discovering semantic connections in community … · discovering semantic connections in community...
TRANSCRIPT

The candidate confirms that the work submitted is their own and the appropriate credit has been given where reference has been made to the work of others. I understand that failure to attribute material which is obtained from another source may be considered as plagiarism. (Signature of student) _______________________________
Discovering Semantic
Connections in Community Data Eleni Yiangou
BSc Computer Science 2009/2010

i
Summary Modern search engines consist of indexes amounting to billions of pages of spidered web content.
When a user enters any given keyword phrase into a web browser search box, the search engines
return those pages that they CONCEIVE to have a high relevance to the keywords entered by the web
user.
I say CONCEIVE, as the results returned by the search engines for any given keyword are not
necessarily ranked by the value of the content. More often than not, these results are biased by ranking
factors other than the content. This is a whole different ranking algorithm, and outside the scope of
this report.
Despite the fact that all major search engines have made conscious efforts to improve the relevancy of
their search results by employing LSI (Latent Semantic Indexing), the relevancy of the content in a
particular web-page to the searched keywords is not sufficient by itself to return search results based
on content value alone.
With this in mind, I set out to develop a web based application that would use semantic algorithms to
separate, rank and present search results based on the relevance to the searched keywords and also
based on raking factors from outside the system.
User feed-back is an example of such an outside ranking factor. Users of the system would have the
ability to “vote” on the value and relevance of the search results the application returned. This “vote”
ability would have an additional benefit, in that it would allow the system to apply semantic
algorithms to results returned across all users.
Search engines like Google, Yahoo and Bing, have enormous resources at their disposal and are
constantly updating their algorithms. Their search results however are still lacking in semantic
relevance. What we get when we search for “Bears” still gives us pages about “Polar Bears” and “The
Chicago Bears Football Team” for example. This was want I set out to address.
My aim was to solve the relevance problem by employing advanced semantic algorithms to create an
online application that would return relevant results to users searching a database of academic papers,
along with the possible connections (research topic, searched keywords, search results, etc) existing
between users of the system.

ii
Acknowledgments First of all I would like to thank God for the constant encouragement to work hard and ultimately
complete this project to my satisfaction. Then, I would like to thank my supervisor Dr. Vania
Dimitrova for the continued support and advice she offered me. Without her help, I don’t know if this
project would have ever been completed successfully. I hope God will keep her, and her family
healthy! Moreover, I would like to say a big thanks to my best friend Bill for his unlimited patience
and willingness to support me. I’m also very grateful to all the people who devoted their time and
energy to participating in the evaluation process of my project.
Special thanks to:
• KRR Group participants for their presentations, recommendations and support.
• My proofreader, Andrew Paxton
I would like to dedicate this work to my mother!

iii
Table of Contents
Project Summary ………………………………………… i
Acknowledgments ………………………………………… ii
Table of Contents ………………………………………… iii
1. Project Outline ………………………………………… 1
1.1. Problem Description ………………………………… 1
1.2. Project Aim ……………………………………………… 2
1.3. Methodology and Objectives ………………………….. 2
1.4. Minimum Requirements ………………………………… 4
1.5. Schedule ……………………………………………… 5
2. Background Reading and Research …………………. 6
2.1. Research Aim ……………………………………………… 6
2.2. Community Background ………………………………… 6
2.3. Semantic Connections ………………………………… 9
2.4. Semantic Similarity …………………………………….. 10
2.5 Semantic Relatedness ……………………………….. 12
2.6. Functional Requirements of the LeARN Community …… 13
2.7. Tools and Methods ………………………………………. 14

iv
2.7.1. Wordnet ……………………………………….. 15
2.7.2 Wordnet MySQL Database …………………… 17
2.7.3 Measures of Relatedness …………………………. . 20
2.7.4. Sphider Version 1.3 – A Search-based Method … 24
2.7.5 Ranking Algorithms ………………………….. 25
3. Design ……………………………………………………... 28
3.1. The LeARN Community Data ………………………….. 28
3.2. The System Use Case Diagram ………………………….. 29
3.3. Application Scenarios ………………………………… 30
3.4. Prototype …………………………..…………………... 32
3.5. Data Selection ………………………………………. . 34
3.6. Client - Server Architecture …………………………. 35
3.7. General LeARN Community Architecture ……………. 36
4. Algorithms Used ……………………………………….... 40
4.1 Algorithm 1: Related Users ………………………….. 40
4.2 Algorithm 2: User-Based Related Keywords …………….. 44
4.3 Algorithm 3: Recommended Materials Based on Keywords .. 46
4.4 Algorithm 4: Recommended Materials Based on Rankings .. 49

v
5. Implementation of the Application …………………… 53
5.1. Iteration 1: Feasibility of the LeARN prototype Architecture .. 53
5.2. Iteration 2: Algorithms Implementation ……………….. 54
5.3 Implementation of Extension 1 – Include in Services Menu the
Upload in the Prototype ….…………………………………. 57
6. Evaluation …………………………………………… 58
6.1 User Prototype Evaluation objectives ……………………… 58
6.2 Procedures, Participants and Materials ……………… 58
6.3 User Result Analysis …………………………………... 59
6.4 Project evaluation …………………………………………. 62
6.5 Further Work …………………………………………. 62
7. Project Conclusion ……………………………………. 63
8. References ………………………………………………... 64
9. Appendices ………………………………………….. 67
Appendix A. Personal Reflection …………………….. 67
Appendix B1. Original Project Schedule ……………… 69
Appendix B2. Original Project Schedule ……………… 69
Appendix B3. Analysis of Schedule …………………….. 70
Appendix C. Background Reading and Research Plan .... 72
Appendix D. The description of community data schema .. 73
Appendix E. The core tables of WorNet SQL database … 76

vi
Appendix F. MySQL query (section 2.7.2, p. 19) result …. 77
Appendix G. Sphider Sorted Results in LeARN prototype … 78
Appendix H. Ranking Algorithm 1 [45] ……………….. 79
Appendix I. Prototype Environment Screenshots ………… 80
Appendix J. Algorithm implementation coding parts ……… 90
Appendix K. Client-server architecture, with server
side scripting technologies [50] …………. 96
Appendix L. Evaluation Scenarios and Questionnaires ……… 97

