document de travail 2004-023 - fsa ulavaldisponible sur internet : available on internet disponible...
TRANSCRIPT

Publié par : Published by : Publicación de la :
Faculté des sciences de l’administration Université Laval Québec (Québec) Canada G1K 7P4 Tél. Ph. Tel. : (418) 656-3644 Fax : (418) 656-7047
Édition électronique : Electronic publishing : Edición electrónica :
Aline Guimont Vice-décanat - Recherche et affaires académiques Faculté des sciences de l’administration
Disponible sur Internet : Available on Internet Disponible por Internet :
http://rd.fsa.ulaval.ca/ctr_doc/default.asp [email protected]
DOCUMENT DE TRAVAIL 2004-023
MÉTHODES DE CLASSIFICATION: REVUE DE LA LITTÉRATURE, ESSAI DE CARACTÉRISATION ET DE
COMPARAISON Loubna BENABBOU Adel GUITOUNI Pascal LANG
Version originale : Original manuscript : Version original :
ISBN – 2-89524-213-5
Série électronique mise à jour : On-line publication updated : Seria electrónica, puesta al dia
10-2004

1
Méthodes de Classification : Revue de la littérature, Essai de Caractérisation et de
Comparaison*
Loubna Benabbou1, Adel Guitouni2, Pascal Lang1
1 : Département Opérations et Systèmes de Décision, Faculté des sciences de l’administration, Université Laval, Québec, Canada.
2 : Recherche et Développement pour la Défense Canada-Valcartier, Québec, Canada.
Résumé
La revue de la littérature ressort l’existence de plusieurs familles de méthodes de classification. Cette diversité est due essentiellement à la richesse des situations décisionnelles de classification. Dans la littérature, les revues de ces méthodes sont généralement relatives à une discipline scientifique en particulier. Dans ce travail, nous présentons une taxonomie des méthodes de classification, renvoyant à des paradigmes distincts : statistique, recherche opérationnelle, intelligence artificielle, aide multicritère à la décision. Sur la base des éléments dégagés de cette revue, nous proposons une synthèse des caractéristiques de ces méthodes et un essai de comparaison entre elles. Nous explicitons pour chaque catégorie de méthodes, les points forts, les points faibles, les conditions et les situations d’application.
1. Introduction La classification se fait naturellement depuis déjà bien longtemps pour comprendre, clarifier et communiquer notre vision du monde (par exemple les espèces animales, minérales ou végétales). Elle permet de reconnaître, de caractériser, d’organiser et de structurer des données. C’est un excellent moyen pour aboutir à une description utile des données et de ressortir certaines propriétés que possèdent les éléments de la même classe.
La classification a suscité l’intérêt de plusieurs domaines de recherche notamment en statistique, programmation mathématique, datamining, intelligence artificielle et aide multicritère à la décision. En statistique, la classification est considérée comme une technique de génération des hypothèses d’appartenance ou non des données aux classes. En data mining c’est un outil de découverte de connaissance qui permet d’ouvrir de nouveaux champs de recherche à explorer. L'action de classer est souvent associée à celle d'apprendre à classer, ce qui rend la classification le moyen d’apprentissage par excellence en intelligence artificielle. En aide multicritère à la décision, la classification est un outil de prise de décision, elle constitue à côté du choix et du rangement la troisième problématique de décision. * Ce travail a était financé conjointement par Recherche et Développement pour la Défense Canada-Valcartier et le Fonds Québécois de la Recherche sur la Société et la Culture.

2
Essayons de trouver une définition originale et intuitive à la classification, voyons d’abord comment le petit Larousse définit ce terme. Il s’agit d’une distribution par classes, par catégories, selon un certain ordre ou une certaine méthode. Dans la littérature, nous trouvons plusieurs définitions mais, à notre avis, elles sont plus relatives à un problème de classification en particulier. Nous retenons néanmoins la définition de Michie et al (1994), qui ont un point de vue axé sur l’apprentissage, qui nous semble la plus générale et la plus complète : la classification est l'action de regrouper en différentes catégories des objets ayant certains points communs ou faisant partie d'un même concept, on parle alors de problème de clustering ou de classification automatique ou l'action d'affecter des objets à des catégories prédéfinies, on parle dans ce cas de problème d'affectation et d'apprentissage supervisé.
Le champ d’application de la classification est très large. Elle traite une multitude de problèmes d’ordre intellectuel, économique ou commercial. Ces applications diffèrent selon l’approche utilisée : En programmation mathématique, le problème de classification est modélisé par un réseau ou par un programme mathématique à optimiser. Dans le domaine statistique, datamining et intelligence artificielle, la classification consiste à examiner des caractéristiques d’un élément nouvellement présenté afin de l’affecter à une classe d’un ensemble prédéfini. Dans le domaine de l’aide multicritère à la décision, la classification est basée sur les préférences du décideur considérant des catégories ordonnées ou non. On parle ici beaucoup plus de tri que de classification.
Tout au long de cette introduction, nous avons constaté la diversité des domaines de recherche qui se sont intéressés à la classification. Dans ce document, nous nous intéressons particulièrement à cette diversité. L’objectif de ce document est de présenter une revue, la plus exhaustive que possible, des différentes méthodes de la classification dans la littérature. L’analyse de cette revue nous permettra de proposer par la suite un essai de caractérisation, de description et de comparaison des différentes méthodes.
Dans ce rapport, nous allons présenter les deux principales catégories de méthodes de classification:
- Les méthodes de classification automatique: basées sur la notion d’apprentissage non supervisé. Ces méthodes peuvent être hiérarchiques ou non hiérarchiques.
- Les méthodes d’affectation ou les méthodes de classification basées sur la notion d’apprentissage supervisé. Ces méthodes peuvent être divisées à leur tour en trois groupes selon le type d’apprentissage : les méthodes d’apprentissage inductif, les méthodes d’apprentissage déductif et les méthodes d’affectation multicritère.
Dans la dernière partie de ce document, nous proposons une synthèse des caractéristiques des méthodes présentées dans les chapitres précédents et un essai de comparaison entre elles. Nous explicitons pour chaque catégorie de méthodes les points forts, les points faibles, les conditions et les cadres d’application.
2. Les méthodes de classification automatique «When the data have not been forced into clusters, the observer can assess better whether clusters exist» Cormack (1971). Comme leur nom l’indique, ces méthodes classent automatiquement les objets, elles les regroupent, en un nombre restreint de classes homogènes et séparées. Homogènes signifie que les éléments d’une classe sont les plus proches possibles les uns des autres. Séparées implique qu’il y a un maximum d’écart entre les classes. La proximité et l’écart ne sont pas nécessairement au sens de distance. L’homogénéité et la séparation entrent dans le cadre des principes de cohésion et d’isolation de Cormack (1971).

3
Au contraire des autres méthodes de classification où les classes sont obtenues par des procédures subjectives, les méthodes de classification automatiques déterminent leurs classes à l’aide d’algorithmes formalisés. On parle aussi de méthodes exploratoires, qui ne sont pas explicatives. Ces méthodes ont fait l’objet de plusieurs ouvrages : Benzecri (1973), Caillez et Pages (1976), Roux (1986), Celeux et al. (1989), dans (Belacel, 1999). Les méthodes de classification automatique ont apporté une aide précieuse, notamment par leurs applications en biologie, en médecine, en astronomie et en chimie.
La classification automatique fait appel à plusieurs disciplines scientifiques. Initialement, ce sont les statisticiens qui ont développé les premières méthodes. Par la suite, il y a eu l’implication de la recherche opérationnelle, notamment par la modélisation du problème de classification automatique par un graphe ou par un programme mathématique. Plus récemment, nous retrouvons les gens du Datamining qui se sont intéressés à la classification automatique.
Avant de présenter les différentes méthodes de classification, il est nécessaire de définir la notion de dissimilarité; nous avons essayé de la formuler de la manière la plus simple.
Définition : Une fonction de dissimilarité est une fonction réelle d(k,l) positive et symétrique, définie entre chaque paire d’objet k et l de l’échantillon d’étude, telle que : ∀ k, l :…N :
- d(k,l)≥ 0;
- d(k,k) = 0;
- d(k,l) = d(l,K).
La distance est un cas particulier de la fonction de dissimilarité, qui respecte l’inégalité triangulaire : ljkpour)l,j(d)j,k(d)l,k(d ≤≤+≤ . Dans sa revue des méthodes de classification, Cormak (1971) présente les différentes propriétés algébriques que doivent vérifier les fonctions de dissimilarité. Il propose aussi une revue de la littérature des différentes mesures de dissimilarité.
Les méthodes de la classification automatique sont classées selon l’approche en question. Cormack (1971) distingue entre trois familles de méthodes: la classification hiérarchique, le partitionnement et le groupement (Clumping). Quant à Gordon (1981) il rajoute trois autres catégories à la taxonomie de Cormack : la classification automatique sous contraintes, la classification automatique floue et les méthodes géométriques. Hansen et Jaumard (1997) définissent deux autres types d’algorithmes de classification : les sous ensembles, et le « Packing ».
Pour présenter les méthodes de la classification automatique, nous avons retenu les deux principales catégories : les méthodes de la classification hiérarchique et les méthodes de partitionnement. La classification hiérarchique peut être ascendante ou descendante, le nombre de classes n’est pas fixé au préalable. Quant au partitionnement, c’est une classification non hiérarchique en un nombre fixe de classes. Elle se distingue par une multitude d’algorithmes exacts et d’heuristiques.
2.1 Méthodes hiérarchiques La classification hiérarchique, consiste à effectuer une suite de regroupements en classes de moins en moins fines en agrégeant à chaque étape les objets ou les groupes d’objets les plus proches. Le nombre d’objets n’est pas fixé a priori mais, sera fixé a posteriori. Elle fournit ainsi un ensemble de partitions de l’ensemble d’objets (Celeux et al., 1989; Belacel, 1999). On distingue deux types de méthodes, les méthodes ascendantes (algorithmes agglomératifs) et les méthodes descendantes (algorithmes divisifs).

4
2.1.1 Classification hiérarchique ascendante : Ces méthodes sont les plus anciennes et les plus utilisées dans la classification automatique. Supposons que nous avons N objets à classer. Les algorithmes agglomératifs suivant cette approche, définissent d’abord une partition initiale en N classes unitaires. Par la suite, ils fusionnent successivement les classes jusqu'à ce que toutes les entités soient dans la même classe. Dans chaque étape de fusion des classes, le recalcule des dissimilarités entre les nouvelles classes est nécessaire. Le choix des classes se fait selon le critère qui caractérise la méthode.
Les méthodes suivant cette catégorie diffèrent selon le critère local choisi et selon la méthode de calcul des dissimilarités interclasses. Nous retrouvons notamment les méthodes issues de la théorie des graphes et les méthodes qui se basent sur la minimisation des carrés des erreurs. Dans les méthodes issues de la théorie des graphes, nous retrouvons la méthode du lien simple, du lien complet et du lien moyen. Quant à la deuxième catégorie, elle regroupe les méthodes de P-mediane, centroïd, la méthode de Ward et la méthode de la variance.
Étape 1. Déterminer toutes les dissimilarités inter-objets.
Étape2. Construire une classe à partir des deux plus proches objets ou classes (selon un critère local).
Étape3. Redéfinir les dissimilarités entre la nouvelle classe et les autres objets ou classes (toutes les autres dissimilarités ne changent pas).
Étape 4. Retour à l’étape 2 jusqu'à ce que tous les objets soient dans la même classe. Figure 2. 1 Algorithme agglomératif de la classification automatique (Murtag, 1983)
La formule combinatoire de Lance et William (1967) (Murtage, 1983) nous permet de redéfinir les différentes dissimilarités inter-objets de l’étape 3 de l’algorithme agglomératif (Figure 2.1). Soient i et j les deux objets fusionnés à l’étape 2. Alors la dissimilarité entre la nouvelle classe et n’importe quel autre objet k est donnée par :
|k)d(j,-k)d(i,|cj)bd(i,k)a(j)d(j,k)a(i)d(i, k) j,d(i +++=+ (2.1)
Les valeurs de a, b et c dépendent de la méthode de classification hiérarchique choisie.
2.1.2 Classification hiérarchique descendante : Dans le paragraphe précédent, nous avons vu que la classification hiérarchique ascendante, essaie d’optimiser un seul critère à la fois. Ceci engendre uniquement une séparation (méthode du lien simple) ou une homogénéité (méthode du lien complet) optimale des classes. Ce qui risque de donner naissance à l’effet de chaînage (deux entités très dissimilaires appartenants aux points extrêmes d’une longue chaîne, peuvent appartenir à la même classe) ou l’effet de dissection (deux entités très similaires peuvent être dans deux classes différentes). Pour palier à ces problèmes, nous retrouvons les algorithmes divisifs de la classification hiérarchique descendante. Ces méthodes ont eu moins de succès que les premières. Les algorithmes divisifs commencent par former une seule classe qui englobe tous les objets. Par la suite, ils choisissent une classe de la partition en cours selon un premier critère local. Ils procèdent ensuite à une bipartition successive selon un deuxième critère local des classes choisies. Cette bipartition continue jusqu'à ce que toutes les entités soient affectées à différentes classes.

