
Tackling the Big Data Deluge in Science with Metadata
The term “Big Data” has become virtually synonymous with “schema on read” (where data is applied to
a plan or schema as it is ingested or pulled out of a stored location) unstructured data analysis and
handling techniques like Hadoop. These “schema on read” techniques have been most famously
exploited on relatively ephemeral human-readable data like retail trends, twitter sentiment, social
network mining, log files, etc.
But what if you have unstructured data that, on its own, is hugely valuable, enduring, and created at
great expense? Data that may not immediately be human readable or indexable on search? Exactly the
kind of data most commonly created and analyzed in science and HPC. Research institutions are awash
with such data from large-scale experiments and extreme-scale computing that is used for high-
consequence applications. As the recent DOE High Performance Computing Operational Review 20141
noted:
“The value and cost of data relative to computation is growing and, with it, a recognition that concerns such as reproducibility, provenance, curation, unique referencing, and future availability are going to become the rule rather than the exception in scientific communities.” “Schema on write” (where data is mapped to a plan or schema when it is written) metadata centric data
analysis and handling techniques are critical to meeting research goals of ensuring data consistency and
trustworthiness along with being the only techniques capable of meeting these scientific concerns of
data identification, access, reproducibility, provenance, curation, unique referencing, and future data
availability. In fact, a case can be made that metadata-based techniques are the most valuable “Big
Data” analysis and handling techniques in scientific computing and HPC.
Increased sensor resolution from more and more sequencers, cameras, microscopes, telescopes,
scanners and instruments of all types are driving a deluge in scientific data. And while today’s high
capacity scale-out file and object storage systems can accommodate the sheer volume of data
produced, they can’t help identify what data is valuable or how to move and process that data through a
global workflow, sharing it securely with geographically dispersed collaborators. Or how to make sure
that data is authentic and unaltered. Reducing the cost of storing increasingly immense datasets is
paramount. Cost effectively managing and ensuring continued access to valuable data, is critical to
driving results and new discovery. The alternative is that important scientific data becomes effectively
lost forever, even as more and more data is being stored.
1 “DOE High Performance Computing Operational Review (HPCOR) Enabling Data-Driven Scientific Discovery at
DOE HPC Facilities”, www.nersc.gov/assets/HPCOR/HPCOR-Data-2014.pdf

Tackling the Big Data Deluge in Science with Metadata 2
Metadata is the Key
Metadata is the key to keeping track of all this unstructured scientific data. Metadata is “data about
data.” In the case of scientific data, metadata is structured data (written in a prescribed schema or
order) that describes what the data is, how it was derived, and where it is located.
Metadata makes scientific data easy to find, track, share, move and manage – at low cost.
Unfortunately, today’s high capacity storage systems only provide bare bones system metadata
consisting of as little as file name, owner and creation/access timestamps. Data intensive scientific
workflows need supplemental enhanced metadata, along with access rights and security safeguards.
Workflow constituents can then find and access valuable data by querying such extensive metadata.
With the increasing data deluge across all scientific domains, rich workflow specific metadata is essential
to enable collaborators to find and share valuable data crucial to their endeavors.
Key Benefits of Metadata in Scientific Computing
Eliminate “Data Junkyards”
Keep track of, and never lose, valuable data
Access and manage data on any storage device, anywhere in the world
Orchestrate global data intensive workflows, achieving faster time to results
Maintain data provenance, audit, security, and access control
Reduce storage costs
Metadata can now be easily exploited in a wide range of scientific data intensive workflows in life
sciences, government, energy exploration and media & entertainment with the metadata creation and
management facilities of the broadly deployable General Atomics Nirvana Metadata Centric Intelligent
Storage System. Nirvana is a software product that works with existing storage systems and is
developed by the General Atomics Magnetic Fusion Energy and Advanced Concepts group in San Diego,
California from a joint effort with the San Diego Supercomputing Center’s Storage Resource Broker
(SRB). Without an application-specific metadata management system like Nirvana, researchers will likely
spend most of their time just looking for data, instead of exploiting that data to accelerate discovery.
