Download - 1 Business Intelligence Technologies – Data Mining Lecture 5 Personalization, k-Nearest Neighbors

1
Business Intelligence Technologies – Data Mining
Lecture 5 Personalization, k-Nearest Neighbors

2
Agenda
Personalization
K-Nearest Neighbors
Collaborative Filtering
Case Discussion
Software Demo

3
Personalization
Personalization/customization tailors certain offerings by providers to consumers based on knowledge about them with certain goals in mind.
CustomerPersonalized
offeringsHow?

4
What is Currently Being Personalized
Personalized recommendations of products and services e.g., recommend books, CDs and vacations;
Personalized products for individual consumers e.g., custom-made CDs, Dell computers
Personalized emails Personalized content
e.g., Yahoo’s personalized home page Amazon’s channel management
Personalized (dynamic) prices

5
Sample Automated E-mail

6
Personalization Process Understand-Deliver-Measure Cycle
Measuring Personalization Impact
Data Collection
Building Consumer Profiles
Matchmaking
Delivery and Presentation
Measure Impact of
Personalization
Deliver Personalized
Offerings
Understand the Consumer
Adjusting Personalization Strategy
Fee
dbac
k lo
op

7
Building Profiles from Data Data Needed
Personal information, preferences & interests Registration data, including demographic data Customer ratings
Purchasing data What was bought, when and where
Browsing & visitation data Clickstream (Weblog files)
Building customer profiles Demographic (e.g., name, address, age) Behavioral (e.g., favorite type of book – adventure,
largest transaction - $295) Things learned from data

8
Matchmaking Problem Example: Large e-Commerce Site
10M customers1M productsQuestion: How to match (target) the products
to individual customers? What 10 books (out of 1M) should I show to Jane on her homepage?
Solution: To do matchmaking, use customer profiles various recommendation technologies

9
Recommendation Technologies Collaborative filtering
Find the closest customers and recommend what they buy
Content-based filtering See what a customer has bought in the past, and use this
information to predict what he would like in the future. e.g. Recommendation things that are similar to the things he bought before.
Rule-based approach Identify business rules about what products should be
recommended Example:
IF a customer fits a certain profile (e.g. male, age 25-35), THEN recommend a certain set of products.

10
Agenda
Personalization
K-Nearest Neighbors
Collaborative Filtering
Case Discussion
Software Demo

11
Nearest Neighbor Approaches
Based on the concept of similarity
Memory-Based Reasoning (MBR)
k Nearest Neighbor (KNN)
Collaborative Filtering (CF)

12
K Nearest Neighbor (KNN)K-Nearest Neighbor can be used for classification/prediction tasks.
Step 1: Using a chosen distance metric, compute the distance between the new example and all past examples.
Step 2: Choose the k past examples that are closest to the new example.
Step 3: Work out the predominant class of those k nearest neighbors - the predominant class is your prediction for the new example. i.e. classification is done by majority vote of the k nearest neighbors. For prediction problem with numeric target variable, the (weighted) average of the k nearest neighbors is used as the predicted target value.

13
Each example is represented with a set of numerical attributes
“Closeness” is defined in terms of the Euclidean distance between two examples. The Euclidean distance between X=(x1, x2, x3,…xn) and Y
=(y1,y2, y3,…yn) is defined as:
Distance (John, Rachel)=sqrt [(35-41)2+(95K-215K)2 +(3-2)2]
n
iii yxYXD
1
2)(),(
John:John:Age=35Age=35Income=95KIncome=95KNo. of credit No. of credit cards=3cards=3
Rachel: Rachel: Age=41Age=41Income=215KIncome=215KNo. of credit No. of credit cards=2cards=2
How do we determine our neighbors? -Distance Measure Revisited.

