
Recomputing Materialized Instances After Changes to Mappings and Data
Todd J. Green Zachary G. Ives
ICDE ’12 Washington, DC April 2, 2012
&

2
Change is a Constant in Data Management
• Databases are highly dynamic; many kinds of changes need to be propagated efficiently:
– To data (“view maintenance”)
– To view definitions (“view adaptation”)
– Others, such as schema evolution, etc.
• Collaborative data sharing systems (e.g., ORCHESTRA [Ives+ 05]), declarative programming platforms (e.g., LogicBlox [Huang+11]) exacerbate this need:
– Large numbers (100s to 10s of 1000s) of materialized views
– Frequent updates to data, schemas, mapping/view definitions

3
Change Propagation: a Problem of Computing Differences
R¢
change to source data (difference wrt current version)
V¢compute change to materialized view (difference)
Goal:
change to view definition (another kind of difference) V¢
compute change to materialized view
Goal:
R Vsource data
materialized view
Given:view definition
View adaptation
R Vsource data
materialized view
Given:view definition
View maintenance

4
Challenges in Change Propagation
• View maintenance: studied since at least the mid-eighties [Blakeley+ 86],
but existing solutions quite narrow and limited
– Various known methods to compute changes “incrementally”, e.g., count algorithm [Gupta+ 93]
– How do we optimize this process? What is space of all update plans?
• View adaptation: less attention, but renewed importance in context of data exchange/collaborative data sharing systems
– Previous approaches: limited to case-based methods for simple changes [Gupta+ 01]
– Complex changes? Again, space of all update plans?
• Key challenge: compute changes using database queries!

5
Contributions
• We build on our previous theoretical work [G+ 09] to implement a unified and cost-based approach to handling updates to source data, view definitions, or both
• Practical implementation in Orchestra CDSS, based on rewriting queries using materialized views and enriched data model
– Core of our engine is unaware of which kind of update (to source data or to view definition) it is dealing with!
– Engine also automatically exploits provenance information, if present
• We demonstrate significant practical benefits on workloads typical of data sharing in the life sciences

6
Background I: ORCHESTRA CDSS [Ives+08]
a Collaborative Data Sharing System
• Set of peers (e.g., collaborating life scientists), each with database, agree to share information
• Peers linked via network of compositional schema mappings
– define how data/updates applied to one peer instance should be transformed and applied to other peer instances
• System tracks provenance (lineage) information [Green+ 07] as updates are mapped/transformed
– Basis of provenance-based trust policies
– Also used to guide update propagation

7
SID Species Picture61 Lemur
catta
Example: Sharing Morphological Data
Species Common NameLemur catta Ring-Tailed Lemur
ID Species Image Character State34 Lemur
cattahand color white
47 Lemur catta
hand color white
Alice’s field observations: a
Bob’s field observations: b, c
SID Char State
61 hand color black Common Name Hand Color
Standard species names: d
Carol’s Guide to Primate Hand Colors
Carol wants to gather information from Alice, Bob, uBio, and put into own data repository:
Can do this usingschema mappings
schema mappings

8
Common Name Hand ColorRing-Tailed Lemur whiteSID Species Picture
61 Lemur catta
Species Common NameLemur catta Ring-Tailed Lemur
ID Species Image Character State34 Lemur
cattahand color white
47 Lemur catta
hand color white
Alice’s field observations: a
Bob’s field observations: b, c
SID Char State
61 hand color black
Standard species names: d
Carol’s Guide to Primate Hand Colors: e
Datalog mappings relating databases
Example: Sharing Morphological Data (2)
e(Name, Color) :– b(Id, “hand color”, Color), c(Id, Species,_), d(Species, Name).
e(Name, Color) :– a(Id, Species,_, “hand color”, Color), d(Species, Name).
Common Name Hand Color

9
Common Name Hand ColorRing-Tailed Lemur whiteCommon Name Hand ColorRing-Tailed Lemur blackSID Species Picture
61 Lemur catta
Species Common NameLemur catta Ring-Tailed Lemur
ID Species Image Character State34 Lemur
cattahand color white
47 Lemur catta
hand color white
Alice’s field observations: a
Bob’s field observations: b, c
SID Char State
61 hand color black
Standard species names: d
Carol’s Guide to Primate Hand Colors: e
Datalog mappings relating databases
Example: Sharing Morphological Data (2)
e(Name, Color) :– b(Id, “hand color”, Color), c(Id, Species,_), d(Species, Name).
join
e(Name, Color) :– a(Id, Species,_, “hand color”, Color), d(Species, Name).

