
Quincy: Fair Scheduling for Distributed Computing
Clusters
Microsoft Research Silicon ValleySOSP’09
Presented at the Big Data Reading Group by Babu Pillai
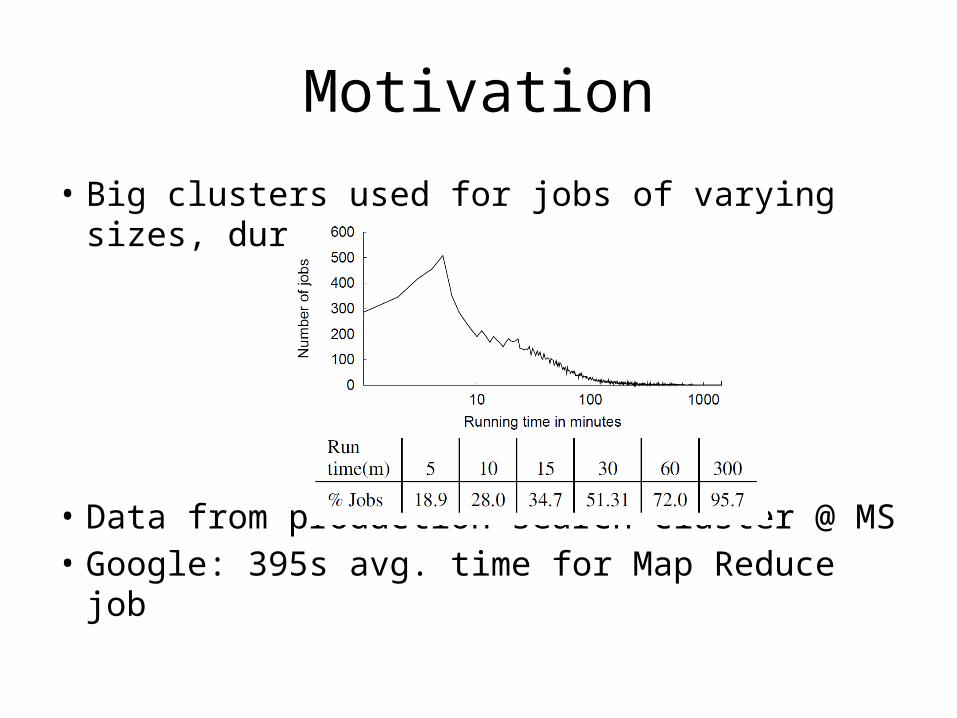
Motivation
• Big clusters used for jobs of varying sizes, durations
• Data from production search cluster @ MS• Google: 395s avg. time for Map Reduce job

Goal
• Fine grained sharing of resources, not semi-static allocations
• Comply with locality constraints – move computation to the data
• Ensure a notion of fairness – large job should not monopolize cluster at expense of many small jobs

Job Model
• Dryad jobs – root process + set of worker processes, related by a DAG
• loosely coupled, independently executing processes• Model is compatible with Map-Reduce, Hadoop,
Condor• Model will not work for MPI
• Will NOT work for SLIPstream jobs
• May work for Dicer??

Locality
• Cluster modeled as 2 level hierarchy: racks and machines
• Each worker can have a rack or machine preference based on fraction of data on rack/machine
• Preference is late bound – when process ready to run

Fairness
• If a job takes t time, and J jobs are running, then it should take no more than Jt
• Admission control to limit to K concurrent jobs choice trades off fairness w/locality against avoiding idle resources
• Queue others, admit in FIFO order as jobs complete
• Fine grained sharing of whole cluster• Assumes only one process per machine

Baseline: Queue-based scheduling• Queues for each machine,
rack, and system-wide• Greedy: dispatch from
most local queue to keep all machines occupied
• Greedy Fair: “block” jobs with lots of resources, give priorityto unblocked ones
• Greedy Fair Preemptive: shoot down processes of jobs with more than their fair share, shortest-lived first
• Hysteresis can be added to GF, GFP to avoid sticky slot issue

