
Glenn Reinman, Brad Calder,
Department of Computer Science and Engineering,
University of California San Diego
and Todd AustinDepartment of Electrical Engineering and Computer Science,
University of Michigan

Fetch Directed Instruction PrefetchingFetch Directed Instruction Prefetching 2
IntroductionIntroduction• Instruction supply critical to processor performance
– Complicated by instruction cache misses– Instruction cache miss solutions:
• Increasing size or associativity of instruction cache
• Instruction cache prefetching– Which cache blocks to prefetch?
– Timeliness of prefetch
– Interference with demand misses
...Instruction Fetch
Execution Core
Issue Buffer

Fetch Directed Instruction PrefetchingFetch Directed Instruction Prefetching 3
Prior Instruction Prefetching WorkPrior Instruction Prefetching Work• Next line prefetching (NLP) (Smith)
– Each cache block is tagged with an NLP bit
– When block is accessed during a fetch
• NLP bit determines whether next sequential block is prefetched
– Prefetch into fully associative buffer
• Streaming buffers (Jouppi)
– On cache miss, sequential cache blocks, starting with block that
missed, are prefetched into a buffer
• Buffer can use fully associative lookup
• Uniqueness filter can avoid redundant prefetches
• Multiple streaming buffers can be used together

Fetch Directed Instruction PrefetchingFetch Directed Instruction Prefetching 4
Our Prefetching ApproachOur Prefetching Approach• Desirable characteristics
– Accuracy of prefetch
• Useful prefetches
– Timeliness of prefetch
• Maximize prefetch gain
• Fetch Directed Prefetching
– Branch predictor runs ahead of instruction cache
– Instruction cache prefetch guided by instruction stream

Fetch Directed Instruction PrefetchingFetch Directed Instruction Prefetching 5
Talk OverviewTalk Overview
• Fetch Target Queue (FTQ)
• Fetch Directed Prefetching (FDP)
• Filtering Techniques
• Enhancements to Streaming Buffers
• Bandwidth Considerations
• Conclusions

Fetch Directed Instruction PrefetchingFetch Directed Instruction Prefetching 6
Fetch Target QueueFetch Target Queue
• Queue of instruction fetch addresses
• Latency tolerance– Branch predictor can continue in face of icache miss
– Instruction Fetch can continue in face of branch predictor miss
• When combined with high bandwidth branch predictor– Provides stream of instr addresses far in advance of current PC
Branch Predictor
Instruction Fetch
Execution Core
... ...
FTQ Issue Buffer

Fetch Directed Instruction PrefetchingFetch Directed Instruction Prefetching 7
Fetch Directed PrefetchingFetch Directed Prefetching
Instruction FetchBranch Predictor
FTQ
Fully associative
buffer
Prefetch Enqueue(filtration mechanisms)
Prefetch
current FTQprefetch candidate
•Stream of PCs contained in FTQ guides prefetch–FTQ is searched in-order for entries to prefetch–Prefetched cache blocks stored in fully associative queue–Fully associative queue and instruction cache probed in parallel
PIQ
(32 entry)
(32 entry)

Fetch Directed Instruction PrefetchingFetch Directed Instruction Prefetching 8
MethodologyMethodology• SimpleScalar Alpha 3.0 tool set (Burger, Austin)
– SPEC95 C Benchmarks• Fast forwarded past initialization portion of benchmarks
– Can issue 8 instructions per cycle
– 128 entry reorder buffer
– 32 entry load/store buffer
– Variety of instruction cache sizes• 16K 2-way and 4-way associative
• 32K 2-way associative
• Tried both single and dual ported configurations
– Instruction cache size for this talk is 16K 2-way
– 32K 4-way associative data cache
– Unified 1MB 4-way associative second level cache

