diva - university of fribourg - switzerland seminar presentation, jan. 2005 lawrence michel, msc...
TRANSCRIPT

DIVA - University of Fribourg - SwitzerlandSeminar presentation, jan. 2005Lawrence Michel, MSc Student
Portable Meeting Recorder
A multimodal meeting recorder solution designed by RicohDar-Shyang Lee
Berna ErolJamey Graham
Jonathan J. HullNorihiko Murata

Concept 1/3
Intended goal
A methodology to enable a full multimodal (A/V, metadata) recording and browsing of a meeting
under strong constraint of
minimal hardware intrusion,portabilityand maximal data extraction capability

Concept 2/3
The Portable MeetingRecorder system
Hardware specifications “Minimal intrusive” A/V capture
component 4 Microphones 1 360° Videocamera
Meeting Recorder interface Touchscreen browsing
A common PC for processingdata

Concept 3/3
The Portable Meeting Recorder system
Overview of the recording process
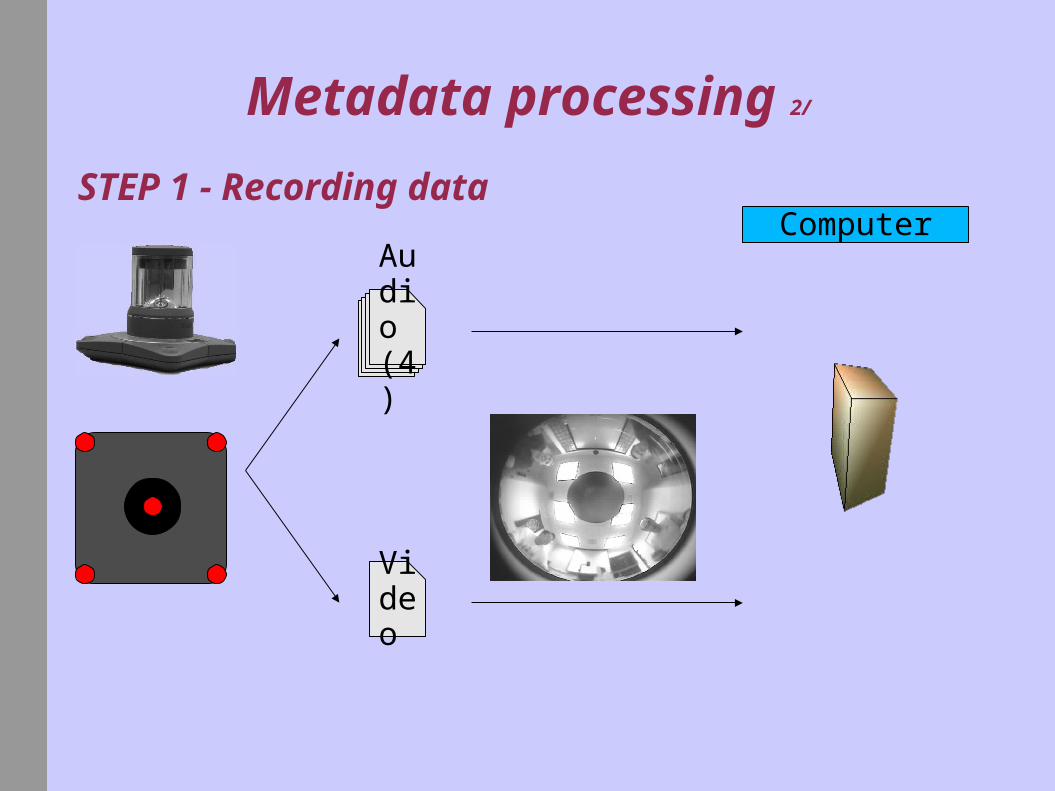
1° Computer records A/V
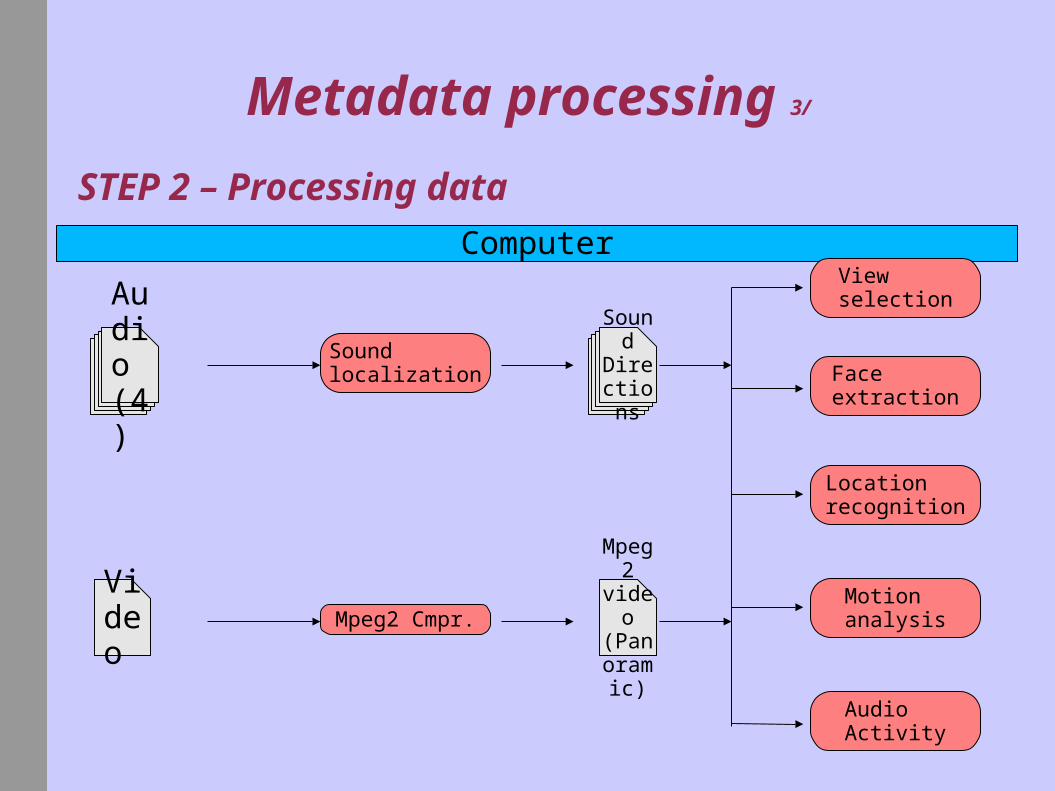
2° Computer processes Data
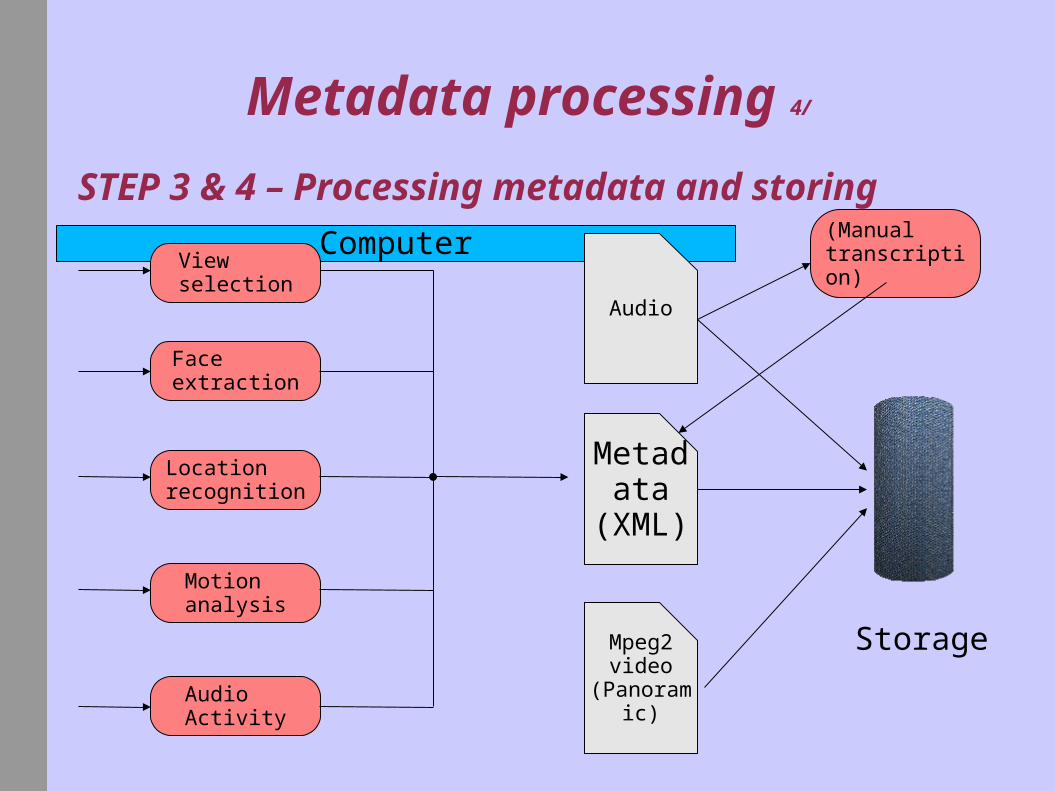
3° Computer creates Metadata (XML) (input for browser)
4° Computer consolidates data in database
Computer
Metadata processing 2/
STEP 1 - Recording data
Audio (4)
Video
Computer
Metadata processing 3/
STEP 2 – Processing data
Audio (4)
Video
Sound localization
Mpeg2 Cmpr.
Mpeg2
video(Panoramic)
SoundDirections
View selection
Face extraction
Locationrecognition
Motion analysis
Audio Activity
Computer
Metadata processing 4/
STEP 3 & 4 – Processing metadata and storing
View selection
Face extraction
Locationrecognition
Motion analysis
Audio Activity
Metadata
(XML)
Mpeg2video
(Panoramic)
Storage
Audio
(Manualtranscription)