Big Idea: Graph-based scheduling
• Represent cluster and process set as a graph• Add weights to represent preferences, costs• Use solver to convert this to a set of
scheduling assignments that satisfy global criteria
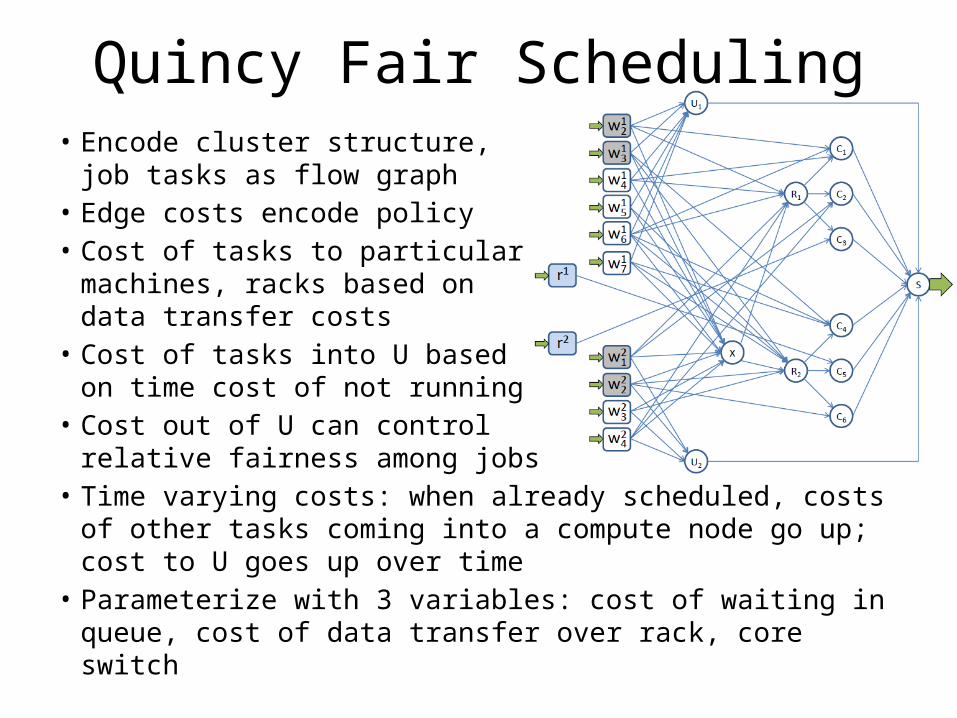
Quincy Fair Scheduling• Encode cluster structure,
job tasks as flow graph• Edge costs encode policy• Cost of tasks to particular
machines, racks based ondata transfer costs
• Cost of tasks into U basedon time cost of not running
• Cost out of U can control relative fairness among jobs
• Time varying costs: when already scheduled, costs of other tasks coming into a compute node go up; cost to U goes up over time