Eliminating “Data Junkyards”
Today’s high capacity scale out file (GPFS, Lustre, Isilon) and object (Cleversafe, WOS, Amplidata) storage
systems make it easy to store tremendous quantities of data. As a result, many organizations are
accumulating “Data Junkyards” consisting of tens of millions of files from hundreds of past and present
users accumulating for years with no way of identifying their technical or business value. And because
there is no detailed description of what the data consists of, organizations are afraid to remove any of it.
And as capacity is exhausted the only solution seems to be repeatedly purchase additional storage. This
is shown in the figure on the next page. Look familiar?

Tackling the Big Data Deluge in Science with Metadata 3
Reducing storage costs by removing data that’s no longer needed with Nirvana
Perhaps not too surprisingly, storage vendors provide no tools to evaluate what is being stored, and
analyzing the Data Junkyard by hand is hopeless. Running scanning scripts over millions of files can take
days and slows the production file system. But what if you had a tool that could extract a simple
inventory of the Data Junkyard in to a separate database explicitly designed for fast query and analysis?
Using existing storage system metadata, General Atomics Nirvana can inventory Data Junkyards,
characterizing the data according to size, owner, when last accessed, etc. Nirvana exposes what types of
files are being stored and usage trends, by file type and user. Nirvana shows how much storage is
consumed by duplicate, temporary or improper files types. With this information, administrators and
managers can decide what data to keep, move or even delete.
How it Works
Nirvana is a metadata management and file tracking system that inventories the Data Junkyard using a
relational database explicitly designed for fast query and analysis. Nirvana performs background scans
on Data Junkyard file systems and records its findings in the Nirvana Metadata Catalog. Administrators
can quickly formulate and execute queries and reports over the entire catalog with no performance
impact on the production file system. Nirvana identifies what data is valuable and reduces the cost of
storing data, by keeping only what is needed. How many files are there? Who owns how many of what
types of files? How old are they? When was the last time they were used? Nirvana builds up
information to answer those questions and more, and provides information to justify data retention
policies and provides continuing analysis of storage consumption.

Tackling the Big Data Deluge in Science with Metadata 4
With Nirvana’s reports, retention policies can be formulated and applied across all users. Files that are
important to keep, but not current, can be moved off to lower cost storage, violations of storage policy
can be detected, and terabytes of unused and unwanted data can be cleaned away. The need to buy
additional expensive storage, because you do not know what else to do, is no longer necessary.
General Atomics Fusion Research stores key research data on expensive, enterprise class storage. Data
growth necessitated the purchase of even more expensive storage. Nirvana was used to characterize the
data stored and found that 65% of data stored wasn’t accessed for years, multiple copies of the same
data were found and one user generated over 80% of the files, limiting storage system performance.
With this analysis in hand, superfluous data was removed, eliminating the need to buy more storage.
Keeping Track of Valuable Data
Like a needle in a haystack, high value data stored in large scale storage systems can be effectively lost
over time – losing its value forever. Nirvana prevents this by creating and exploiting detailed, additional,
application-specific metadata about data valuable to all stakeholders. Data can be discovered and
accessed through an object’s attributes such as creation date, size, frequency of access, author,
keywords, projects, devices and more. With Nirvana, valuable information can be found and analyzed
even if it resides on very different, incompatible, platforms anywhere in the world. Nirvana can execute
complex queries for quick and simple data discovery and also generate summary reports characterizing
large data collections. The following figure illustrates standard storage file system metadata and
example application-specific (in this case, genome sequencing) metadata added with Nirvana.
Nirvana example comprehensive application-specific (genomics) metadata

Tackling the Big Data Deluge in Science with Metadata 5
Orchestrating Global Data Intensive Workflows; Access and Manage Data on any Storage
Device, Anywhere in the World
With collaborative scientific research done on a global scale, today’s data intensive workflows are
geographically dispersed, spanning multiple storage tiers across many vendor’s storage devices – over
multiple administrative domains among different organizations. By presenting a single global namespace
across any storage device, anywhere in the world, Nirvana allows data to be easily and securely shared
among globally distributed teams. Nirvana also automatically moves data to various workflow resources,
based on policies, so data is always available at the right place, at the right time, and at the right cost ―
while keeping an audit trail as data is ingested, transformed, accessed, and archived through its
complete lifecycle. Nirvana can also create multiple copies of the data to be stored at multiple locations
for extra data protection and disaster recovery. Nirvana global workflow orchestration is showing in the
following figure.