5
Étape 1. Déterminer toutes les dissimilarités inter-objets.
Étape2. Choisir selon un critère local une classe.
Étape3. Partitionner la classe choisie en deux classes suivant un deuxième critère local.
Étape 4. Redéfinir les dissimilarités entre la nouvelle partition et les autres classes.
Étape 5. Retour à l’étape 2 jusqu’à ce que chaque objet soit dans une seule classe. Figure 2. 2 Algorithme divisif de la classification automatique.
Le premier critère n’est pas important, dans la mesure où il permet juste de donner l’ordre suivant lequel les classes doivent être partitionnées. La difficulté réside dans le critère de partitionnement. Le problème de la classification descendante revient donc à un problème de bipartition. Ce dernier peut être modélisé sous forme d’un graphe. Les objets à classer représentent les sommets, et les poids des arrêts sont les dissimilarités inter-objets. Trouver la bipartition optimale, revient donc à résoudre le problème de bicoloration du graphe. Le problème de bicoloration de graphe est un problème NP-dur. Guénohe (1989), Monma et Suri (1991) ont démontré que l’unique bicoloration de l’arbre partiel maximum d’un graphe, définit une bipartition avec un diamètre minimal (Hansen et Jaumard, 1997). Donc le problème de bipartition revient à déterminer l’arbre partiel maximum d’un graphe. Nous retrouvons dans la littératures plusieurs algorithme qui permettent de traiter ce probléme : Kruskal, Dijkstra.
Les méthodes suivant cette approche présentent l’inconvénient de ne produire que des bipartitions, c’est à dire uniquement deux classes. Aussi, dès que le nombre d’objets à classer est très important, le problème de l’arbre partiel maximum, devient très compliqué, ce qui entrave sa résolution.
Les méthodes hiérarchiques s’appliquent sur de petits échantillons (N<100). Cette restriction s’impose au niveau de l’interprétation des résultats. En effet, les méthodes hiérarchiques produisent une hiérarchie de partitions. Cette hiérarchie est d’autant plus grande que l’échantillon est important. Ceci complique l’interprétation de la quantité importante des partitions produites. D’autre part, à chaque étape, les groupes sont fusionnés ou divisés et ceci de façon définitive. Ceci élimine toute possibilité de retour en arrière ou d’amélioration du résultat de la classification. L’interprétation de la signification des classes est subjective. Les classes obtenues à l’aide du dendrogramme peuvent être expliquées de plusieurs façons. En général, cette explication est faite de la manière la plus cohérente possible avec les hypothèses fixées au départ sur la structure des données.
2.2 Partitionnement Les algorithmes divisifs et agglomératifs des méthodes hiérarchiques reflètent le processus naturel de l’évolution qui est le produit de séparation et de regroupement. La classification dans le domaine de la biologie, par exemple, correspond exactement au comportement de ce type d’algorithmes. Or, dans d’autres domaines, supposer qu’il y a uniquement des séparations et des regroupements n’est pas acceptable, voir même, dans certains cas, restreint. Il est plus intéressent d’être plus général pour traiter des problèmes de classification en gestion des opérations par exemple. Les méthodes de partitionnement sont plus générales que les méthodes hiérarchiques. Le principe de cette famille de méthodes, est de trouver une partition des objets qui optimise un critère additif donné. Cette partition est composée d’un nombre de classes fixé au préalable.
Du point de vue programmation mathématique, le problème de partitionnement se modélise par un programme mathématique. La fonction objectif représente le critère à optimiser. Quant aux contraintes, elles traduisent les règles de partitionnement à respecter. Les deux règles les plus

6
importantes dans le partitionnement sont relatives au nombre de classes et à l’appartenance unique d’un élément à une classe donnée.
Soit l’échantillon de N objets }O,....,O{O N1= , nous voulons trouver la partition optimale }C,....,C{P M1M = de M classes, sous le critère additif f . Soit J l’ensemble des indices de toutes les classes possibles. La modélisation mathématique de partitionnement de l’ensemble O en M classes se présente comme suit :
( )
=
∉
∈=
=∈
=
=
=
∑
∑
∑
∈
∈
∈
N.....1iCOsi0
COsi1a
J......1j},1,0{y
1ya
MySt
y)C(f)P(fOpt
P
ji
jiij
j
Jjjij
Jjj
JjjjM
(2.2)
Afin de résoudre le programme mathématique ( )P , les méthodes de partitionnement font appel à des algorithmes exacts et des heuristiques. La programmation mathématique est utilisée avec toutes ses branches en partitionnement : programmation dynamique, théorie des graphes, branch and bound, méthodes de coupe et génération de colonnes. La programmation dynamique est appliquée en partitionnement dans le cas où les objets sont définis sur une seule dimension. La théorie des graphes est appliquée, comme généralisation de la méthode du lien simple. Les algorithmes branch and bound ont été appliqués, avec un certain succès, pour plusieurs problèmes de partitionnement. L’application la plus concrète est celle de la méthode de génération de colonnes. En effet, l’algorithme exact pour les critères de la somme des carrés des erreurs avec la méthode de génération de colonnes de Hansen et Jaumard (1987) a fait ses preuves dans plusieurs applications.
Quant aux heuristiques, les méthodes les plus répandues de partitionnement sont celles qui visent à minimiser la somme des carrées des erreurs. Parmi ces méthodes, nous retenons : la méthode de leader, la méthode de k-means et la méthode des nuées dynamiques (Belacel, 1999). D’autres méta-heuristiques ont fait leurs preuves dans le partitionnement : recuit simulé, recherche taboue, algorithmes génétiques, variable neighborhood search (Hansen et Jaumard, 1997).
Les méthodes de partitionnement permettent de traiter rapidement de grands ensembles d’individus. Grâce à l’évolution de la puissance de calcul des ordinateurs et le développement de nouvelles techniques en programmation mathématique, nous arrivons à résoudre le problème mathématique de partitionnement avec de plus en plus de variables (objets). Ces méthodes produisent directement une partition en un nombre de classes fixé au départ. Les classes qui forment la partition finale sont mutuellement exclusives. Toutefois, les techniques de partitionnement présentent un problème au niveau du nombre de classes qui doit être fixé au départ. Si le nombre de classes n’est pas connu ou si ce nombre ne correspond pas à la configuration véritable de l’ensemble d’individus (d’où le risque d’obtenir des partitions de valeurs douteuses), il faut presque toujours tester diverses valeurs, ce qui augmente le temps de calcul. C’est la raison pour laquelle, lorsque le nombre des individus n’est pas trop élevé, on fait appel aux méthodes hiérarchiques.

7
2.4 Conclusion Dans la conclusion de ce chapitre, nous proposons de ressortir quelques caractéristiques qui nous permettront de mieux distinguer les méthodes et de les comparer par la suite entre elles. Nous avons retenu les indices suivants :
- Type de classification : partitionnement ou hiérarchique, ascendante ou descendante. - Nombre de classes : est-ce que le nombre de classe est connu au préalable ou non? - Nature des données : nous précisons l’échelle de mesure des données. - Nature de l’algorithme : quelle est la nature de l’algorithme? est-il divisif ou
agglomératif? c’est une heuristique ou un algorithme exact? - Type de traitement : c’est en fait le type de traitement que la méthode utilise pour
résoudre le problème de la classification. - Hypothèses sous-jacentes : ce sont les hypothèses mises de l’avant pour appliquer la
méthode. - Résultat escompté : obtient-on une partition ou plusieurs partitions? - Interprétation des résultats : Comment peut-on qualifier cette interprétation? Objective ou
subjective?
La lecture du tableau (2.1) nous montre la diversité de traitement de la classification automatique. Toutefois, cette diversité appartient principalement à deux disciplines scientifiques: la statistique et la recherche opérationnelle. L’exploitation des résultats du tableau fait ressortir plusieurs limitations de ces méthodes. Du point de vue nature des données, l’échelle de mesure doit être cardinale. Les adeptes de la classification automatique exigent un traitement de données au préalable pour pouvoir calculer les différentes dissimilarités avec des données cardinales. Les méthodes de classification hiérarchique sont adaptées pour les petits échantillons de données. En effet, ces méthodes produisent plusieurs niveaux de partitions avec plusieurs classes. L’interprétation des résultats est très difficile dans le cas de très grands ensembles de données.
Pour les méthodes de partitionnement, il faut fixer au préalable le nombre de classes. La fixation du nombre de classes ne se base sur aucune donnée au préalable. Ceci risque de fausser les résultats. Il existe certains indicateurs statistiques qui permettent d’interpréter les résultats. Mais cette interprétation demeure toujours subjective, dans la mesure où nous n’avons aucune information au préalable sur les données. Tableau 2. 1 Propriétés des méthodes de classification automatique
Ascendantes Descendantes Heuristiques Algorithmes exacts
Type de classification Hiérarchique ascendante Hiérarchique descendante Partitionnement Partitionnement
Nombre de classe Non connu Connu a priori Connu a priori
Nature des données Cardinales
Nature de l'algorithme Divisif Agglomératif Heuristiques Algorithmes exacts
Type de traitement Théorie des graphes et minimisation carrée des erreurs Bicoloration de graphe Minimisation
carrée des erreurs Programmation mathématique
Complexité Faible Élevé Élevé
Hypothèse sous-jacente Petit échantillon de données <100
Un grand échantillon de données Nombre de classes fixé au départ
Résultat escompté Hiérarchie de partitions une seule partition avec deux classes
Une seule partition avec le nombre de
classe fixé au préalable Interprétation des
résultats Subjective

8
Au niveau axiomatisation des méthodes, nous n’avons pas trouvé beaucoup de travaux dans la littérature. Nous retenons néanmoins, l’essai de Fisher et Van Ness (1971) et de Baulieu (1989). Fisher et Van Ness (1971) ont essayé de ressortir quelques propriétés qui permettent de guider le choix d’une méthode de classification automatique. Quant à Baulieu (1989), il s’est placé dans un cadre bien particulier de classification binaire (présence/absence) pour ressortir quelques postulats sur la fonction de dissimilarité.
3. Les méthodes d’affectation «There are many branches of learning theory that have not yet been analyzed and that are important both for understanding the phenomenon of learning and for practical applications. They are waiting for their researchers» Vladimir Vapnik
Comme leur nom l’indique, les méthodes d’affectation affectent les actions aux classes prédéfinies au préalable. Contrairement à la classification automatique, ces méthodes sont basées sur l’apprentissage supervisé. L’apprentissage supervisé consiste à établir des règles de classification à partir des expériences réussies dans le passé. Pour un problème de classification, un système d’apprentissage permet de construire une fonction de prise de décision (un classificateur) à partir des actions déjà classées (ensemble d’apprentissage). Dans l’entrée du système de classification, nous trouvons un ensemble d’exemples et à la sortie un classificateur h . L’échantillon est divisé en deux ensembles : un ensemble d’apprentissage S et un ensemble de test. Le système de classification est basé sur un algorithme d’apprentissage A tel que h)S(A = . L’ensemble de test permet d’évaluer l’algorithme d’apprentissage et de le valider.
Michie et al. (1994) distinguent deux raisonnements pour l'apprentissage. Le premier, le raisonnement inductif, du particulier au général, qui consiste à considérer un ensemble maximal de règles de classification, puis à réduire cet ensemble de règles à un sous-ensemble qui le résume au mieux. Le deuxième raisonnement est déductif, du général au particulier, il consiste à construire les règles une à une jusqu'à obtenir une bonne description de l'ensemble d'apprentissage. Pour présenter ces techniques, nous avons gardé les trois principales catégories pour traiter les problèmes de classification selon Weiss et Kulikowski (1991) :
- Les techniques statistiques, - Les réseaux de neurones, - Machine learning.
Les techniques statistiques regroupent une panoplie de méthodes. Nous présentons dans ce chapitre les techniques basées sur l’apprentissage bayesien, l’analyse discriminante et la méthode du k plus proche voisins. Dans la catégorie machine learning, nous présentons les arbres de décision, et les SVM (Support Vector Machine) comme une technique d’apprentissage par les noyaux. Pour les autres techniques de machine learning : algorithmes génétiques, apprentissage par renforcement, Set covering machine, apprentissage à base de règles, nous referons les lecteurs pour plus de détail aux livres de Weiss et Kulikowski (1991), Michie et al. (1994), Mitchell (1997) et Marchand et al. (2002). Toutes ces méthodes sont basées sur l’apprentissage inductif. Pour illustrer l’apprentissage déductif, nous présenterons à la fin de ce paragraphe l’affectation par système expert. Quant aux méthodes d’affectation multicritère, même si elles sont des méthodes de classification basées sur l’apprentissage supervisé, nous avons jugé qu’il est opportun de les mettre dans un autre chapitre.