1
1. Project Outline
1.1. Problem Description Web-based communities are becoming increasingly important places for people from diverse
backgrounds to seek and share expertise. This is because existing search engines are unable to answer
queries that require deep semantic understanding of the query or the document [1]. Additionally,
research communities are valuable for researchers undertaking new studies. This is because it is vital
to know the communities of researchers with the same research topic or area of interest [2].
As a result, researchers are in need a of an effective web-based Community environment consisting of
tools capable of understanding material in depth and discovering the semantic connections existing in
the community data. For people (students, researchers and staff) within the University of Leeds who
are conducting research with a common aim, but are members of different departments, will find web-
based research communities an invaluable tool to pool resources, interact and learn. Learning is a
result of interactions within a particular social community data. As such, users can benefit from
discovering resources read by other users or other data that both increases their knowledge in a
particular research area and helps them to understand a particular topic of interest.
The initial idea behind this project came from two existing projects, the AWESOME1 and the
BRAIN2. The AWESOME project is an online community for dissertation writing, which integrates
information about Final Year Projects. This information (title, author, degree program, year and
semantic annotation) can serve to recommend relevant projects to Undergraduate students. Moreover,
in the AWESOME project, students and tutors have the opportunity to annotate dissertations and
share not only examples but also useful guidelines. The BRAIN project is about developing an online
environment to help people discover connections between them, which can give them the opportunity
to develop collaborative research and innovation networks.
Based on how those two projects work, author decided to develop a similar web-based client/server
application where the participants are Research students. The aim of this application is to give
students the opportunity to find and share material relevant to the research area they are interested in.
Furthermore, it will discover the possible connections users may have according to the material they
downloaded or ranked and help them identify other materials which may be related to their research.
1 http://awesome.leeds.ac.uk/ 2 http://innovation1.coventry.ac.uk/brain/

2
1.2. Project Aim The aim of this project is to create a web-based client-server application in which community data
will be analyzed in order to identify similarities and connections between community members and
the material (papers, reports, books) they are involved with. It will focus on discovering the semantic
connections that exist in community data. The community is called LeARN Community (Leeds
Academic Research Network). This community aims to identify how users coming from different
departments within the University of Leeds can be related / connected according to the material they
are most interested in so that they will have the opportunity to develop collaborative research
networks.
The initial idea was to use Community data from the existing research projects AWESOME and
BRAIN. However, author decided to analyze data that aims to be beneficial for students who are
doing research. Consequently, the data to be analyzed are materials written by people are working in
the University of Leeds. Since most of the staff members within the University are participants of at
least one research area, they will have written material for these areas. Therefore, students (users) who
are doing research in a particular area will have the opportunity to interact with material written by
their teachers and if they have a strong connection with regard to their interests, collaborate with
them.
Finally, as the LeARN Community aims to be a practical tool for students of the University of Leeds
only, the materials, research areas and any other relations which may exist are devised to give users
the opportunity to collaborate, leading to a true community research network.
1.3. Methodology and Objectives The project described in this report, involves the design of a prototype. This prototype is a web-based
client server application, called LeARN (Leeds Academic Research Network). To develop a
prototype, the author first decided which methodology to follow in order to describe the software
process.
First of all, according to Summerville [13], a software process can be defined as “the set of activities
that leads to the production of a software product and these activities may involve the development of
software from scratch in a standard programming language.” Based on the same source, four
fundamental activities are common to all software processes. These activities are: System
Specification; Software Design and implementation; Software Validation; Software Evolution.
The users of this prototype will be students and staff of the University of Leeds, who are currently
involved in research. These people are the future end-users of the LeARN application. As identifying
end-users for the purposes of the project development was difficult, for the initial software validation
the use of opportunistic software development methodologies such as scenarios was required. This

3
meant that three scenarios were to be used to receive feedback regards to the functionality of the
prototype.
Although the traditional waterfall model has been at the centre of software development for a number
of years, the LeARN community was designed using the Evolutionary Development model. Keeping
in mind that the LeARN application is designed to be web-based and internet architectures and
technologies are constantly changing, a more fluid model was required.
The Evolutionary Model has a number of benefits which are highly applicable to such a changing web
environment:
1. Frequent Updates are simplified
2. Dynamic Architecture
3. Simple to integrate with user feed-back
4. Simple to integrate with a developing prototype
The Evolutionary Model is in essence a collection of Waterfall Models. As such, the extension of
applications is simplified and working prototypes can be delivered in a more timely fashion. Given
the benefits, the Evolutionary Model was the logical choice for the LeARN community application.
The LeARN Community application ultimately aims to allow people to browse and search for
materials related to their particular research area and identify potential research similarities with other
users. The activities that users could perform are:
• Search for papers related to keywords they enter
• Search and read abstracts of particular materials
• Download material
• Search and view which material has been downloaded by each users
• Search and view material written by a particular author
• View and rank particular material
• Vote (Like or Don’t Like) for material (People can Like a material if and only if they believe that the keywords they used are related to the material returned and not if they Like the material itself).
• Perform advanced search using keywords that are similar (synonyms) to the keywords they already entered into the system (According to WordNet dictionary)
The functions of the LeARN community aim to promote and foster new research collaboration
amongst people from varied academic sectors.
Consequently, the objectives and process structure of this project are:

4
• Collection of the sample data and identification of the structure
• Identify what connections could be identified and decide the possible scenarios (what the possible connections between community data and projects will be)
• Do the appropriate Research. For example, research on identification of possible methods and tools that are either readily available or author created for semantic comparison of the data.
• Create the web-based Client-Server LeARN Community
• Implement the community data related to the scenarios identified at the second stage.
• Conduct evaluations so that the effect of scenarios on the application will show how effective and successful the application is
1.4. Minimum Requirements The minimum requirements have changed since author first submitted the original set because the
initial idea was to use the data from the existing AWESOME and BRAIN projects. The format of that
data was not compatible with the requirements of this project however and as a result, a review of the
minimum requirements became necessary.
The new set of minimum requirements is:
• Create the data scheme for representing the community data
• Formulate possible scenarios and queries for mining community data
• Design the prototype of a Client - Server web-based application that provides basic knowledge functionality focusing on reading or downloading materials
• Discover how users can be connected based on the material they have accessed
Possible extensions include:
• Allow staff - users to upload different types of community data. On the one hand this will extend the interface of the application and on the other, reformulate the application so that it converts the data to the appropriate data format allowing it to be used in the database etc.
• Integrate appropriate Visualization techniques to show the relevant connections between the community data and between people.
• Extend the community data mining algorithms so that they will use ontologies.
• Extend the project by doing deeper evaluation involving real users rather than scenarios.

5
1.5. Schedule Appendix B1 includes a Gantt chart that details the original schedule for this project. The revised
schedule (in Appendix B2) was deemed inefficient to accurately depict the course of events. This is
mainly due to the fact that the initial schedule did not make allowances for completion of implementation
of the prototype. The Appendix B3, describes how events of Schedule followed.

6
2. Background Reading and Research The Background Reading and Research schedule is illustrated in Appendix C, using Mind Map.
2.1. Research Aim Web-based communities have rapidly become important places for people with different interests and
background knowledge but common goals to collaborate, share and develop a new knowledge base.
Author’s first target is to discover the possible semantic connections between people in order to help
them to work constructively in the community. The second target is to find the semantic connections of
the materials existing in the community, in order to help users find materials related to the keywords
provided. Consequently, in order to help readers understand all the terminologies and notations
surrounding semantic connections, community and community data, this part of the report will discuss all
the relevant definitions, tools and methods that are used during the design of this project.
2.2. Community Background The term community carries various meanings, types, characteristics and purposes. In general, it is
pointed out that community can be defined as a particular type of social system that is distinguished by
characteristics [3] such as:
1. Users of a system can easily recognize their relationships and areas of common interest with other users
2. The system is persistent and has continuity
3. The operations are dependent on voluntary cooperation
4. The system is multifunctional
5. The system is not only complex and dynamic, but also large enough to make instrumental relationships predominate
6. There is a geographic element which is associated with its definition as well as basic boundaries
However, that is not the only description of the term community. According to Christenson and
Robinson, community has many standard definitions that are sufficient in most situations but they vary in
terms of the elements included. Consequently, it is difficult to explore all the meanings of communities.
Therefore, the idea that best fits in this project’s approach adopted and points out that community is the
environment that is characterized by membership, influence, integration as well as the fulfilment of needs
and emotional connection [4].
Types of Community
The term community is not only open to various definitions but also can be of various types such as
Geographic Community, Community of Culture and Community Organizations. The type of community
adopted in the research described in this report is the Community of one Organization. This is because
the participants of the LeARN community will be Researchers, students and staff who are within the

7
University of Leeds only. People who are not registered at the University of Leeds will have access to the
LeARN Community but they will not have the necessary permissions to download material or use the
other functionalities of the system. Moreover, the community is categorized into:
• International Community: participants of this community are the governments of the entire
world or a group of them and all have a specific international relation.
• Community of Practice (CoP): users are participants of groups who learn to do their work
together, even if they are experienced or not and sustain their success on discussion about their
work together. It arises as people address recurring set of problems together [5].
• Virtual Community (VC): is a community where participants use words on screens to exchange
pleasantries or argue, engage in intellectual discourse, conduct commerce, exchange knowledge,
share emotional support, make plans, brainstorm, gossip, find friends and lose them, play games,
create a little high art and a lot if idle talk. Virtual communities support everything people do in
real life, leaving their bodies behind. [6]
• Community of Interest: a collaborative group of users who exchange information in pursuit of
their shared goals, interests, missions, or business processes and who therefore require a shared
vocabulary for the information they exchange. [7]
Type of LeARN Community:
The Community of Practice is based on the key idea of “Legitimate Peripheral Participants” where users
inexperienced in the research area expand their knowledge by working on the periphery of the
community and as soon as they prove their competence, are invited to play more important roles by
completing much more important tasks. In addition to this key idea, it encourages inexperienced users to
rate the publications existing within the community. Since knowledge is inseparable from practice, this
benefits them due to the fact that they participate in expert activities and as a result broaden their
knowledge on a specific area. In general, in a Community of practice all users are active members. They
learn how to participate by learning the traditions, ideas and vocabulary of the group they related to.
However, having similar work doesn’t necessarily imply this is a community of practice. It may simply
be a community of interest. In a community of interest, it is presumed that users have a similar way of
working, related ideas to discuss, a way of interaction, shared experiences and common way of thinking
about the specific research area [8]. As a result, the most important things that keep members working
together within the community are the shared learning and interests. A Community of Interest is more
task-based instead of knowledge-based [5]
Taking into account the above clarifications, the term that best describes the LeARN Community is the
Community of Interest. This is due to the fact that the participants of the LeARN Community want to

