Download - Computer Archicture F07 - UH

1
COSC 6339
Big Data Analytics
Fuzzy Clustering
Some slides based on a lecture by Prof. Shishir Shah
Edgar Gabriel
Spring 2017
Clustering
• Clustering is a technique for finding similarity groups in data, called clusters. i.e.,
– it groups data instances that are similar to (near) each other in one cluster and data instances that are very different (far away) from each other into different clusters.
• Clustering is often called an unsupervised learning taskas no class values denoting an a priori grouping of the data instances are given.

2
K-means algorithm• Given k, the k-means algorithm works as follows:
1)Randomly choose k data points (seeds) to be the initial
centroids, cluster centers
2)Assign each data point to the closest centroid
3)Re-compute the centroids using the current cluster
memberships.
4) If a convergence criterion is not met, go to 2).
Stopping/convergence criterion
1. no (or minimum) re-assignments of data points to different clusters,
2. no (or minimum) change of centroids, or
3. minimum decrease in the sum of squared error (SSE),
– Cj is the jth cluster, mj is the centroid of cluster Cj (the mean vector of all the data points in Cj), and dist(x, mj) is the distance between data point x and centroid mj.
k
jC j
j
distSSE1
2),(x
mx

3
Strengths of k-means
• Strengths:
– Simple: easy to understand and to implement
– Efficient: Time complexity: O(tkn),
where n is the number of data points,
k is the number of clusters, and
t is the number of iterations.
– Since both k and t are small. k-means is considered a
linear algorithm.
• K-means is the most popular clustering algorithm.
• Note that: it terminates at a local optimum if SSE is
used. The global optimum is hard to find due to
complexity.
Weaknesses of k-means• The algorithm is only applicable if the mean is defined.
– For categorical data, k-mode - the centroid is
represented by most frequent values.
• The user needs to specify k.
• The algorithm is sensitive to outliers
– Outliers are data points that are very far away from other
data points.
– Outliers could be errors in the data recording or some
special data points with very different values.

4
Weaknesses of k-means:
Problems with outliers
Weaknesses of k-means: outliers
• One method is to remove some data points in the
clustering process that are much further away from
the centroids than other data points.
– To be safe, we may want to monitor these possible
outliers over a few iterations and then decide to remove
them.
• Another method is to perform random sampling.
Since in sampling we only choose a small subset of
the data points, the chance of selecting an outlier
is very small.
– Assign the rest of the data points to the clusters by
distance or similarity comparison, or classification
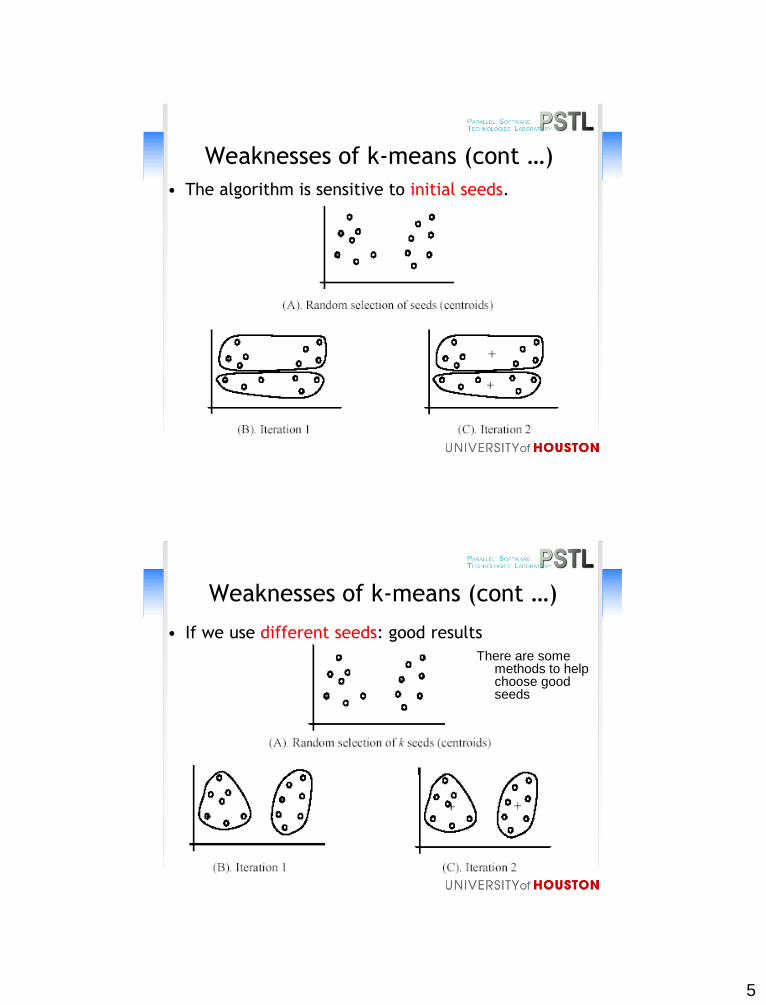
5
Weaknesses of k-means (cont …)
• The algorithm is sensitive to initial seeds.
• If we use different seeds: good results
There are some methods to help choose good seeds
Weaknesses of k-means (cont …)

