
Data LibertyAlternatives to the shackles of limited scale in data solutions
Andy Cross
Windows Azure MVP
Elastacloud

Competition and Hashtag
• Tell everyone I’m awesome #ukmvpcloud
• Fill in the forms on your seats – for a chance to win a WINDOWS PHONE!

Data value at scale requires technology choices;
* often prioritising data read traversal over operational characteristics of create/update/delete
* embracing hybrid data platforms with varied technology partners over homogenous estates
* establishing alternative skillsets, augmented with entrenched languages, trusting cloud over maintenance
* following robust engineering processes to provide rigour in a deterministic world

Bravery leads to rewards;
* the winners will have data which shows them that they’ve won
* the commoditised query turns energy sucking data silos into profit centres
* new data traversal mechanisms lead to new connotative data expression
* everything you already know is relevant and valid; the constraints on how it is applied are not

Today we’ve already heard about the position of big data in the market and the usual
I’m going to give a tour of actually how to get some value out. By value I mean a result to a query. It’s not going to be visualised.
But it’s a tour so lets start with the history.

IBM have been a leader in Big Data for years.
Wikimedia commons

We’re not as great as we’d hope; we’re often still bound by our ability to marshal our IO.
Just as the speed of loading punchcards was historically a limiting factor, we are now limited by our capacity to ingest data on individual machines.
This leads to ideas such as DFS and data locality.


During the evolution of data we eventually moved to client/server and this was a big step up from dBase et al of the time.
Fundamentally however, the tabular structured nature of data poses many changes; not least the long term effects of normalisation which trade off effective storage in the short term with long term offset compute which is required to reconstruct sets.
This eventually leads to such ideas as NoSQL document and entity stores.


Modelling of data provides a consistent challenge. Our world is highly connected and our brains are effective connectors of data. Real world data fits poorly into highly structured data sets.
This leads to semi-structured and unstructured data formats and data queryability through relationship traversal

The technologies shown today are primarily written in non-.net and non-Microsoft languages and frameworks. Every time we do this, I’ll show examples ONLY in the .net and Microsoft stacks.
There are obviously challenges beyond language to running the alternative stacks; but remember in the Cloud you aren’t responsible for tuning a Linux cluster which has been running for 5 years. You should provision for a duration that is bounded by the likelihood of the cluster requiring routine maintenance.

Hadoop – KEY FACTS
Open Source; Apache Foundation.
Java.
Map Reduce framework for job distribution; Distributed File System for file access.
In Windows Azure this is known as HDInsight.

Hadoop is O(n)It exhibits linear performance; when the dataset doubles, the time taken to execute the algorithm doubles.

Hadoop SDK

public class SwedishSessionsJob : HadoopJob<SwedishSessionsMapper, SessionsReducer>
{
public override HadoopJobConfiguration Configure(ExecutorContext context)
{
var config = new HadoopJobConfiguration()
{
InputPath = "\"/AllSessions/*.gz\"",
OutputFolder = "/SwedishSessions/"
};
return config;
}
}
Jobs

public class SwedishSessionsMapper : MapperBase
{
public override void Map(string inputLine, MapperContext context)
{
if (inputLine.Contains("Country=Sweden")
{
context.IncrementCounter("SwedishSession");
context.EmitKeyValue(“SE", "1");
}
}
}
Mapper

public class SessionsReducer : ReducerCombinerBase
{
public override void Reduce(string key, IEnumerable<string> values, ReducerContext context)
{
context.EmitKeyValue(key, values.Count());
}
}
Reducer

Testing Hadoop Queries
var inputData = "Country=Sweden&Name=Magnus";
var result = StreamingUnit.Execute<Jobs.SwedishJob>(new[]{inputData});
Assert.AreEqual("SE\t1", result.ReducerResult.First());

* Tools are great but not friendly
HDInsight wins.
Automated provisioning and job execution services.
Transient clusters limit exposure to poorly tooled* java estate.
Persistence with Windows Azure Blob Storage as HDFS proxy known as Azure Storage Vault (ASV).
Persistence in Windows Azure SQL Database for Hive Metastore.
Javascript console.

