
Fast Billion-scale Graph Computation Using a BimodalBlock Processing Model
Hugo Gualdron1, Robson Cordeiro1, Jose Rodrigues-Jr1,Duen Horng (Polo) Chau 2, Minsuk Kahng2, U Kang3
1University of Sao Paulo, Brazil2Georgia Institute of Technology, Atlanta, USA3Seoul National University, Republic of Korea
{gualdron,robson,junio}@icmc.usp.br, {polo,kahng}@gatech.edu, [email protected]
Sept/2016
Gualdron et al. (1University of Sao Paulo, Brazil 2Georgia Institute of Technology, Atlanta, USA 3Seoul National University, Republic of Korea {gualdron,robson,junio}@icmc.usp.br, {polo,kahng}@gatech.edu, [email protected])Sept/2016 1 / 28

Summary
1 Introduction
2 Graph Organization
3 Processing Model
4 Programming Model
5 Results
6 Conclusions
Gualdron et al. (1University of Sao Paulo, Brazil 2Georgia Institute of Technology, Atlanta, USA 3Seoul National University, Republic of Korea {gualdron,robson,junio}@icmc.usp.br, {polo,kahng}@gatech.edu, [email protected])Sept/2016 2 / 28

Introduction
Summary
1 Introduction
2 Graph Organization
3 Processing Model
4 Programming Model
5 Results
6 Conclusions
Gualdron et al. (1University of Sao Paulo, Brazil 2Georgia Institute of Technology, Atlanta, USA 3Seoul National University, Republic of Korea {gualdron,robson,junio}@icmc.usp.br, {polo,kahng}@gatech.edu, [email protected])Sept/2016 3 / 28

Introduction
Introduction
Frameworks for large-graph processing based on secondary memoryhave shown better or equal performance than distributed frameworks.They are better to solve problems such as PageRank, ConnectedComponents and Triangle Counting.
Large-graph processing by minimizing computational resources is veryimportant for the industry.
“You can have a second computer once you have shown you knowhow to use the first one.”
Paul Barham
Gualdron et al. (1University of Sao Paulo, Brazil 2Georgia Institute of Technology, Atlanta, USA 3Seoul National University, Republic of Korea {gualdron,robson,junio}@icmc.usp.br, {polo,kahng}@gatech.edu, [email protected])Sept/2016 4 / 28

Introduction
Contributions
M-Flash, the fastest graph computation framework to date.
A Bimodal Block Processing Model, an innovation that is able toboost the graph computation by minimizing the I/O cost even further.
A flexible and simple programming model to easily implementpopular and essential graph algorithm including the firstsingle-machine billion-scale eigensolver.
Gualdron et al. (1University of Sao Paulo, Brazil 2Georgia Institute of Technology, Atlanta, USA 3Seoul National University, Republic of Korea {gualdron,robson,junio}@icmc.usp.br, {polo,kahng}@gatech.edu, [email protected])Sept/2016 5 / 28

Graph Organization
Summary
1 Introduction
2 Graph Organization
3 Processing Model
4 Programming Model
5 Results
6 Conclusions
Gualdron et al. (1University of Sao Paulo, Brazil 2Georgia Institute of Technology, Atlanta, USA 3Seoul National University, Republic of Korea {gualdron,robson,junio}@icmc.usp.br, {polo,kahng}@gatech.edu, [email protected])Sept/2016 6 / 28

Graph Organization
Graph Organization – Facts
Edges and vertex values do not fit in main memory.
Sequential operations on disk must be maximized, improving theperformance on HDDs and SSDs.
Real graphs have a varying density of edges (sparse and denseregions) and these regions can be processed in different ways toachieve superior performance.
Gualdron et al. (1University of Sao Paulo, Brazil 2Georgia Institute of Technology, Atlanta, USA 3Seoul National University, Republic of Korea {gualdron,robson,junio}@icmc.usp.br, {polo,kahng}@gatech.edu, [email protected])Sept/2016 7 / 28

