
PlanetLab: an open community test-bed for Planetary-Scale Services
a “work in progress” for USITS03
David Culler*
UC Berkeley
Intel Research @ Berkeley
•with Larry Peterson, Tom Anderson, Mic Bowman, Timothy Roscoe, Brent Chun,•Frans Kaashoek, Mike Wawrzoniak, ....

3/26/2003 USITS PlanetLab
PlanetLab today
• 121 nodes at 52 sites in 10 countries, 4 continents, ...• Universities, Internet 2, co-lo’s soon• Active and growing research community• Just beginning... ... on way to 1,000
http://www.planet-lab.org

3/26/2003 USITS PlanetLab
Where did it come from?• Sense of wonder
– what would be the next important thing to do in extreme networked systems post cluster, post yahoo, post inktomi, post akamai, post gnutella, post bubble?
• Sense of angst– NRC: “looking over the fence at networks”
» ossified internet (intelluctually, infrastructure, system)
» next internet likely to emerge as overlay on current one (again)
» it will be defined by its services, not its transport
• Sense of excitement– new class of services & applns that spread over much of the web
» CDN’s, P2P’ss just the tip of the iceberg
– architectural concepts emerging
» scalable translation, dist. storage, dist. events, instrumentation, caching, management

3/26/2003 USITS PlanetLab
key missing element – hands on experience
• Researchers had no vehicle to try out their next n great ideas in this space
• Lot’s of simulations
• Lot’s of emulation on large clusters– emulab, millennium, modelnet
• Lot’s of folks calling their 17 friends before the next deadline
– RON testbed
• but not the surprises and frustrations of experience at scale to drive innovation
3/26/2003 USITS PlanetLab
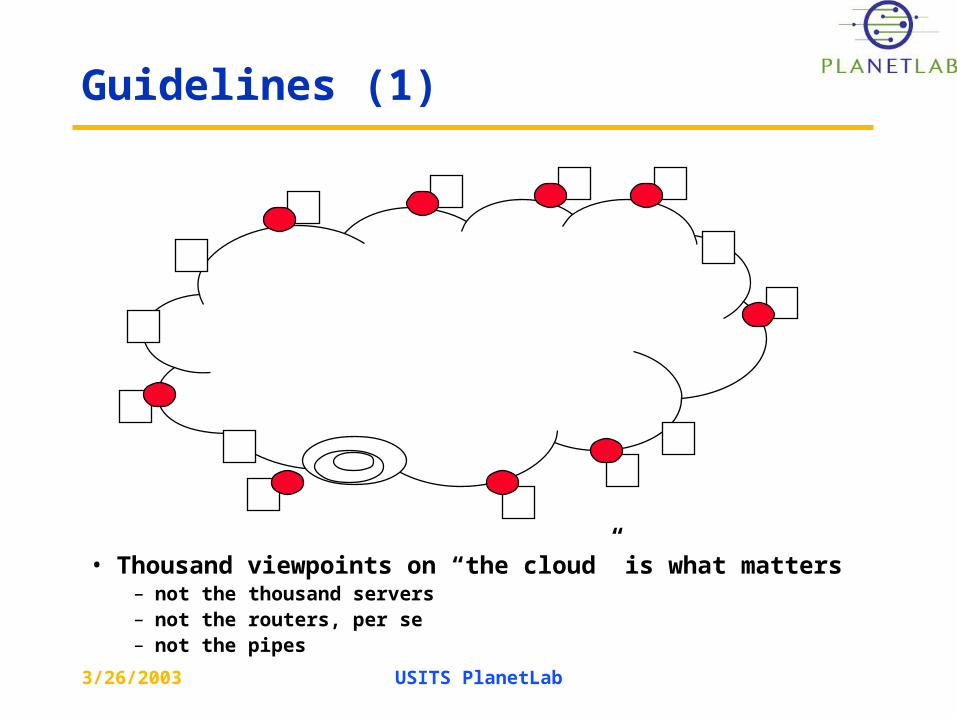
Guidelines (1)
• Thousand viewpoints on “the cloud” is what matters– not the thousand servers– not the routers, per se– not the pipes

3/26/2003 USITS PlanetLab
Guidelines (2)
• and you miust have the vantage points of the crossroads– primarily co-location centers

