Download - Ontology2 platform

Ontology2 PlatformPaul Houle, Founder Ontology2
Bill Freeman, President KMSolutions
(774) 301-1301
O2
kms

OUR PLATFORM
For organizations handling complex, heterogeneous, and big data from a large number of sources, structured, unstructured and semistructured.We rapidly (in terms of computer time and configuration time) combine, curate, and index your data, both in batch and in real-time.Based on our experience with Freebase (the basis for the Google Knowledge Graph), we combine Hadoop technology with SQL and NoSQL databases on a next generation cloud technology;Focus: quality, usability, cross-domain integration and inference, standards-driven interoperability, open-source components

Current State as we understand it
Technical: Need for extreme agility
• High-quality, curated data is important• Limited by MySQL speed/scalability (and slow schema changes because of row store)• Difficulty of handling taxonomy/ontology/schema changes• Dealing with data loss and broken inter-concept links caused by changes• Difficulty of linking entity between silos; inability to infer accurate, high quality relationships
between collections• Need for clean, normalized data for input to machine learning algorithms• Need ability to manage spatial and temporal data• To keep up with competition: It must be easy has to make changes, fast to implement changes• Need for data typing beyond SQL (currency, length, time interval, etc.) to support inference and
user interfaces• Infrastructure built ad-hoc is difficult to document, maintain, expand
Business Challenges• To be discussed

Benefits from cloud-native Infovore™ platform
Index construction does not interfere with user-facing real-time services
Development, Test and Staging do not interfere with production
Batch Jobs Don’t Interfere with Interactive Services

Next Generation Cloud
• Near Bare Metal PerformanceHardware Virtualization
• Incredible Speed• Predictable Response TimeSSD Drives
• Take advantage of competition between cloud provider
• Use existing on premise capacity; control physical security, flexible options
Hybrid cloud
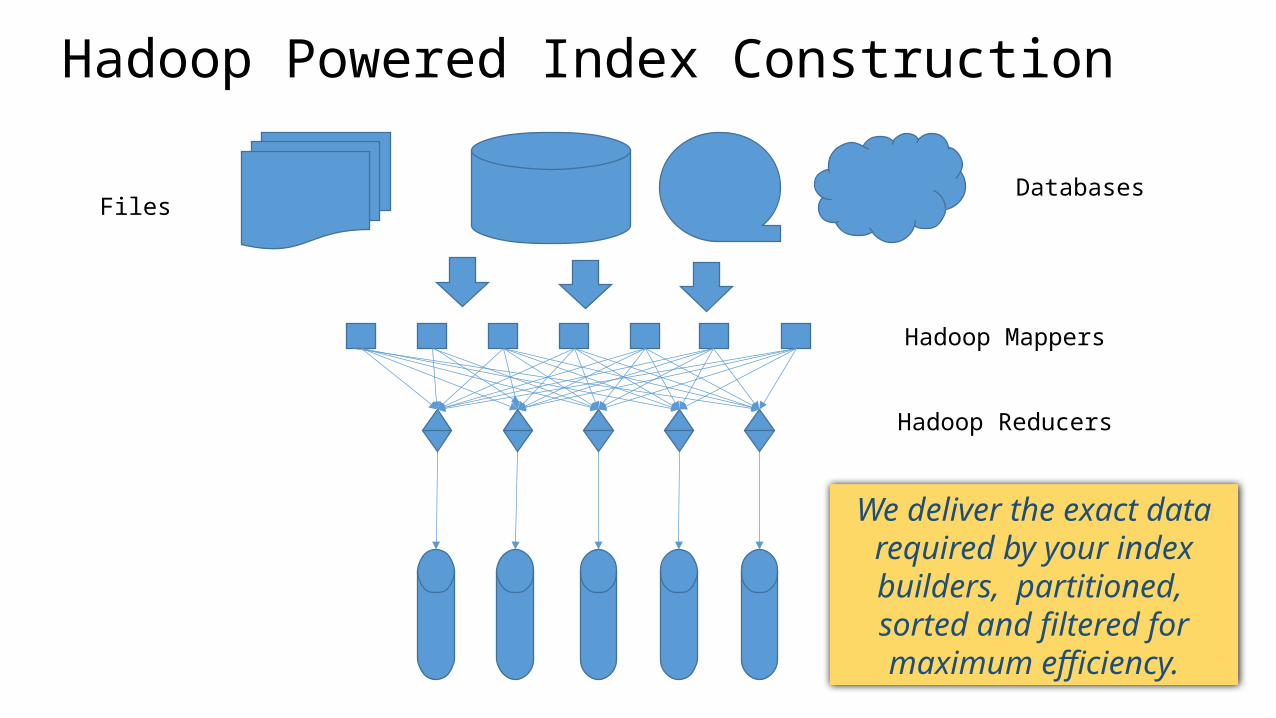
FilesDatabases
Hadoop Mappers
Hadoop Reducers
Hadoop Powered Index Construction
We deliver the exact data required by your index
builders, partitioned, sorted and filtered for maximum
efficiency.

