
Cross-genre Information Linking and Summarization
Heng Ji [email protected]
Acknowledgement: summarization introduction slides from Ed Hovy, Daniel Marcu, Sujian Li

2
Outline
Summarization Recap Cross-genre Information Linking Cross-genre Summarization

MILAN, Italy, April 18. A small airplane crashed into a governmentbuilding in heart of Milan, setting the top floors on fire, Italianpolice reported. There were no immediate reports on casualties asrescue workers attempted to clear the area in the city's financialdistrict. Few details of the crash were available, but news reportsabout it immediately set off fears that it might be a terrorist actakin to the Sept. 11 attacks in the United States. Those fears sentU.S. stocks tumbling to session lows in late morning trading.
Witnesses reported hearing a loud explosion from the 30-storyoffice building, which houses the administrative offices of the localLombardy region and sits next to the city's central train station.Italian state television said the crash put a hole in the 25th floorof the Pirelli building. News reports said smoke poured from theopening. Police and ambulances rushed to the building in downtownMilan. No further details were immediately available.
How many victims?
Was it a terrorist act?
What was the target?
What happened?
Says who?
When, where?

1. How many people were injured?2. How many people were killed? (age, number, gender, description)3. Was the pilot killed?4. Where was the plane coming from?5. Was it an accident (technical problem, illness, terrorist act)? 6. Who was the pilot? (age, number, gender, description) 7. When did the plane crash? 8. How tall is the Pirelli building? 9. Who was on the plane with the pilot? 10. Did the plane catch fire before hitting the building? 11. What was the weather like at the time of the crash? 12. When was the building built? 13. What direction was the plane flying? 14. How many people work in the building? 15. How many people were in the building at the time of the crash? 16. How many people were taken to the hospital? 17. What kind of aircraft was used?

5
Questions What kinds of summaries do people want?
What are summarizing, abstracting, gisting,...?
How sophisticated must summ. systems be? Are statistical techniques sufficient?Or do we need symbolic techniques and deep
understanding as well?
What milestones would mark quantum leaps in summarization theory and practice? How do we measure summarization quality?

Summary definition(Sparck Jones,1999)
“a reductive transformation of source text to summary text through content condensation by selection and/or generalization on what is important in the source.”
Definitions

Schematic summary processing model
Source text Interpretation
Source representation
Transformation
Summary
representation
GenerationSummary text

8
Summarizing factors Input (Sparck Jones 2007)
subject type: domain genre: newspaper articles, editorials, letters, reports... form: regular text structure; free-form source size: single doc; multiple docs (few; many)
Purpose situation: embedded in larger system (MT, IR) or not? audience: focused or general usage: IR, sorting, skimming...
Output completeness: include all aspects, or focus on some? format: paragraph, table, etc. style: informative, indicative, aggregative, critical...

9
ExamplesExercise: summarize the following texts for
the following readers:
text1: Coup Attempt
text2: childrens’ story
reader1: your friend, who knows nothing about South Africa.
reader2: someone who lives in South Africa and knows the political position.
reader3: your 4-year-old niece.reader4: the Library of Congress.

10
‘Genres’ of Summary? Indicative vs. informative
...used for quick categorization vs. content processing.
Extract vs. abstract...lists fragments of text vs. re-phrases content coherently.
Generic vs. query-oriented...provides author’s view vs. reflects user’s interest.
Background vs. just-the-news...assumes reader’s prior knowledge is poor vs. up-to-date.
Single-document vs. multi-document source...based on one text vs. fuses together many texts.

11
A Summarization Machine
EXTRACTS
ABSTRACTS
?
MULTIDOCS
Extract Abstract
Indicative
Generic
Background
Query-oriented
Just the news
10%
50%
100%
Very BriefBrief
Long
Headline
Informative
DOC QUERY
CASE FRAMESTEMPLATESCORE CONCEPTSCORE EVENTSRELATIONSHIPSCLAUSE FRAGMENTSINDEX TERMS

12
Computational Approach
Top-Down: I know what I want!
User needs: only certain types of info
System needs: particular criteria of interest, used to focus search
Bottom-Up: • I’m dead curious:
what’s in the text?
• User needs: anything that’s important
• System needs: generic importance metrics, used to rate content