3/26/2003 USITS PlanetLab
Guidelines (3)
• Each service needs an overlay covering many points
– logically isolated
• Many concurrent services and applications– must be able to slice nodes => VM per service– service has a slice across large subset
• Must be able to run each service / app over long period to build meaningful workload
– traffic capture/generator must be part of facility
• Consensus on “a node” more important than “which node”

3/26/2003 USITS PlanetLab
Guidelines (4)
• Test-lab as a whole must be up a lot– global remote administration and management
» mission control
– redundancy within
• Each service will require its own remote management capability
• Testlab nodes cannot “bring down” their site– generally not on main forwarding path
– proxy path
– must be able to extend overlay out to user nodes?
• Relationship to firewalls and proxies is key
Management, Management, Management

3/26/2003 USITS PlanetLab
Guidelines (5)
• Storage has to be a part of it– edge nodes have significant capacity
• Needs a basic well-managed capability– but growing to the seti@home model should be considered at
some stage
– may be essential for some services

3/26/2003 USITS PlanetLab
Confluence of Technologies
• Cluster-based scalable distribution, remote execution, management, monitoring tools
– UCB Millennium, OSCAR, ..., Utah Emulab, ...
• CDNS and P2Ps– Gnutella, Kazaa, ...
• Proxies routine• Virtual machines & Sandboxing
– VMWare, Janos, Denali,... web-host slices (EnSim)
• Overlay networks becoming ubiquitous– xBone, RON, Detour... Akamai, Digital Island, ....
• Service Composition Frameworks– yahoo, ninja, .net, websphere, Eliza
• Established internet ‘crossroads’ – colos• Web Services / Utility Computing• Authentication infrastructure (grid)• Packet processing (layer 7 switches, NATs, firewalls)• Internet instrumentation
The Time is NOW

3/26/2003 USITS PlanetLab
March 02 “Underground Meeting”
WashingtonTom AndersonSteven GribbleDavid Wetherall
MITFrans KaashoekHari BalakrishnanRobert MorrisDavid Anderson
BerkeleyIon StoicaJoe HelersteinEric Brewer
Kubi
Intel ResearchDavid CullerTimothy RoscoeSylvia RatnasamyGaetano BorrielloSatya (CMU Srini)Milan Milenkovic
DukeAmin VadatJeff Chase
PrincetonLarry PetersonRandy WangVivek Pai
Rice Peter Druschel
UtahJay Lepreau
CMUSrini SeshanHui Zhang
UCSDStefan Savage
ColumbiaAndrew
Campbell
ICIRScott ShenkerEddie Kohler
see http://www.cs.berkeley.edu/~culler/planetlab

3/26/2003 USITS PlanetLab
Outcome
• “Mirror of Dreams” project
• K.I.S.S.– Building Blocks, not solutions
– no big standards, OGSA-like, meta-hyper-supercomputer
• Compromise– A basic working testbed in the hand is much better than
“exactly my way” in the bush
• “just give me a bunch of (virtual) machines spread around the planet,.. I’ll take it from there”
• small distr. arch team, builders, users

3/26/2003 USITS PlanetLab
Tension of Dual Roles
• Research testbed– run fixed-scope experiments
– large set of geographically distributed machines
– diverse & realistic network conditions
• Deployment platform for novel services– run continuously
– develop a user community that provides realistic workload
design deploy
measure

3/26/2003 USITS PlanetLab
Overlapping Phases
2003 2004 2005
0. seed
I. get API & interfaces right
II. get underlying arch. and impl. right
Build a working “sandbox” of significant scale quickly tocatalyze the community.
YOUAREHERE

3/26/2003 USITS PlanetLab
Architecture principles
• “Slices” as fundamental resource unit– distributed set of (virtual machine) resources
– a service runs in a slice
– resources allocated / limited per-slice (proc, bw, namespace)
• Distributed Resource Control– host controls node, service producer, service consumers
• Unbundled Management– provided by basic services (in slices)
– instrumentation and monitoring a fundamental service
• Application-Centric Interfaces– evolve from what people actually use
• Self-obsolescence– everything we build should eventually be replaced by the community
– initial centralized services only bootstrap distributed ones