NoSQL Document and Entity Stores
Examples in MongoDb and Windows Azure Table Storage.
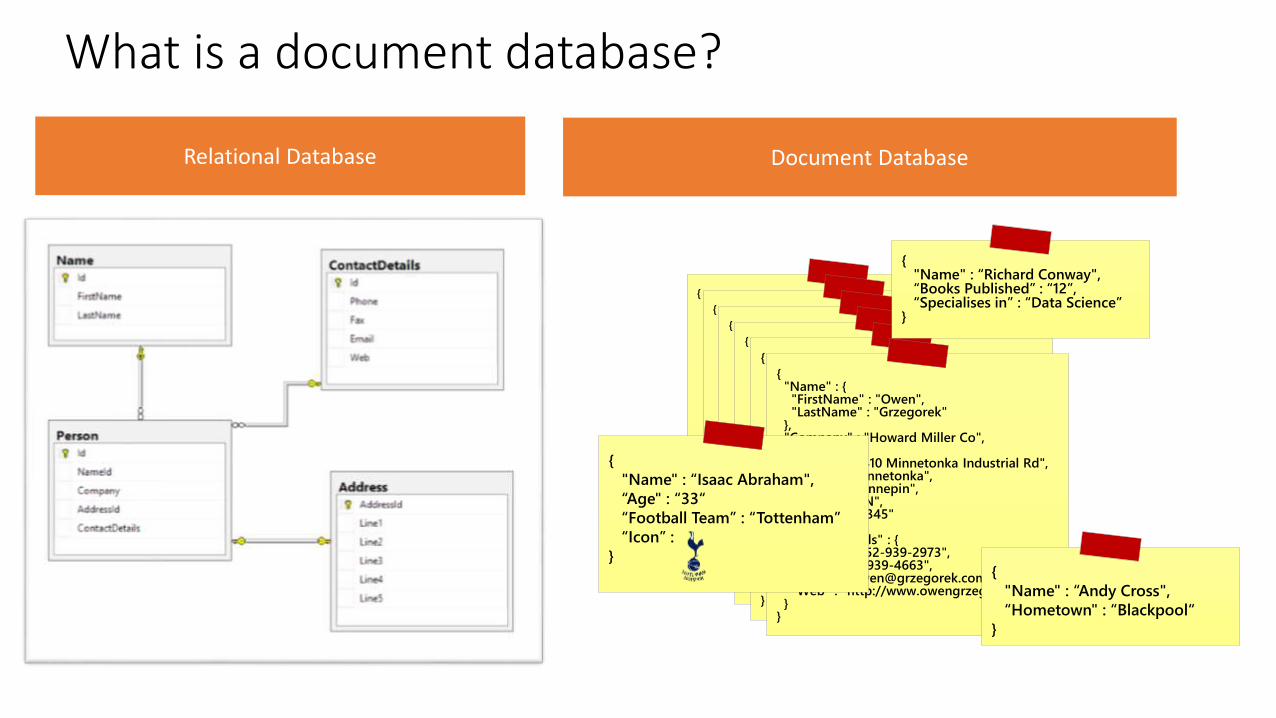
What is a document database?
{"_id" : ObjectId("51fccc57f82352d76653bdae"),"Name" : {"FirstName" : "Owen","LastName" : "Grzegorek"
},"Company" : "Howard Miller Co","Address" : {"Line1" : "15410 Minnetonka Industrial Rd","Line2" : "Minnetonka","Line3" : "Hennepin","Line4" : "MN","Line5" : "55345"
},"ContactDetails" : {"Phone" : "952-939-2973","Fax" : "952-939-4663","Email" : "[email protected]","Web" : "http://www.owengrzegorek.com"
}}
{"_id" : ObjectId("51fccc57f82352d76653bdae"),"Name" : {"FirstName" : "Owen","LastName" : "Grzegorek"
},"Company" : "Howard Miller Co","Address" : {"Line1" : "15410 Minnetonka Industrial Rd","Line2" : "Minnetonka","Line3" : "Hennepin","Line4" : "MN","Line5" : "55345"
},"ContactDetails" : {"Phone" : "952-939-2973","Fax" : "952-939-4663","Email" : "[email protected]","Web" : "http://www.owengrzegorek.com"
}}
{"_id" : ObjectId("51fccc57f82352d76653bdae"),"Name" : {"FirstName" : "Owen","LastName" : "Grzegorek"
},"Company" : "Howard Miller Co","Address" : {"Line1" : "15410 Minnetonka Industrial Rd","Line2" : "Minnetonka","Line3" : "Hennepin","Line4" : "MN","Line5" : "55345"
},"ContactDetails" : {"Phone" : "952-939-2973","Fax" : "952-939-4663","Email" : "[email protected]","Web" : "http://www.owengrzegorek.com"
}}
{"_id" : ObjectId("51fccc57f82352d76653bdae"),"Name" : {"FirstName" : "Owen","LastName" : "Grzegorek"
},"Company" : "Howard Miller Co","Address" : {"Line1" : "15410 Minnetonka Industrial Rd","Line2" : "Minnetonka","Line3" : "Hennepin","Line4" : "MN","Line5" : "55345"
},"ContactDetails" : {"Phone" : "952-939-2973","Fax" : "952-939-4663","Email" : "[email protected]","Web" : "http://www.owengrzegorek.com"
}}
{"Name" : {
"FirstName" : "Owen","LastName" : "Grzegorek"
},"Company" : "Howard Miller Co","Address" : {
"Line1" : "15410 Minnetonka Industrial Rd","Line2" : "Minnetonka","Line3" : "Hennepin","Line4" : "MN","Line5" : "55345"
},"ContactDetails" : {
"Phone" : "952-939-2973","Fax" : "952-939-4663","Email" : "[email protected]","Web" : "http://www.owengrzegorek.com"
}}
{"Name" : {
"FirstName" : "Owen","LastName" : "Grzegorek"
},"Company" : "Howard Miller Co","Address" : {
"Line1" : "15410 Minnetonka Industrial Rd","Line2" : "Minnetonka","Line3" : "Hennepin","Line4" : "MN","Line5" : "55345"
},"ContactDetails" : {
"Phone" : "952-939-2973","Fax" : "952-939-4663","Email" : "[email protected]","Web" : "http://www.owengrzegorek.com"
}}
{"Name" : “Richard Conway",“Books Published” : “12”,“Specialises in” : “Data Science”
}
{
"Name" : “Andy Cross",
“Hometown" : “Blackpool“
}
{
"Name" : “Isaac Abraham",
“Age" : “33“
“Football Team” : “Tottenham”
“Icon” :
}

MongoDB Key Facts
• High Performance
• High Availability
• Easy Scalability

MongoDB is O(log n)It exhibits logarithmic performance; when the dataset doubles, the time taken to execute the algorithm increases by a fixed amount

Strengths of MongoDB

Mongo SDK
There are many different way to connect with MongoDB from a .netproject.
Official
Wrapper
Alternative
Tool

C# implementations
If your data is regularly structured, you can use domain classes:
public class Book{
public string Author { get; set; }public string Title { get; set; }
}
// "entities" is the name of the collectionvar books = database.GetCollection<Entity>("books");
Book book = new Book{
Author = "Ernest Hemingway",Title = "For Whom the Bell Tolls"
};books.Insert(book);

C# implementations
If your data is irregularly structured or semi-structured, you can use a BSON object model:BsonDocument person = new BsonDocument {
{ "name", "John Doe" },{ "address", new BsonDocument {
{ "street", "123 Main St." },{ "city", "Centerville" },{ "state", "PA" },{ "zip", 12345}
}}};
var people = database.GetCollection<BsonDocument>("people");
people.Insert(person);

Windows Azure Table Storage

Table Storage Concepts

Table Details

Entity Properties

No Fixed Schema

Querying

Purpose of the PartitionKey

ScalabilityPartition: Range of entities with same partition key value.Partitions are fanned out based on loadThey can be condensed when load decreasesReads are load balanced against three replicas


C# Examples
public class Book : TableEntity{
public string Author { get; set; }public string Title { get; set; }
}

// Retrieve the storage account from the connection string.CloudStorageAccount storageAccount = CloudStorageAccount.Parse(
CloudConfigurationManager.GetSetting("StorageConnectionString"));
// Create the table client.CloudTableClient tableClient = storageAccount.CreateCloudTableClient();
// Create the CloudTable object that represents the "people" table.CloudTable table = tableClient.GetTableReference("books");
// Create a new customer entity.Book book = new Book() { Author = "Ernest Hemingway", Title = "For Whom The Bell Tolls" };book.PartitionKey = "ErnestHemingway";book.RowKey = "1";
// Create the TableOperation that inserts the customer entity.TableOperation insertOperation = TableOperation.Insert(customer1);
// Execute the insert operation.table.Execute(insertOperation);

NoSQL Document and Entity store Wins
Semi-structured data first class citizen
Built in MapReduce
Operational and interactive
Massively scalable *if you get your partitions correct*

Graph Databases, Neo4j KEY FACTS
Open Source; Neotechnologies
Java
Runs equally well on Windows or Linux. In Windows Azure there are VMDepot images able to be deployed in a few simple steps. Additionally the Azure Linux VMs are a good fit for this database engine.
There is an Open Source .net SDK available through Nuget and actively maintained primarily by an Australian company, Readify.

Neo4j is O(1)It exhibits constant-time performance; that is, the algorithm takes the same time to execute irrespective of the size of the dataset.

How O(1)?
• Graphs don’t have tables. They don’t have collections.
• They have nodes and relationships.
• Rather than having to select out a whole table, we can identify a point on the graph• A start point
• Follow the traversal of relationships from that point.

http://www.apcjones.com/arrows/#

Things we can do
• Find all the things formed in Sweden
START sweden = node:countryIdx(“country=Sweden”)
MATCH Sweden<-[:FORMED_IN]-something
RETURN something;
• Find friends of friends
START magnus = node:peopleIdx(“name=magnus”)
MATCH magnus-[:FRIENDS]->friend-[:FRIENDS]->friendoffriend
RETURN friendoffriend;

NEO4J Client
Open source Neo4j Client

C# examples
var query = neo4Jclient.Cypher.Start(new{
sweden = Node.ByIndexLookup("countryIdx", "country", "sweden")}).Match("sweden-[:FRIENDS]->friend-[:FRIENDS]->friendoffriend").Return<Node<Friend>>("friendoffriend");

Graph Database Wins
• Modelled domains match cognitive processes
• Optimised for traversal of relationships allow complex and “social” queries to emerge• LIKES of FRIENDS of COLLEAGUES
• O(1) performance characteristics due to ability to START queries at arbitrary graph points.

Summary
• HDInsight brings Hadoop to Azure• Suited to Data Volume, Variety, Variability etc
• MongoDB brings Document stores• Suited to Data Volume, Operational concerns
• Table Storage brings Entity stores• Suited to Data Volume, strong consistency requirements, low cost and TCO
• Neo4j brings Graph database• Suited to data relationship traversal

ThanksQuestions







