Download - CS 7810 Lecture 24 The Cell Processor H. Peter Hofstee Proceedings of HPCA-11 February 2005

CS 7810 Lecture 24
The Cell Processor
H. Peter HofsteeProceedings of HPCA-11
February 2005

Heterogeneous CMPs
Multi-core design at 0.1 technology: half the area occupiedby shared L2 cache; half the area occupied by 4 diverse cores
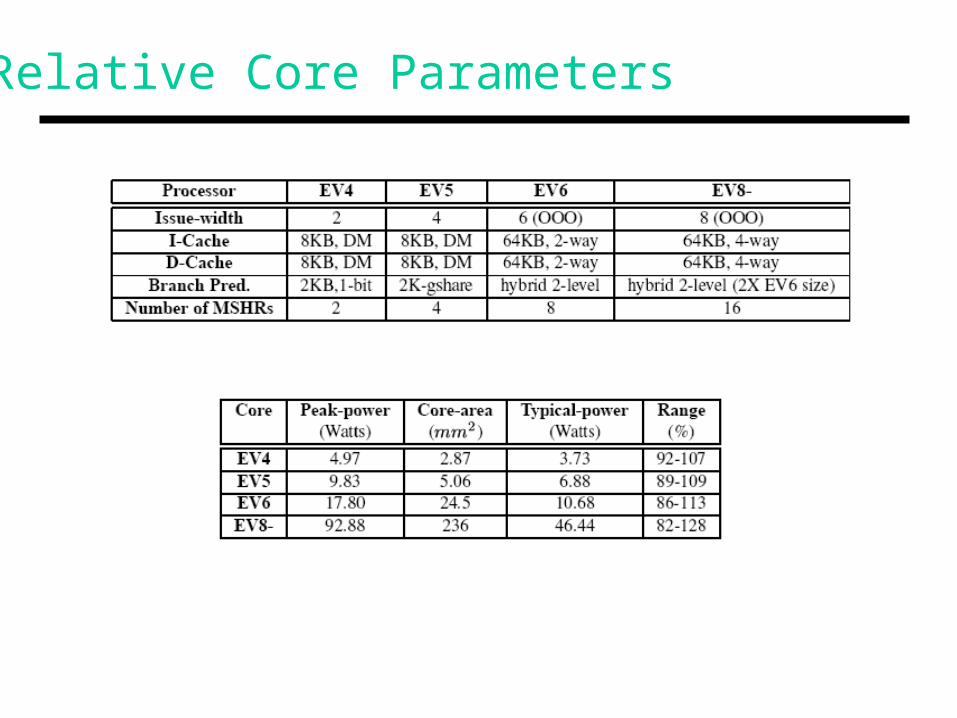
Relative Core Parameters

Dynamic Core Selection
An oracle selects the core that minimizesenergy, while performing within 10% of optimal
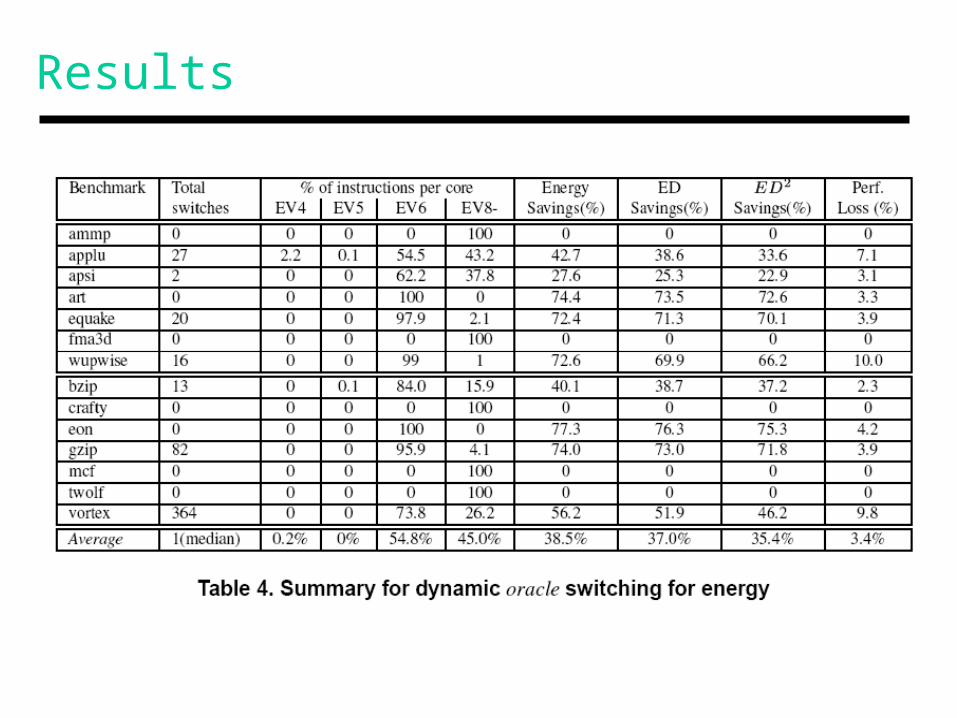
Results

