
TCP & Data Center Networking
• TCP & Data Center Networking: Overview• TCP Incast Problem & Possible Solutions• DC-TCP • MPTCP (multipath TPC)
• Please read the following papers [InCast] [DC-TCP] [MPTCP]
1CSci5221: TCP and Data Center Networking

TCP Congestion Control: Recap• Designed to address network congestion problem
– reduce sending rates when network conges• How to detect network congestion at end systems?
– Assume packet losses (& re-ordering) network congestion
• How to adjust sending rates dynamically?– AIMD (additive increase & multiplicative decrease):
• no packet loss in one RTT: W W+1• packet loss in one RTT: W W/2
• How to determine the initial sending rates?– probe the network available bandwidth via “slow
start”• W:=1; no loss in one RTT: W 2W
• Fairness: assume everyone will use the same algorithm
2

TCP Congestion Control: Devils in the Details
• How to detect packet losses? – e.g., as opposed to late-arriving packets? – estimate (average) RTT times, and set a time-out threshold
• called RTO (Retransmission Time-Out) timer• packets arriving very late are treated as if they were
lost!
• RTT and RTO estimations: Jacobson’s algorithm • Compute estRTT and devRTT using exponential
smoothing:• estRTT := (1-a)estRTT + sampleRTT (a>0 small, e.g.,
a=0.125)• devRTT:=(1-a)devRTT + a|sampleRTT-devRTT|
• Set RTO conservatively:• RTO:= max{minRTO, estRTT + 4xdevRTT}
where minRTO = 200 ms
• Aside: many variants of TCP: Tahoe, Reno, Vegas, ...
3

4
But ….
Internet vs. data center network: Internet propagation delay: 10-100 ms data center propagation delay: 0.1 ms
• packet size 1 KB, link capacity 1 Gbps packet transmission time is 0.01 ms

5
What Special about Data Center Transport
Application requirements (particularly, low latency)
Particular traffic patterns• customer facing vs. internal: often co-exist• internal: e.g.,
• Google file system• Map-Reduce • …
Commodity switches: shallow buffer
And time is money!
6
TLA
MLAMLA
Worker Nodes
………
How does search work?
Picasso
“Everything you can imagine is real.”“Bad artists copy. Good artists steal.”
“It is your work in life that is the ultimate seduction.“
“The chief enemy of creativity is good sense.“
“Inspiration does exist, but it must find you working.”“I'd like to live as a poor man
with lots of money.““Art is a lie that makes us
realize the truth.“Computers are useless.
They can only give you answers.”
1.
2.
3.
…..
1. Art is a lie…
2. The chief…
3.
…..
1.
2. Art is a lie…
3. …
..Art is…
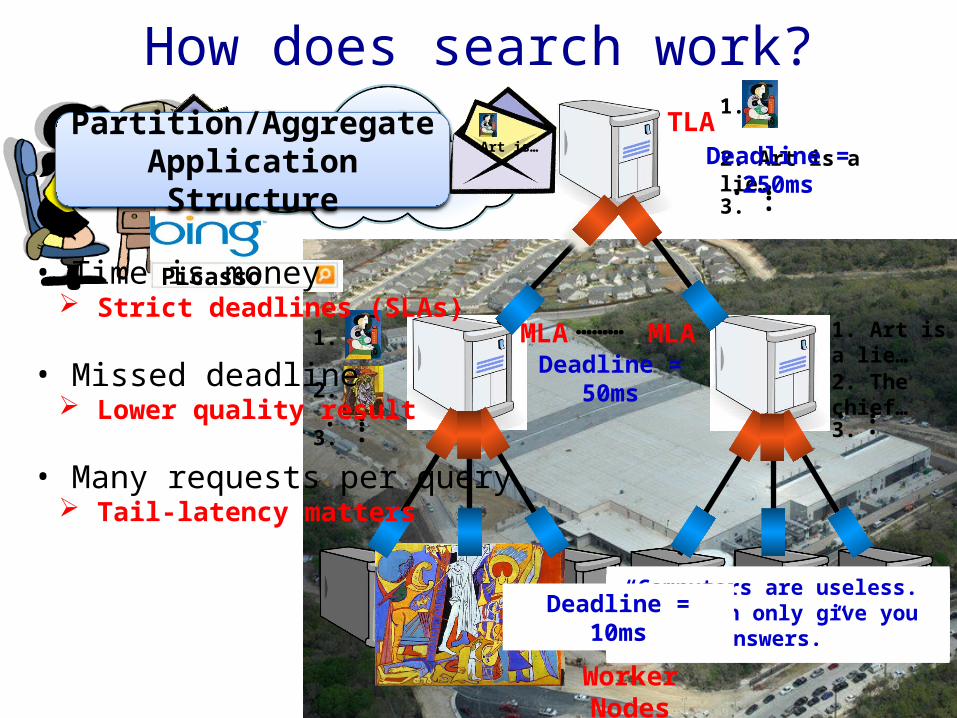
Picasso• Time is money Strict deadlines (SLAs)
• Missed deadline Lower quality result
• Many requests per query Tail-latency matters
Deadline = 250ms
Deadline = 50ms
Deadline = 10ms
Partition/Aggregate Application Structure