10
Common Name Hand ColorRing-Tailed Lemur whiteRing-Tailed Lemur white
SID Species Picture61 Lemur
catta
Species Common NameLemur catta Ring-Tailed Lemur
ID Species Image Character State34 Lemur
cattahand color white
47 Lemur catta
hand color white
Alice’s field observations: a
Bob’s field observations: b, c
SID Char State
61 hand color black Common Name Hand Color
Ring-Tailed Lemur black
Standard species names: d
Carol’s Guide to Primate Hand Colors: E
Datalog mappings relating databases
Example: Sharing Morphological Data (2)
e(Name, Color) :– b(Id, “hand color”, Color), c(Id, Species,_), d(Species, Name).
join
e(Name, Color) :– a(Id, Species,_, “hand color”, Color), d(Species, Name).

11
Background II: Data Updates as Z-Relations [G+09]
• Z-relation: a relation where each tuple is associated with a (positive or negative) count
– Positive counts indicate (multiple) insertions;
negative counts, (multiple) deletions
– Uniform representation for both data and changes to data
– Update application = union (a query!)
inserted tuple +
deleted tuple –
r¢
r’ = r [ r¢
• Can think of changes to data as a kind of annotated relation
a b 2
c d –3

12
Relational Algebra (RA) on Z-Relations [G+09]
join (⋈) multiplies counts
union ([), projection (¼) add counts
selection (¾) multiplies counts by 0 or 1
difference (–) subtracts counts
Note,Note, difference can lead to negative counts (unlike “proper subtraction” in bag semantics where negative counts are truncated to 0)
(same as for semiring-annotated relations[G+07])

13
Incremental View Maintenance: An Application of Z-Relations
a b 1c b 1b c 1b a 1
R
a a 1
a c 1
b b 2
c c 1
Source relation:
b a -1
c d +1
b b -1
b d +1R¢ V¢
Delta rules [Gupta+ 93] for v with Z-relations semantics:
v¢(X,Y) :– r(X,Z), r¢(Z,Y) v¢(X,Y) :– r¢(X,Z), r’(Z,Y)
2 copies of (b,b)
delete 1 copy of (b,b)
insert 1 copy of (b,d)
deletion
insertion
v(X,Y) :– r(X,Z), r(Z,Y)
Materialized view (with duplicates):

14
Z-Relations are Amenable to Advanced Optimization Strategies [G+09]
• For change propagation, fundamental need for difference in query language => full relational algebra (RA)
• Under set or bag (multiset) semantics, basic optimization tasks---e.g., testing query equivalence---are undecidable for RA
• Under Z-semantics, equivalence of RA queries is, surprisingly, decidable
• Even better, rewriting queries using materialized views can be done via sound and complete procedure

15
Our Approach in This Work
• Cast view maintenance/view adaptation as special cases of rewriting queries using views
• Use cost-based search to find a good (not perfect) plan within time budget
• Emulate Z-semantics with an off-the-shelf DBMS via encoding scheme
• Handle / exploit provenance information, if we have it– Provenance has sizable storage overhead
– But also unlocks many useful new rewritings

16
View Maintenance: a Special Case of Rewriting Queries Using Views on Z-Relations
v¢(X,Y) :– r(X,Z), r¢(Z,Y)v¢(X,Y) :– r¢(X,Z), r’(Z,Y) v¢(X,Y) :– r¢(X,Z), r(Z,Y)
v¢(X,Y) :– r’(X,Z), r¢(Z,Y)
v¢(X,Y) :– r’(X,Z), r’(Z,Y)– v¢(X,Y) :– r(X,Z), r(Z,Y)
v(X,Y) :– r(X,Z), r(Z,Y)
r’(X,Y) :– r(X,Y) r’(X,Y) :– r¢(X,Y)
Query (to compute diff.): Materialized views:
Delta rules rewriting: Another delta rules rewriting:
rewrite v¢ using the materialized views ... OTHER PLANS…?

17
View Adaptation: Another Application of Rewriting Queries Using Views
Old view definition: New view definition:
v(X,Y) :– r(X,Z), r(Z,Y).v(X,Y) :– s(X,Y,_).
v’(X,Y) :– r(X,Z), r(Z,Y).
v’(X,Y) :– v(X,Y).– v’(X,Y) :– s(X,Y,_).
A plan to “adapt” v into v’:
reformulate using materialized view v
... OTHER PLANS…?

