Download - Dublin Ireland Spark Meetup October 15, 2015

After DarkGenerating High-Quality Recommendations usingReal-time Advanced Analytics and Machine Learning with
Chris [email protected], IBM Spark Technology Center (spark.tc)

Who am I?
2
Streaming Data EngineerNetflix Open Source Committer
Data Solutions EngineerApache Contributor
Principal Data Solutions EngineerIBM Technology Center
Meetup OrganizerAdvanced Apache Meetup
Book AuthorAdvanced (2016)

Advanced Apache Spark MeetupTotal Spark Experts: ~1300 in 3 mos!Top 5 most active Spark Meetup globally!
Main GoalsDig deep into the Spark & extended-Spark codebase
Study integrations such as Cassandra, ElasticSearch,Tachyon, S3, BlinkDB, Mesos, YARN, Kafka, R,
etc
Surface and share the patterns and idioms of these well-designed, distributed, big data components

Why “ After Dark”?
“Playboy After Dark”
Late 1960’s TV Show
Progressive Show For Its Time
4
And it rhymes!!
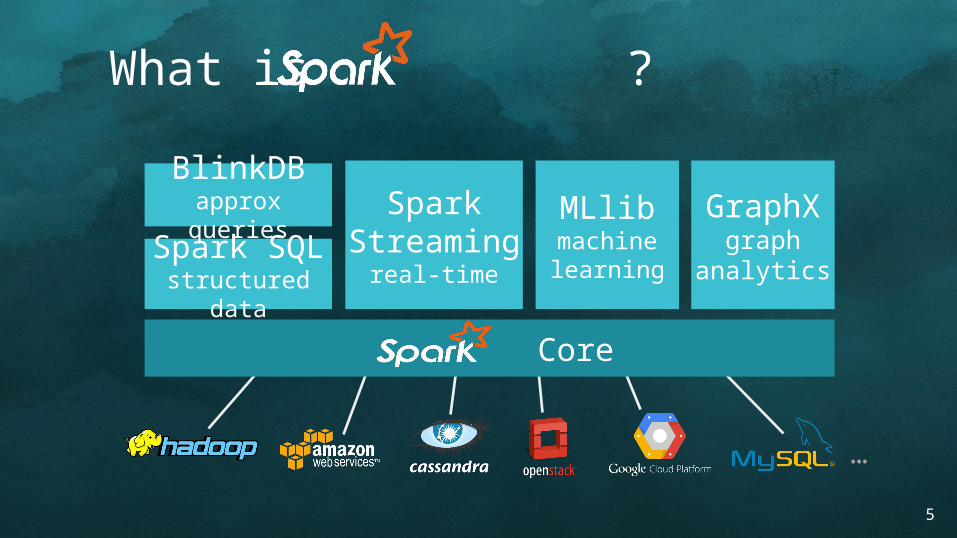
What is ?
5
Core
Spark Streaming
real-timeSpark SQLstructured data
MLlibmachine learning
GraphXgraph
analytics
…
BlinkDBapprox queries

Deployments in Production
6

Tools of this Talk
7
① Redis② Docker③ Cassandra④ MLlib, GraphX⑤ Parquet, JSON⑥ Apache Zeppelin⑦ Spark Streaming, Kafka⑧ Spark SQL, DataFrames⑨ Spark JDBC/ODBC Hive ThriftServer⑩ ElasticSearch, Logstash, Kibana (ELK)
and…

SMACK Stack!
8
① S park (Data Processing)② M esos (Cluster Manager)③ A kka (Actors)④ C assandra (NoSQL)⑤ K afka (Streaming)

Themes of This Talk
9
① Parallelism② Performance③ Streaming④ Approximations⑤ Similarity Measures⑥ Recommendations
and…

10
① Generate high-quality recommendations② Demonstrate high-level libraries:
③ Spark Streaming -> Kafka, Approximates④ Spark SQL -> DataFrames, Cassandra① GraphX -> PageRank, Shortest Path① MLlib -> Matrix Factor, Word2Vec
Goals of After Dark?
Images courtesy of tinder.com, however not affiliated with Tinder in any way.

