
Reconstructing historical populations from genealogical dataAn overview of methods used for aggregating data from GEDCOM files
Corry Gellatly
Department of Historyand Art HistoryUtrecht University
Workshop on Population ReconstructionIISH Amsterdam, 19-21 February 2014

1. Overview
Why build a large genealogical database by aggregating hundreds of genealogical data (GEDCOM) files?
Research increasingly requires big data, to:
Understand large-scale population dynamics
between regions
over time
social, biological, cultural and economic aspects
Detect rare or ‘small-effects’
epidemiology (disease and intervention)
inheritance (genetics)
comparative life histories

2. GEDCOM files
Why use GEDCOM files for population reconstruction?
Pros a standard file structure for representing information about
familial relationships and life events
most popular format for storage and exchange of genealogical data
used internationally and widely available online
Cons it is a highly flexible format that allows users to enter wildly
incorrect information (if they wish to)

3. Data aggregation
Single GEDCOM files typically contain only a few hundred individuals, so we import hundreds of files into a single genealogical database
There are broadly 3 steps between import of files and the output, which is usable research datasets
1.Screening (to reject poor quality files)
2.Data cleaning
3.Linkage / de-duplication

4. Screening
Screening is carried out for various errors, e.g.
low mean number of offspring per family individuals younger than 0 or very old (>110) impossible relationships (due to age difference between individuals) individuals occurring as different sexes missing individuals
If errors are detected, then the file is either:
removed (in the case of obvious errors)
retained for further checking (in the case of ambiguous errors):
e.g. where individuals have more than two parents – this can be due to adoption or incorrect family links between individuals

5. Cleaning
Example: date errors
If DOB is 1857
Born to 10 year old mother?
Wife 17 years older?
First of 5 children born atthe age of 39?
If DOB is actually 1875
Born to 28 year old mother?
Wife 1 year younger?
First of 5 children born atthe age of 21?

6. Dataset extraction
Definition of datasets is driven by research questions:
which timespan? which region? do we need complete families? do we need dates of birth, death, marriage?
The identification of links between genealogies (or removal of duplicate individuals) is done during the process of dataset extraction

7. Linkage, de-duplication
Linkage fields
Day of birth, marriage or death (DOB, DOM, DOD) Year of birth, marriage or death (YOB, YOM, YOD) Surname Given names Sex
Problems
YOB, YOM, YOD more common than DOB, DOM, DOD (particularly in older data) but less unique to each individual
High inconsistency in recording of given names Middle names included or excluded Middle names used instead of first names Abbreviated names Nicknames (sometimes in brackets)

8. Linkage, de-duplication
Trade-off between data coverage and quality
Surname, given name, DOB Low risk of false linkages, but high risk of missing linkages (due
to problems with given names) and low data coverage
Surname, DOB Low risk of false linkages, but low data coverage
Surname, YOB High risk of false linkages, but high data coverage

