Download - Spark Summit EU 2015: Matei Zaharia keynote

How Spark Usage is Evolving in 2015
Matei ZahariaOctober 28, 2015

A Great Year for Spark
Most active open source project in big data
New language: R
Widespread industry support & adoption

Community Growth
2014 2015
Summit Attendees
2014 2015
MeetupMembers
2014 2015
Developers Contributing
3900
1100
42K
12K
350
600

Meetup Groups: January 2015
source: meetup.com

Meetup Groups: October 2015
source: meetup.com

What Spark Provides
General engine with libraries for many data analysis tasks
Access to diverse data sources
Simple, unified API
SQLStreaming ML Graph
…
Major focus in past 2 years
Data source API added 2015

What Changed in 2015?
Databricks Survey
1400 respondents from 840 companies
Three trends:
1) Diverse applications
2) More runtime environments
3) More types of users

Industries Using Spark
Other
Software(SaaS, Web, Mobile)
Consulting (IT)Retail,
e-Commerce
Advertising,Marketing, PR
Banking, Finance
Health, Medical,Pharmacy, Biotech
Carriers,Telecommunications
Education
Computers, Hardware
29.4%
17.7%
14.0%
9.6%
6.7%
6.5%
4.4%
4.4%
3.9%
3.5%

Top Applications
29%
36%
40%
44%
52%
68%
Faud Detection / Security
User-Facing Services
Log Processing
Recommendation
Data Warehousing
Business Intelligence

Spark Components Used
58%
58%
62%
69%
MLlib + GraphX
Spark Streaming
DataFrames
Spark SQL
75%
of users use morethan one component

Diverse Runtime Environments
Hadoop: combinedcompute + storage
HDFS
MapReduce
Spark: independentof storage layer
Spark
HDFS SQLe.g. Oracle
NoSQLe.g. Cassandra
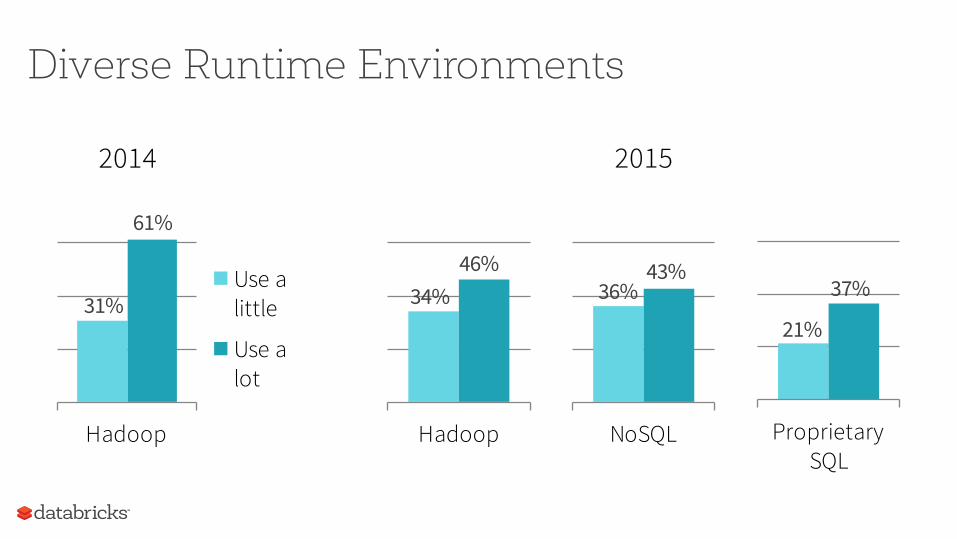
Diverse Runtime Environments
2014 2015
Hadoop
Use a little
Use a lot
Hadoop
61%
31%
NoSQL Proprietary SQL
46%34%
43%36% 37%
21%

Diverse Runtime EnvironmentsHOW RESPONDENTS ARE
RUNNING SPARK
51%on a public cloud
MOST COMMON SPARK DEPLOYMENTENVIRONMENTS (CLUSTER MANAGERS)
48% 40% 11%Standalone mode YARN Mesos
Cluster Managers

Diversity of Users
84%
38% 38%
71%
31%
58%
18%
Languages Used: 2014 Languages Used: 2015

Fastest Growing Components
+280%
increase inWindows users
+56%
production useof Streaming
+380%
production use of SQL

Are We Done?
No! Development is faster than ever.
Biggest technical change in 2015 was DataFrames• Moves many computations onto the relational Spark SQL optimizer
Enables both new APIs and more optimization, which is now happening through Project Tungsten

Traditional Spark DataFrames
RDDs DataFrames
OpaqueJava
objects
User code
Storage
DataFrame API SQL
Schema-aware cache
Structured data sources
Java functions Expressions
Optimizer
Query pushdown

Coming in Spark 1.6
Dataset API: typed interface over DataFrames / Tungsten• Common ask from developers who saw DataFrames
case class Person(name: String, age: Int)
val dataframe = read.json(“people.json”)val ds: Dataset[Person] = dataframe.as[Person]
ds.filter(p => p.name.startsWith(“M”)).groupBy(“name”).avg(“age”)

Other Upcoming Features
DataFrame integration with GraphX and Streaming
More Tungsten features: faster in-memory cache, SSD storage, better code generation
Data sources for Streaming
See Reynold’s talk tomorrow for details

Dank je!Enjoy Spark Summit