Nirvana orchestrates global data intensive workflows

Tackling the Big Data Deluge in Science with Metadata 6
Data Provenance
Provenance (from the French provenir, "to come from"), is the chronology of the ownership, custody or
location of a historical object in order to verify its authenticity. In the context of electronic data,
provenance is the information on how data was created, accessed and processed throughout its
processing pipeline and workflow. In many fields, data sets are useless without knowing the exact
provenance and processing pipeline used to produce derived results. Nirvana tracks data within
workflows, through all transformations, analyses, and interpretations, ensuring data authenticity. With
Nirvana, data is optimally managed, shared, and reused with verified provenance of the data and the
conditions under which it was generated – so results are reproducible and analyzable for defects.
An example of how provenance is used in genomics research2 is shown in the figure below. The
provenance of the genomics data produced is a record of all the hardware components (sequencer,
computers) and software (including version) used in the processing pipeline (base conversion,
alignment, pre-processing and variant analysis) to create the final data product. Provenance is
essentially like hitting the “record” button during the process, so derived results can be authenticated
and reproduced as needed. Provenance metadata is stored in the Nirvana Metadata Catalog (MCAT) so
it can be queried and validated.
Genomics sequencing processing and data provenance metadata
2 “IBM Reference Architecture for Genomics Brings Power to Research”, Frank Lee, Ph.D., IBM Systems Magazine,
August 2014, http://www.ibmsystemsmag.com/power/trends/ibmresearch/reference-architecture-genomics

Tackling the Big Data Deluge in Science with Metadata 7
Audit, Security, and Access Control
Nirvana can audit every transaction within a workflow with automated metadata capture and
amendment. An audit trail can contain information such as date of transaction, success or error code,
user performing transaction, type of transaction, and notes. Audit trails, like everything else with
Nirvana, can be easily queried and filtered.
Nirvana maintains multiple authentication mechanisms for access to data and metadata. Nirvana
creates access control lists for every user-level metadata attribute, ensuring a high level of security.
Single-sign-on and access through one common set of APIs, LDAP or Active Directory provide for
complete access transparency. Data can only be viewed and modified by users authorized to do so.
Nirvana enforces authentication to protect data through Challenge Response Mechanism, Grid Security
Infrastructure - GSI, and Kerberos. Support is also built in for data encryption through GSI and Kerberos.
Reducing Storage Costs
Nirvana restrains the cost of data growth four ways:
Nirvana helps prevent worthless data from entering the workflow and being stored.
Nirvana migrates data to lower cost storage tiers using workflow policies, not just file policies.
Nirvana removes data that’s no longer valuable.
Nirvana consolidates and automates complete data lifecycle management.
The best way to avoid unwanted data to accumulate is to prevent its introduction into the workflow in
the first place. Nirvana can help make sure data ingested is valuable and usable by utilizing metadata
information about instrument conditions, configuration, data quality, error rates and missing elements
to decide whether to store ingested data.
Nirvana also reduces storage costs by orchestrating the migration of data to lower cost storage – from
multiple vendors – with automated data life cycle management incorporating detailed workflow
policies, not just file policies, for data migration, retention and disposal. For example, data associated
with a specific project or person that hasn’t been accessed in a year could be migrated, or even deleted.
Nirvana can consolidate and lower management costs by migrating data from multiple distributed
locations to one central archive storage system. Data can be analyzed and managed, no matter where
it’s located. Backup or migration from a local administrative domain can be done centrally, enterprise-
wide with Nirvana. And all this happens behind the scenes, transparent to users and applications.