8
find materials related to their interest in a particular research topic. They can the find the material that
other people are interested in. The benefits of this community lie in its ability to identify how users can
be related. The interested area/category, the materials being downloaded, uploaded or ranked and
generally the ways that each user interacts within the community are the main characteristics that will be
identified and related for each individual. As a result, each user can find within this community other
users that share common interests in order to collaborate and find useful material for their topics.
Consequently, according to the definition of the communities and categories described above as well as
the way users in our approach interact, the Community of Interest can best describe LeARN community,
despite the fact that it can also characterized in some cases as a Community of Practice. The main overlap
with a Community of Practice lies in how it offers similar benefits and impacts people working together
exchanging material and keywords.
Characteristics of the LeARN Community
The main characteristics of the Community in this project are:
Actors of Community:
The Research Community consists of the following actors:
1. Researchers,
2. Students coming from different departments,
3. Staff who currently work within the University of Leeds.
Activities of Actors within the Community:
The benefits and activities of the members in this small functioning community are the following:
1. Users from different disciplines and knowledge background will find material by entering some keywords into the system,
2. Users can rank material returned if they believe that it is what they expected when entering the keywords into the system,
3. Users shall share materials. For example, users will download and upload material.
4. Users shall rank materials they like from 1 to 5 in order to leave their feedback and help other users.
5. Users shall identify which other users downloaded a particular piece of material.
6. Users shall find all the publications of a particular author through references to the author name existing in any material.
7. Users shall conduct advanced search by choosing synonyms that the system returns in the event
that the user is unable to describe their exact requirements and therefore, the initial keywords
didn’t return the expected materials.

9
Size of Community:
Despite the fact that Communities of Interest may vary from fairly large, to relatively small, for the
purposes of this paper, the LeARN Community will assumed to be of a small size.
2.3. Semantic Connections “Definition 1 (Semantic Connectivity): Two entities e1 and en are semantically connected if there exists a
sequence e1, P1, e2, P2, e3, … en-1, Pn-1, en in an RDF3 graph where ei, 1 ≤ i ≤ n, are entities and Pj, 1
≤ j < n, are properties. “ [35]
Semantic connections in the LeARN Community data can refer to the possible meaningful relations that
may exist between not only the content (data which are publications) but also between members but the
term can be associated with many descriptions. In the particular Community, semantic connections
derived from activities achieved by users. Author assumes that there can be connections which members
are unaware of.
Firstly, taking into account that users are from diverse departments probably with completely different
knowledge background author can discover a connection between them by examining their interests, the
material they have worked with and the research area in which they are most active. For example, this
can be shown if we design the following scenario:
Two people share an interest in the same material, they have searched for similar keywords or they are
interested in the same research area even if they are from different disciplines. Therefore, these two
people should have a connection as they have similar interests, research area and possibly common
topic, which means that those two people have a semantic connection.
Secondly, the community data that will be used by researchers consists of materials such as papers,
articles and books. Author cannot only define semantic relationships between users and their interests but
also between the materials they rank and download. For example, this can be shown if we design the
following scenario:
Material-1, Material-2 and Material-3 are available in the Community database. User-1 is downloads
Material-1, User-2 is downloads Material-1 and Material-2 and a User-3 is downloads Material-2 and
Material-3. Consequently, since users choose to download some common materials, it can be assumed
not only that they share common areas of interest, but also that the three materials share common
3 Resource Description Framework

10
content and could effectively be clustered into the same research area. Therefore, those three materials
have a semantic connection.
The LeARN Community includes not only people but also learning resources such as publications of the
staff of the University of Leeds. With continued interaction between people, resources and community,
sharable resources accumulate become better organized and a wider knowledge base is developed.
Consequently, semantic relations are discovered. The increased resources, relations and knowledge in
turn help in discovering more relations [10].
In this section of the report the input data formalized so that a conventional structure of a community
considered by material sharing, aiming to help users improve their knowledge of a particular topic.
Therefore, semantic connections such as those described above, will be exploited, enabling the LeARN
Community function to be described as follows:
The input data will be:
• Keywords associated with each material
• Materials - Publications of KRR (Knowledge Representation and Reasoning Group)
• Author’s information
• The user who shared or accessed specific materials
• A list of KRR group teams
The types of semantic connections between LeARN users will be:
• The relationship between users according to the material Downloaded
• The relationship between users according to the material they are related (Like)
• The connections between keywords prompted to the system by users (Liked / Don’t Liked)
• The connections between materials according to the rank value assigned to each material by users
• The similarity of the materials downloaded by each user, taking into account its keywords. In
case a piece of material does not have associated keywords, the keywords provided by the user
system consider in order to return the particular material which is ranked by the user as well
related (liked).
The aim of this work is to use algorithms, methods and tools that can discover the semantic connections
of the users. The common interests that may connect people may be unknown by them, so author aims to
discover them in order to give them the opportunity to work together, taking into account the possible
semantic connections described above.