• Parameterize with 3 variables: cost of waiting in queue, cost of data transfer over rack, core switch
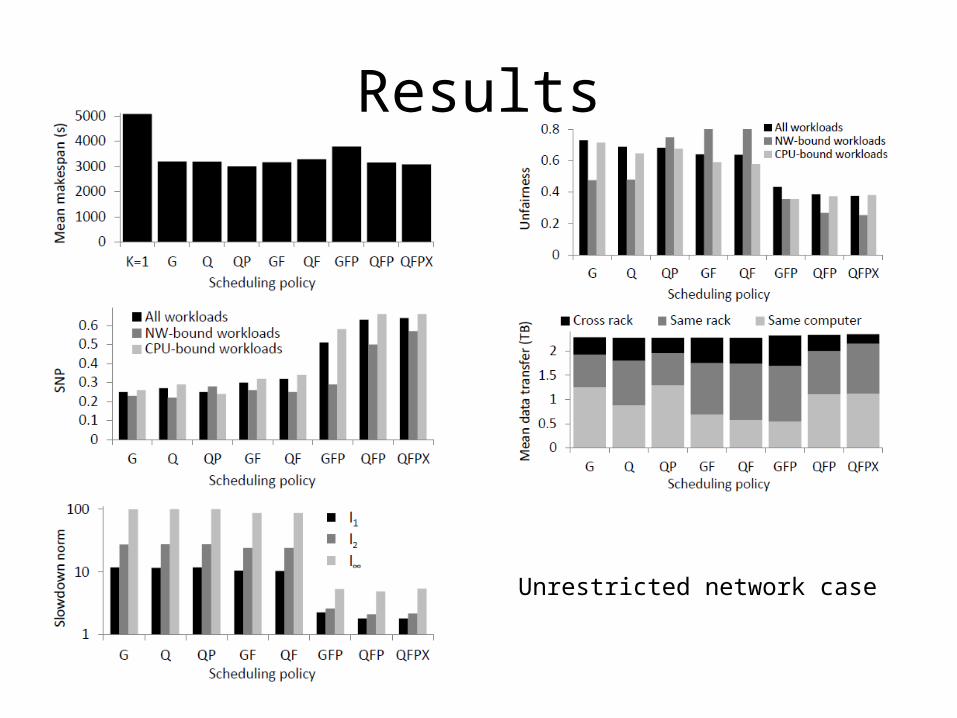
Results
Unrestricted network case
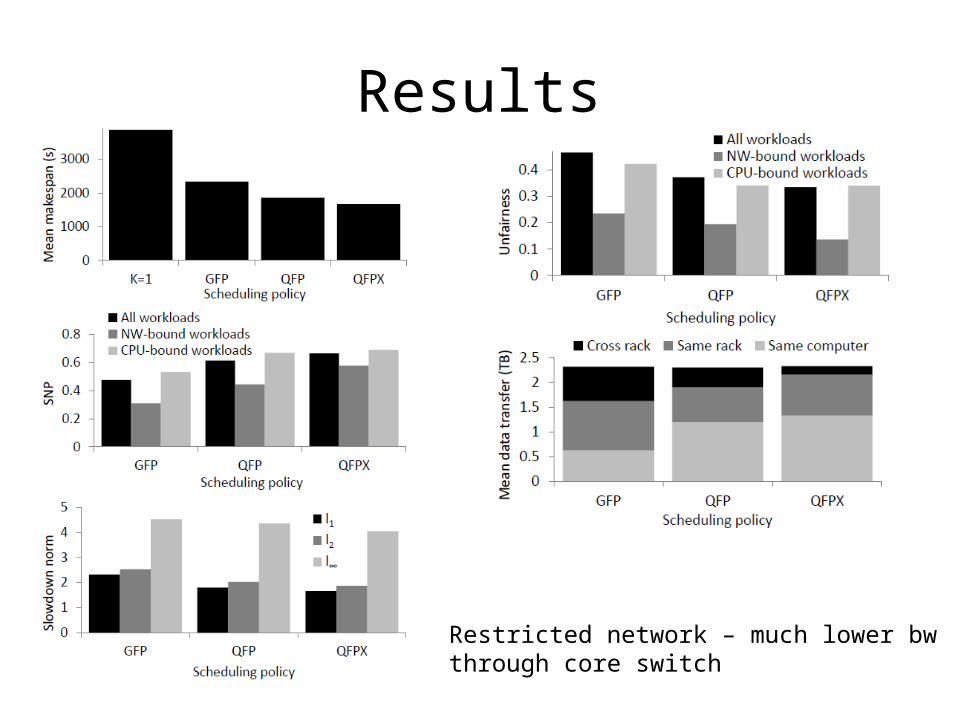
Results
Restricted network – much lower bwthrough core switch

Issues / Discussion
• Assignment of tasks independent – this is not possible for MPI, many VM placement
• Single dimensional capacities, not easily extended to multidimensional
• Can support multiple tasks/computer• Can adapt K to improve cluster utilization• Cannot express constraints such as t1 and t2
should execute on the same rack