Tackling the Big Data Deluge in Science with Metadata 8
Nirvana Components
Show in the figure below, the heart of Nirvana is the Metadata Catalog (MCAT) which implements the
Global Namespace and maps data objects to Storage Resources. MCAT metadata is stored in a relational
database such as Postgres or Oracle to support fast, efficient queries. A Storage Resource is any File or
Object Storage System, located anywhere in the world. Location Agents directly access Storage
Resources. The Nirvana Client allows the user to interact with the MCAT and Location Agents via
Browser GUI, Java, Python or custom SDK. Files can also be viewed and accessed as familiar Windows
and Linux folders and files through Nirvana. Nirvana can linearly scale Storage Resources horizontally.
Multiple MCATS can be deployed to ensure uninterrupted operation and disaster recovery.
Nirvana components
A Comprehensive, Affordable, Easily Deployed, Fully Supported Solution
General Atomics developed Nirvana in a joint effort with the San Diego Supercomputing Center
leveraging successful methods proven in data intensive multinational “Big Science” research. Nirvana
responds to the needs of researchers in collaborative projects to share access to data on remote
heterogeneous storage systems as part of a global workflow. Nirvana is a comprehensive, easily
deployed solution with enhanced metadata capabilities, bolstering advanced data discovery. Nirvana is
tuned for performance and scalability focusing on secure operation, ease of use, ease of
administration, and reliability. Nirvana is fully supported, ensuring our customer’s success.

Tackling the Big Data Deluge in Science with Metadata 9
About General Atomics
General Atomics (“GA”) and its affiliated companies constitute one of the world's leading resources for
high-technology systems ranging from electromagnetic systems, remotely operated surveillance aircraft,
airborne sensors, and advanced electronic, wireless and laser technologies. GA carries out the largest
and most successful nuclear fusion program in private industry.
For More Information
www.ga.com/nirvana
Phone: +1 866.312.8896
Email: [email protected]
Tackling the Big Data Deluge in Science with Metadata 10
Technical Data
Nirvana is a distributed application - the multiple software components (daemon services and user-
launched clients) communicate across network connections within or between computer hosts to
