
David J. Mountain
Senior Technical Director
Advanced Computing Systems Research Program
Neuromorphic Computing:
Our approach to developing applications
using a new model of computing

Outline
• Background Info
• Mapping applications onto a neuromorphic computer
• Example Applications*
– AES-256 Encryption
– Malware Identification
• Quantitative results
*I will not be using cats, MNIST digits or ImageNet pictures – there are lots of people demonstrating those applications

Neuromorphic Computing
• The integration of algorithms, architectures, and technologies,
informed by neuroscience, to create new computational
approaches.
Image: zmescience.com
Silicon Brain not required

Neural Networks
Feed-Forward Neural Network
Ʃ
w2
x3
x2
x1 w1
w3
Single Neuron Equation Multiply accumulate (MACC) with an activation function
Activation Function
McCulloch/Pitts Diagram

• A neuron can be considered a threshold gate and used to
perform logic functions
• Many interconnected threshold gates can perform complex
logic functions
Threshold Gates
β = -2.5 β = 0.5
Ʃ
1
x3
x2
x1 1
1 Ʃ
1
x3
x2
x1 1
1
AND OR
Ʃ x1 -1
NOT
β = -0.5

McCulloch & Pitts
Threshold Logic, Neural Nets
A Logical Calculus of the Ideas Immanent in Nervous Activity,
Bulletin of Mathematical Biophysics, 1943
Images: (L) NESFA, Boskone V Conference, 1968 (R) Estate of Francis Bello/ScienceSource via Nautilus/A. Gefter

Frank Rosenblatt
Mark I Perceptron, circa 1960
Images: Hecht-Nielsen, R. Neurocomputing (Reading, Mass.: Addison-Wesley, 1990)
via rutherfordjournal.org.

Different computational primitives
will become the common case:
Majority function example
Digital implementations are relatively inefficient for large numbers of inputs;
MACC-centric design appears to have a large sweet spot
Ʃ
1
d
c
b
1
1
a
e
β = -2.5 1
1 0.00
1.00
2.00
3.00
4.00
5.00
6.00
7.00
0 200 400 600 800 1000
No
rmali
zed
in
pu
ts/s
ec/W
att
Number of inputs
Majority Gate -- Throughput per Watt
MACC
Digital

Our approach
• Architectures that scale to handle real applications
Ohmic Weave
• Methodologies and algorithms for designing/programming these systems
Loom
• Experience & experiments with applications to guide architectures and methodologies
AES-256, malware triage

Implementing neurons using physics
Image: Stan Williams, HP Labs via arstechnica.com
Ʃ
w2
x3
x2
x1 w1
w3
- + -
I = V/R
G = 1/R
I = VG
Multiply
Multiply
Multiply
Accumulate

3x4 Crossbar = 2 Neurons
+ - + -
memristor
input
drivers
comparators

Ohmic Weave: Single Tile
INP
UT
DR
IVE
RS
COMPARATORS IO
PORT
+ - + - memristor
input
drivers
comparators
256x256 memristor crossbar
128 differential comparators
All inputs and all outputs are sent to a central router
256 axons, 128 neurons, 65536 synapses

Ohmic Weave: 64 Tile General
Purpose Processor*
64 port router
all-to-all connectivity
16k axons
8k neurons
4M synapses
*56 Tera synaptic ops per watt (TSOPS/W), 1.1 TSOPS/mm2

Tools, Methodologies, Algorithms
• Loom – Ohmic Weave design tool
– Python classes with C, Cuda extensions
– Enables exploration of design trade-offs
• Limited precision weights
• Neural network topologies (layers, neurons per layer)
• Connectivity pruning
• Simulates Ohmic Weave designs on CPUs, GPUs • Debug with full view of internal state

Methodology: Block Based Design
• Decompose the problem into blocks
– Much like block based CMOS design
– Can pull blocks from a “circuit library”
• Loom can compose blocks into a single larger network
– Will optimize by removing unused neurons and connections
– Compresses to minimum number of layers
– Handles recurrence/loops

Digital Hierarchical Neural Nets
• Digital functions must be 100% correct
• Divide and conquer by partitioning – 64 inputs = 1.6 x 1019 training vectors
– 4 x 16 inputs = 2.56 x 105 training vectors
• Reduce the training set size – But train to 100% accuracy
– The logic truth table becomes the training set
– The training data encompasses all possible data

Training
• Loom can train blocks given a training set or
truth table
– Uses the Concurrent Learning Algorithm*
– Can train for exact logic or for inexact classifiers
*M. McLean, “Concurrent Learning Algorithm and the Importance Map,” Network Science and Cybersecurity, ed. By R. Pino, Springer 2014,
vol. 55, pp. 239-250.

Libraries and Composability
• Once trained, a block can be reused
– Train once, use often
• We have a growing library, starting with simple logic
(NANDs, NORs, latches) and growing to more sophisticated
functions (majority gates)
• We have algorithms for composing multiple neural networks
into a single network

AES-256 Encryption
• Advanced Encryption Standard, 256 bit – 128 bits of data encrypted using 256 bit key
– Algorithm uses 14 rounds of 4 steps each
– Published standard, result must be exact
• Ohmic Weave Implementation – 45 blocks, 21 unique types
• 16 Subbytes Blocks, 3 Mix Col Blocks, 1 Control Block, 1 Mux
• Each Subbytes block unique because keys “baked in”
– 12,500 neurons in 10 layers
– Each block trained using CLA