3/26/2003 USITS PlanetLab
Slice-ability
• Each service runs in a slice of PlanetLab– distributed set of resources (network of virtual machines)
– allows services to run continuously
• VM monitor on each node enforces slices– limits fraction of node resources consumed
– limits portion of name spaces consumed
• Challenges– global resource discovery
– allocation and management
– enforcing virtualization
– security

3/26/2003 USITS PlanetLab
Unbundled Management
• Partition management into orthogonal services– resource discovery
– monitoring system health
– topology management
– manage user accounts and credentials
– software distribution and updates
• Approach– management services run in their own slice
– allow competing alternatives
– engineer for innovation (define minimal interfaces)

3/26/2003 USITS PlanetLab
Distributed Resource Control
• At least two interested parties– service producers (researchers)
» decide how their services are deployed over available nodes
– service consumers (users)
» decide what services run on their nodes
• At least two contributing factors– fair slice allocation policy
» both local and global components (see above)
– knowledge about node state
» freshest at the node itself

3/26/2003 USITS PlanetLab
Application-Centric Interfaces
• Inherent problems– stable platform versus research into platforms
– writing applications for temporary testbeds
– integrating testbeds with desktop machines
• Approach– adopt popular API (Linux) and evolve implementation
– eventually separate isolation and application interfaces
– provide generic “shim” library for desktops

3/26/2003 USITS PlanetLab
Service-Centric Virtualization

3/26/2003 USITS PlanetLab
Changing VM landscape
• VMs for complete desktop env. re-emerging– e.g., VMware– extremely complete, poor scaling
• VM sandboxes widely used for web hosting– ensim, BSD Jail, linux vservers (glunix, ufo, ...)– limited /bin, no /dev, many VMs per M– limit the API for security
• Scalable Isolation kernels (VMMs) – host multiple OS’s on cleaner VM– Denali, Xen– Simple enough to make secure
» attack on hosted OS is isolated
Savage/Anderson view: security is the most critical requirement, there has never been a truly secure VM, it can only be secure if it has no bugs...

3/26/2003 USITS PlanetLab
How much to virtualize?
• enough to deploy the next planet-lab within a slice on the current one...
• enough network access to build network gateways for overlays
• Phase 0: unix process as VM– SILK (Scout in Linux Kernal) to provide resource metering,
allocation
• Phase 1: sandbox– evolved a constrained, secure API (subset)
• Phase 2: small isolation kernel with narrow API– some services built on it directly– host linux / sandbox on top for legacy services

3/26/2003 USITS PlanetLab
Slivers of a Slice: long-term plan
Hardware
Isolation Kernel
Service 1
Service 2
XP
Service 3
BSD
Service 4
Linux
Service n
ApplicationInterface
IsolationInterface
- Denali- Xenoserver- VMWare

3/26/2003 USITS PlanetLab
Kickoff to catalyze community
• Seeded 100 machines in 42 sites July 02– avoid machine configuration issues
– huge set of administrative concerns
• Intel Research, Development, and Operations
• UCB Rootstock build distribution tools– boot once from floppy to build local cluster
– periodic and manual update with local modification
• UCB Ganglia remote monitoring facility– aggregate stats from each site, pull into common database
• 10 Slices (accounts) per site on all machines– authenticate principal (PIs), delegation of access
– key pairs stored in PL central, PIs control which get pushed out
– PIs map users to slices
• Discovery by web pages
• Basic SSH and scripts ... grad students roll what they need

3/26/2003 USITS PlanetLab
the meta-testbed effect
• Emulab / netbed– boot-your-own OS doesn’t scale to unaffiliated site– architecture should permit it virtually
» service lives in a slice» offers its own user mgmt, authentication, ...
=> need to offer virtual machine with virtual chroot ASAP
• RON– need access to raw sockets to build gateways need safe (restricted) access to raw sockets early need mount
• Hard to put a machine in someone else’s site and give out root.
• Architecturally, should not need to do it.=> pushed VServer and SILK agenda
and ... federate without losing identity

3/26/2003 USITS PlanetLab
Current Approach (on to phase I)
Hardware
Linux
Vserver
Service 1
Vserver
Service 2
Vserver
Service 3
Vserver
Service 4
Vserver
Service n
CombinedIsolation andApplicationInterface
+ Resource Isolation+ Safe Raw Sockets+ Instrumentation
+ Ganglia, InforSpec, ScoutMonitor