Graph Organization
Graph Organization
Each vertex has a set of attributes γ
Gualdron et al. (1University of Sao Paulo, Brazil 2Georgia Institute of Technology, Atlanta, USA 3Seoul National University, Republic of Korea {gualdron,robson,junio}@icmc.usp.br, {polo,kahng}@gatech.edu, [email protected])Sept/2016 8 / 28
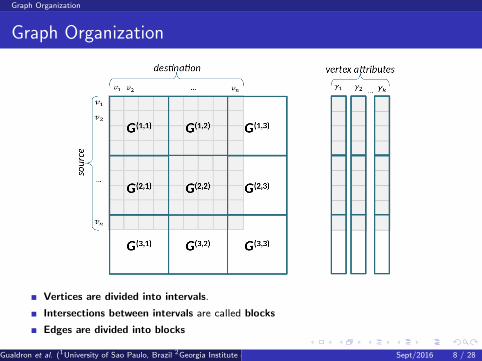
Graph Organization
Graph Organization
Vertices are divided into intervals.
Intersections between intervals are called blocks
Edges are divided into blocks
Gualdron et al. (1University of Sao Paulo, Brazil 2Georgia Institute of Technology, Atlanta, USA 3Seoul National University, Republic of Korea {gualdron,robson,junio}@icmc.usp.br, {polo,kahng}@gatech.edu, [email protected])Sept/2016 8 / 28

Graph Organization
Graph Organization
M-Flash loads in memory some vertex intervals and edges areprocessed using streaming.
Gualdron et al. (1University of Sao Paulo, Brazil 2Georgia Institute of Technology, Atlanta, USA 3Seoul National University, Republic of Korea {gualdron,robson,junio}@icmc.usp.br, {polo,kahng}@gatech.edu, [email protected])Sept/2016 8 / 28

Graph Organization
Graph Organization
Edges create a source-partition (SP) when they are grouped by source interval.
Gualdron et al. (1University of Sao Paulo, Brazil 2Georgia Institute of Technology, Atlanta, USA 3Seoul National University, Republic of Korea {gualdron,robson,junio}@icmc.usp.br, {polo,kahng}@gatech.edu, [email protected])Sept/2016 8 / 28

Graph Organization
Graph Organization
Edges create a destination-partition (DP) when they are grouped by destination interval.
Gualdron et al. (1University of Sao Paulo, Brazil 2Georgia Institute of Technology, Atlanta, USA 3Seoul National University, Republic of Korea {gualdron,robson,junio}@icmc.usp.br, {polo,kahng}@gatech.edu, [email protected])Sept/2016 8 / 28

Graph Organization
Number of intervals to process a graph
β =
⌈φ(T + 1) |V |
M
⌉M = RAM size|V | = Number of vertices of the graphφ = Size of data per vertexT = Number of threads
For example, 4 bytes of data per node, 2 threads, a graph with 2 billionnodes, and for 1 GB RAM:
β = 23 intervals529 blocks
Gualdron et al. (1University of Sao Paulo, Brazil 2Georgia Institute of Technology, Atlanta, USA 3Seoul National University, Republic of Korea {gualdron,robson,junio}@icmc.usp.br, {polo,kahng}@gatech.edu, [email protected])Sept/2016 9 / 28

Graph Organization
Number of intervals to process a graph
β =
⌈φ(T + 1) |V |
M
⌉M = RAM size|V | = Number of vertices of the graphφ = Size of data per vertexT = Number of threads
For example, 4 bytes of data per node, 2 threads, a graph with 2 billionnodes, and for 1 GB RAM:
β = 23 intervals529 blocks
Gualdron et al. (1University of Sao Paulo, Brazil 2Georgia Institute of Technology, Atlanta, USA 3Seoul National University, Republic of Korea {gualdron,robson,junio}@icmc.usp.br, {polo,kahng}@gatech.edu, [email protected])Sept/2016 9 / 28

Graph Organization
Number of intervals to process a graph
β =
⌈φ(T + 1) |V |
M
⌉M = RAM size|V | = Number of vertices of the graphφ = Size of data per vertexT = Number of threads
For example, 4 bytes of data per node, 2 threads, a graph with 2 billionnodes, and for 1 GB RAM:
β = 23 intervals529 blocks
Gualdron et al. (1University of Sao Paulo, Brazil 2Georgia Institute of Technology, Atlanta, USA 3Seoul National University, Republic of Korea {gualdron,robson,junio}@icmc.usp.br, {polo,kahng}@gatech.edu, [email protected])Sept/2016 9 / 28

