
CS 7810 Lecture 23
Maximizing CMP Throughput with Mediocre Cores
J. Davis, J. Laudon, K. OlukotunProceedings of PACT-14
September 2005

Niagara
• Commercial servers require high thread-level throughput and suffer from cache misses
• Sun’s Niagara focuses on: simple cores (low power, design complexity, can accommodate more cores) fine-grain multi-threading (to tolerate long memory latencies)

Niagara Overview

SPARC Pipe
No branch predictorLow clock speed (1.2 GHz)One FP unit shared by all cores

Thread Selection
• Round-Robin
• Threads that are speculating on a load-hit receive lower priority
• Threads are unavailable if they suffer from cache misses, long-latency ops

Register File
• Each procedure has eight local and eight in registers (and eight out registers that serve as in registers for the callee) – each thread has eight such windows
• Total register file size: 640! 3 read and 2 write ports (1 write/cycle for long and short latency ops)
• Implemented as a 2-level structure: 1st level contains the current register windows

Cache Hierarchy
• 16KB L1I and 8KB L1D, write-thru, read-allocate, write-no-allocate
• Invalidate-based directory protocol – the shared L2 cache (3MB, 4 banks) identifies sharers and sends out the invalidates
• Rather than store sharers per L2 line, the L1 tags are replicated – such a structure is more efficient to search through

Next Generation: Rock
• 4 cores; each core has 4 pipelines; each pipeline can execute two threads: 32 threads

Design Space Exploration: Methodology
• Workloads: SPEC-JBB (Java middleware), TPC-C (OLTP), TPC-W (transactional web), XML-Test (XML parsing) – all are thread-oriented
• Sun’s chip design databases were examined to derive area overheads of various features (primarily to evaluate the overhead of threading and ooo execution)

Pipelines
8-stage pipelinesScalar proc is fine-grain multi-threadedSuperscalar proc is SMTFrequency not more than ½ of the max ITRS-projected frequency
400mm2 die25% devoted to off-chip interfaces: mem controllers, I/O, clocking11% devoted to the inter-core xbar
Of the remaining area, 25-75%are allocated to cores/L2-cache
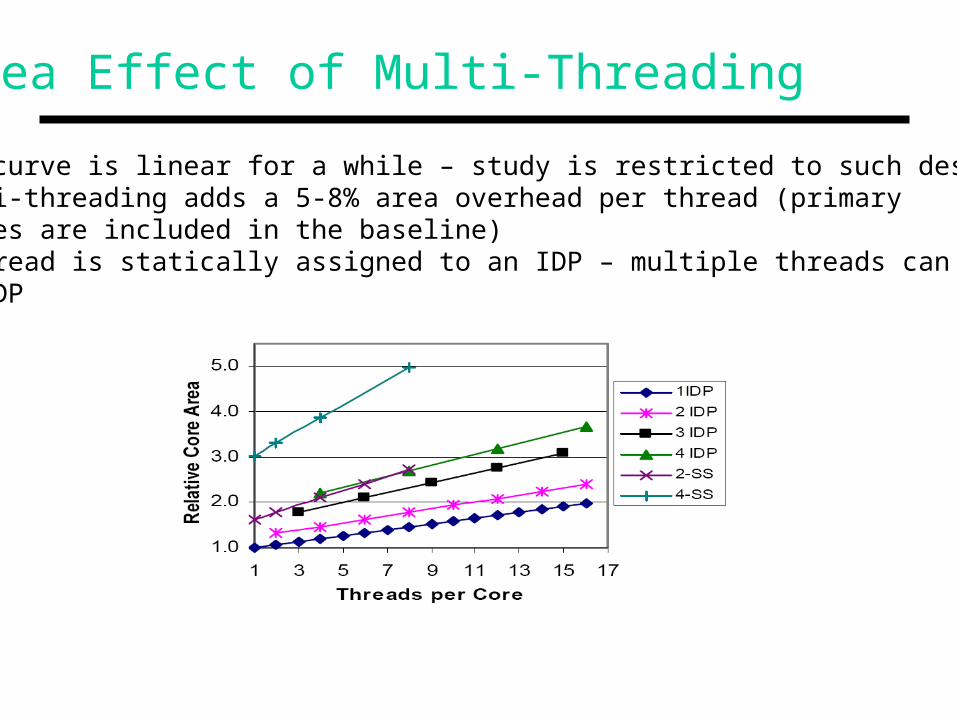
Area Effect of Multi-Threading
• The curve is linear for a while – study is restricted to such designs• Multi-threading adds a 5-8% area overhead per thread (primary caches are included in the baseline)• A thread is statically assigned to an IDP – multiple threads can share an IDP
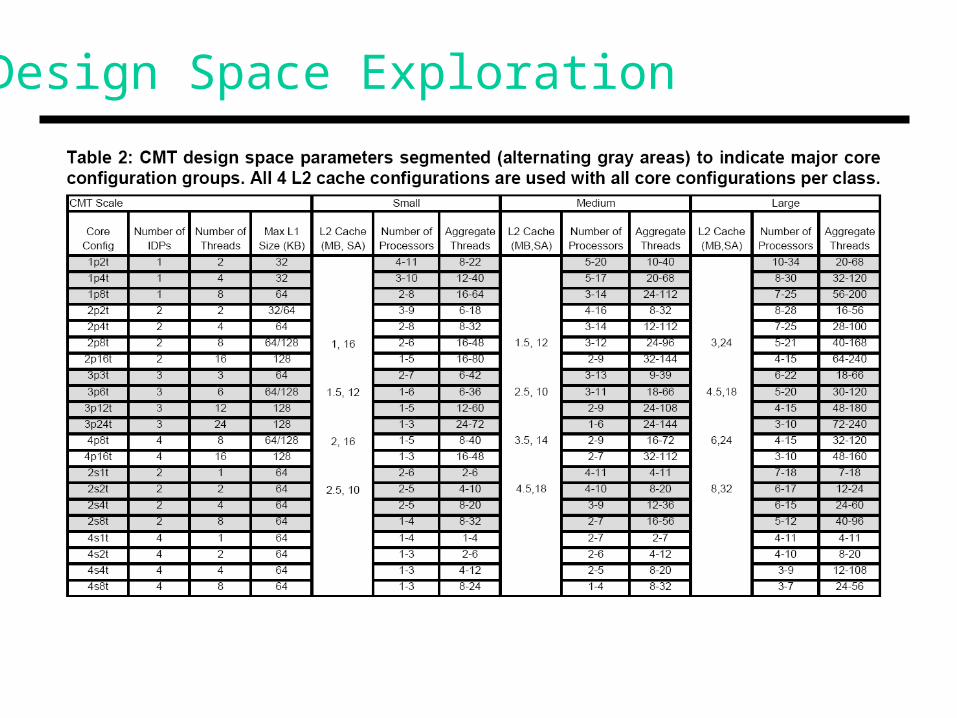
Design Space Exploration