3/26/2003 USITS PlanetLab
vServer experience (Brent Chun)
• New set of scaling issues: disk footprint– 1581 directories, 28959 files
• VM-specific copy-on-write reduced 29 MB/vm– copied part: 5.6 MB /etc, 18.6 MB /var– 1000 VMs per disk
• Current– 222+ per node– 30-40 secs create, 10 secs delete
» developing VM preallocate & cache
• slice login -> vserver root• Limitations
– common OS for all VMs (few calls for multiple OS’s)– user-level NFS mount (MIT’s on it)– incomplete self-virtualization– incomplete resource isolation (eg. buffer cache)– inperfect (but unbroken) kernel security
=> raised the bar on isolation kernels

3/26/2003 USITS PlanetLab
SILK (Princeton)
• key elements of ANets NodeOS in linux– familiar API
• Safe raw sockets– enables network gateways, application overlays
• Monitoring– traffic per slice, per node
– 5 min snapshots bytes sent/recv per slice x node
• Isolation and limits– bandwidth
– memory soon

3/26/2003 USITS PlanetLab
Dynamic Slice Creation
N3
N4
Nm
N1
N2
.
.
.
Agent Broker
.
.
.
.
.
.
candidates
reserve
description
ticket
description
desc
riptio
n
acquireticket lease
ServiceManager

3/26/2003 USITS PlanetLab
BootCD – enabling growth
• Constrained linux booted from CD with networking
• Knows how to phone home and get signed script
• check signature and run– install
– chain boot
– reboot with special sshd
• register first...
• grow the testbed and use it too
http://www.planet-lab.org/joining/

3/26/2003 USITS PlanetLab
A typical day (1/28)
0
20
40
60
80
100
120id
sl1
irb2
nobo
dyns
cd ntp
root
uw1
sshd
prin
ceto
n7ke
ntuc
ky2
ucsd
3uc
sb1
tenn
esse
e1uc
la2
mit5
irb6
colu
mbi
a9sy
dney
2pr
ince
ton4
mit3
rice2
mit4
mit7
mit8
sydn
ey1
cmu4
duke
5hu
ji1hu
ji10
huji2
huji3
huji4
huji5
huji6
huji7
lanc
aste
r3 pipr
ince
ton9
smile
yal
pha
beta
trid
elts
duke
3m
ail
ucb3
colu
mbi
a3on
euc
b6uc
hica
go2
colu
mbi
a8co
rnel
l1id
sl2
idsl
3pr
ince
ton3
Series1

3/26/2003 USITS PlanetLab
Run up to SIGCOMM

3/26/2003 USITS PlanetLab
A Slice for a Month (Duke)
bytes sent per day by nodes
bytes recv’d per day by nodes

3/26/2003 USITS PlanetLab
So what are people doing?

3/26/2003 USITS PlanetLab
Really...
• Internet Instrumentation
• DHT – scalable lookup, location
• Distributed Storage
• User-level Multicast
• Distributed CDN, Search, ...
• and all of them are doing a lot of pinging, copying, and timing
• key aspect of an overlay network is to estimate performance characteristics of each virtual link

3/26/2003 USITS PlanetLab
with the internet in the middle
83 machines, 11/1/02 Sean Rheabasis for DHT comparison
scp 4 MB to MIT, Rice, CIT confirm Padhye SIGCOMM98
110 machine, c/o Ion Stoicai3 weather service
143 RON+PlanetLabSynthetic Coodinatec/o Frans Kaashoek

3/26/2003 USITS PlanetLab
Analysis of Tapestry (Ben Zhao)
• 98 machines, 6-7 Tapestry nodes per machine, all node pairs
• Ratio of end-to-end routing latency to shortest ping time between node
• Ratio of object location to ping
• 10,000 objects per node
0
5
10
15
20
25
30
35
0 50 100 150 200 250 300
Internode RTT Ping time (5ms buckets)
RDP
(min
, med
, 90%
) Median=31.5, 90th percentile=135
0
5
10
15
20
25
0 20 40 60 80 100 120 140 160 180 200
Client to Obj RTT Ping time (1ms buckets)
RD
P (
min
, m
ed
ian
, 9
0%
)
90th percentile=158