14
Example : 3-Nearest Neighbors K-Nearest Neighbor Classifier
Customer Age Income No. credit cards Response
John 35 35K 3 No
Rachel 22 50K 2 Yes
Hannah 63 200K 1 No
Tom 59 170K 1 No
Nellie 25 40K 4 Yes
David 37 50K 2 ?
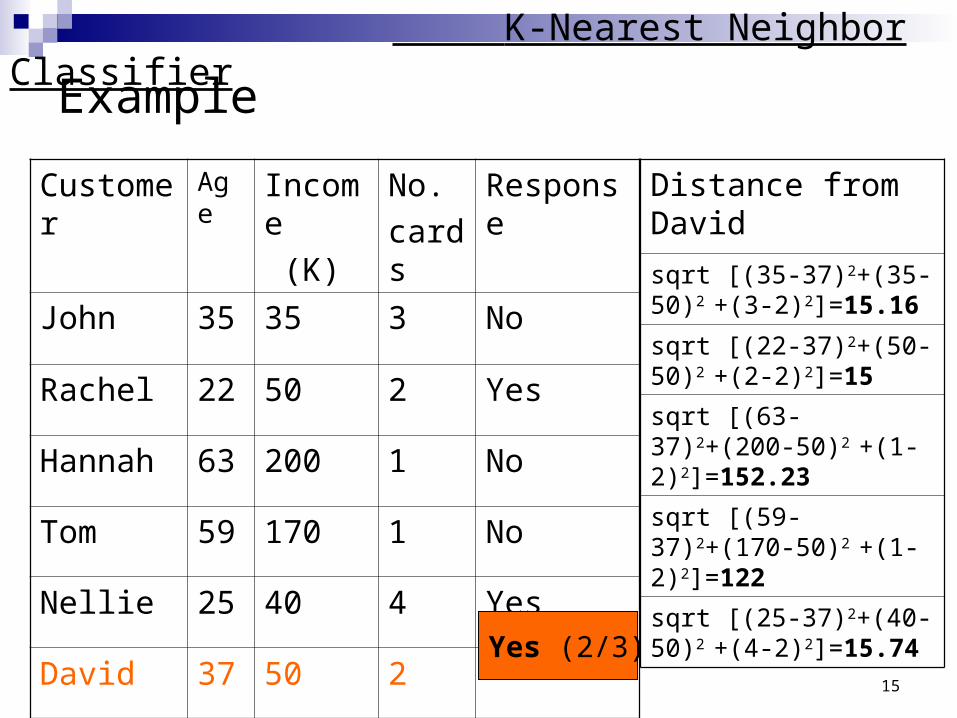
15
Example K-Nearest Neighbor Classifier
Customer Age Income
(K)
No.
cards
Response
John 35 35 3 No
Rachel 22 50 2 Yes
Hannah 63 200 1 No
Tom 59 170 1 No
Nellie 25 40 4 Yes
David 37 50 2
Distance from David
sqrt [(35-37)2+(35-50)2
+(3-2)2]=15.16
sqrt [(22-37)2+(50-50)2
+(2-2)2]=15
sqrt [(63-37)2+(200-50)2
+(1-2)2]=152.23
sqrt [(59-37)2+(170-50)2
+(1-2)2]=122
sqrt [(25-37)2+(40-50)2
+(4-2)2]=15.74
Yes (2/3)

16
Some Issues with Euclidian Distance
Scaling of values Since each numeric attribute may be measured in different units,
they should be standardized.
Weighting of attributes: Manual weighting: Weights may be suggested by experts Automatic weighting: Weights may be computed based on
discriminatory power or other statistics. (e.g. in SAS, weighted dimension is based on the correlation to the target variable.)
Treatment of categorical variables Various ways of assigning distance between categories are
possible.

17
Dealing with Categorical Values• For categorical values, we can to convert them to numeric values.
• We might treat ‘being in class A’ as ‘1’, and ‘not in class A’ as 0. Therefore, two items in the same class have distance 0 for that attribute, and two items in different classes have distance 1 for that attribute. For example:
Take the bridge attributes: (deck type, purpose)Take the bridges: Bridge 1 = (concrete, auto)
Bridge 2 = (steel, railway)Bridge 3 = (concrete, railway)
We could compute distances as:d(Bridge1,Bridge2) = 1 + 1 = 2d(Bridge2,Bridge3) = 1 + 0 = 1d(Bridge1,Bridge3) = 0 + 1 = 1
• Again, some form of weighting for attributes of different importance may be useful.

18
Dealing with Categorical Values
• We might also construct aggregation hierarchies, so that categories far away from each other conceptually are given higher distances.
Concrete deck Steel deck
Pre-cast deck Cast-at-site deck
Deck
• Using this hierarchy, we might regard the distance between pre-cast and cast-at-site as 1 (they have a common parent), while the distance between pre-cast and steel could be 2 (they have a common grandparent). The distance between concrete and steel would be 1 (they have a common parent).