Processing Model
Summary
1 Introduction
2 Graph Organization
3 Processing Model
4 Programming Model
5 Results
6 Conclusions
Gualdron et al. (1University of Sao Paulo, Brazil 2Georgia Institute of Technology, Atlanta, USA 3Seoul National University, Republic of Korea {gualdron,robson,junio}@icmc.usp.br, {polo,kahng}@gatech.edu, [email protected])Sept/2016 10 / 28

Processing Model
Processing Model
Dense Block Processing model DBP
An efficient model to process blocks with higher density, i.e., blockswith high number of edges.
Gualdron et al. (1University of Sao Paulo, Brazil 2Georgia Institute of Technology, Atlanta, USA 3Seoul National University, Republic of Korea {gualdron,robson,junio}@icmc.usp.br, {polo,kahng}@gatech.edu, [email protected])Sept/2016 11 / 28

Processing Model
Processing Model
Dense Block Processing model DBP
An efficient model to process blocks with higher density, i.e., blockswith high number of edges.
Gualdron et al. (1University of Sao Paulo, Brazil 2Georgia Institute of Technology, Atlanta, USA 3Seoul National University, Republic of Korea {gualdron,robson,junio}@icmc.usp.br, {polo,kahng}@gatech.edu, [email protected])Sept/2016 11 / 28

Processing Model
Processing Model
Streaming Partition Processing Model SPP
SP = Source-partition, DP = Destination-partition
An efficient model for processing sparse blocks.
Gualdron et al. (1University of Sao Paulo, Brazil 2Georgia Institute of Technology, Atlanta, USA 3Seoul National University, Republic of Korea {gualdron,robson,junio}@icmc.usp.br, {polo,kahng}@gatech.edu, [email protected])Sept/2016 12 / 28

Processing Model
Processing Model
Streaming Partition Processing Model SPP
SP = Source-partition, DP = Destination-partition
An efficient model for processing sparse blocks.
Gualdron et al. (1University of Sao Paulo, Brazil 2Georgia Institute of Technology, Atlanta, USA 3Seoul National University, Republic of Korea {gualdron,robson,junio}@icmc.usp.br, {polo,kahng}@gatech.edu, [email protected])Sept/2016 12 / 28

Processing Model
Processing Model
Bimodal Block Processing Model BBP
I/O cost as a metric of efficiencyDBP = Dense Block Processing, SSP = Streaming Partition Processing
O (DBP (G )) = O(
(β + 1) |V | + |E |B
+ β2)
O (SPP (G )) = O
2 |V | + |E | + 2∣∣∣E ∣∣∣
B+ β
β = Number of intervalsV = Number of VerticesE = Number of EdgesE = Number of edges with extended sizeB = Block size for I/O operations on disk
Gualdron et al. (1University of Sao Paulo, Brazil 2Georgia Institute of Technology, Atlanta, USA 3Seoul National University, Republic of Korea {gualdron,robson,junio}@icmc.usp.br, {polo,kahng}@gatech.edu, [email protected])Sept/2016 13 / 28

Processing Model
Processing Model
Bimodal Block Processing Model BBP
I/O cost per block G (p,q)
O(
DBP(G (p,q)
))= O
(ϑφ (1 + 1/β) + ξψ
B
)O(
SPP(G (p,q)
))= O
(2ϑφ/β + 2ξ(φ+ ψ) + ξψ
B
)DBP = Dense Block Processing, SSP = Streaming Partition Processing
ξ = Number of edges withing the block G (p,q)
ϑ = Number of vertices within the intervalφ = Vertex size in bytesψ = Edge size in bytesB = Block size for I/O operations on disk.
Gualdron et al. (1University of Sao Paulo, Brazil 2Georgia Institute of Technology, Atlanta, USA 3Seoul National University, Republic of Korea {gualdron,robson,junio}@icmc.usp.br, {polo,kahng}@gatech.edu, [email protected])Sept/2016 14 / 28