• Partition/Aggregate
(Query)
• Short messages [50KB-1MB] (Coordination, Control state)
• Large flows [1MB-100MB] (Data update)
Bursty, Delay-sensitive
Delay-sensitive
Throughput-sensitive
Data Center Workloads
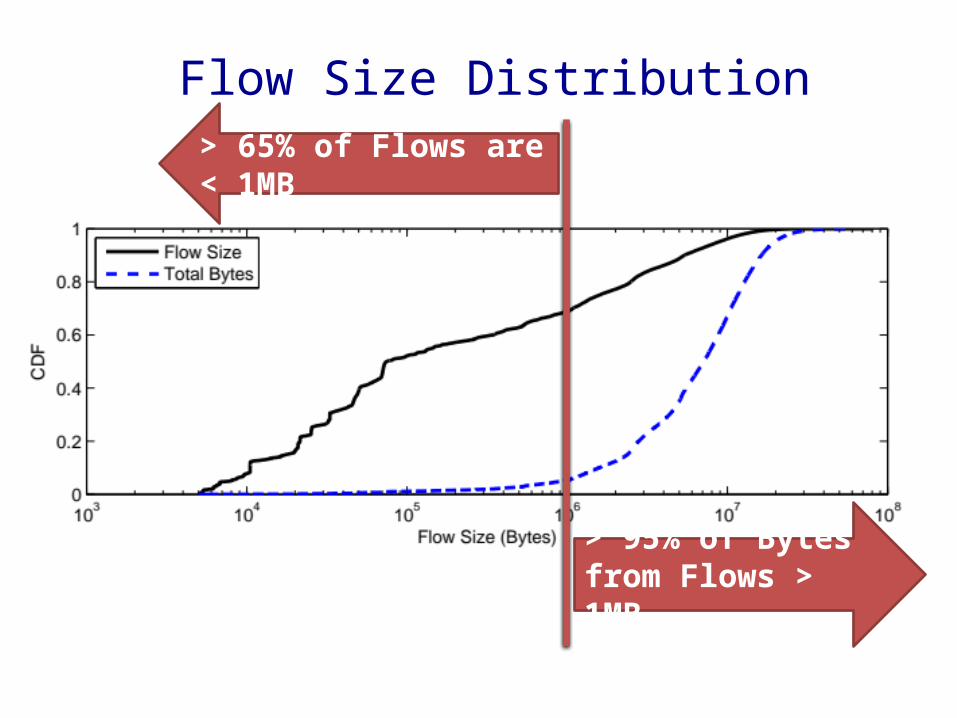
Flow Size Distribution
> 65% of Flows are < 1MB
> 95% of Bytes from Flows > 1MB

