
Evaluation Function in Game Playing Programs
M1 Yasubumi Nozawa
Chikayama & Taura Lab

Outline
1. Introduction
2. Parameter tuning
1. Supervised learning
2. Comparison training
3. Reinforcement learning
3. Conclusion

Introduction

Game Playing Program
Simple implementation of real-world problem- If one player wins, the other must lose.
Very large search spaces- We can’t get complete information in limited time.

Game tree search
7
9 8 7 6 5 4 3 2 1
7 4 1
Root node: current position Node: position Branch: legal move
MINIMAX SEARCH

Requirements for a evaluation function accuracy efficiency
Static Evaluation Function
4 5 2 -1 6 3 7 -2 1
Static Evaluation FunctionEvaluated by

Features and Weights
Feature f(The number of pieces of each side, etc.)
Weight w(The weight of a important feature must be big.)
Linear
Non-linear Neural Network , etc.
nn fwfw 11

Parameter tuning

Machine learning in games
In simple game like Othello and backgammon, parameter tuning by machine learning has been successful.
In complex games like Shogi, hand-crafted evaluation function is still better. Machine learning is used only in limited domains.(only value of materials, etc.)

Outline
1. Introduction
2. Parameter tuning
1. Supervised learning
2. Comparison training
3. Reinforcement learning
3. Conclusion

Training sample:
Minimize the error of the evaluation function on these positions.
Supervised learning
(Position, Score)

Supervised learning(1)
Backgammon program [Tesauro 1989] Score is given by human experts. Standard back-propagation Far from human expert-level. Out
In1 In2 In458 In459
・・・
・・・
Input : Position and move (459 hand-crafted feature of Boolean value)
Score of Move
w1 w2
w3 w5w4

Supervised learning
Difficulties in supplying training data by experts Consuming much time of experts to create a
database. Human experts don’t think in terms of absolute
scores.

Supervised learning(2)
Bayesian learning [Lee et. al. 1988] Training position is labeled win or lose. Estimate the mean feature vector and the covariance
matrix for each label from training data.
x1
x3
x4
x2
μwin
μlose
Test sample

Supervised learning(3)
LOGISTELLO [Buro 1998] Build different classifiers for different stages of the game.
(Othello is a game of finite plies.) last stage → middle/first stage.
(Scores of last stage is more reliable than middle/first stage.)

Outline
1. Introduction
2. Parameter tuning
1. Supervised learning
2. Comparison training
3. Reinforcement learning
3. Conclusion

Comparison training
Training sample:
Evaluation function learns to satisfy the constraint of these training sample.
Expert’s move is preferred above all other moves.
(Position_1 , Position_2, which is preferable)

Backgammon program [Tesauro 1989] Consistency Transitivity Standard back-propagation Simpler and stronger than
preceding versions of supervisedlearning.
Comparison training
Final position (a) Final position (b)
W1 W2
W3 W4
W1=W2
W3=-W4
Which is preferable
)( abba )( cacbba

Comparison training
Problems of Comparison training Is the assumption “human expert’s move is the
best“ correct? A program trained on experts’ games will imitate a
human playing style, which makes it harder for the program to surprise a human being.

Outline
1. Introduction
2. Parameter tuning
1. Supervised learning
2. Comparison training
3. Reinforcement learning
3. Conclusion

Reinforcement learning
No training information from a domain expert.
Program explores the different actions.
It will receive feedback from the environment (reward). Win or Lose By which margin the
program won/lost. Program (Learner)
Environment
action reward position

TD(λ)
Temporal Difference Learning
t
kk
kttttt xFxFxFww
111 )())()((
wt : Weight vector at time t.
F: Evaluation function (Function of vector W and position x)
xt : Position at time t.
α: Learning rate.
λ: Influence of the current evaluation function value for weight updates of previous moves

Temporal Difference Learning
F(xt-3) F(xt-2) F(xt-1) F(xt) F(xt+1)
TD(λ)
t
kk
kttttt xFxFxFww
111 )())()((
0)()( 1 tt xFxFλ= 0
λ= 0.5
λ= 1
F(xt+1)
F(xt+1)
F(xt)
F(xt)
F(xt-1)
F(xt-1)
F(xt-2)
F(xt-2)
F(xt-3)
F(xt-3)

Temporal Difference Learning(1)
TD-Gammon [Tesauro 1992-] Neural Network (Input: raw board information) TD(λ) Self-play (300,000games) Human expert level
Program
Program
action action

Self-play in other games
None of those successors achieved a performance as impressive as TD-Gammon’s.
In case of backgammon, dice before each move ensured a sufficient variety.
exploration-exploitation dilemmaProgram
Program
action action

Temporal Difference learning(2)
KNIGHT CAP [Baxter et al. 1998] Learned on Internet chess server 1468 features (linearly combined) × 4 stages TDLeaf (λ)
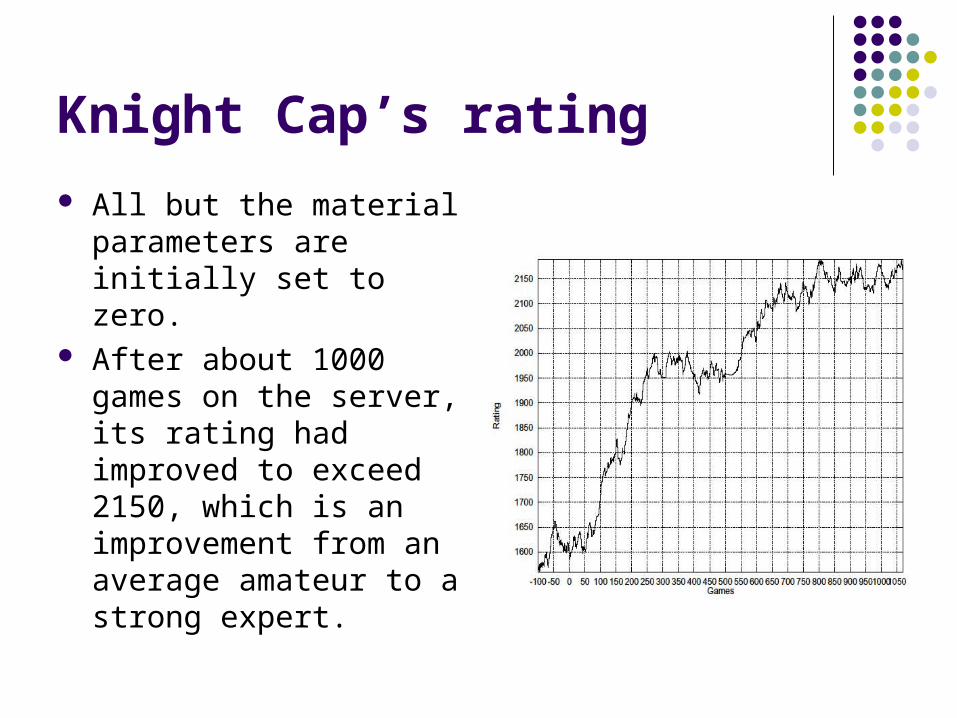
Knight Cap’s rating
All but the material parameters are initially set to zero.
After about 1000 games on the server, its rating had improved to exceed 2150, which is an improvement from an average amateur to a strong expert.

Conclusion

Conclusion
Machine learning in games Successful in simple game Used in limited domains in complex game such as
Shogi Reinforcement learning is successful is stochastic
game such as Backgammon.