Popular Dating Sites
11

Parallelism
12
My First Experience with Parallelism
13
Brady Bunch circa 1980Season 5, Episode 18: “Two Pete’s in a Pod”
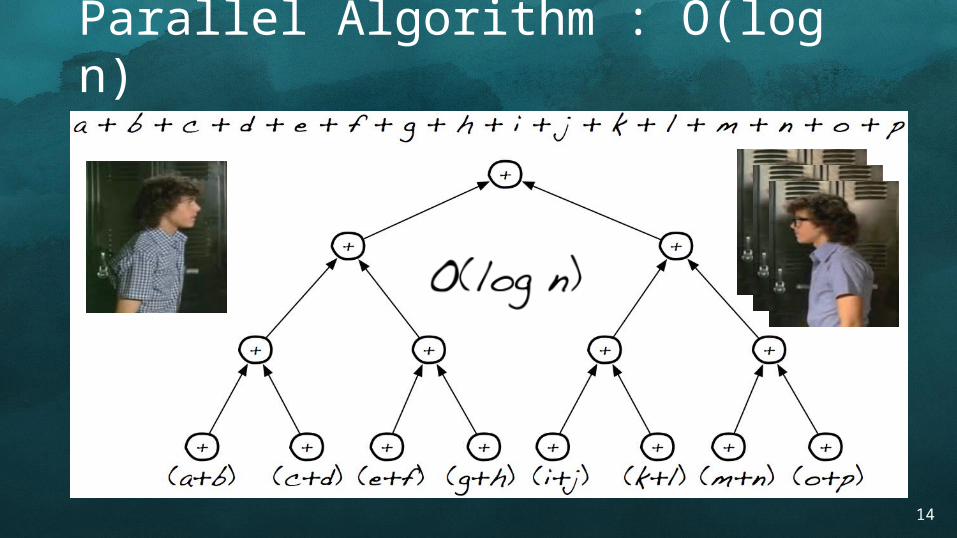
Parallel Algorithm : O(log n)
14

Non-parallel Algorithm : O(n)
15

is Parallel
16

Performance
17

Daytona Gray Sort Contest
18
① On-disk only② 28,000 partitions③ No in-memory caching
(2014)(2013) (2014)

Improved Shuffle and Network Layer
19
① “Sort-based shuffle”② Minimize OS resources③ Switched to async Netty④ Keep CPUs hot ⑤ Reuse byte buffers to minimize GC⑥ Use epoll for I/O to stay in kernel space

Project Tungsten: CPU and Memory
20
① More JVM bytecode generation, JIT optimize② CPU-cache-aware data structs and algos
-->
③ Custom memory management Serializers Performance HashMap
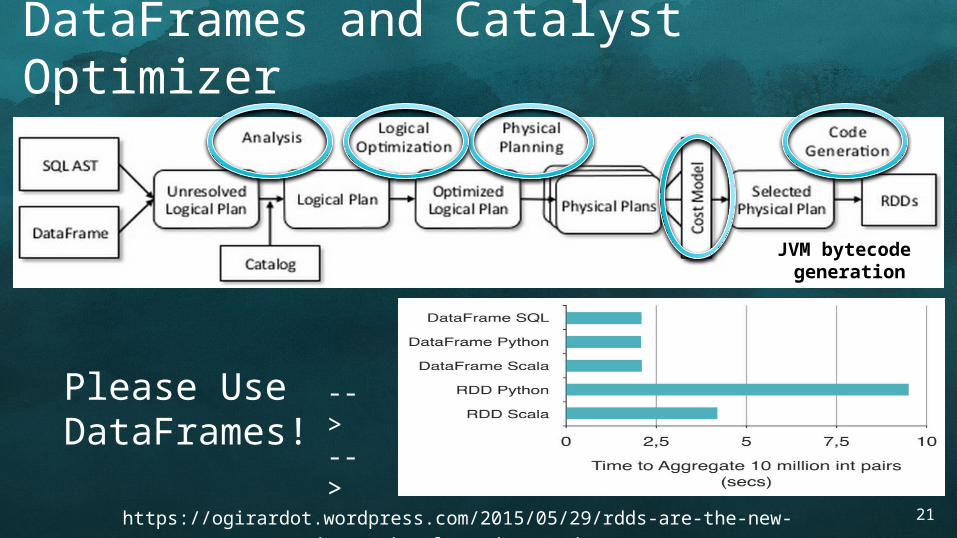
DataFrames and Catalyst Optimizer
21
21
https://ogirardot.wordpress.com/2015/05/29/rdds-are-the-new-bytecode-of-apache-spark/
Please Use DataFrames!
-->-->
JVM bytecode generation