9
A Simple Data Center Network Model
N servers
1
2
3
N
packet size S_DATA
small buffer B
link capacity Cswitch
aggregator
Round Trip Time (RTT): 100-10us
Ethernet: 1-10Gbps
Logical
data block
(S)
(e.g., 1 MB)
Server
Request
Unit
(SRU)
(e.g., 32 KB)
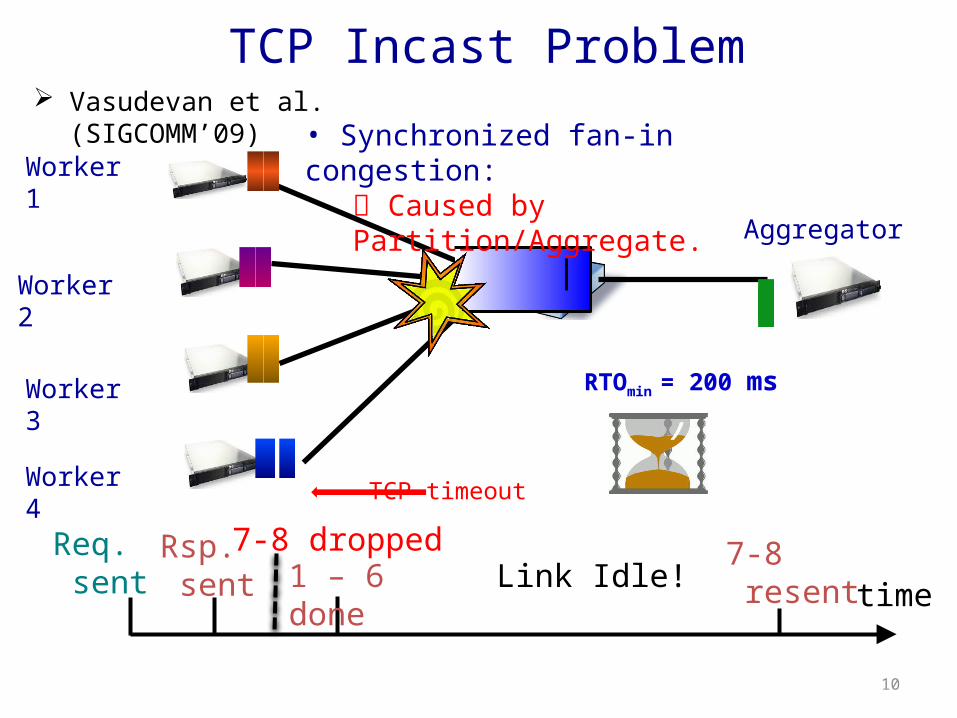
TCP timeout
Worker 1
Worker 2
Worker 3
Worker 4
Aggregator
RTOmin = 200 ms
• Synchronized fan-in congestion: Caused by Partition/Aggregate.
10
TCP Incast Problem Vasudevan et al. (SIGCOMM’09)
time
Req. sent
Rsp. sent
7-8 dropped 7-8 resent1 – 6 done Link Idle!

TCP Throughput Collapse
Collapse!
Cluster Setup
1Gbps Ethernet
Unmodified TCP
S50 Switch
1MB Block Size
TCP Incast • Cause of throughput collapse:
coarse-grained TCP timeouts

MLA
Qu
ery
Com
ple
tion
Tim
e
(ms)
12
Incast in Bing
1313
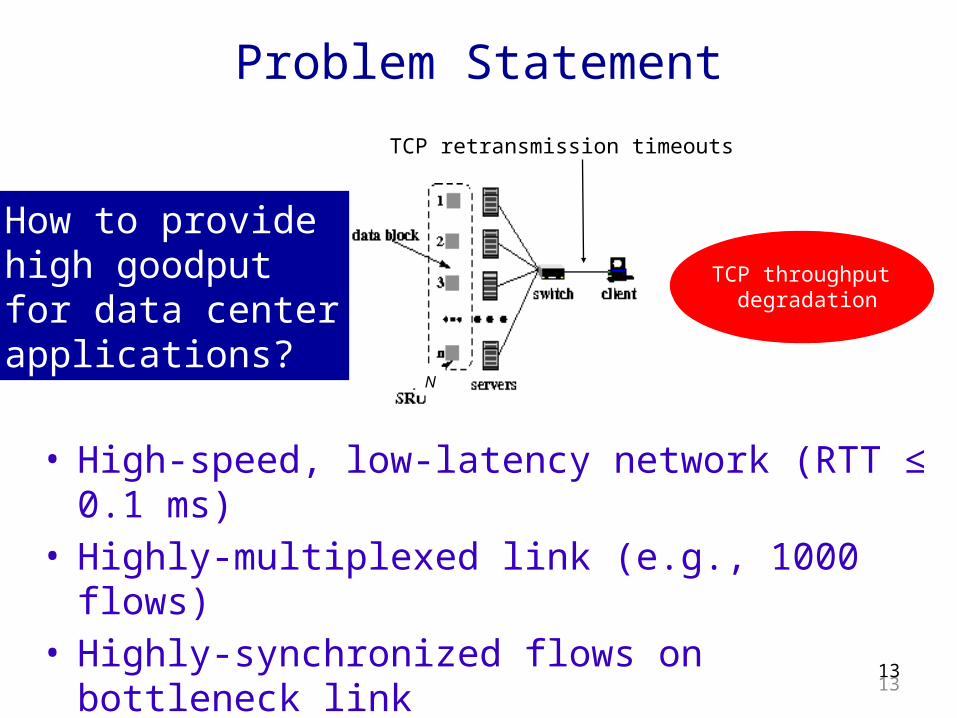
Problem Statement
• High-speed, low-latency network (RTT ≤ 0.1 ms)
• Highly-multiplexed link (e.g., 1000 flows)• Highly-synchronized flows on bottleneck link• Limited switch buffer size (e.g., 32 KB)
How to provide high goodputfor data centerapplications?
TCP retransmission timeouts
TCP throughput degradation
N

