
Overview of Conditional Logistic Regression
Gur Hoshen
BASAS 7-7-9

What is Conditional Logistic Regression?
Also known as fixed effects (not be confused with fixed vs. random effects model)
Useful for non-experimental data In experimental studies, one ensures that groups of interest have similar
characteristics In non-experimental studies, traditional way was to use explanatory variables to
account for variances in outcomes What happens if we do not have these variables at our disposal?
Use each individual as a control Models are based on variances within individuals

Conditional Logistic Regression: a brief history in SAS
Phreg STRATA ID had limitations in number of records
Strata statement in PROC LOGISTIC version 9 http://www2.sas.com/proceedings/sugi27/p257-27.pdfHas matched pairs example
Paul Allison’s excellent examples under http://www2.sas.com/proceedings/sugi31/184-31.pdf
Longitudinal studies on poverty, repeat offenders STRATA ID (not to be confused with SURVEY PROCs)

Conlog: a slight twist
Can also be used in a completely different context of employment equity, like promotions.
Minorities do not get their fair share of promotions What does this have to be with Conlog? How do we answer such allegations? Consider a simple case first: What is fair share?

Conlog: a slight twist
Example below has data aggregated requisition, but we do have individual data.
AGGREGATED job data
minority applied
white applied
minority promoted
white promoted
expected minority promoted
difference
A 4 4 0 4 2 -2B 2 8 1 0 0.2 0.8C 3 3 3 3 0 0D 4 0 0 0 0 0All 13 15 4 7 2.2 -1.2

Back to Conlog In this particular situation, the STRATA is not the individual ID but the job. Also, in the previous table assumes everyone equally qualified.
Individual qualifications are the explanatory variables account for selections and reduce the disparities
Expected (predicted) promotions is equal to actual at the level of the STRATA in Conlog
Strata where no one (or everyone) is selected do not contribute to disparities “noninformative” strata in SAS Strata with just whites or just minorities do not contribute to disparities

Actual Settled Case Allegation that certain race did not receive promotions proportional to
their representation About 670 applicants About 70 job requisitions
How do we measure this shortfall with no qualifications? Calculate shortfall from one job to the next, then aggregate across all requisitions Assumes minority is equally likely to be selected as white Selection in each job requisition is independent of other job openings Think of it as drawing balls from urns of different colors

Actual Settled Case
AGGREGATED job data
minor-ity applied
white applied
Minor-ity promoted
white promoted
Expdmin-ority promoted
difference
A 4 4 0 4 2.0 -2.0B 2 8 1 0 0.2 0.8C 3 3 3 3 3.0 0.0D 4 5 0 0 0.0 0.0A few dozen+ -- -- -- -- -- -- All 351 323 113 134 120.7 -9.7

Actual Settled Case Notice again that requisitions with no selections or where
everyone is selected have disparities equal to zero Yes, we deal with partial people. This is one way of
quantifying disparities and $s. Some requisitions have positive, others negative shortfall
so one can see which particulars areas are problematic.

Actual Settled Case What if we use unconditional logistic regression? What if we use simulated variables to account for the
disparity? Simulated variables in order to tell a simple story
What if we use simulated variables which do not account for the disparity in order to see if we are over-fitting the model? Common allegation is there are too many variables in model used
in order to capitalize on chance