Sound Localization
An interesting algorithm : the 360° Sound localization using 4 microphones
α°
β°
Elevation computingAzimuth computing
► Method basically based on phase properties of 4 input signals, computing differences between them and “guessing” the appropriate angle.

Sound Localization 2/
Properties
► The method is applied at real-time meeting recording (30-40% CPU load in a 933MHz PC)
► Permits a maximum data extraction while requiring a minimum of hardware (thus needed a boily human brain output!)
► Accuracy is highly dependent on several factor, such as room specifications (e.g. reflectiv surfaces that leads to high signal reverberation), amplitude of signals, speech overlap, particular angles, etc.
► hardware dependency : Accuracy effectiveness is strongly correlated with signal sampling rate, sensitivity of input devices, etc.
► These datas are mainly needed for view selection and face extraction process

Meeting Location Recognition 1/
Another interesting method : recognizing the meeting location - adaptiv background modeling
The process is as follow :
1° Analyzing frame by comparing its historgram with template2° Applying foreground extraction
3° Resulting background image will be set as the newest template

Searching and Browsing with Visual and Audio Content
How are the audio files, video files and XML metadatas efficiently exploited?

Searching and Browsing with Visual and Audio Content 1/
Introduction
Searching and browsing audiovisual information is a time consuming task. The Audio and Video Recorder is, at it's actual state of development, unable to transcript automatically audio files.
Alternatively, searching and browsing within our meeting document is based on visual and audio content activity.

Searching and Browsing with Visual and Audio Content 2/
Visual activity analysis
In most of meeting sequences, there are most of the time minimal motions.
High motion segments sequences will be corresponded to significant events