9. Group-linking method
Individuals are identifiable by those they are related to
This principle is being applied to the problem of genealogical data, in which many records have YOB, but not DOB and given names are somewhat unreliable for linking
Group-linking string
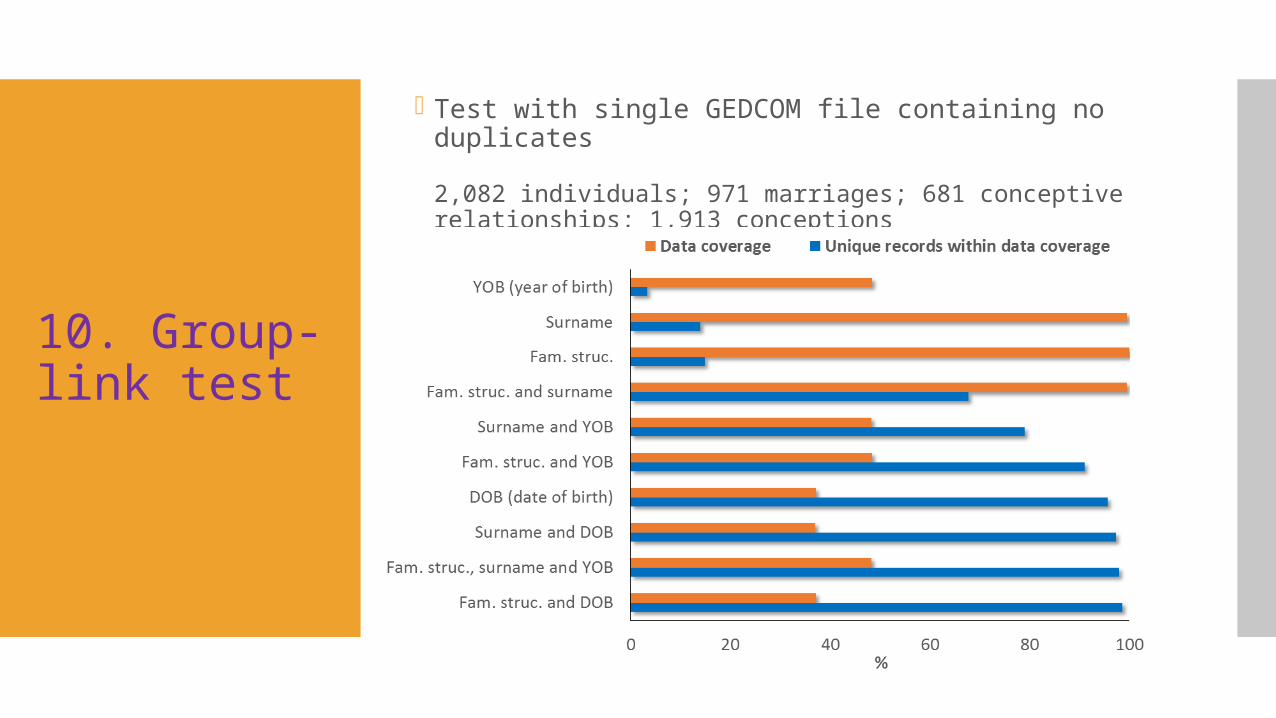
10. Group-link test
Test with single GEDCOM file containing no duplicates
2,082 individuals; 971 marriages; 681 conceptive relationships; 1,913 conceptions