13
Review of Methods
Text location: title, position Cue phrases Word frequencies Internal text cohesion:
word co-occurrences local salience co-reference of names,
objects lexical similarity semantic rep/graph
centrality
Discourse structure centrality
Information extraction templates
Query-driven extraction: query expansion lists co-reference with query
names lexical similarity to query
Bottom-up methods Top-down methods

14
Query-Driven vs. Text-Driven Focus Top-down: Query-driven focus
Criteria of interest encoded as search specs. System uses specs to filter or analyze text
portions. Examples: templates with slots with semantic
characteristics; termlists of important terms. Bottom-up: Text-driven focus
Generic importance metrics encoded as strategies.
System applies strategies over rep of whole text. Examples: degree of connectedness in semantic
graphs; frequency of occurrence of tokens.

15
Bottom-Up, using Info. Retrieval IR task: Given a query, find the relevant
document(s) from a large set of documents. Summ-IR task: Given a query, find the relevant
passage(s) from a set of passages (i.e., from one or more documents).
• Questions: 1. IR techniques work on large
volumes of data; can they scale down accurately enough?
2. IR works on words; do abstracts require abstract representations?
xx xxx xxxx x xx xxxx xxx xx xxx xx xxxxx xxxx xx xxx xx x xxx xx xx xxx x xxx xx xxx x xx x xxxx xxxx xxxx xxxx xxxxxx xx xx xxxx x xxxxx x xx xx xxxxx x x xxxxx xxxxxx xxxxxx x xxxxxxxx xx x xxxxxxxxxx xx xx xxxxx xxx xx xxx xxxx xxx xxxx xx xxxxx xxxxx xx xxx xxxxxx xxx

16
Top-Down, using Info. Extraction IE task: Given a template and a text, find all the
information relevant to each slot of the template and fill it in.
Summ-IE task: Given a query, select the best template, fill it in, and generate the contents.
• Questions:1. IE works only for very particular
templates; can it scale up?
2. What about information that doesn’t fit into any template—is this a generic limitation of IE?
xx xxx xxxx x xx xxxx xxx xx xxx xx xxxxx xxxx xx xxx xx x xxx xx xx xxx x xxx xx xxx x xx x xxxx xxxx xxxx xxxx xxxx xxxxxx xx xx xxxx x xxxxx x xx xx xxxxx x x xxxxx xxxxxx xxxxxx x xxxxxxxx xx x xxxxxxxxxx xx xx xxxxx xxx xx x xxxx xxxx xxx xxxx xx xxxxx xxxxx xx xxx xxxxxx xxx
Xxxxx: xxxx Xxx: xxxx Xxx: xx xxx Xx: xxxxx xXxx: xx xxx Xx: x xxx xx Xx: xxx x Xxx: xx Xxx: x

17
NLP/IE:• Approach: try to ‘understand’
text—re-represent content using ‘deeper’ notation; then manipulate that.
• Need: rules for text analysis and manipulation, at all levels.
• Strengths: higher quality; supports abstracting.
• Weaknesses: speed; still needs to scale up to robust open-domain summarization.
IR/Statistics:• Approach: operate at lexical
level—use word frequency, collocation counts, etc.
• Need: large amounts of text.
• Strengths: robust; good for query-oriented summaries.
• Weaknesses: lower quality; inability to manipulate information at abstract levels.
Paradigms: NLP/IE vs. ir/statistics

18
Toward the Final Answer... Problem: What if neither IR-like nor
IE-like methods work?
Solution: semantic analysis of the text (NLP), using adequate knowledge bases that
support inference (AI).
Mrs. Coolidge: “What did the preacher preach about?”
Coolidge: “Sin.”Mrs. Coolidge: “What did he
say?”Coolidge: “He’s against it.”
– sometimes counting and templates are insufficient,
– and then you need to do inference to understand.
Word counting
Inference

2Elaboration
2Elaboration
8Example
2BackgroundJustification
3Elaboration
8Concession
10Antithesis
Mars experiences
frigid weather
conditions(2)
Surface temperatures typically average
about -60 degrees
Celsius (-76 degrees
Fahrenheit) at the
equator and can dip to -
123 degrees C near the
poles(3)
4 5Contrast
Although the atmosphere
holds a small
amount of water, and water-ice
clouds sometimes develop,
(7)
Most Martian weather involves
blowing dust and carbon monoxide.
(8)
Each winter, for example, a blizzard of
frozen carbon dioxide
rages over one pole, and a few meters of
this dry-ice snow
accumulate as
previously frozen carbon dioxide
evaporates from the opposite
polar cap.(9)
Yet even on the summer pole, where
the sun remains in the sky all day long,
temperatures never warm
enough to melt frozen
water.(10)
With its distant orbit (50 percent farther from the sun than Earth) and
slim atmospheric
blanket,(1)
Only the midday sun at tropical latitudes is
warm enough to
thaw ice on occasion,
(4)
5Evidence
Cause
but any liquid water formed in this way would
evaporate almost
instantly(5)
because of the low
atmospheric pressure
(6)
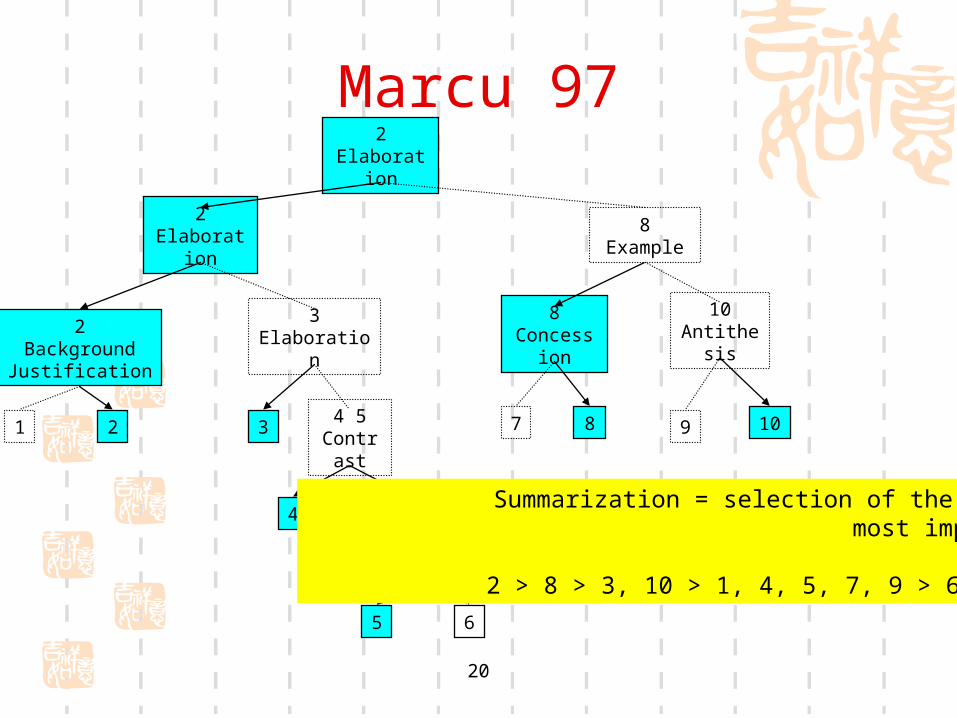
20
Marcu 97
5Evidence
Cause
5 6
4
4 5Contrast
3
3Elaboration
1 2
2BackgroundJustification
2Elaboration
7 8
8Concession
9 10
10Antithesis
8Example
2Elaboration
Summarization = selection of the most important units
2 > 8 > 3, 10 > 1, 4, 5, 7, 9 > 6

21
Information extraction Method Idea: content selection using templates
Predefine a template, whose slots specify what is of interest.
Use a canonical IE system to extract from a (set of) document(s) the relevant information; fill the template.
Generate the content of the template as the summary.
Previous IE work: FRUMP (DeJong, 78): ‘sketchy scripts’ of terrorism,
natural disasters, political visits... (Mauldin, 91): templates for conceptual IR. (Rau and Jacobs, 91): templates for business. (McKeown and Radev, 95): templates for news.

22
Information Extraction method
Example template:
MESSAGE:ID TSL-COL-0001SECSOURCE:SOURCE ReutersSECSOURCE:DATE 26 Feb 93
Early afternoonINCIDENT:DATE 26 Feb 93INCIDENT:LOCATION World Trade CenterINCIDENT:TYPE BombingHUM TGT:NUMBER AT LEAST 5

23
Full Generation Example
Challenge: Pack content densely!
Example (McKeown and Radev, 95): Traverse templates and assign values to
‘realization switches’ that control local choices such as tense and voice.
Map modified templates into a representation of Functional Descriptions (input representation to Columbia’s NL generation system FUF).
FUF maps Functional Descriptions into English.

24
Generation Example (McKeown and Radev, 95)
NICOSIA, Cyprus (AP) – Two bombs exploded near government ministries in Baghdad, but there was no immediate word of any casualties, Iraqi dissidents reported Friday. There was no independentconfirmation of the claims by the Iraqi National Congress. Iraq’sstate-controlled media have not mentioned any bombings.
Multiple sources and disagreement
Explicit mentioning of “no information”.

Graph-based Methods
Degree Centrality LexRank Continuous LexRank

Degree Centrality
Problem Formulation Represent each sentence by a vectorDenote each sentence as the node of a graph Cosine similarity determines the edges
between nodes

Degree Centrality
Since we are interested in significant similarities, we can eliminate some low values in this matrix by defining a threshold.

Degree Centrality
Compute the degree of each sentence
Pick the nodes (sentences) with high degrees

Degree Centrality
Disadvantage in Degree Centrality approach

LexRank Centrality vector p which will give a
lexrank of each sentence (similar to page rank) defined by :

LexRank
B is a stochastic matrix Is it an irreducible and aperiodic matrix? Dampness (Page et al. 1998)

Summarization&keyphrase
句子 - 句子关系图
词 - 词关系图

3 kinds of relations
SS-Relation: U
WW-Relation: V
SW-Relation: W

Build Sentence-Sentence Graph
Sentence relations [ ]ij n nU U
1 2, ,... i ns wt wt wt
*
1 log( / )i i
i i
i t t
t t
wt tf isf
isf N n
( , ),
0,
ij i j
ij
U sim s s i j
U i j

Build Word-Word Graph
Word relations
Word similariy computation:Based on dictionary (WordNet)Based on corpus (mutual information)
[ ]ij n nV V
( , ),
0,
ij i j
ij
V sim t t i j
V i j

Build Sentence-Word Graph
Relation between sentences and words
Similarity computation:
{ |1 }iS s i m { |1 }jT t j n
( , ) j j
i
t t
i jt t
t S
tf isfaff s t
tf isf
[ ]ij m nW W ( , )ij i jW aff s t

Document Model Assumption 1 If a sentence is important, its closely connected
sentences are also important; If a word is important, its closely related words are also important.
Assumption 2 More important words are included in a sentence,
more important the sentence is.
More frequent a word occurs in important sentences, more important the word is.

Reinforcement Algorithm
Assumptions:
( ) ( )i ji jju s U u s( ) ( )j ij ii
v t V v t( ) ( )i ji jj
u s W v t( ) ( )j ij ii
v t W u s

matrix form:
1 1
( ) ( ) ( )m n
i ji j ji jj j
u s U u s W v t
1 1
( ) ( ) ( )n m
j ij i ij ii i
v t V v t W u s
T
T T
u aU u W v
v aV v W u
Then we can simultaneously rank sentences (u) and words (v).

Postprocessing
Simple processingExtract the highest scored sentences until the
length reaches the requirement. Problems
1: redundancy 2: meaningless words in sentences (rules
based)3: coherence

Sentence simplification
Delete meaningless words in sentences News specific noisy words Content irrelevant words
Rule based method The beginning of news: e.g.,“ALBUQUERQUE, N.M.
(AP) ; The initial words in the sentence: such as
“and” ,” also” ,” besides ,”,” though ,”,” in addition” ,” somebody said” ,“ somebody says”; ;
“somebody ( 代词 )/It is said/reported/noticed/thought that” ;
The parenthesized content in captalized letters …

Sentence ordering
Sentence ordering by score: no logic in the content
Temporal based sentence ordering Acquire the time stamp from the original texts Order sentence according to the publish time of
documents; For the sentences in the same document, order them by their occurrence in the document

43
Outline
Summarization Recap Cross-genre Information Linking
(Huang et al., 2012) Cross-genre Summarization

What are Other People Planning? 10K tweets posted each hour
Top tweets ranked by TextRank

Desperately Looking for a Better Ranker
Top Ranked Tweets from our system

After temporal and spatial constraints, informative to a general audience or helpful for tracking events Break news Real-time coverage of ongoing events …
Informative Tweet Examples New Yorkers, find your exact evacuation zone by your address
here: http://t.co/9NhiGKG /via @user #Irene #hurricane #NY Hurricane Irene: Latest developments http://t.co/2nQOJLO
Non-Informative Tweet Examples Me, Myself, and Hurricane Irene. I'm ready For hurricane Irene.
What is Informativeness?

