dna, rna, and the flow of information the expression of a gene takes place in two steps: ...
TRANSCRIPT


DNA, RNA, and the Flow of Information The expression of a gene takes place
in two steps:
Transcription makes a single-stranded RNA copy of a segment of the DNA.
Translation uses information encoded in the RNA to make a polypeptide.

DNA, RNA, and the Flow of Information RNA (ribonucleic acid) differs from
DNA in three ways: RNA consists of only one polynucleotide
strand.
The sugar in RNA is ribose, not deoxyribose.
RNA has uracil instead of thymine. RNA can base-pair with single-stranded
DNA (adenine pairs with uracil instead of thymine) and also can fold over and base-pair with itself.

DNA, RNA, and the Flow of Information Francis Crick’s central dogma
stated that DNA codes for RNA, and RNA codes for protein.
How does information get from the nucleus to the cytoplasm?
What is the relationship between a specific nucleotide sequence in DNA and a specific amino acid sequence in protein?

Figure 17.2 The Central Dogma

DNA, RNA, and the Flow of Information Messenger RNA, or mRNA moves
from the nucleus of eukaryotic cells into the cytoplasm, where it serves as a template for protein synthesis.
Transfer RNA, or tRNA, is the link between the code of the mRNA and the amino acids of the polypeptide, specifying the correct amino acid sequence in a protein.

Figure 17.3 From Gene to Protein

DNA, RNA, and the Flow of Information Certain viruses use RNA rather than DNA as
their information molecule during transmission.
These viruses transcribe from RNA to RNA; they make a complementary RNA strand and then use this “opposite” strand to make multiple copies of the viral genome by transcription.
HIV and certain tumor viruses (called retroviruses) have RNA as their infectious information molecule; they convert it to a DNA copy inside the host cell and then use it to make more RNA.

Transcription: DNA-Directed RNA Synthesis In normal prokaryotic and eukaryotic
cells, transcription requires the following:
A DNA template for complementary base pairing
The appropriate ribonucleoside triphosphates (ATP, GTP, CTP, and UTP) to act as substrates
The enzyme RNA polymerase

Transcription: DNA-Directed RNA Synthesis Just one DNA strand (the template
strand) is used to make the RNA. For different genes in the same DNA
molecule, the roles of these strands may be reversed.
The DNA double helix partly unwinds to serve as template.
As the RNA transcript forms, it peels away, allowing the already transcribed DNA to be rewound into the double helix.

Transcription: DNA-Directed RNA Synthesis The first step of transcription, initiation,
begins at a promoter, a special sequence of DNA.
There is at least one promoter for each gene to be transcribed.
The RNA polymerase binds to the promoter region when conditions allow.
The promoter sequence directs the RNA polymerase as to which of the double strands is the template and in what direction the RNA polymerase should move.

Figure 17.4 (Part 1) DNA is Transcribed in RNA

Transcription: DNA-Directed RNA Synthesis After binding, RNA polymerase unwinds
the DNA about 20 base pairs at a time and reads the template in the 3-to-5 direction (elongation).
The new RNA elongates from its 5 end to its 3 end; thus the RNA transcript is antiparallel to the DNA template strand.
Transcription errors for RNA polymerases are high relative to DNA polymerases.

Figure 17.4 (Part 2) DNA is Transcribed in RNA

Transcription: DNA-Directed RNA Synthesis Particular base sequences in the DNA
specify termination. Gene mechanisms for termination vary:
For some, the newly formed transcript simply falls away from the DNA template.
For other genes, a helper protein pulls the transcript away.
In prokaryotes, translation of the mRNA often begins before transcription is complete.

Figure 17.4 (Part 3) DNA is Transcribed in RNA

The Genetic Code
A genetic code relates genes (DNA) to mRNA and mRNA to the amino acids of proteins.
mRNA is read in three-base segments called codons.
The number of different codons possible is 64 (43), because each position in the codon can be occupied by one of four different bases.
The 64 possible codons code for only 20 amino acids and the start and stop signals.

Figure 17.5 The Universal Genetic Code

The Genetic Code
After subtracting start and stop codons, the remaining 60 codons code for 19 different amino acids.
This means that many amino acids have more than one codon. Thus the code is redundant.
However, the code is not ambiguous. Each codon is assigned only one amino acid.
Except for a few very minor exceptions, the code is universal. It is one of the strongest pieces of evidence for evolution from a common ancestor.

