Download - Building Realtime Data Pipelines with Kafka Connect and Spark Streaming by Ewen Cheslack-Postava

BUILDING REALTIME DATA PIPELINES WITH KAFKA CONNECT AND SPARK STREAMING
Ewen Cheslack-PostavaConfluent

About Me: Ewen Cheslack-Postava• Engineer @ Confluent• Kafka Committer• Kafka Connect Lead

Traditional ETL

More Data Systems
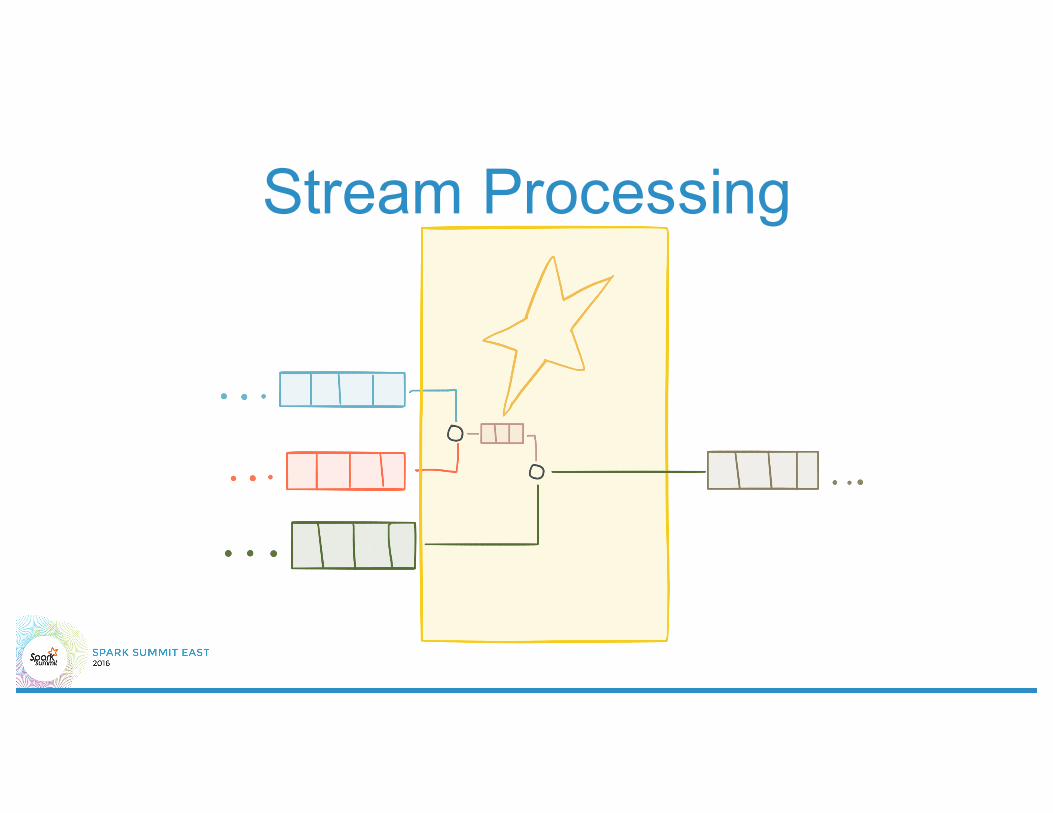
Stream Processing
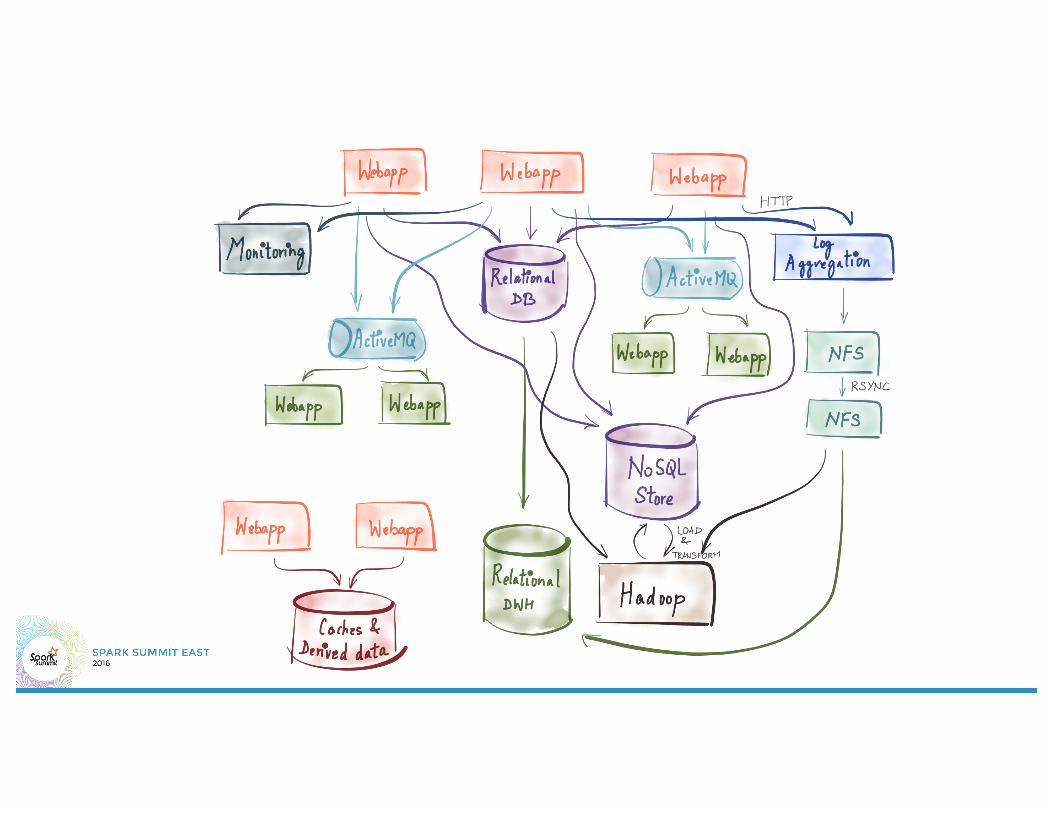


Separation of Concerns
Large-scale streaming data import/export for Kafka
Kafka Connect
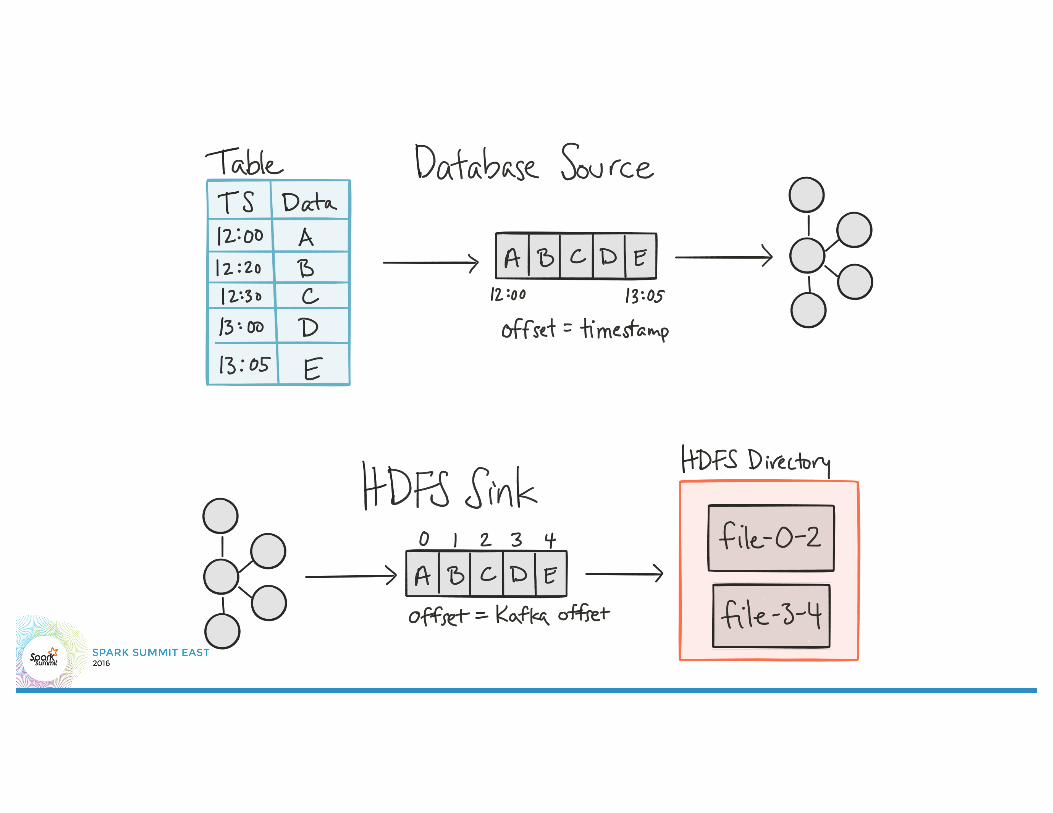