µsecond Retransmission Timeouts (RTO)
RTO = max( minRTO, f(RTT) )
200ms
200µs?
0?
RTT tracked in milliseconds
Track RTT in µsecond
One Quick Fix: µsecond TCP + no minRTO
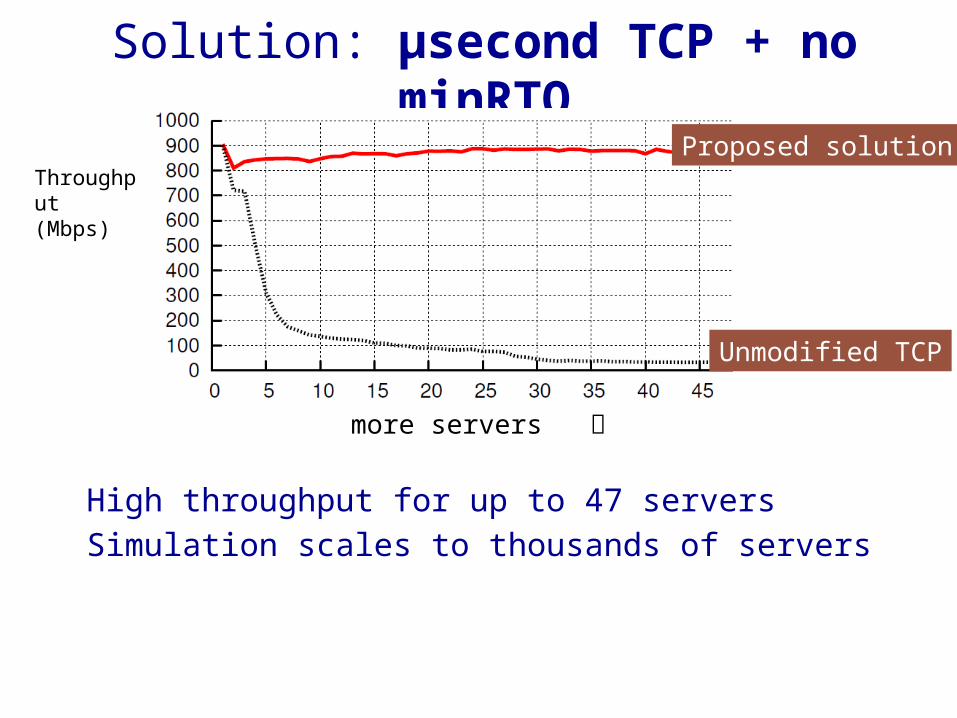
Solution: µsecond TCP + no minRTO
more servers
High throughput for up to 47 serversSimulation scales to thousands of servers
Throughput(Mbps)
Unmodified TCP
Proposed solution

16
TCP in the Data Center
• TCP does not meet demands of applications.– Requires large queues for high throughput:
Adds significant latency. Wastes buffer space, esp. bad with shallow-buffered
switches.
• Operators work around TCP problems.‒ Ad-hoc, inefficient, often expensive solutions‒ No solid understanding of consequences,
tradeoffs

• Partition/Aggregate
(Query)
• Short messages [50KB-1MB] (Coordination, Control state)
• Large flows [1MB-100MB] (Data update)
Bursty, Delay-sensitive
Delay-sensitive
Throughput-sensitive
Data Center Workloads

Flow Size Distribution
> 65% of Flows are < 1MB
> 95% of Bytes from Flows > 1MB

Sender 1
Send 2
Receiver
• Large flows buildup queues. Increase latency for short flows.
• Measurements in Bing cluster For 90% packets: RTT < 1ms For 10% packets: 1ms < RTT <
15ms
19
Queue Buildup
How was this supported by measurements?