11. Group-link test
Percentage data coverage x Percentage of unique records within that data (÷ 100) gives an estimation of linkage power
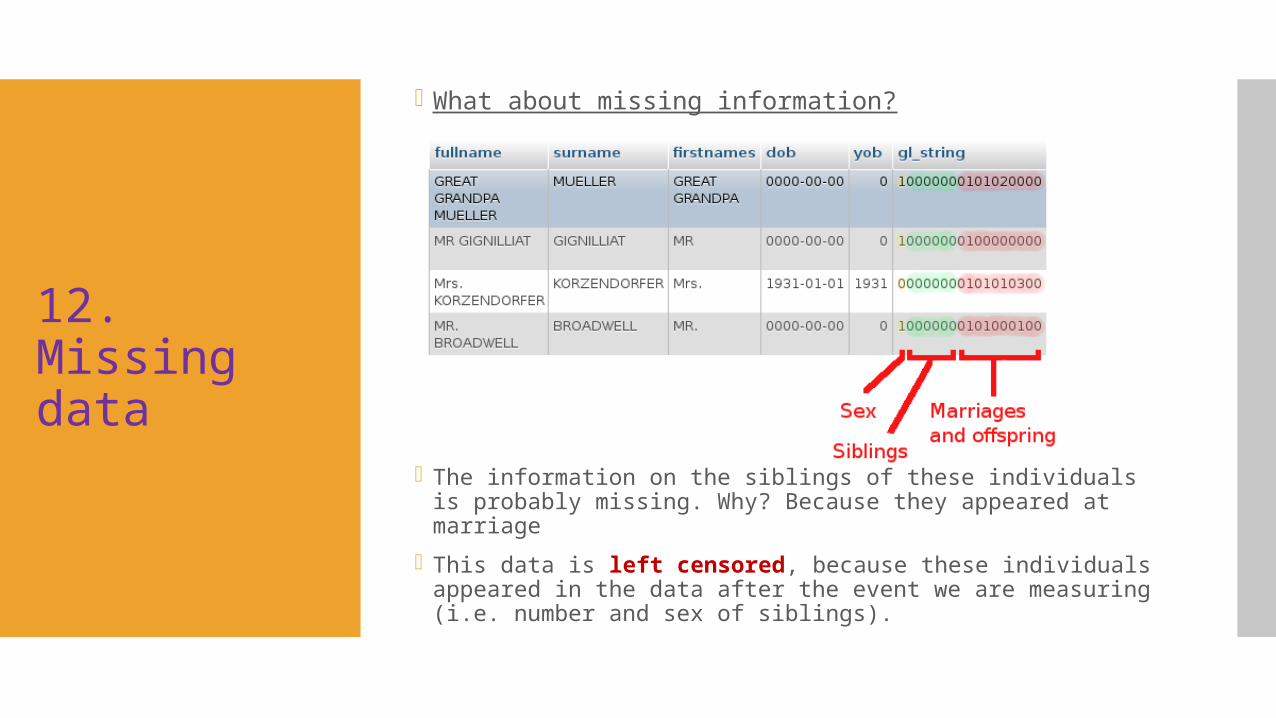
12. Missing data
What about missing information?
The information on the siblings of these individuals is probably missing. Why? Because they appeared at marriage
This data is left censored, because these individuals appeared in the data after the event we are measuring (i.e. number and sex of siblings).