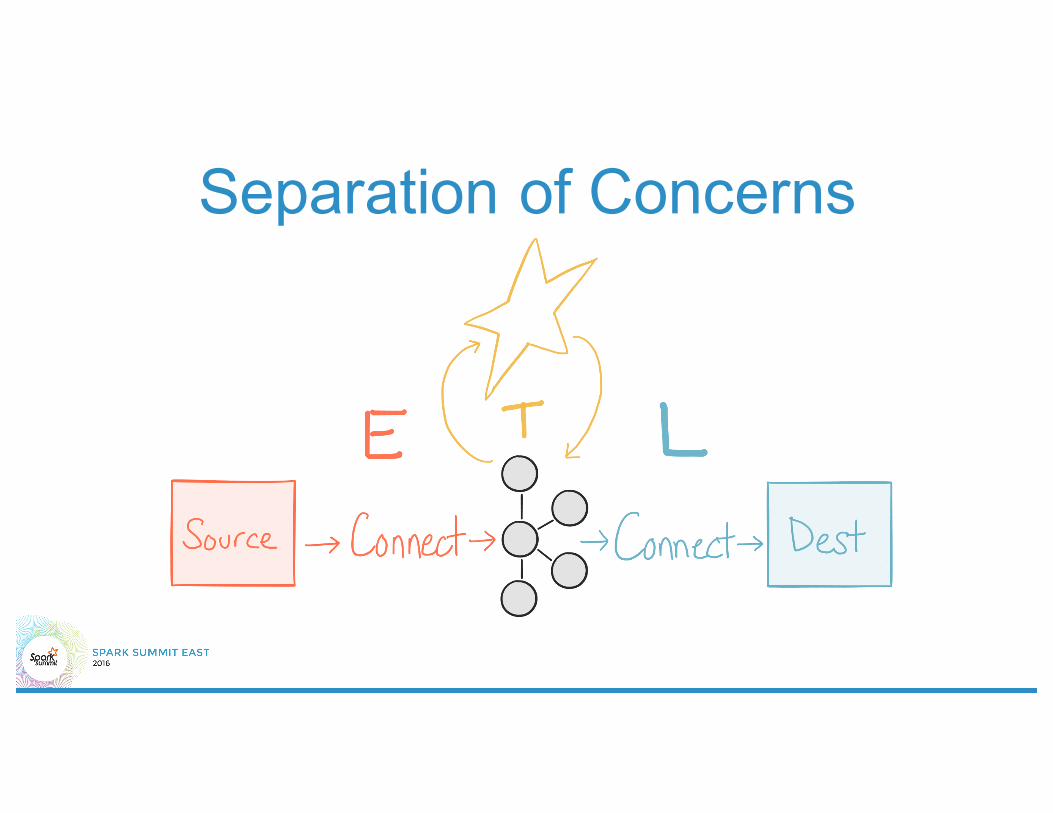
Separation of Concerns
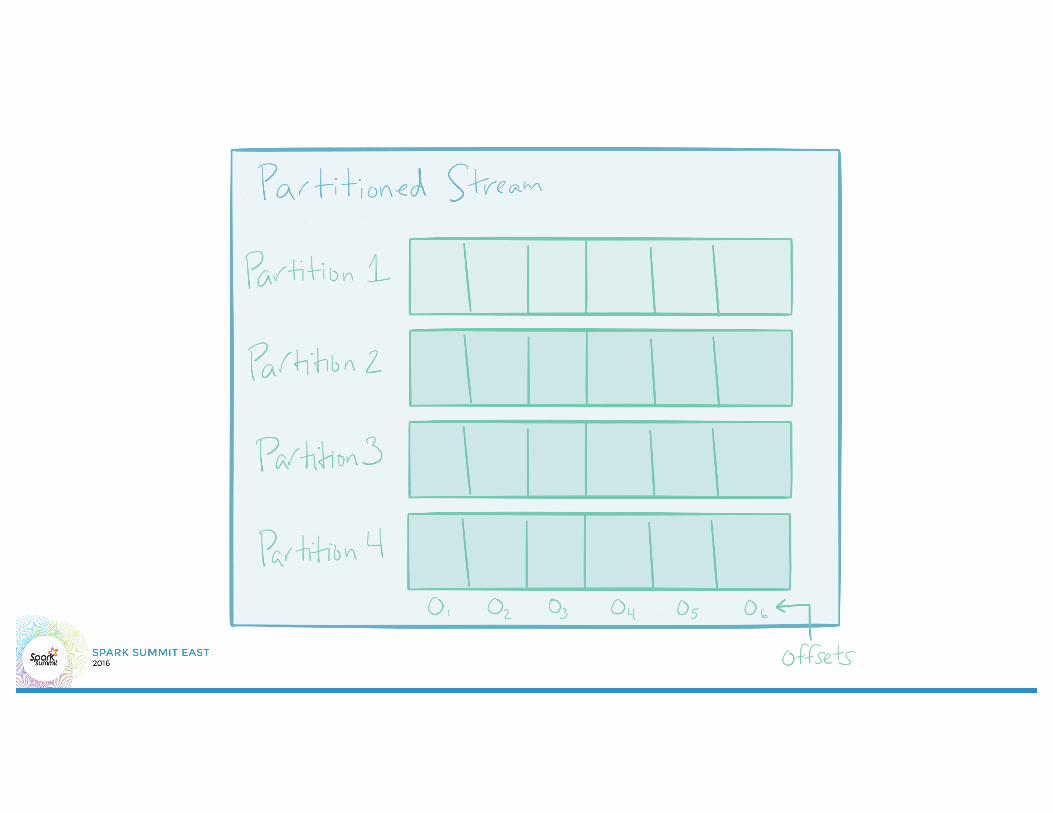
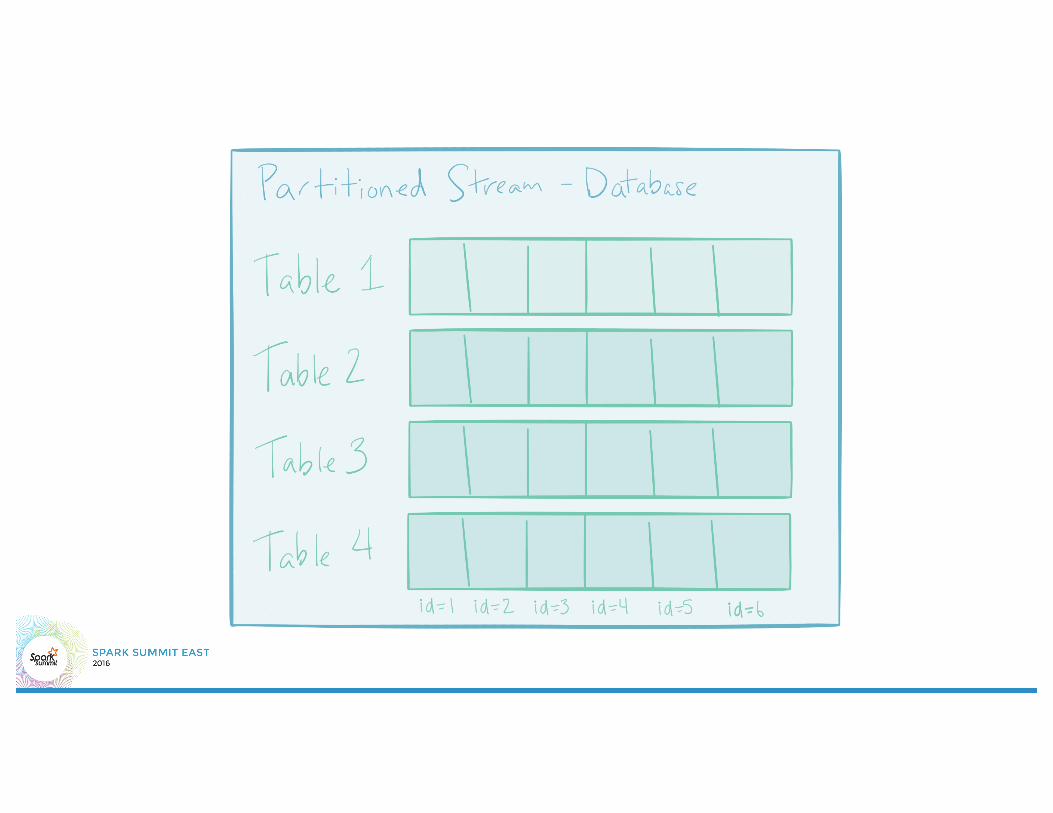
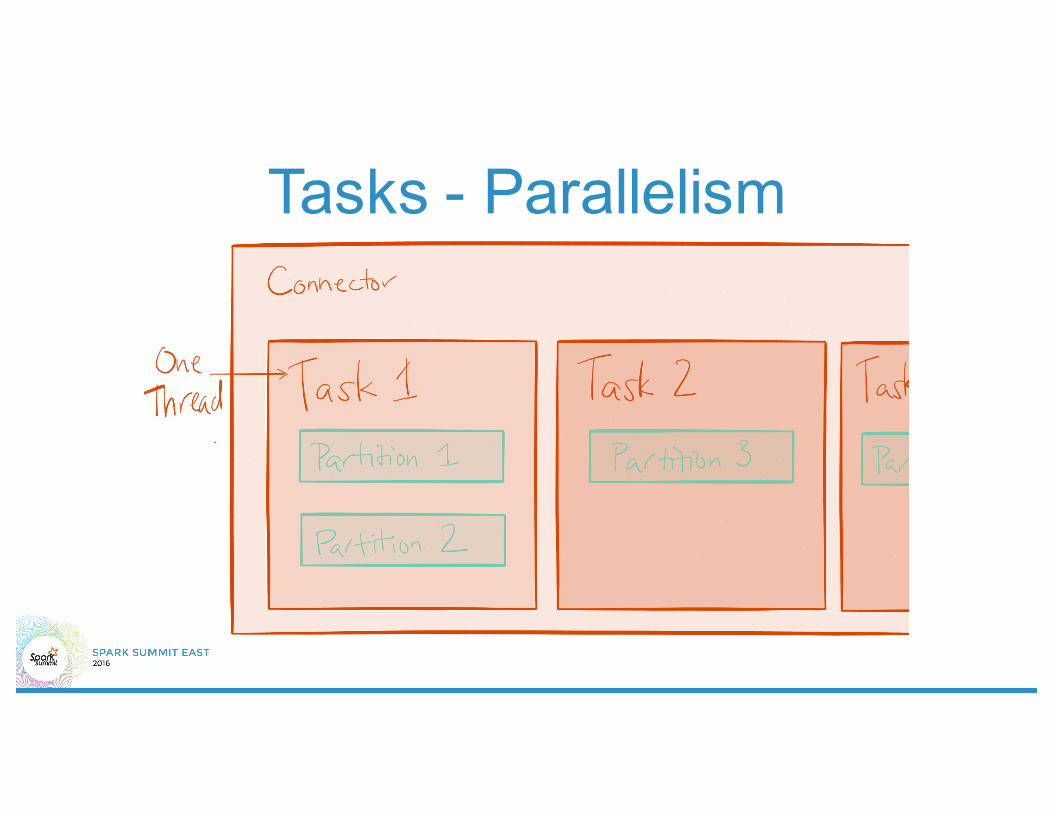
Tasks - Parallelism
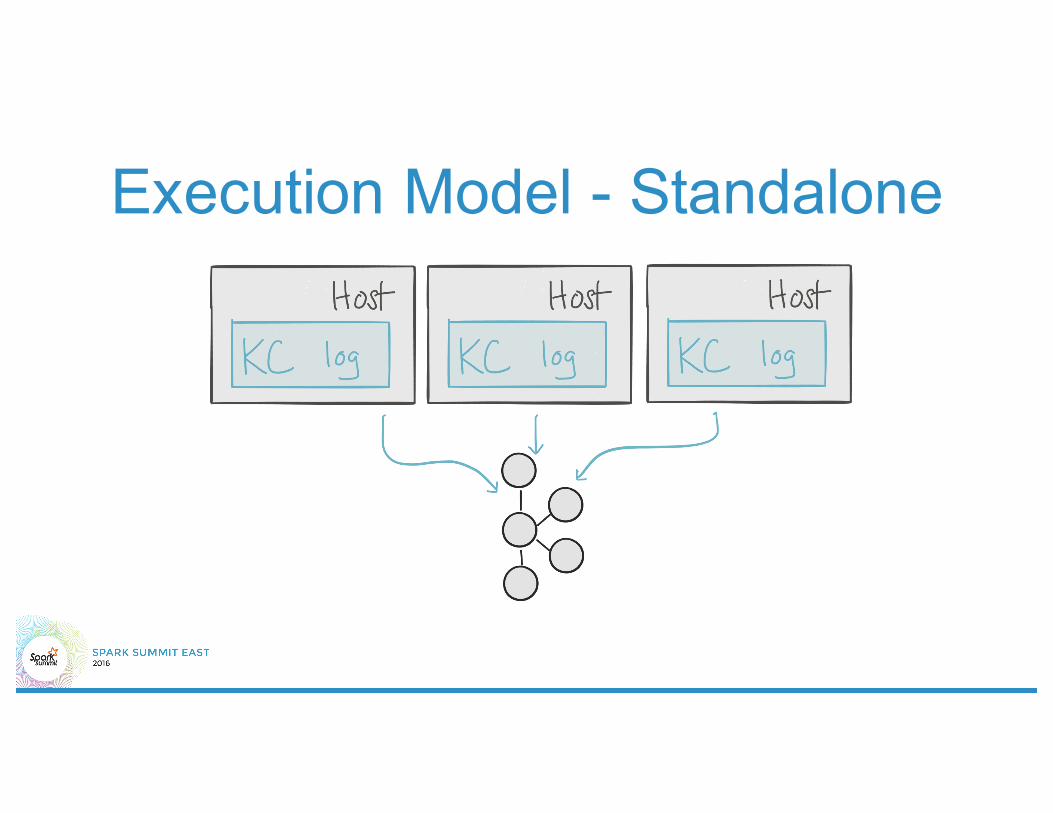
Execution Model - Standalone
