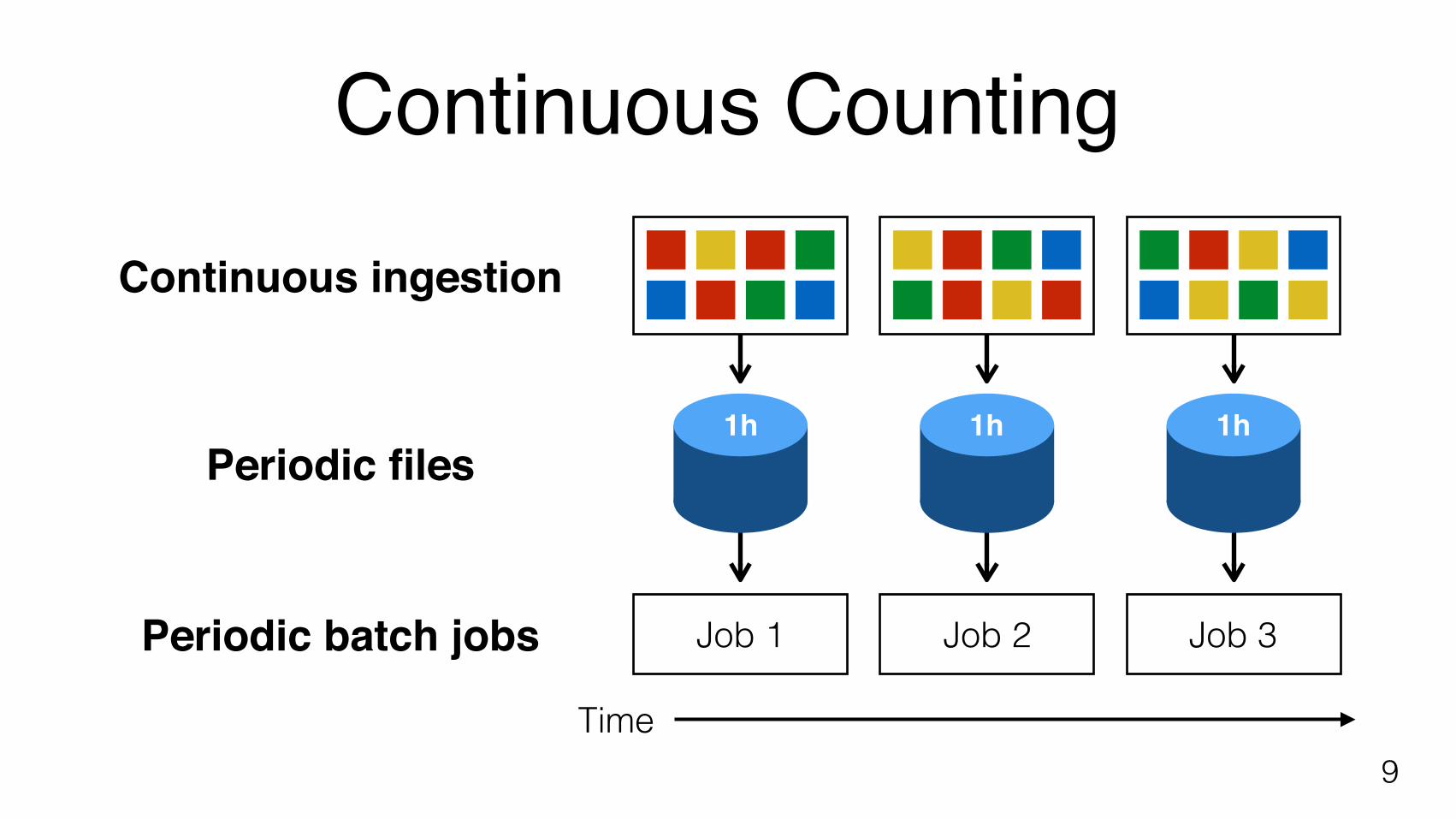
Continuous Counting
9Time
1h
Job 1
Continuous ingestion
Periodic files
Periodic batch jobs
1h
Job 2
1h
Job 3
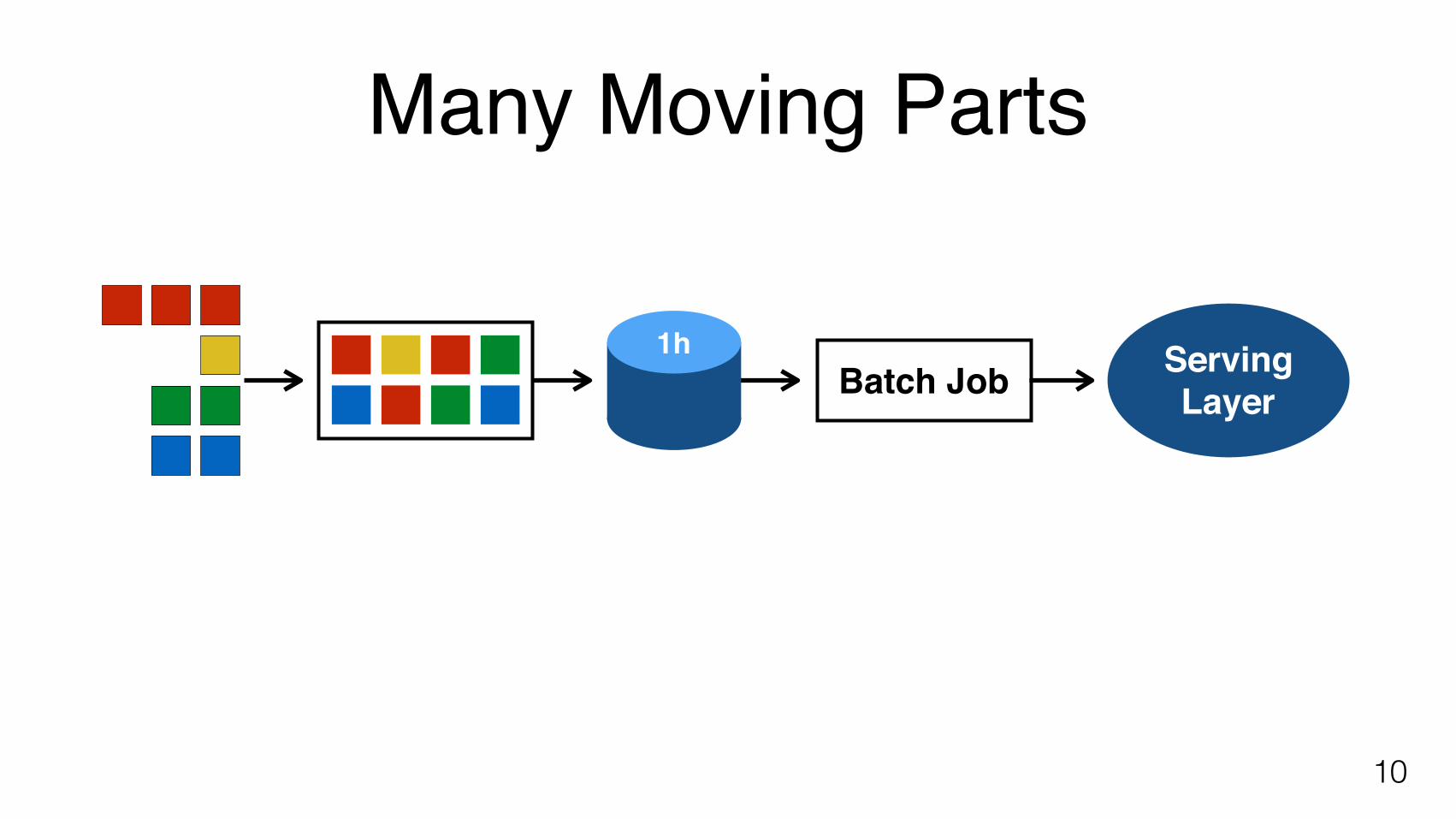
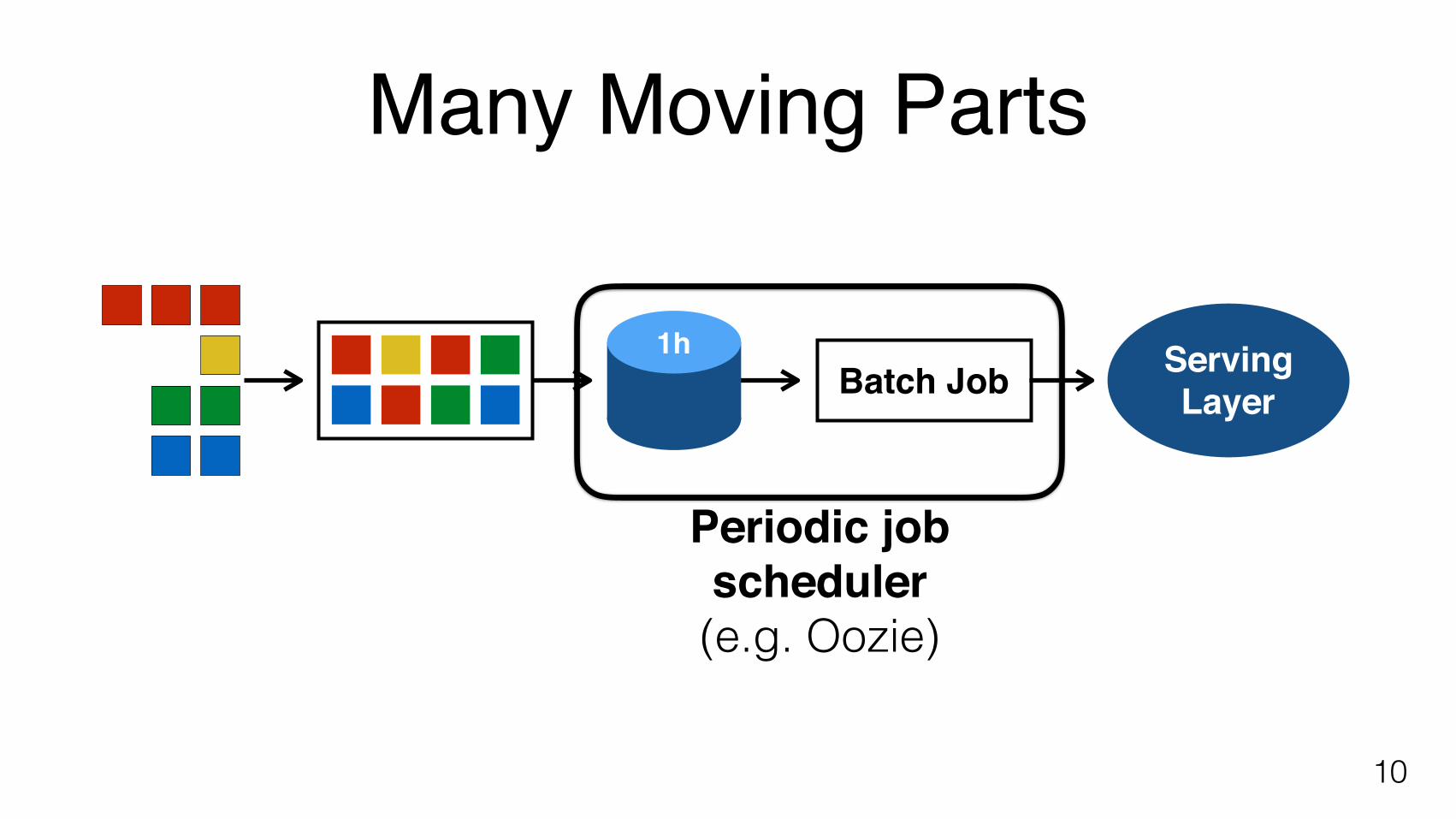
Many Moving Parts
10
Batch Job1h Serving
Layer
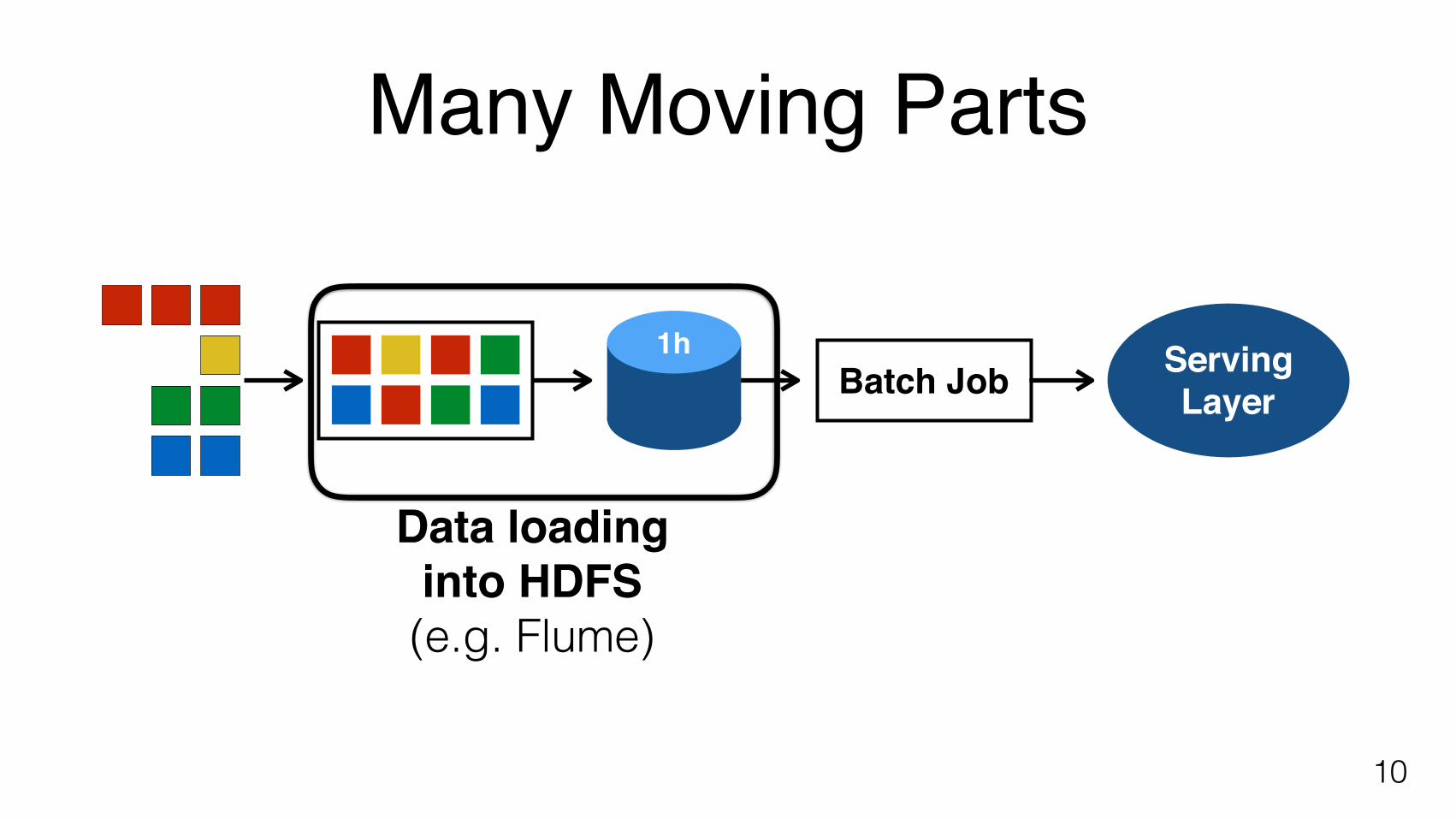
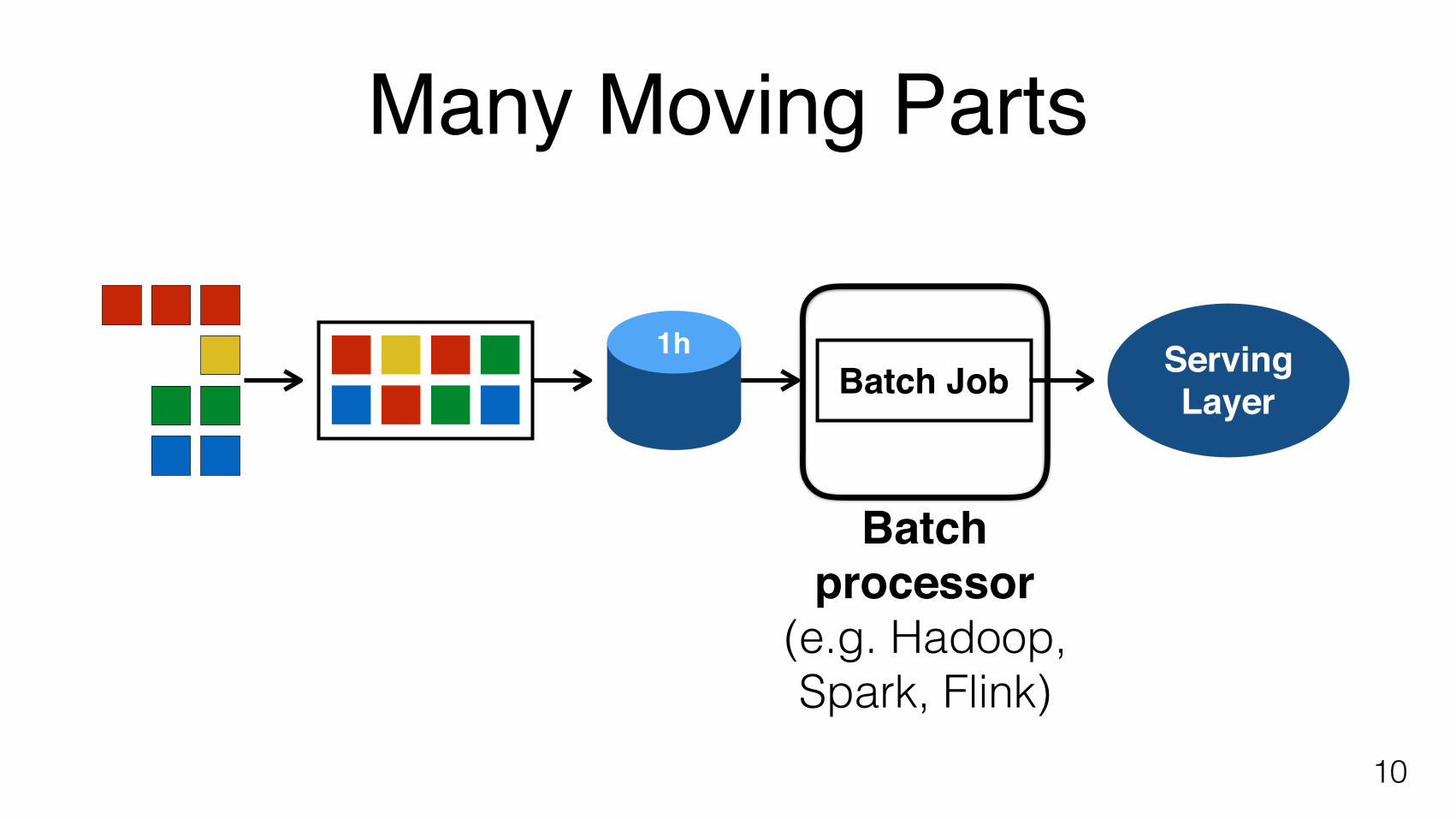
Many Moving Parts
10
Batch Job1h Serving
Layer
Data loadinginto HDFS(e.g. Flume)
Many Moving Parts
10
Batch Job1h Serving
Layer
Periodic jobscheduler(e.g. Oozie)
Many Moving Parts
10
Batch Job1h Serving
Layer
Batch processor
(e.g. Hadoop,Spark, Flink)
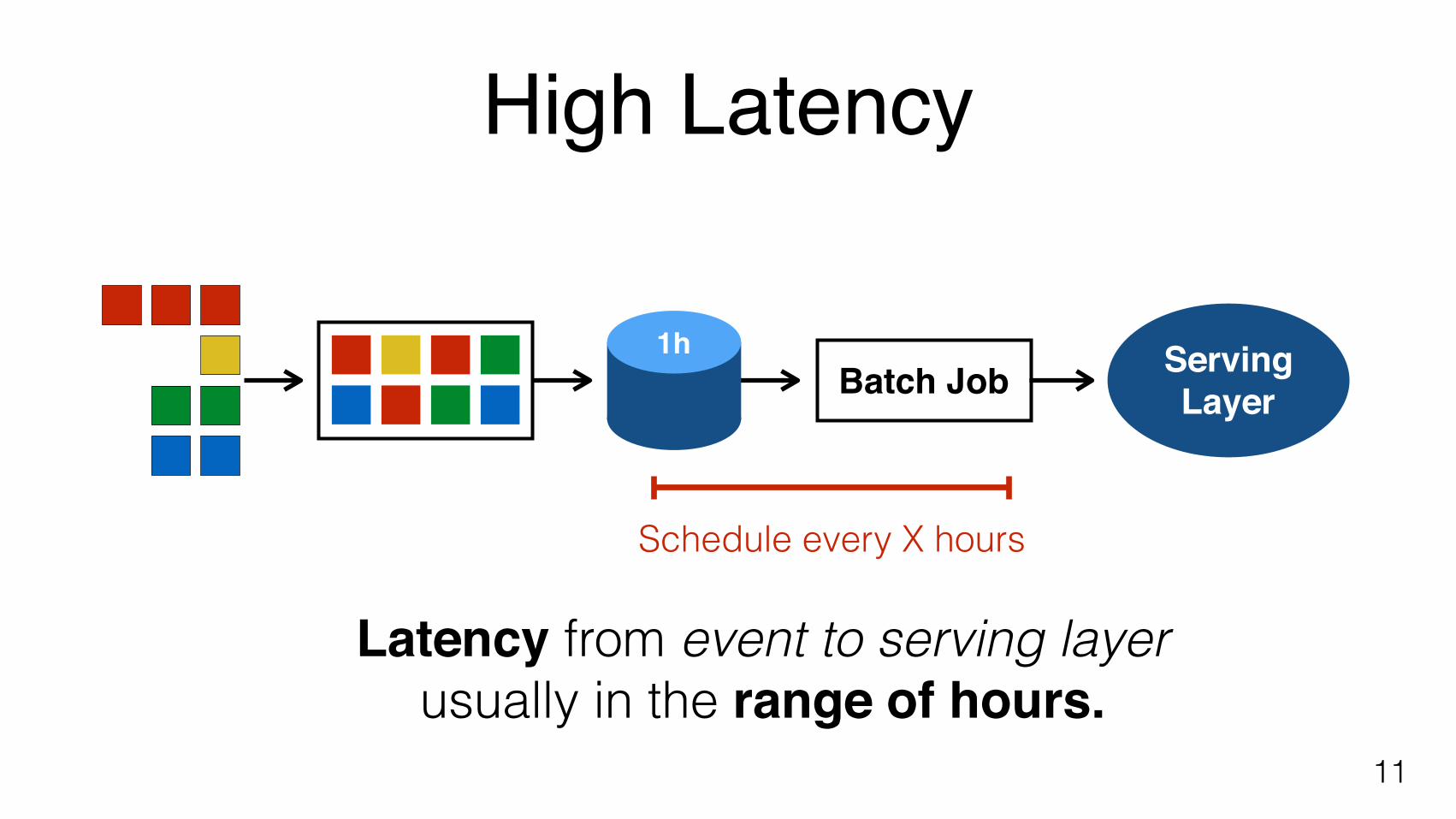
High Latency
11
Latency from event to serving layerusually in the range of hours.
Batch Job1h Serving
Layer
Schedule every X hours