Data Center Transport Requirements
1. High Burst Tolerance– Incast due to Partition/Aggregate is common.
2. Low Latency– Short flows, queries
3. High Throughput – Continuous data updates, large file transfers
20
The challenge is to achieve these three together.

React in proportion to the extent of congestion.• Reduce window size based on fraction of marked
packets.
21
ECN Marks TCP DCTCP
1 0 1 1 1 1 0 1 1 1 Cut window by 50% Cut window by 40%
0 0 0 0 0 0 0 0 0 1 Cut window by 50% Cut window by 5%
DCTCP: Main Idea

DCTCP: Algorithm
Switch side:– Mark packets when Queue Length >
K.
Sender side:– Maintain running average of fraction of packets marked
(α).
- Adaptive window decreases:
Note: decrease factor between 1 and 2.
BK
Mark
Don’t Mark
each RTT : F # of marked ACKs
Total # of ACKs (1 g) gF
W (12
)W
22

23
Setup: Win 7, Broadcom 1Gbps SwitchScenario: 2 long-lived flows,
(Kbyte
s)
ECN Marking Thresh = 30KB
DCTCP vs TCP

In a data center with rich path diversity (e.g., Fat-Tree or Bcube), can we use multipath to get higher throughput?
Initially, there is one flow.
Multi-path TCP (MPTCP)
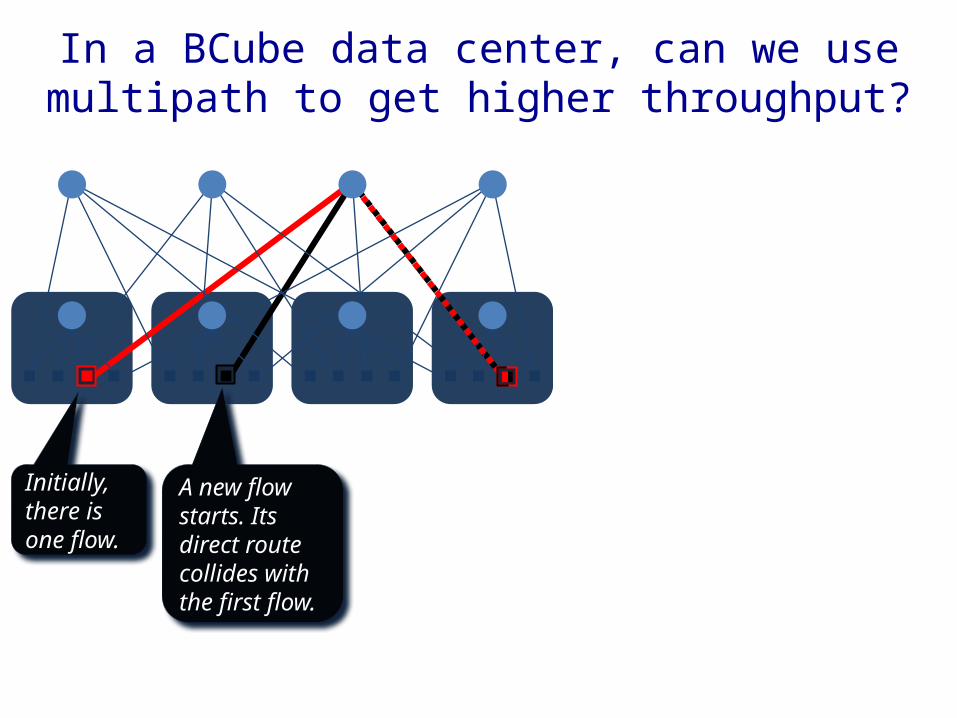
In a BCube data center, can we use multipath to get higher throughput?
Initially, there is one flow.
A new flow starts. Its direct route collides with the first flow.

In a BCube data center, can we use multipath to get higher throughput?
Initially, there is one flow.
A new flow starts. Its direct route collides with the first flow.
But it also has longer routes available, which don’t collide.