The Genetic Code In the early 1960s, molecular
biologists broke the genetic code. Nirenberg prepared an artificial mRNA
in which all bases were uracil (poly U). When incubated with additional
components, the poly U mRNA led to synthesis of a polypeptide chain consisting only of phenylalanine amino acids.
UUU appeared to be the codon for phenylalanine.
Other codons were deciphered from this starting point.

Figure 17.6 Deciphering the Genetic Code

Preparation for Translation: Linking RNAs, Amino Acids, and Ribosomes The molecule tRNA is required to
assure specificity in the translation of mRNA into proteins.
The tRNAs must read mRNA correctly.
The tRNAs must carry the correct amino acids.

Preparation for Translation: Linking RNAs, Amino Acids, and Ribosomes The codon in mRNA and the amino
acid in a protein are related by way of an adapter—a specific tRNA molecule.
tRNA has three functions: It carries an amino acid.
It associates with mRNA molecules.
It interacts with ribosomes.

Preparation for Translation: Linking RNAs, Amino Acids, and Ribosomes A tRNA molecule has 75 to 80 nucleotides
and a three-dimensional shape (conformation).
The shape is maintained by complementary base pairing and hydrogen bonding.
The three-dimensional shape of the tRNAs allows them to combine with the binding sites of the ribosome.

Figure 17.7 Transfer RNA

Preparation for Translation: At the 3 end of every tRNA molecule
is a site to which its specific amino acid binds covalently.
Midpoint in the sequence are three bases called the anticodon.
The anticodon is the contact point between the tRNA and the mRNA.
The anticodon is complementary (and antiparallel) to the mRNA codon.
The codon and anticodon unite by complementary base pairing.

Preparation for Translation: Each ribosome has two subunits: a large
one and a small one. In eukaryotes the large one has three
different associated rRNA molecules and 45 different proteins. (60S)
The small subunit has one rRNA and 33 different protein molecules.(40s)
When they are not translating, the two subunits are separate. When translating they are 80S
Prokaryotic ribosomes are also two subunits of 50S and 30S. When translating they are 70S.

Figure 12.9 Ribosome Structure

Preparation for Translation: Linking RNAs, Amino Acids, and Ribosomes The proteins and rRNAs are held together
by ionic bonds and hydrophobic forces. The large subunit has four binding sites:
The T site where the tRNA first lands The A site where the tRNA anticodon binds to
the mRNA codon The P site where the tRNA adds its amino
acid to the polypeptide chain The E site where the tRNA goes before
leaving the ribosome

Translation: RNA-Directed Polypeptide Synthesis Translation begins with an initiation
complex: a charged tRNA with its amino acid and a small subunit, both bound to the mRNA.
This complex is bound to a region upstream of where the actual reading of the mRNA begins.
The start codon (AUG) designates the first amino acid in all proteins.
The large subunit then joins the complex. The process is directed by proteins called
initiation factors.

Figure 17.10 The Initiation of Translation

Translation: RNA-Directed Polypeptide Synthesis Ribosomes move in the 5-to-3
direction on the mRNA. The peptide forms in the NH–to–
COOH direction. The large subunit catalyzes two
reactions: Breaking the bond between the tRNA in
the P site and its amino acid
Peptide bond formation between this amino acid and the one attached to the tRNA in the A site

Figure 12.11 Translation: The Elongation Stage

Translation: RNA-Directed Polypeptide Synthesis After the first tRNA releases
methionine, it dissociates from the ribosome and returns to the cytosol.
The second tRNA, now bearing a dipeptide, moves to the P site.
The next charged tRNA enters the open A site.
The peptide chain is then transferred to the P site.
These steps are assisted by proteins called elongation factors.