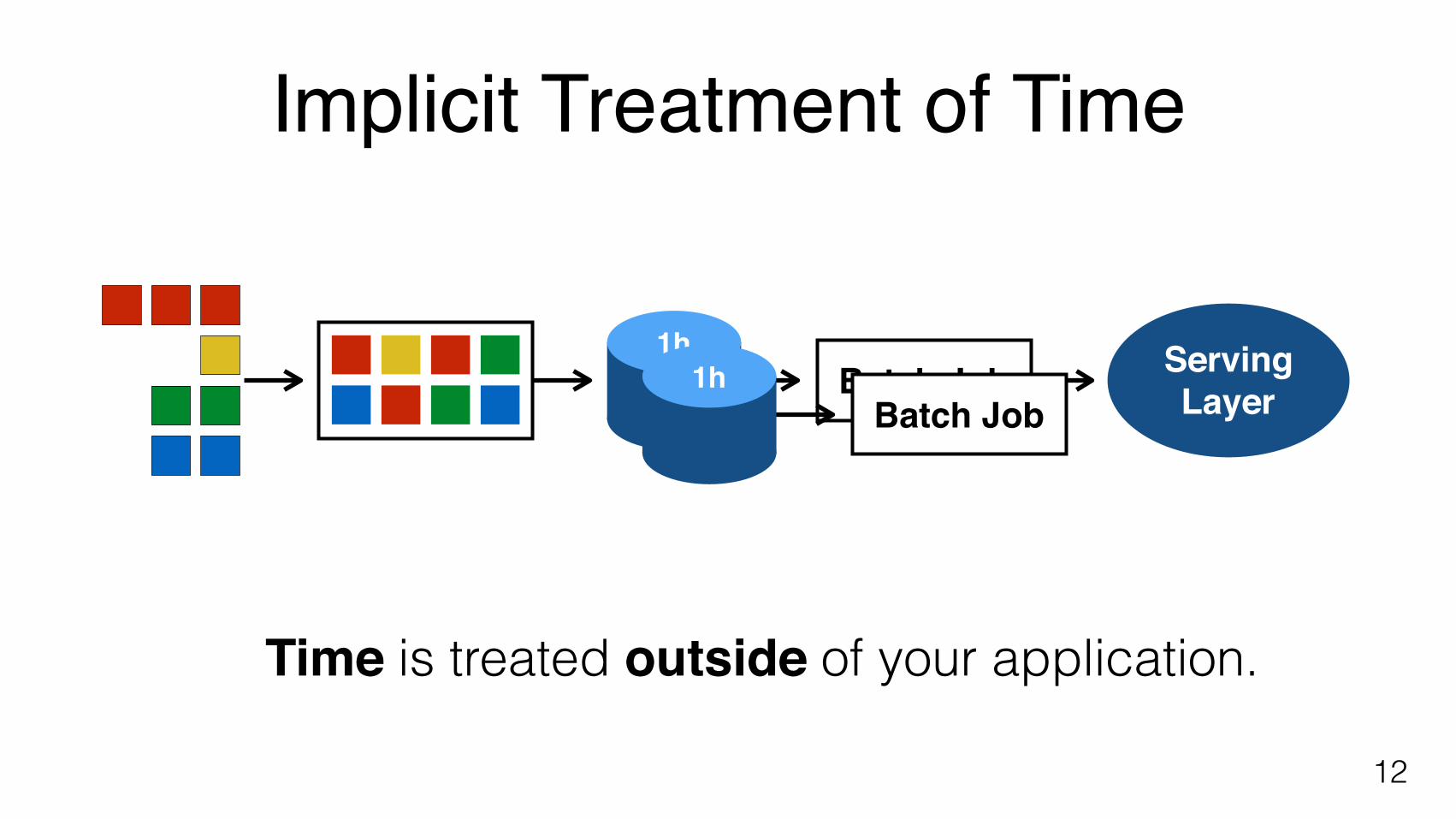
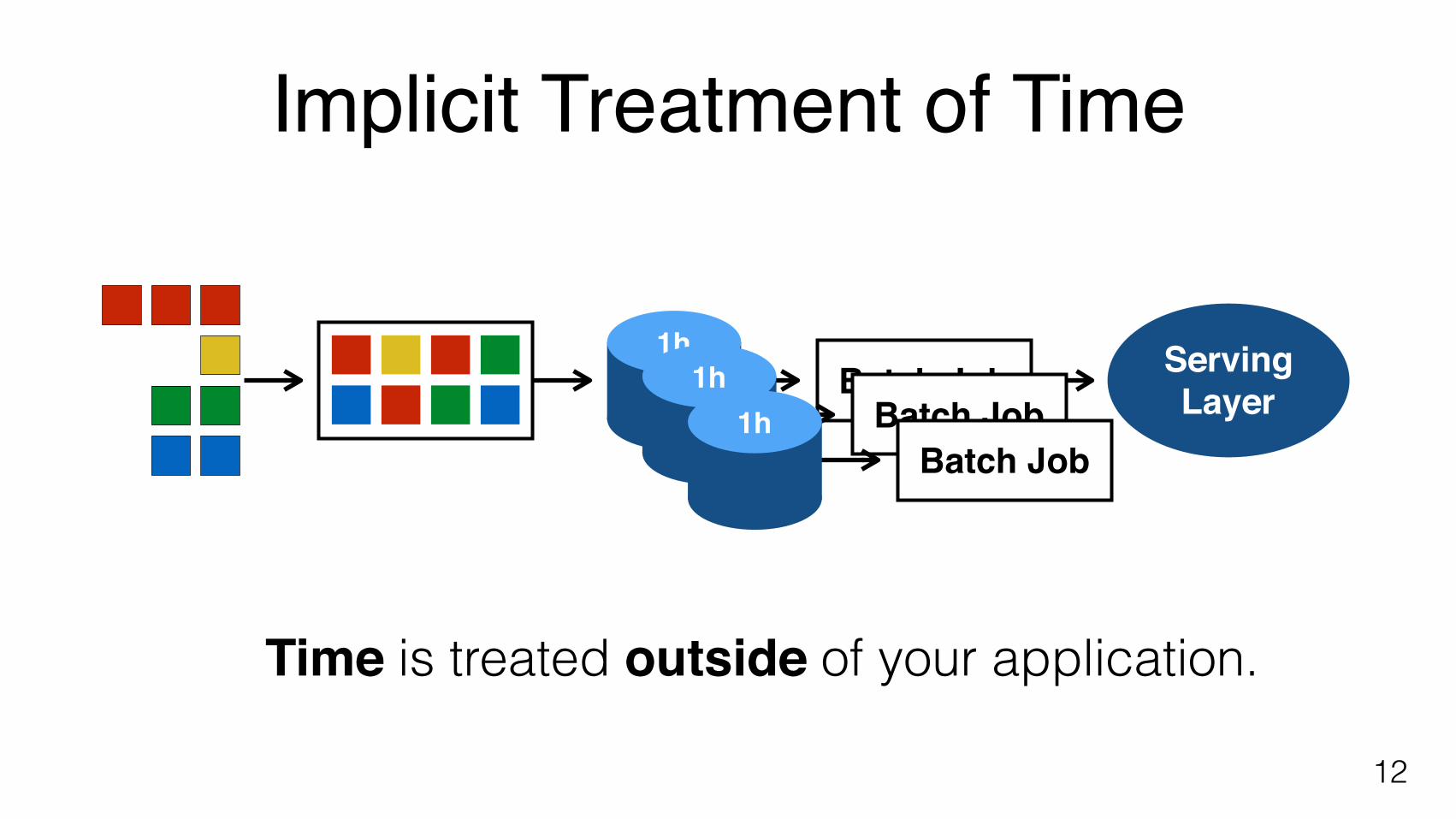
Implicit Treatment of Time
12
Time is treated outside of your application.
Batch Job1h Serving
Layer
Implicit Treatment of Time
12
Time is treated outside of your application.
Batch Job1h Serving
LayerBatch Job1h
Implicit Treatment of Time
12
Time is treated outside of your application.
Batch Job1h Serving
LayerBatch Job1h
Batch Job1h

Implicit Treatment of Time
13
DataSet<ColorEvent>counts=env.readFile("MM-dd.csv").groupBy("color").count();
Time is implicit in input file
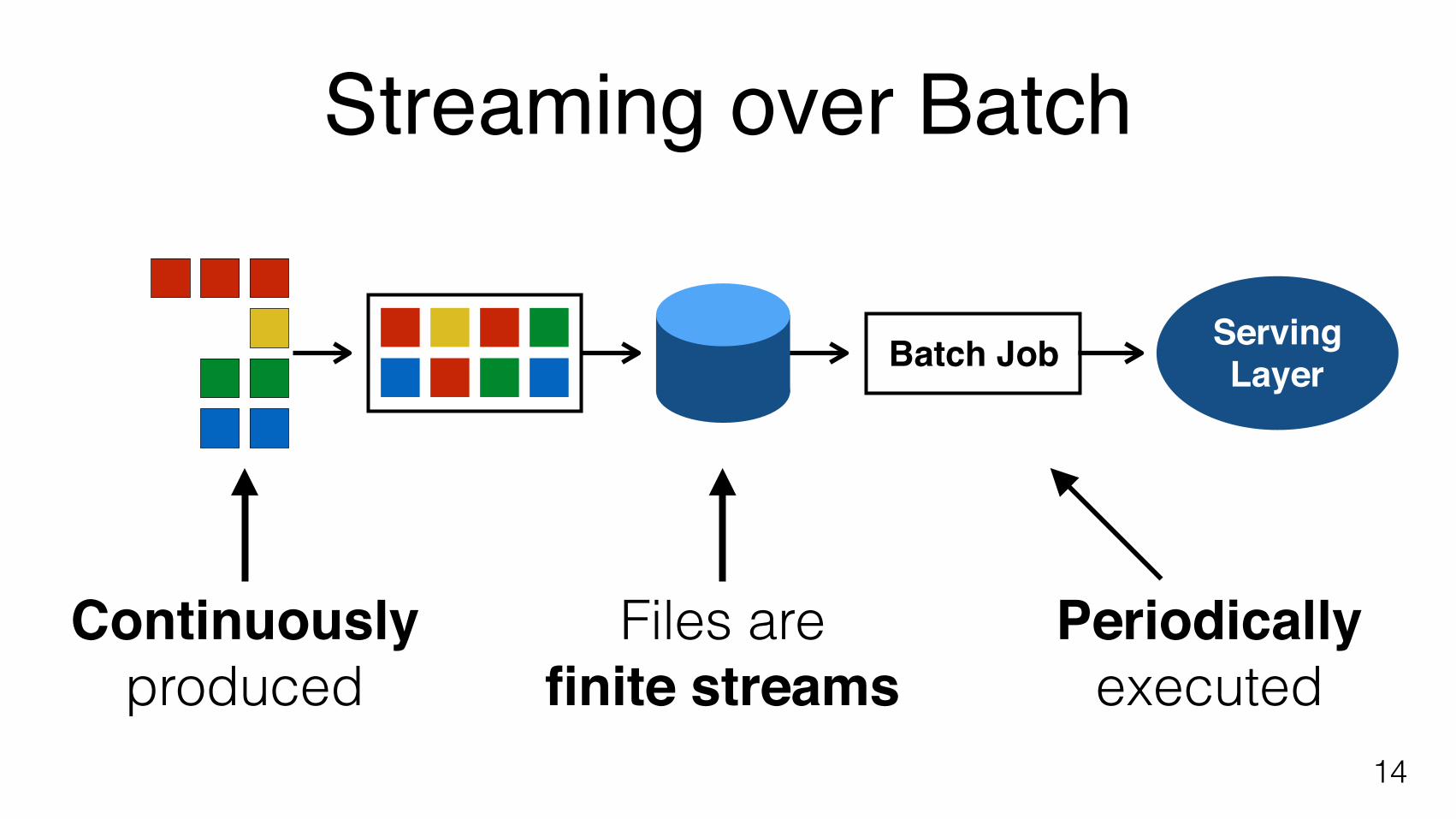
Batch Job ServingLayer
Continuouslyproduced
Files are finite streams
Periodicallyexecuted
Streaming over Batch
14