The MPTCP protocolMPTCP is a replacement for TCP which lets you use
multiple paths simultaneously.
TCP
IP
user spacesocket API
MPTCP MPTCP
addr1addr2addr
The sender stripes packets across paths
The receiver puts the packets in the correct order
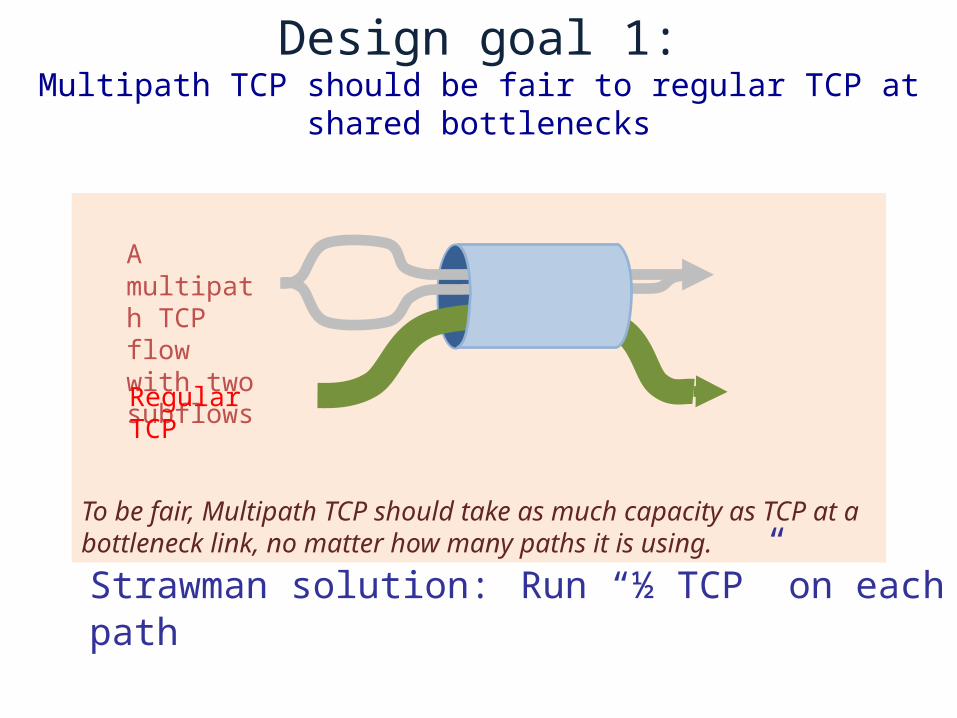
Design goal 1:Multipath TCP should be fair to regular TCP at shared
bottlenecks
To be fair, Multipath TCP should take as much capacity as TCP at a bottleneck link, no matter how many paths it is using.
Strawman solution: Run “½ TCP” on each path
A multipath TCP flow with two subflows
Regular TCP
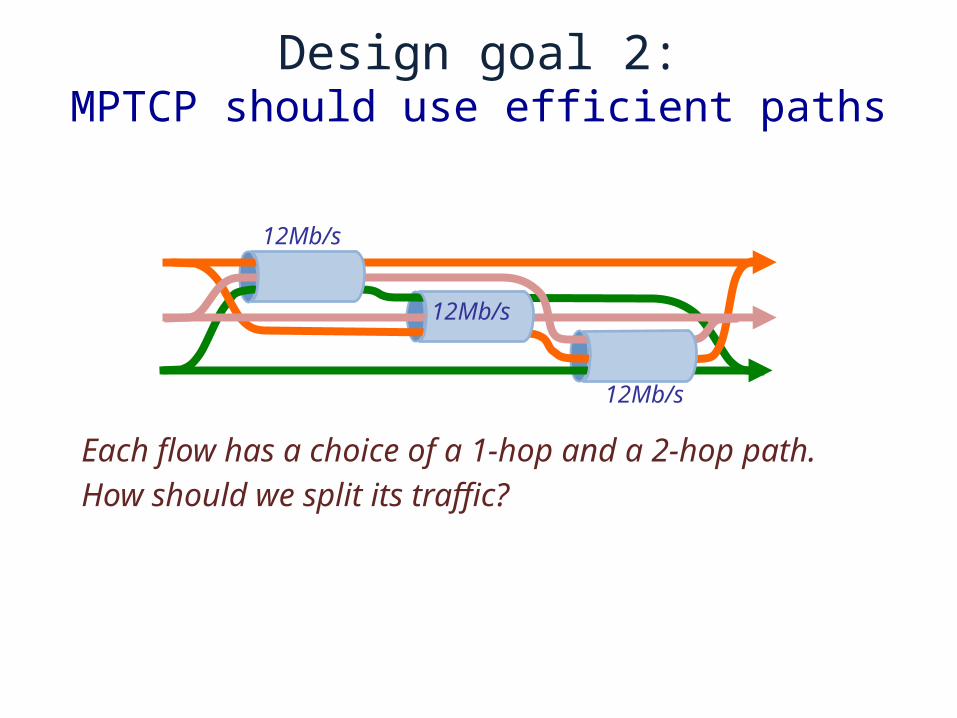
Design goal 2:MPTCP should use efficient paths
Each flow has a choice of a 1-hop and a 2-hop path.
How should we split its traffic?
12Mb/s
12Mb/s
12Mb/s

