Download - “Towards an SSI for HP Java”

““Towards an SSI for HP Java”Towards an SSI for HP Java”
Francis Lau
The University of Hong Kong
With contributions from C.L. Wang, Ricky Ma, and W.Z. Zhu

7/10/2003 ICPP-HPSECA03 2
Cluster Coming of AgeCluster Coming of Age
• HPC– Cluster the de facto standard
equipment– Grid?
• Clusters– Fortran or C + MPI the norm– 99% on top of bare-bone Linux or
the like– Ok if application is embarrassingly
parallel and regular

7/10/2003 ICPP-HPSECA03 3
Cluster for the MassCluster for the Mass
• Two modes:– For number crunching
in Grande type applications (superman)
– As a CPU farm to support high-throughput computing (poor man)
Commercial: Data mining, Financial Modeling, Oil Reservoir Simulation, Seismic Data Processing, Vehicle and Aircraft Simulation
Government: Nuclear Stockpile Stewardship, Climate and Weather, Satellite Image Processing, Forces Modeling
Academic: Fundamental Physics (particles, relativity, cosmology), Biochemistry, Environmental Engineering, Earthquake Prediction
Commercial: Data mining, Financial Modeling, Oil Reservoir Simulation, Seismic Data Processing, Vehicle and Aircraft Simulation
Government: Nuclear Stockpile Stewardship, Climate and Weather, Satellite Image Processing, Forces Modeling
Academic: Fundamental Physics (particles, relativity, cosmology), Biochemistry, Environmental Engineering, Earthquake Prediction

7/10/2003 ICPP-HPSECA03 4
Cluster ProgrammingCluster Programming
• Auto-parallelization tools have limited success
• Parallelization a chore but “have to do it” (or let’s hire someone)
• Optimization for performance not many users’ cup of tea– Partitioning and parallelization– Mapping– Remapping (experts?)

7/10/2003 ICPP-HPSECA03 5
Amateur Parallel ProgrammingAmateur Parallel Programming
• Common problems– Poor parallelization: few large chunks or many
small chunks– Load imbalances: large and small chunks
• Meeting the amateurs half-way– They do crude parallelization– System does the rest: mapping/remapping
(automatic optimization)– And I/O?

7/10/2003 ICPP-HPSECA03 6
Automatic OptimizationAutomatic Optimization
• “Feed the fat boy with two spoons, and a few slim ones with one spoon”
• But load information could be elusive• Need smart runtime supports• Goal is to achieve high performance with g
ood resource utilization and load balancing• Large chunks that are single-threaded a pr
oblem

7/10/2003 ICPP-HPSECA03 7
The Good “Fat Boys”The Good “Fat Boys”
• Large chunks that span multiple nodes
• Must be a program with multiple execution “threads”
• Threads can be in different nodes – program expands and shrinks
• Threads/programs can roam around – dynamic migration
• This encourages fine-grain programming
cluster node
“amoeba”

7/10/2003 ICPP-HPSECA03 8
Mechanism and PolicyMechanism and Policy
• Mechanism for migration– Traditional process migration– Thread migration
• Redirection of I/O and messages• Objects sharing between nodes for threads• Policy for good dynamic load balancing
– Message traffic a crucial parameter– Predictive
• Towards the “single system image” ideal

7/10/2003 ICPP-HPSECA03 9
Single System ImageSingle System Image
• If user does only crude parallelization and system does the rest …
• If processes/threads can roam, and processes expand/shrink …
• If I/O (including sockets) can be at any node anytime …
• We achieve at least 50% of SSI– The rest is difficult
SingleSingleEntry PointFile SystemVirtual NetworkingI/O and Memory SpaceProcess SpaceManagement / Programming View…
SingleSingleEntry PointFile SystemVirtual NetworkingI/O and Memory SpaceProcess SpaceManagement / Programming View…

7/10/2003 ICPP-HPSECA03 10
Bon Java!Bon Java!
• Java (for HPC) in good hands– JGF Numerics Working Group, IBM Ninja, …– JGF Concurrency/Applications Working Group (benchmarki
ng, MPI, …)– The workshops
• Java has many advantages (vs. Fortran and C/C++)• Performance not an issue any more• Threads as first-class citizens!• JVM can be modified
“Java has the greatest potential to deliver an attractive productive programming environment spanning the very broad range of tasks needed by
the Grande programmer ” – The Java Grande Forum Charter
“Java has the greatest potential to deliver an attractive productive programming environment spanning the very broad range of tasks needed by
the Grande programmer ” – The Java Grande Forum Charter