implement and coordinate Nirvana functions. Each of the component types has a supported set of host
environments (operating system and processor hardware) on which they can be installed and operate.
The Nirvana clients interact with the user via GUI or command line and with their host’s filesystems to
send client host data to an Agent, receive data from an Agent and write it locally to the client host, and
for local logging. The Nirvana Agents interact with their host’s filesystems for logging and typically use
some portion as Nirvana Storage Resources, and interact with data-stores external to their host such as
object store systems and relational databases and even remote from their host such as SFTP sites and
Amazon S3. The Nirvana Metadata Catalog program utilizes a ‘back-end’ database consisting of a
standard relational database. Since the database can run on a separate server from the Metadata
Catalog, its host environment is not important to Nirvana.
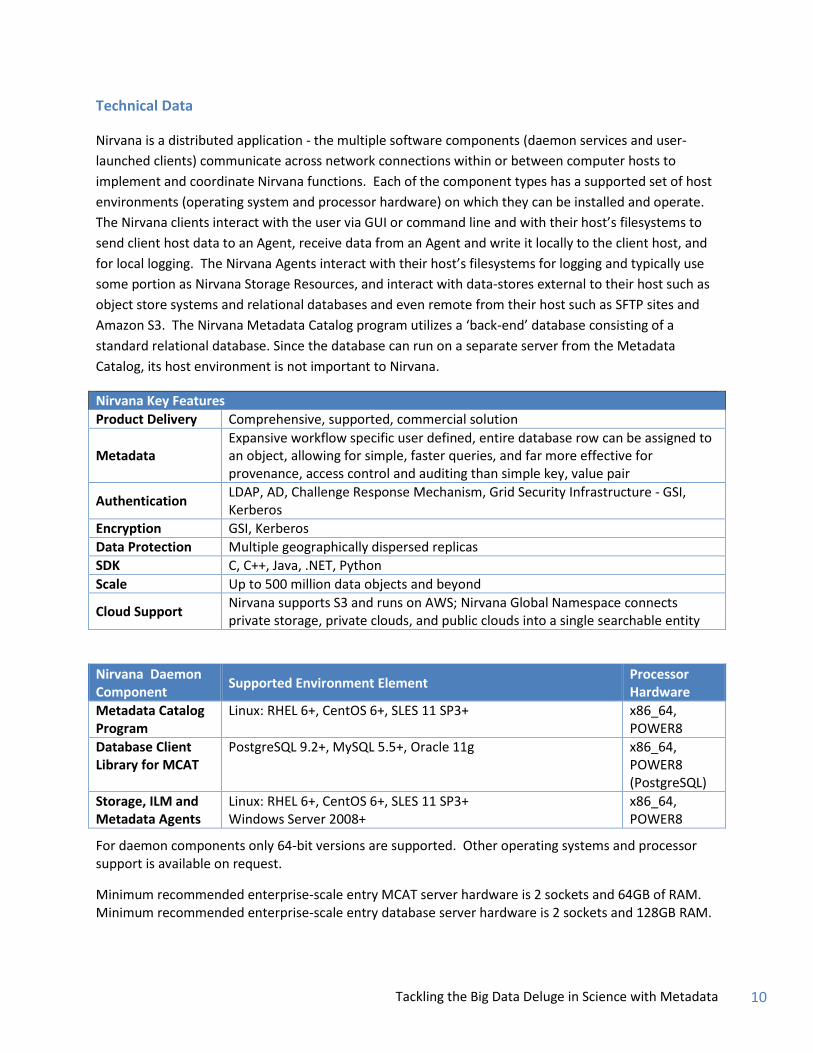
Nirvana Key Features
Product Delivery Comprehensive, supported, commercial solution
Metadata Expansive workflow specific user defined, entire database row can be assigned to an object, allowing for simple, faster queries, and far more effective for provenance, access control and auditing than simple key, value pair
Authentication LDAP, AD, Challenge Response Mechanism, Grid Security Infrastructure - GSI, Kerberos
Encryption GSI, Kerberos
Data Protection Multiple geographically dispersed replicas
SDK C, C++, Java, .NET, Python
Scale Up to 500 million data objects and beyond
Cloud Support Nirvana supports S3 and runs on AWS; Nirvana Global Namespace connects private storage, private clouds, and public clouds into a single searchable entity
Nirvana Daemon Component
Supported Environment Element Processor Hardware
Metadata Catalog Program
Linux: RHEL 6+, CentOS 6+, SLES 11 SP3+ x86_64, POWER8
Database Client Library for MCAT
PostgreSQL 9.2+, MySQL 5.5+, Oracle 11g x86_64, POWER8 (PostgreSQL)
Storage, ILM and Metadata Agents
Linux: RHEL 6+, CentOS 6+, SLES 11 SP3+ Windows Server 2008+
x86_64, POWER8
For daemon components only 64-bit versions are supported. Other operating systems and processor support is available on request.
Minimum recommended enterprise-scale entry MCAT server hardware is 2 sockets and 64GB of RAM. Minimum recommended enterprise-scale entry database server hardware is 2 sockets and 128GB RAM.