Columnar Storage Format
22
*Skip whole chunks with min-max heuristicsstored in each chunk (sorted data only)

Parquet File Format
23
① Based on Google Dremel Paper② Implemented by Twitter and Cloudera③ Columnar storage format④ Optimized for fast columnar aggregations⑤ Tight compression⑥ Supports pushdowns⑦ Nested, self-describing, evolving schema

Types of Compression
24
① Run Length EncodingRepeated data
② Dictionary EncodingFixed set of values
③ Delta, Prefix EncodingSorted dataset

Types of Query Optimizations
25
① Column, Partition Pruning② Row, Predicate Pushdown
SELECT b FROM table WHERE a in [a2,a3]

Streaming
26

Direct Kafka Streaming - KafkaRDD① No single Receiver, no Write Ahead Log (WAL)② Workers pull from Kafka in parallel③ Each KafkaRDD partition stores relevant offsets④ Upon Worker Node failure, rebuild from offsets⑤ Optimizes happy path by avoiding the WAL
27
At least oncedelivery guarantee
<--

Approximations
28

Count Min Sketch
29
① Approximate counters② Better than HashMap③ Low, fixed memory④ Known error bounds⑤ Large num of counters⑥ From Twitter’s Algebird⑦ Streaming example in codebase

HyperLogLog
30
① Approximate cardinalityApprox count distinct
② Low memory1.5KB @ 2% error10^9 elements!
③ From Twitter’s Algebird④ Streaming example in codebase⑤ RDD: countApproxDistinctByKey()

Monte Carlo Simulations
31
From Manhattan Project (A-bomb) Simulate movement of neutrons
Law of Large Numbers (LLN) Average of results of many trials Converge on expected value
SparkPi example in codebase Pi ~ # red dots /
# total dots * 4

Recommendations
32

Interactive Demo!
33

Audience Participation Needed!
34
① Navigate to sparkafterdark.com
② Click 3 actors and 3 actresses
->You are here
->

Types of Recommendations
35
Non-personalized Cold Start
No preference or behavior data for user, yetPersonalized User-Item Similarity
Items that others with similar prefs have liked Item-Item Similarity
Items similar to your previously-liked items

Non-personalized Recommendations
36

Summary Statistics and Aggregations
37
① Top Users by Like Count“I might like users with the highest sum aggregation of likes overall.”
SparkSQL + DataFrame: Aggregations

Like Graph Analysis
38
② Top Influencers by Like Graph“I might like users who have the highest probability of me liking them randomly while walking the like graph.”
GraphX: PageRank

Demo! Spark SQL + DataFrames + GraphX
+ Hive ThriftServer
39

Finding Similarities
40

Types of Similarity
41
Euclidean: linear measure Magnitude biasCosine: angle measure Adjust for magnitude biasJaccard: (intersection / union) Popularity biasLog Likelihood Adjust for popularity bias
Ali Matei Reynold Patrick AndyKimberly 1 1 1 1Leslie 1 1Meredith 1 1 1Lisa 1 1 1Holden 1 1 1 1 1
z

All-Pairs Similarity Comparison
42
Compare everything to everything aka. “pair-wise similarity” or “similarity join” Naïve shuffle: O(m*n^2); m=rows, n=cols
Must Minimize shuffle through approximations Reduce m (rows)
Sampling and bucketing Reduce n (cols): Remove most frequent value (ie.0)

Reduce m: DIMSUM Sampling
43
Dimension Independent Matrix Square Using MR Remove rows with low similarity probability MLlib: RowMatrix.columnSimilarities(…)
Twitter: 40% efficiency gain over Cosine

Reduce m: LSH Bucketing
44
Locality Sensitive Hashing Split m into b buckets
Use similarity hash algoRequires pre-processing of data
Compare bucket contents in parallel Converts O(m*n^2) -> O(m*n/b*b^2);
m=rows, n=cols, b=buckets 500k x 500k matrix
O(1.25E17) -> O(1.25E13); b=50 github.com/mrsqueeze/spark-hash

Reduce n: Remove Most Frequent Value
45
Eliminate most-frequent valueRepresent other values with (index,value) pairsConverts O(m*n^2) -> O(m*nnz^2); nnz=num nonzeros, nnz << n
Choose most frequent value – may not be zero!
(index,value)
(index,value)