Heterogeneous CMPs
• Inevitable!
• A 100-core CMP in 2015: special-purpose cores to execute network operations, SIMD code, GP code, OS code, graphics operations, …
• Special-purpose cores Vs. general-purpose cores: is the investment in silicon area, design effort worthwhile?
Importance of target applications (games!) Difference in behavior (performance, power)

Arguments for Cell: Improve Efficiency
• Metric of choice: performance per transistor or performance per watt or …
• Gelsinger’s Law: transistor doubling leads to 40% improvement in architectural performance
larger caches/bpreds, diminishing returns transistor overhead issue widthx ; low utilization of issue slots overheads for deep pipelines

Cell Innovations
• For regular apps, the compiler can better manage the cache, loop unrolling helps, software branch prediction is not terrible
Local storage: can be directly addressed by the program (almost like a large register file) DMA controllers to keep local storage full: fight memory latency with high bandwidth! Large register file to enable unrolling Branch target hints
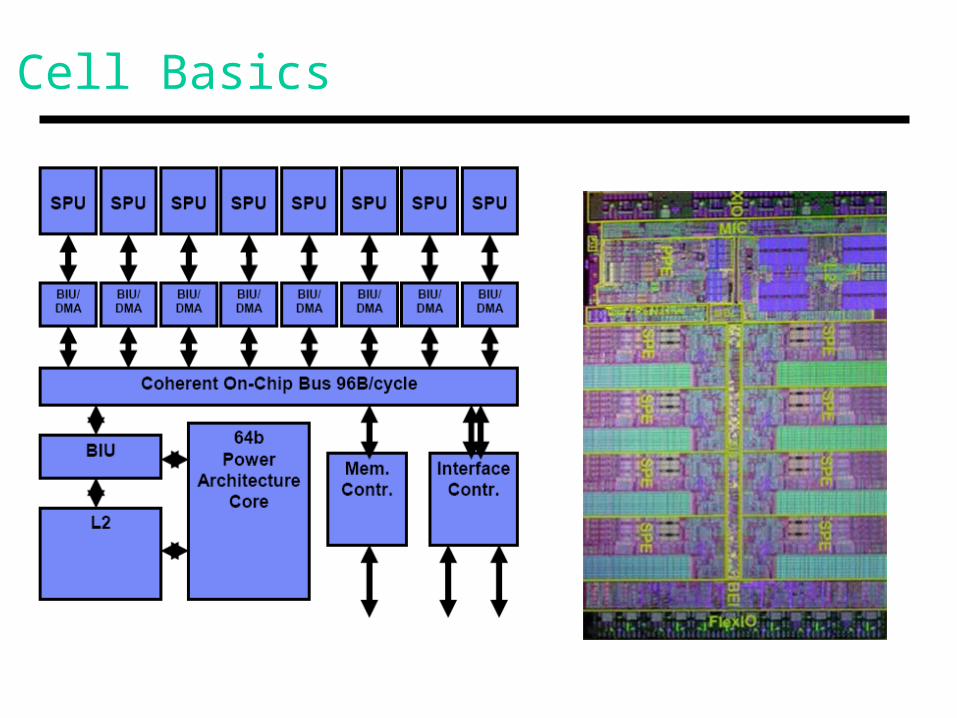
Cell Basics

PowerPC Core
• PPC core serves as the master – the SPEs have no provision for protection
• This is the “inefficient” general-purpose processor that provides high performance for most GP apps (including the OS)
• 2-way in-order issue; 2-thread SMT; 32KB L1s; 512KB L2

SPE Features
• Simple 2-wide in-order pipeline for number crunching • 11 FO4 pipeline stages (3.2 GHz); 14M SRAM transistors and 7M logic transistors (total 234M)
• 256KB local storage that is explicitly managed by the program; 128-entry register file (128b registers); 2-cycle register file access with full bypass
• Most ALUs are SIMD: they operate on 128b vectors of four 32b elements