Tackling the Big Data Deluge in Science with Metadata 11
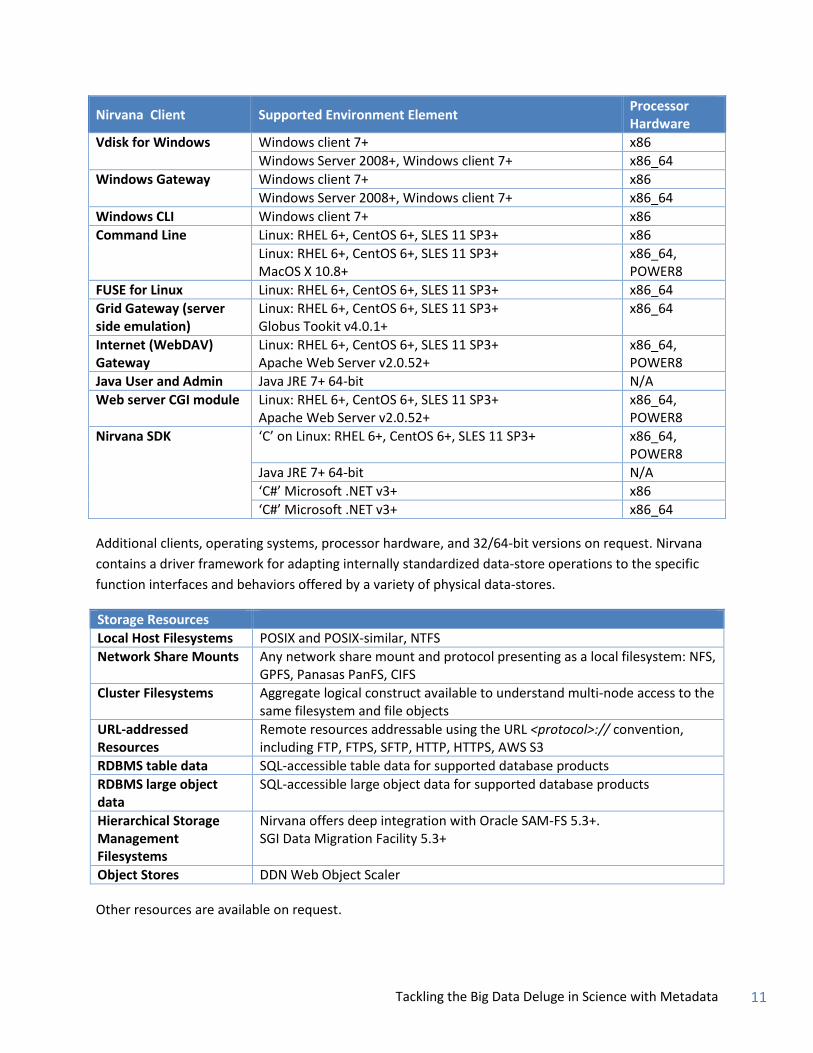
Nirvana Client Supported Environment Element Processor Hardware
Vdisk for Windows Windows client 7+ x86
Windows Server 2008+, Windows client 7+ x86_64
Windows Gateway Windows client 7+ x86
Windows Server 2008+, Windows client 7+ x86_64
Windows CLI Windows client 7+ x86
Command Line Linux: RHEL 6+, CentOS 6+, SLES 11 SP3+ x86
Linux: RHEL 6+, CentOS 6+, SLES 11 SP3+ MacOS X 10.8+
x86_64, POWER8
FUSE for Linux Linux: RHEL 6+, CentOS 6+, SLES 11 SP3+ x86_64
Grid Gateway (server side emulation)
Linux: RHEL 6+, CentOS 6+, SLES 11 SP3+ Globus Tookit v4.0.1+
x86_64
Internet (WebDAV) Gateway
Linux: RHEL 6+, CentOS 6+, SLES 11 SP3+ Apache Web Server v2.0.52+
x86_64, POWER8
Java User and Admin Java JRE 7+ 64-bit N/A
Web server CGI module Linux: RHEL 6+, CentOS 6+, SLES 11 SP3+ Apache Web Server v2.0.52+
x86_64, POWER8
Nirvana SDK ‘C’ on Linux: RHEL 6+, CentOS 6+, SLES 11 SP3+ x86_64, POWER8
Java JRE 7+ 64-bit N/A
‘C#’ Microsoft .NET v3+ x86
‘C#’ Microsoft .NET v3+ x86_64
Additional clients, operating systems, processor hardware, and 32/64-bit versions on request. Nirvana
contains a driver framework for adapting internally standardized data-store operations to the specific
function interfaces and behaviors offered by a variety of physical data-stores.
Storage Resources
Local Host Filesystems POSIX and POSIX-similar, NTFS
Network Share Mounts Any network share mount and protocol presenting as a local filesystem: NFS, GPFS, Panasas PanFS, CIFS
Cluster Filesystems Aggregate logical construct available to understand multi-node access to the same filesystem and file objects
URL-addressed Resources
Remote resources addressable using the URL <protocol>:// convention, including FTP, FTPS, SFTP, HTTP, HTTPS, AWS S3
RDBMS table data SQL-accessible table data for supported database products
RDBMS large object data
SQL-accessible large object data for supported database products
Hierarchical Storage Management Filesystems
Nirvana offers deep integration with Oracle SAM-FS 5.3+. SGI Data Migration Facility 5.3+
Object Stores DDN Web Object Scaler
Other resources are available on request.