9
3.1 Les techniques statistiques Les méthodes statistiques sont les plus anciennes techniques d’apprentissage pour la résolution des problèmes de classification. Elles sont issues de l'analyse des données et supposent l'existence d'un modèle probabiliste décrivant les données. L'objectif de ces méthodes est ainsi de caractériser ce modèle. La littérature nous offre une multitude de méthodes et d’applications statistiques (Duda and Hart, 1973; Fukunaga, 1972 dans Belacel, 1999). L’objectif de ce type de techniques est d’arriver à classer de nouveaux cas, en réduisant le taux d’erreur de classification. Selon Weiss et Kulikowski (1991), ces méthodes ont fait leurs preuves pour des données assez simples. Dans ce contexte, nous présentons les méthodes statistiques suivantes :
- L’apprentissage bayesien, - L’analyse discriminante, - La méthode du plus proche voisin.
3.1.1 L’apprentissage Bayesien : Comme son nom l’indique, l’apprentissage bayésien est basé sur le théorème de Bayes. Le problème de classification peut se traduire par la minimisation du taux d’erreur, ce qui peut être formulé mathématiquement en utilisant la règle de Bayes. Cependant, il y a quelques obstacles qui entravent l’application de cette méthode; les hypothèses du théorème de Bayes ne sont pas toujours vérifiées : l’indépendance des variables et la population doit être finie. Dans le cadre de l’apprentissage bayésien nous retrouvons plusieurs types de classificateurs : classificateur optimal de Bayes, classificateur Bayes naïf, classificateur de Gibs, réseaux bayésiens. Dans cette partie nous allons présenter le classificateur optimal de Bayes qui est la base des autres méthodes.
Classificateur optimal de Bayes. Si on veut classer un évènement ei alors il y a deux situations qui se présentent. La première si chaque occurrence de ei est de la même classe C, alors la réponse est la classe C. La deuxième, si les occurrences de l’évènement ei sont des classes différentes, alors la meilleure prédiction de classe est celle qui minimise le taux d’erreur, donc on doit choisir la classe qui apparaît le plus pour les différentes occurrences. On choisit la classe Ci pour l’évènement e si et seulement si :
jichaquepoureCPeCP ji ≠≥ )/()/( (3.1)
Avec P(C/e) est la probabilité d’une classe sachant un évènement. La formule de Bayes relie P(C/e) à P(e/C), la probabilité conditionnelle d’un évènement sachant la classe telle que :
)()()/()/(
ePCPCePeCP =
(3.2)
Ainsi la règle de la décision de classer l’événement e dans la classe Ci peut être formulée comme suit :
jichaquepourCPCePCPCeP jjii ≠≥ )()/()()/( (3.3)
Tout système qui classifie de nouvelles données suivant la règle de décision (3.3) est appelé classificateur optimal de Bayes. Ce classificateur maximise la probabilité qu’une nouvelle instance est correctement classifiée, pour un ensemble de données, en respectant la condition du théorème de Bayes et bien sûr des probabilités a priori des événements. Théoriquement parlant, aucun classificateur ne peut battre celui ci, d’où sa qualification de classificateur optimal.
Dans cette analyse bayesienne, la difficulté se situe au niveau de la détermination de la probabilité conditionnelle. Mathématiquement, l’estimation de cette probabilité est le centre de la

10
résolution de tout problème de classification. En théorie, l’application de cette méthode est très claire mais en pratique les valeurs des probabilités ne sont pas toujours faciles à estimer. Chaque méthode de classification qui est basée sur la minimisation du taux d’erreur peut être considérée comme un cas particulier de la règle de Bayes. Toutefois, des compromis sont nécessaires afin d’appliquer cette méthode (Weiss et Kulikowski, 1991).
En guise de généralisation du classificateur optimale de Bayes, nous retrouvons le classificateur Bayesien naïf qui simplifie l’hypothèse d’indépendance des données et qui peut traiter avec des données manquantes. Les réseaux bayesiens se basent aussi sur cette hypothèse simplifiée. Ils ont étaient largement utilisés en classification, toutefois, ils demeurent plus des outils de représentation et de modélisation que de résolution. L’autre forme de l’apprentissage bayésien est le classificateur de Gibs. Il consiste à tirer un classificateur d’un ensemble de classificateurs prédéfinis selon une distribution de probabilité et à classer une nouvelle instance selon le classificateur tiré (Mitchell, 1994).
3.1.2 L’analyse discriminante L’analyse discriminante est le fruit des travaux de Fisher depuis 1936. La littérature abonde d’ouvrages traitant cette approche : (Tomassone et al., 1988 ; Caleux, 1990 ; Celeux et al., 1994 ; Belacel, 1999). Le but des méthodes suivant cette approche, est de produire des décisions concernant l’appartenance ou non d’un objet à une classe en utilisant des fonctions discriminantes appelées également fonctions de décision. Dans cette partie, nous présentons les formes les plus utilisées de l’analyse discriminante : la discrimination linéaire et quadratique.
La discrimination linéaire. C’est la forme la plus simple des méthodes de cette catégorie. Elle présente l'avantage de pouvoir traiter des données de très grande taille. Le mot linéaire fait référence à la combinaison linéaire des évènements, hyperplans, qui va être utilisée afin de séparer entre les classes et de déterminer la classe d’un nouveau cas.
La construction de ces hyperplans de séparation peut être effectuée en utilisant plusieurs techniques, comme c’est le cas avec la méthode des moindres carrées et la méthode du maximum de vraisemblance. Les hyperplans sont construits de manière à minimiser la dispersion des points d'une même catégorie autour du centre de gravité de celle-ci. L'utilisation d'une distance est alors nécessaire pour mesurer cette dispersion. Intuitivement, nous pouvons qualifier la discrimination linéaire comme une fonction d’agrégation pondérée. Cette technique est considérée comme une méthode de classification très compacte. Le défi dans cette méthode consiste à déterminer les poids de la somme pondérée.
La discrimination quadratique. La discrimination quadratique est la généralisation de la discrimination linéaire. Au lieu que les classes soient séparées d’hyperplans, elles sont séparées généralement d’ellipsoïdes. On utilise dans ce cas plusieurs métriques (une par classe) pour mesurer la dispersion de chaque classe par rapport au centre de gravité (Henriet, 2000).
Le choix de la métrique n’est pas toujours évident. En effet, il faut choisir la métrique qui permet d’obtenir des classes où les points d’une même classe soient les moins dispersés possible autour du centre de gravité de la classe. Ces méthodes sont totalement compensatoires. Dans les deux cas, on constate l’utilisation de fonctions d’agrégation complète. Comme pour les autres méthodes statistiques, cette agrégation ne tient pas compte de l’hétérogénéité des données, ceci renforce le côté arbitraire de la méthode.
3.1.3 K plus proches voisins Weiss et Kulikowski (1991) font référence à la méthode de k plus proches voisins comme une technique d’apprentissage de classification dans le cadre des méthodes statistiques. Le principe de cette méthode consiste à chercher pour chaque action à classer un ensemble k d’actions de

11
l’ensemble d’apprentissage parmi les plus proches possibles de l’action. L’action est alors affectée à la classe majoritaire parmi ces k plus proches voisins.
La fixation du paramètre k est délicate, une valeur très faible va engendrer une forte sensibilité au bruit d’échantillonnage. La méthode va devenir faiblement robuste. Un k trop grand va engendrer un phénomène d’uniformisation des décisions. La plupart des actions vont être affectées à la classe la plus représentée. Pour remédier à ce problème, il faut tester plusieurs valeurs de k et de choisir le k optimal : k* qui minimise le taux d’erreur de classification (Henriet, 2000).
Le choix de la classe majoritaire entre les classes des voisins peut poser des problèmes dans le cas où l’action à classer se trouve à la frontière de plusieurs classes. Pour remédier à ce problème, on donne des poids aux voisins. Ce poids est généralement proportionnel à l’inverse du carré de la distance du voisin par rapport à l’action à classer. Une généralisation de la méthode a été proposée pour traiter le cas d’appartenance floue à des catégories. Cette extension floue de la méthode permet de prendre en compte la distance comme une valeur qui n’est plus uniquement ordinale (Henriet, 2000).
3.2 Les réseaux de neurones Les réseaux de neurones sont nés à partir de plusieurs sources. La fascination des scientifiques par la compréhension et la simulation du cerveau humain et la reproduction de la capacité humaine de compréhension et d’apprentissage. Le fonctionnement d’un réseau de neurones est inspiré de celui du cerveau humain. Il reçoit des impulsions, qui sont traitées, et en sortie d’autres impulsions sont émises pour activer les muscles. Un réseau de neurones s’exprime sous forme d’un graphe composé de trois éléments : l’architecture, la fonction de transfert et la règle d’apprentissage (figure 3.1).
L’architecture a trait, d’une part, à la structure du réseau en ce qui concerne le nombre et la disposition des neurones et, d’autre part, aux caractéristiques (pondération et direction) des arcs du réseau, aux couches d’entrées, de sorties et intermédiaires. Le nombre de neurones des différentes couches dépend du contexte d’application. Par ailleurs, la détermination du nombre de neurones à y associer demeure dans la plupart du temps arbitraire. En général, les poids initiaux des arcs sont déterminés aléatoirement et les valeurs sont modifiées par le processus d’apprentissage.
La fonction de transfert traduit le niveau d’activation d’un neurone en un état. Le niveau d’activation d’un neurone est obtenu en cumulant l’état de l’ensemble des entrées qui agissent sur lui. Par la suite, la fonction de transfert transforme le niveau d’activation en une valeur binaire ou continue, identifiant ainsi l’état du neurone. Les trois fonctions de transfert les plus utilisées sont : la fonction saut (avec ou sans seuil), la fonction linéaire (avec ou sans seuil) et la fonction sigmoïde (figure 3.1).
La règle d’apprentissage a trait au processus d’ajustement des poids associés aux arcs lorsque le réseau est en situation d’apprentissage. La réduction de l’erreur entre la valeur de sortie du réseau et la valeur initiale dans l’ensemble d’apprentissage permet de déterminer les paramètres (poids) du réseau. Il existe une variété de réseaux de neurones à apprentissage non supervisé. Ces réseaux sont capables de mémoriser, ils raisonnent par analogie avec ce qu’ils ont effectué. Pour ce type d’apprentissage, on présente une entrée sans aucune sortie et on laisse le réseau évoluer jusqu'à ce qu’il se stabilise.
Il existe différents types de réseaux, selon le nombre de couches, la fonction de transfert ou l’architecture elle-même du réseau : Perceptron, Adaline et le réseau de rétropropagation (Weiss et Kulikowski, 1991).

12
Figure 3. 1 Représentation d’un réseau de neurones avec une seule couche.
Les réseaux de neurones sont souples, ils sont capables de traiter une gamme très étendue de problèmes. Leur résultat peut être une prédiction, une classification ou encore une analyse de clusters. Le degré de résolution est assez élevé. Ils donnent de bons résultats, même dans des domaines complexes; ils sont beaucoup plus puissants que les statistiques ou les arbres de décision. Les techniques des réseaux de neurones s’adaptent facilement avec plusieurs types de variables et ils sont intégrés dans plusieurs supports informatiques (4Thought, Saxon, Neural connection, Clementine, Intelligent Miner, SAS, etc.).
Les réseaux de neurones ont des problèmes au niveau du codage des entrées. Toutes les entrées doivent se trouver dans un intervalle défini, en général, entre 0 et 1. Ce qui entraîne des transformations et risquent de fausser les résultats. La lisibilité au niveau des résultats n’est pas satisfaisante dans la mesure où l’on ne peut avoir accès à des explications claires des résultats obtenus. Pour assurer de bons résultats, le nombre d’exemples doit être très grand puisqu’il tient compte du nombre d’entrées, du nombre de couches et du taux de connexion. Au niveau de la performance, le réseau peut paraître optimal d’une façon globale, mais il n’est pas toujours la meilleure solution. Enfin le nombre de calculs à effectuer pour définir un réseau optimal peut être très consommateur de puissance, ce qui peut donner de mauvaises performances à cette technique.
3.3 Les techniques du machine learning 3.3.1 Les arbres de décision Les arbres de décision ont pour objectif la classification et la prédiction. Leur fonctionnement est basé sur un enchaînement hiérarchique de règles exprimées en langage courant. Un arbre de décision est composé d’un nœud racine par lequel entrent les données, de nœuds feuilles qui correspondent à un classement de questions et de réponses qui conditionnent la question suivante.
La mise en place d’un arbre de décision consiste à préparer les données ; puis, à créer et valider l’arborescence. Dans un premier temps, Il faut définir la nature, le format des variables et leur méthode de traitement. Ces variables peuvent être non ordonnées ou encore continues. Dans le cas de l’existence d’une base de règles simple et limitée, la construction de l’arbre se fait en interaction avec le décideur, en validant les arborescences une à la fois jusqu'à la détermination de l’affectation. C’est un processus interactif d’induction de règles qui permet d’aboutir à une affectation bien justifiée. Mais, en général la création et la validation de l’arborescence se passe selon l’algorithme de calcul choisi. Il existe différents algorithmes développés pour appliquer cette technique : CART, C4.5 et CHAID. Un autre critère de segmentation est l'entropie star qui est une généralisation floue de l'entropie de Shannon. L'utilisation de ce critère permet la
X1
X2
X3
XL
∑
∑
∑
f
f
f
∑
Y1
Y2
YK
Sortie
r(k,l) r’(k)
δ1
δ2
δK
Couche Couche cachée Couche de sortie