19
How to Decided K?Assume a new example X (at the center of the circles below). Notice that:
• With a 3-Nearest Neighbor classifier (inner circle), X is assigned to the majority Class B, whereas
• With an 11-Nearest Neighbor classifier (outer circle), X is assigned to the majority Class A.
• Can use validation data set to decide k.
Class A
Attribute B
Class B
Attribute A
XX

20
• Often work well for classes that are hard to separate using parametric methods or the splits used by decision trees.
• Simple to implement and use• Comprehensible – easy to explain prediction• Robust to noisy data by averaging k-nearest neighbors.• Some appealing applications (e.g. personalization)
Strengths of K-Nearest Neighbor
Class A
Attribute A
Attribute B
Class B
Class C
Class D

21
• How to choose k ? Do we use 1 nearest neighbor, 10 nearest neighbors, 50 nearest neighbors?
• Computational cost: For a large database, we’d have to compute the distance between the new example and every old example, and then sort by distance, which can be very time-consuming. Possible resolutions are:
• sampling: store only a sample of the historic data so that you have fewer distances to compute.
Problems with K Nearest Neighbor (KNN)

22
Applications of MBR
• Medicine / 911: Find which diagnosis was made for similar symptoms in the past, and adapt treatment appropriately
• Customer Support (HelpDesk): Find which solution was proposed for similar problems in the past, and adapt appropriately (e.g. Compaq’s SMART/QUICKSOURCE system)
• Engineering / Construction: Find what costing or design was made for projects with similar requirements in the past, and adapt appropriately
• Law (Legal Advice): Find what judgment was made for similar cases in the past, and adapt appropriately
• Audit and Consulting Engagements: find similar past projects
• Insurance Claims Settlement: find similar claims in the past
• Real estate: Property price appraisal based on previous sales

23
Agenda
Personalization
K-Nearest Neighbors
Collaborative Filtering
Case Discussion
Software Demo

24
One seeks recommendations about movies, restaurants, books etc. from people with similar tastes
Automate the process of "word-of-mouth" by which people recommend products or services to one another.
CF is a variant of MBR particularly well suited to personalized recommendations
Collaborative Filtering: Finding the like-minded people

25
Collaborative Filtering Starts with a history of people’s personal
preferences Uses a distance function – people who
like the same things are “close” Uses “votes” which are weighted by
distances, so close neighbor votes count more

26
Collaborative filtering1. Consumers’ preferences are registered
Restaurants Rating (0:bad - 10:Excelent)
Fridays Thai Food The Barns University Cafe Cosi
Don 5 1 6 6 2
Rachel 1 4 2 3 5
David 1 3 2 ??? ???
…
2. David is seeking recommendations on restaurants .
3. Using a similarity metric, the similarity between another person and David is calculated based on their preferences (i.e., restaurant ratings).
4. Their (weighted) average ratings for any given restaurant is computed, and restaurants with a high average score are recommended to David.
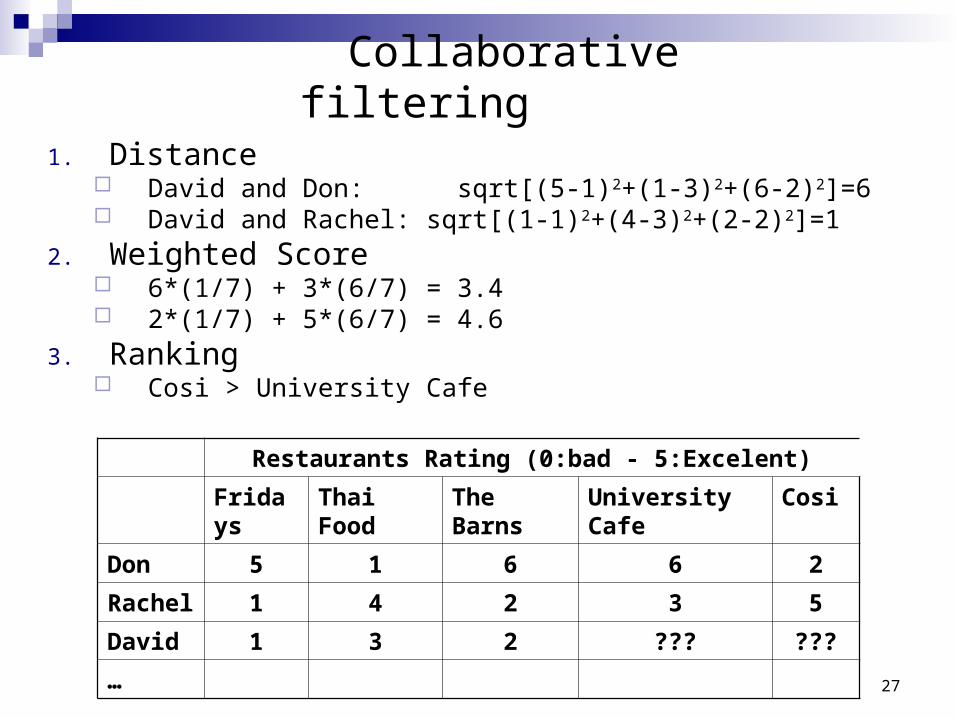
27
Collaborative filtering
1. Distance David and Don: sqrt[(5-1)2+(1-3)2+(6-2)2]=6 David and Rachel: sqrt[(1-1)2+(4-3)2+(2-2)2]=1
2. Weighted Score 6*(1/7) + 3*(6/7) = 3.4 2*(1/7) + 5*(6/7) = 4.6
3. Ranking Cosi > University Cafe
Restaurants Rating (0:bad - 5:Excelent)
Fridays Thai Food The Barns University Cafe Cosi
Don 5 1 6 6 2
Rachel 1 4 2 3 5
David 1 3 2 ??? ???
…