Tackling the Big Data Deluge in Science with Metadata 12
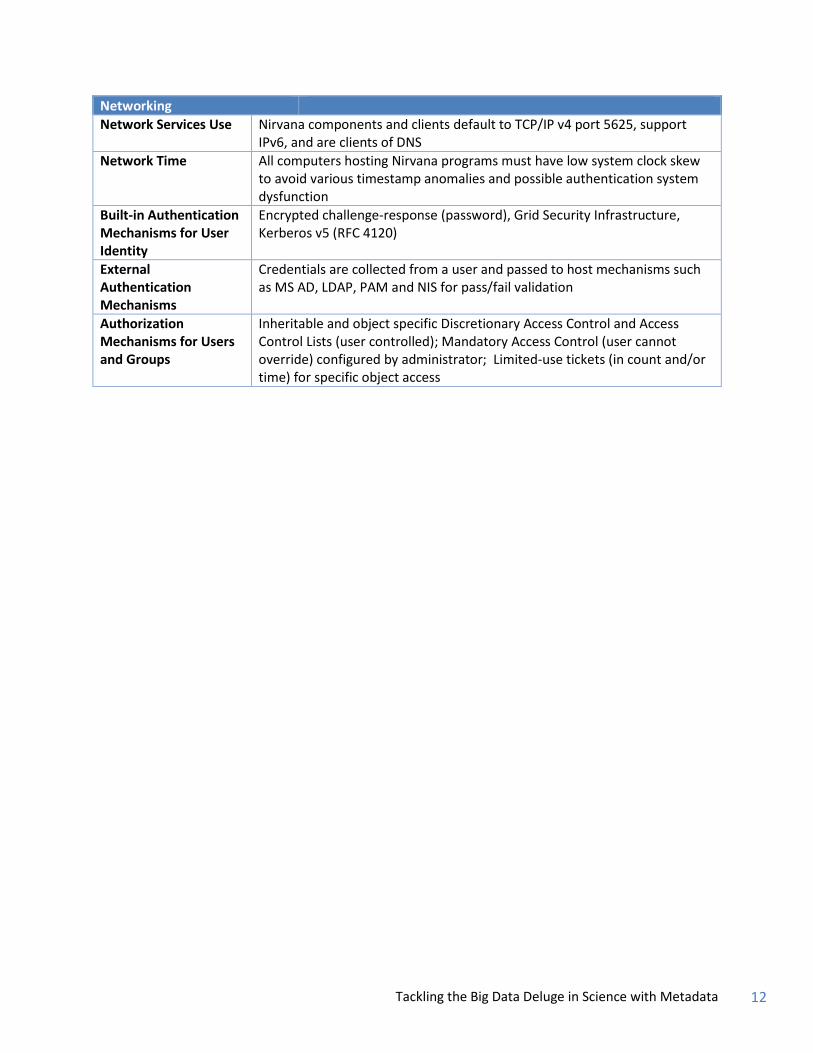
Networking
Network Services Use Nirvana components and clients default to TCP/IP v4 port 5625, support IPv6, and are clients of DNS
Network Time All computers hosting Nirvana programs must have low system clock skew to avoid various timestamp anomalies and possible authentication system dysfunction
Built-in Authentication Mechanisms for User Identity
Encrypted challenge-response (password), Grid Security Infrastructure, Kerberos v5 (RFC 4120)
External Authentication Mechanisms
Credentials are collected from a user and passed to host mechanisms such as MS AD, LDAP, PAM and NIS for pass/fail validation
Authorization Mechanisms for Users and Groups
Inheritable and object specific Discretionary Access Control and Access Control Lists (user controlled); Mandatory Access Control (user cannot override) configured by administrator; Limited-use tickets (in count and/or time) for specific object access