Translation: RNA-Directed Polypeptide Synthesis When a stop codon—UAA, UAG, or
UGA—enters the A site, a release factor and a water molecule enter the A site, instead of an amino acid.
The newly completed protein then separates from the ribosome.
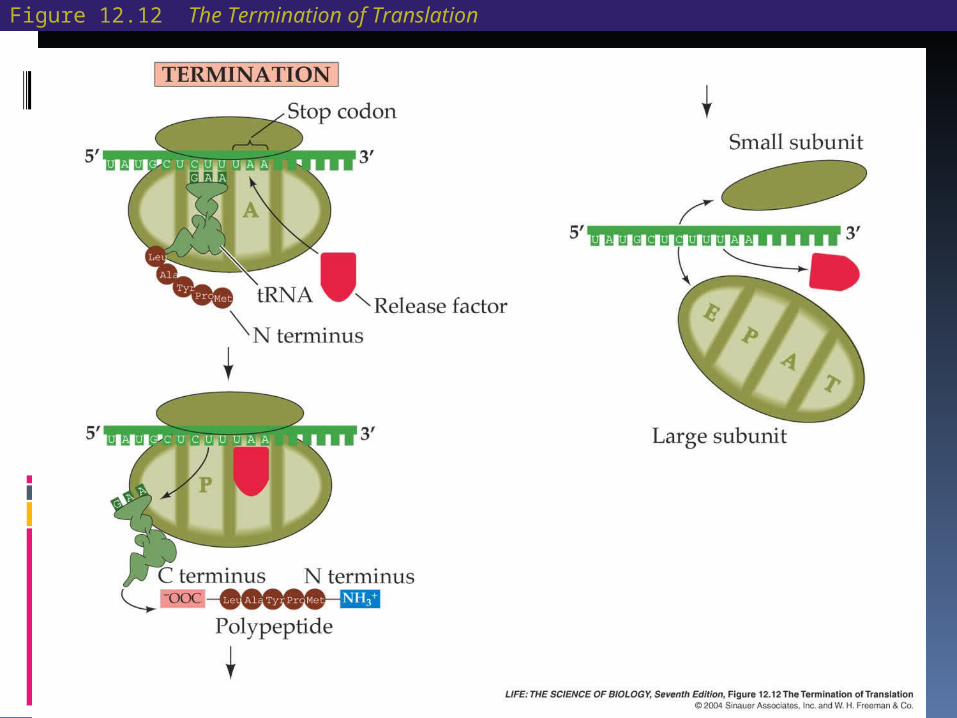
Figure 12.12 The Termination of Translation

Regulation of Translation Antibiotics are defensive molecules
produced by some fungi and bacteria, which often destroy other microbes.
Some antibiotics work by blocking the synthesis of the bacterial cell walls, others by inhibiting protein synthesis at various points.
Because of differences between prokaryotic and eukaryotic ribosomes, the human ribosomes are unaffected.

Regulation of Translation Polysomes are mRNA molecules
with more than one ribosome attached.
These make protein more rapidly, producing multiple copies of protein simultaneously.

Figure 17.13 A Polysome (Part 1)

Figure 17.13 A Polysome (Part 2)

Posttranslational Events
Two posttranslational events can occur after the polypeptide has been synthesized:
The polypeptide may be moved to another location in the cell, or secreted.
The polypeptide may be modified by the addition of chemical groups, folding, or trimming.

Figure 12.14 Destinations for Newly Translated Polypeptides in a Eukaryotic Cell

Posttranslational Events
Most proteins are modified after translation.
These modifications are often essential to the functioning of the protein.
Three types of modifications:
Proteolysis (cleaving)
Glycosylation (adding sugars)
Phosphorylation (adding phosphate groups)

Figure 12.16 Posttranslational Modifications to Proteins

Mutations: Heritable Changes in Genes
All mutations are alterations of the DNA nucleotide sequence and are of two types:
Point mutations are mutations of single genes.
Chromosomal mutations are changes in the arrangements of chromosomal DNA segments.

Mutations: Heritable Changes in Genes
Point mutations result from the addition or subtraction of a base or the substitution of one base for another.
Point mutations can occur as a result of mistakes during DNA replication or can be caused by environmental mutagens.
Because of redundancy in the genetic code, some point mutations, called silent mutations, result in no change in the amino acids in the protein.