18
Searching the Space of Rewritings:Time-Boxed, Cost-Based Hill-Climbing
VIEWS
q(…) :- … .
r’(…) :- … .
s’(…) :- … .
p1 : 27
p2 : 45 p3 : 17 p14 : 20
original plan p1 for q’ with its (est’d) cost : 27
“one-step” rewritingsof p1 using views : + costs
…
TIME BUDGET
p15 : 12 p16 : 74
(none)
“two-step” rewritingsof p1 using views : + costsp17 : 18
OUT OF TIMEreturn best plan found, p15 : 12
PLAN HEAP
p1 : 27 v’(…) :- …
EXPLORED SET
PLAN HEAP
p3 : 17 v’(…) :- …
p14 : 20 v’(…) :- …
p2 : 45 v’(…) :- …
…
EXPLORED SET
p1 : 27 v’(…) :- …
BEST p1 : 27
PLAN HEAP
p15 : 12 v’(…) :- …
p14 : 20 v’(…) :- …
p2 : 45 v’(…) :- …
p16 : 74 v’(…) :- …
…
EXPLORED SET
p1 : 27 v’(…) :- …
p3 : 17 v’(…) :- …
BEST p3 : 17
PLAN HEAP
p14 : 20 v’(…) :- …
p2 : 45 v’(…) :- …
p16 : 74 v’(…) :- …
…
EXPLORED SET
p1 : 27 v’(…) :- …
p3 : 17 v’(…) :- …
p15 : 12 v’(…) :- …
BEST p15 : 12
PLAN HEAP
p17 : 18 v’(…) :- …
p2 : 45 v’(…) :- …
p16 : 74 v’(…) :- …
…
EXPLORED SET
p1 : 27 v’(…) :- …
p3 : 17 v’(…) :- …
p15 : 12 v’(…) :- …
p14 : 20 v’(…) :- …
BEST p15 : 12

19
How Does Provenance Fit In?
• For view adaptation, often useful to “separate” disjuncts of a union, or “recover” values projected away
• Would like some sort of index structure for this
• Such a structure already exists in CDSS in form of provenance information
20
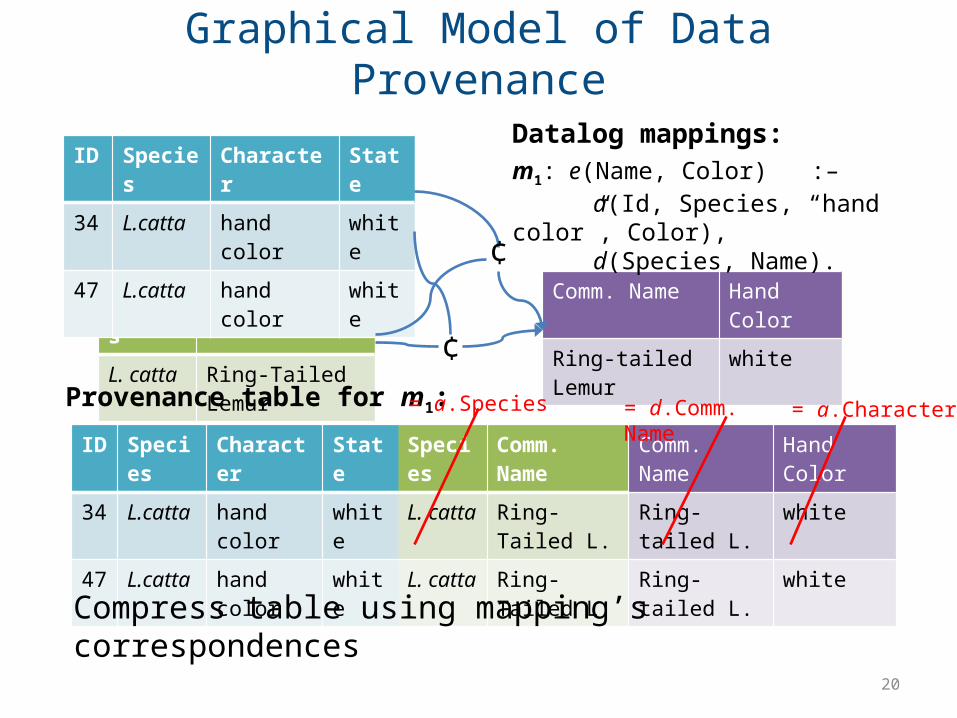
Graphical Model of Data Provenance
Species Comm. NameL. catta Ring-Tailed Lemur
ID Species Character State34 L.catta hand color white47 L.catta hand color white
Comm. Name Hand ColorRing-tailed Lemur white
Species Comm. NameL. catta Ring-Tailed L.L. catta Ring-Tailed L.
ID Species Character State34 L.catta hand color white47 L.catta hand color white
Comm. Name Hand ColorRing-tailed L. whiteRing-tailed L. white
m1: e(Name, Color) :– a(Id, Species, “hand color”, Color), d(Species, Name).
Provenance table for m1:
Datalog mappings:
Compress table using mapping’s correspondences
= a.Species = d.Comm. Name = a.Character
¢
¢