7/10/2003 ICPP-HPSECA03 11
Process vs. Thread MigrationProcess vs. Thread Migration
• Process migration easier than thread migration– Threads are tightly coupled– They share objects
• Two styles to explore– Process, MPI (“distributed
computing”)– Thread, shared objects (“parallel
computing”)– Or combined
• Boils down to messages vs. distributed shared objects

7/10/2003 ICPP-HPSECA03 12
Two Projects @ HKUTwo Projects @ HKU
• M-JavaMPI – “M” for “Migration”– Process migration– I/O redirection– Extension to grid– No modification of JVM and MPI
• JESSICA – “Java-Enabled Single System Image Computing Architecture”– By modifying JVM– Thread migration, Amoeba mode– Global object space, I/O redirection– JIT mode (Version 2)

7/10/2003 ICPP-HPSECA03 13
Design ChoicesDesign Choices
• Bytecode instrumentation – Insert code into programs, manually or via pre-processor
• JVM extension– Make thread state accessible from Java program– Non-transparent– Modification of JVM is required
• Checkpointing the whole JVM process– Powerful but heavy penalty
• Modification of JVM – Runtime support– Totally transparent to the applications– Efficient but very difficult to implement

7/10/2003 ICPP-HPSECA03 14
M-JavaMPIM-JavaMPI
• Support transparent Java process migration and provide communication redirection services
• Communication using MPI• Implemented as a middleware on top of st
andard JVM• No modifications of JVM and MPI• Checkpointing the Java process + code in
sertion by preprocessor

7/10/2003 ICPP-HPSECA03 15
System ArchitectureSystem Architecture
Native MPINative MPI
JVMJVM
HardwareHardware
JavaJava--MPI APIMPI API
Java MPI program Java MPI program (Java(Java bytecodebytecode))
Java APIJava API
OSOS
JVMDI JVMDI (Debugger interface in Java 2)(Debugger interface in Java 2)
Restorable MPI layerRestorable MPI layer
Migration layerMigration layer(Save and restore process)(Save and restore process)
Preprocessing layer Preprocessing layer (Insert exception handlers)(Insert exception handlers)
Support low-latency and high-bandwidthdata communication
Provide MPI wrapper for Java program
Save and restore process. Process and object information are saved and restored by using object serialization, reflection and exception through JVMDI
Java .class files are modified by inserting an exception handler in each method of each class. The handler is used to restore the process state.
Provide restorable MPI communication through MPI daemons
Debugger interface in Java 2. Used to retrieve and restore process state
Native MPINative MPI
JVMJVM
HardwareHardware
JavaJava--MPI APIMPI API
Java MPI program Java MPI program (Java(Java bytecodebytecode))
Java APIJava API
OSOS
JVMDI JVMDI (Debugger interface in Java 2)(Debugger interface in Java 2)
Restorable MPI layerRestorable MPI layer
Migration layerMigration layer(Save and restore process)(Save and restore process)
Preprocessing layer Preprocessing layer (Insert exception handlers)(Insert exception handlers)
Support low-latency and high-bandwidthdata communication
Provide MPI wrapper for Java program
Save and restore process. Process and object information are saved and restored by using object serialization, reflection and exception through JVMDI
Java .class files are modified by inserting an exception handler in each method of each class. The handler is used to restore the process state.
Provide restorable MPI communication through MPI daemons
Debugger interface in Java 2. Used to retrieve and restore process state
Native MPINative MPI
JVMJVM
HardwareHardware
JavaJava--MPI APIMPI API
Java MPI program Java MPI program (Java(Java bytecodebytecode))
Java APIJava API
OSOS
JVMDI JVMDI (Debugger interface in Java 2)(Debugger interface in Java 2)
Restorable MPI layerRestorable MPI layer
Migration layerMigration layer(Save and restore process)(Save and restore process)
Preprocessing layer Preprocessing layer (Insert exception handlers)(Insert exception handlers)
Support low-latency and high-bandwidthdata communication
Provide MPI wrapper for Java program
Save and restore process. Process and object information are saved and restored by using object serialization, reflection and exception through JVMDI
Java .class files are modified by inserting an exception handler in each method of each class. The handler is used to restore the process state.
Provide restorable MPI communication through MPI daemons
Debugger interface in Java 2. Used to retrieve and restore process state