Variables in Model (100 simulations)
What kind of variables go into model: Education (BA degree or not) Work experience: roughly triangular with lots of “0”s
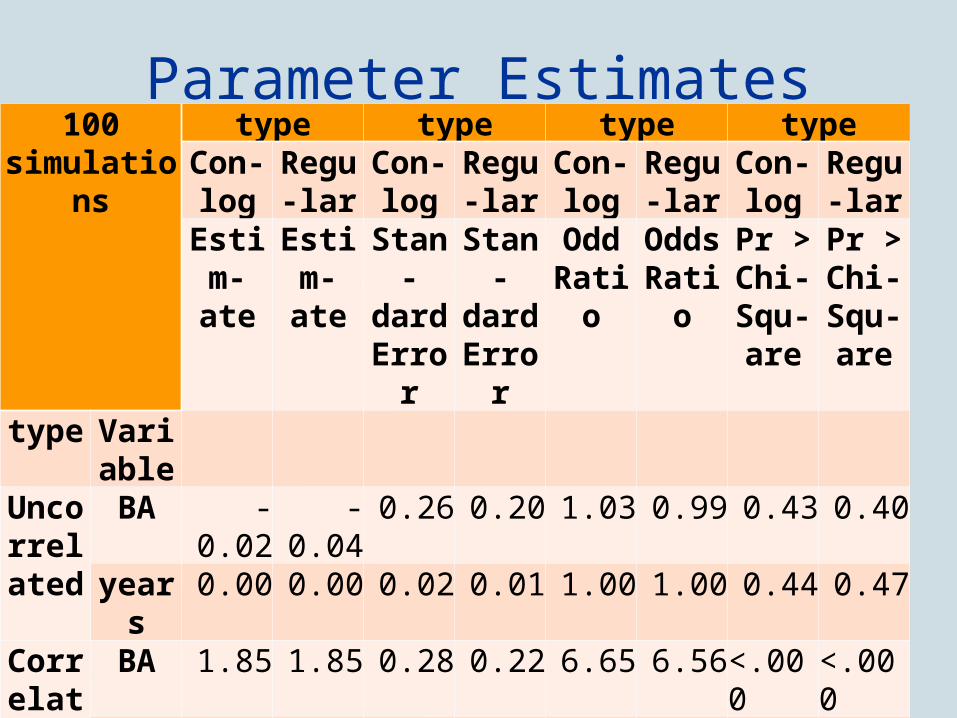
Parameter Estimates100
simulationstype type type type
Con-log
Regu-lar
Con-log
Regu-lar
Con-log
Regu-lar
Con-log
Regu-lar
Estim-ate
Estim-ate
Stan-dard Error
Stan-dard Error
Odd Ratio
Odds Ratio
Pr > Chi-Squ-are
Pr > Chi-Squ-are
type Variable
Uncorrelate
d
BA -0.02 -0.04 0.26 0.20 1.03 0.99 0.43 0.40years 0.00 0.00 0.02 0.01 1.00 1.00 0.44 0.47
Correlated
BA 1.85 1.85 0.28 0.22 6.65 6.56<.000 <.000years 0.11 0.11 0.02 0.01 1.12 1.12<.000 <.000

Disparities Parameter estimates are not meaningful in terms of disparities but one can use predicted probabilities
that an individual will be selected. These can be aggregated to a meaningful disparity. Uncorrelated variables for conditional regression has a disparity of -9.7 (-9.7 if used no qualifications) Note that, even though odd ratios were closers to zero for uncorrelated model for regular model,
disparity increases to -15.6 from -9.7. Why?
l
l
Variables in model
Conditional Regular
correlated with outcome
-6.1 -8.2
Uncorrelated -9.7 -15.6!

l
AGGREGATED job data
minority applied
white applied
minority promoted
white promoted
Expected No Quals
Con-Log
Reg-ular
Diff No Quals
Diff Con-Log
Diff Reg-ular
A 4 4 0 4 2.0 1.9 1.8-2.0 -1.9 -1.8B 2 8 1 0 0.2 1.6 1.6 0.8 -0.6 -0.6C 3 3 3 3 3.0 3.0* 2.8 0.0 0.0 0.2D 4 5 0 0 0.0 0.0* 0.1 0.0 0.0 -0.1A few dozen+ -- -- -- -- -- -- -- -- -- -- All 351 323 113 134 120.7 119.1 121.2-9.7 -6.1 -8.2
* Noninformative strata where we fill in data

Disparities Regular regression ignores that some strata may have no (or 100%) selections and yet calculate non-zero
expected number of selections, as well as strata with one race only If do regular regression by requisition, would have on average, 9-10 applicants per position so could not
use many variables. Could do regression by level of position (low, medium, high) rather than just one overall regression, but
still have problem that some pools with no (or 100%) selections will have non-zero disparities
l
l

Conclusions Can use Conlog in situations where people are competing against one another
Could be for scholarships, college admissions, not just in the labor market Note that if strata have large number of records, resultant disparities are close to regular logistic regressions Can take long time to run if want to output predicted (expected) probabilities Questions?
l
l