28
Collaborative Filtering: Drawback for sellers
Need real time recommendation Scale – millions of customers, thousands of items Works well only once a "critical mass" of preference has
been obtained Need a very large number of consumers to express their
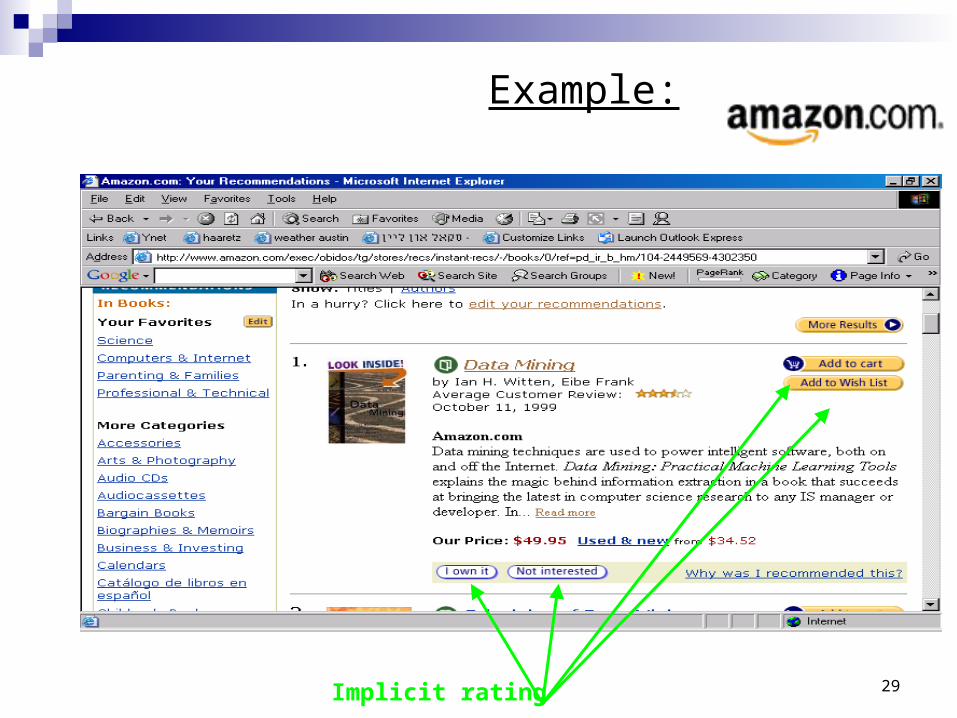
preferences about a relatively large number of products. Consumer input is difficult to get Solution: identify preferences that are implicit in people's actions
For example, people who order a book implicitly express their preference for the book they buy over other books
Works well but results are not as good as the results achieved using explicit ratings.
29
Example:
Implicit rating

Case Discussion Firefly
1. What are the pros and cons of collaborative filtering, content-based systems and rule-based systems for recommendations? What industries/applications is each technique good for?
2. How are implicit ratings learned? What are the limitations of implicit ratings? How can they be improved?
Polyphonic HMI1. How is the same technique used for music recommendation
and hit-song prediction?
2. How can Hit Song Science benefit the record labels, producers and the unsigned artists?
3. Can KNN be used for hit-song prediction? How?
General Discussion Question:1. How to evaluate a personalization system?
30




![Neural Nearest Neighbors Networks › paper › 7386-neural-nearest... · relaxations of the k-nearest neighbors classifier [13, 35, 41]. Note that the crucial difference to our](https://cdn.vdocuments.us/doc/165x107/5f224fd74b919f33c94c5845/neural-nearest-neighbors-networks-a-paper-a-7386-neural-nearest-relaxations.jpg)