11
2.4. Semantic Similarity “Definition 2 (Semantic Similarity): Two entities e1 and f1 are semantically similar if there exist two
semantic paths e1, P1, e2, P2, e3, … en-1, Pn-1, en and f1, Q1, f2, Q2, f3,…, fn-1, Qn-1, fn semantically
connecting e1 with en and f1 with fn, respectively, and that for every pair of properties Pi and Qi, 1 ≤ i <
n, either of the following conditions holds: Pi = Qi or Pi ⊆ Qi or Qi ⊆ Pi. We say that the two paths
originating at e1 and f1, respectively, are semantically similar.” [35]
The aim of this section of the report is to define the term semantic similarity that best fits to this project.
Before attempting to describe what semantic similarity is, let consider the following scenarios:
• The similarity between two words correlates with the common attributes/characteristics one word shares with the other. The more shared and common attributes/characteristics the two words have the closer similarity they have.
• The similarity of two words correlates with their differences. That means, the more differences one word has with any other word(s), the less possibility there is to be similar.
• The maximum similarity between two words occurs when they are exactly the same. [22]
According to the above scenarios, the semantic similarity of two words could be the measure that defines
the similarities and the differences of the features/characteristics between those two words. Significant
characteristics could be some fundamental definitions or connotations of a particular word. For example,
the term {dog} could have as a connotation {has four feet}. Based on this idea, the term {dog} has much
more semantic similarity with the term {cat} than the term {computer}.
Usually, the measure of the similarity is displayed as a score (number) that represents how similar or
different two words are. Of course, this score does not always correspond to people’s way of thinking as
soon as a human may find a correlation between two words from his point of view and finally point out
that the words are semantically similar in some way. Consequently, programmers and researchers are
designing algorithms for discovering semantic similarities of the words using an additional percentage on
the score in order to be closer to all the human similarity reasoning point of views and judgments. In the
next section, we discuss the semantic similarity as well as semantic relatedness of the words.
According to Nuno Alexandre Lopes Seco [14], there are four approaches that can be used in order to
compute the semantic similarity [15]., those approaches are:
1. Ontology-based approaches: Uses ontology such as Wordnet in order to find the relations of its
nodes and discover the score of similarity.
2. Corpus-based approaches: Uses a body of text (corpus or corpora) in order to identify co-
occurrence relations from the statistical relations that exist. This aims to discover if a semantic
affinity exists between two words. This can be achieved if two words frequently occurre together.
3. Information Theoretic approaches: Uses a hybrid approach that considers not only corpora but

12
also ontologies. It is based on Information Content that stems from the information theory.
4. Dictionary- based approaches: Uses a machine-readable dictionary aiming to identify relations,
which may exist between the various concepts.
Comparing the various approaches of similarity that are also computational approaches to semantic
relatedness, Dictionary-based approaches are the most relevant at the first stage to be used for this type of
project. At a further stage, corpus-based approaches may be used as an extension of this project or as
future work. This section of the report discusses the algorithm that calculates the semantic similarity
between two words.
As shown in section 2.5.1, a word can have more than one sense that can lead to ambiguity. For example,
the term {community} has 6 senses. Therefore, the algorithm [16] that is used in order to discover the
semantic similarity works as follows:
The complete algorithms that are used for discovering semantic similarities in LeARN community data
can be found in the Implementation chapter.
2.5 Semantic Relatedness The previous section discussed the semantic similarity between two words. This section, discuss how two
words could be semantically related based on their meaning (similarity of meaning). This is due to the
fact that it is essential to distinguish between similarity and relatedness, as the two terms are often used
incorrectly. According to Philip Rensik, semantic similarity represents a special case of semantic
relatedness. For example, the terms {car} and {gasoline} have a closer relation than the terms {car} and
{bicycle}, but it is true to say that the latter pair are more semantically similar. This is because, {car} and
{bicycle} share features such as {have wheels}, {transport people or objects}, and many more [10].
Pertaining to the above example, it is obvious that two terms may be coupled (i.e cars require gasoline to
function) but they may not have any common features / characteristics and consequently in accordance
with the definition described in the previous section, are not semantically similar [11] .
By associating semantic similarity and semantic relatedness, author can conclude that two words could be
semantically similar and semantically related when and only when they share common features, common
characteristics, and many more shared senses. This can be best explained by recalling the above
Initial Query: “Distance Learning” Distance has 6 senses and Learning has 2 senses in WordNet 3.0
To get optimized query: 1. Calculate similarity score of each pair of concepts as 6*2 = 12
similarity score is returned 2. Choose the sense with highest value of similarity score
3. Replace the original query with synonyms of a sense that has the highest similarity score.

13
example with the {car} and {gasoline} as well as by another example; The term {motherboard}, is part-
of the term {computer}. Taking into account these examples, is becomes crucial to focus on the different
relations of meronyms (Part-of) , antonyms ,etc). On the other hand, it is important to check the relations
of hyponyms and hypernyms of the two words. For example, the terms {car} and {bicycle} have
common features which arises from the term{vehicle} and consequently both {car} and {bicycle} are
part of the term {vehicle} ( is-a-kind-of) .
The above descriptions and examples, aim to give an overview of how two terms can be related. In this
project approach, one example of semantic relatedness could be the following; User-1 provide as
keywords the term {taxonomy} and he is member of the Visualization research area. User-2 provides as
keyword the terms {Biological classification} and he is a student so doesn’t belongs to any research area.
User-3 enters as keyword the terms {Linnaean taxonomy}. Despite the fact that all three user’s keywords
seem to be semantically related and especially User-1 to User-3, User-2 and User-3 are more
semantically similar and related as the keywords they have provide have exactly the same meaning, sense
and features.
In addition to the above, a different way of measuring the relatedness of two words is to measure their
semantic distance [12]. For example, using a dictionary like WordNet4, it is possible to measure, the
distances that two significations have, and therefore discover how related they are. This can achieved by
considering that, the closer two significations (words) are, the more related they are. Some measures used
to calculate this distance are Leacock-Chodorow, Rensik, Wu-Palmer, and many more [20]. The Wordnet
dictionary is semantically-similar-based rather than linguistic-similar-based thus by measuring the
distance of the two words then can discover how related or unrelated they are.
As an example, the measure of semantic distance [12] is described in the following scenario:
We assume that we have the following pairs of keywords with the similarity scores shown. The keywords
entered into the system by the user are: sim(k1,k2) = 0,1 ; sim(k1,k3) = 0,2; sim(k1,k4)= 0,3. Based on
the above measures, it is obvious that there exists a constant growth of 0,1 between each similarity
assessment. At this stage, if we assume to measure it in different way, we have: dist (k1,k2)=10;
dist(k1,k3)=0,2; sim(k1,k4)=3,33. Now, we get a difference of 5 between the first pair and a difference of
1,7 between the second
Therefore, it is obvious that when calculating correlation values we get erroneous results. The
implementation of LeARN prototype, uses sim(k1,k2) rather than dist(k1,k2). More details about how
this works are discussed in chapter 4.
4 http://wordnet.princeton.edu/

14
2.6. Functional Requirements of the LeARN Community According to Summerville [13], functional requirements should describe what the system should do in
detail. This aims to discuss the inputs, outputs and exceptions of the software that is created. This section
of the report provides the functional requirements of LeARN Community prototype.
The input data of the community was discussed in section 2.3 and considered in this section. In addition
to this, the phase of this community is functioning. As a result, this part of the research starts by
providing all the elements that relate to the functioning of this knowledge sharing community. This
community consists of a list of users U, a set of Materials M, and a set of material ratings R.
Consequently, the LeARN Community environment E, will be defined as E:{U,M,R}. Since the
environment E is changing all the time, it means that the user performs various actions on it.
Those actions are:
• Sign_Up : a user shall be able to register to the community
• Sign_In : a user shall be able to log in to the community
• Sign_Out: a user shall be able to exit the community
• Download_Material : a material could be downloaded from the community by a user
• Upload_Material: a new material could be uploaded by a user
• Rate_Material: a user shall be able to assess how related to the keywords prompted to the system a particular material is
• Rank_Like: a user shall rate a material to assess how interesting he found a particular material
The description of the actions performed in the environment of the community, are going to be stored in
the database (section 3.1, figure 4). Appendix D analyzes all the information about the entities of the
database.
2.7. Tools and Methods In this section of the report, author discuss the part of our research that focuses on the identification of
various tools and methods to be used to discover semantic connections in the Community data based on
the semantic similarity of the data. The aim of this research is to find the most compatible tools and
methods and apply them to our prototype so that it will achieve its goal. In order to achieve this goal, the
functionality of the LeARN Community Environment considered as discussed in previous sections and
how these actions can practically formulated. The tools we have chosen to use are the following:
• Wordnet: [22] is a semantic lexicon for the English language. It groups English words into sets of
synonyms called synsets, provides short, general definitions, and records the various semantic
relations between these synonym sets. It was developed at Princeton University.

15
• Wordnet MySQL Database: is a ready-to-use WordNert database, designed by Bernard Bou, and is
available from Princenton University. It is available in MySQL, PostgressSQL, Sqlite, HsglDB and
Derby. [36]
• Sphider Version 1.3: is an open source web spider and search engine. It includes an automated
crawler, which can follow links found on a site, and an indexer that builds an index of all the search
terms found in the pages. It is written in PHP and uses MySQL as its back end database. [37]
• Wordnet Similarity: “implements measures of similarity and relatedness that are all in some way
based on the structure and content of WordNet.” [28]. It is a package developed by Ted Pederson et
al. This package has a Wordnet::Similarity API which receives two words and applies computer
measures in order to calculate the semantic similarity value of the particular words. It is based on the
WordNet English lexicographic dictionary. [38]
2.7.1. Wordnet: WordNet is a semantic electronic dictionary which is based on the meaning / definition of the words as
well as on the semantic relationships a particular word may have with any other word. All the words are
semantically ordered instead of alphabetically ordered. Thanks to the semantic connections, the meaning
of the words of a particular language can be correlated, designing a Network of Definitions and that is
exactly the network illustrated in WordNet. Its design derives not only from the psychological but also
the from the linguistic theories based on how lexical information is structured and stored in the memories
of English people or other people who speak and have a well versed background in the English language.
WordNet was first developed in Princeton under the direction of Professor George A. Miller (Principal
Investigator) for the English language. Due to its huge success, programmers began the design of
WordNets for other languages such as EuroWordNet5 (Dutch, Italian, Spanish, English, French, German,
Czech and Estonian), Balkanet6 (the Balkan languages Bulgarian, Czech, Greek, Rumanian, Serbian,
Turkish), etc. WordNet is designed to use four syntactic categories. Thus, it saves especially words that
are in one of the four parts the speech (POS): Nouns, Verbs, Adjectives and Adverbs.
WordNet 3.0 database consists of 117.798 nouns grouped in 82.115 set of synonyms, 11.529 verbs
grouped in 13.767 sets of synonyms, 21.479 adjectives grouped in 18.156 set of synonyms and finally
4.481 adverbs grouped in 3.621 sets of synonyms. In total it consists of 155.287 records and 117.659 sets
of synonyms. According to WordNet 3.0 database statistics [15], WordNet 3.0 database consists of
147.278 noun, verb, adjective, and adverb strings. All exist only once. Despite the fact that many strings
exist only once within a syntactic category, strings may belong to more than one syntactic category.
The main monad in such a network is a definition that is represented from a particular word, a particular
explicative definition (gloss) and all the possible synonyms that can represent the particular word 5 http://www.illc.uva.nl/EuroWordNet/ 6 http://www.ceid.upatras.gr/Balkanet/