3/26/2003 USITS PlanetLab
Towards an instrumentation service
• every overlay, DHT, and multicast is measuring the internet in the middle
• they do it in different ways
• they do different things with the data
• Can this be abstracted into a customizable instrumentation service?
– Share common underlying measurements
– Reduce ping, scp load
– Grow down into the infrastructure

3/26/2003 USITS PlanetLab
Ossified or fragile?
• One group forgot to turn off an experiment– after 2 weeks of router being pinged every 2 seconds, ISP contacted
ISI and threatened to shut them down.
• One group failed to initialize destination address and ports (and had many virtual nodes on each of many physical nodes)
– worked OK when tested on a LAN
– trashed flow-caches in routers
– probably generated a lot of unreachable destination traffic
– triggered port-scan alarms at ISPs (port 0)
– n^2 probe packets trigger other alarms

3/26/2003 USITS PlanetLab
the Gaetano advice
• for this to be successful, it will need the support of network and system administrators at all the sites...
• it would be good to start by building tools that made their job easier

3/26/2003 USITS PlanetLab
ScriptRoute (Spring, Wetherall, Anderson)
• Traceroute provides a way to measure from you out
• 100s of traceroute servers have appeared to help debug connectivity problems
– very limited functionality
• => provide simple, instrumentation sandbox at many sites in the internet
– TTL, MTU, BW, congestion, reordering
– safe interpreter + network guardian to limit impact
» individual and aggregate limits

3/26/2003 USITS PlanetLab
Example: reverse trace
• underlying debate: open, unauthenticated, community measurement infrastructure vs closed, engineered service
• see also Princeton BGP multilateration
UWGoogle

3/26/2003 USITS PlanetLab
Ossified or brittle?
• Scriptroute set of several alarms
• Low bandwidth traffic to lots of ip addresses brought routers to a crawl
• Lots of small TTLs but not exactly Traceroute packets...
• isp installed filter blocking subnet at Harvard and sent notice to network administrator without human intervention
– Is innovation still allowed?

3/26/2003 USITS PlanetLab
NetBait Serendipity
• Brent Chun built a simple http server on port 80 to explain what planetlab was about and to direct inquiries to planet-lab.org
• It also logged requests• Sitting just outside the firewall of ~40
universities...• the worlds largest honey pot• the number of worm probes from compromized
machines was shocking• imagine the the epidemiology
• see netbait.planet-lab.org

3/26/2003 USITS PlanetLab
One example
• The monthly code-red cycle in the large?
• What happened a little over a week ago?
0
50
100
150
200
250
1/5/
2003
1/10
/200
3
1/15
/200
3
1/20
/200
3
1/25
/200
3
1/30
/200
3
2/4/
2003
2/9/
2003
2/14
/200
3
2/19
/200
3
2/24
/200
3
3/1/
2003
3/6/
2003
3/11
/200
3
3/16
/200
3
Pro
be
s p
er
da
y
Code Red
Nimda

3/26/2003 USITS PlanetLab
No, not Iraq
• A new voracious worm appeared and displaced the older Code Red
0
200
400
600
800
1000
1200
1400
3/1/
2003
3/2/
2003
3/3/
2003
3/4/
2003
3/5/
2003
3/6/
2003
3/7/
2003
3/8/
2003
3/9/
2003
3/10
/200
3
3/11
/200
3
3/12
/200
3
3/13
/200
3
3/14
/200
3
3/15
/200
3
3/16
/200
3
3/17
/200
3
3/18
/200
3
3/19
/200
3
3/20
/200
3
Pro
be
s p
er
da
y
Code Red
Nimda
Code Red II.F

3/26/2003 USITS PlanetLab
Netbait view of March

3/26/2003 USITS PlanetLab
DHT Bakeoff
• Proliferation of distributed hash tables, content-address networks, dist. object location was a primary driver for PlanetLab
– chord, can, pastry, tapestry, Kademlia, viceroy, ...– map a large identifier (160 bits) to object by routing (in the
overlay) to node responsible for that key – in presence of concurrent inserts, joins, fails, leaves, ...
• Natural for the community to try resolve the many proposals
Common API to allow for benchmarking (Dabek etal, IPTPS)
Analytical Comparisons Ratnasamy says “rings are good”
Empirical Comparisons