13. Missing data
Depending on what type of links we are trying to find, we may want to break up the string
String to link individuals based on their siblings String to link individuals based on their marriages and children

14. Record de-duplication (1600-1699)
De-duplication of 17th century records from the genealogical database
Febrl program (Freely Extensible Biomedical Record Linkage)
17,488 records with Surname and YOB
Indexes Surname > YOB Surname > Group-link string 2 (sex + siblings) Surname > Group-link string 3 (sex + marriages + offspring)
Comparison function Winkler
Classifier KMeans
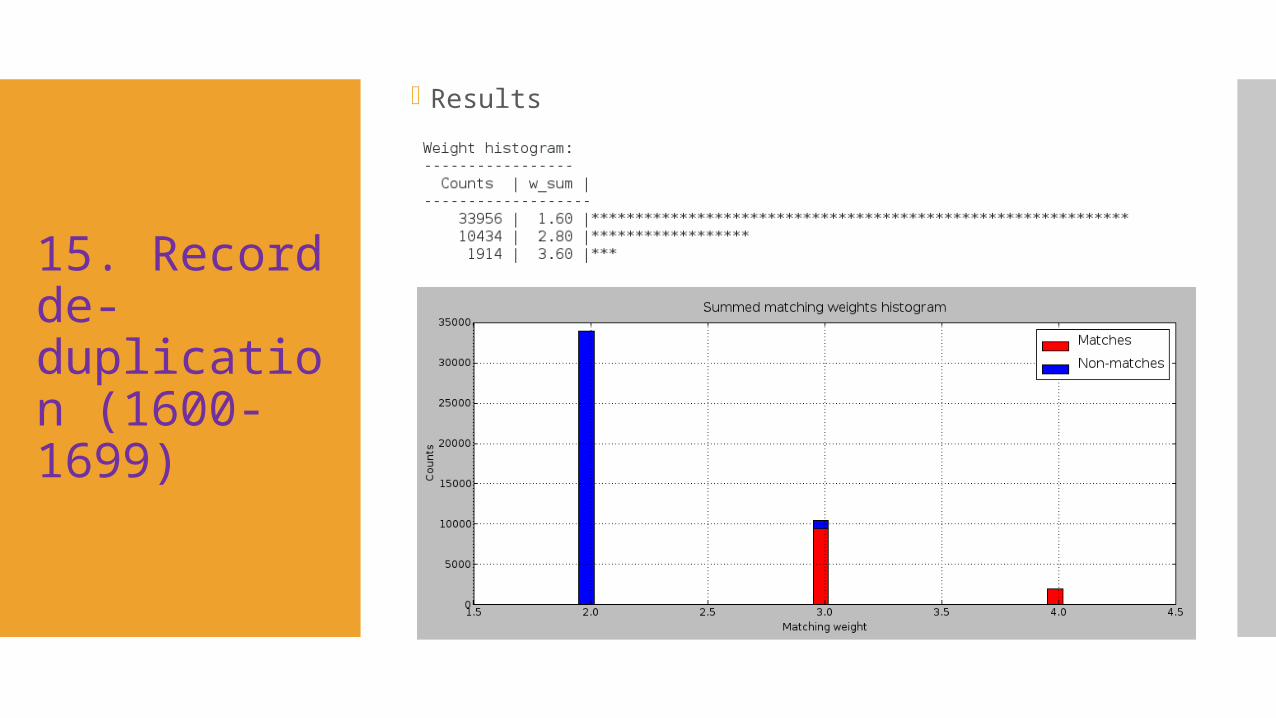
15. Record de-duplication (1600-1699)
Results
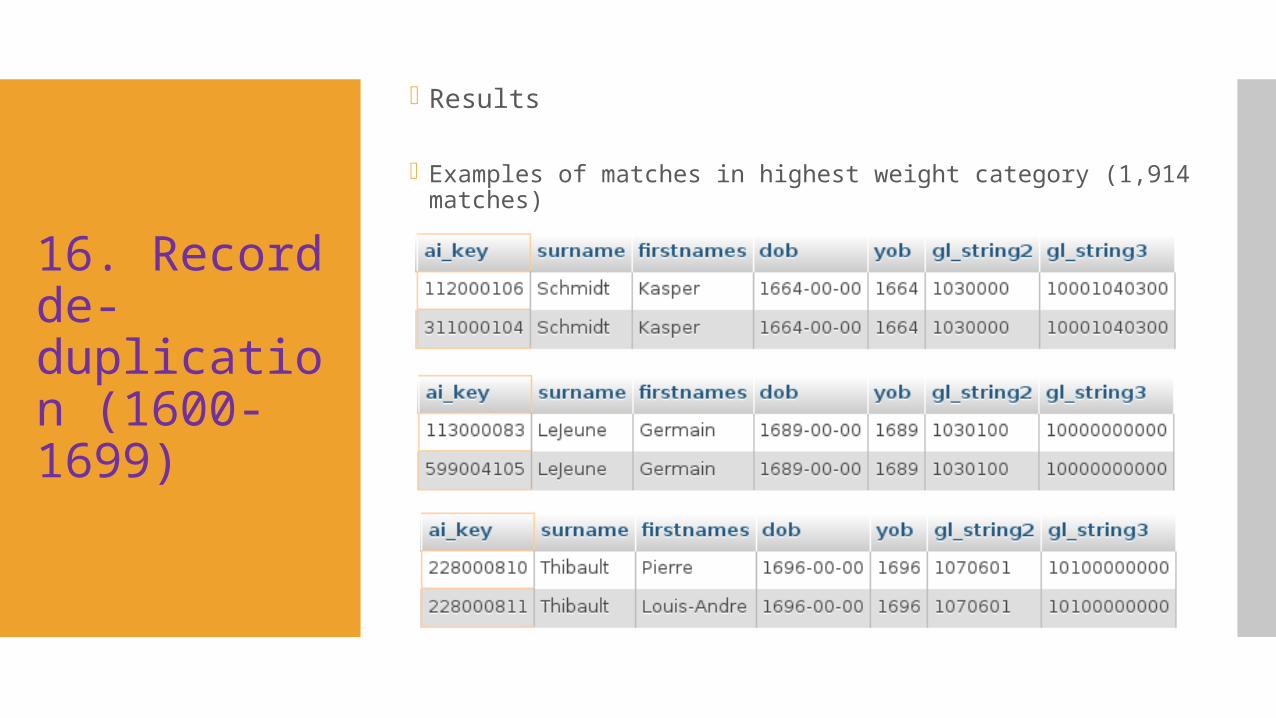
16. Record de-duplication (1600-1699)
Results
Examples of matches in highest weight category (1,914 matches)
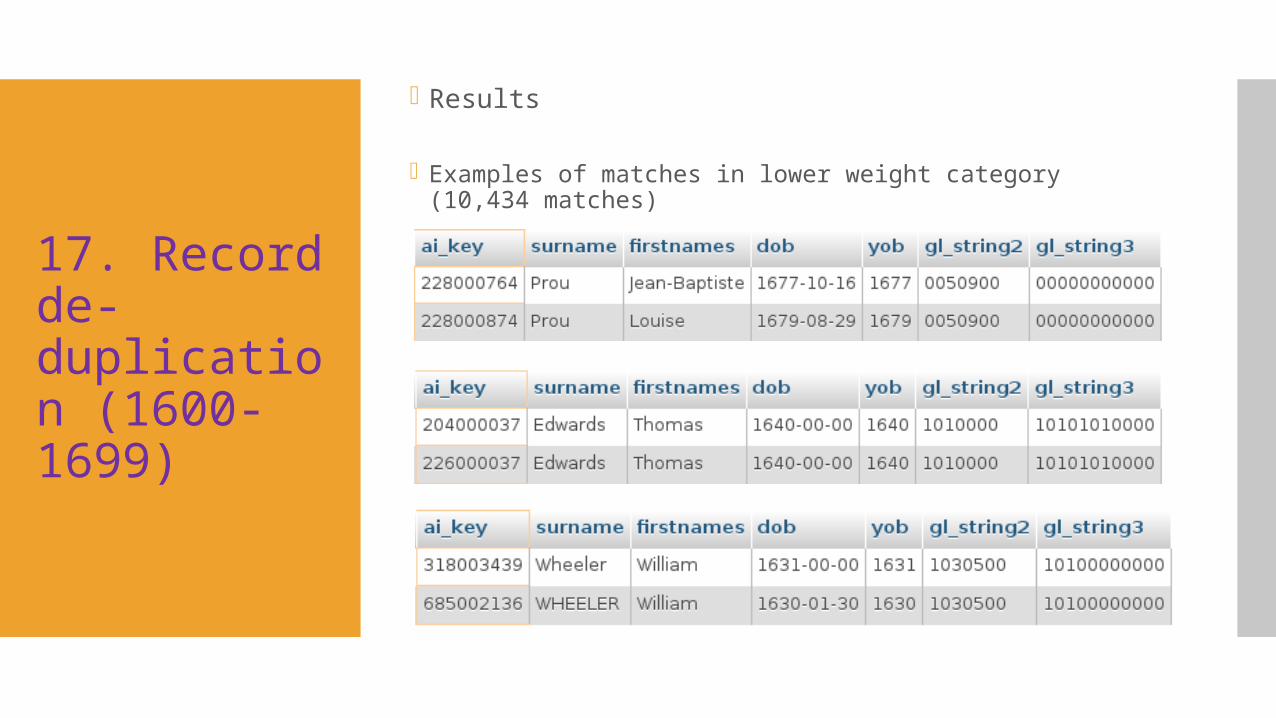
17. Record de-duplication (1600-1699)
Results
Examples of matches in lower weight category (10,434 matches)

17. Further work
Record linkage
Refine a method of probabilistic data matching that can identify linkages
where typo errors or name variations occur possible date typos exist there are missing persons in the family structure
Group-linking algorithm
Using the group-linking string as a start point to then check for existence of birth, marriage and death dates of relatives (where these exist) and performing matches on these variables
Inherently based on probabilistic matching

18. Acknowledgements
Netherlands Organisation for Scientific Research (NWO)
Project number 276-53-008: “Nature or nurture? A search for the institutional and biological determinants of life expectancy in Europe during the early modern period”
Colleagues at Utrecht University
Tine De Moor Institutions for Collective Action team:







