
IO-Lite:IO-Lite:A Unified Buffering and Caching SystemA Unified Buffering and Caching System
By Pai, Druschel, and Zwaenepoel (1999)By Pai, Druschel, and Zwaenepoel (1999)
Presented by Justin KligerPresented by Justin Kligerfor CS780: Advanced Techniques in Cachingfor CS780: Advanced Techniques in Caching
Professor Zhang (Summer 2005)Professor Zhang (Summer 2005)

OutlineOutline
Problem & SignificanceProblem & Significance Literature ReviewLiterature Review Proposed Solution Proposed Solution Design, Implementation, & OperationDesign, Implementation, & Operation Experimental Design Experimental Design ResultsResults Conclusion Conclusion Further ResearchFurther Research

The ProblemThe Problem
The I/O subsystem and various The I/O subsystem and various applications all tend to use their own applications all tend to use their own private I/O buffersprivate I/O buffers
Redundant data copyingRedundant data copying
Multiple bufferingMultiple buffering
Lack of cross-subsystem optimizationLack of cross-subsystem optimization

Problem’s SignificanceProblem’s Significance
Wastes memoryWastes memory
Reduces space Reduces space available for cachingavailable for caching
Causes higher cache Causes higher cache miss ratesmiss rates
•High CPU overhead
Limits server throughput

Literature ReviewLiterature Review
1.1. POSIX I/OPOSIX I/O-Problem: -Problem:
double-bufferingdouble-buffering
2.2. Memory-mapped files (Memory-mapped files (mmapmmap))
--Problem:Problem:Not generalized to network I/ONot generalized to network I/O

Literature ReviewLiterature Review
3.3. Transparent Copy AvoidanceTransparent Copy Avoidance-Problem:-Problem:
VM page alignment problemsVM page alignment problems
Copy-on-write faultsCopy-on-write faults Genie (emulated copy)Genie (emulated copy)
Lack of full transparency leads to same problemsLack of full transparency leads to same problems
4.4. Copy Avoidance with Handoff SemanticsCopy Avoidance with Handoff Semantics-Problem:-Problem:
Lack of concurrent sharing reduces effectivenessLack of concurrent sharing reduces effectiveness

Literature ReviewLiterature Review
5.5. Fast buffers (Fast buffers (fbufsfbufs))Designed by DruschelDesigned by Druschel
-Problem:-Problem:Does not support filesystem access,Does not support filesystem access,
or a file cacheor a file cache
6.6. Extensible kernelsExtensible kernels-Problem:-Problem:
More overhead, not OS-portableMore overhead, not OS-portable

IO-Lite SolutionIO-Lite Solution
UnifiedUnified buffering and caching buffering and caching
Allow all applications and subsystems share Allow all applications and subsystems share the same buffered I/O datathe same buffered I/O data
Very simple at face value, Very simple at face value,
very complex to implementvery complex to implement

Basic DesignBasic Design
Immutable buffersImmutable buffers Initial allocated data cannot be modifiedInitial allocated data cannot be modified Effectively read-only sharingEffectively read-only sharing
Advantages?Advantages? Eliminates synchronization and protection Eliminates synchronization and protection
problemsproblems
Disadvantages?Disadvantages? I/O data cannot be modified in placeI/O data cannot be modified in place

Further Design ConsiderationsFurther Design Considerations
To make up for immutable buffers:To make up for immutable buffers: Create buffer aggregate abstraction (an ADT)Create buffer aggregate abstraction (an ADT)
mutablemutable
Reference to Reference to IO-Lite WindowIO-Lite Window in VM in VM
Aggregates contain ordered list of form <address, length>Aggregates contain ordered list of form <address, length> Aggregates passed by valueAggregates passed by value Buffers passed by referenceBuffers passed by reference

Further Design ConsiderationsFurther Design Considerations
Buffer sharing must be Buffer sharing must be concurrentconcurrent
To achieve this, use similar method to To achieve this, use similar method to fbufsfbufs Expand to include the filesystemExpand to include the filesystem
Adapts for general purpose OSAdapts for general purpose OS
Worst case scenario (in terms of overhead):Worst case scenario (in terms of overhead): Page remapping Page remapping
(when last buffer is allocated before first is deallocated)(when last buffer is allocated before first is deallocated)

IO-Lite ImplementationIO-Lite Implementation
New read & write API which supersedes New read & write API which supersedes the regular read & write the regular read & write
size_t IOL_read(int fd, IOL_Agg **aggr, size_t size);size_t IOL_read(int fd, IOL_Agg **aggr, size_t size); size_t IOL_write(int fd, IOL_Agg *aggr);size_t IOL_write(int fd, IOL_Agg *aggr);
IOL_Agg is buffer aggregate data typeIOL_Agg is buffer aggregate data type
Both operations are Both operations are atomicatomic

IO-Lite ImplementationIO-Lite Implementation
Applications:Applications: Recommends implementation in runtime I/O Libraries Recommends implementation in runtime I/O Libraries
to avoid modifying all programsto avoid modifying all programs
Filesystem:Filesystem: File cache data structure: <file-id, offset, length>File cache data structure: <file-id, offset, length>
Network:Network: Need to modify network device drivers to allow Need to modify network device drivers to allow early early
demultiplexingdemultiplexing (using a packet filter) (using a packet filter)

IO-Lite OperationIO-Lite Operation
With regards to the cache:With regards to the cache:
Cache replacement basically LRUCache replacement basically LRU Allows for application customizationAllows for application customization
Cache eviction controlled by VM daemonCache eviction controlled by VM daemon Do >½ replaced pages contain I/O data?Do >½ replaced pages contain I/O data?

IO-Lite OperationIO-Lite Operation
Impact of immutable buffers:Impact of immutable buffers:
Case 1: Entire object is modifiedCase 1: Entire object is modified Lack of in-place modification has no ill effectLack of in-place modification has no ill effect
Case 2: Subset of object needs to be modifiedCase 2: Subset of object needs to be modified Rather than recopy entire object, use Rather than recopy entire object, use chainingchaining
Performance loss is small if blocks are localizedPerformance loss is small if blocks are localized
Case 3: Scattered subset needs modificationCase 3: Scattered subset needs modification IO-Lite incorporates IO-Lite incorporates mmapmmap interface for this interface for this

Experimental DesignExperimental Design
Compared:Compared:
Apache 1.3.1Apache 1.3.1Widely used web serverWidely used web server
Flash (event-driven HTTP server)Flash (event-driven HTTP server)Designed by authors in previous yearDesigned by authors in previous year
Flash-Lite (Flash modified to use IO-Lite API)Flash-Lite (Flash modified to use IO-Lite API)New design by authorsNew design by authors

Experimental DesignExperimental Design
1.1. General: varied requested file sizeGeneral: varied requested file size 40 requests for same file40 requests for same file File size ranged from 500 bytes – 200 KbytesFile size ranged from 500 bytes – 200 Kbytes
2.2. Persistent connectionsPersistent connections Reduces overheadReduces overhead
3.3. CGICGI Additional I/O traditionally slows serversAdditional I/O traditionally slows servers

Experimental DesignExperimental Design
4.4. Real workloadsReal workloads Shows performance benefits by allowing more Shows performance benefits by allowing more
space for cachingspace for caching Based on Rice’s CSCI department logsBased on Rice’s CSCI department logs
5.5. Wide Area Network (WAN)Wide Area Network (WAN) Test throughput with 0-256 slow clients connectingTest throughput with 0-256 slow clients connecting
6.6. ApplicationsApplications Incorporated API into UNIX programsIncorporated API into UNIX programs
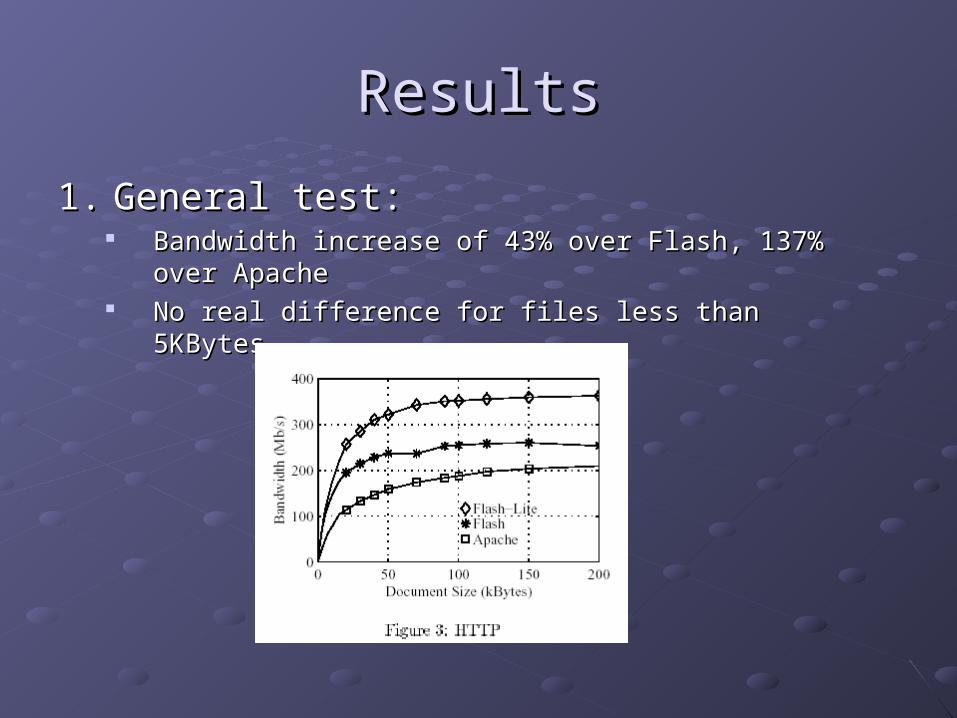
ResultsResults
1.1. General test:General test: Bandwidth increase of 43% over Flash, 137% over ApacheBandwidth increase of 43% over Flash, 137% over Apache No real difference for files less than 5KBytesNo real difference for files less than 5KBytes

ResultsResults
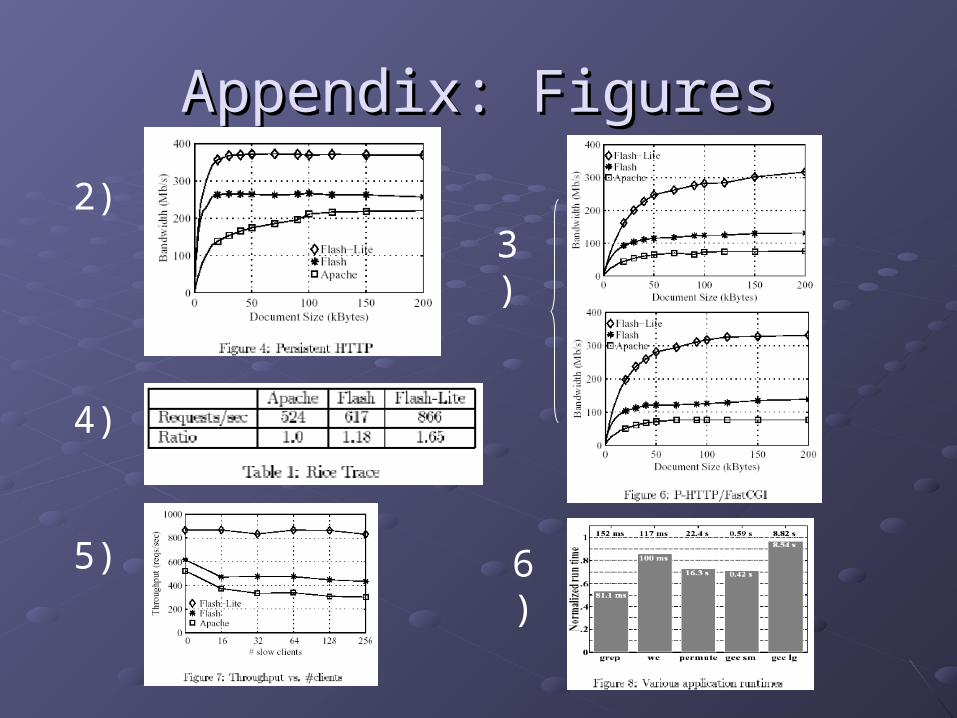
2.2. Persistent ConnectionsPersistent Connections Flash-Lite even more effective at smaller file sizesFlash-Lite even more effective at smaller file sizes
3.3. CGICGI All servers slow, but Flash-Lite still much betterAll servers slow, but Flash-Lite still much better
4.4. Real workloadReal workload Flash-Lite throughput 65% greater than ApacheFlash-Lite throughput 65% greater than Apache
5.5. WANWAN Flash-Lite does not suffer from slow clientsFlash-Lite does not suffer from slow clients
6.6. ApplicationsApplications Varied improvement for all programs testedVaried improvement for all programs tested

ConclusionConclusion
IO-Lite consistently improved IO-Lite consistently improved performance in all contexts testedperformance in all contexts tested
Requires modification to numerous Requires modification to numerous libraries and network device driverslibraries and network device drivers EG: see Peng, Sharma, & Chiueh (2003)EG: see Peng, Sharma, & Chiueh (2003)

Further ResearchFurther Research
There have been 42 citations There have been 42 citations Almost all fell between 2001-2003Almost all fell between 2001-2003
Authors have not written any follow-upsAuthors have not written any follow-ups
Lack of papers that involve implementation Lack of papers that involve implementation of IO-Lite or a variation of itof IO-Lite or a variation of it Probably because of complexity and number Probably because of complexity and number
of modifications that are necessaryof modifications that are necessary
Appendix: FiguresAppendix: Figures
2)
4)
5)
3)
6)

Questions?Questions?