Limitation of Previous Work Supervised ranking models require large amount of labeled
data and multiple levels of features (e.g. content and user account features)
Ignored cross-genre linkages and background knowledge Tweets about events of general interest are sent by many
disconnected users Need to handle link sparsity with implicit user network prediction
Ignored subjectivity detection and redundancy removal
Our relationships have been ignored

Motivations and Hypotheses Informative tweets often contain rich links to diverse
networks Hypothesis 1: Informative tweets are more likely to be
posted by credible users; and vice versa (credible users are more likely to post informative tweets).
Hypothesis 2: Tweets involving many users are more likely to be informative.
Similar tweets appear with high frequency Synchronous behavior of users indicates informative
information Had fun in the excursion bus for 16 hours Saw some empty ancient caves in darkness Our bus hit a house before the second caves!

Motivations and Hypotheses (Cont’) Hypothesis 3: Tweets aligned with contents of web
documents are more likely to be informative. New Yorkers, find your exact evacuation zone by your
address here: http://t.co/9NhiGKG /via @user #Irene \#hurricane \#NY
Details of Aer Lingus flights affected by Hurricane Irene can be found at http://t.co/PCqE74V\u201d
Hurricane Irene: City by City Forecasts http://t.co/x1t122A

Approach Overview
Make use of correlations to formal genre web documents
Infer implicit tweet-user relations to enrich network linkages
Extend to heterogeneous networks instead of homogeneous networks
Effective propagation model to consider global evidence from different genres
U1
U2
U3
T1
T2
T3
T4
D1
D2
D3
Web-Tweet Networks Tweet-User Networks
Web-Tweet-User Networks

Non-Informative Tweet Filtering Capture the characteristics of a noisy tweet by a few
patterns very short tweets without a complementary URL tweets with subjective opinions (e.g. include I, me, my…)
I'm ready for hurricane Irene I hope New York and New Jersey are ok when the hurricane
hits
informal tweets containing slang words
Precision: 96.59%

Initializing Ranking Scores Initializing Tweet and Web Document Scores
TextRank based on content similarity (cosine & tf.idf) Initializing User Credibility Scores
TextRank based on retweet/reply/user mention networks Bayesian Ranking approach to consider user and tweet
networks simultaneously (Wang et al 2011)
Rank(x): the increase of posterior probability that a user is credible, normalized by prior probability
: the percentage of true claims
: the percentage of credible users
: the explicit tweet-user networks

Constructing Heterogeneous Networks Tweet-User Networks
Explicit tweet-user relations are sparse Infer implicit tweet-user relations.
-U1 posts T1, if sim(T1,T2) exceeds an threshold, an direct edge is created for U1 and T2.
Web-Tweet Networks Ti is aligned with relevant web document Dj if they
are on the similar topic (cosine & tf.idf)

S0(d)S0(t)S0(u)
Implicit links between tweets and web documents: Wtd WdtExplicit and implicit linksbetween tweets and users: Wtu Wut
Tri-HITS: preliminaries
D1
D2
U1
U2
T1
T2
T3
Heterogeneous NetworksInitial ranking scores
0.45
0.8
0.1
1.0
1.0
1.0
0.5
Similarity matrix Wdt Transition matrix Pdt

Propagated ScoreInitial ScoreUpdated Score
Propagation from tweets to web
documents Tri-HITS: based on the similarity matrix
Co-HITS: based on transition matrix (Deng et al 2009)
Differences between Tri-HITS and Co-HITS: Tri-HITS: normalize the propagated ranking scores based on
original similarity matrix Co-HITS propagates normalized ranking scores using the
transition matrix

Tri-HITS (con’t)
Propagation from tweets to users
Propagation from web documents and users to tweets
Set to 0 will only consider tweet-user networks Set to 0 will only consider web-tweet networks