13
construction d'arbre de décision flou par une méthode dérivée de C4.5. L'affectation à une catégorie est alors calculée à l'aide d'une probabilité conditionnelle floue définie au niveau de chaque branche de l'arbre (Bouchon-Meunier et al., 1996; Henriet, 2000).
Les avantages procurés par les méthodes utilisant l’arbre de décision sont leur rapidité et, surtout, leur facilité quant à l’interprétation des règles de décision. La clarté des règles de décision facilite le dialogue homme-machine. Ce sont des méthodes non paramétriques qui ne font aucune hypothèse sur les données. Ils peuvent traiter des ensembles d’apprentissage avec des données manquantes. Cependant, Les arbres de décision ont une faiblesse au niveau de la performance et le coût d’apprentissage. Ils deviennent peu performants et très complexes lorsque le nombre d’attributs et de classes augmente. En effet, ils risquent de devenir trop détaillés, ce qui leur fait perdre un peu de leur lisibilité ou encore d’aboutir à de mauvais classements et d’augmenter le coût d’apprentissage. D’autre part, les algorithmes d’arbres de décision les plus utilisés en classification, font appel aux probabilités a priori et au coût d’une erreur de classification.
3.3.2 Apprentissage par les noyaux Ce type d’apprentissage est parfaitement adapté pour les problèmes de classification. L’objectif des techniques d’apprentissage avec les noyaux, est de réduire la complexité des algorithmes d’apprentissage. Cette réduction se passe via la minimisation des nombres d’opération et par la suite du temps de calcul. Elle consiste à introduire les noyaux qui permettent de réduire le nombre d’opérations, notamment au niveau du produit scalaire dans le calcul des distances, quand nous avons un vecteur d’entrée de dimension assez importante.
Afin de formuler le problème de classification, nous introduisons les fonctions paramétriques qui permettent de transformer chaque cas (vecteur d’entrée dans le système) χ∈x en un nombre réel positif. La fonction fi va exprimer notre croyance que x correspond à la sortie réelle dans l’ensemble d’apprentissage. Pour simplifier les calculs, cette fonction doit être linéaire :
j
N
1jji x.w)x(f ∑
=
= (3.4)
Pour déterminer la valeur de chaque if , il faut trouver la valeur du vecteur des paramètres w .
Soit κ∈ΦΦΦ=Φ ),.....,,( 21 n un vecteur de caractéristiques qui permet de transformer chaque vecteur d’entrée x de dimension N en un nouveau vecteur Φ (x) avec une dimension plus faible de dimension n<N. Donc, nous effectuons un changement de variable avec un changement de repère.
Le vecteur de paramètres w peut s’exprimer sous forme d’une combinaison linéaire des vecteurs caractéristiques de l’ensemble d’apprentissage de dimension m )x,....,x,x( m21 :
)x(wm
1iii∑
=
φα= (3.5)
La fonction f peut être exprimée sous forme d’une combinaison linéaire de produit scalaire dans l’espace des caractéristiques Φ .
∑∑ ∑== =
α=φφα=m
1iiij
m
1i
n
1jiji )x,x(k)x().x()x(f (3.6)

14
Donc, nous n’avons plus besoin de calculer le produit scalaire )'x().x( φφ , Il suffit de calculer uniquement )'x,x(k la fonction k appelée Noyau. La fonction linéaire f est appelée classificateur noyau, elle a comme paramètre nℜ∈α .
De manière générale, la technique du noyau consiste à choisir d’abord un noyau )'x,x(k . Par la suite, il faut utiliser un algorithme d’apprentissage (comme le plus proche voisin, ou le perceptron dual), sur un échantillon d’apprentissage de m exemples χ : )x,....,x,x( m21 , pour se construire un classificateur h dont la valeur de sortie ,x),x(h χ∈∀ est donnée par :
∑=
α=m
1iii )x,x(k)x(h (3.7)
Ce classificateur est un classificateur linéaire dans un espace de caractéristiques κ si et seulement si il existe un φ tel que :
∑∞
=
φφ=φφ=1i
ii )'x()x()'x().x()'x,x(k (3.8)
La condition (3.8) s’appelle la condition de Mercer, et le noyau qui respecte cette condition est appelé noyau de Mercer.
Ainsi, l’introduction du noyau comme une fonction symétrique facilement calculable entre deux éléments, nous permet d’éliminer tous les calculs relatifs aux produits scalaires entre les éléments. Ce produit scalaire se retrouve dans toutes les méthodes qui utilisent les distances. D’autre part, le passage du vecteur simple x aux vecteurs de caractéristiques Φ permet de passer d’un classificateur non linéaire dans l’espace d’entrée à un classificateur linéaire dans l’espace des caractéristiques, dans le cas où le noyau choisi satisfait la condition de Mercer. L’objectif de réduire la complexité de l’algorithme doit être atteint tout en assurant la performance de l’algorithme. Cette performance se mesure en terme de minimisation des erreurs de la classification de l’ensemble d’apprentissage. Ainsi, les techniques d’apprentissage par noyau, essayent de minimiser la complexité des algorithmes d’apprentissage et d’augmenter la performance du classificateur résultant. Dans cette partie, nous allons présenter la méthode Support Vector Machine, comme une application directe de l’apprentissage par noyaux.
Support Vector Machine. Nous considérons ici, le cas de la classification binaire (deux classes). Soit S l’échantillon d’apprentissage composé de vecteurs d’entrée xi. La classification de ces vecteurs, est connue au préalable. Elle est représentée par le vecteur de sortie yi={-1,1}. Donc, il suffit de connaître le signe du classificateur pour déterminer la classe de l’exemple. Si S est de dimension m, alors le classificateur binaire h dont la valeur de sortie ,x),x(h χ∈∀ est donnée par :
))x,x(kysgn()x(h m
1iiii∑
=
α= (3.9)
Ayant choisi un noyau de Mercer, l’algorithme d’apprentissage pour les SVMs consiste à trouver l’hyperplan de marge géométrique maximale qui sépare les données. Vapnick (1995) a été le premier à avoir introduit les notions d’hyperplan dans les algorithmes vecteurs de support (Herbrich, 2002). Pour déterminer l’équation de l’hyperplan, on modélise le problème sous forme d’un programme mathématique qui maximise la marge géométrique entre les données, tout en tenant compte de la nécessité de la bonne classification de l’ensemble d’apprentissage.

15
L’efficacité de l’algorithme SVM est due au fait qu’il combine deux idées pertinentes. La première est le changement de repère et des variables d’entrée vers un autre espace de caractéristiques. Ce double changement permet de simplifier la construction de classificateur non linéaire en utilisant uniquement les hyperplans dans l’espace des caractéristiques. L’idée seconde est de construire des hyperplans de séparation, dans l’espace des caractéristiques avec la marge géométrique la plus large possible (Vapnik, 1998; Cristianini and Shawe-Taylor, 2000; Marchand et al., 2002). D’un autre côté, l’approche des SVM se base sur des fondements statistiques, une théorie bien enracinée dans le temps, qui arrive à justifier aisément ses propos.
Les SVM sont en pleine expansion ces dernières années. Nous retrouvons plusieurs supports informatiques conviviaux sur le marché qui permettent l’utilisation de cette méthode. Pour intégrer le cas de traitement de données dans un contexte d’incertitude, il existe un essai de traitement flou de la marge géométrique. Cependant, au niveau de la résolution du programme mathématique il y a encore des améliorations à apporter. Il serait profitable, de développer des heuristiques ou d’autres techniques d’optimisation mathématique pour résoudre le problème. D’un autre côté, les SVMs présentés traitent la classification binaire. Dans le cas multi-classe (n>2), Vapnick (1998) a proposé de construire n classificateurs binaires. Chaque classificateur discrimine à chaque fois une classe des autres. Par la suite, on construit le classificateur de n-classes en choisissant la classe qui correspond à la valeur maximale des classificateurs. Il y’a d’autres travaux, pour le traitement du passage du mono-classe ou multi-classe (V.Blanz, Vapnick, Later, 1995; Vapnick, 1998). Toutefois cette discrimination n’est pas toujours optimale, ce qui peut donner de mauvaises performances dans le cas multiclasse.
3.4 Affectation déductive 3.4.1 Système expert Contrairement aux méthodes précédentes basées sur le raisonnement inductif, l’affectation par système expert utilise un raisonnement analytique avec des inférences déductives. On essaie par cette méthode de transformer les connaissances sous la forme désirée par l’utilisateur. Weiss et Kulikowski (1991) ont définit le système expert comme étant un modèle informatique qui reproduit le raisonnement et les conclusions d’un expert humain face au même problème. Les connaissances sont représentées par une base de règles et une base de faits. Les règles peuvent être interprétées comme des conditions pour déclencher une action donnée. Ces règles sont déterminées par une expertise et non par des exemples comme c’est le cas dans les arbres de décision. La base de fait contient des assertions, elle représente une connaissance relevant du cas particulier de l’individu à traiter. Il arrive que plusieurs règles soient simultanément applicables à un état donné de la base de faits, il faut donc choisir. Ce choix est réalisé par un module particulier du système expert. Ce module doit aussi savoir reconnaître quand il faut arrêter le processus. On définit pour cela une condition d’arrêt. Cette partie du système expert s’appelle la structure de contrôle (Lévine et Pomerol, 1990; Belacel, 1999).
L’affectation des individus aux différentes classes se fait à l’aide de la base de règles, le système cherche l’ensemble des règles applicables en effectuant un choix, puis il applique la règle choisie et recommence le cycle. Le processus s’arrête lorsque le but est atteint ou lorsqu’il n’y a plus de règle applicable. Ce traitement est appelé moteur d’inférence. Il n’est pas toujours évident pour l’expert d’exprimer sa connaissance, ce qui constitue l’un des inconvénients de ces systèmes. Notons aussi que le nombre de règles est énorme pour la plupart des applications pratiques, et les variables doivent être qualitatives. Toutefois, Les systèmes experts présentent l’avantage d’exprimer des connaissances certaines et précises.

16
3.5 Conclusion Les méthodes de classification basées sur l’apprentissage supervisé sont les méthodes les plus étudiées et les plus utilisées dans la littérature. Grâce à leur connexion aux statistiques et à l’intelligence artificielle, ces méthodes ont connu beaucoup d’essor dans le passé, avec la statistique, et dans les dernières années avec le datamining et l’intelligence artificielle. L’analyse des différentes méthodes présentées dans ce chapitre, nous a permis de ressortir quelques indicateurs descriptifs des méthodes d’affectation (Tableau 3.1).
La lecture du tableau 3.1 nous montre que les méthodes d’affectation sont issues principalement de la statistique et de l’intelligence artificielle. Nous retrouvons plusieurs niveaux d’exigences informationnelles sur les données. Si l’apprentissage bayésien exige que les données suivent une certaine distribution de probabilités et soient indépendantes alors le système expert nécessite l’existence de base de règles afin de pouvoir les inférer pour déterminer la classification des données. Outre les arbres de décision et les méthodes d’affectation déductive, les données doivent être cardinales afin de pouvoir appliquer les autres méthodes. Notons que ces méthodes sont totalement compensatoires, à l’exception des arbres de décision, aucune attention n’est portée à la possibilité de critères hétérogènes ou conflictuels. Au niveau du caractère explicatif, nous retrouvons plusieurs degrés d’explication : une absence complète avec la structure de boite noire des réseaux de neurones, un caractère explicatif faible ou fort des autres méthodes.
4. Les méthodes d’affectation multicritère Dans ce chapitre, nous allons aborder la classification du point de vue aide multicritère à la décision. La classification en aide multicritère à la décision se situe dans le cadre de la problématique de tri. La problématique de tri consiste à affecter les actions à des catégories caractérisées par des actions de référence. B. Roy (1985) définit cette problématique par : « Elle consiste à poser le problème en terme de tri des actions par catégorie, celles-ci étant conçues relativement à la suite à donner aux actions qu'elles sont destinées à recevoir, c'est-à-dire à orienter l'investigation vers une mise en évidence d'une affectation des actions de A à ces catégories en fonction de normes portant sur la valeur intrinsèque de ces actions et ce compte tenu du caractère révisable et/ou transitoire de A; cette problématique prépare une forme de prescription ou de simple participation» (Roy et Bouyssou, 1993).
Contrairement aux autres approches, l’aide multicritère à la décision ne cherche pas uniquement à développer des méthodes automatiques pour analyser les données afin de les classer. Cette branche de la science a pour objectif de construire une méthodologie de modélisation de préférence efficiente, ce qui permet de tenir compte des préférences du décideur dans le développement d’un modèle d’affectation (Doumpos et Zopounidis, 2002). Ainsi, l’objectif des méthodes d’affectation multicritère n’est pas de décrire au mieux les données, mais de respecter un ensemble de préférences qui auront été élicitées auparavant (Henriet, 2000).
Bana e Costa (1992) distingue entre deux situations de la problématique de tri (Léger et Martel, 2002) :
- Problématique du tri ordinal. Les catégories sont ordonnées, elles sont caractérisées par des actions de référence (profils) limites. Ces profils limites définissent les frontières de la catégorie. Une action est affectée à une catégorie si elle est jugée entre les frontières de la catégorie.
- Problématique du tri nominal. Les catégories sont non ordonnées, elles sont caractérisées par des actions de référence centrales. Une action est affectée à une catégorie, si elle est jugée semblable à au moins une action du profil central.