Index Construction in Hybrid CloudNew Index Construction Never Conflicts With Production
time
Old index (multiple copies for throughput & availability)
Source data
Test
Clone
New Index
Terminate andrecover
resources

Batch Index plus Real-Time IndexEffortless and efficient scalability
Message Queue
Bulk Data time stamped master data
small real-time index
large bulk index
merger
RESULTS

New approach to data managementA FRAMEWORK FOR DATA QUALITY
Multiple sources of instance data
Factsclassifications
Reference data…
ExamplesTest Data
Training DataRequirements
Quality metrics

WE DELIVER FAST CYCLE TIME
HYBRID CLOUD: No waiting for hardware
PARALLEL DATA PROCESSING: Handle large data sets quickly
DEVOPS AUTOMATION: Little system administration overhead
EFFICIENT DATA REPRESENTATION: Rapid turnaround, low hardware cost
COMPETITIVEADVANTAGE
MINIMIZE WASTED CYCLESautomation eliminates errors
MINIMIZE TIME AROUND CYCLE

Ontology2 Spatial HierarchyFreebase data enriched for Language+Contextual Performance
Global coverage30+ languages
250 countries
36,000 regions1.5M names
400,000 cites & towns8M names
Large alternative name bank + hierarchical constraint =• Resolution of jurisdictions in international business listings• Resolution of place names in free text

Extensive Graph-Based SchemaMETA-MODEL SYSTEMATICAL DESCRIBES PROCESSES AND THINGS
RDFStypes + properties
XML SCHEMAData types
EXTENDEDData types
DECLARATIVE MAPPINGS
CSV RDBMS XML …
DECLARATIVEHINTS
formatting
editing
…
LINGUISTIC +CONTEXTUAL
KnowledgeRepresentation
SOLVES ISSUES, SEE SLIDE 3 !

Compiledrepresentation
databases
COMMON TEXT FORMATS
CSV, XML, JSON, RDF
FAST BINARY FORMATS
THRIFT, AVROPROTOCOL BUFFERS

RAW DATAEvent-driven real-time pipeline
applications
MERGEDPRODUCTION
INDEX
batch pipeline
MODEL-DRIVEN ARCHITECTUREHANDLING CONTENT AND DATA WITH CONTEXTUAL UNDERSTANDING

SUMMARY
For organizations handling complex, heterogeneous, and big data from a large number of sources, structured, unstructured and semistructured.We rapidly (in terms of computer time and configuration time) combine, curate, and index your data, both in batch and in real-time.Based on our experience with Freebase (the basis for the Google Knowledge Graph), we combine Hadoop technology with SQL and NoSQL databases on a next generation cloud technology;Focus: quality, usability, cross-domain integration and inference, standards-driven interoperability, open-source components
Bill Freeman, President [email protected] (774) 301-1301