Streaming
15
Until now, stream processors were less maturethan their batch counterparts. This led to:
• in-house solutions, • abuse of batch processors, • Lambda architectures
This is no longer needed with new generation stream processors like Flink.
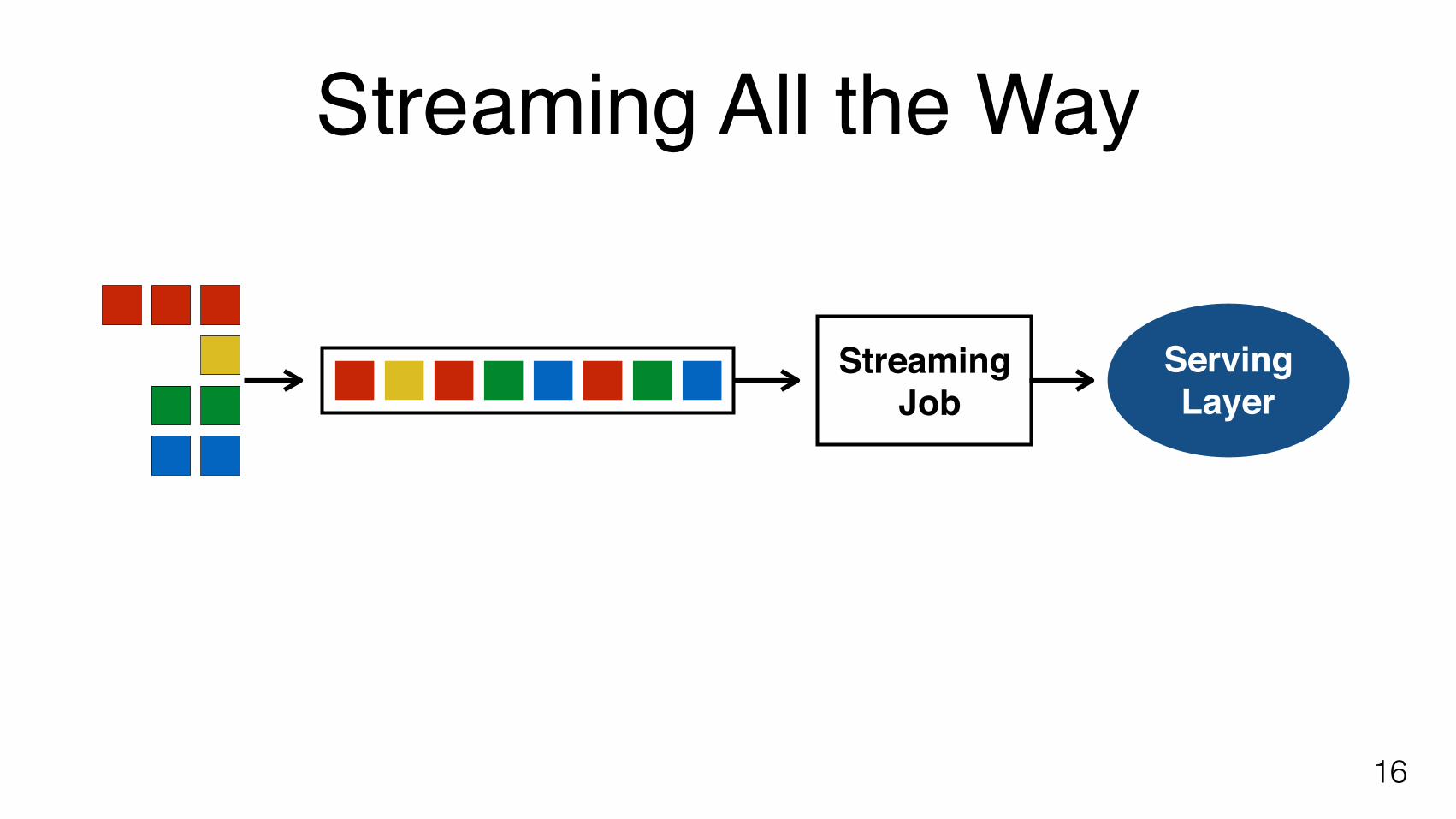
Streaming All the Way
16
Streaming Job
ServingLayer
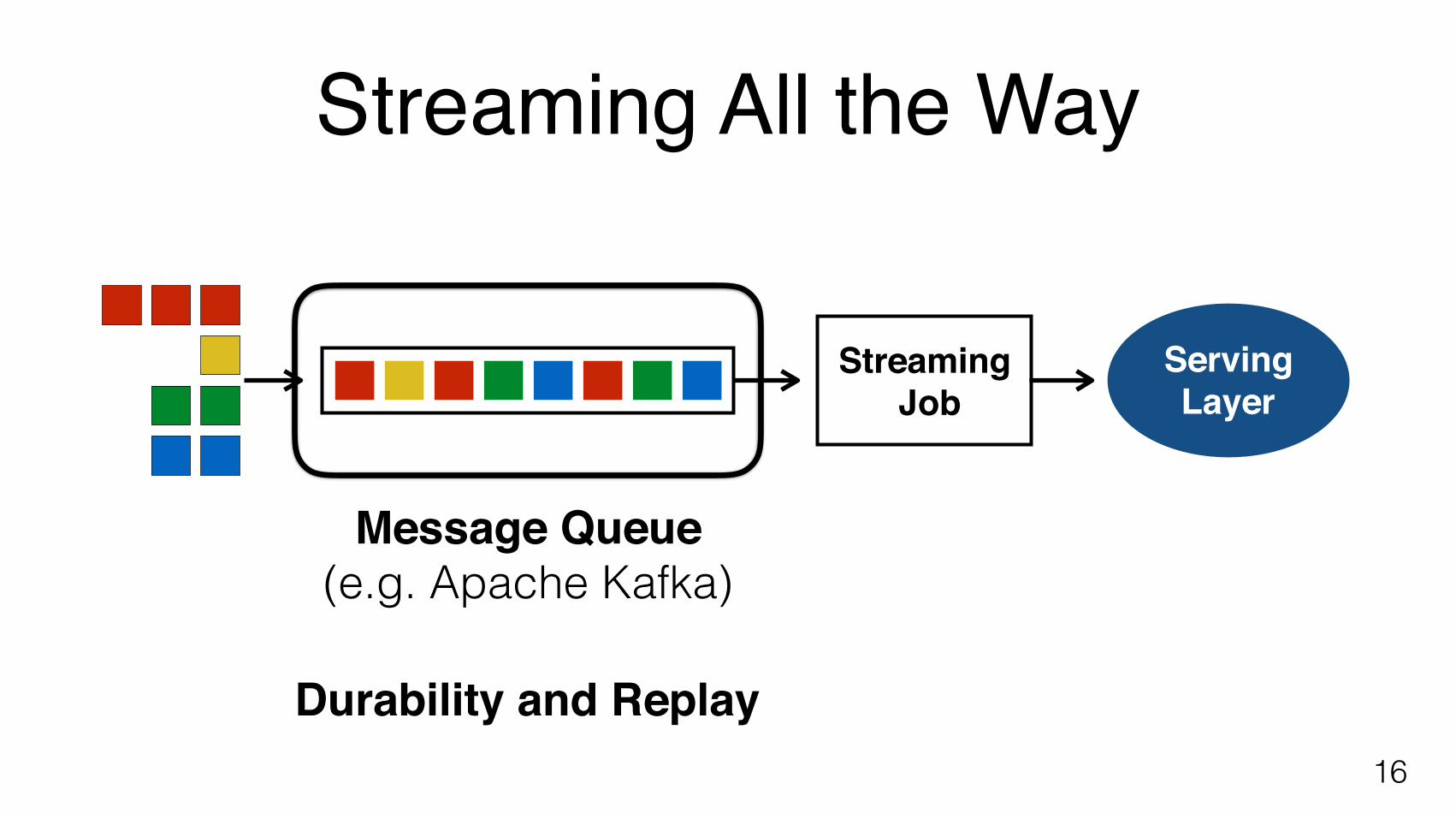
Streaming All the Way
16
Streaming Job
ServingLayer
Message Queue (e.g. Apache Kafka)
Durability and Replay
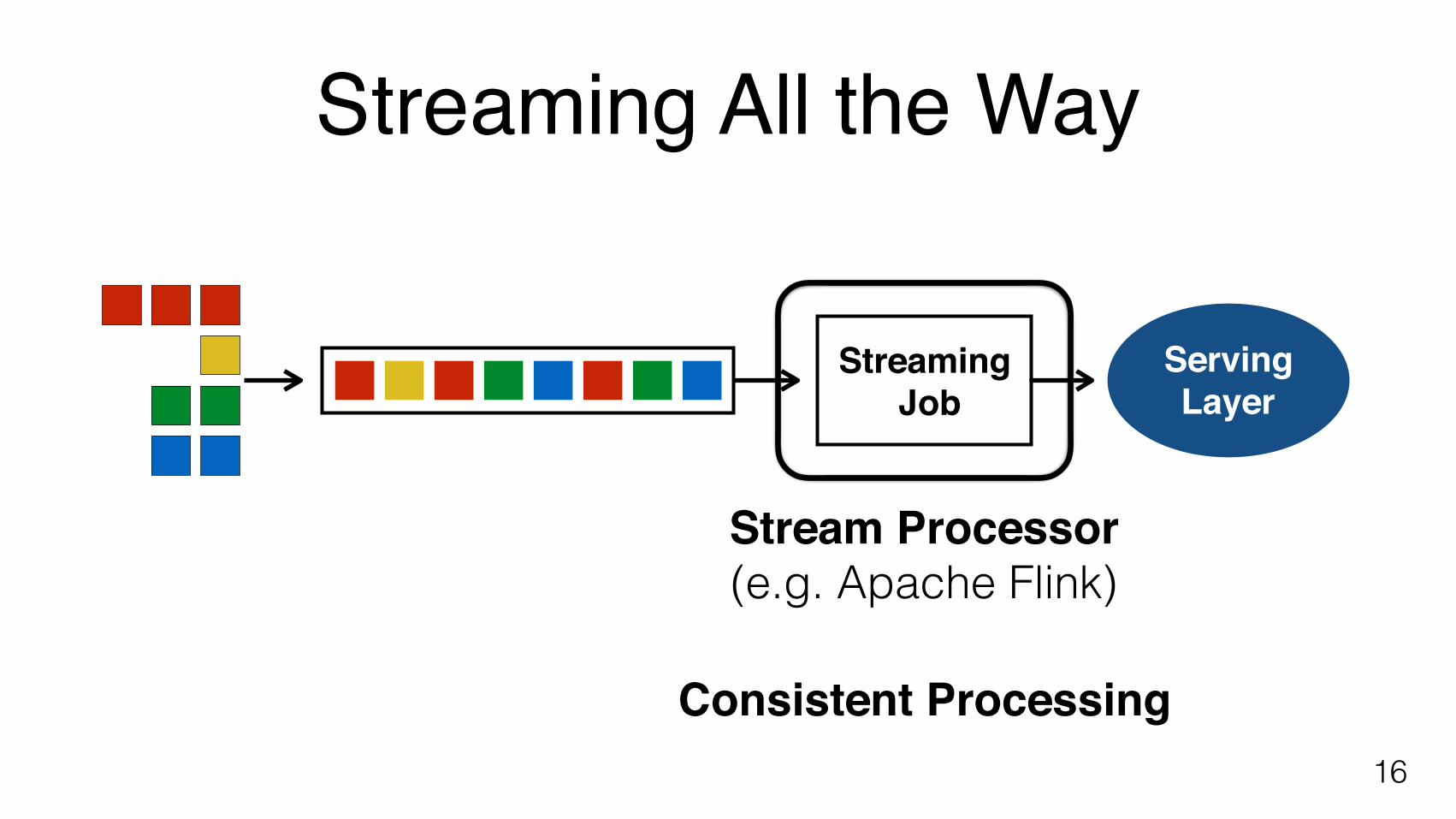
Streaming All the Way
16
Streaming Job
ServingLayer
Stream Processor (e.g. Apache Flink)
Consistent Processing
Building Blocks of Flink
17
Explicit Handling of Time
State & Fault Tolerance
Performance
Building Blocks of Flink
17
Explicit Handling of Time
State & Fault Tolerance
Performance
Explicit Handlingof Time
Windowing
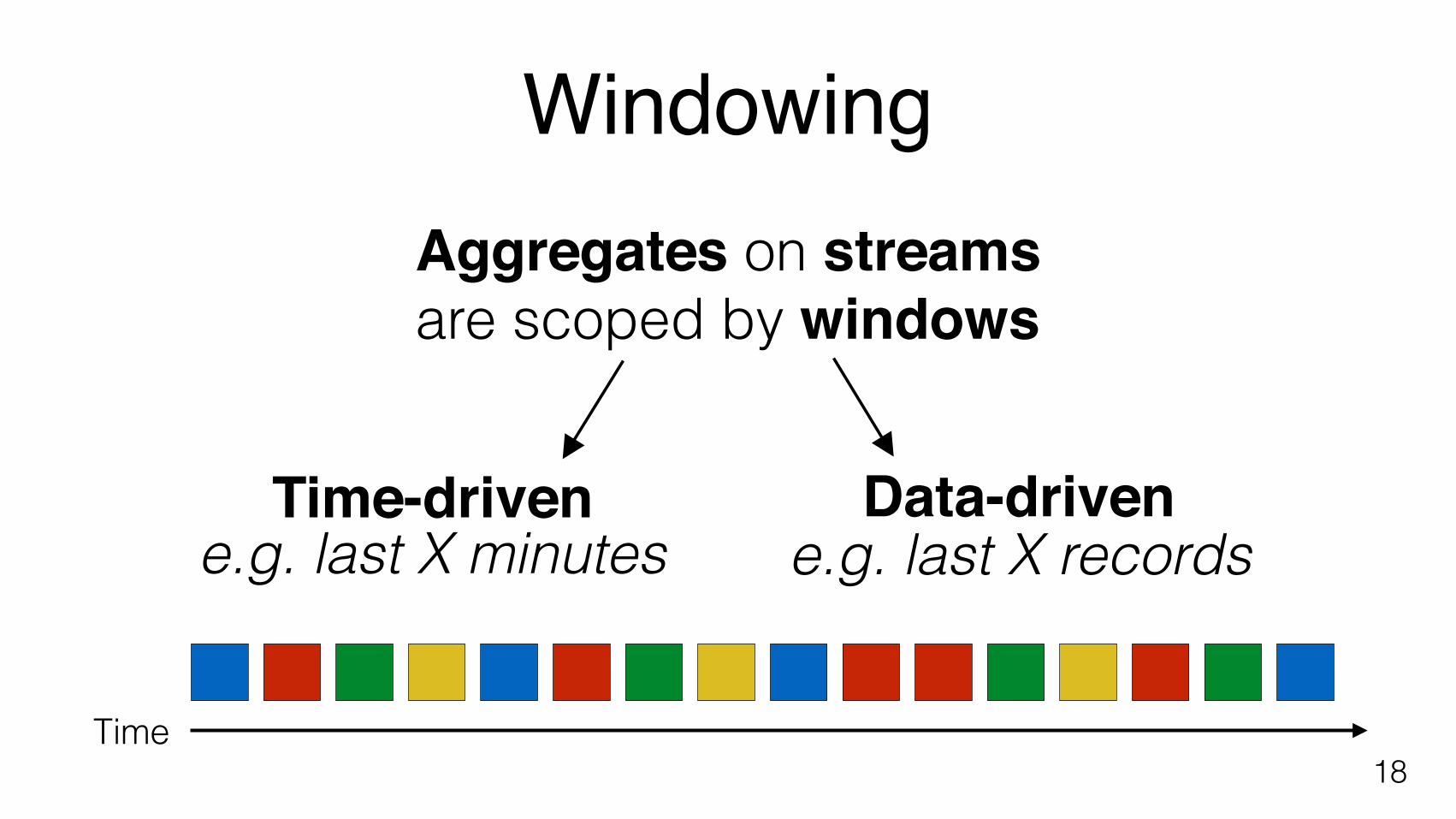
18Time
Aggregates on streamsare scoped by windows
Time-driven Data-drivene.g. last X minutes e.g. last X records
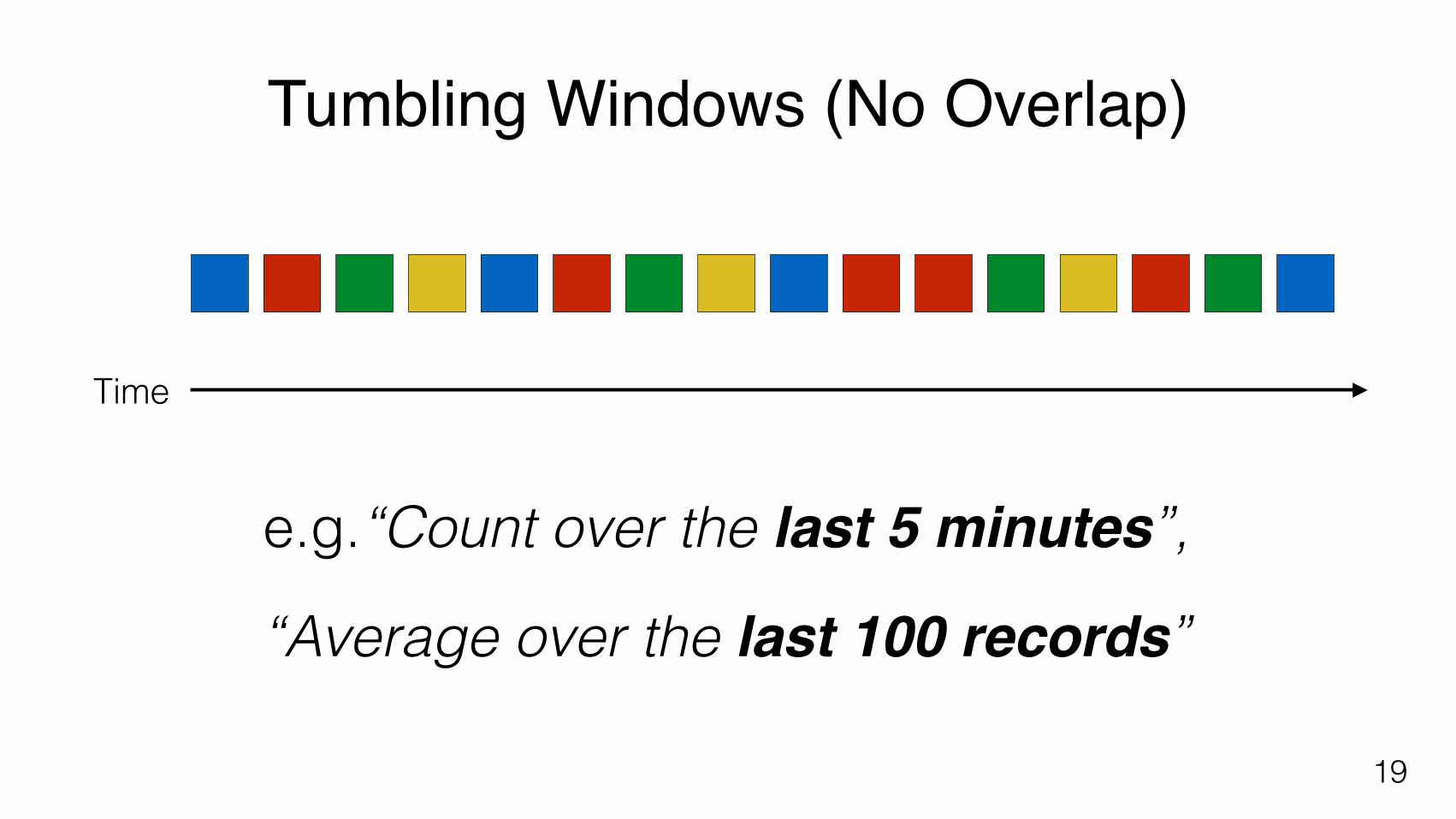
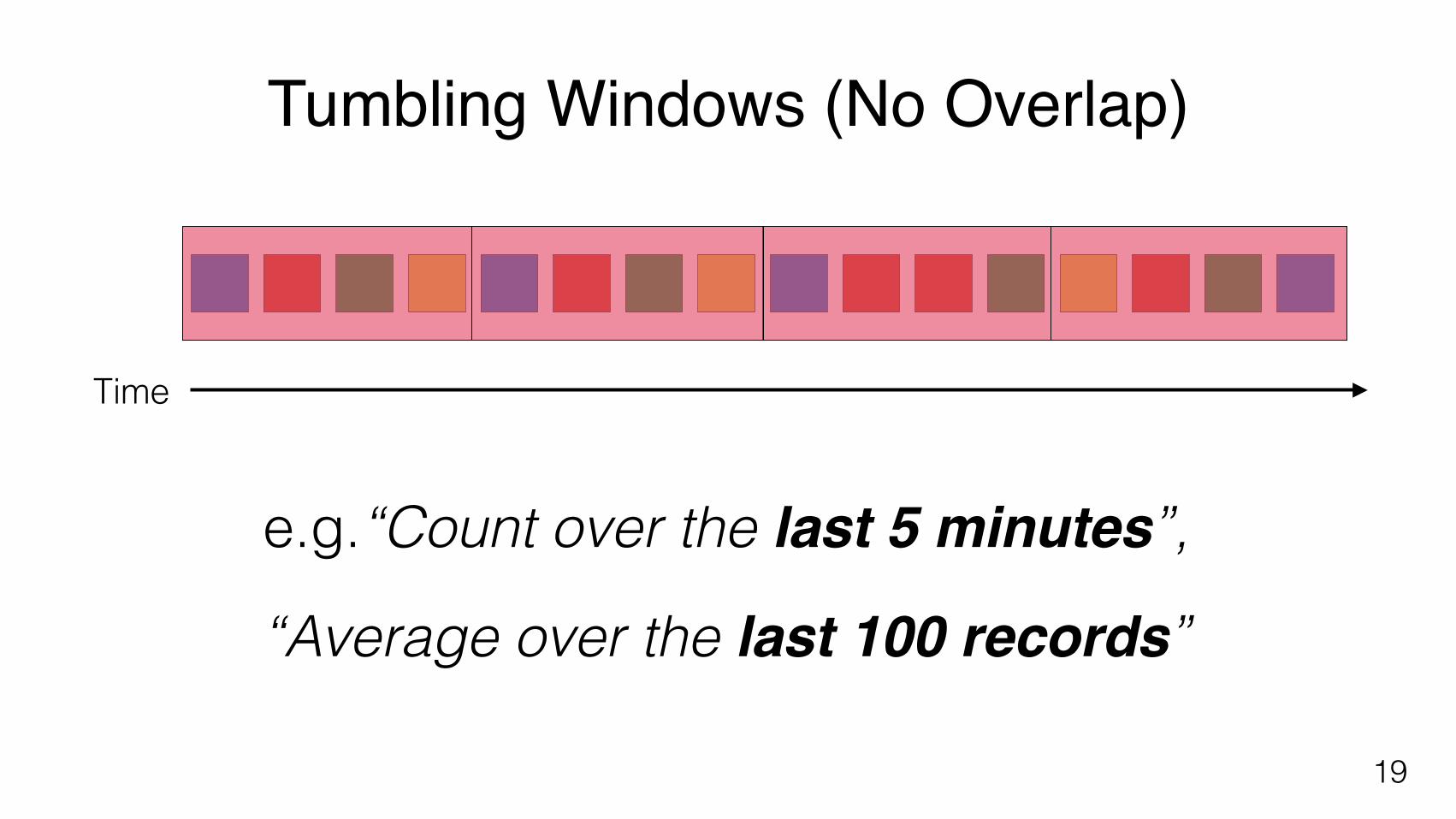
Tumbling Windows (No Overlap)
19
Time
e.g.“Count over the last 5 minutes”,
“Average over the last 100 records”
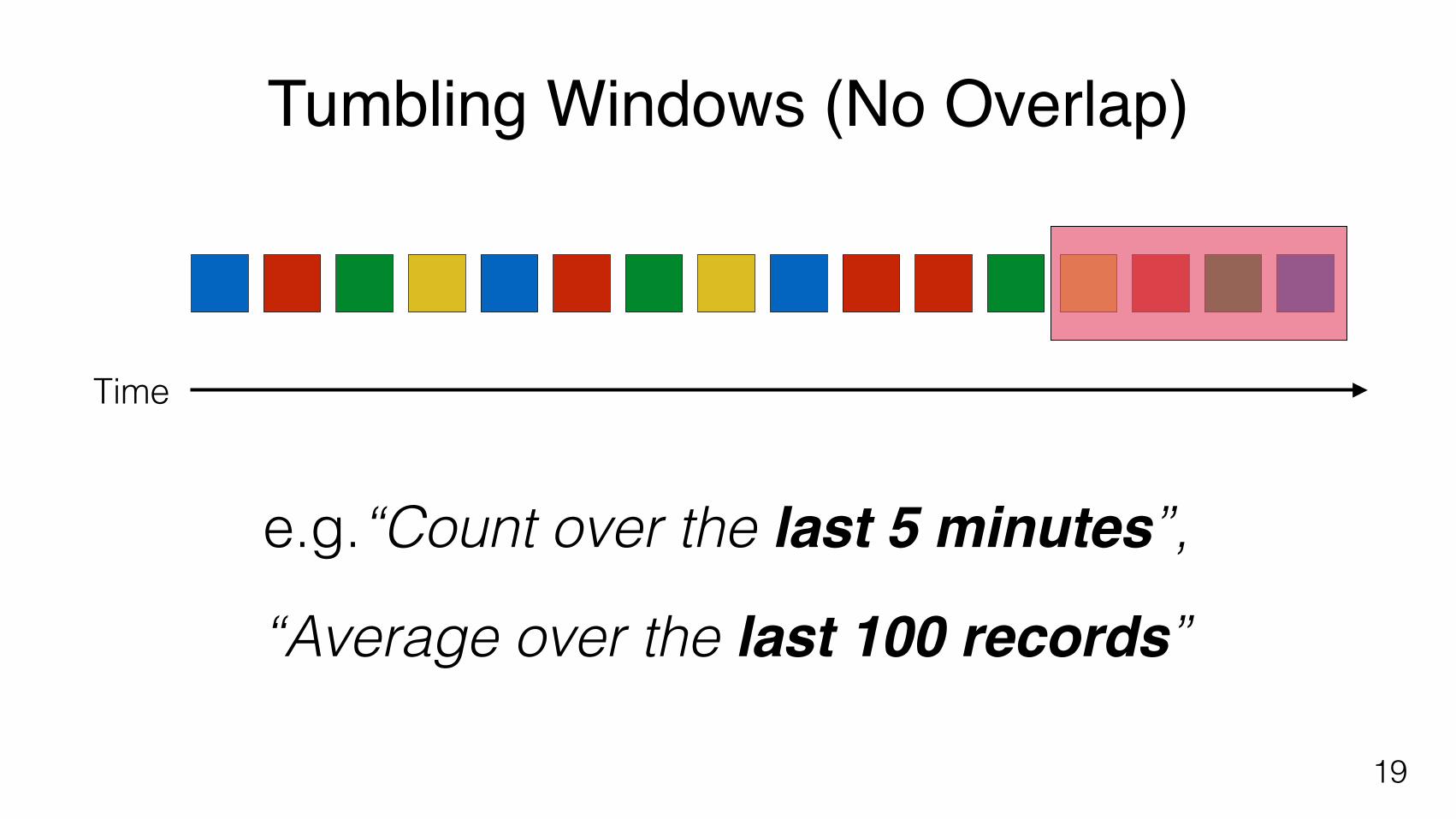
Tumbling Windows (No Overlap)
19
Time
e.g.“Count over the last 5 minutes”,
“Average over the last 100 records”
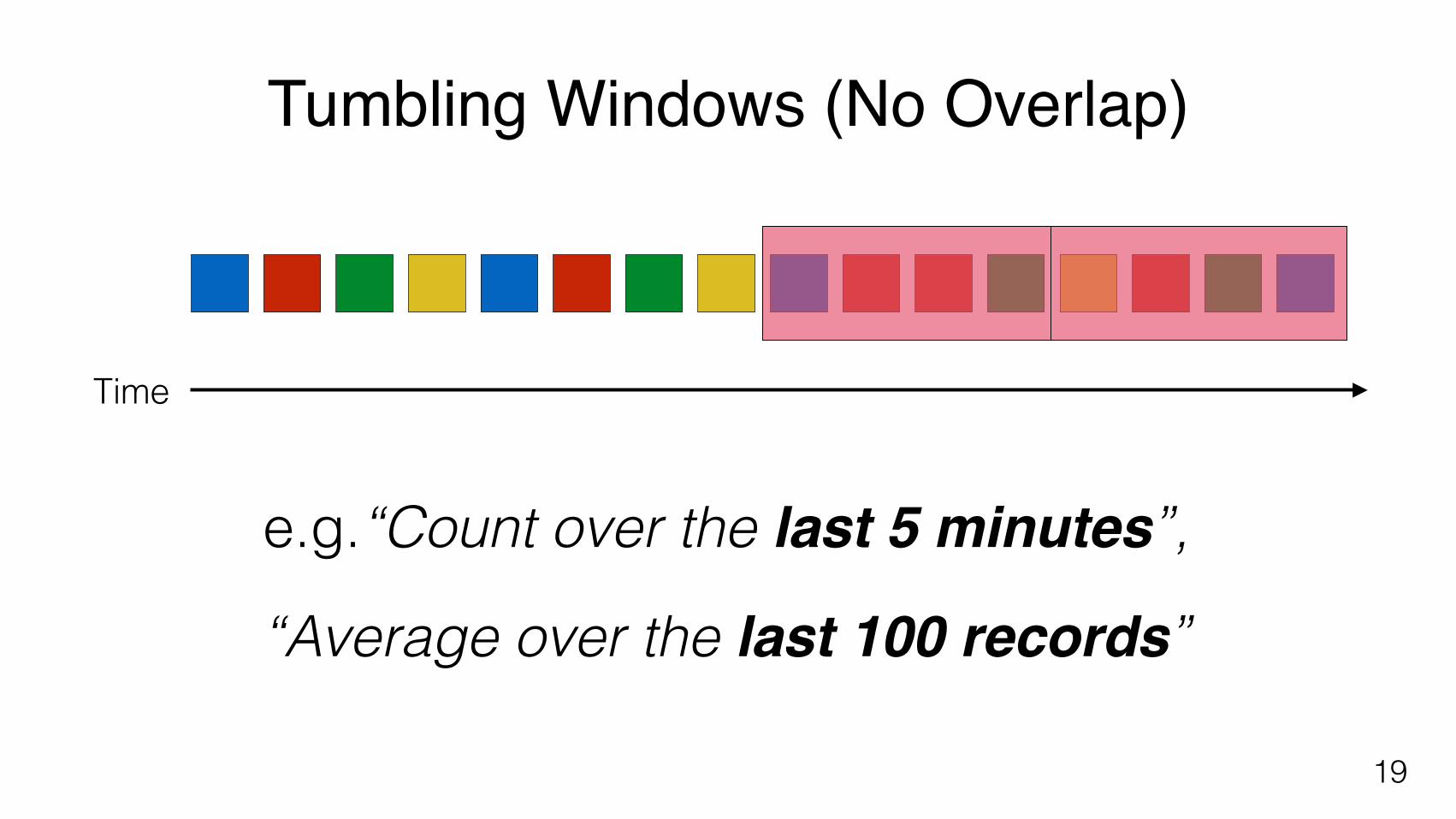
Tumbling Windows (No Overlap)
19
Time
e.g.“Count over the last 5 minutes”,
“Average over the last 100 records”
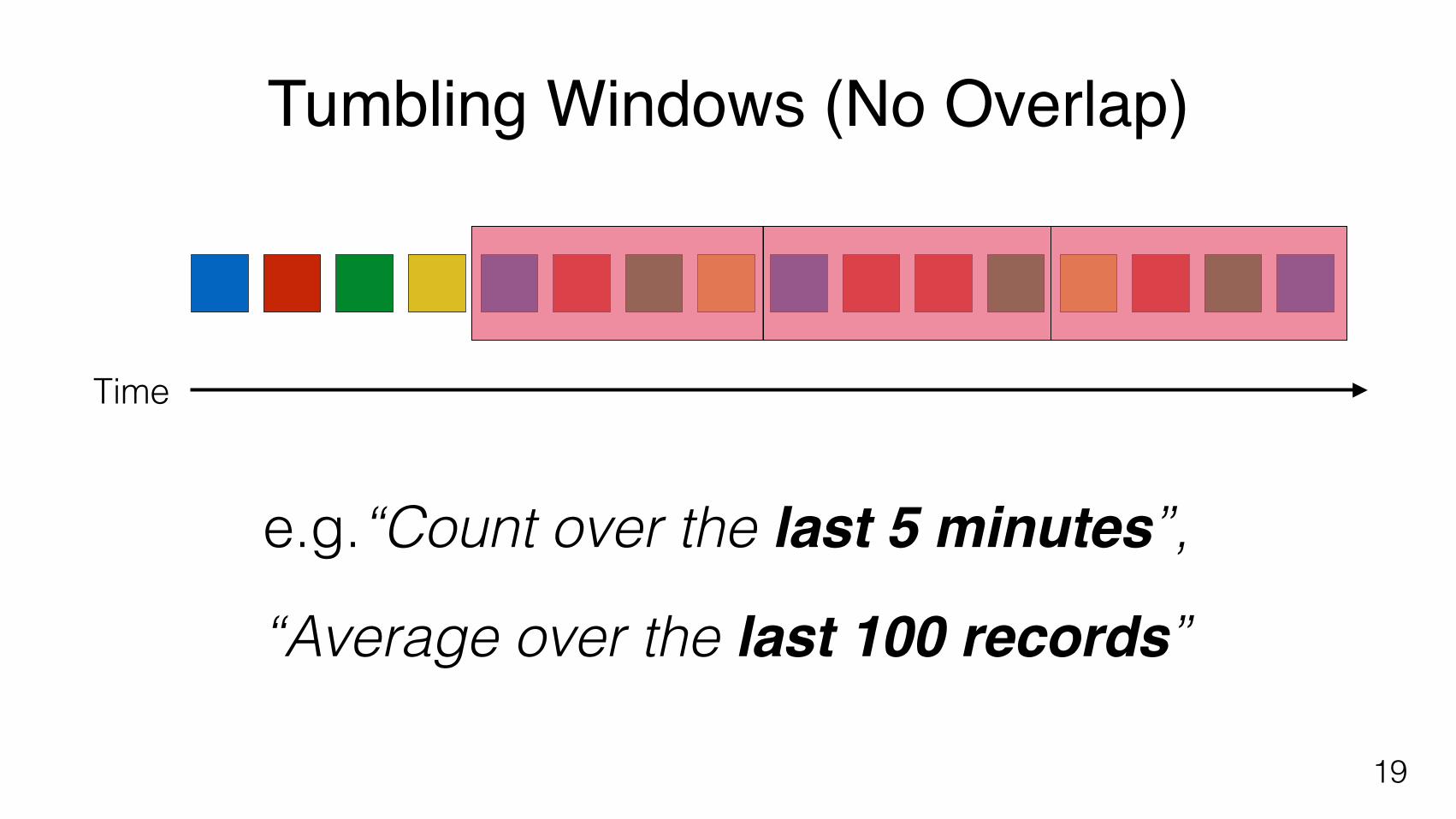
Tumbling Windows (No Overlap)
19
Time
e.g.“Count over the last 5 minutes”,
“Average over the last 100 records”
Tumbling Windows (No Overlap)
19
Time
e.g.“Count over the last 5 minutes”,
“Average over the last 100 records”
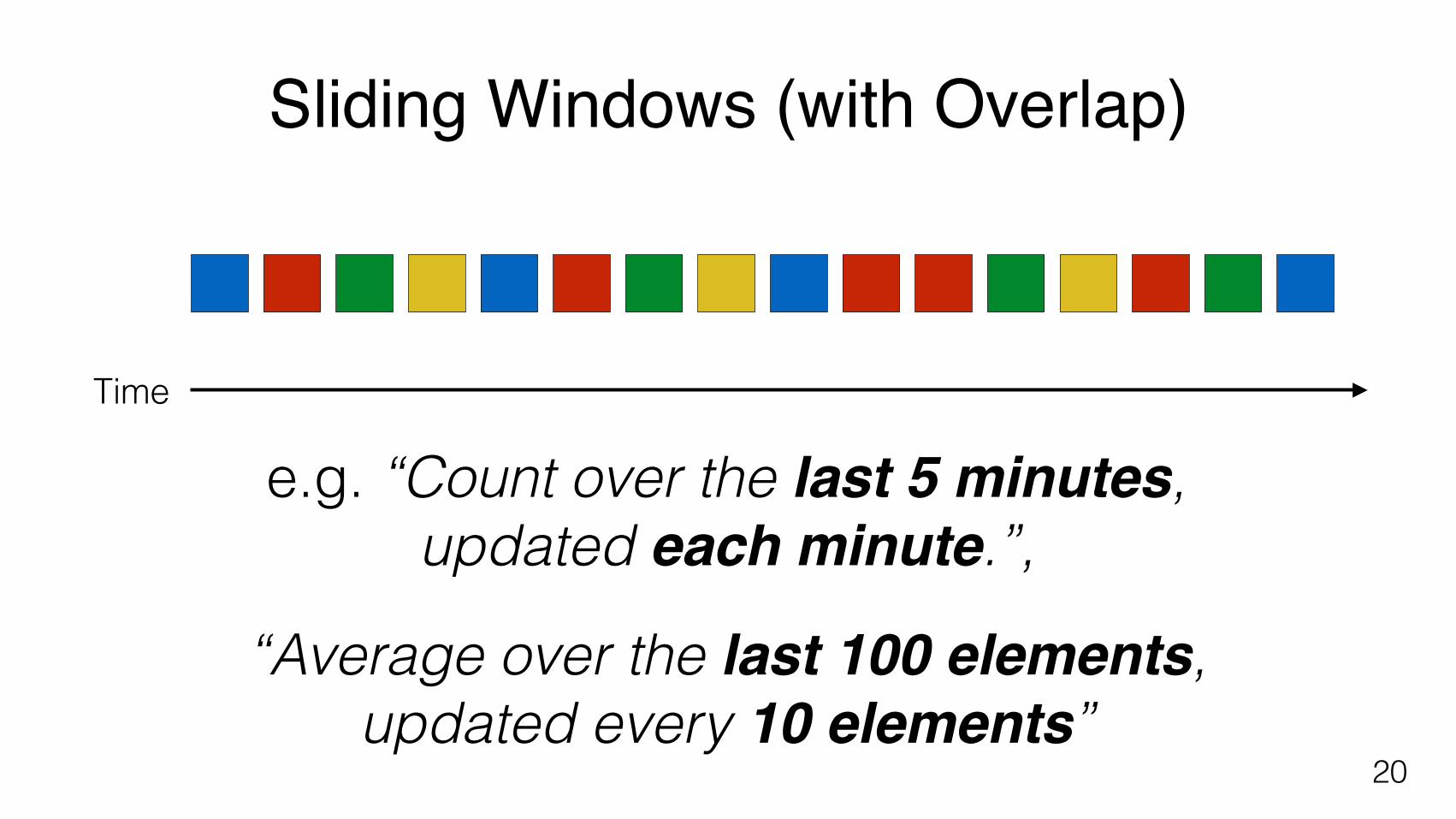
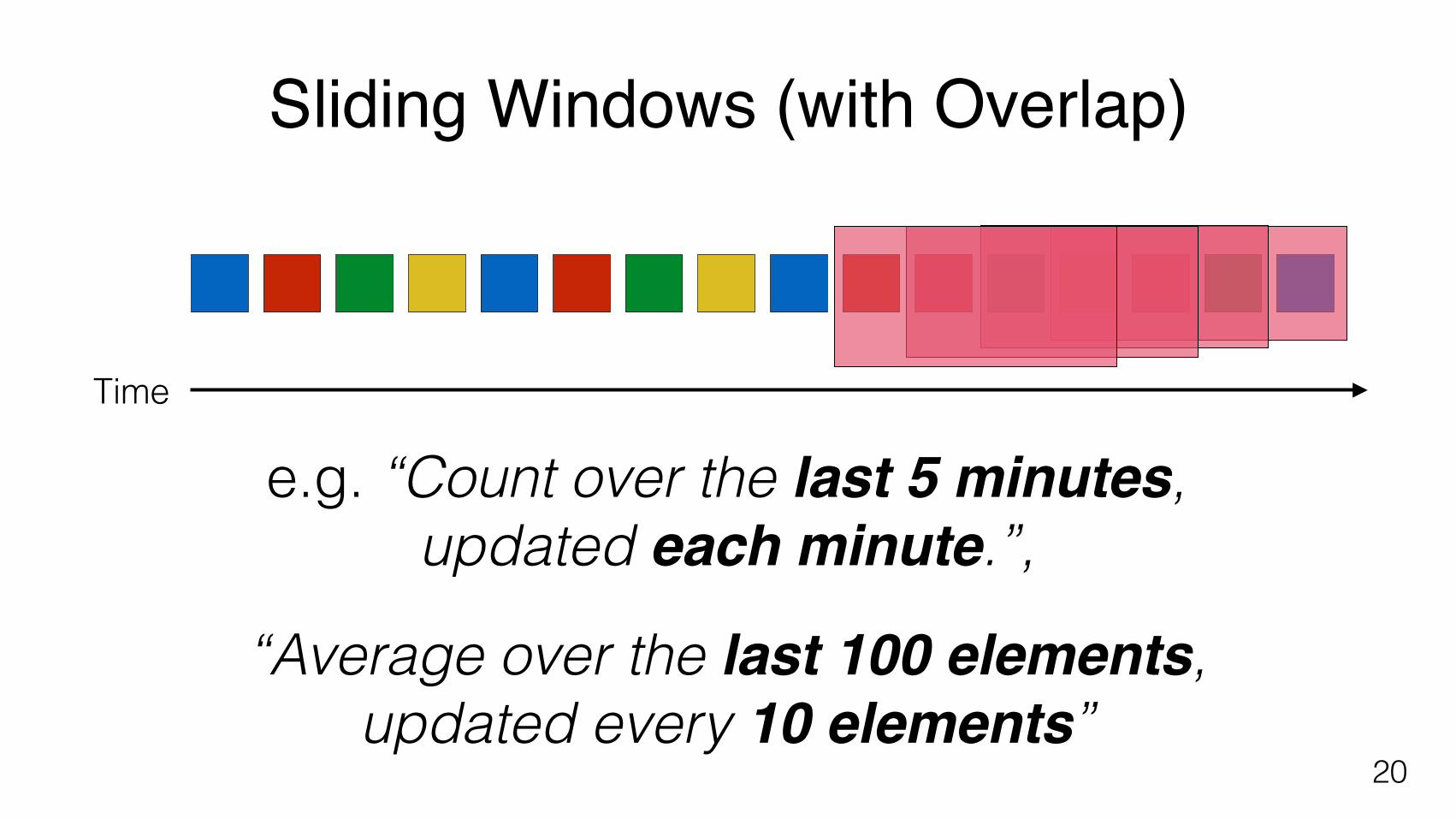
Sliding Windows (with Overlap)
20
Time
e.g. “Count over the last 5 minutes, updated each minute.”,
“Average over the last 100 elements, updated every 10 elements”