Silent Mutation

Mutations: Heritable Changes in Genes Some mutations, called missense
mutations, cause an amino acid substitution.
An example in humans is sickle-cell anemia, a defect in the -globin subunits of hemoglobin.
The -globin in sickle-cell differs from the normal by only one amino acid.
Missense mutations may reduce the functioning of a protein or disable it completely.
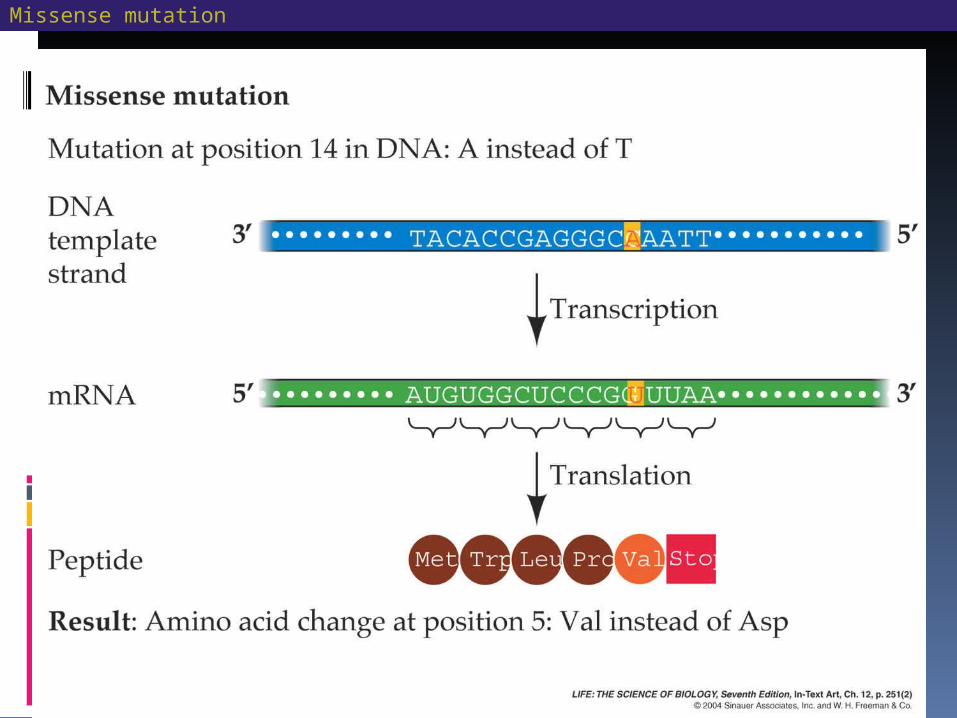
Missense mutation

Figure 12.17 Sickled and Normal Red Blood Cells

Mutations: Heritable Changes in Genes Nonsense mutations are base
substitutions that substitute a stop codon.
The shortened proteins are usually not functional.

Nonsense mutation

Mutations: Heritable Changes in Genes A frame-shift mutation consists of
the insertion or deletion of a single base in a gene.
This type of mutation shifts the code, changing many of the codons to different codons.
These shifts almost always lead to the production of nonfunctional proteins.

Frame-shift mutation

Mutations: Heritable Changes in Genes Spontaneous mutations are
permanent changes, caused by any of several mechanisms: Nucleotides occasionally change their
structure (called a tautomeric shift). Bases may change because of a chemical
reaction. DNA polymerase sometimes makes errors in
replication which can escape being repaired. Meiosis is imperfect. Nondisjunction and
translocations can occur.

Mutations: Heritable Changes in Genes Induced mutations are permanent
changes caused by some outside agent (mutagen).
Mutagens can alter DNA in several ways:
Altering covalent bonds in nucleotides
Adding groups to the bases
Radiation damages DNA: Ionizing radiation (X rays) produces free
radicals.
Ultraviolet radiation is absorbed by thymine and causes interbase covalent bonds to form.

Figure 17.19 Spontaneous and Induced Mutations (Part 1)

Figure 17.19 Spontaneous and Induced Mutations (Part 2)

Mutations: Heritable Changes in Genes Mutations have both benefits and
costs. Germ line mutations provide
genetic diversity for evolution, but usually produce an organism that does poorly in its environment.
Somatic mutations do not affect offspring, but can cause cancer.

Mutations: Heritable Changes in Genes Mutations are rare events and most of
them are point mutations involving one nucleotide.
Different organisms vary in mutation frequency.
Mutations can be detrimental, neutral, or occasionally beneficial.
Random accumulation of mutations in the extra copies of genes can lead to the production of new useful proteins.