AES-256 Conceptual Diagram
45 instances of 21 unique blocks
About 12,500 neurons in 10 layers
SubBytes
SubBytes
SubBytes
MixCol
C
MixCol
A
MixCol
B
Cypher
text MixCol
C
MixCol
C
MixCol
C
32 b
it mux
SubBytes 8
ShiftRows
(to other cols)
8
8
8 16
16
State Machine
Plain
text

Application: Malware Detection
• Classifies files as malware (e.g. virus) or
benign
– Looks at the file in 6 byte n-grams at a time
– Matches 2000 critical n-grams, notes their
presence in a 2000 bit latch
– Uses a neural network classifier to decide if pattern
in latch is malware

48:1536
DECODER
6 byte
n-gram 2000
PATTERN
MATCHER
2000
BIT
LATCH
MALWARE
DETECTOR
STAGE
1
MALWARE
DETECTOR
STAGE
2
malware?
Conceptual Diagram
About 4007 instances of 5 unique blocks
About 5800 neurons in 5 layers

Mapped to Ohmic Weave using Loom
64 port router
all-to-all connectivity
Layer 1
Layer 2
Layer 3
Layer 4
Layer 5
Unused

Malware detection using neural nets:
General purpose Ohmic Weave vs CPU
Function Area (mm^2) Power (mW)
Row Drivers 0.70 77.56
Memristive Array 8.15 860.36
Comparators 15.01 38.78
Router 0.43 493.04
Total 24.29 1469.74
CPU: 6 Core Intel Core i7 3930K; Throughput is 1.92 Gbps
Ohmic Weave requires 12 copies to match that throughput
Numbers shown below are total for 12 copies -- comparison is performance neutral
14x Improvement in Area
54x Improvement in Power*
*Aggressive implementations of memristor technology and on-chip routing increase the power improvement to ~500x
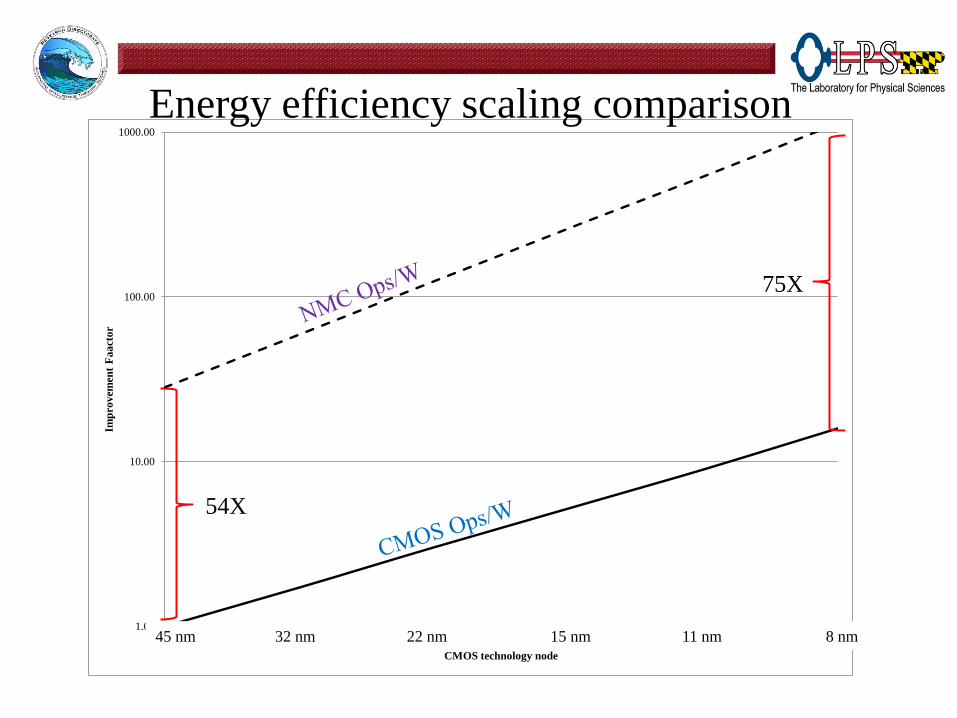
1.00
10.00
100.00
1000.00
0 1 2 3 4 5
Imp
rov
emen
t F
aa
cto
r
CMOS technology node
Energy efficiency scaling comparison
54X
75X
45 nm 32 nm 22 nm 15 nm 11 nm 8 nm

Roadmap Forward
• Fabricate and characterize circuits
• Continue to characterize memristor crossbars
• Build increasingly mature prototype boards
– Explore on-chip vs. off-chip training
– Validate routing choices
– Provide more realistic power comparisons
• Improve tools and simulation environment
• More applications and comparisons (to FPGA, GPU, ASIC, etc.)

Acknowledgments to the NMC team that
is making all this happen
Chris Krieger
Mark McLean
Josh Prucnal
Doug Palmer
along with a substantial number of
academic, national lab and industry
partners

Questions?

A first attempt at road mapping NMC
• Strengths
– CMOS compatible
– Room T operation
– Integrates with
other approaches
(traditional,
approximate)
– Self-learning
• Neutral
– Security
– Programmer
productivity
• Weaknesses
– Legacy code
– FP intensive
applications
– Serial speed
– Data selection
Efficient STDP/Spiking device
Memristors
Access devices (monolithic 3D)
Comparators and on-chip programming
Interconnect density
Controlled growth of interconnects
Efficient analog comms (or efficient
transducers to optical, magnetic, etc.);
includes sensors
NMC attributes
Nanotechnology challenges

What are the right metrics?
Ops/analyst
Ops/trained analyst
Learning rate for analysts
Scaling rate
World Class
Expert
Proficient
Skilled
Entry Level
Novice
Skill level pyramid
How much of the pyramid can you
augment with NMC?