3/26/2003 USITS PlanetLab
Rationalizing Structured P2P Overlays
Key-based Routing Tier 0
Tier 1
Tier 2CFS PAST SplitStreami3 OceanStoreBayeux
CASTDHT DOLRget, put, remove
publish,unpublish,sendToObj
join,leavemulticast,anycast
route(key, msg)+upcalls andid mgmt

3/26/2003 USITS PlanetLab
Empirical Comparison (Rhea, Roscoe,Kubi)
• 79 PlanetLab nodes, 400 ids per node
• Performed by Tapesty side

3/26/2003 USITS PlanetLab
Bake-off Controversy
• Huge set of subtle issues• Different designs optimized for different aspects
– which workload
• Design versus engineering– eg, Chord has 408 node cache
• What sort of churn (joins, leaves)?• What sort of failures?• What scale?
• A very healthy process. PlanetLab still way too small.

3/26/2003 USITS PlanetLab
Distributed Storage
• Phase 0 provides basic copy scripts– community calls for global nfs / afs !!!
• Good spectrum of novel proposals
• Internet Backplane Protocol (Tenn)– basic transport and storage of variable sized blocks (in depots)
– intermittently available, untrusted, bounded duration
– do E2E redundancy, encryption, permanence
• Cooperative File System (MIT, UCB)– FS over DHASH (replicated blocks) over Chord
» PAST distributes whole files over Pastry
– distributed read-only file storage
• Ocean store– versioned updates of private, durable storage over untrusted servers

3/26/2003 USITS PlanetLab
Dipping in to OceanStore Prototype
• Studies on 500 virtual nodes across 30 planetlab sites
• Efficiency of dissemination tree– more replicas allows more of the bytes to move across fast
links

3/26/2003 USITS PlanetLab
Tenn IBP traffic
bytes sent per day bytes rcv per day

3/26/2003 USITS PlanetLab
SOSP Crunch

3/26/2003 USITS PlanetLab
Deep resource management
• Inherently shared, inherently distributed
• Individual ownership of portions
• Each research gains unique value from scale
• and many want it at the same time
• Is this where computational economies take off?– not just pricing and mechanism design
– automated contracting and bartering

3/26/2003 USITS PlanetLab
Example Services
• ScriptRoute (Washington)• PlanetProbe (Cambridge)• CoDeeN (Princeton)• End-System Multicast (CMU)• OverQoS (Berkeley, MIT)• Various DHTs
– Chord (Berkeley, MIT), Pastry (Rice), CAN (ICIR),…
• PIER (Berkeley)• OceanStore (Berkeley)• RON (MIT)• NetBait (Intel)• …

3/26/2003 USITS PlanetLab
Evolving the Architecture (Peterson)
Internet
Underlay:
the new thin waste?
routing, topology services
sink down into the internet

3/26/2003 USITS PlanetLab
What Planet-Lab is about• Create the open infrastructure for invention of the next
generation of wide-area (“planetary scale”) services– post-cluster, post-yahoo, post-CDN, post-P2P, ...
• Potentially, the foundation on which the next Internet can emerge
– think beyond TCP/UDP/IP + DNS + BGP + OSPF... as to what the net provides
– building-blocks upon which services and applications will be based– “the next internet will be created as an overlay in the current one” (NRC)
• A different kind of network testbed– not a collection of pipes and giga-pops– not a distributed supercomputer – geographically distributed network services– alternative network architectures and protocols
• Focus and Mobilize the Network / Systems Research Community to define the emerging internet

3/26/2003 USITS PlanetLab
Join the fun ... www.planet-lab.org• It is just beginning
– towards a representative sample of the internet
• Working Groups– Virtualization– Common API for DHTs– Dynamic Slice Creation– System Monitoring– Applications– Software Distribution Tools
• Building the consortium• Hands-on experience with wide-area services at scale is
mothering tremendous innovation– nothing “just works” in the wide-area at scale
• Rich set of research challenges ahead– reach for applications (legal please)
• see Pick up the bootCD, ....Throw in your nodes

3/26/2003 USITS PlanetLab
Thanks