An Example over bipartite graph
D1
D2
T1
T2
T3
0.45
0.8
0.1Wtd Pdt
Propagated scores in first iteration of Tri-HITS:
0.2
0.3
0.5
0.6
0.4
Propagated scores in first iteration of Co-HITS:
Ptd
Choose =0.5, the final ranking of tweetsTri-HITS: (0.276, 0.463, 0.261)Co-HITS: (0.202, 0.331, 0.467)
Co-HITS: Weaken or damage original meaning of semantic similarity

Overall Performance
nDCG@ top n ranked tweets
Non-informative tweets filtering is important for informal information from social media.
Evidence from multi-genre networks improves TextRank significantly
Knowledge transferred from the Web and the Inferred Implicit Social Networks dramatically boosted quality

Remaining Error Analysis Topically-relevant tweet identification
Hurricane Kitty: http://t.co/cdIexE3
Non-informative tweet identification by performing deeper linguistic analysis and rumor/sarcasm detection Hurricane names hurricane names http://t.co/iisc7UY ;) My favorite parts of Hurricane coverage is when the weathercasters
stand in those 100 MPH winds right on the beach. Good stuff.
Deep semantic analysis to improve inferring implicit linkages “MTA closed” = “Subway shut down”
Subjectivity Detection with opinion mining Damn earthquake & hurricane in the same week… = Worst week to
live on the East Coast

60
Outline Summarization Recap Cross-genre Information Linking Cross-genre Summarization

61
Tweet Ranking (Liu et al., 2012) Modifying Weights in TextRank
Retw: a tweet is more important if it has been re-tweeted more times
Foll: a tweet is more important if it is published by an account with more followers
Readability: sentence length, word length, OOV They also considered user diversity
62
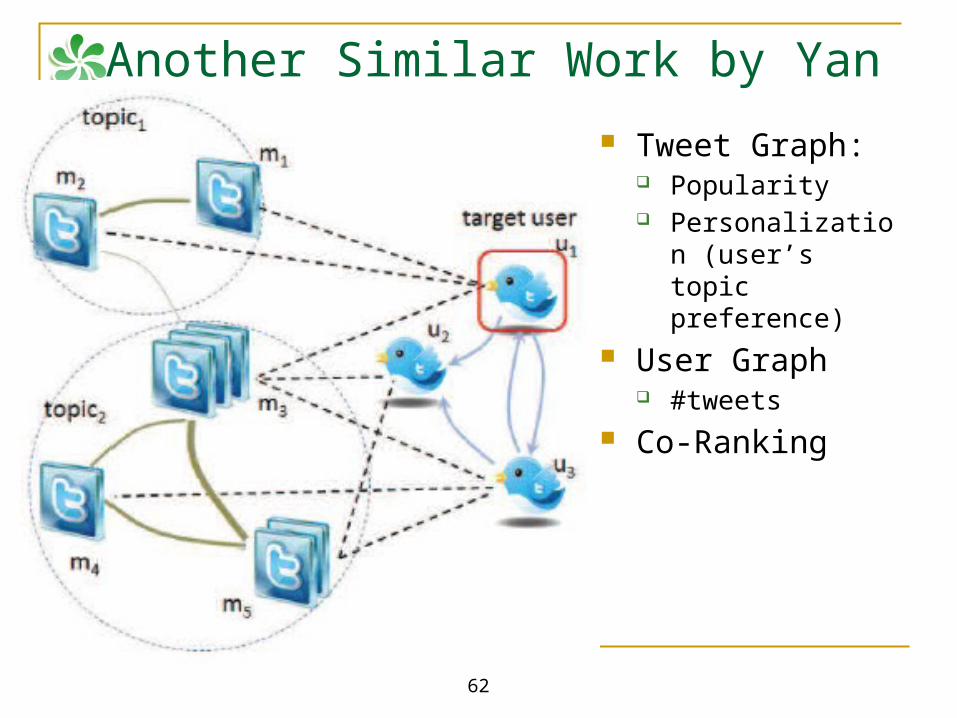
Another Similar Work by Yan et al., 2012
Tweet Graph: Popularity Personalization
(user’s topic preference)
User Graph #tweets
Co-Ranking

63
Discussion No Solid Work on News Summarization
using Newsworthy tweets yet How to Proceed? Look at Jesse’s data and Results