17
Tableau 3. 1 Propriétés des méthodes d’affectation
* N/a ne s’applique pas
Propriétés Apprentissage bayésien
Analyse discriminante KPPV réseaux de
neurone Arbre de décision SVM système expert
Type d'apprentissage Inductif Déductif
Nombre de classes
Nombre limité de classe Quelconque Quelconque Quelconque Nombre limité de
classes 2 Quelconque
Affectation Nette Nette Nette Nette Nette ou floue Nette Nette
Nature des données Cardinale Cardinale Cardinale Cardinale Cardinale
Ordinale Cardinale Cardinale Ordinale
Hypothèses sous-jacentes
- Indépendance des variables - Probabilité a priori -coût mauvaise classification
-Coût mauvaise classification
- Coût mauvaise classification
- Codage des données à l'entrée - Très grand échantillon d’apprentissage
- Base de règles ou - Distribution de probabilité a priori - Coût mauvaise classification
- Distribution de probabilité
-Indépendance des données
Existence de base de
connaissance
Nature de l'algorithme
Minimisation des erreurs Somme pondérée Minimisation des
distances Fonction de
transfert
Induction des règles ou probabilité
conditionnelle
Maximisation de la marge géométrique
Construction base de règles
Type de traitement Statistique Réseaux de
neurones Machine learning Intelligence artificielle
Niveau de compensation Totale Totale Totale Totale Partielle Totale N/a*
Caractère explicatif Faible Faible Fort Absent Fort Faible Fort
Utilisation de distance Non Oui Oui Non Non Oui N/a
Utilisation de distribution probabilité
Oui Non Non Non Oui Non N/a

18
En aide multicritère à la décision, Roy et Bouyssou (1993) distinguent entre trois approches opérationnelles : i) l’approche du critère unique de synthèse, ii) l’approche de surclassement de synthèse et iii) l’approche du jugement local interactif. L’approche du critère unique de synthèse, attribuée à l’école anglo-saxonne, consiste à déterminer une fonction de valeur ou d’utilité qui représente les préférences du décideur. Le concept de surclassement de synthèse, attribué à l’école francophone, se base sur l’introduction de la relation de surclassement qui permet de juger deux actions lors de la comparaison par paire. L’approche du jugement local interactif consiste à progresser avec le décideur sur la base d’alternance entre étapes de calculs et étapes de dialogue. Dans le cadre de ce document, nous nous intéressons aux méthodes d’affectation multicritère discrètes représentées par les deux premières approches : critère unique de synthèse et surclassement de synthèse.
4.1 Approche du critère unique de synthèse 4.1.1 UTADIS : Utilités Additives Discriminantes La méthode UTADIS a été développée initialement par Jacquet-Lagrèze en 1995, et améliorée par Doumpos et Zopoundis en 1999. UTADIS est une méthode de tri ordinal qui fait appel à l’agrégation par fonction d’utilité pour classer les actions. Elle établit un modèle global d’utilité additive pour classer un ensemble d’alternatives dans des classes prédéfinies avec un minimum d’erreur. Les préférences du décideur doivent être des fonctions monotones sous l’échelle d’évaluation des critères.
Les seuils d’utilité ont étaient introduits pour décider de l’affectation des actions aux classes selon leur utilité globale. L’objectif d’ UTADIS est de déterminer les utilités partielles et les seuils d’utilité en minimisant les erreurs de classification entre les classes déterminées par la méthode et celles données par le décideur. Ce problème a était modélisé sous forme de programme mathématique linéaire.
UTADIS est accompagnée en général d’une analyse post-optimale. On y analyse la sensibilité des utilités partielles. Ceci permet d’avoir une idée de la sensibilité des seuils d’utilité. L’autre version de la méthode, UTADIS I, intègre la notion de distance par rapport aux classes correctes dans sa fonction objectif. Ces méthodes ont eu plusieurs applications, plus particulièrement en finance. UTADIS est disponible sur PREFDIS, un DSS (Decision Support System) développé par Doumpos et Zopounidis (2000, 2002).
La méthode UTADIS, repose sur la construction de la fonction d’utilité, ce qui lui assure une forte axiomatisation. En effet, la fonction d’utilité, ou de valeur, suppose que les préférences vérifient les axiomes de Von-Neuman Morgensterm (existence d’un ordre complet, transitivité, continuité, réduction des loteries composées, substitution). Cette approche exclut toute incomparabilité et fournit un résultat très intéressent mais qui ne reflète pas réellement les préférences du décideur. Dans la méthode UTADIS, tous les critères sont mesurés par des échelles cardinales, une telle échelle ne reflète pas toujours la réalité des données. L’application d’UTADIS est basée sur le principe d’agrégation complète. Une agrégation qui n’est pas toujours justifiée dans le cas de plusieurs points de vue hétérogènes et conflictuels. UTADIS exige la monotonie des fonctions des préférences du décideur. Une hypothèse mathématique très forte, qui permet de manipuler facilement les fonctions d’utilités partielles, au prix de la considération des préférences réelles du décideur convenablement raisonnées.

19
4.2 Approche de surclassement de synthèse
4.2.1 Procédure Trichotomique de segmentation Les travaux de Roy et de Moscarola (1977) ont été à l’origine de cette méthode. C’est une procédure de choix dans laquelle on essaie d’affecter les actions à trois catégories selon les recommandations qu’on pourrait donner à un décideur. Ainsi, les actions ayant des raisons suffisamment importantes pour être recommandées à un décideur sont affectées à la catégorie C1, celles qui ont des raisons importantes pour ne pas être recommandées au décideur vont être affectées à la catégorie C3, et les dernières qu’on ne peut affecter ni à C1 ni à C3 vont être affectées à la catégorie C2. La difficulté d’affecter des actions à C1 et à C3 peut être à cause soit de la mauvaise connaissance, soit de la mauvaise détermination des performances des actions (Belacel, 1999).
Cette méthode fait appel à une relation de surclassement floue. Elle va prendre des valeurs dans l’intervalle [0,1]. 1 correspond à un surclassement certain et 0 à une absence totale de surclassement. Cette relation floue fait appel aux niveaux de coupe qui sont fixés par le décideur.
Le principe de fonctionnement de cette procédure est d’établir des profils limites B={b1,…..,bl} et C={c1,……..,ck} qui sont respectivement les bornes inférieures de C1 et supérieures de C3 puis de déterminer les degrés de surclassement, S, de x avec les profils B et C. On note :
)}c)/cc{S(x,maxc*)S(x,
x),S(cmaxx)S(c,
)}bx)/b,{S(bmaxx)S(b*,
)bS(x,maxb)S(x,
ii
k
1i
i
k
1i
ii
l
1i
i
l
1i
≠=
=
≠=
=
=
=
=
=
(4.1)
Les actions sont affectées selon le résultat de la comparaison de chaque degré de surclassement avec les seuils fixés au préalable pour chaque classe.
4.2.2 nTOMIC La procédure nTOMIC permet de classer des actions suivant des catégories ordonnées. Issue des travaux de Ostanello et Massaglia (1991), cette méthode est basée sur l’utilisation de deux profils fictifs b et c qui n’ont pas de signification réelle en terme d’actions, mais ils correspondent respectivement à une action jugée comme bonne et une autre comme mauvaise sur tous les critères. Pour faire face au manque d’information et à la mauvaise détermination des performances, cette procédure introduit des seuils de discrimination s et d’indifférence q (Belacel, 1999).
À chaque performance des profils pour chaque critère, on trouve un seuil d’indifférence et un seuil de discrimination. À partir des seuils, on définit deux sous ensembles goodness, respectivement badness qui correspondent au sous ensemble flou de critères qui confirment que l’action est bonne, respectivement mauvaise. L’appartenance d’un critère donné à ces sous ensembles est déterminée par l’indice de goodness dj(x) et de badness Dj(x); leurs valeurs sont calculées à partir de l’évaluation de l’action x sur le critère j suivant la courbe de la figure (4.1) :

20
Figure 4. 1 Fonctions de goodness et de badness dans nTOMIC
Pour obtenir des indices globaux sur tous les critères de badness et de goodness, deux approches d’agrégation ont été proposées : une compensatoire et une autre non compensatoire. La fonction d’affectation est basée uniquement sur les indices globaux et sur les seuils. Les catégories sont définies par une partition du plan (d,D), en plusieurs régions allant de bon jusqu’au mauvais.
4.2.3 Electre Tri Due à Yu (1992), Electre tri est une méthode multicritère d’affectation à des catégories complètement ordonnées. Chaque catégorie est représentée par un profil limite supérieur et inférieur. Pour chaque action de référence bi, on connaît son seuil d’indifférence, de préférence pj et qj et de veto vj pour chaque critère. Electre tri se déroule en deux étapes principales. La première consiste à construire la relation de surclassement valuée et la deuxième est la procédure d’affectation.
La construction de la relation de surclassement se base sur les notions de concordance et de discordance. L’indice de concordance global C(a, bh) pour chaque action exprime dans quelle mesure les performances de a et de b sur tous les critères sont en concordance avec « a surclasse b». Il est calculé à partir de l’indice de concordance partiel Cj(a,bh). Quant à l’indice de discordance partiel, il exprime dans quelle mesure le critère en question s’oppose à la proposition « a surclasse b».
Les degrés de crédibilité entre chaque action et l’action de référence ( )a,b(),b,a( is
is σσ ) sont
calculés à partir des indices de concordance globaux et de discordance. ce degré de crédibilité représente une relation de surclassement floue. Elle est transformée par la suite en relation nette en utilisant une valeur de coupe λ .
La deuxième étape est la procédure d’affectation. Cette affectation est le résultat du jumelage de deux procédures. la première conduit à une affectation pessimiste, la seconde conduit à une affectation optimiste. Ce sont deux procédures de filtrage respectivement conjonctif et disjonctif (Roy et Bouyssou, 1993). L’utilisation de ces deux procédures permet de gérer les situations d’incomparabilité. Ainsi, on aura deux attitudes vis à vis de l’incomparabilité. Une attitude pessimiste qui consiste à affecter l’action à la plus mauvaise catégorie dont la borne supérieure est incomparable, et une attitude optimiste affecte l’action à la meilleure des catégories dont la borne inférieure est incomparable.
4.2.4 Filtrage Flou Perny a introduit une approche générale avec indifférence floue et une relation de préférence stricte construite en utilisant le principe de concordance et de non discordance. L’idée de base derrière sa méthode est le filtrage flou. Il définit le filtrage des actions comme étant la
Dj(x) dj(x)
bj bj- s-j cj+ s+
j cj+ q+j cj bj- q-
1

21
comparaison des actions à des points de référence afin de décider à quelle catégorie (classe) elles vont appartenir.
Il considère deux types de filtrage:
- Filtrage flou par préférence stricte (FFP): La règle d’affectation consiste à tester quant est-ce qu’une action est préférée ou non à un point de référence qui reflète la limite inférieure de la catégorie.
- Filtrage par indifférence (FFI) : Dans ce cas, la règle d’affectation consiste à tester quand est-ce qu’une action est indifférente ou non à un point de référence qui représente un prototype de la catégorie.
Perny (1993) a largement étudié les méthodes de rangement basées sur des mécanismes d’agrégation des relations de préférences floues. En 1998, il a proposé la méthode FFP qui, contrairement à Electre Tri, utilise une relation de préférence floue. Cette méthode traite la problématique du tri ordinal et construit une relation de préférence floue binaire valuée dans [0,1]. Les catégories sont supposées ordonnées en ordre décroissant et chaque catégorie est représentée par deux frontières supérieure et inférieure Yk et Yk-1, en supposant que la frontière supérieure d’une classe est la frontière inférieure de la classe qui vient après. L’action x est affectée à la catégorie Ct si et seulement si elle est préférée à au moins un élément de Yk sans pour autant être préférée à aucun élément de Yk-1.
Quant à la méthode FFI, elle a été proposée initialement par Perny (1998) et améliorée par Henriet (2000). Elle traite la problématique du tri nominal. L’affectation des actions aux différentes catégories se fait graduellement à partir d’une relation d’indifférence des actions à chaque prototype qui caractérise la catégorie. La relation d’indifférence floue est construite à partir d’un sous ensemble flou concordant et discordant, caractérisé par des seuils de concordance flous et des seuils de discordance flous. Une fois les indices de concordance et de discordance de chaque action par rapport à un critère donné sont calculés, on les agrége pour obtenir un indice global. Lorsqu’une action est indifférente à un prototype d’une catégorie donnée, on affecte l’action à cette catégorie.
4.2.5 PROAFTN : PROcédure d’Affectation Floue dans le cadre de la problématique du Tri Nominal PROAFTN détermine la classe d’affectation d’une action à partir des relations de ressemblances floues déterminées par les indices de ressemblance (Belacel, 1999, 2000). La procédure PROAFTN se caractérise par une affectation graduelle des actions aux différentes classes. Cette méthode peut combiner les deux types d’apprentissage : déductif et inductif, ce qui n’est pas le cas des autres méthodes. Comme son nom l’indique, cette méthode traite la problématique du tri nominal, chaque classe est caractérisée par un ensemble de prototypes. PROAFTN traite les problèmes avec des données de nature qualitative ou quantitative.
Dans un premier temps, PROAFTN détermine l’indice de concordance )b,a(c hij . C’est le degré
avec lequel le critère gj est en concordance avec l’indifférence de l’action a par rapport à l’un des prototype i de la classe h : h
ib . Pour tenir compte de l’indifférence faible on introduit à ce niveau
les seuils de discrimination qj- ( h
ib ) et qj+( h
ib ) (avec qj- ( h
ib ), qj+( h
ib ) ≥0 ). Dans un deuxième
temps, on calcule l’indice de discordance )b,a(D hij qui exprime le degré de discordance avec
l’indifférence de l’action a par rapport au prototype hib en utilisant les seuils de veto.