6
• The k-means algorithm is not suitable for
discovering clusters that are not hyper-ellipsoids
(or hyper-spheres).
+
Weaknesses of k-means (cont …)
Weaknesses of k-means (cont…)
• Membership of a point to a single cluster not always
clear
-> Fuzzy clustering can help with that

7
Boolean Logic
• In Boolean logic, an object is either a member of a set
or is not, i.e. their membership function can be
expressed as
μ𝐴 𝑥 = 1 𝑥 ∈ 𝐴0 𝑥 ∉ 𝐴
• In Boolean Logic
𝜇𝐴 ∩ ~𝐴𝑥 = ∅
𝜇𝐴 ∪ ~𝐴𝑥 = {𝐴𝑈}
• A set is a collection of objects grouped sharing a
common property
• A boolean set is also referred to as a crisp set
Fuzzy Logic
• Logic based on continuous variables
• Provides the ability to represent intrinsic ambiguity
• Fuzzification: the process of finding the membership
value of a (scalar) number in a fuzzy set
• Defuzzification: the process of converting the outcome
of a fuzzy set to a single representative number

8
Fuzzy Sets
• Indicate that the membership function can be different
than just 0 and 1
– 0 indicates no membership
– 1 indicates complete set membership
– [>0,<1] indicate partial membership
• Superset of Boolean Logic
• Fuzzy set has three principal components
– Degree of membership
– Possible Domain values
– Membership function: a continuous function that
connects a domain value to its degree of membership in
the set
Fuzzy Numbers
Gra
de o
f m
em
bers
hip
m(x
)
Support set
1.0
0
Domain
• Fuzzy number: a fuzzy set representing an approximation to a number
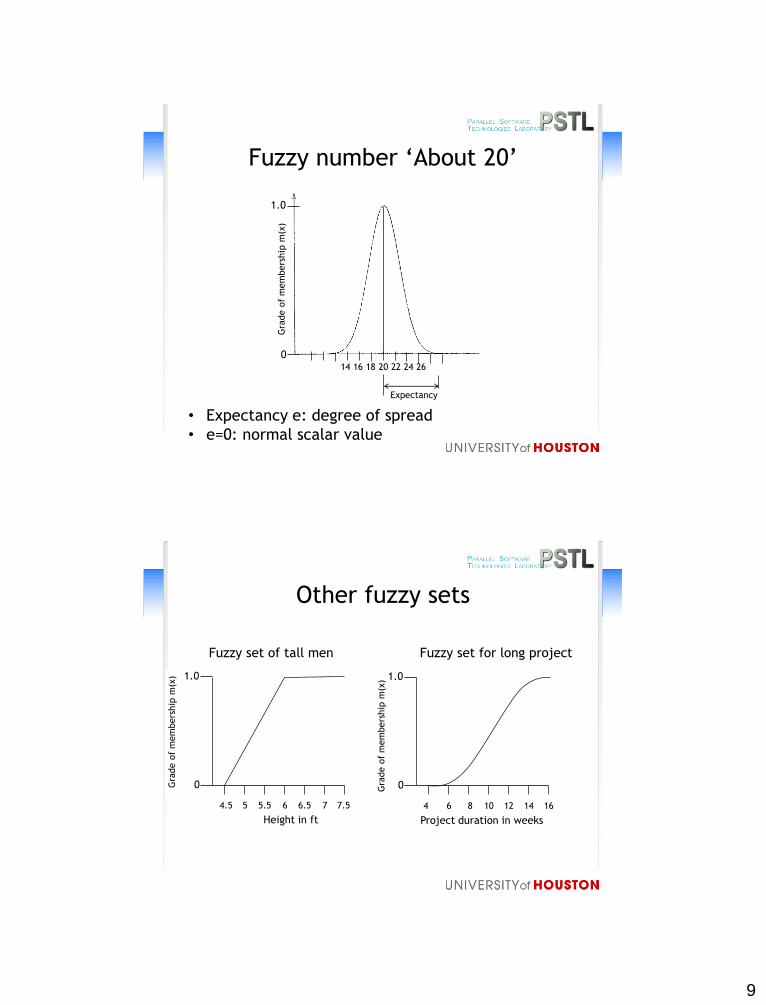
9
Fuzzy number ‘About 20’
Gra
de o
f m
em
bers
hip
m(x
)
14 16 18 20 22 24 26
1.0
0
Expectancy
• Expectancy e: degree of spread
• e=0: normal scalar value
Other fuzzy sets
1.0
0
4.5 5 5.5 6 7 7.56.5
Height in ft
1.0
0
4 6 8 10 14 1612
Project duration in weeks
Fuzzy set of tall men Fuzzy set for long project
Gra
de o
f m
em
bers
hip
m(x
)
Gra
de o
f m
em
bers
hip
m(x
)