7/10/2003 ICPP-HPSECA03 16
PreprocessingPreprocessing
• Bytecode is modified before passing to JVM for execution
• “Restoration functions” are inserted as exception handlers, in the form of encapsulated “try-catch” statements
• Re-arrangement of bytecode, and addition of local variables

7/10/2003 ICPP-HPSECA03 17
The LayersThe Layers
• Java-MPI API layer• Restorable MPI layer
– Provides restorable MPI communications– No modification of MPI library
• Migration Layer– Captures and save the execution state of the
migrating process in the source node, and restores the execution state of the migrated process in the destination node
– Cooperates with the Restorable MPI layer to reconstruct the communication channels of the parallel application

7/10/2003 ICPP-HPSECA03 18
State Capturing and State Capturing and RestoringRestoring
• Program code: re-used in the destination node• Data: captured and restored by using the object
serialization mechanism • Execution context: captured by using JVMDI and
restored by inserted exception handlers• Eager (all) strategy: For each frame, local
variables, referenced objects, the name of the class and class method, and program counter are saved using object serialization

7/10/2003 ICPP-HPSECA03 19
State Capturing using JVMDIState Capturing using JVMDI
public class A { int a; char b; …}
public class A { try { … } catch (RestorationException e) { a = saved value of local variable a; b = saved value of local variable b; pc = saved value of program counter when the program is suspended jump to the location where the program is suspended }}

7/10/2003 ICPP-HPSECA03 20
Message Redirection ModelMessage Redirection Model
• MPI daemon in each node to support message passing between distributed java processes
• IPC between Java program and MPI daemon in the same node through shared memory and semaphores
Java Program
Java-MPI API
MPI Daemon(linked with native MPI library)
Java Program
Java-MPI API
MPI Daemon(linked with native MPI library)
MPI communication
Network
IPC IPC
Node 1 Node 2
client-server client-server

7/10/2003 ICPP-HPSECA03 21
migration layer(source node)
MPI daemon(source node)
MPI daemon(destination node)
migration client(destination node)
suspend userprocess
send migrationrequest
broadcast mig.info. to all MPI
daemonsstart an instance
of JVM withJVMDI client
captureprocess state
send bufferedmessages
notify MPIdaemon of thecompletion of
capturing send notificationmessage
(and capturedprocess data if
central file systemis not used)
send notificationof the readiness ofcaptured process
data execution ofmigrated
process isrestored
LEGENDS Migration events
Event triggers
Restorationof executionstate starts
process isrestarted and
suspended
JVM andprocess quit
Process migration steps
Source Node
Destination Node

7/10/2003 ICPP-HPSECA03 22
ExperimentsExperiments
• PC Cluster– 16-node cluster– 300 MHz Pentium II with 128MB of memory– Linux 2.2.14 with Sun JDK 1.3.0– 100Mb/s fast Ethernet
• All Java programs executed in interpreted mode

7/10/2003 ICPP-HPSECA03 23
0
2
4
6
8
10
12
1 2 4 8
16
32
64
12
8
25
6
51
2
10
24
20
48
40
96
81
92
16
38
4
32
76
8
65
53
6
13
10
7
message size (byte)
band
wid
th (
Mby
te/s
)
native MPI direct Java-MPI binding migratable Java-MPI
Bandwidth: PingPong Test
Native MPI: 10.5 MB/sDirect Java-MPI binding: 9.2 MB/sRestorable MPI layer: 7.6 MB/s

7/10/2003 ICPP-HPSECA03 24
0
0.0001
0.0002
0.0003
0.0004
0.0005
0.0006
0.0007
0.0008
1 2 4 8 16 32 64 128
256
512
1024
2048
4096
message size (byte)
late
ncy(
s)
native MPI direct Java-MPI binding migratable Java-MPI
Native MPI: 0.2 msDirect Java-MPI binding: 0.23 msRestorable MPI layer: 0.26 ms
Latency: PingPong Test

7/10/2003 ICPP-HPSECA03 25
Migration Cost: capturing and restoring objects
1
10
100
1000
10000
0 10100
100010K
100K
1000K
data size (# of integers)
time
spen
t (m
s)
capturing time restoring time

7/10/2003 ICPP-HPSECA03 26
0
1000
2000
3000
4000
0 200 400 600
number of frames
time
spen
t (m
s)
capture time (ms) restore time (ms)
Migration Cost: capturing and restoring frames

