
Four Tips for Faster Development with DynamoDB
David Pearson Business Development Manager AWS Database Services
Amazon RDS
Amazon DynamoDB Amazon Redshift
Amazon ElastiCache
Compute Storage
AWS Global Infrastructure
Database
Application Services
Deployment & Administration
Networking
AWS Database Services
Scalable High Performance Application Storage in the Cloud

RDBMS
infrastructure scaling
+ application scaling
infrastructure
scaling only
Read Replicas Data Sharding Denormalization
NoSQL
Scaling Databases

Amazon’s Database Journey
DynamoDB RDBMS

distributed key/value database service
=

distributed key/value database service
simple API fast development =
predictable performance automated operations
durable low latency cost effective
massively scalable

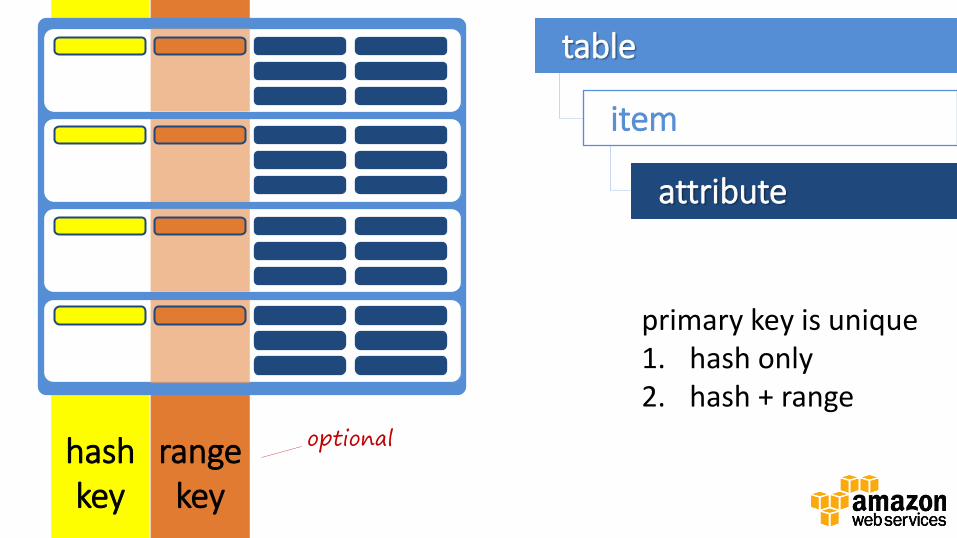
table
item
attribute

primary key is unique 1. hash only
table
item
attribute
mandatory hash key
table
item
attribute
optional
primary key is unique 1. hash only 2. hash + range
range key
hash key

attributes are associated
with items rather than tables (as in RDBMS)
table
item
attribute
sparse schema
range key
hash key

Faster Development
Customer Experiences
Weatherbug mobile app
Lightning detection & alerting for 40M users/month
Developed and tested in weeks, at “1/20th of the cost of
the traditional DB approach”
Super Bowl promotion
Millions of interactions over a relatively short period of time
Built the app in 3 days, from design to production-ready

Faster Development
Four Tips
design for scale leverage range keys use libraries & tools
develop & test locally

Design for Scale
Common Problem = inefficiently designed schemas Hot spots create premature throttling
Excessive payloads cost more to move
Design Goals:
• Optimize the schema to the access patterns
• Minimize multi-table fetches (for high-scale patterns)
• Minimize payload size for each pattern

partitions 1 .. N
table
• DynamoDB automatically partitions data by the hash key Hash key spreads data (& workload) across partitions
• Auto-partitioning driven by: Data set size
Throughput provisioned
Design for Scale – Partitioning
large number of unique hash keys
+ uniform distribution of workload
across hash keys
ready to scale!