10
Collection of Fuzzy Sets
1.0
0
10 15 20 25 35 4030
Client age (in years)
50 5545 65 7060
Child TeenYoung
adult
Middle
aged senior
• Each underlying fuzzy set defines a portion of the
variables domain
• A portion is not necessarily uniquely defined
Gra
de o
f m
em
bers
hip
m(x
)
Hedges: Fuzzy set transformers
• A hedge acts on a fuzzy set the same way an adjective
acts on a noun
– Increase or decrease the expectancy of a fuzzy number
– Intensify or dilute the membership of a fuzzy set
– Change the shape of a fuzzy set through contrast or
restriction
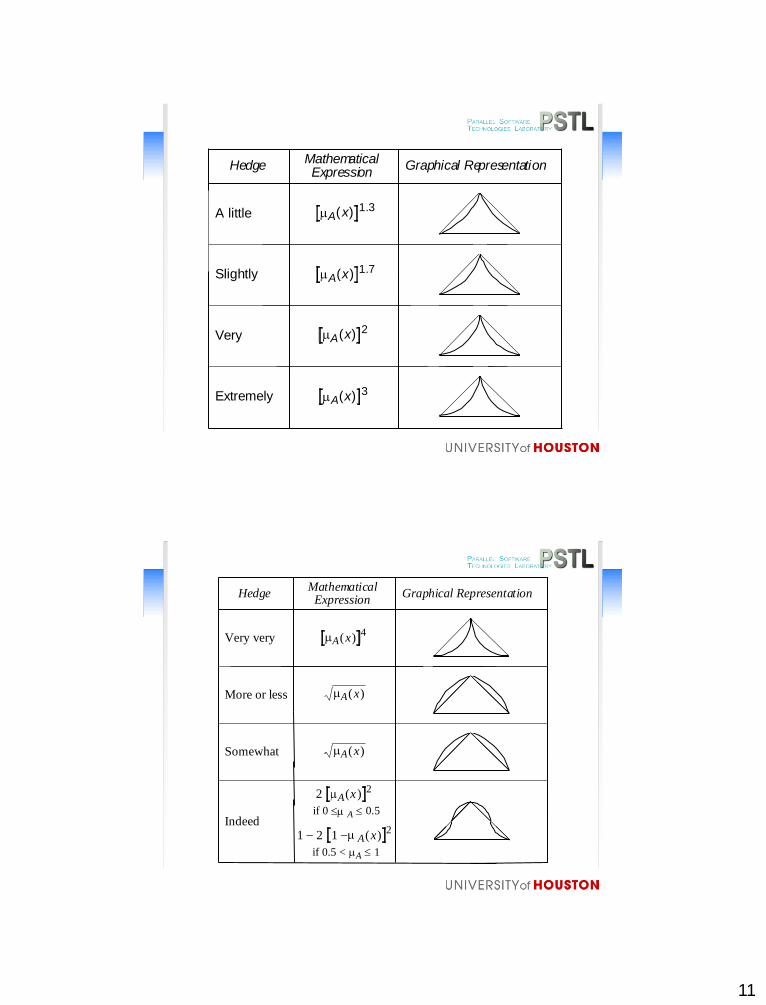
11
HedgeMathematicalExpression
A little
Slightly
Very
Extremely
Graphical Representation
[A(x)]1.3
[A(x)]1.7
[A(x)]2
[A(x)]3
HedgeMathematicalExpression
Graphical Representation
Very very
More or less
Indeed
Somewhat
2 [A(x )]2
A(x)
A(x)
if 0 A 0.5
if 0.5 < A 1
1 2 [1 A(x)]2
[A(x)]4