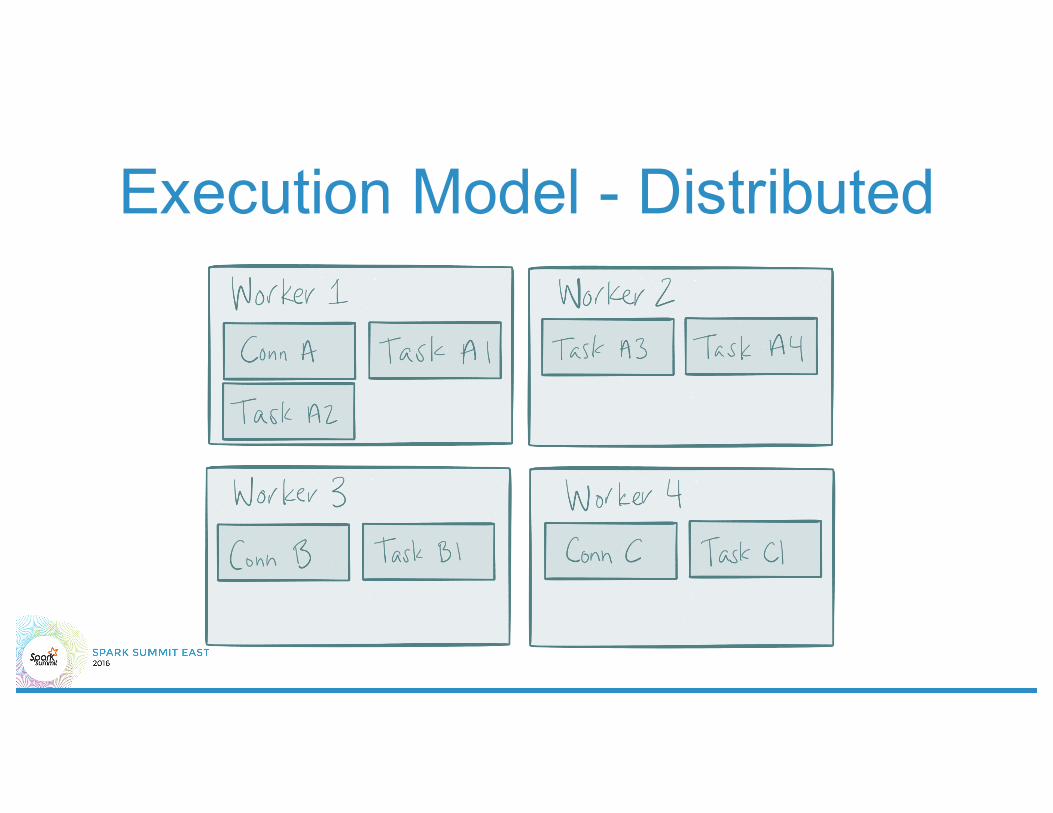
Execution Model - Distributed
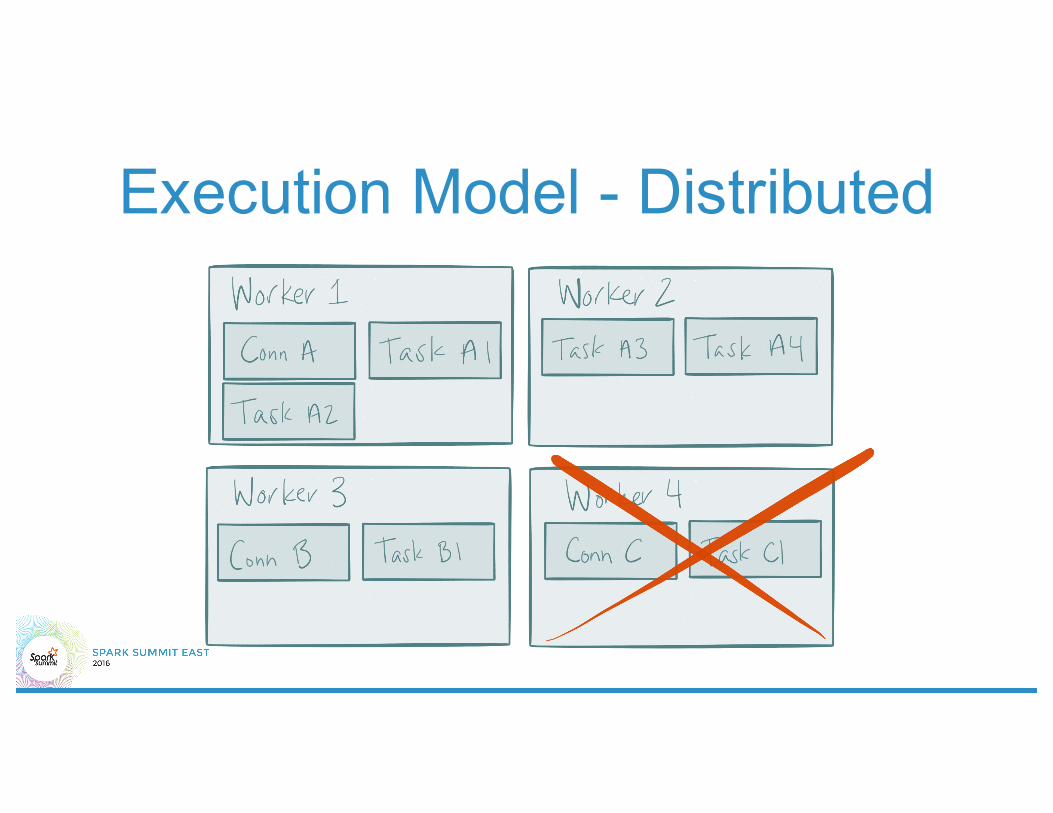
Execution Model - Distributed
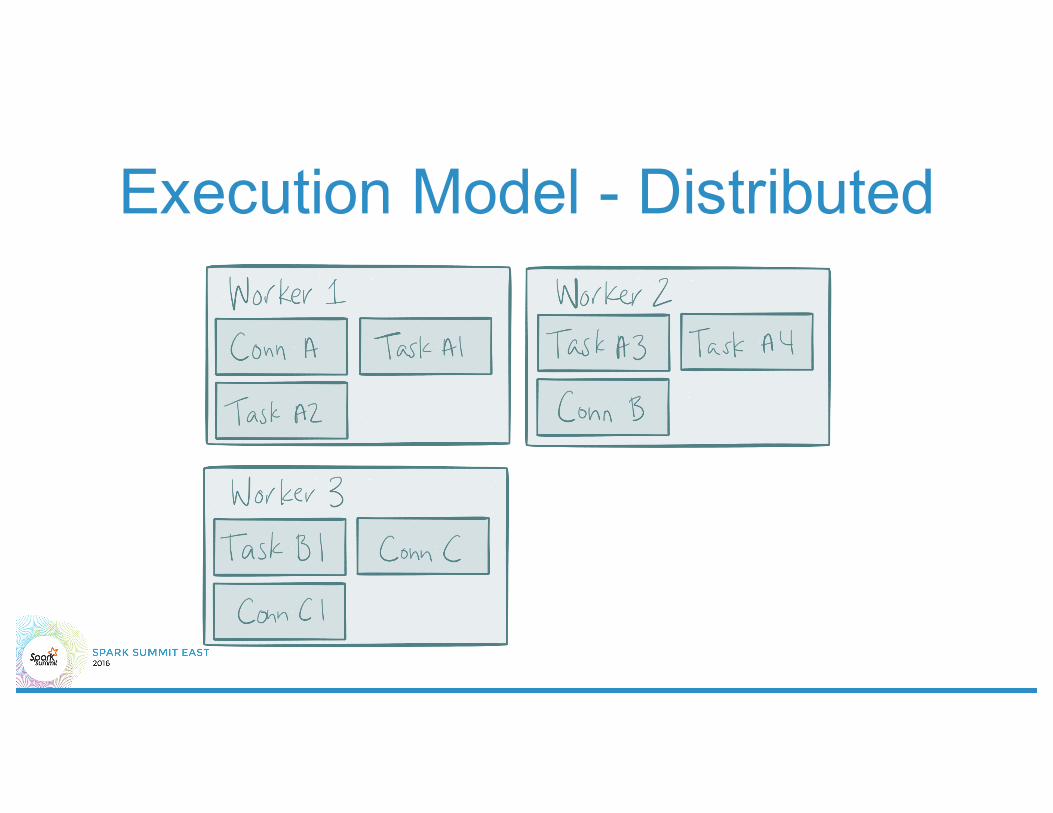
Execution Model - Distributed
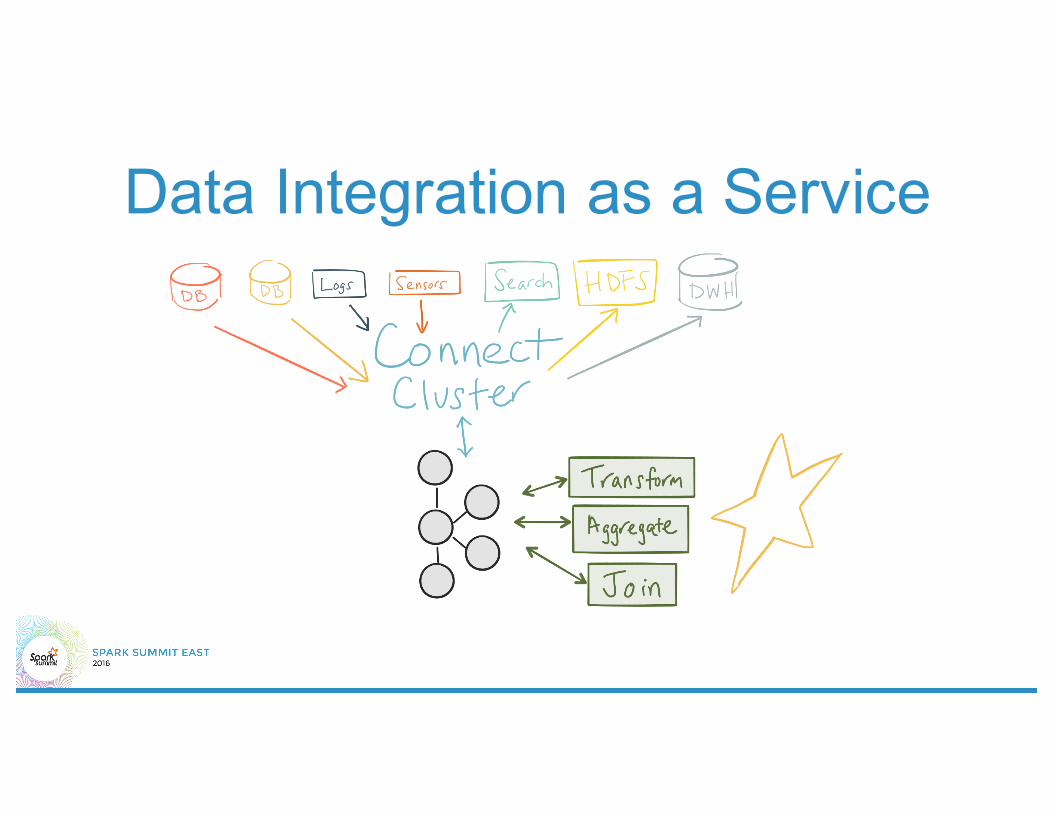
Data Integration as a Service

Delivery Guarantees• Automatic offset checkpointing and recovery
– Supports at least once– Exactly once for connectors that support it
(e.g. HDFS)– At most once simply swaps write & commit– On restart: task checks offsets & rewinds

Spark Streaming• Use Direct Kafka streams (1.3+)
– Better integration, more efficient, better semantics
• Spark Kafka Writer– At least once– Kafka community is working on improved
producer semantics

Spark Streaming & Kafka Connect• Increase # of systems Spark Streaming
works with, indirectly• Reduce friction to adopt Spark Streaming• Reduce need for Spark-specific connectors• By leveraging Kafka as de facto streaming
data storage

Kafka Connect Summary
23
• Designed for large scale stream or batch data integration
• Community supported and certified way of using Kafka
• Soon, large repository of open source connectors• Easy data pipelines when combined with Spark &
Spark Streaming

THANK YOU.Follow me on Twitter: @ewencpTry it out: http://confluent.io/downloadMore like this, but in blog form: http://confluent.io/blog

Add Pages as Necessary• Supporting points go here.