Personalized Recommendations
46

Terminology of Recommendations
47
User User seeking recommendations
Item Item that has been liked or rated
Feedback Explicit: like, rating Implicit: search, click, hover, view, scroll

Collaborative Filtering Personalized Recs
48
③ Like behavior of similar users“I like the same people that you like. What other people did you like that I haven’t seen?” MLlib: Matrix Factorization, User-Item Similarity

Demo! Spark SQL + DataFrames + MLlib
49

Text-based Personalized Recs
50
④ Similar profiles to me“Our profiles have similar, unique k-skip n-grams. We might like each other.” MLlib: Word2Vec, TF/IDF, Doc Similarity

More Text-based Personalized Recs
51
⑤ Similar profiles from my past likes“Your profile shares a similar feature vector space to others that I’ve liked. I might like you.” MLlib: Word2Vec, TF/IDF, Doc Similarity

More Text-based Personalized Recs
52
⑥ Relevant, High-Value Emails“Your initial email has similar named entities to my profile. I might like you just for making the effort.” MLlib: Word2Vec, TF/IDF, Entity Recognition
^ Her Email< My Profile

The Future of
Personalized Recommendations
53

Facial Recognition
54
⑦ Eigenfaces“Your face looks similar to others that I’ve liked. I might like you.”
MLlib: RowMatrix, PCA, Item-Item Similarity
Image courtesy of http://crockpotveggies.com/2015/02/09/automating-tinder-with-eigenfaces.html
Conversation Bot
55
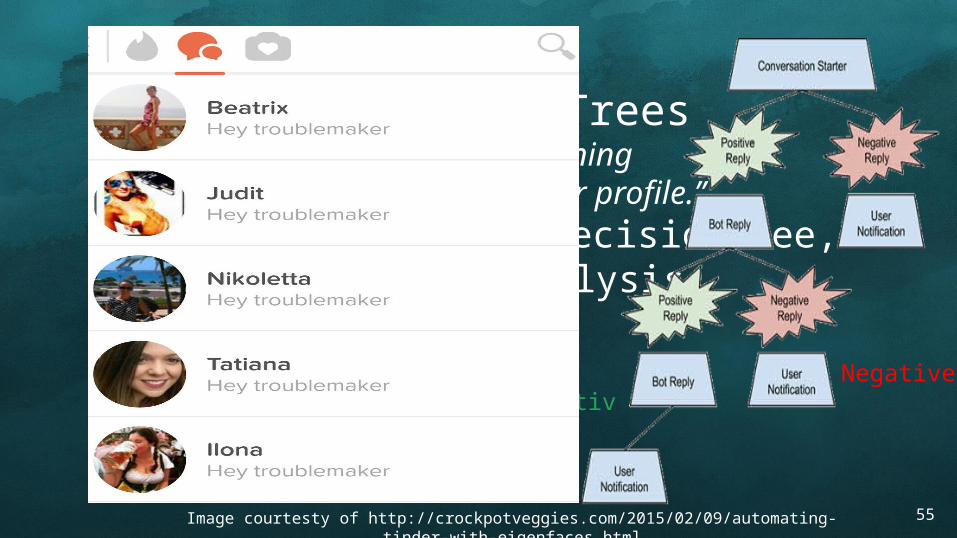
⑧ NLP and DecisionTrees“If your responses to my trite opening lines are positive, I may read your profile.” MLlib: TF/IDF, DecisionTree,
Sentiment Analysis
Positive Negative
Image courtesty of http://crockpotveggies.com/2015/02/09/automating-tinder-with-eigenfaces.html

56
Maintaining the

Couples’ Recommendations
57
⑨ Pathways of Similarity“I want Mad Max. You want Message In a Bottle. Let’s find something in between to watch tonight.”
MLlib: RowMatrix, Item-Item Similarity GraphX: Nearest Neighbors, Shortest Path
similar similar plots -> <- actors

58
Final Recommendation

⑩ Get Off The Computer and Meet People!
[email protected]@cfreglyIBM Spark Technology Center (spark.tc)
advancedspark.com
github.com/fluxcapacitor/pipeline
hub.docker.com/r/fluxcapacitor/pipeline/
59
Thank you!!
Image courtesy of http://www.duchess-france.org/