1. Identify the individual access patterns
2. Model each pattern to its own discrete data set
3. Consolidate data sets into tables and indexes
Design for Scale – Efficient Schema Design
Access Patterns given userid…
• return all items by file name • return all items by date created • return all items by size • return all items by type • return all items by date updated
Abbreviated Example: File Sharing

• Enable modeling 1:M relationships
Range Keys
hash range attributes
userid=“@mza” postdate=“2013-09-12T20:59:28Z”
posttext=“New! Develop and test your apps with DynamoDB Local: http://aws.typepad.com/aws/2013/09/dynamodb-local-for-desktop-development.html … #aws”
userid=“@mza” postdate=“2013-09-13T09:17:37Z”
posttext=“Also! Copy DynamoDB data between regions with Data Pipeline: http://aws.typepad.com/aws/2013/09/copy-dynamodb-data-between-regions-using-the-aws-data-pipeline.html … #aws”
userid=“@werner” postdate=“2013-10-04T17:41:09Z”
posttext=“cool! RT @dialtone_: Worldwide DynamoDB replication for billions of rows a day? No problem! http://tech.adroll.com/blog/ops/2013/10/02/dynamodb-replication.html … @AdRoll can handle that!”

• Currently 13 operations in total
Range Keys – Simple API
Manage Tables
• CreateTable
• UpdateTable
• DeleteTable
• DescribeTable
• ListTables
Read and Write Items
• PutItem
• GetItem
• UpdateItem
• DeleteItem
Read and Write Multiple Items
• BatchGetItem
• BatchWriteItem
• Query
• Scan
• Query

Query
• Available for hash+range primary key tables
• Retrieve all items by hash key
• Range key conditions:
• ==, <, >, >=, <=, begins with, between
• Sorted results. Counts. Top and bottom n values. Paged responses
Range Keys – Query

• Query treats all items as a single read operation Items share the same hash key = same partition
By contrast, BatchGetItem reads each item in the batch separately
• Example Read 100 items in a table, all of which share the same hash key
Each item is 120 bytes in size
Range Keys – Query and Efficient Reads
note: read capacity units are 4K in size
Query BatchGetItem
RCU Consumed 3 100
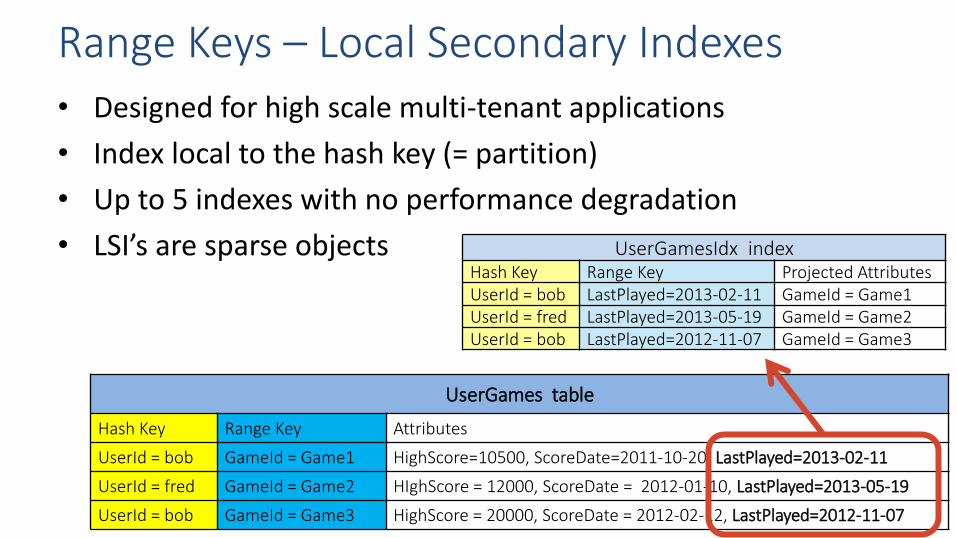
• Designed for high scale multi-tenant applications
• Index local to the hash key (= partition)
• Up to 5 indexes with no performance degradation
• LSI’s are sparse objects
Range Keys – Local Secondary Indexes
UserGames table
Hash Key Range Key Attributes
UserId = bob GameId = Game1 HighScore=10500, ScoreDate=2011-10-20, LastPlayed=2013-02-11
UserId = fred GameId = Game2 HIghScore = 12000, ScoreDate = 2012-01-10, LastPlayed=2013-05-19
UserId = bob GameId = Game3 HighScore = 20000, ScoreDate = 2012-02-12, LastPlayed=2012-11-07
UserGamesIdx index Hash Key Range Key Projected Attributes UserId = bob LastPlayed=2013-02-11 GameId = Game1 UserId = fred LastPlayed=2013-05-19 GameId = Game2 UserId = bob LastPlayed=2012-11-07 GameId = Game3