21
How to Compute Provenance Graph?Use Datalog!
To record provenance for mapping m1
we convert it to a pair of mappings
“Just more Datalog views” => automatically exploited by reformulation engine!
– engine doesn’t even know that it’s using provenance!
m1(I, S, N, C) :– a(I, S, “...”, C), d(S, N).
e(N, C) :– m1(_, _, C, N).
e(N, C) :– a(I, S, “...”, C), d(S, N).
The first rule builds the provenance table for m1
The second rule projects over m1 to populate e
22
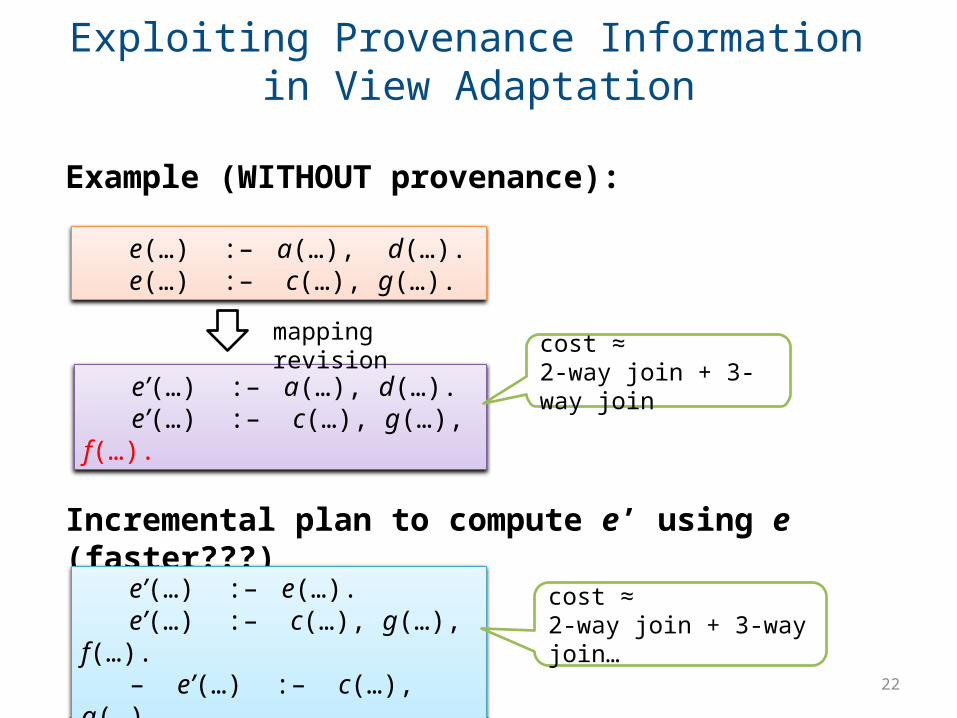
Exploiting Provenance Information in View Adaptation
e(…) :– a(…), d(…).e(…) :– c(…), g(…).
e’(…) :– a(…), d(…).e’(…) :– c(…), g(…), f(…).
Incremental plan to compute e’ using e (faster???)
Example (WITHOUT provenance):
e’(…) :– e(…).e’(…) :– c(…), g(…), f(…).
– e’(…) :– c(…), g(…).
mapping revisioncost ≈ 2-way join + 3-way join
cost ≈ 2-way join + 3-way join…
23
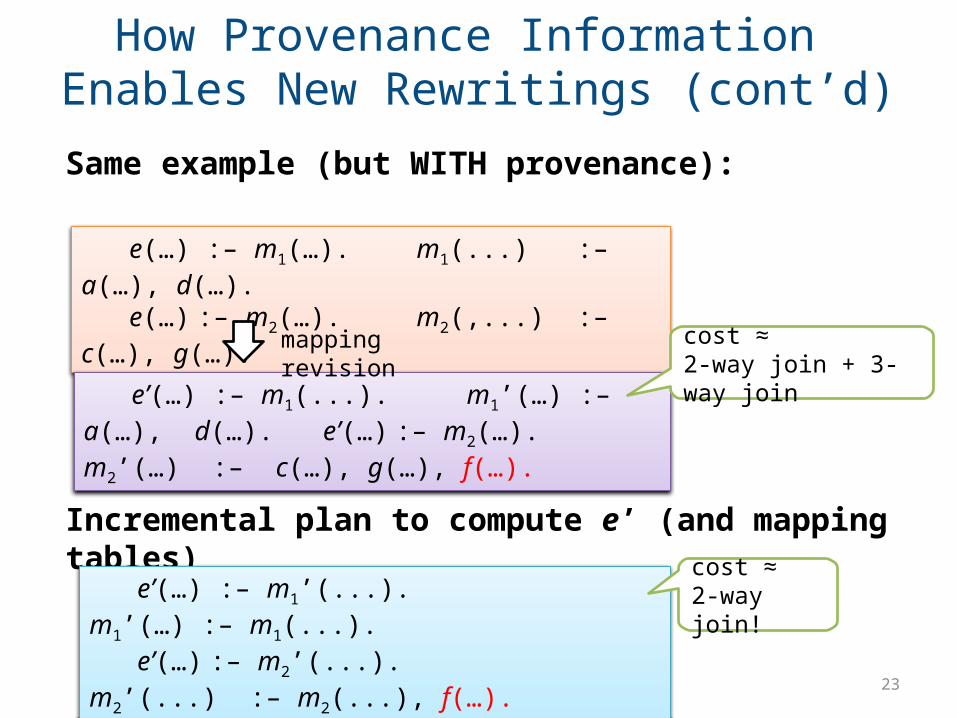
e(…) :– m1(…). m1(...) :– a(…), d(…).
e(…) :– m2(…). m2(,...) :– c(…), g(…).
e’(…) :– m1(...). m1’(…) :– a(…), d(…). e’(…) :– m2(…).m2’(…) :– c(…), g(…), f(…).
Incremental plan to compute e’ (and mapping tables)
Same example (but WITH provenance):
e’(…) :– m1’(...). m1’(…) :– m1(...).e’(…) :– m2’(...). m2’(...) :– m2(...),
f(…).
How Provenance Information Enables New Rewritings (cont’d)
mapping revision cost ≈ 2-way join + 3-way join
cost ≈ 2-way join!