Design goal 2:MPTCP should use efficient paths
If each flow split its traffic 1:1 ...
8Mb/s
8Mb/s
8Mb/s
12Mb/s
12Mb/s
12Mb/s
Design goal 2:MPTCP should use efficient paths
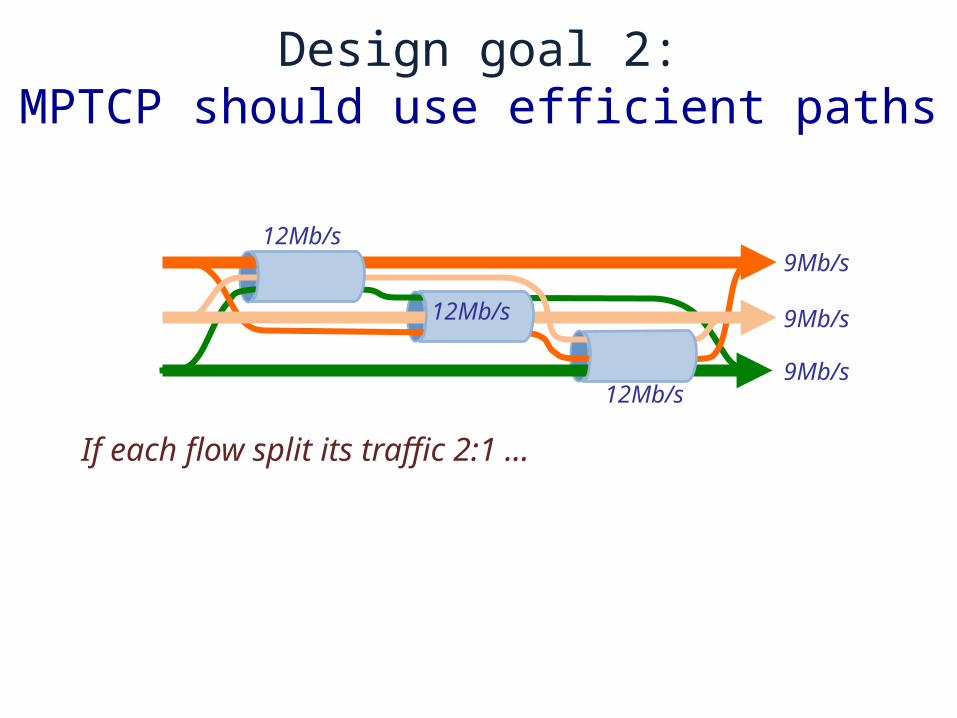
If each flow split its traffic 2:1 ...
9Mb/s
9Mb/s
9Mb/s
12Mb/s
12Mb/s
12Mb/s