Searching and Browsing with Visual and Audio Content 3/
Audio activity analysis
The system, which is highly based on audio analysis, enables to navigate through our document in various way, such as :
Speaker segmentation using audio data
► Lost of efficiency when bad audio based tracking data are present (resulting from speech overlap, hardware specification, bad angle positioning,...).
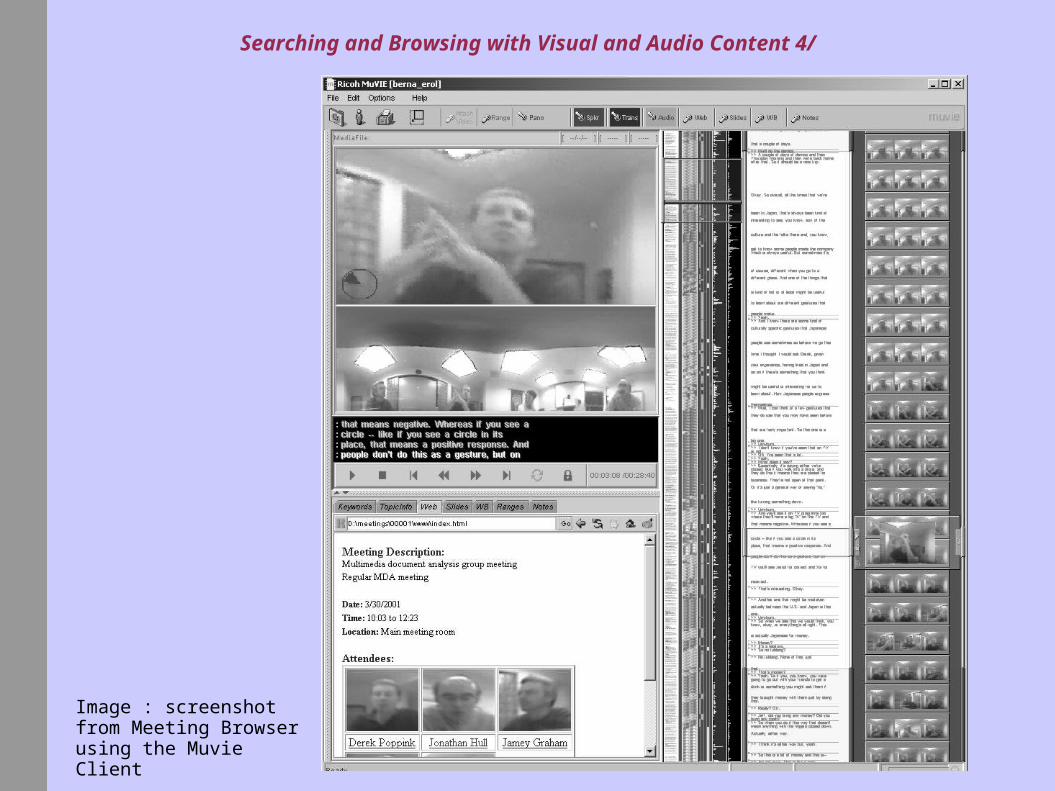
Searching and Browsing with Visual and Audio Content 4/
Image : screenshot from Meeting Browser using the Muvie Client
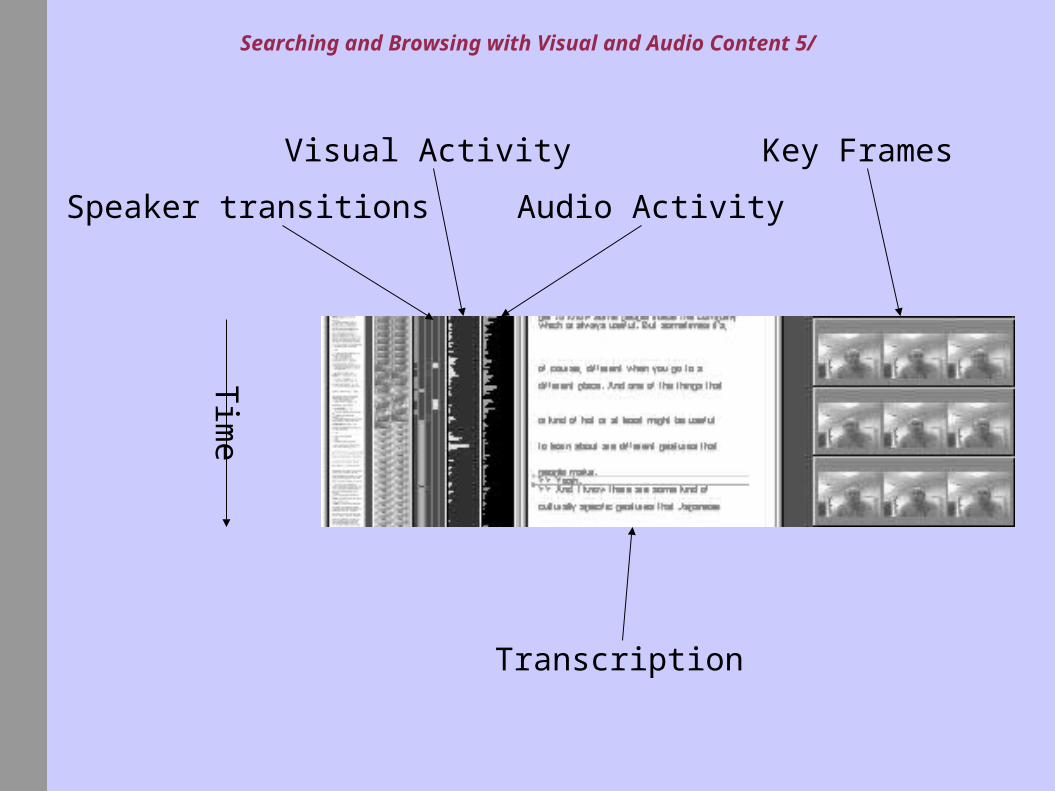
Searching and Browsing with Visual and Audio Content 5/
Tim
e
Speaker transitions
Visual Activity
Audio Activity
Key Frames
Transcription

Thank you