24
Experimental Evaluation
• Synthetic workload based on SWISS-PROT biological dataset
• Generate source tables, mappings, changes to mappings and data– Changes to mapping definitions guided by empirical
observations of schema changes in practice
• Start with 16 source relations, 24 views
• Apply sequences of 24 “primitive modifications” to view definitions– add/drop column in rule head, add/drop data source for
view, add correspondence table, reorder columns, ...

25
Highlights of Experiments
Net speedup ~40% Net speedup ~80%
Net speedup ~20% Net speedup ~45%
without provenance with provenance
mappingchangesonly
mappingchanges+ datachanges

26
Summary
• We’ve shown that optimized change propagation is feasible, and can yield large speedups
– Can handle updates to mappings, data, or both via a generic reformulation engine based on optimizing queries using materialized views
• For systems like ORCHESTRA that store provenance information, even more opportunities for optimization
– Easy to retrofit any Datalog-based system (e.g., LogicBlox) to store same kind of provenance information
– (Benefits must be balanced with storage costs…)

27
Related Work
• Incremental view maintenance [Blakeley+ 86], [Gupta+ 93], ...
– “deltas” [Gupta+ 93]: an early form of our Z-relations
• Answering queries using views [Levy+ 95], [Chaudhuri+ 95], [Afrati&Pavlaki 06], Chase&Backchase [Deutsch,Popa,Tannen 99], ...
• Bag-containment/bag-equivalence of CQs/UCQs [Lovasz 67], [Chaudhuri&Vardi 93], [Ioannidis&Ramakrishnan 95], [Cohen+ 99], [Jayram+ 06]
• View adaptation [Mohania&Dong 96], [Gupta+ 01]

28
Related Work (cont)
• Mapping evolution [Velegrakis+ 03]
• Recursively-compiled view maintenance plans [Ahmad&Koch 09, Koch 10]
• Data exchange [Fagin+05], P2P data exchange [Fuxman+05]
• Youtopia [Koch09]
• Mapping adaptation [Yu&Popa05]