Sliding Windows (with Overlap)
20
Time
e.g. “Count over the last 5 minutes, updated each minute.”,
“Average over the last 100 elements, updated every 10 elements”
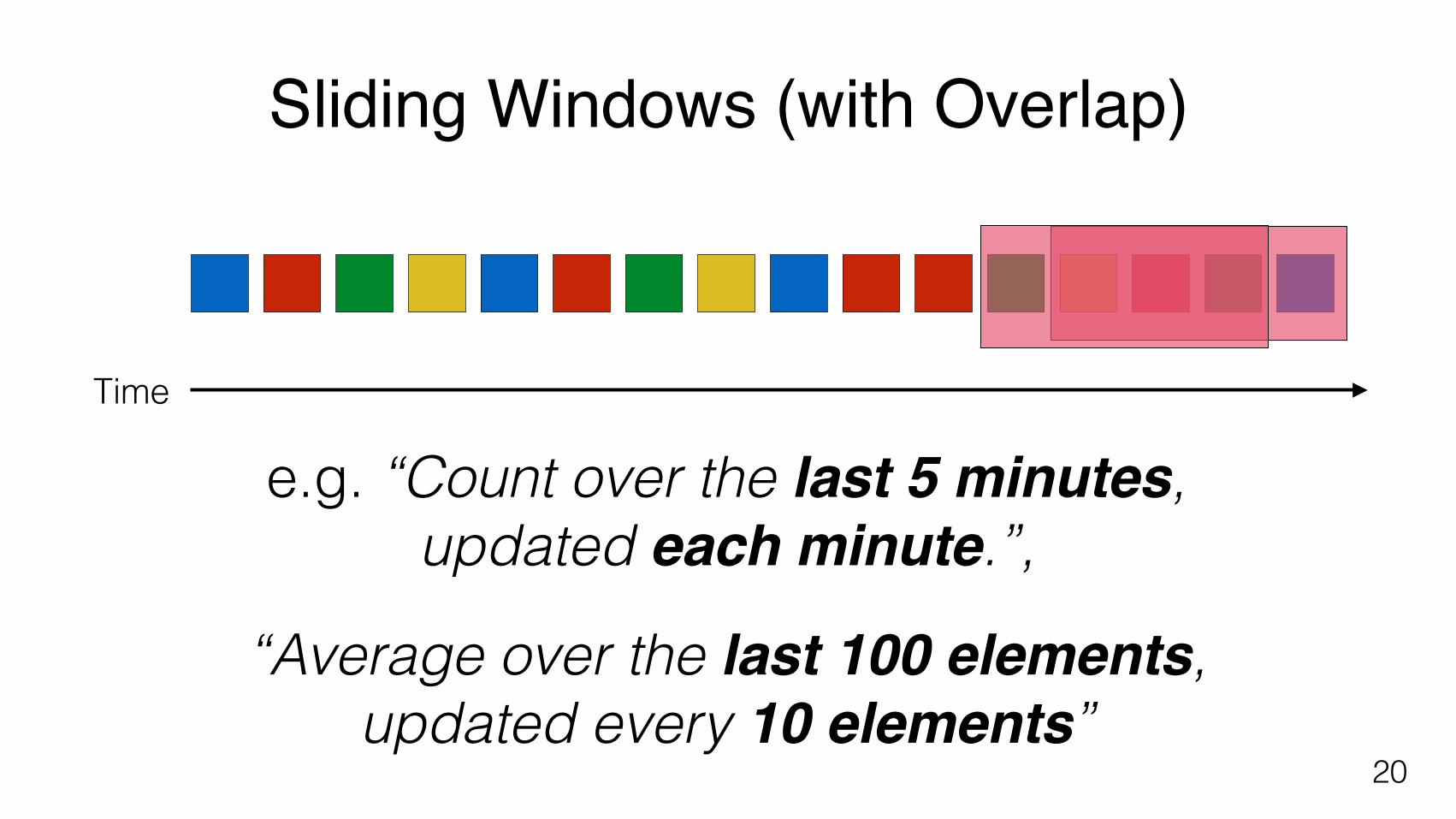
Sliding Windows (with Overlap)
20
Time
e.g. “Count over the last 5 minutes, updated each minute.”,
“Average over the last 100 elements, updated every 10 elements”
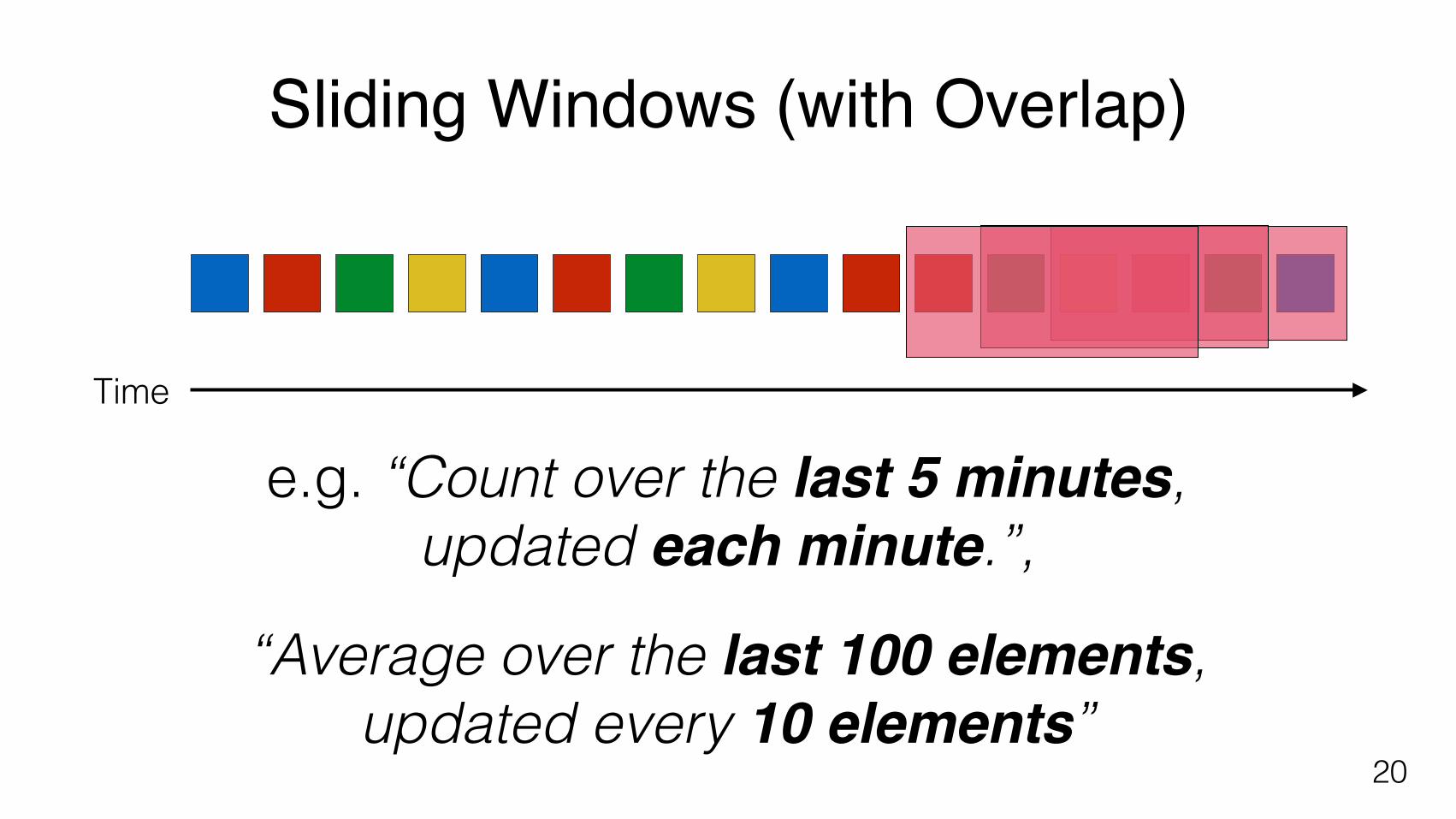
Sliding Windows (with Overlap)
20
Time
e.g. “Count over the last 5 minutes, updated each minute.”,
“Average over the last 100 elements, updated every 10 elements”
Sliding Windows (with Overlap)
20
Time
e.g. “Count over the last 5 minutes, updated each minute.”,
“Average over the last 100 elements, updated every 10 elements”

Explicit Handling of Time
21
DataStream<ColorEvent>counts=env.addSource(newKafkaConsumer(…)).keyBy("color").timeWindow(Time.minutes(60)).apply(newCountPerWindow());
Time is explicit in your program
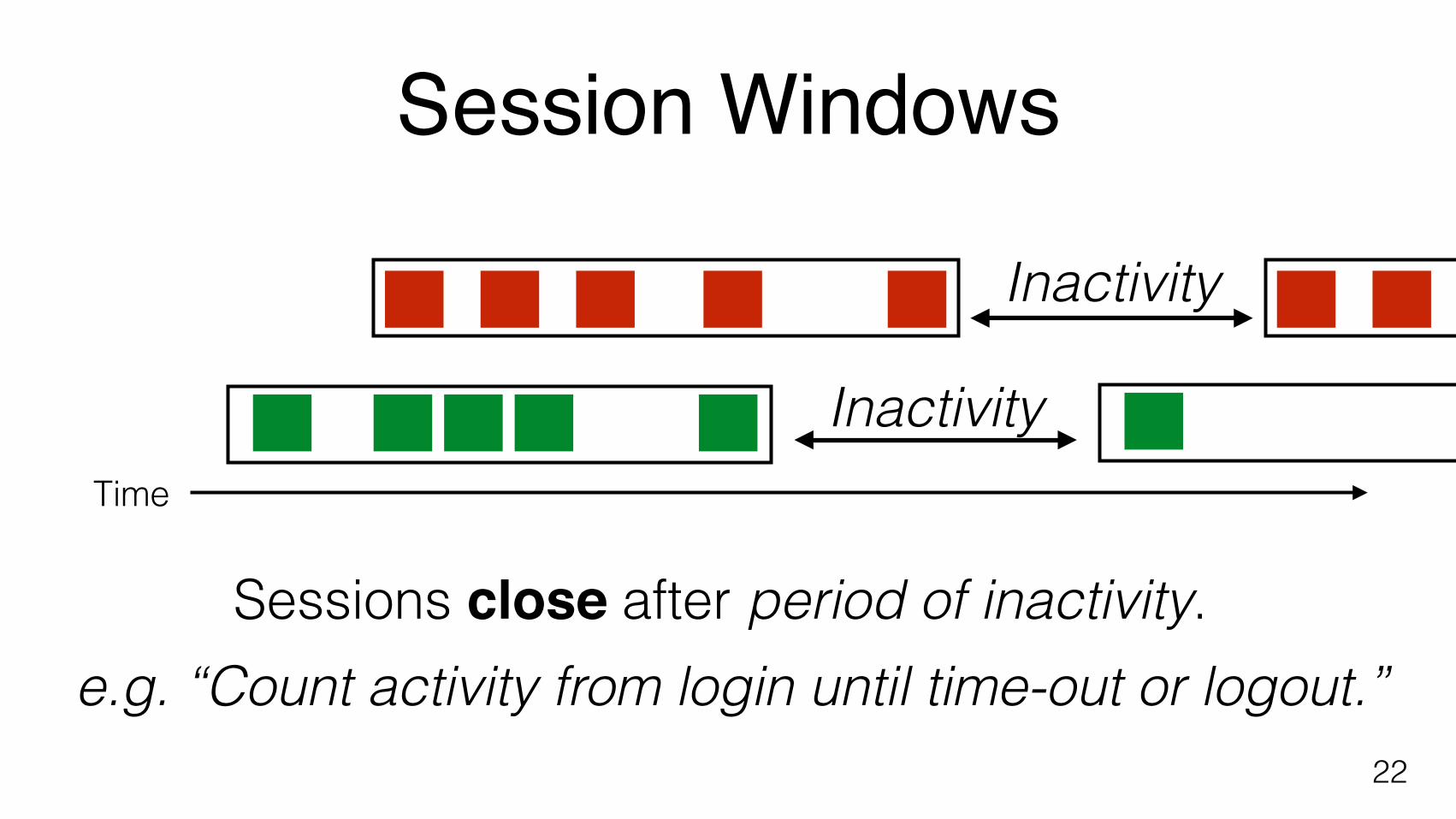
Session Windows
22
Time
Sessions close after period of inactivity.
Inactivity
Inactivity
e.g. “Count activity from login until time-out or logout.”

Session Windows
23
DataStream<ColorEvent>counts=env.addSource(newKafkaConsumer(…)).keyBy("color").window(EventTimeSessionWindows.withGap(Time.minutes(10)).apply(newCountPerWindow());

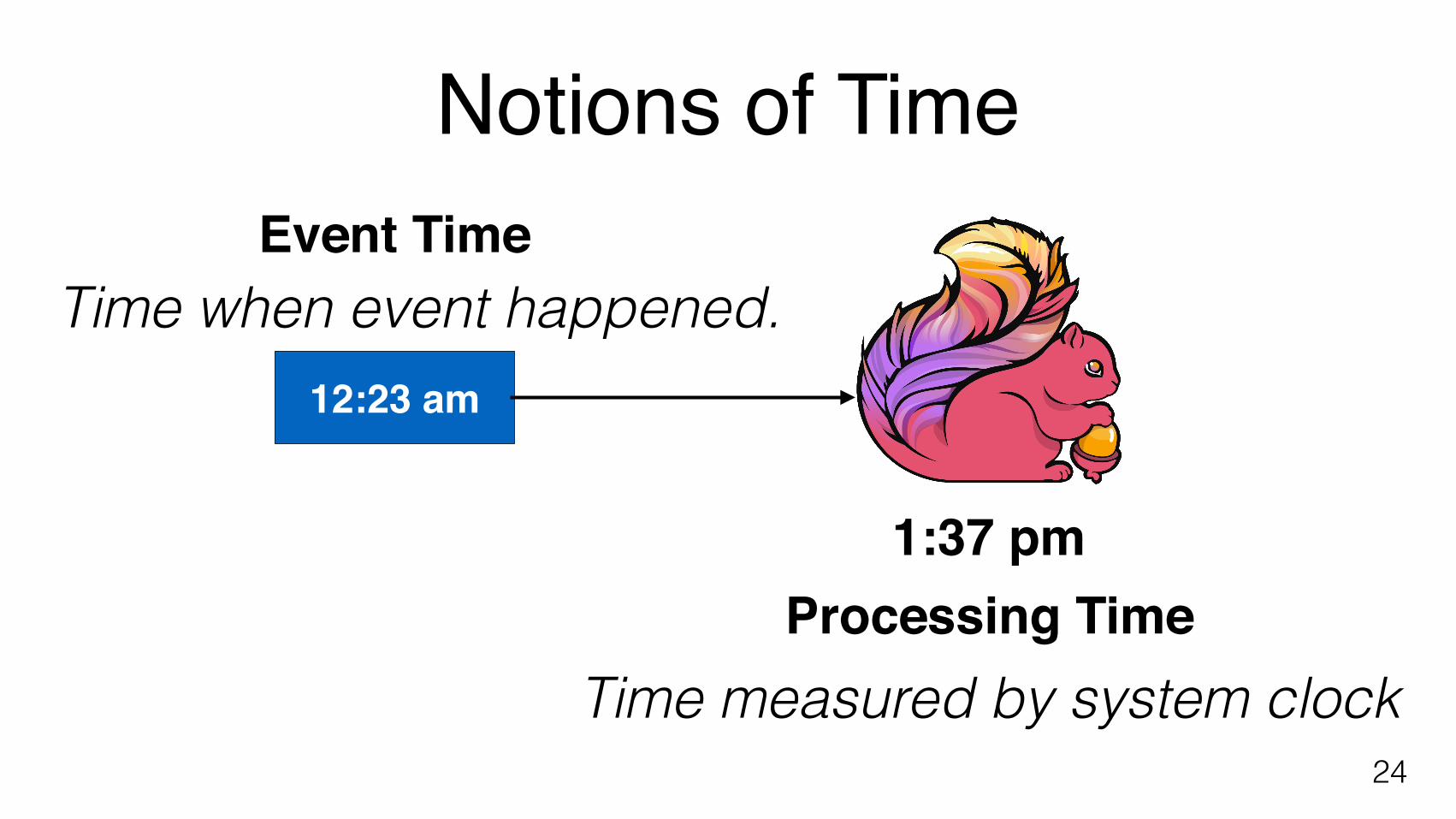
Notions of Time
24
12:23 am
Event TimeTime when event happened.
Notions of Time
24
12:23 am
Event Time
1:37 pmProcessing Time
Time measured by system clock
Time when event happened.
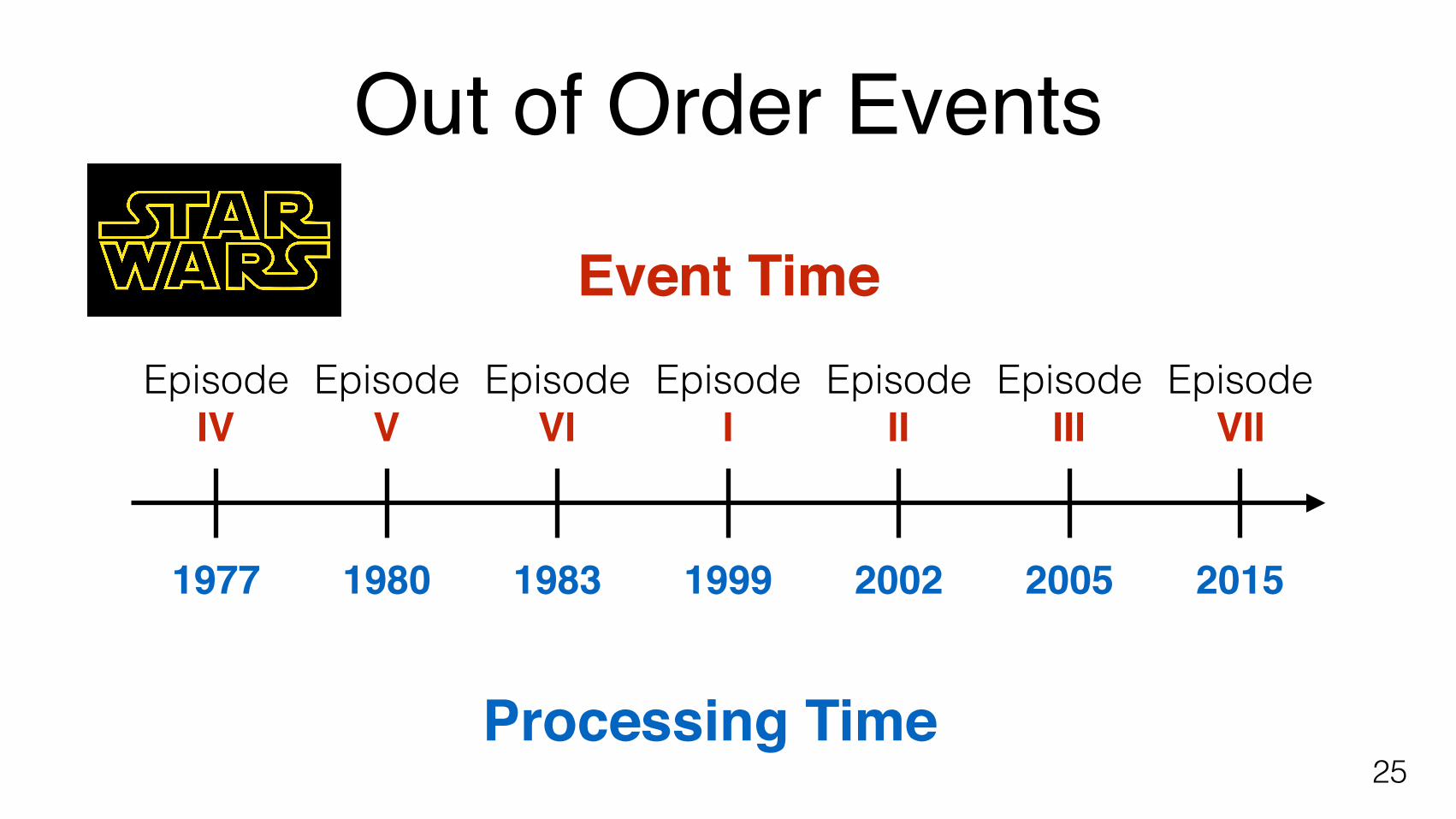
1977 1980 1983 1999 2002 2005 2015
Processing Time
EpisodeIV
EpisodeV
EpisodeVI
EpisodeI
EpisodeII
EpisodeIII
EpisodeVII
Event Time
Out of Order Events
25
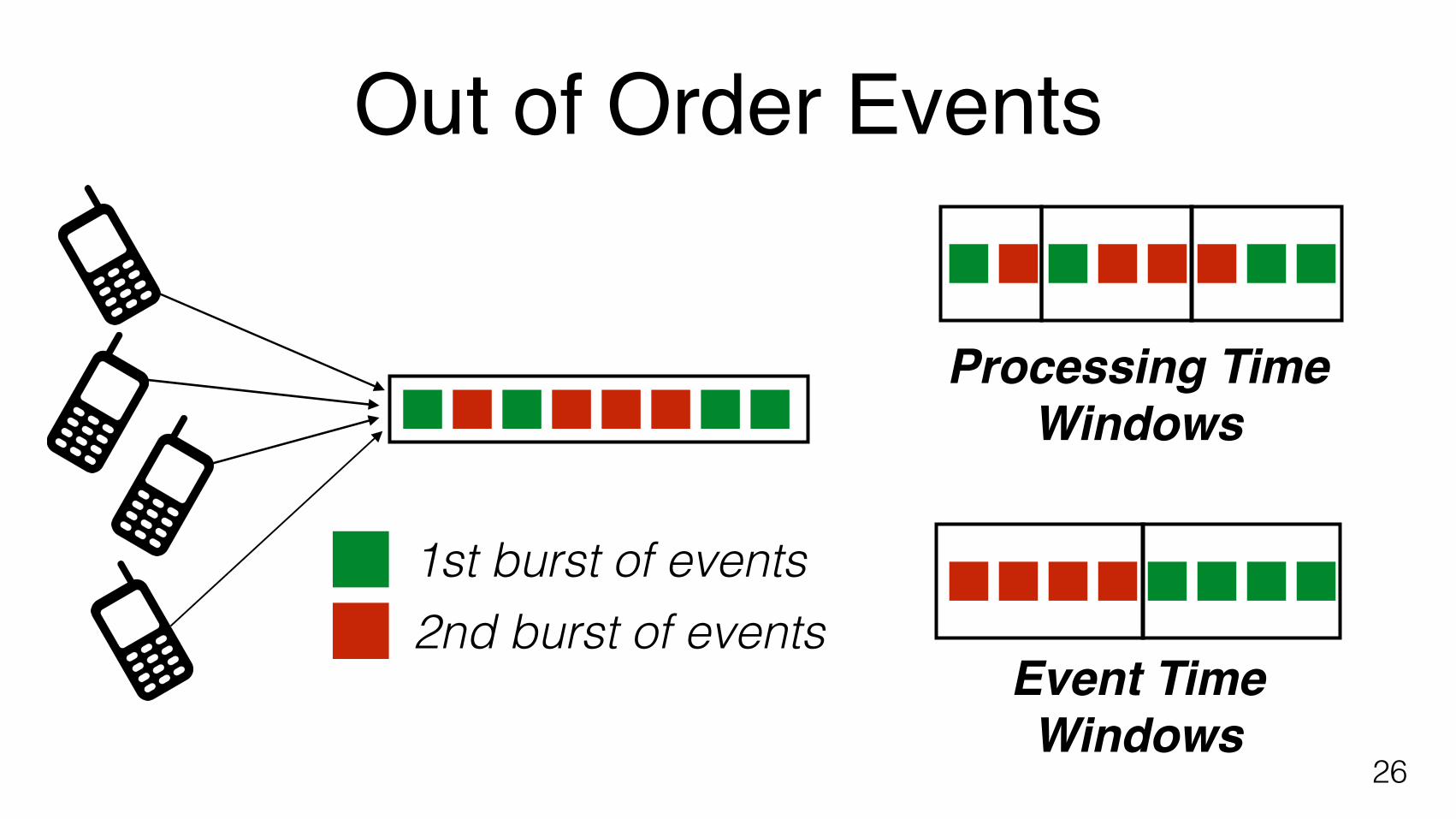
Out of Order Events
26
1st burst of events2nd burst of events
Event TimeWindows
Processing TimeWindows

Notions of Time
27
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
DataStream<ColorEvent>counts=env....timeWindow(Time.minutes(60)).apply(newCountPerWindow());

Explicit Handling of Time
28
1. Expressive windowing 2. Accurate results for out of order data 3. Deterministic results
Building Blocks of Flink
29
Explicit Handling of Time
State & Fault Tolerance
Performance
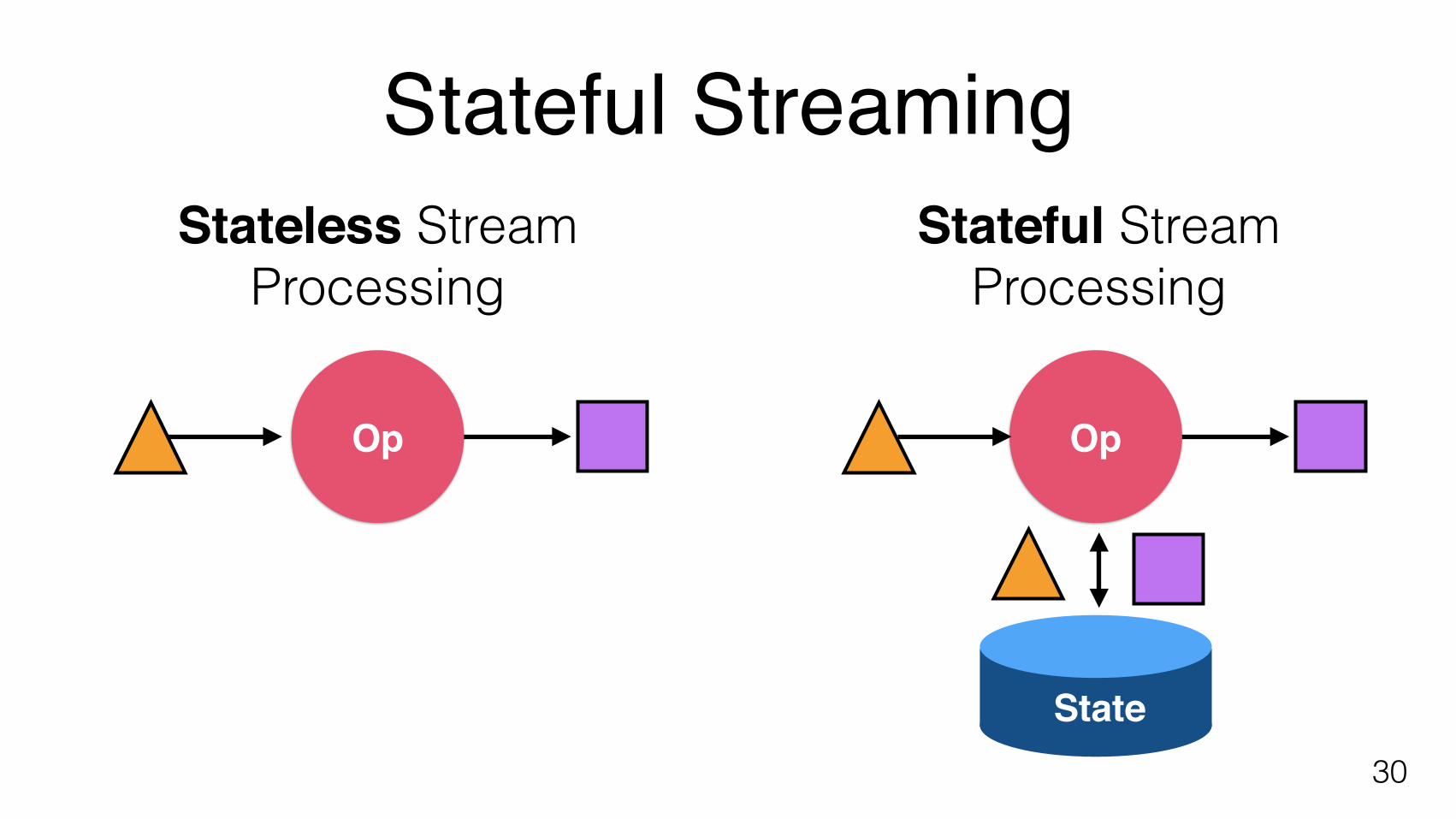
Stateful Streaming
30
Stateless Stream Processing
Stateful Stream Processing
Op Op
State

Processing Semantics
31
At-least onceMay over-count
after failure
Exactly OnceCorrect counts after failures
End-to-end exactly onceCorrect counts in external system (e.g. DB, file system) after failure

Processing Semantics
32
• Flink guarantees exactly once (can be configuredfor at-least once if desired)
• End-to-end exactly once with specific sourcesand sinks (e.g. Kafka -> Flink -> HDFS)
• Internally, Flink periodically takes consistentsnapshots of the state without ever stoppingcomputation
Building Blocks of Flink
33
Explicit Handling of Time
State & Fault Tolerance
Performance

Yahoo! Benchmark
34
• Storm 0.10, Spark Streaming 1.5, and Flink 0.10benchmark by Storm team at Yahoo!
• Focus on measuring end-to-end latency at low throughputs (~ 200k events/sec)
• First benchmark modelled after a real application
https://yahooeng.tumblr.com/post/135321837876/benchmarking-streaming-computation-engines-at

Yahoo! Benchmark
35
• Count ad impressions grouped by campaign • Compute aggregates over last 10 seconds • Make aggregates available for queries in Redis
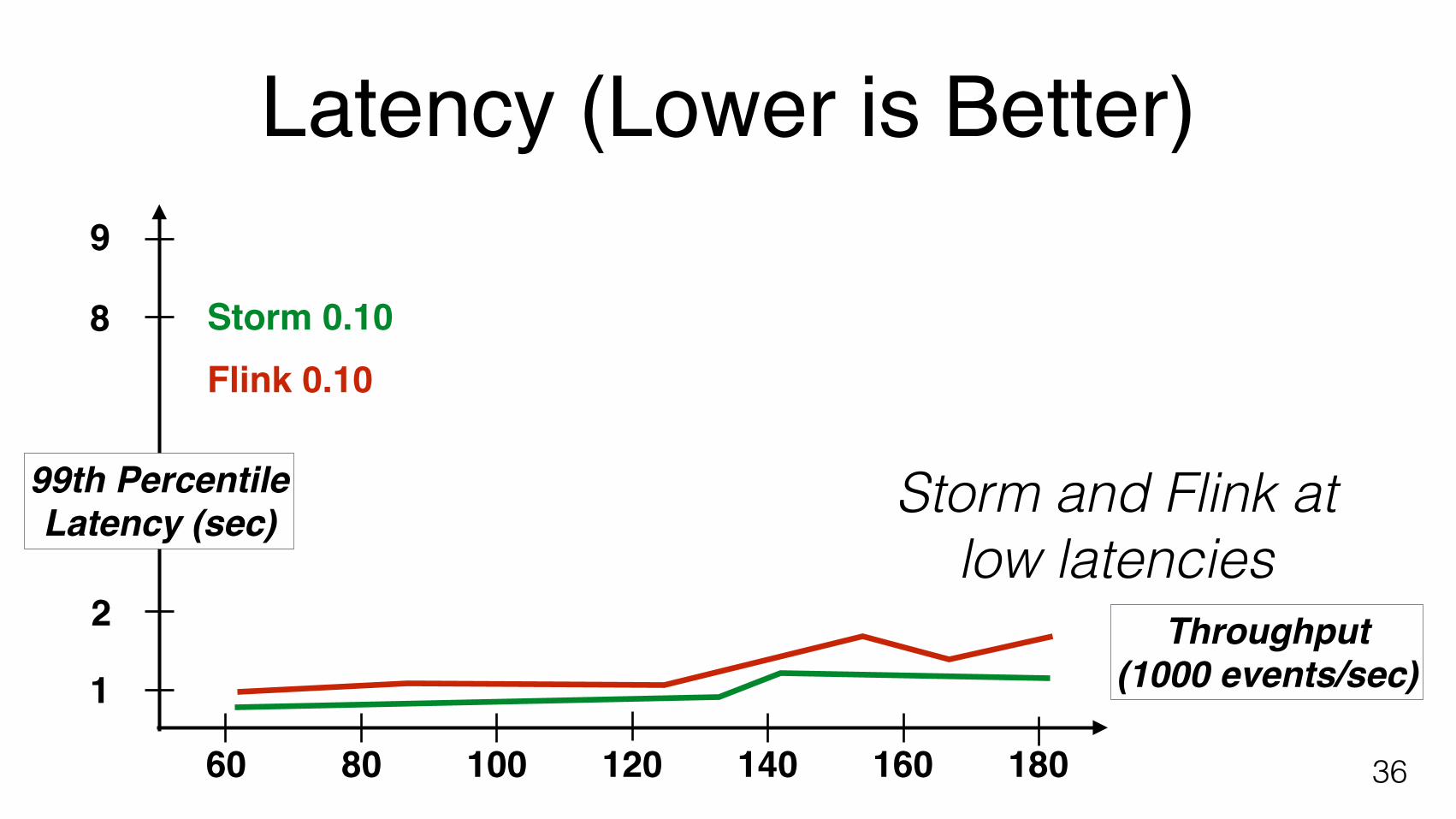
99th Percentile Latency (sec)
9
8
2
1
Storm 0.10Flink 0.10
60 80 100 120 140 160 180
Throughput(1000 events/sec)
Storm and Flink atlow latencies
Latency (Lower is Better)
36
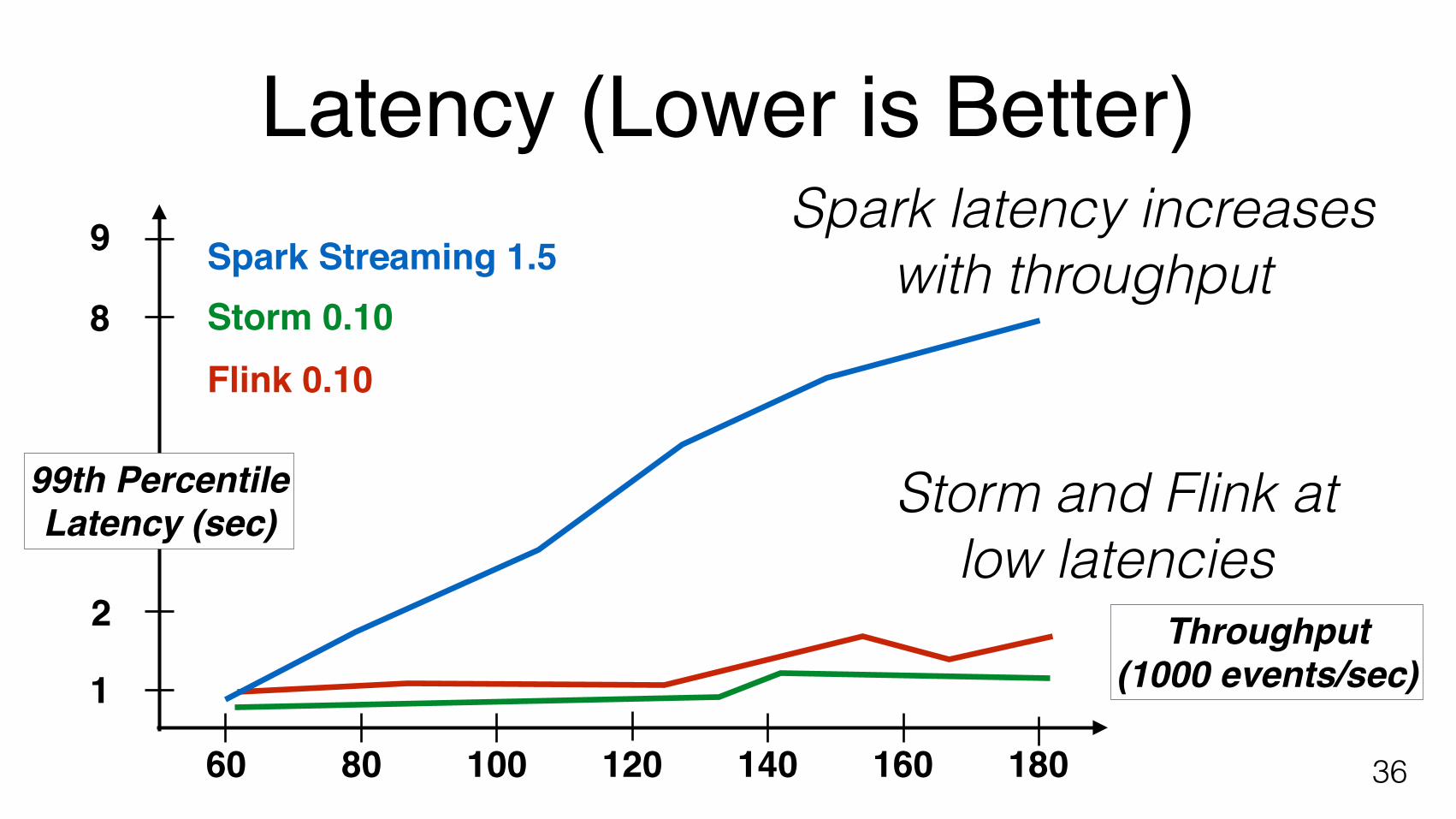
99th Percentile Latency (sec)
9
8
2
1
Storm 0.10Flink 0.10
60 80 100 120 140 160 180
Throughput(1000 events/sec)
Spark Streaming 1.5Spark latency increases
with throughput
Storm and Flink atlow latencies
Latency (Lower is Better)
36

Extending the Benchmark
37
• Great starting point, but benchmark stops at low write throughput and programs are notfault-tolerant
• Extend benchmark to high volumes and Flink’s built-in fault-tolerant state
http://data-artisans.com/extending-the-yahoo-streaming-benchmark/
Extending the Benchmark
38
Use Flink’s internal state
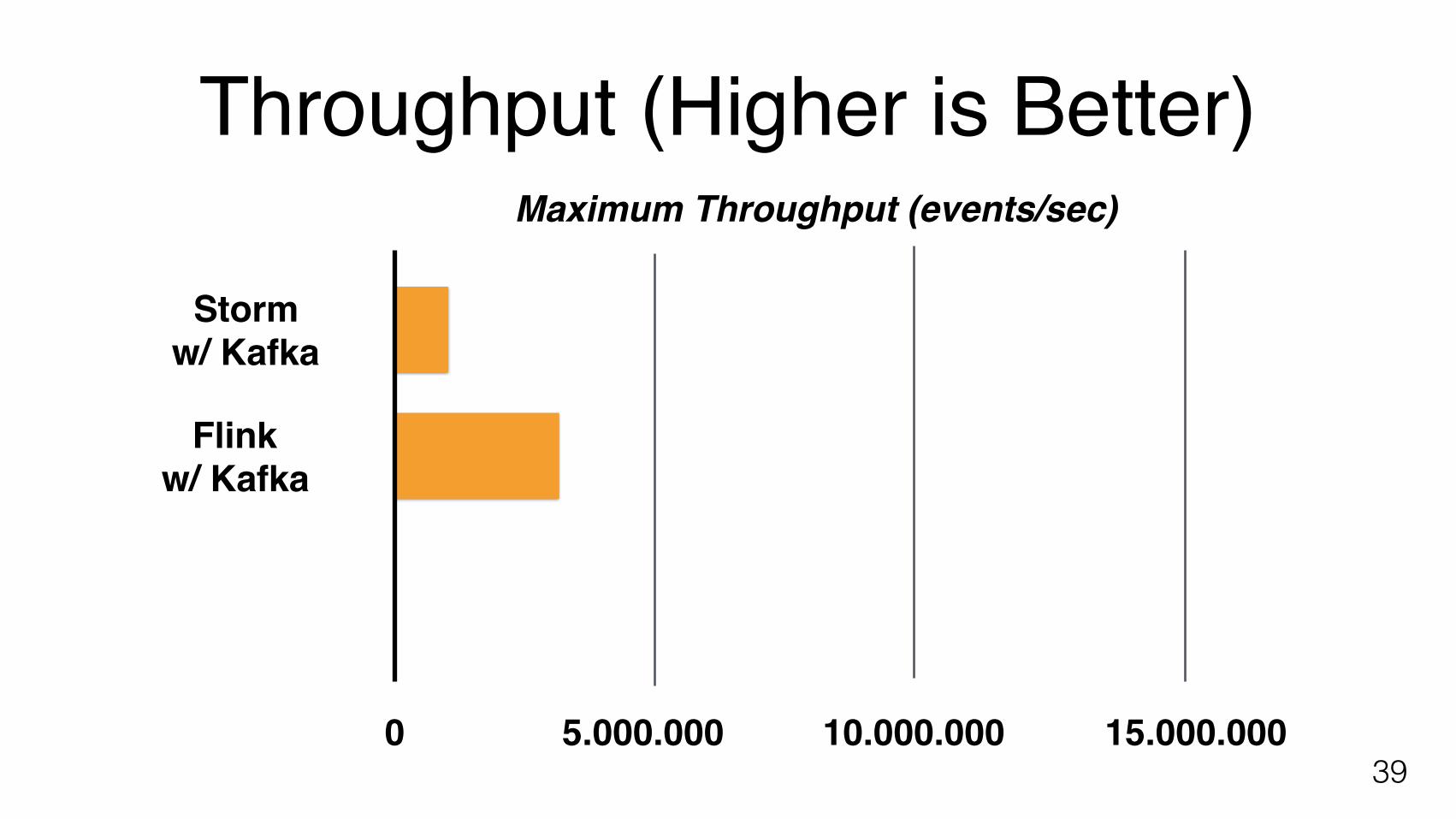
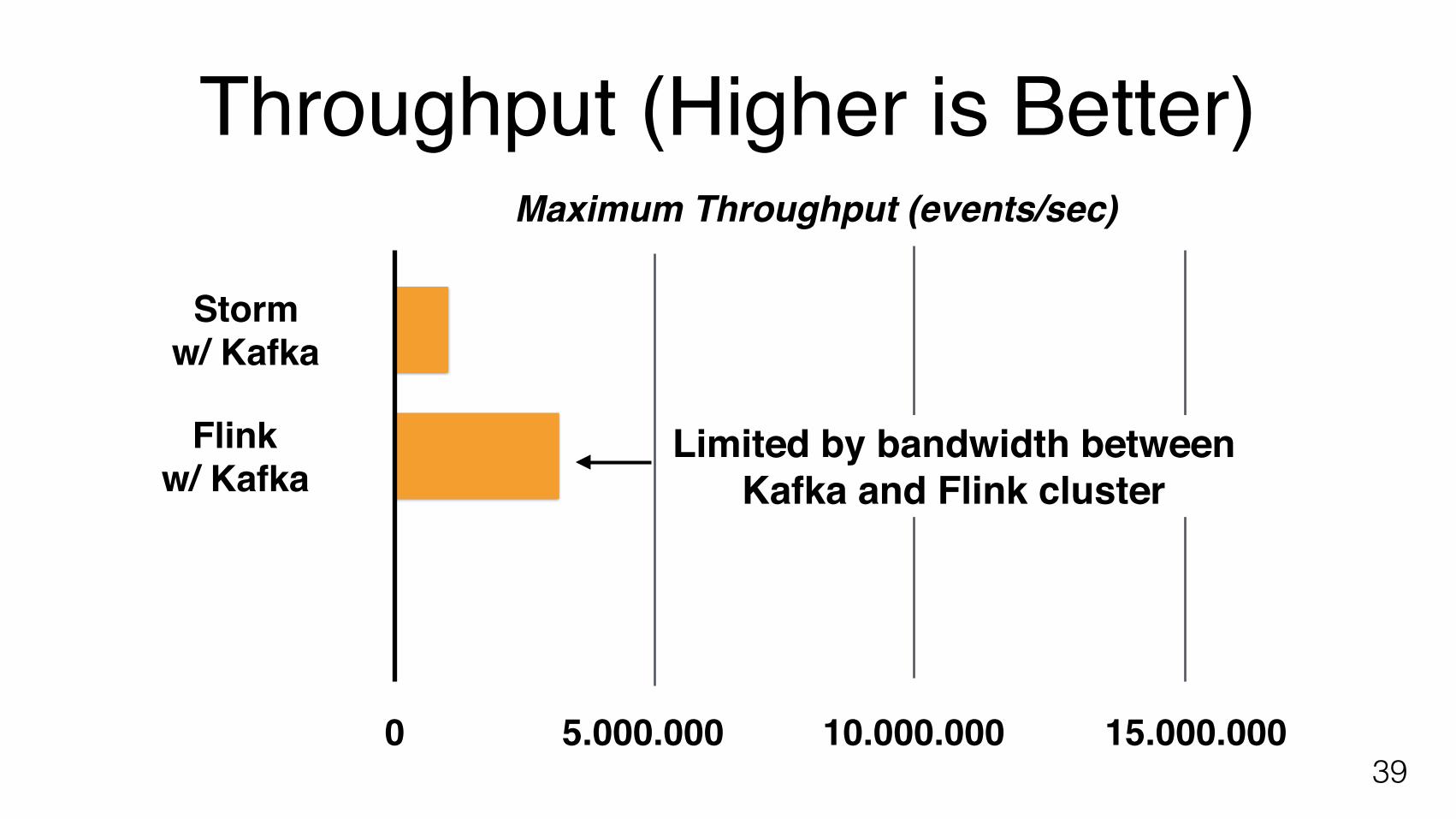
Throughput (Higher is Better)
395.000.000 10.000.000 15.000.000
Maximum Throughput (events/sec)
0
Flinkw/ Kafka
Stormw/ Kafka
Throughput (Higher is Better)
395.000.000 10.000.000 15.000.000
Maximum Throughput (events/sec)
0
Flinkw/ Kafka
Stormw/ Kafka
Limited by bandwidth betweenKafka and Flink cluster
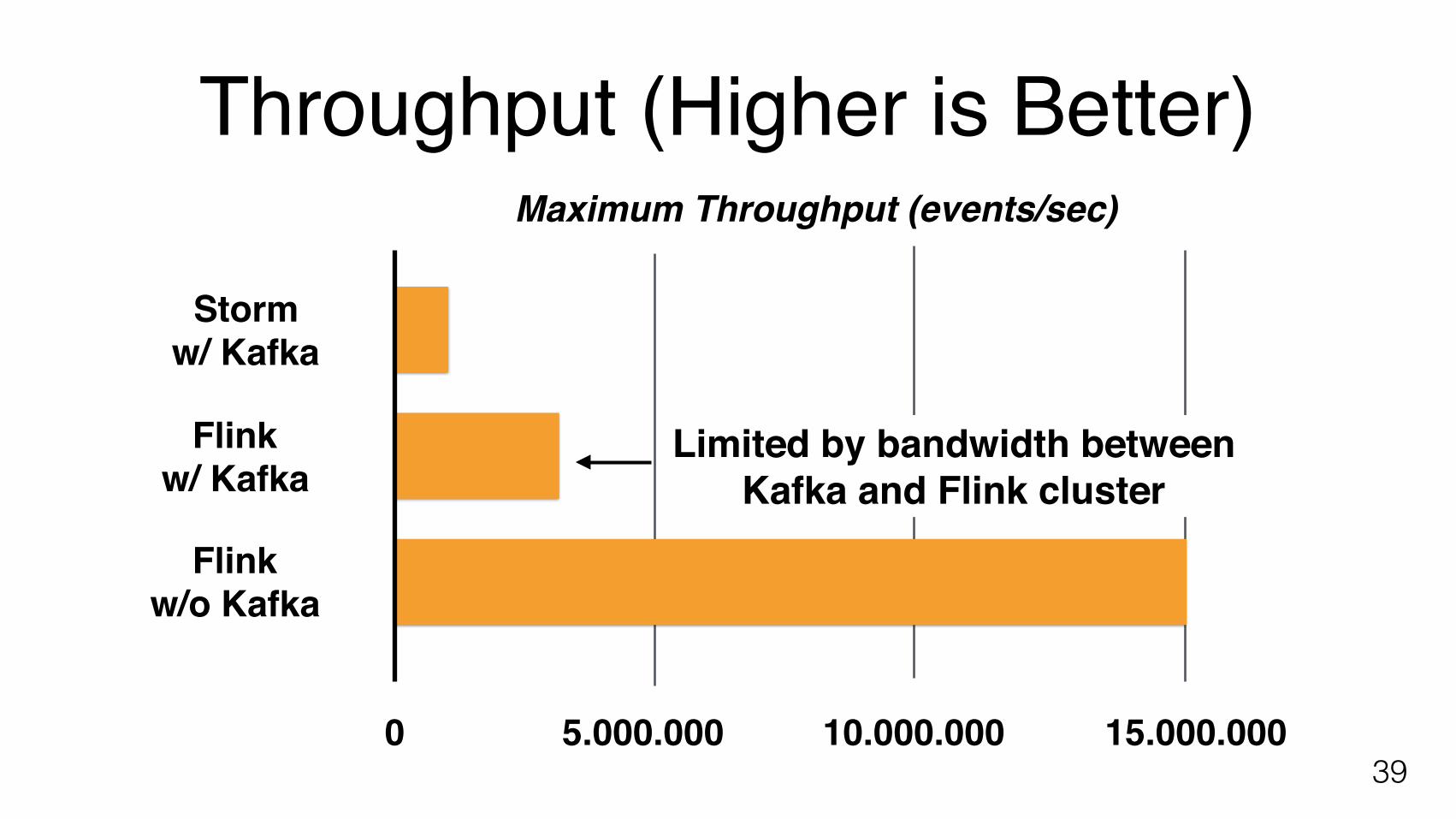
Throughput (Higher is Better)
395.000.000 10.000.000 15.000.000
Maximum Throughput (events/sec)
0
Flinkw/o Kafka
Flinkw/ Kafka
Stormw/ Kafka
Limited by bandwidth betweenKafka and Flink cluster

Summary
40
• Stream processing is gaining momentum, the right paradigm for continuous data applications
• Choice of framework is crucial – even seemingly simple applications become complex at scale and in production
• Flink offers unique combination of efficiency, consistency and event time handling
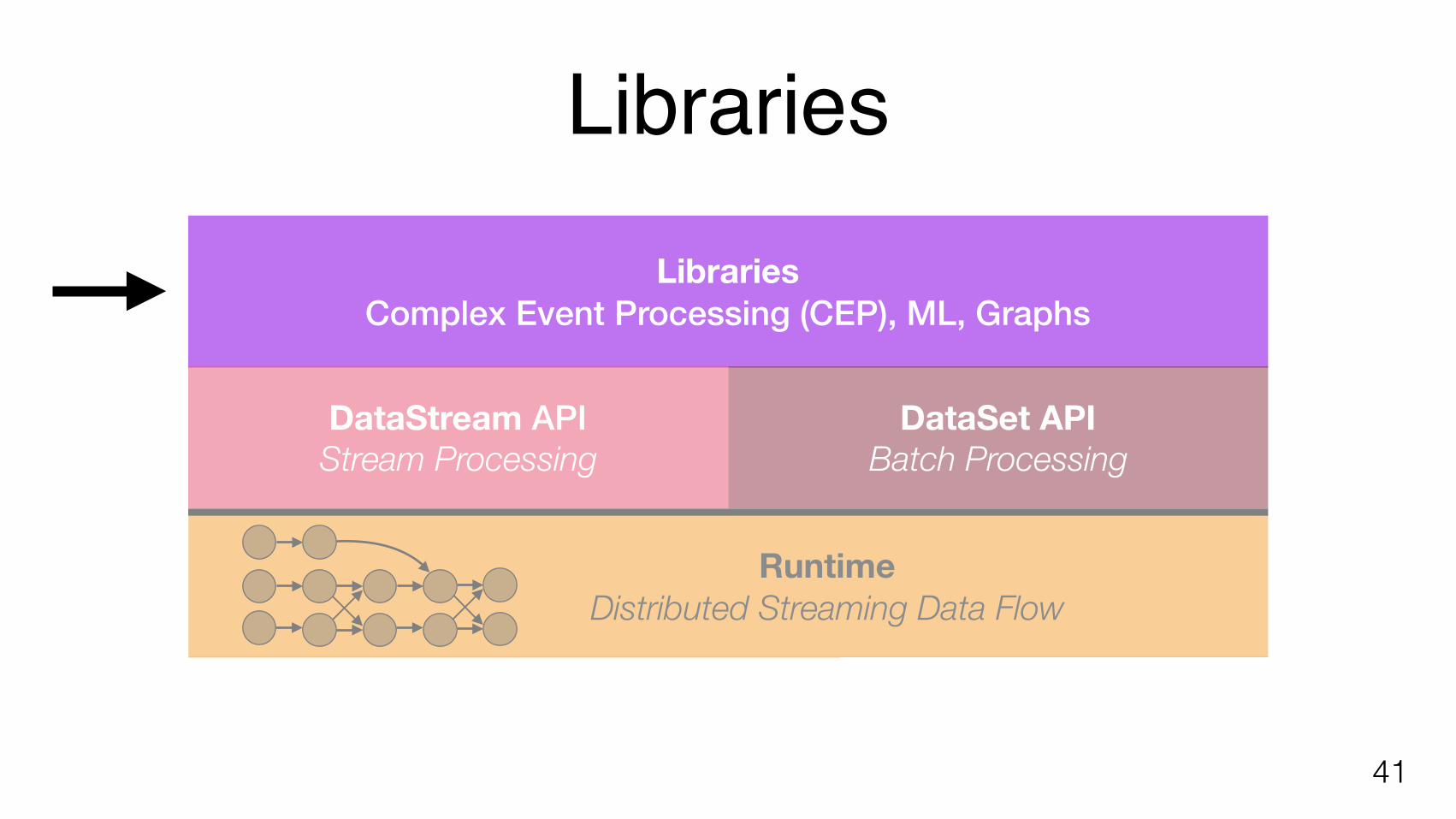
Libraries
41
DataStream API Stream Processing
DataSet API Batch Processing
Runtime Distributed Streaming Data Flow
LibrariesComplex Event Processing (CEP), ML, Graphs

42
Pattern<MonitoringEvent, ?> warningPattern = Pattern.<MonitoringEvent>begin("First Event") .subtype(TemperatureEvent.class) .where(evt -> evt.getTemperature() >= THRESHOLD) .next("Second Event") .subtype(TemperatureEvent.class) .where(evt -> evt.getTemperature() >= THRESHOLD) .within(Time.seconds(10));
Complex Event Processing (CEP)

Upcoming Features
43
• SQL: ongoing work in collaboration with Apache Calcite
• Dynamic Scaling: adapt resources to stream volume, scale up for historical stream processing
• Queryable State: query the state inside the stream processor
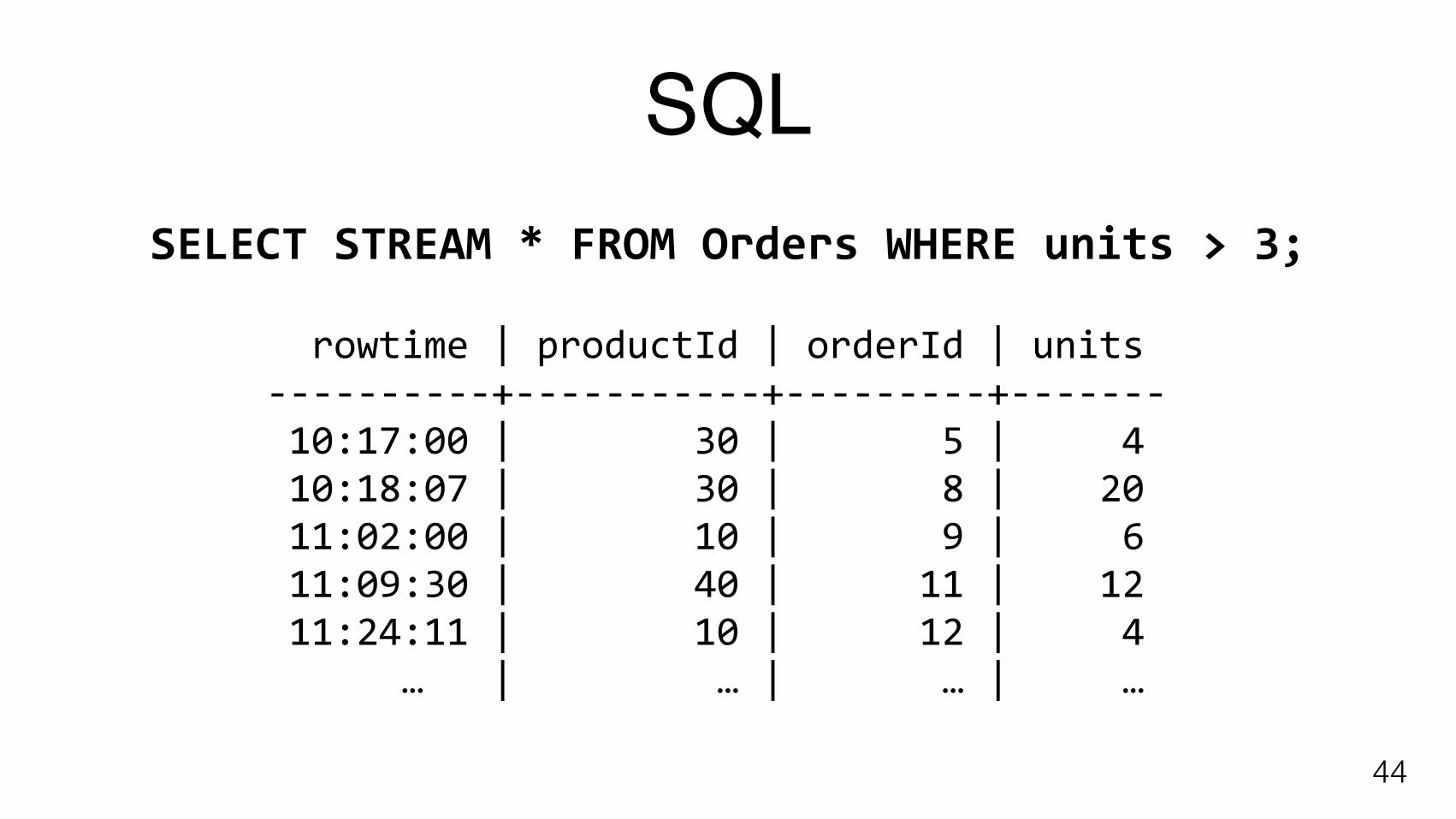
SQL
44
SELECTSTREAM*FROMOrdersWHEREunits>3;
rowtime|productId|orderId|units----------+-----------+---------+-------10:17:00|30|5|410:18:07|30|8|2011:02:00|10|9|611:09:30|40|11|1211:24:11|10|12|4…|…|…|…
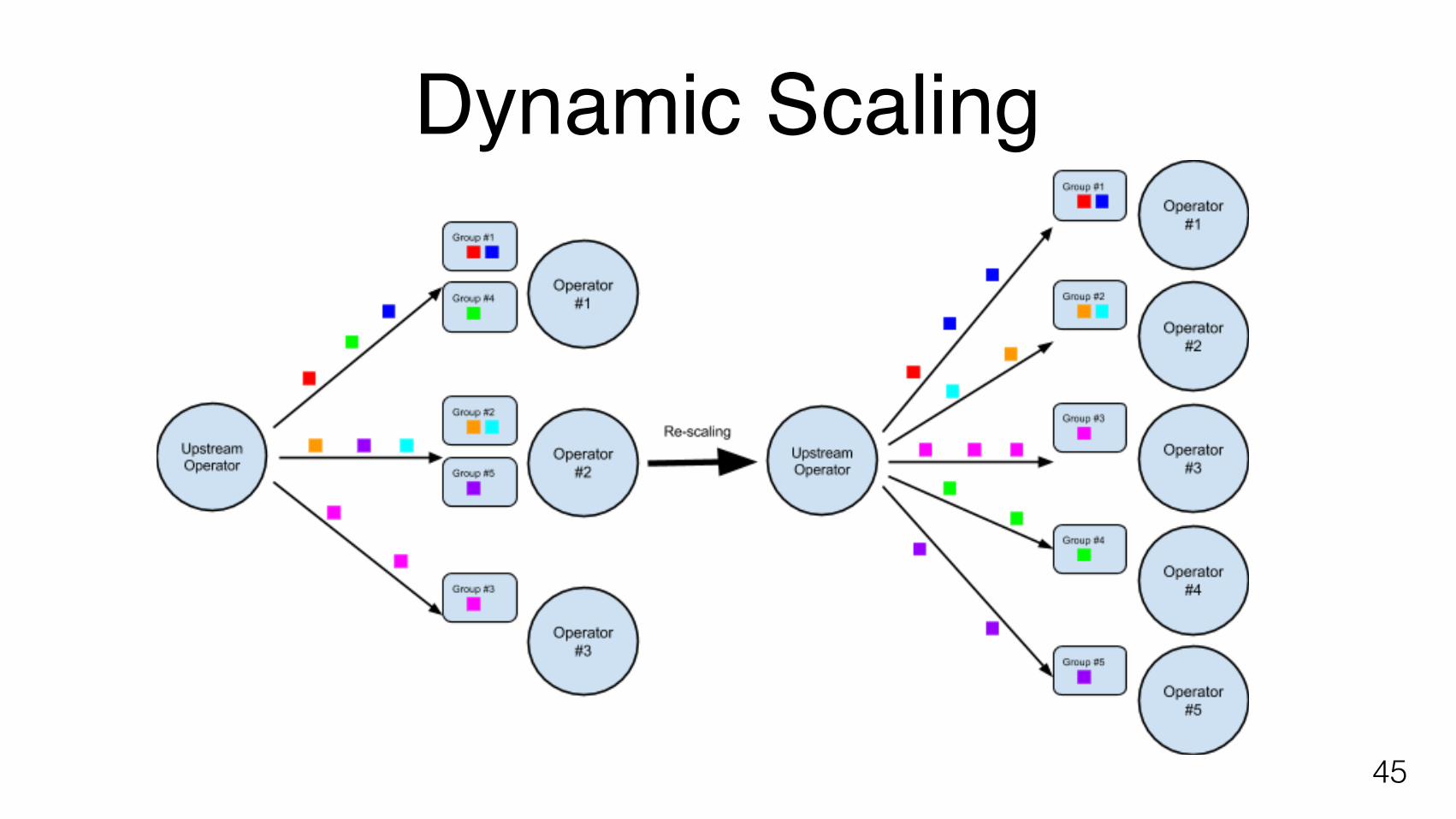
keyvalue states have to be redistributed when rescaling a Flink job. Distributing the keyvalue
states coherently with the job’s new partitioning will lead to a consistent state.
Requirements
In order to efficiently distribute keyvalue states across the cluster, they should be grouped into
key groups. Each key group represents a subset of the key space and is checkpointed as an
independent unit. The key groups can then be reassigned to different tasks if the DOP
changes. In order to decide which key belongs to which key group, the user has to specify the
maximum number of key groups. This number limits the maximum number of parallelism for an
operator, because each operator has to receive at least one key group. The current
implementation of Flink can be thought of as having only a single implicit key group per
operator.
In order to mitigate the problem of having a fixed number of key groups, it is conceivable to
provide a tool with which one can change the number of key groups for a checkpointed
program. This of course would most likely be a very costly operation.
Dynamic Scaling
45
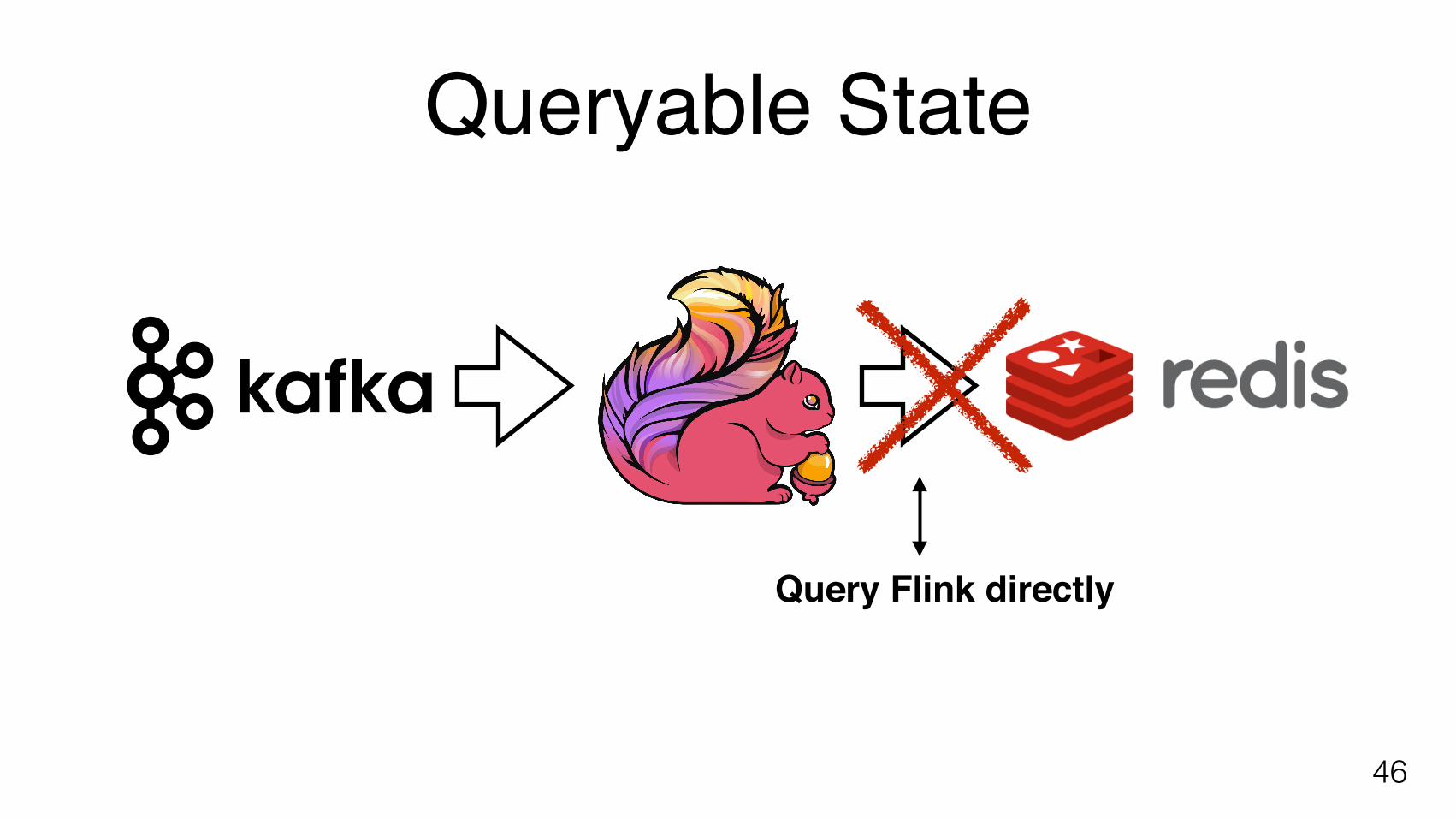
Queryable State
46
Query Flink directly
Join the Community
47
Read http://flink.apache.org/blog http://data-artisans.com/blog
Follow@ApacheFlink @dataArtisans
Subscribe (news | user | dev)@flink.apache.org