Use Libraries and Tools
Transactions Atomic transactions across multiple items & tables
Tracks status of ongoing transactions via two tables
1. Transactions
2. Pre-transaction snapshots of modified items
Geolocation Add location awareness to mobile
applications
Find Yourself – sample app
https://github.com/awslabs

Community Contributions
Use Libraries and Tools

• Disconnected development with full API support
No network
No usage costs
Develop and Test Locally – DynamoDB Local
Note! DynamoDB Local does not have a durability or availability SLA
m2.4xlarge
DynamoDB Local
do this instead!

Some minor differences from Amazon DynamoDB
• DynamoDB Local ignores your provisioned throughput settings The values that you specify when you call CreateTable and
UpdateTable have no effect
• DynamoDB Local does not throttle read or write activity
• The values that you supply for the AWS access key and the Region are only used to name the database file
• Your AWS secret key is ignored but must be specified Recommended using a dummy string of characters
Develop and Test Locally – DynamoDB Local

Additional Options
Develop and Test Locally

Faster Development
Customer Experiences
"Since we had such a short time frame to build Digg Reader we had to lean heavily on some of the hosted AWS services, like DynamoDB, versus rolling our own.” – Digg CTO Mike Young
“If we used a different product we would have spent a lot of development time to reach parity with DynamoDB instead of developing our business.”
– Peter Bogunovich, Software Engineer RightAction, Inc

database service
automated operations predictable performance
durable low latency cost effective
=

Provision / Configure Servers and Storage
Repartition Data and Balance Clusters
Manage Cross-Availability Zone Replication
Update Hardware and Software
Monitor and Handle Hardware Failures
• As scalability increases, performance degrades
• Substantial effort is required to sustain high performance
Automated Operations

Provisioned Throughput • Request-based capacity provisioning model
• Throughput is declared and updated via the API or the console CreateTable (foo, reads/sec = 100, writes/sec = 150) UpdateTable (foo, reads/sec=10000, writes/sec=4500)
• DynamoDB handles the rest Capacity is reserved and available when needed Scaling-up triggers repartitioning and reallocation No impact to performance or availability
Predictable Performance

WRITES Continuously replicated to 3 AZ’s Always consistent Persisted to disk (custom SSD)
READS Strongly or eventually consistent
No trade-off in latency
Durable Low Latency

WRITES Continuously replicated to 3 AZ’s Always consistent Persisted to disk (custom SSD)
READS Strongly or eventually consistent
No trade-off in latency
Durable Low Latency – At Scale

efficient design
is cost effective
“Our previous NoSQL database required almost an full time administrator to run.
Now AWS takes care of it.”
managed services
reduce effort
Experiment Optimize
agility = time

Recommended Resources
AWS Mobile Development Blog
http://mobile.awsblog.com
• Geo Library for Amazon DynamoDB (series)
• Amazon DynamoDB on Mobile (series)
DynamoDB Best Practices, How-Tos, and Tools
http://aws.amazon.com/dynamodb/resources
• Local development and testing tools
• Backup and archive
• Autoscale

Questions?
David Pearson Business Development Manager AWS Database Services