7/10/2003 ICPP-HPSECA03 27
Application PerformanceApplication Performance
• PI calculation
• Recursive ray-tracing
• NAS integer sort
• Parallel SOR

7/10/2003 ICPP-HPSECA03 28
Time spent in calculating PI and ray-tracing with and without the migration layer
020406080
100120140160180200
0 1 2 3 4 5 6 7 8 9no. of nodes
exec
utio
n tim
e (s
ec)
PI (w/o migration layer) ray -tracing (w/o migration layer)
PI (w/ migration layer) ray -tracing (w/ migration layer)

7/10/2003 ICPP-HPSECA03 29
Execution time of NAS program with different problem sizes (16 nodes)
Problem size (no. of integers)
Time used (sec) in environment without M-JavaMPI
Time used (sec) in environment with M-JavaMPI
Overhead introduced by M-JavaMPI (in %)
Total Comp Comm Total Comp Comm Total Comm
Class S: 65536
0.023 0.009 0.014 0.026 0.009 0.017 13% 21%
Class W:1048576
0.393 0.182 0.212 0.424 0.182 0.242 7.8% 14%
Class A: 8388608
3.206 1.545 1.66 3.387 1.546 1.840 5.6% 11%
No noticeable overhead introduced in the computation part; while in the communication part, an overhead of about 10-20%

7/10/2003 ICPP-HPSECA03 30
Time spent in executing SOR using different numbers of nodes with and without migration layer
0200400600800
10001200
0 1 2 3 4 5 6 7 8 9
no. of nodes
exec
utio
n tim
e (s
ec)
SOR (w/o migration layer) SOR (w/ migration layer)

7/10/2003 ICPP-HPSECA03 31
Cost of MigrationCost of Migration
No. of nodes No migration (sec) One migration (sec) 1 1013 1016 2 518 521 4 267 270 6 176 178 8 141 144
Time spent in executing the SOR program on an array of size 256x256 without and with one migration during the execution

7/10/2003 ICPP-HPSECA03 32
Applications Average migration time
PI 2
Ray-tracing 3
NAS 2
SOR 3
• Time spent in migration (in seconds) for different applications
Cost of MigrationCost of Migration

7/10/2003 ICPP-HPSECA03 33
Dynamic Load BalancingDynamic Load Balancing
• A simple test– SOR program was executed using six nodes
in an unevenly loaded environment with one of the nodes executing a computationally intensive program
• Without migration : 319s
• With migration: 180s

7/10/2003 ICPP-HPSECA03 34
In ProgressIn Progress
– M-JavaMPI in JIT mode– Develop system modules for automatic dynam
ic load balancing – Develop system modules for effective fault-tol
erant supports

7/10/2003 ICPP-HPSECA03 35
Java Virtual MachineJava Virtual Machine
• Class Loader– Loads class files
• Interpreter– Executes bytecode
• Runtime Compiler– Converts bytecode to
native code
0a0b0c0d0c6262431c1d688662a0b0c0d0c1334514726522723
010101010001011101010101100011101010110011010111011
Class loader
Interpreter
Runtimecompiler
Bytecode
Native code
Application Class File Java API Class File

7/10/2003 ICPP-HPSECA03 36
Threads in JVMThreads in JVM
Heap (Data)object object
Class loader
Class files
Thread 3
Java Method Area (Code)
Thread 2Thread 1
PC
Stack Frame
Stack Frame
public class ProducerConsumerTest { public static void main(String[] args) { CubbyHole c = new CubbyHole(); Producer p1 = new Producer(c, 1); Consumer c1 = new Consumer(c, 1);
p1.start(); c1.start(); }}
A Multithreaded Java Program
Execution Engine

7/10/2003 ICPP-HPSECA03 37
Java Memory Model(How to maintain memory consistency between threads)
Load variable from main memory to working memory before use.
Variable is modified in T1’s working memory.
T1 T2
Upon T1 performs unlock, variable is written back to main memory
Upon T2 performs lock, flush variable in working memoryWhen T2 uses variable, it will be loaded from main memory
Garbage Bin
Per-Thread working memory
Main memory
Object
Variable Heap Area
Threads: T1, T2
JMMJMM
master copy

7/10/2003 ICPP-HPSECA03 38
Problems in Existing DJVMsProblems in Existing DJVMs
• Mostly based on interpreters– Simple but slow
• Layered design using distributed shared memory system (DSM) cannot be tightly coupled with JVM– JVM runtime information cannot be channeled to DSM– False sharing if page-based DSM is employed– Page faults block the whole JVM
• Programmer to specify thread distribution lack of transparency– Need to rewrite multithreaded Java applications– No dynamic thread distribution (preemptive thread migration) for
load balancing

7/10/2003 ICPP-HPSECA03 39
Related WorkMethod shipping: IBM cJVM Like remote method invocation (RMI) : when accessing object
fields, the proxy redirects the flow of execution to the node where the object's master copy is located.
Executed in Interpreter mode. Load balancing problem : affected by the object distribution.
Page shipping: Rice U. Java/DSM, HKU JESSICA Simple. GOS was supported by some page-based Distributed
Shared Memory (e.g., TreadMarks, JUMP, JiaJia) JVM runtime information can’t be channeled to DSM. Executed in Interpreter mode.
Object shipping: Hyperion, Jackal Leverage some object-based DSM Executed in native mode: Hyperion: translate Java bytecode to
C. Jackal: compile Java source code directly to native code

7/10/2003 ICPP-HPSECA03 40
Global Object Space
High Speed Network
PC
OS
Java Threads created in a program
PC
OS
PC
OS
PC
OS
JESSICA2: A distributed Java Virtual Machine (DJVM) spanning multiple cluster nodes can provide a true parallel execution environment for multithreaded Java applications with a Single System Image illusion to Java threads.
Distributed Java Virtual Machine (DJVM)Distributed Java Virtual Machine (DJVM)

7/10/2003 ICPP-HPSECA03 41
JESSICA2 Main FeaturesJESSICA2 Main Features• Transparent Java thread migration
– Runtime capturing and restoring of thread execution context.
– No source code modification; no bytecode instrumentation (preprocessing); no new API introduced
– Enables dynamic load balancing on clusters
• Operated in Just-In-Time (JIT) compilation Mode
• Global Object Space– A shared global heap spanning all cluste
r nodes – Adaptive object home migration protocol– I/O redirection
Transparentmigration
JIT GOS
JESSICA2

7/10/2003 ICPP-HPSECA03 42
Transparent Thread Migration in Transparent Thread Migration in JIT ModeJIT Mode
• Simple for interpreters (e.g., JESSICA)– Interpreter sits in the bytecode decoding loop which can be stopped u
pon a migration flag checking– The full state of a thread is available in the data structure of interprete
r – No register allocation
• JIT mode execution makes things complex (JESSICA2)– Native code has no clear bytecode boundary– How to deal with machine registers?– How to organize the stack frames (all are in native form now)?– How to make extracted thread states portable and recognizable by th
e remote JVM?– How to restore the extracted states (rebuild the stack frames) and res
tart the execution in native form?
Need to modify JIT compiler to instrument native code

7/10/2003 ICPP-HPSECA03 44
An overview of JESSICA2 Java thread migration
Thread
Frame
(1) Alert
Frames
Method Area
GOS(heap)
JVM
Frame parsingRestore execution
Frame
Stack analysisStack capturing
Thread Scheduler
Source node
Destination node
Migration Manager
LoadMonitor
Method Area
GOS(heap)
(4b) Load method from NFS
FramesFrames
(2)
(4a) Object Access
(3)
PC
PC

7/10/2003 ICPP-HPSECA03 45
Essential FunctionsEssential Functions
• Migration points selection– At the start of loop, basic block or method
• Register context handler– Spill dirty registers at migration point without invalidation so that
native code can continue the use of registers– Use register recovering stub at restoring phase
• Variable type deduction– Spill type in stacks using compression
• Java frames linking– Discover consecutive Java frames

7/10/2003 ICPP-HPSECA03 46
Dynamic Thread State Capturing and Dynamic Thread State Capturing and Restoring in JESSICA2Restoring in JESSICA2
mov slot1->reg1mov slot2->reg2...
Bytecode verifier
bytecode translation
migration point
code generation
Intermediate Code
invoke
1. Add migration checking2. Add object checking3. Add type & register spilling
register allocation
Native Code
Native stack scanningLinking &
Constant Resolution
Register recovering
reg slots
cmp obj[offset],0jz ...
cmp mflag,0jz ...
mov 0x110182, slot...
Native thread stack
Java frame
C frame
(Restore)
Global Object Access
Frame
(Capturing)
migration point Selection

7/10/2003 ICPP-HPSECA03 47
How to Maintain Memory Consistency in a How to Maintain Memory Consistency in a Distributed Environment?Distributed Environment?
T2
High Speed Network
PC
OSPC
OS
PC
OS
PC
OS
T4 T6 T8T1 T3 T5 T7
Heap Heap

7/10/2003 ICPP-HPSECA03 48
Embedded Global Object Space Embedded Global Object Space (GOS)(GOS)
• Take advantage of JVM runtime information for optimization (e.g., object types, accessing threads, etc.)
• Use threaded I/O interface inside JVM for communication to hide the latency Non-blocking GOS access
• OO-based to reduce false sharing• Home-based, compliant with JVM Memory Model
(“Lazy Release Consistency”)• Master heap (home objects) and cache heap (local
and cached objects): reduce object access latency

7/10/2003 ICPP-HPSECA03 49
Object CacheObject Cache
Global Heap
JVM
Master Heap Area Cache Heap Area
Hashtable Hash table
JVM
Master Heap Area Cache Heap Area
Hashtable
Hashtable
Ja
va
threa
d
Java th
read
Java th
read
Java th
read

7/10/2003 ICPP-HPSECA03 50
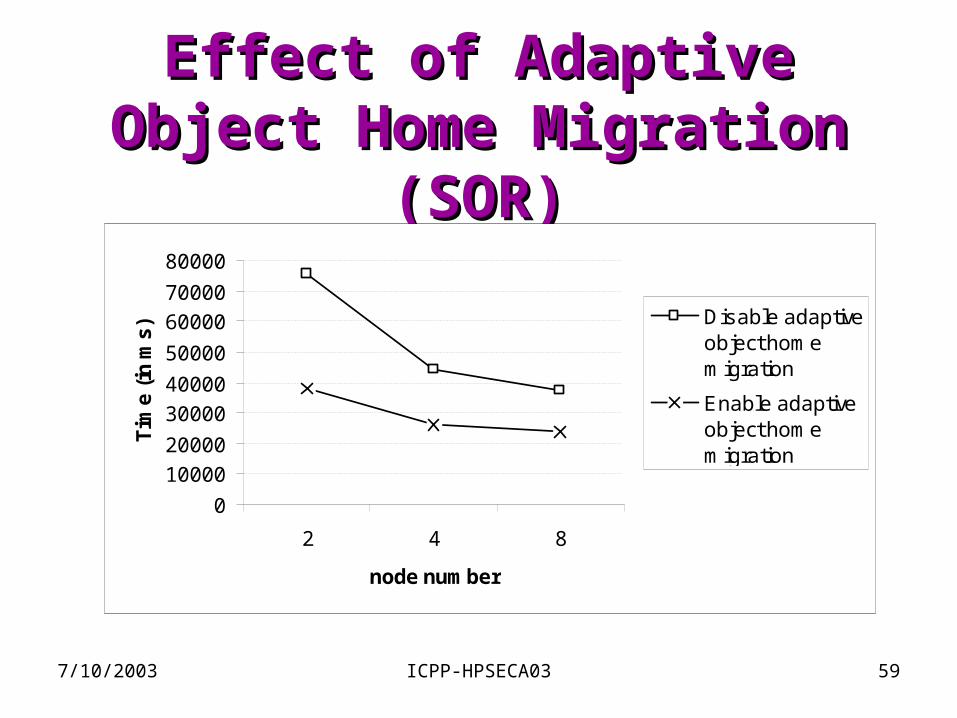
Adaptive object home Adaptive object home migrationmigration
• Definition– “home” of an object = the JVM that holds the master
copy of an object
• Problems– cache objects need to be flushed and re-fetched from
the home whenever synchronization happens
• Adaptive object home migration– if # of accesses from a thread dominates the total # of
accesses to an object, the object home will be migrated to the node where the thread is running

7/10/2003 ICPP-HPSECA03 51
I/O redirectionTimer Use the time in master node as the standard time Calibrate the time in worker node when they register to master n
ode
File I/O Use half word of “fd” as node number Open file
For read, check local first, then master node For write, go to master node
Read/Write Go to the node specified by the node number in fd
Network I/O Connectionless send: do it locally Others, go to master

7/10/2003 ICPP-HPSECA03 52
Experimental SettingExperimental Setting
• Modified Kaffe Open JVM version 1.0.6
• Linux PC clusters 1. Pentium II PCs at 540MHz (Li
nux 2.2.1 kernel) connected by Fast Ethernet
2. HKU Gideon 300 Cluster (for the Ray Tracing demo)

7/10/2003 ICPP-HPSECA03 53
Parallel Ray Tracing on JESSICA2(Using 64 nodes of the Gideon 300 cluster)
Linux 2.4.18-3 kernel (Redhat 7.3)
64 nodes: 108 seconds
1 node: 4420 seconds (~ 1 hour)
Speedup = 4402/108 = 40.75

7/10/2003 ICPP-HPSECA03 54
Micro BenchmarksMicro Benchmarks
Time breakdown of thread migration
Capture time
Pasring time
native thread creation
resolution of methods
frame setup time
(PI Calculation)

7/10/2003 ICPP-HPSECA03 55
Java Grande BenchmarkJava Grande Benchmark
Java Grande benchmark result(Single node)
01020304050607080
Barrie
r
ForkJ
oinSyn
cCry
pt
LUFac
tSOR
Series
Spars
eMat
mult
Kaffe 1.0.6 JIT
JESSICA2

7/10/2003 ICPP-HPSECA03 56
SPECjvm98 BenchmarkSPECjvm98 Benchmark
“M-”: disabling migration mechanism “M+”: enabling migration“I+”: enabling pseudo-inlining “I-”: disabling pseudo-inlining

7/10/2003 ICPP-HPSECA03 57
JESSICA2 vs JESSICA (CPI)JESSICA2 vs JESSICA (CPI)
CPI(50,000,000iterations)
050000
100000150000200000250000
2 4 8
Number of nodes
Tim
e(m
s) JESSICA
JESSICA2

7/10/2003 ICPP-HPSECA03 58
Application PerformanceApplication Performance
Speedup
0
2
4
6
8
10
2 4 8
Node number
Spe
edup
Linear speedup
CPI
TSP
Raytracer
nBody
7/10/2003 ICPP-HPSECA03 59
Effect of Adaptive Object Effect of Adaptive Object Home Migration (SOR)Home Migration (SOR)
0
10000
20000
30000
40000
50000
60000
70000
80000
2 4 8
node number
Tim
e (
in m
s) Disable adaptive
object homemigration
Enable adaptiveobject homemigration

7/10/2003 ICPP-HPSECA03 60
Work in ProgressWork in Progress
• New optimization techniques for GOS
• Incremental Distributed GC
• Load balancing module
• Enhanced single I/O space to benefit more real-life applications
• Parallel I/O support

7/10/2003 ICPP-HPSECA03 61
ConclusionConclusion
• Effective HPC for the mass– They supply the (parallel) program, system does the rest– Let’s hope for parallelizing compilers– Small to medium grain programming– SSI the ideal– Java the choice– Poor man mode too
• Thread distribution and migration feasible• Overhead reduction
– Advances in low-latency networking– Migration as intrinsic function (JVM, OS, hardware)
• Grid and pervasive computing

7/10/2003 ICPP-HPSECA03 62
Some PublicationsSome Publications• W.Z. Zhu , C.L. Wang, and F.C.M. Lau, “A Lightweight Solution for
Transparent Java Thread Migration in Just-in-Time Compilers”, ICPP 2003, Taiwan, October 2003.
• W.J. Fang, C.L. Wang, and F.C.M. Lau, “On the Design of Global Object Space for Efficient Multi-threading Java Computing on Clusters”, Parallel Computing, to appear.
• W.Z. Zhu , C.L. Wang, and F.C.M. Lau, “JESSICA2: A Distributed Java Virtual Machine with Transparent Thread Migration Support,” CLUSTER 2002, Chicago, September 2002, 381-388.
• R. Ma, C.L. Wang, and F.C.M. Lau, “M-JavaMPI : A Java-MPI Binding with Process Migration Support,'' CCGrid 2002, Berlin, May 2002.
• M.J.M. Ma, C.L. Wang, and F.C.M. Lau, “JESSICA: Java-Enabled Single-System-Image Computing Architecture,’’ Journal of Parallel and Distributed Computing, Vol. 60, No. 10, October 2000, 1194-1222.

7/10/2003 ICPP-HPSECA03 63
THE ENDAnd Thanks!