Design goal 2:MPTCP should use efficient paths
If each flow split its traffic 4:1 ...
10Mb/s
10Mb/s
10Mb/s
12Mb/s
12Mb/s
12Mb/s
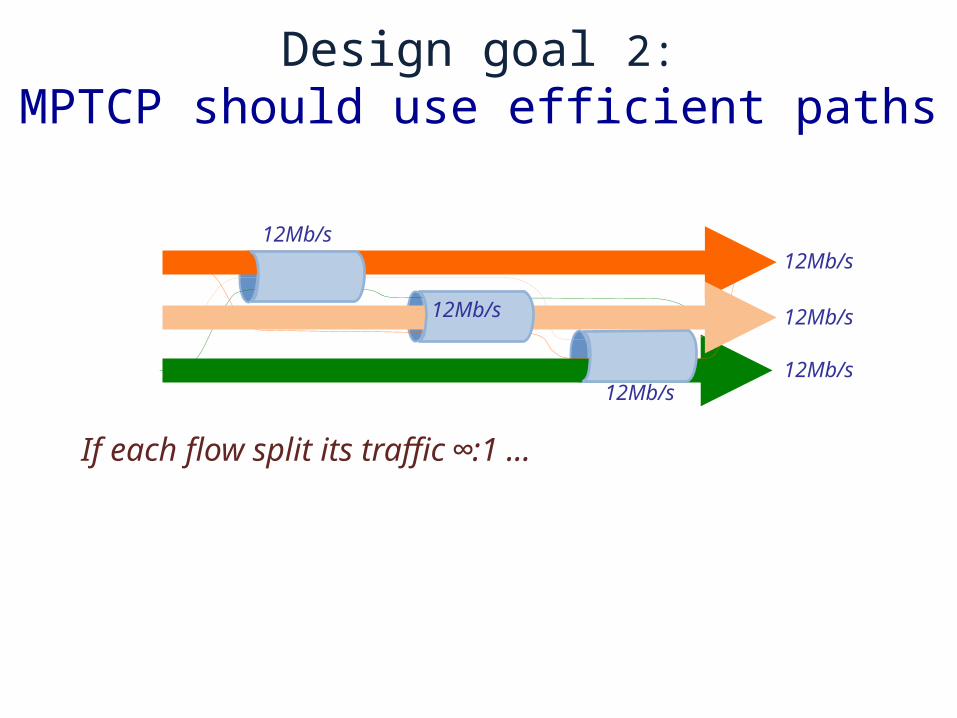
Design goal 2:MPTCP should use efficient paths
If each flow split its traffic ∞:1 ...
12Mb/s
12Mb/s
12Mb/s
12Mb/s
12Mb/s
12Mb/s

Design goal 2:MPTCP should use efficient paths
12Mb/s
12Mb/s
12Mb/s
12Mb/s
12Mb/s
12Mb/s
Theoretical solution (Kelly+Voice 2005; Han, Towsley et al. 2006)
Theorem: MPTCP should send all its traffic on its least-congested paths.
This will lead to the most efficient allocation possible, given a network topology and a set of available paths.

Design goal 3:MPTCP should be fair compared to TCP
Design Goal 2 says to send all your traffic on the least congested path, in this case 3G. But this has high RTT, hence it will give low throughput.
wifi path: high loss, small RTT
3G path: low loss, high RTT
Goal 3a. A Multipath TCP user should get at least as much throughput as a single-path TCP would on the best of the available paths.
Goal 3b. A Multipath TCP flow should take no more capacity on any link than a single-path TCP would.

Design goals
Goal 1. Be fair to TCP at bottleneck linksGoal 2. Use efficient paths ...Goal 3. as much as we can, while being fair to TCPGoal 4. Adapt quickly when congestion changesGoal 5. Don’t oscillate
How does MPTCP try to achieve all this?
redundant

How does MPTCP congestion control work?
Maintain a congestion window wr, one window for each path, where r ∊ R ranges over the set of available paths.
- Increase wr for each ACK on path r, by
- Decrease wr for each drop on path r, by wr /2

How does MPTCP congestion control work?Maintain a congestion window wr, one window for each path, where r ∊ R ranges over the set of available paths.
- Increase wr for each ACK on path r, by
- Decrease wr for each drop on path r, by wr /2
Design goal 3:At any potential bottleneck S that path r might be in, look at the best that a single-path TCP could get, and compare to what I’m getting.

How does MPTCP congestion control work?
Maintain a congestion window wr, one window for each path, where r ∊ R ranges over the set of available paths.
- Increase wr for each ACK on path r, by
- Decrease wr for each drop on path r, by wr /2
Design goal 2:We want to shift traffic away from congestion.
To achieve this, we increase windows in proportion to their size.

MPTCP chooses efficient paths in a BCube data center, hence it gets high
throughput.
Initially, there is one flow.
A new flow starts. Its direct route collides with the first flow.
But it also has longer routes available, which don’t collide.
MPTCP shifts its traffic away from the congested link.

MPTCP chooses efficient paths in a BCube data center, hence it gets high throughput.
Packet-level simulations of BCube (125 hosts, 25 switches, 100Mb/s links) and measured average throughput, for three traffic matrices.
For two of the traffic matrices, MPTCP and ½ TCP (strawman) were as good. For one of the traffic matrices, MPTCP got 19% higher throughput.
0
50
100
150
200
250
300
½ TCPMPTCP
perm. traffic matrix
sparse traffic matrix
local traffic matrix
throughput [Mb/s]

42