Single Core IPC
4 bars correspond to 4 different L2 sizes
IPC range for different L1 sizes

Aggregate IPC
C1: 2p4t with 64KB L1 cachesC2: 2p4t with 32KB L1 caches*L1 latencies are always constant

Maximal Aggregate IPCs

Maximal Aggregate IPCs

Observations
• Scalar cores are better than ooo superscalars
• Too many threads (> 8) can saturate the caches and memory buses
• Processor-centric design is often better (medium sized L2s are good enough)
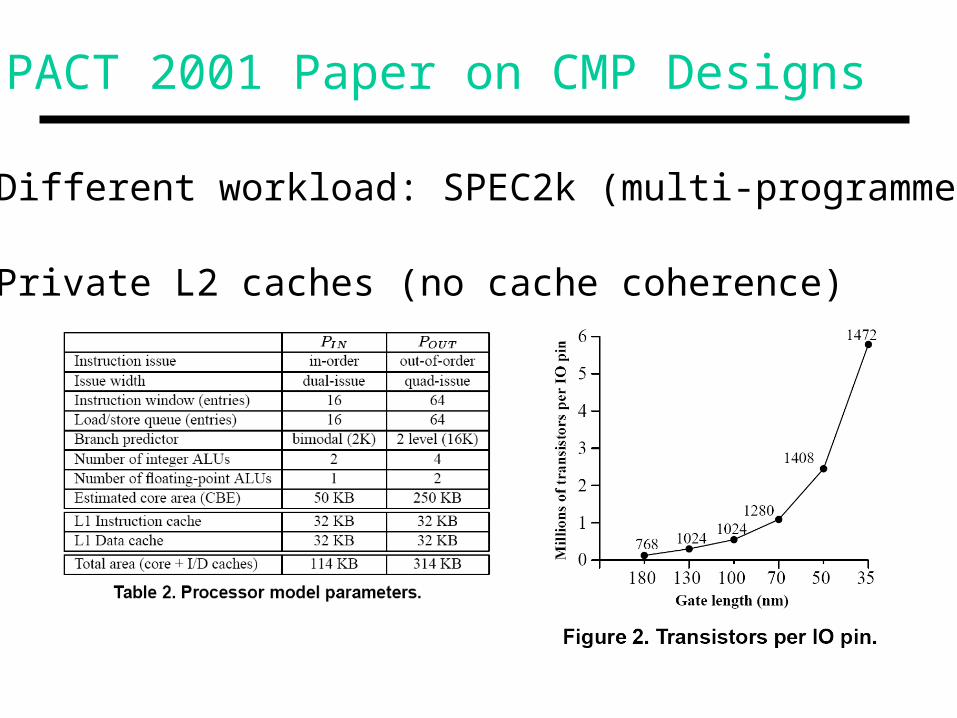
PACT 2001 Paper on CMP Designs
• Different workload: SPEC2k (multi-programmed)
• Private L2 caches (no cache coherence)

Effect of L2 Size

Effect of Memory Bandwidth

Optimal Configurations

Title
• Bullet