Processing Model
Processing Model
Bimodal Block Processing Model BBP
Ratio SPP/DBP
O(
SPP
DBP
)= O
(1
β+
2ξ
ϑ
[1 +
ψ
φ
])
BlockType(G (p,q)
)=
{sparse, if O
(SPPDBP
)< 1
dense, otherwise
DBP = Dense Block Processing, SSP = Streaming Partition Processing
Gualdron et al. (1University of Sao Paulo, Brazil 2Georgia Institute of Technology, Atlanta, USA 3Seoul National University, Republic of Korea {gualdron,robson,junio}@icmc.usp.br, {polo,kahng}@gatech.edu, [email protected])Sept/2016 15 / 28

Processing Model
Processing Model — Preprocessing 1
Edges are divided in source intervals.
Gualdron et al. (1University of Sao Paulo, Brazil 2Georgia Institute of Technology, Atlanta, USA 3Seoul National University, Republic of Korea {gualdron,robson,junio}@icmc.usp.br, {polo,kahng}@gatech.edu, [email protected])Sept/2016 16 / 28

Processing Model
Processing Model — Preprocessing 1
The number of edges is measured at the same time to classify the block (sparse or dense).
Gualdron et al. (1University of Sao Paulo, Brazil 2Georgia Institute of Technology, Atlanta, USA 3Seoul National University, Republic of Korea {gualdron,robson,junio}@icmc.usp.br, {polo,kahng}@gatech.edu, [email protected])Sept/2016 16 / 28

Processing Model
Processing Model — Preprocessing 2
Source Partitions are rewritten and we store only edges of sparse blocks.
Gualdron et al. (1University of Sao Paulo, Brazil 2Georgia Institute of Technology, Atlanta, USA 3Seoul National University, Republic of Korea {gualdron,robson,junio}@icmc.usp.br, {polo,kahng}@gatech.edu, [email protected])Sept/2016 16 / 28

Processing Model
Processing Model - an iteration
Destination-partitions are generated since the source-partitions.For processing a source-partition, vertex values of the source interval are loaded inmemory.The edges are rewritten and divided by destination.
Gualdron et al. (1University of Sao Paulo, Brazil 2Georgia Institute of Technology, Atlanta, USA 3Seoul National University, Republic of Korea {gualdron,robson,junio}@icmc.usp.br, {polo,kahng}@gatech.edu, [email protected])Sept/2016 16 / 28

Processing Model
Processing Model - an iteration
Destination-partitions are generated since the source-partitions.
For processing a source-partition, vertex values of the source interval are loaded inmemory.
The edges are rewritten and divided by destination.
Gualdron et al. (1University of Sao Paulo, Brazil 2Georgia Institute of Technology, Atlanta, USA 3Seoul National University, Republic of Korea {gualdron,robson,junio}@icmc.usp.br, {polo,kahng}@gatech.edu, [email protected])Sept/2016 16 / 28

Processing Model
Processing Model - an iteration
Destination-partitions are generated since the source-partitions.
For processing a source-partition, vertex values of the source interval are loaded inmemory.
The edges are rewritten and divided by destination.
Gualdron et al. (1University of Sao Paulo, Brazil 2Georgia Institute of Technology, Atlanta, USA 3Seoul National University, Republic of Korea {gualdron,robson,junio}@icmc.usp.br, {polo,kahng}@gatech.edu, [email protected])Sept/2016 16 / 28

Processing Model
Processing Model - an iteration
The graph processing starts over the destination-partitions and the dense blocks.
Gualdron et al. (1University of Sao Paulo, Brazil 2Georgia Institute of Technology, Atlanta, USA 3Seoul National University, Republic of Korea {gualdron,robson,junio}@icmc.usp.br, {polo,kahng}@gatech.edu, [email protected])Sept/2016 16 / 28

Processing Model
Processing Model - an iteration
Vertex values of the destination interval are initialized.Next, edges of the destination partition are processed.
Gualdron et al. (1University of Sao Paulo, Brazil 2Georgia Institute of Technology, Atlanta, USA 3Seoul National University, Republic of Korea {gualdron,robson,junio}@icmc.usp.br, {polo,kahng}@gatech.edu, [email protected])Sept/2016 16 / 28

Processing Model
Processing Model - an iteration
Next, dense blocks of the interval are processed. To do the processing, vertex valuesassociated with the source interval are loaded in memory.
Gualdron et al. (1University of Sao Paulo, Brazil 2Georgia Institute of Technology, Atlanta, USA 3Seoul National University, Republic of Korea {gualdron,robson,junio}@icmc.usp.br, {polo,kahng}@gatech.edu, [email protected])Sept/2016 16 / 28