22
En appliquant le principe de concordance et de non-discordance, nous déterminons l’indice d’indifférence de l’action a par rapport au prototype i de la classe h : h
ib .
∏∑ −=j
whij
j
hij
hj
hi
hi))b,a(D1(*)b,a(cw)b,a(I (4.2)
En calculant cet indice sur tous les prototypes de la classe h, nous pouvons déterminer l’indice d’appartenance global, de l’action a par rapport à la classe h tel que :
{ })b I(a, ,),b I(a, max )C d(a, hL
h1
hh
…= (4.3)
La décision d’affectation s’annonce comme suit :
{ } K....1kavec),a(dmax),a(d k ==⇔ ∈ khh CCC a (4.4)
Il existe d’autres variétés de la méthode, PROCTN et PROCFTN, ce sont deux procédures de choix dans le cadre de la problématique du tri nominal. La famille des méthodes a eu beaucoup de succès, notamment dans le diagnostic médical. Nous retenons l’application pour le diagnostic des leucémies aigues, des tumeurs de cerveau et plus récemment, nous trouvons l’application de PROAFTN dans le diagnostic de l’asthme (Belacel, 1999; Larburu et al, 2003; Belacel et Boulassel, 2001 et 2004).
L’analyse de la méthode PROAFTN nous permet de constater l’existence d’une procédure floue d’affectation multicritère, avec un nombre illimité de catégories. Elle combine les deux techniques d’apprentissage inductif et déductif, tout en assurant une interaction avec le décideur afin de déterminer les paramètres. Cette interaction est très importante dans un processus de décision. Seulement, le nombre de paramètres que doit déterminer le décideur augmente d’une manière très rapide avec l’augmentation du nombre des classes et du nombre des critères. Ceci constitue le point faible de cette méthode, qui est généralisé pour les autres les méthodes d’affectation multicritère.
4.2.6 TRINOMFC : TRI NOMinal basé sur des Fonctions Critères Développée par Léger et Martel (2002), TRINOMFC est une méthode de tri nominal. Elle se base sur une extension de la notion de critère en lui introduisant une fonction, pour chaque critère, donnant la préférence du décideur pour une action par rapport à une autre action. Elle fait appel aux indices de similarité au lieu des seuils de discordance et de veto. La fonction de similarité a le même principe que celui de la fonction de dissimilarité présentée dans le deuxième chapitre de la classification automatique. Contrairement à la dissimilarité, la similarité exprime la proximité, pas nécessairement au sens de distance entre deux éléments. Ainsi, la similarité entre l’objet et lui même est égale à 1.
La première étape de TRINOMFC, consiste à choisir une des fonctions des critères proposées par Léger et Martel (2002). Ces fonctions constituent une adaptation des fonctions de PROMÉTHÉE. À partir des fonction des critères et des seuils de similarité et de dissimilarité, nous calculons l’indice de similarité local h
jSI (a, hpb ) pour chaque prototype h
pb , pour chaque classe h et pour chaque critère j. La troisième étape consiste à calculer l’indice de similarité global de chaque action a par rapport au prototype h
pb de la classe h : ( )hp
h b,aSI .
La quatrième étape consiste à déterminer l’indice d’appartenance de l’action a à la catégorie Ch :
( ) ( ){ } .K,....1h,b,aSIminC,aMI hp
h
p
hh == (4.5)

23
À partir de ce degré, nous pouvons formuler la décision d’affectation de la méthode TRINOMFC :
( ) ( ){ }hh
h
ttt C,aMImaxC,aMICa =⇔∈ . (4.6)
TRINOMFC est une méthode très simple. Grâce aux indices de similarité, elle ne fait appel à aucun seuil de discordance ni de veto. Contrairement aux autres méthodes d’affectation multicritère, TRINOMFC se base sur la similarité entre l’objet à classer et les prototypes des classes, au lieu des préférences.
4.3 Conclusion À partir de l’étude des méthodes présentées dans ce paragraphe, et des propriétés des méthodes d’affectation multicritère d’Henriet (2000) nous avons caractérisé les méthodes d’affectation multicritère selon plusieurs indices (Tableau 4.1).
La première méthode UTADIS, se distingue par le fait qu’elle est la seule méthode appartenant à l’approche de critère unique de synthèse. Se basant sur la fonctions d’utilité, cette méthode de tri ordinal, fait appel à la programmation mathématique pour déterminer ses profils limites. Ceci permet de réduire le nombre de paramètres à déterminer en concertation avec le décideur. Néanmoins, c’est une méthode totalement compensatoire, qui ne s’applique que dans le cas de données cardinales.
Les premières méthodes d’affectation basées sur l’approche de surclassement de synthèse, segmentation trichotomique et n-tomic, avaient un nombre de catégories limité et une affectation nette, Electre Tri avec son caractère explicatif assez fort, peut traiter n’importe quel nombre de catégories, mais l’affectation est toujours nette, le tri est ordinal et la structure est un préordre. La méthode du Filtrage Floue par Préférence a introduit l’approche d’affectation floue et la relation binaire de préférence. La dernière méthode du Filtrage Flou par Indifférence, PROAFTN et TRINOMFC sont des méthodes de tri nominal qui n’exigent aucune structure particulière. Ces améliorations apportées au fur et à mesure aux méthodes d’affectation multicritère ont permis d’élargir leur champ d’application et de renforcer leur caractère explicatif.
Au niveau axiomatisation des méthodes, Roy et Yu (1991) ont défini sept principes fondamentaux indépendants présentés sous forme d’exigences axiomatiques : universalité, unicité, indépendance, homogénéité, conformité, monotonicité et stabilité. Belacel (1999) a définit deux autres axiomes : la neutralité et la nominalité.
Ces axiomes ont été élaborés dans le souci de conformité de la méthode d’affectation, d’une part à l’objectif de la problématique de tri, et d’autre part à la conception des actions de référence. Ils ne sont pas des normes absolues sur lesquelles doivent se baser la procédure d’affectation. Ces axiomes reflètent une forme de rationalité parmi d’autres (Roy et Bouyssou 1991; Yu, 1991)

24
Tableau 4. 1 Propriétés des méthodes d’affectation multicritère
Propriétés UTADIS Segmentation trichotomique n-Tomic Electre Tri FFI FFP PROAFTN TRINOMFC
Approche Critère unique de synthèse Surclassement de synthèse
Tri ordinal ordinal ordinal ordinal nominal ordinal nominal nominal
Nature des données Cardinale Ordinale
Cardinale Ordinale Cardinale
Ordinale Cardinale
Ordinale Cardinale
Ordinale Cardinale
Ordinale Cardinale
Ordinale Cardinale
Nombre classes quelconque 3 3 à 12 quelconque quelconque quelconque quelconque quelconque
Définition classes Seuils limites d’utilité Multiprofils limites Intervales d’indice
de surclassement Monoprofil limites Multiprofils centraux Multiprofils limites Multiprofils centraux Multiprofils centraux
affectation nette nette nette nette floue floue floue floue
Articulation des préférences
Tradeoffs et évaluation
Relation binaire: surclassement
Relation binaire: surclassement
Relation binaire: surclassement
Relation binaire: indifférence
Relation binaire: préférence
Relation binaire: indifférence
Indice de similarité
Structure Préordre total Préordre partiel Préordre partiel Ordre intervale partiel aucune Préordre partiel aucune aucune
Exigences axiomatiques
Indépendance Invariance Transitivité Dominance
Universalité Unicité
Indépendance Homogénéité Conformité
Monotonicité Stabilité
Universalité Unicité
Indépendance Homogénéité Conformité
Monotonicité Stabilité
Universalité Unicité
Indépendance Homogénéité Conformité
Monotonicité Stabilité
Universalité Unicité
Indépendance Neutralité
Conformité Nominalité
Stabilité
Universalité Unicité
Indépendance Homogénéité Conformité
Monotonicité Stabilité
Universalité Unicité
Indépendance Neutralité
Conformité Nominalité
Stabilité
Universalité Unicité
IndépendanceNeutralité
Conformité Nominalité
Stabilité
Caractère explicatif fort fort faible fort fort fort fort fort

25
5. Étude descriptive et comparative entre les méthodes de la classification «While techniques are important…knowing when to use them and why to use them is more important» Tukey (1954)
La revue de la littérature nous montre l’existence d’une panoplie de méthodes de classification appartenant à différentes disciplines scientifiques. Une telle diversité reflète une certaine richesse et un dynamisme intellectuel, mais en même temps constitue la preuve de la limitation de ces méthodes. Comme nous l’avons ressorti dans la première partie, les méthodes de classification font appel à plusieurs domaines de recherche : Statistique, recherche opérationnelle, intelligence artificielle, aide multicritère à la décision. Ces domaines sont assez disjoints, chaque domaine propose ses propres méthodes et ses propres objectifs de la classification. Sans oublier bien sûr que dans un souci d’amélioration continue, ces domaines développent au fur et à mesure des méthodes de plus en plus performantes et de plus en plus simples. La multiplicité des méthodes de classification, et surtout le fait que les domaines sont complètement disjoints posent plusieurs défis.
Dans ce chapitre, nous allons essayer d’analyser et de comparer les différentes méthodes de classification. Dans un premier temps, nous allons présenter un essai de caractérisation des différentes méthodes de classification. Par la suite, nous allons comparer les méthodes de classification afin de ressortir les limites et les avantages de chaque approche avec les contextes d’application.
5.1 Essai de caractérisation des méthodes de classification La caractérisation des méthodes de classification est une tâche qui nous a paru très complexe au début. En effet, la multitude des méthodes et leur appartenance à des domaines de recherche disjoints et surtout l’analyse détaillée des méthodes affectent cette vue globale qui permet de caractériser les méthodes. Toutefois, nous croyons qu’il est possible de ressortir certains indicateurs descriptifs. Ces indicateurs permettront de décrire les méthodes et de les distinguer entre elles.
L’analyse des différents tableaux de synthèse que nous avons produit dans les premiers chapitres, nous permet de ressortir quelques points communs entre les différentes disciplines de la classification. Ces points communs peuvent être considérés comme des caractéristiques ou des indices descriptifs des méthodes de classification. Pour identifier les indicateurs descriptifs, nous nous sommes inspirés des travaux de Guitouni (1998) dans la caractérisation des situations décisionnelles.
La revue des méthodes de classification nous permet de ressortir l’apprentissage comme étant le premier critère qui permet de caractériser les méthodes. On distingue entre deux types d’apprentissage supervisé ou non supervisé. Cette distinction permet de ressortir deux catégories de méthodes : les méthodes de classification automatique et les méthodes d’affectation.
La première catégorie n’a aucune connaissance sur les classes des données. Dans le cas où le nombre de classe est fixé au préalable, on utilise des méthodes de partitionnement, sinon on utilise des méthodes hiérarchiques ascendantes ou descendantes. Quant à la deuxième catégorie, les données ont des expériences dans le passé qui permettent de former un ensemble d’apprentissage, avec des classes prédéfinies. Les méthodes d’affectation peuvent à leur tour être classées selon le schéma d’inférence de l’apprentissage en question. Nous retenons

26
l’apprentissage déductif, qui est représenté par le système expert. Puis l’apprentissage inductif, représenté par les techniques statistiques, les réseaux de neurones et le machine learning. Et enfin les méthodes d’affectation multicritère qui peuvent faire appel aux deux schémas d’inférence à la fois, ou l’un des deux, mais dont les classes sont déjà prédéfinies. La figure (5.1) représente une taxonomie des méthodes de classification selon le type de l’apprentissage en question.
Figure 5. 1 Taxonomie des méthodes de classification.
Automatique : Apprentissage non supervisé
Méthodes ascendantes : - Méthodes des liens, - P-médiane, - Centroide - Ward’s.
Méthodes descendantes :Bi-coloration de graphes
Méthodes
hiérarchiques
Classification
Partitionnement
Affectation :
apprentissage supervisé
Apprentissage
déductif
Apprentissage inductif
Techniques statistiques:
- Apprentissage bayésien, - Analyse discriminante, - k-plus proches voisins.
Machine learning:
- Arbre de décision, - Apprentissage par
noyaux,
- SVM, SCM…
Réseaux de neurones Critère unique de synthèse - UTADIS. Surclassement de synthèse - Segmentation tricothomique,
- Méthodes N-Tomic,
- ELECTRE TRI,
- Filtrages flous,
- PROAFTN,
- TRINOMFC.
Système expert
Heuristiques : - K-means, - Nués dynamiques, - Leader.
Algorithmes exacts
Affectation multicritère