Cell Voltage/Frequency/Power

Power5 Overview
• Two cores, each being 2-way SMT (more threads increase complexity and yield little benefit)
• Cores share a 1.875MB L2 and an off-chip 36MB L3
• 389mm2 in 130nm technology
• 8-wide fetch is fine-grain multi-threaded; rest is SMT
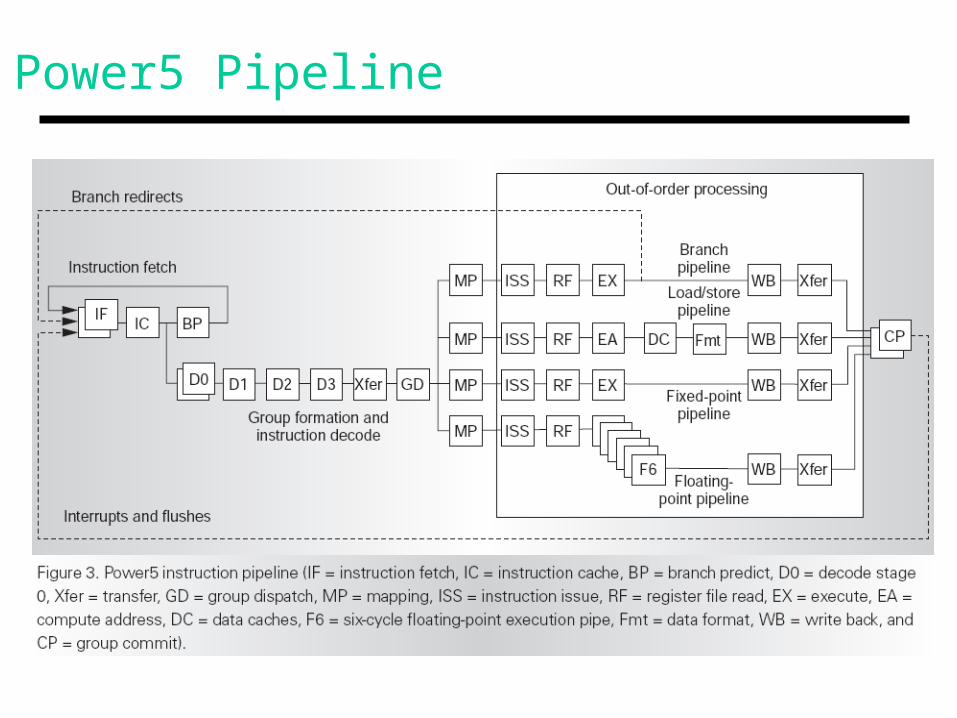
Power5 Pipeline

Pipeline Details
• Long loop within fetch
• Combining branch predictor (bimodal and gshare)
• Five instructions (from the same thread) are dispatched in a cycle
• 120 Int and 120 FP registers; only 20 entries in the ROB (each entry tracks a group of 5 instrs)
• Eight execution units (many register ports!)

SMT Features
• A thread is given lower priority during fetch if it occupies too many ROB entries
• A thread is not decoded until outstanding L2 misses clear
• If a thread executes a long-latency operation, decode is stalled and part of the pipeline is flushed
• Software can set priority for a thread (useful for real-time apps or when the app knows that a thread is in an idle loop)
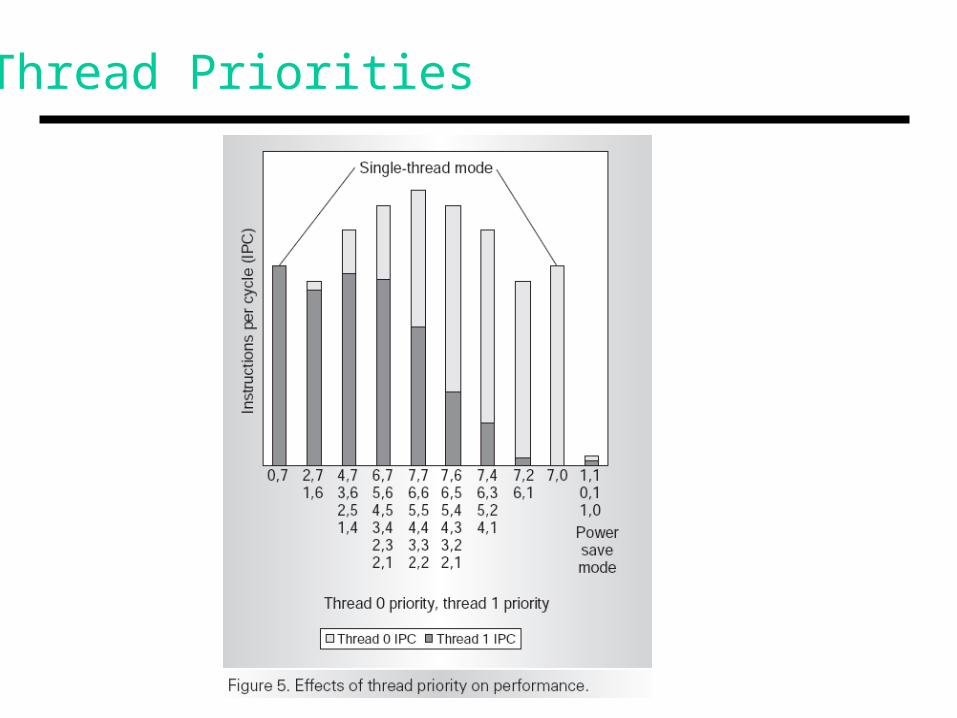
Thread Priorities

Title
• Bullet