Processing Model
Processing Model - an iteration
Vertex values of the destination interval are initialized.Next, edges of the destination partition are processed.
Gualdron et al. (1University of Sao Paulo, Brazil 2Georgia Institute of Technology, Atlanta, USA 3Seoul National University, Republic of Korea {gualdron,robson,junio}@icmc.usp.br, {polo,kahng}@gatech.edu, [email protected])Sept/2016 16 / 28

Processing Model
Processing Model - an iteration
Next, dense blocks of the interval are processed. To do the processing, vertex valuesassociated with the source interval are loaded in memory.
Gualdron et al. (1University of Sao Paulo, Brazil 2Georgia Institute of Technology, Atlanta, USA 3Seoul National University, Republic of Korea {gualdron,robson,junio}@icmc.usp.br, {polo,kahng}@gatech.edu, [email protected])Sept/2016 16 / 28

Processing Model
Processing Model - an iteration
Vertex values of the destination interval are initialized.Next, edges of the destination partition are processed.
Gualdron et al. (1University of Sao Paulo, Brazil 2Georgia Institute of Technology, Atlanta, USA 3Seoul National University, Republic of Korea {gualdron,robson,junio}@icmc.usp.br, {polo,kahng}@gatech.edu, [email protected])Sept/2016 16 / 28

Processing Model
Programming Model
MAlgorithm: Algorithm Interface
initialize (Vertex v);gather (Vertex u, Vertex v, EdgeData data);process (Accum v 1, Accum v 2, Accum v out);apply (Vertex v);
PageRank
degree(v) = out degree for Vertex v;initialize (v): v.value = 0gather (u, v, data): v.value += u.value / degree(u)process (v 1, v 2, Accum v out): v out = v 1 + v 2apply (Vertex v): v.value = 0.15 + 0.85 * v.value
Gualdron et al. (1University of Sao Paulo, Brazil 2Georgia Institute of Technology, Atlanta, USA 3Seoul National University, Republic of Korea {gualdron,robson,junio}@icmc.usp.br, {polo,kahng}@gatech.edu, [email protected])Sept/2016 17 / 28

Programming Model
Summary
1 Introduction
2 Graph Organization
3 Processing Model
4 Programming Model
5 Results
6 Conclusions
Gualdron et al. (1University of Sao Paulo, Brazil 2Georgia Institute of Technology, Atlanta, USA 3Seoul National University, Republic of Korea {gualdron,robson,junio}@icmc.usp.br, {polo,kahng}@gatech.edu, [email protected])Sept/2016 18 / 28

Programming Model
Programming Model
Algorithm for Connected Components
initialize (v): v.value = v.idgather (u, v, data): v.value = min (u.value, v.value)process: (v 1, v 2, Accum v out): v out = min (v 1, v 2)
Algorithm for Sparse Matrix-Vector Multiplication SpMV
initialize (v): v.value = 0gather (u, v, data): v.value += u.value * dataprocess: (v 1, v 2, Accum v out): v out = v 1 + v 2
Gualdron et al. (1University of Sao Paulo, Brazil 2Georgia Institute of Technology, Atlanta, USA 3Seoul National University, Republic of Korea {gualdron,robson,junio}@icmc.usp.br, {polo,kahng}@gatech.edu, [email protected])Sept/2016 19 / 28

Results
Summary
1 Introduction
2 Graph Organization
3 Processing Model
4 Programming Model
5 Results
6 Conclusions
Gualdron et al. (1University of Sao Paulo, Brazil 2Georgia Institute of Technology, Atlanta, USA 3Seoul National University, Republic of Korea {gualdron,robson,junio}@icmc.usp.br, {polo,kahng}@gatech.edu, [email protected])Sept/2016 20 / 28

Results
Results
Datasets
Graph Nodes Edges Size
LiveJournal 4,847,571 68,993,773 SmallTwitter 41,652,230 1,468,365,182 MediumYahooWeb 1,413,511,391 6,636,600,779 LargeR-Mat (Synthetic graph) 4,000,000,000 12,000,000,000 Large
Gualdron et al. (1University of Sao Paulo, Brazil 2Georgia Institute of Technology, Atlanta, USA 3Seoul National University, Republic of Korea {gualdron,robson,junio}@icmc.usp.br, {polo,kahng}@gatech.edu, [email protected])Sept/2016 21 / 28