27
Outre le type d’apprentissage, nous estimons que les cinq points suivants peuvent décrire au mieux les méthodes de la classification : nature des classes, nature des données, hypothèses sous-jacentes de la méthode, type de traitement et résultat escompté.
Nature des classes. La première question qu’il faut poser, à notre avis, est-ce que les classes sont connues au préalable? Si non, connaît-on au moins le nombre de classes? Si oui, les classes sont-elles ordonnées? Comment ces classes sont-elles définies?
Nature des données. Une fois le type d’apprentissage et la nature des classes sont fixés, il faut analyser la nature des données : soient les critères et les actions. Quelle est l’échelle de mesure des données? Les données sont-elles ponctuelles ou représentées par des distributions? La méthode de la classification peut traiter n’importe quelle taille d’échantillon de données, ou doit-on lui spécifier une limite? Y a t’il une limite sur le nombre des critères?
Hypothèses sous-jacentes des méthodes. Il faut spécifier quelles sont les conditions d’application des méthodes, et si c’est possible les axiomes ou les propriétés des différentes techniques.
Algorithme de traitement. L’algorithme de traitement a trait au type de traitement que la méthode utilise pour la classification. Ça peut être général, dans le cas de la spécification du domaine de recherche, ou particulier en spécifiant le type exact du traitement : théorie des graphes, minimisation du carrée des erreurs etc. Aussi, nous pouvons spécifier à ce niveau l’utilisation de la dissimilarité, de la distance ou de la probabilité et le niveau de compensation entre les données.
Le résultat escompté. Quel est le résultat obtenu? Comment peut-on interpréter ce résultat? Quel est le caractère explicatif de la méthode?
L’analyse minutieuse des différentes méthodes de classification présentées dans la première partie nous a permis de construire les tableaux 5.1 et 5.2.
La lecture de ces tableaux nous montre l’hétérogénéité des méthodes. Cet essai de caractérisation nous donne une idée sur les conditions d’application des méthodes.
5.2 Comparaison des méthodes :
Dans cette partie, nous allons comparer les méthodes de la classification dans le but de ressortir un cadre d’application pour chaque approche des méthodes. Reprendre l’analyse des méthodes de classification en détail serait un travail redondant à notre avis. Ainsi, pour comparer les méthodes entre elles, nous allons essayer de projeter une vue d’ensemble sur les différentes approches de la classification, afin d’avoir une idée globale sur les avantages, les limites voir même les conditions d’application. L’objectif de cette étude comparative n’est pas de porter des jugements subjectifs sur les méthodes de genre bon ou mauvais. Mais de regarder les approches de classification en général avec un œil critique, en tenant compte des informations recueillies jusqu’ici dans ce rapport, et selon notre connaissance et notre vision sur la classification.
Pour comparer les méthodes de classification, nous allons considérer quatre groupes de méthodes qui représentent, à notre avis les quatre grandes approches de la classification :
- Classification automatique, - Affectation multicritère, - Affectation inductive, (Statistique, Réseaux de neurones, Machine learning) - Affectation déductive, (Systèmes expert)
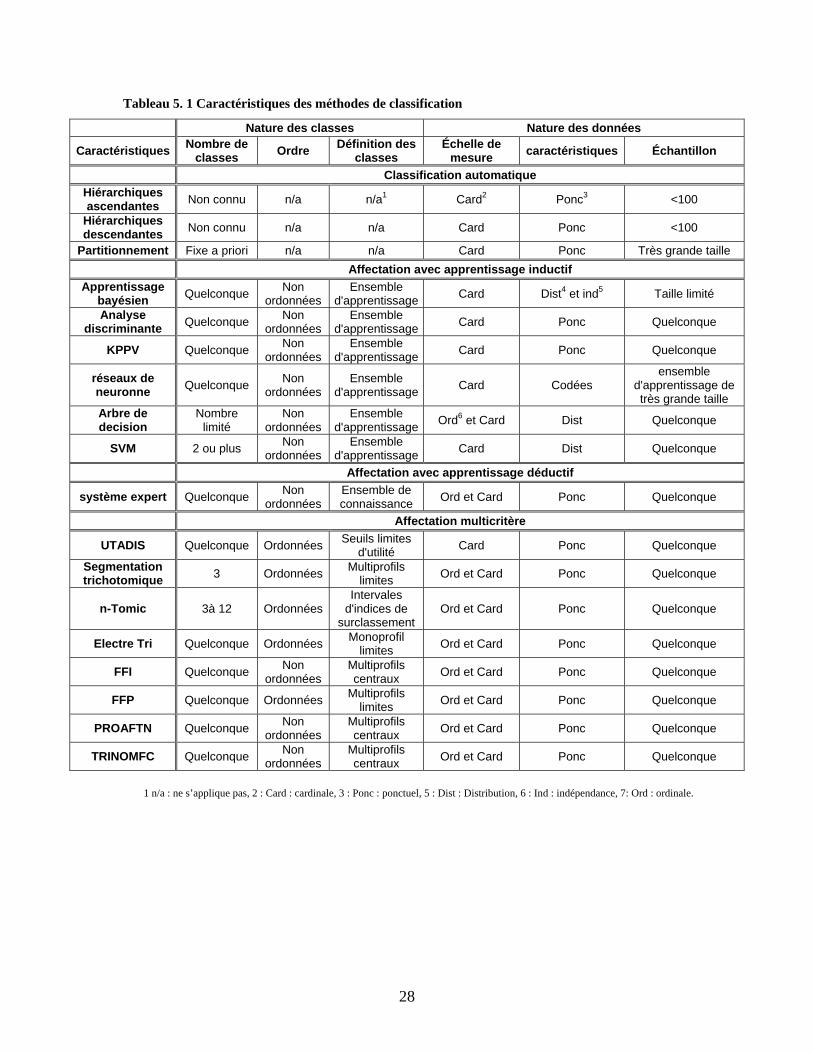
28
Tableau 5. 1 Caractéristiques des méthodes de classification
Nature des classes Nature des données
Caractéristiques Nombre de classes Ordre Définition des
classes Échelle de
mesure caractéristiques Échantillon
Classification automatique Hiérarchiques ascendantes Non connu n/a n/a1 Card2 Ponc3 <100
Hiérarchiques descendantes Non connu n/a n/a Card Ponc <100
Partitionnement Fixe a priori n/a n/a Card Ponc Très grande taille Affectation avec apprentissage inductif
Apprentissage bayésien Quelconque Non
ordonnées Ensemble
d'apprentissage Card Dist4 et ind5 Taille limité
Analyse discriminante Quelconque Non
ordonnées Ensemble
d'apprentissage Card Ponc Quelconque
KPPV Quelconque Non ordonnées
Ensemble d'apprentissage Card Ponc Quelconque
réseaux de neuronne Quelconque Non
ordonnées Ensemble
d'apprentissage Card Codées ensemble
d'apprentissage de très grande taille
Arbre de decision
Nombre limité
Non ordonnées
Ensemble d'apprentissage Ord6 et Card Dist Quelconque
SVM 2 ou plus Non ordonnées
Ensemble d'apprentissage Card Dist Quelconque
Affectation avec apprentissage déductif
système expert Quelconque Non ordonnées
Ensemble de connaissance Ord et Card Ponc Quelconque
Affectation multicritère
UTADIS Quelconque Ordonnées Seuils limites d'utilité Card Ponc Quelconque
Segmentation trichotomique 3 Ordonnées Multiprofils
limites Ord et Card Ponc Quelconque
n-Tomic 3à 12 Ordonnées Intervales
d'indices de surclassement
Ord et Card Ponc Quelconque
Electre Tri Quelconque Ordonnées Monoprofil limites Ord et Card Ponc Quelconque
FFI Quelconque Non ordonnées
Multiprofils centraux Ord et Card Ponc Quelconque
FFP Quelconque Ordonnées Multiprofils limites Ord et Card Ponc Quelconque
PROAFTN Quelconque Non ordonnées
Multiprofils centraux Ord et Card Ponc Quelconque
TRINOMFC Quelconque Non ordonnées
Multiprofils centraux Ord et Card Ponc Quelconque
1 n/a : ne s’applique pas, 2 : Card : cardinale, 3 : Ponc : ponctuel, 5 : Dist : Distribution, 6 : Ind : indépendance, 7: Ord : ordinale.
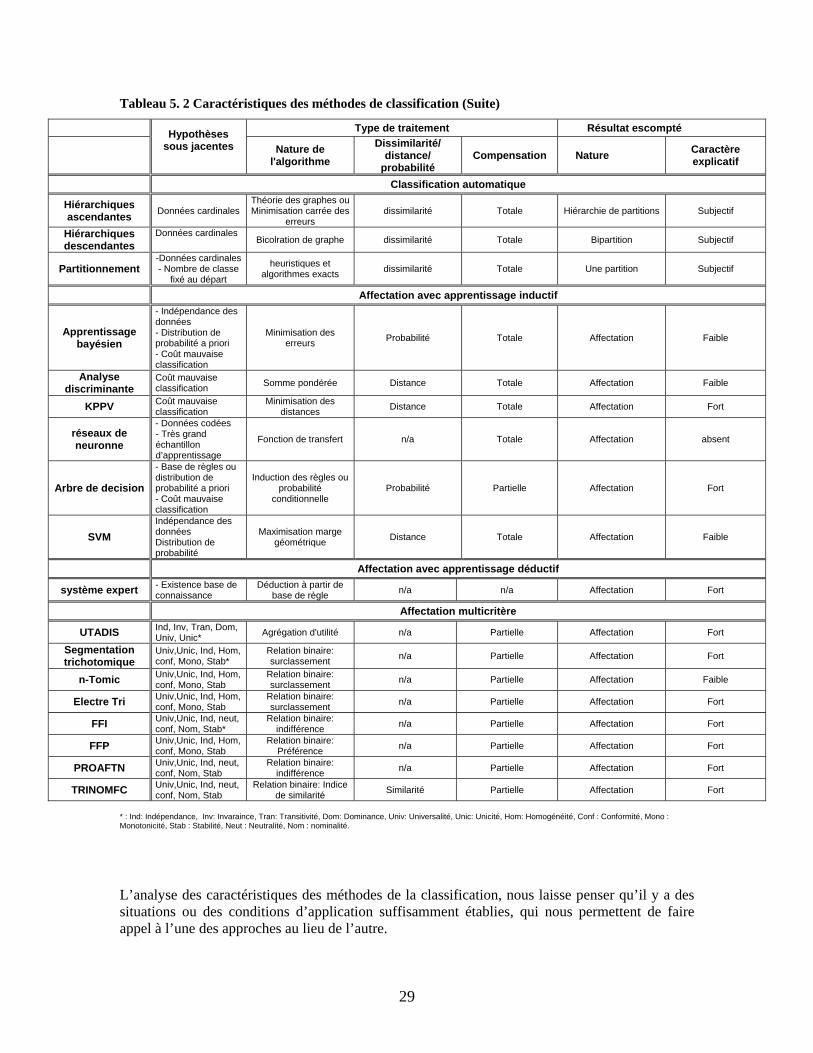
29
Tableau 5. 2 Caractéristiques des méthodes de classification (Suite)
Type de traitement Résultat escompté
Hypothèses sous jacentes
Nature de
l'algorithme Dissimilarité/
distance/ probabilité
Compensation Nature Caractère explicatif
Classification automatique
Hiérarchiques ascendantes Données cardinales
Théorie des graphes ou Minimisation carrée des
erreurs dissimilarité Totale Hiérarchie de partitions Subjectif
Hiérarchiques descendantes
Données cardinales Bicolration de graphe dissimilarité Totale Bipartition Subjectif
Partitionnement -Données cardinales - Nombre de classe
fixé au départ
heuristiques et algorithmes exacts dissimilarité Totale Une partition Subjectif
Affectation avec apprentissage inductif
Apprentissage bayésien
- Indépendance des données - Distribution de probabilité a priori - Coût mauvaise classification
Minimisation des erreurs Probabilité Totale Affectation Faible
Analyse discriminante
Coût mauvaise classification Somme pondérée Distance Totale Affectation Faible
KPPV Coût mauvaise classification
Minimisation des distances Distance Totale Affectation Fort
réseaux de neuronne
- Données codées - Très grand échantillon d’apprentissage
Fonction de transfert n/a Totale Affectation absent
Arbre de decision
- Base de règles ou distribution de probabilité a priori - Coût mauvaise classification
Induction des règles ou probabilité
conditionnelle Probabilité Partielle Affectation Fort
SVM Indépendance des données Distribution de probabilité
Maximisation marge géométrique Distance Totale Affectation Faible
Affectation avec apprentissage déductif
système expert - Existence base de connaissance
Déduction à partir de base de règle n/a n/a Affectation Fort
Affectation multicritère
UTADIS Ind, Inv, Tran, Dom, Univ, Unic* Agrégation d'utilité n/a Partielle Affectation Fort
Segmentation trichotomique
Univ,Unic, Ind, Hom, conf, Mono, Stab*
Relation binaire: surclassement n/a Partielle Affectation Fort
n-Tomic Univ,Unic, Ind, Hom, conf, Mono, Stab
Relation binaire: surclassement n/a Partielle Affectation Faible
Electre Tri Univ,Unic, Ind, Hom, conf, Mono, Stab
Relation binaire: surclassement n/a Partielle Affectation Fort
FFI Univ,Unic, Ind, neut, conf, Nom, Stab*
Relation binaire: indifférence n/a Partielle Affectation Fort
FFP Univ,Unic, Ind, Hom, conf, Mono, Stab
Relation binaire: Préférence n/a Partielle Affectation Fort
PROAFTN Univ,Unic, Ind, neut, conf, Nom, Stab
Relation binaire: indifférence n/a Partielle Affectation Fort
TRINOMFC Univ,Unic, Ind, neut, conf, Nom, Stab
Relation binaire: Indice de similarité Similarité Partielle Affectation Fort
* : Ind: Indépendance, Inv: Invaraince, Tran: Transitivité, Dom: Dominance, Univ: Universalité, Unic: Unicité, Hom: Homogénéité, Conf : Conformité, Mono : Monotonicité, Stab : Stabilité, Neut : Neutralité, Nom : nominalité.
L’analyse des caractéristiques des méthodes de la classification, nous laisse penser qu’il y a des situations ou des conditions d’application suffisamment établies, qui nous permettent de faire appel à l’une des approches au lieu de l’autre.