12
Alpha Cut Threshold
• An Alpha cut threshold defines a minimum truth
membership level for a fuzzy set
1.0
0
4 6 8 10 14 1612
Project duration in wks
Fuzzy set for long project
µ[.15]
Gra
de o
f m
em
bers
hip
m(x
)
Fuzzy AND Operator
• Example: region produced by proposition of Young
Adult and Middle Aged
• Mathematical representation
𝜇𝑇 𝑥𝑖 = min(𝜇𝐴 𝑥𝑖 , 𝜇𝐵 𝑥𝑖 )
1.0
0
10 15 20 25 35 4030
Client age (in years)
50 5545 65 7060
Young
adult
Middle
Aged
Gra
de o
f m
em
bers
hip
m(x
)

13
Fuzzy OR Operator
• Example: region produced by proposition of Young
Adult or Middle Aged
• Mathematical representation
𝜇𝑇 𝑥𝑖 = m𝑎𝑥(𝜇𝐴 𝑥𝑖 , 𝜇𝐵 𝑥𝑖 )
1.0
0
10 15 20 25 35 4030
Client age (in years)
50 5545 65 7060
Young
adult
Middle
Aged
Gra
de o
f m
em
bers
hip
m(x
)
Fuzzy NOT Operator
• Example: region produced by proposition of NOT Middle
Aged
• Mathematical representation
𝜇𝑇 𝑥𝑖 = 1 − 𝜇𝐴 𝑥𝑖
1.0
0
10 15 20 25 35 4030
Client age (in years)
50 5545 65 7060
Middle
Aged
Gra
de o
f m
em
bers
hip
m(x
)

14
Fuzzy Clustering: Motivation
• Crisp clustering allows each data point to be member of
exactly one cluster
• Fuzzy clustering assign membership values for each cluster
– Might be zero for some points
Fuzzy Clustering Concepts
• Each data point will have an associated degree of
membership for each cluster center in the range of
[0,1]
1.0
0

15
Fuzzy clustering concepts
• Fuzzification parameter m
m=1
clusters do not overlapm>1
clusters overlap
Fuzzy c-means clustering• Extension of the k-means algorithm
• Two steps:
– calculation of cluster centers
– Assignment of points to the clusters with varying degree
of memberships
• Constraint on fuzzy membership function associated
with each point: 𝑗=1𝑝
𝜇𝑗 𝑥𝑖 = 1, i=1,..,k
– p : number of clusters
– k: number of datapoints
– xi: ith data point
– µj(): function returning the membership value of xi in the
jth cluster

16
Fuzzy c-means clustering• Minimization of standard loss function
𝑘=1
𝑝
𝑖=1
𝑛
𝜇𝑘 𝑥𝑖𝑚 𝑥𝑖 − 𝑐𝑘 2
• Basic algorithm
Initialize p = number of clusters
m = fuzzification parameter
cj = cluster centers
Repeat
for all data points: calculate distance dij to all centers cj
for i=1 to n: update µj(xi) using cj
for j=1 to p: Update cj using current µj(xi)
Until cj estimates stabilize
Fuzzy c-means clustering
• With µj(xi)=
1
𝑑𝑗𝑖
1𝑚−1
𝑘=1𝑝 1
𝑑𝑘𝑖
1𝑚−1
dji being the distance of xi to cluster center cj (e.g. euclidean
distance)
• and 𝑐𝑗 = 𝑖( µj(𝑥𝑖)
𝑚𝑥𝑖)
𝑖 µj(𝑥𝑖)𝑚

17
Fuzzy c-means clustering
• Problem with c-means clustering:
– Outlier data points still have to be assigned to a cluster
Fuzzy Adaptive Clustering
• Alternative formulation for constraint on membership
𝑗=1
𝑝
𝑖=1
𝑛
µj(xi) = 𝑛
– Membership quantifiers for all sample points is n
– Individual point could have a total value of membership
function of <1
=> µj(xi)=𝑛
1
𝑑𝑗𝑖
1𝑚−1
𝑘=1𝑝 𝑧=1
𝑛 1
𝑑𝑘𝑧
1𝑚−1