Results
Results
State of the art approaches that are compared withthe experiments
GraphChi (2012)
X-Stream (2013)
TurboGraph (2013)
MMap (2014)
GridGraph (2015)
M-Flash
Gualdron et al. (1University of Sao Paulo, Brazil 2Georgia Institute of Technology, Atlanta, USA 3Seoul National University, Republic of Korea {gualdron,robson,junio}@icmc.usp.br, {polo,kahng}@gatech.edu, [email protected])Sept/2016 22 / 28

Results
Preprocessing time (seconds)
LiveJournal Twitter YahooWeb R-Mat
GraphChi 23 511 2,781 7,440X-Stream 5 131 865 2,553TurboGraph 18 582 4,694 -MMap 17 372 636 -M-Flash 10 206 1,265 4,837
In the worst case, M-Flash is twice slower than the best framework(MMAP)
It reads and writes two times the entire graph on disk, which is thethird best performance, after MMap and X-Stream.
Gualdron et al. (1University of Sao Paulo, Brazil 2Georgia Institute of Technology, Atlanta, USA 3Seoul National University, Republic of Korea {gualdron,robson,junio}@icmc.usp.br, {polo,kahng}@gatech.edu, [email protected])Sept/2016 23 / 28

Results
Runtime (in seconds) with 8GB of RAM
The symbol “-” indicates that the corresponding system failed to processthe graph or the information is not available in the respective papers.
Gualdron et al. (1University of Sao Paulo, Brazil 2Georgia Institute of Technology, Atlanta, USA 3Seoul National University, Republic of Korea {gualdron,robson,junio}@icmc.usp.br, {polo,kahng}@gatech.edu, [email protected])Sept/2016 24 / 28

Results
Effect of Memory Size
Gualdron et al. (1University of Sao Paulo, Brazil 2Georgia Institute of Technology, Atlanta, USA 3Seoul National University, Republic of Korea {gualdron,robson,junio}@icmc.usp.br, {polo,kahng}@gatech.edu, [email protected])Sept/2016 25 / 28

Conclusions
Summary
1 Introduction
2 Graph Organization
3 Processing Model
4 Programming Model
5 Results
6 Conclusions
Gualdron et al. (1University of Sao Paulo, Brazil 2Georgia Institute of Technology, Atlanta, USA 3Seoul National University, Republic of Korea {gualdron,robson,junio}@icmc.usp.br, {polo,kahng}@gatech.edu, [email protected])Sept/2016 26 / 28

Conclusions
Conclusions
M-Flash uses an innovative design that considers the varying densityof the graph;
By using an adaptive engineering, it benefits from the best of bothworlds: stream processing and dense-block processing;
Its programming model supports classical and new algorithmsstraightly adapting to the model of other similar frameworks – amongits processing possibilities: PageRank, Connected Components,matrix-vector multiplication, eigensolver, clustering coefficient, toname few;
To date, M-Flash is the fastest single-node graph processingframework, beating competitors GraphChi, X-Stream, TurboGraphand MMAP.
Gualdron et al. (1University of Sao Paulo, Brazil 2Georgia Institute of Technology, Atlanta, USA 3Seoul National University, Republic of Korea {gualdron,robson,junio}@icmc.usp.br, {polo,kahng}@gatech.edu, [email protected])Sept/2016 27 / 28

Conclusions
Acknowledgments
CNPq (grant 444985/2014-0)
Fapesp (grants 2016/02557-0, 2014/21483-2),
Capes
NSF (grants IIS-1563816, TWC-1526254, IIS-1217559)
GRFP (grant DGE-1148903)
Korean (MSIP) agency IITP (grant R0190-15-2012)
Thanks
Gualdron et al. (1University of Sao Paulo, Brazil 2Georgia Institute of Technology, Atlanta, USA 3Seoul National University, Republic of Korea {gualdron,robson,junio}@icmc.usp.br, {polo,kahng}@gatech.edu, [email protected])Sept/2016 28 / 28