30
La première situation est l’absence totale de connaissances sur les classes des données. Dans ce cas, aucun apprentissage supervisé ne peut être envisagé. Seule la classification automatique peut faire face à ce type de problèmes. La classification automatique se base sur des algorithmes formels non subjectifs. En général, ce sont des algorithmes exacts ou des heuristiques. Aucune dimension de préférences n’est intégrée dans ce cas. Cette approche est bien adaptée dans le cas de très grandes bases de données, dont la classification doit se faire automatiquement, et dont le contexte ne nécessite pas d’interaction avec le décideur, ni la formulation de ses préférences. Dans le cas de petit échantillon de données, les méthodes hiérarchiques sont disponibles sur plusieurs logiciels (SPSS et SAS) et permettent d’avoir une classification rapide des données. La classification automatique a apporté une aide précieuse, notamment par ses applications en médecine, en nosologie, en biologie, en astronomie, en chimie etc. Toutefois, cette approche a des faiblesses d’une part au niveau de l’interprétation des résultas qui est très subjective, d’autre part au niveau de l’utilisation des fonctions de dissimilarité, qui doivent être calculées entre chaque paire d’objets. Sans oublier bien sûr les restrictions sur la nature de données pour pouvoir manipuler ces fonctions de dissimilarité.
Supposons maintenant que nous avons quelques connaissances sur les données. Par exemples les classes sont prédéfinies. Cette connaissance ne serait pas suffisante pour appliquer les méthodes d’affectation inductive et déductive. En effet, dans le premier cas, il faut au moins un ensemble d’apprentissage avec toutes les données classées afin de construire le modèle avec un sous ensemble d’apprentissage et le tester et le valider avec l’ensemble de test. Dans le deuxième cas, il faut assez de connaissances sur les données qui nous permettront de déduire des règles de classification. Or, l’affectation multicritère nécessite une connaissance minimale sur les classes afin de pouvoir classer les données.
L’affectation multicritère est parfaitement adaptée dans le cas où le décideur a besoin d’aide multicritère à la décision pour classer ses données. Ce besoin peut se manifester par la nécessité d’intégrer les préférences du décideur ou par la présence de critères conflictuels avec une compensation complexe, ou dans le cas d’hétérogénéité des données, ou des échelles de mesure différentes pour les critères. Pour plus de détail nous référons le lecteur au livre (Roy et Bouyssou; 1993).
L’affectation multicritère utilise des comparaisons entre l’individu à affecter et les individus de référence par le biais d’un modèle de préférence. Ceci évite le recours à des distances et permet d’utiliser des critères qualitatifs et/ou quantitatifs. En outre, cette approche permet d’écarter les complications rencontrées lorsque les données sont exprimées dans différentes unités. Les méthodes issues de cette approche peuvent justifier confortablement leur résultat, faisant ainsi face à la structure de boite noire des autres méthodes de classification. La nature des données n’est pas importante dans cette situation, elle peut être quantitative ou qualitative. On retrouve des méthodes qui ont intégré le flou dans leur calcul. Ceci permet de traiter certaines sources d’incertitude dans les données. L’expression des préférences par le décideur, lui permet de suivre le déroulement du processus de classification et de bien saisir les enjeux des résultats. Ceci est très important dans les situations de décision politique, militaire ou de diagnostic médical par exemple.
Cependant, le comportement de certaines procédures peut sembler obscur et les résultats risquent d’être mal compris. Ces méthodes ne reposent pas sur un fondement théorique solide et sont plutôt des méthodes pragmatiques et subjectives. D’autre part, l’un des points faibles de ces méthodes est la détermination du nombre considérable de paramètres nécessaires pour l’aboutissement de ces méthodes. Cette détermination se passe via une interaction directe avec le

31
décideur. Cependant, le nombre de paramètres à déterminer est de plus en plus élevé, ce qui dépasse les capacités cognitives du décideur. Dans des travaux récents en affectation multicritère, nous constatons l’intérêt des auteurs pour automatiser la détermination des paramètres (Doumpos et Zopounidis, 2002; Mousseau et al., 1996). Les méthodes proposées sont basées sur la modélisation du problème de détermination des paramètres sous forme d’un programme mathématique qui minimise les erreurs de la classification. Ces erreurs sont calculées à partir des données classées a priori. Ceci nécessite un niveau de connaissance équivalent à celui des méthodes d’affectation inductive.
L’idée de déterminer les paramètres permet non seulement de simplifier le processus de classification, mais aussi de tenir compte d’un élément majeur, à notre avis, négligé par les méthodes d’affectation multicritère et de classification automatique : l’erreur de classification. L’erreur de classification a trait d’une part de l’exactitude et de la validité du modèle de classification élaboré. D’autre part, elle a trait à la performance du classificateur. Cette performance permet de ressortir la pertinence d’une méthode de classification par rapport à une autre et de justifier le choix de la méthode.
L’erreur de classification trouve son origine en statistique, plus exactement dans l’apprentissage bayésien. En effet, l’apprentissage bayésien permet de construire un modèle de classification en se basant sur la minimisation de l’erreur. Toutes les méthodes de minimisation de l’erreur de classification, sont des cas particuliers du classificateur optimal de Bayes qui a, théoriquement, une erreur nulle. Toutefois, les conditions d’application de ce théorème, distribution des données suivant une loi connue et leur indépendance, sont difficiles à rencontrer en pratique.
À ce niveau, nous constatons un décloisonnement clair des domaines de recherche. Un rapprochement naturel s’est produit, à notre avis, entre la statistique et l’intelligence artificielle. L’affectation inductive est basée sur la minimisation de l’erreur pour construire leur modèle de classification. Citons à ce niveau l’expansion que connaît la théorie PAC (Probablement Approximativement Correct) Bayes dans des récentes recherches. Nous constatons aussi un rapprochement entre le machine learning et la programmation mathématique. Dans le cas des méthodes SVM, la détermination du modèle se fait via des programmes mathématiques qui optimisent l’objectif de chaque méthode. Toutefois, la résolution de ces modèles est à un niveau assez primaire de la programmation mathématique qui peut être amélioré à notre avis. D’autre part, ces méthodes nécessitent quelques paramètres qui sont déterminés par la validation croisée. Une approche itérative qui peut être consommatrice du temps, et qui risque d’affecter la qualité des résultats.
La dernière approche est l’affectation déductive. Elle utilise un raisonnement analytique qui est basé sur des inférences déductives dont le but est de transformer un ensemble de connaissances sous une forme désirée par l’utilisateur. L’un des avantages des méthodes suivant cette approche est qu’il est très facile d’exprimer des connaissances certaines et précises. Leur principal inconvénient réside dans le risque d’explosion de la base de règles. L’affectation déductive est adaptée dans le cas où les connaissances peuvent être exprimées par l’expert, ce qui n’est pas toujours évident. Elle peut traiter des problèmes utilisant uniquement des variables qualitatives et des problèmes pour lesquels il n’existe pas de solution algorithmique.
En conclusion, nous pouvons dire qu’il est difficile de comparer les méthodes de classification entre elles. Dans la mesure ou chaque science défend ses propres méthodes comme étant universelles et peuvent être appliquées et adaptées dans n’importe quelle situation. Notre analyse nous montre le danger de telles conclusions, dans le sens que chaque méthode est propre à un

32
contexte particulier. Nous remarquons aussi, qu’à part quelques essais récents, il y a une distinction claire entre les méthodes selon la branche de science en question. Chacun reste dans son territoire et n’ose pas faire appel à d’autres disciplines pour enrichir ou améliorer sa propre méthode. Il serait opportun voir même primordial, d’essayer de développer des méthodes qui ne soient pas reliées à une doctrine ou à une école de pensée particulière. Une méthode qui se base sur les connaissances qu’on peut tirer de plusieurs disciplines et qui permet de profiter des avantages de différentes méthodes.
6. Remarques et conclusion
Ce document présente une synthèse des méthodes de classification, renvoyant à des paradigmes distincts : statistique, recherche opérationnelle, intelligence artificielle, aide multicritère à la décision. Nous avons commencé par présenter les différentes méthodes de classification, par la suite nous avons essayé de les décrire et de les comparer. Nous avons constaté qu’il existe deux grandes approches de classification. La première approche dite classification automatique ou classification avec apprentissage non supervisé, consiste à classer automatiquement les individus en les regroupant, en un nombre restreint de classes homogènes et séparées. Les méthodes de cette catégorie ont fait l’objet du deuxième chapitre. La deuxième approche dite affectation ou classification avec apprentissage supervisé affecte les actions aux classes prédéfinies au préalable. Contrairement à la classification automatique, ces méthodes sont basées sur l’apprentissage supervisé. Ce dernier établit des règles de classification à partir des expériences réussies dans le passé. Les méthodes d’affectation peuvent être inductives, déductives ou multicritère.
Les méthodes d’affectation multicritère ont fait l’objet du chapitre 4. Nous avons rappelé au début de ce chapitre les principes des approches de critère unique de synthèse et de surclassement de synthèse. Par la suite, nous avons présenté les méthodes selon l’approche en question. L’analyse des méthodes d’affectation multicritère nous a permis d’établir le tableau 4.1. Ce dernier ressort quelques propriétés et caractéristiques des méthodes présentées.
La revue des méthodes de classification nous a démontré à quel point ces méthodes sont différentes du point de vue de leurs hypothèses sous-jacentes, leurs exigences informationnelles, leurs manières de procéder, leurs limitations et avantages et surtout leurs disciplines scientifiques. Sur la base des éléments dégagés des chapitres 2, 3 et 4, nous avons proposé dans le chapitre 5 une synthèse des caractéristiques de ces méthodes et un essai de comparaison entre elles. Nous avons mis à l’avant cinq indices descripteurs qui sont à l’origine des tableaux 5.1 et 5.2. La lecture et l’analyse de ces tableaux nous ont permis de comparer les méthodes selon le paradigme en question. Nous avons explicité pour chaque catégorie de méthodes les points forts, les points faibles, les conditions d’application et les situations d’application.
Compte tenu des éléments dégagés de la revue de la littérature et des résultats de la comparaison des méthodes de classification, des difficultés des méthodes d’affectation multicritère et du machine learning et de l’essor que connaît la classification dans plusieurs domaines de recherche, nous estimons qu’une recherche pour développer une nouvelle méthode de classification s’appuyant sur plusieurs disciplines scientifiques est entièrement légitime en plus d’être d’actualité. En effet, faire appel à plusieurs paradigmes permettra non seulement de donner un aspect général à la méthode, mais aussi de tenir compte des limites et des avantages de chaque discipline.

33
Références 1. Baulieu F.B., (1989), A classification of presence/absence based dissimilarity coefficients.
Journal of classification, vol.6, pp.233-246.
2. Belacel N., (1999), “Méthodes De Classification Multicritère, Méthodologie Et Applications À L’aide Au Diagnostic Médicale”. Thèse de doctorat en sciences, Université Libre de bruxelles.
3. Belacel N., et Boulassel M.R., (2004) Multicriteria fuzzy classification procedure PROCFTN: methodology and medical application. Fuzzy Sets and Systems, 141# 2, 203-217
4. Cormack R.M., (1971), A Review of Classification. Journal of the Royal Statistical Society, A(134), 321-367.
5. Dombi J., et Zsiros Á., (2003), Learning multicriteria classification models from examples: Decision rules in continuous space. European Journal of Operational Research, In Press.
6. Fisher L., et Van Ness J.W., (1971), Admissible clustering procedures. Biometrika, 58, 1, p.91.
7. Fodor J., Orlovski S.A., Perny P., Roubens M., (1998) “The use of fuzzy preference models in multiple criteria choice, ranking and sorting”, in: R. Slowinski (Ed.), Kluwer Academic Publishers, London, pp. 69–101.
8. Gordon A.D., (1981), “Classification: Methods for the Exploratory Analysis of Multivariate Data”, New York: Chapman and Hall.
9. Guitouni A., (1998), “L’ingénierie du choix d’une procédure d’agrégation multicritère”. Thèse de doctorat en sciences, Université Laval.
10. Hansen P., et Jaumard B., (1997), Cluster Analysis and Mathematical Programming. Mathematic Programming, 79 , 191-215.
11. Henriet L., (2000), “Systèmes D'évaluation Et De Classification Multicritères Pour L'aide A La Décision, Construction De Modèles Et Procédures D'affectation”. Thèse de doctorat en sciences, Université Paris Dauphine.
12. Herbrich R., (2002), “Learning Kernel Classifiers”, MIT Press.
13. Léger J., et J.-M. Martel., (2002), A multicriteria assignment procedure for a nominal sorting problematic. European Journal of Operational Research, 138#2, 349-364.
14. Marchand M., (2003), “Notes du cours : Machine learning” Département informatique, Faculté des sciences et génie. Université Laval.
15. Marchand M., et Shawe-Taylor J., (2002), The Set Covering Machine. Journal of Machine Learning Research, 3, 723-746.
16. Michie D., Spiegelhalter D.J., et Taylor C.C. (1994) “Machine Learning, Neural And Statistical Classification”. Artificial Intelligence. Ellis Horwood.
17. Mitchell T. M. (1997), “Machine Learning”, WCB/McGraw-Hill.
18. Mousseau V., Slowinski R. (1996), Inferring An ELECTRE TRI Model From Assignment Examples. Cahier du LAMSADE N: 40. Université Paris Dauphine.
19. Murtagh F., (1983), A Survey of Recent Advances in Hierarchical Clustering Algorithms. The Computer Journal, 26(4), 354-359.

34
41. Murtagh F., (1984), Complexities of Hierarchic Clustering Algorithms: State of the Art. Computational Statistics Quarterly, 1(2), 101-113.
20. Perny P., (1998), Multicriteria Filtering Methods Based On Concordance And Non-Discordance Principles. Annals of operations research, 80 :137-165.
21. Roy B., et Bouyssou D., (1993) “Aide Multicritère à la Décision”. Economica, Paris.
22. Slowinski R., (1992), “Intelligent Decision Support, handbook of Application and advances of the Rough sets Theory”. Kluwer Academic Publishers, Netherlands.
23. Vapnick V., (1998), “Statistical Learning theory”. John Wiley &Sons.
24. Vincke, P., (1989), “L’aide multicritère à la décision”. Éditions de l’Université de Bruxelles, Belgique.
25. Weiss SM., et Kulikowski CA. (1991), “Computer Systems That Learn, Classification And Prediction Methods From Statistics, Neural Nets, Machine Learning And Expert Systems”. San Mateo, California Morgan Kaufman Publishers.
26. Yu Wei., (1992), “Aide Multicritère A La Décision Dans Le Cadre De La Problématique Du Trie:Concepts, Méthodes Et Applications”. Thèse de Doctorat, LAMSADE, Université de Paris Dauphine.
27. Zopounidis C., et Doumpos M., (2002), Multicriteria classification and sorting methods: A literature review. European Journal of Operational Research, 138 # 2, 229-246