Fetch Directed Instruction PrefetchingFetch Directed Instruction Prefetching 9
Bandwidth ConcernsBandwidth Concerns• Prefetching can disrupt demand fetching
– Need to model bus utilization
• Modified SimpleScalar’s memory hierarchy
– Accurate modeling of bus usage
– Two configurations of L2 cache bus to main memory
• 32 bytes/cycle
• 8 bytes/cycle
– Single port on L2 cache
• Shared by both data and instruction caches
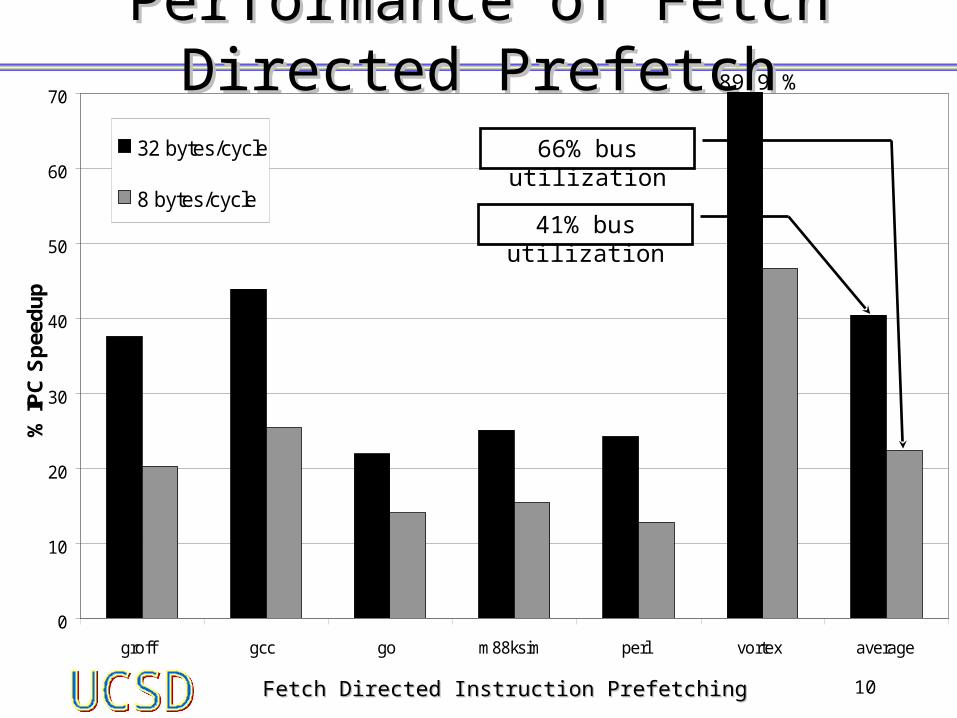
Fetch Directed Instruction PrefetchingFetch Directed Instruction Prefetching 10
Performance of Fetch Directed PrefetchPerformance of Fetch Directed Prefetch
0
10
20
30
40
50
60
70
groff gcc go m88ksim perl vortex average
% IP
C S
pee
du
p
32 bytes/cycle
8 bytes/cycle
41% bus utilization
66% bus utilization
89.9 %

Fetch Directed Instruction PrefetchingFetch Directed Instruction Prefetching 11
Reducing Wasted PrefetchesReducing Wasted Prefetches• Reduce bus utilization while retaining speedup
– How to identify useless or redundant prefetches?
• Variety of filtration techniques
– FTQ Position Filtering
– Cache Probe Filtering
• Use idle instruction cache ports to validate prefetches
– Remove CPF
– Enqueue CPF
– Evict Filtering

Fetch Directed Instruction PrefetchingFetch Directed Instruction Prefetching 12
Cache Probe FilteringCache Probe Filtering• Use instruction cache to validate FTQ entries for prefetch
– FTQ entries are initially unmarked
– If cache block is in i-cache, invalidate FTQ entry
– If cache block is not in i-cache, validate FTQ entry
• Validation can occur whenever a cache port is idle
– When the instruction window is full
– Instruction cache miss
• Lockup-free instruction cache

Fetch Directed Instruction PrefetchingFetch Directed Instruction Prefetching 13
Cache Probe Filtering TechniquesCache Probe Filtering Techniques
• Enqueue CPF
– Only enqueue Valid prefetches
– Conservative, low bandwidth approach
• Remove CPF
– By default, prefetch all FTQ entries.
– If idle cache ports are available for validation
• Do not prefetch entries which are found Invalid
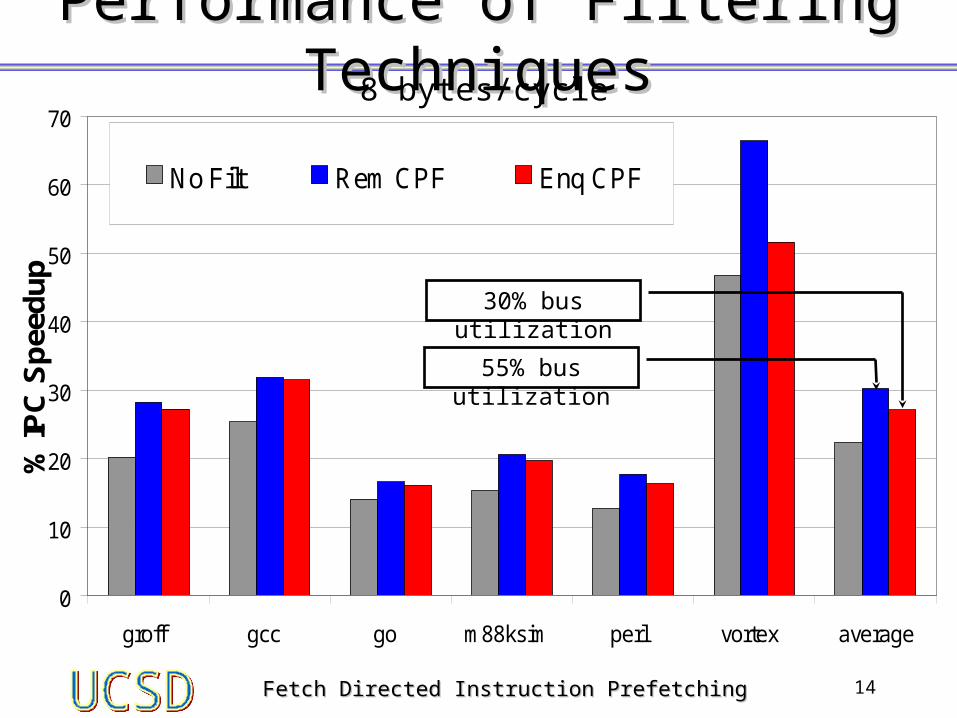
Fetch Directed Instruction PrefetchingFetch Directed Instruction Prefetching 14
Performance of Filtering TechniquesPerformance of Filtering Techniques8 bytes/cycle
0
10
20
30
40
50
60
70
groff gcc go m88ksim perl vortex average
% IP
C S
pee
du
p
No Filt Rem CPF Enq CPF
55% bus utilization
30% bus utilization

Fetch Directed Instruction PrefetchingFetch Directed Instruction Prefetching 15
Eviction Prefetching ExampleEviction Prefetching Example
FTBIndex
InstructionCache
32715
Evict bit0
FTB
10
0
Cachemiss
Cacheblock evicted
Bit set for next
prediction
Evict bit1
00
1
Evict bit2
00
0
Evict
index
01
2•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
• If branch predictor holds more state than instruction cache– Mark evicted cache blocks in branch predictor– Prefetch those blocks when predicted

Fetch Directed Instruction PrefetchingFetch Directed Instruction Prefetching 16
Performance of Filtering TechniquesPerformance of Filtering Techniques
0
10
20
30
40
50
60
70
groff gcc go m88ksim perl vortex average
% IP
C S
pe
ed
up
No Filt Rem CPF
Enq CPF Evicted
Enq CPF + Evict
8 bytes/cycle
20% bus utilization
31% bus utilization

Fetch Directed Instruction PrefetchingFetch Directed Instruction Prefetching 17
Enqueue CPF and Eviction Prefetching• Effective combination of two low bandwidth approaches
• Both attempt to prefetch entries not in instruction cache
• Enqueue CPF needs to wait on idle cache port to prefetch
• Eviction Prefetching can prefetch when prediction is made
• Combined
– Eviction Prefetching gives basic coverage
– Enqueue CPF finds additional prefetches that Evict misses

Fetch Directed Instruction PrefetchingFetch Directed Instruction Prefetching 18
Streaming Buffer EnhancementsStreaming Buffer Enhancements• All configurations used uniqueness filters and fully
associative lookup
• Base configurations– Single streaming buffer (SB1)
– Dual streaming buffers (SB2)
– Eight streaming buffers (SB8)
• Cache Probe Filtering (CPF) enhancements– Filter out streaming buffer prefetches already in icache
– Stop filtering

Fetch Directed Instruction PrefetchingFetch Directed Instruction Prefetching 19
Streaming Buffer ResultsStreaming Buffer Results
0
10
20
30
40
50
60
70
groff gcc go m88ksim perl vortex average
% IP
C S
pee
du
p
SB1 SB2 SB8
SB1-Stop SB2-Stop SB8-Stop
8 bytes/cycle
58% bus utilization
36% bus utilization

Fetch Directed Instruction PrefetchingFetch Directed Instruction Prefetching 20
Selected Low Bandwidth ResultsSelected Low Bandwidth Results
0
5
10
15
20
25
30
35
40
45
NLP SB1 FiltStop
SB8 FiltStop
No Filt Rem CPF Enq CPF Evicted Enq CPF+ Evict
% IP
C S
pee
dup
0
10
20
30
40
50
60
70
% B
us
Util
izat
ion
8 bytes/cycle

Fetch Directed Instruction PrefetchingFetch Directed Instruction Prefetching 21
Selected High Bandwidth ResultsSelected High Bandwidth Results
0
5
10
15
20
25
30
35
40
45
NLP SB1 FiltStop
SB8 FiltStop
No Filt Rem CPF Enq CPF Evicted Enq CPF+ Evict
% IP
C S
pee
dup
0
10
20
30
40
50
60
70
% B
us
Util
izat
ion
32 bytes/cycle

Fetch Directed Instruction PrefetchingFetch Directed Instruction Prefetching 22
ConclusionConclusion• Fetch Directed Prefetching
– Accurate, just in time prefetching
• Cache Probe Filtering– Reduces bus bandwidth of fetch directed prefetching
– Also useful for Streaming Buffers
• Evict Filter– Provides accurate prefetching by identifying evicted
cache blocks
• Fully associative versus inorder prefetch buffer– Available in upcoming tech report by end of year

Fetch Directed Instruction PrefetchingFetch Directed Instruction Prefetching 23
Prefetching Tradeoffs• NLP
– Simple, low bandwidth approach
– No notion of prefetch usefulness
– Limited timeliness
• Streaming Buffers– Takes advantage of latency of a cache miss
– Can use low to moderate bandwidth with filtering
– No notion of prefetch usefulness
• Fetch Directed Prefetching– Prefetch based on prediction stream
– Can use low to moderate bandwidth with filtering
– Most useful with accurate branch prediction