16
(synonym sets - synset). The phrase “all the possible synonyms” can be explained as the set of words all
located in the same community / environment and each can be replaced by any other word without
changing the initial meaning. For example:
The set {ambulance, hospital} is a set of synonym words, which can be defined as follows:
Ambulance is a vehicle, equipped for carrying sick and wounded persons to and from hospitals.
The set {car, auto, automobile, machine, motorcar} is a set of synonym words of the English WordNet
which can be defined as follows:
Wheeled motor vehicle, usually propelled by internal combustion engine
Moreover, since all the words that are synonyms are grouped in order to create sets of synonyms, each
synonym set (synset) represent a concept. For example, the word “community” has three meanings as
shown below:
Figure 5: The noun community has 6 senses (WordNet screenshot)
Each word corresponds to a particular set of synonyms that describes a meaning of the particular word. In
case the word has various definitions/meanings, then it is displayed in many places of the hierarchy
(WordNet organizes the definitions corresponds to each particular word in increasing order, according to
the frequency the word is used). The connection of the words is achieved by discovering the relations
exist between them. According to WordNet, relations can be distributed in two categories:
1.7.3 Semantic Relations: are relations defined between the set of synonyms (synset) that can be
related. For example, hyponym, hypernym, etc
1.7.4 Verbal Relations: are elations defined between the set of words such as: “Antonym” in order to
describe two words that have opposite meaning, “Derived from” in order to describe two words that the
one is the derivative of the other.
To sum up, the connections supported by WordNet are shown in the figure below:
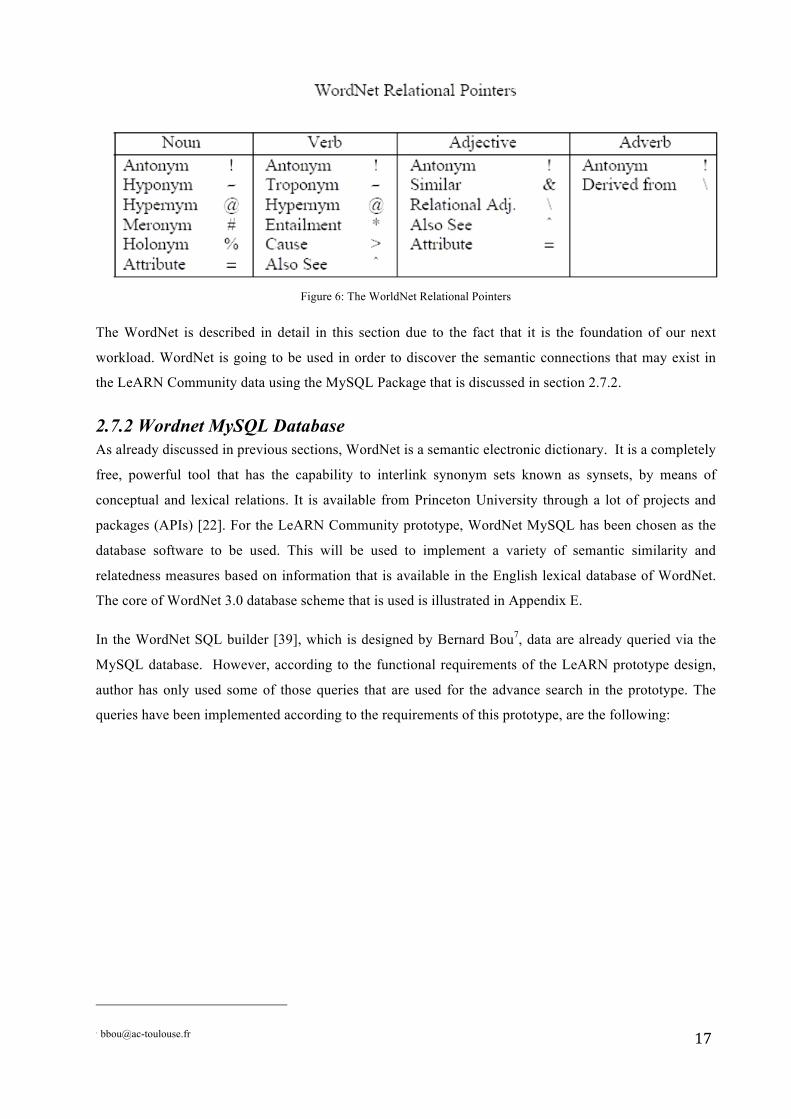
17
Figure 6: The WorldNet Relational Pointers
The WordNet is described in detail in this section due to the fact that it is the foundation of our next
workload. WordNet is going to be used in order to discover the semantic connections that may exist in
the LeARN Community data using the MySQL Package that is discussed in section 2.7.2.
2.7.2 Wordnet MySQL Database As already discussed in previous sections, WordNet is a semantic electronic dictionary. It is a completely
free, powerful tool that has the capability to interlink synonym sets known as synsets, by means of
conceptual and lexical relations. It is available from Princeton University through a lot of projects and
packages (APIs) [22]. For the LeARN Community prototype, WordNet MySQL has been chosen as the
database software to be used. This will be used to implement a variety of semantic similarity and
relatedness measures based on information that is available in the English lexical database of WordNet.
The core of WordNet 3.0 database scheme that is used is illustrated in Appendix E.
In the WordNet SQL builder [39], which is designed by Bernard Bou7, data are already queried via the
MySQL database. However, according to the functional requirements of the LeARN prototype design,
author has only used some of those queries that are used for the advance search in the prototype. The
queries have been implemented according to the requirements of this prototype, are the following:

18
Notions and terminology that are used in the queries description according to [17] are proposed here in
order to describe what each terminology means:
Lemma: “is the string that represents the word”.
Synset: “A synset can be roughly viewed as an entity of semantic information. It is a set of
words that can be substituted for each other in some sentences (but not necessarily all possible
sentences) without changing its truth valuation. A word can also be present in more than one
synset, because a word can have several meanings”.
Sense: “A sense in this context is the association between the syntactic entity (a word) and the
semantic information it carries (a synset).”
This part of the report discusses how author implement each of the queries:
1. The first SQL query ($query_03), consists of 4 SELECT statements.
a) SELECT (morph)

19
FROM morphmaps
INNER JOIN words USING (wordid)
INNER JOIN morphs USING (morphid)
WHERE lemma = ‘$word’
This query uses the SELECT DISTINCT in order to select only the different (distinct) morphs that exist
in the morphmaps table, which is in the database.
Using the INNER JOIN, one query retrieves, the wordid and morphid from the tables words and morphs
respectively.
Using WHERE, only the lemma that is the same with the input word ($word) is selected. The WHERE
clause is the condition of the SELECT query.
The above SQL Select QUERY returns all the possible morphs that a lemma may have.
b) SELECT DISTINCT (lemma)
FROM morphmaps
INNER JOIN words USING (wordid)
INNER JOIN morphs USING (morphid)
WHERE morph = '$word'
This query uses the SELECT DISTINCT in order to select only the different (distinct) lemmas that exist
in the morphmaps table, which is in the database.
The procedure that is followed in order to retrieve wordid and morphid of INNER JOIN is the same as in
1. Using WHERE, the morph that is the same with the input word ($word) is selected.
The above SQL Select QUERY returns the lemma that is the same with the input word.
c) SELECT synsetid, lemma, SUBSTRING (definition FROM 1 FOR 60)
FROM wordsXsensesXsynsets
WHERE synsetid IN (
SELECT synsetid
FROM wordsXsensesXsynsets
WHERE lemma = '$word') AND lemma <> '$word'
This query uses the SELECT query in order to select the synsetid, the lemma and the definition of a
paricular word. The SUBSTRING function is used in order to return only a part of a character string.
Here, it returns only the definition that matches with the particular synsetid and lemma.
Using WHERE statement, the synsetid is selected that is in SELECT query d.
d) SELECT synsetid
FROM wordsXsensesXsynsets

20
WHERE lemma = '$word'
This query uses the SELECT query in order to select the synsetid from the database table
wordsXsensesXsynsets that completes the WHERE condition which requires the lemma to be the same
with the input word('$word').
Therefore, this SQL Select QUERY returns the synsetid of the lemma that is the same with the input
word('$word').
Thus, $query_03 returns the morph of the input word ($word). Using the one SELECT query into the
other, aims to retrieve the morph of a word only once avoiding repetition.
2. The second SQL query ($query_06), consists of 3 SELECT queries, all working as described above.
The only difference here is that it retrieves definition and synsetid from the Views of the Database rather
than a table of the database. The components View of the database consists of Virtual tables which are
components of wordnet 3.0 database. The power of those virtual tables lies in their ability to execute a
particular query and retrieve the desired information in a single query rather than run the whole code and
queries. Here, the View table that is used is the wordsXsensesXsynsets from where it retrieves synsetid ,
lemma and the definition.
An example which shows the results by running the 2nd and 3rd SELECT query, with input word
“model” , can be found in Appendix F.
Therefore, the complete query ($query_06) returns the lemma of the input word ($word) that is not exist
in the results in the table above, only once.
3. The third and final query ($querysynth) that is used returns the lemma from the wordsXsensesXsynsets
View table.
For example, if this query runs for the input word “model” the results returned are: modelling,
simulation, theoretical account, framework, example, good example, exemplar, manikin, mannequin.
2.7.3 Measures of Relatedness In this section of the report, the author decided to discuss 8 algorithms for measuring semantic similarity
or relatedness. Those measurements were originally based on WordNet English lexical database of
concepts and relations.
1. Resnik: This measurement [23], in based on the information content (IC) that the Least Common
Subsumer (LCS) (most informative subsumer) has. The resulting value is always greater-than or
equal-to zero. It notices that the upper bound of the resulting value is too large and varies
according to the size of the content that is used so that the IC values are determined. According to
[34], the upper bound of the result of this measure is ln(N) where N is the number of words

21
existing within the corpus. The formulas that should be applied in order to get the appropriate
similarity value are:
freq(w)= then, p(c)= , followed by p(w)=
where words(w) is the total number of words that exists in the term w, and N is the total number
of words that exists in the corpus. Thus, the information content (IC) of a word can be found by:
IC(w)=-‐log(p(w))
Due to the fact that a word may have multiple senses, the total number of similarity value can be
found by computing the maximum information content value as follows:
simres(w1,w2)= IC(w)
S(w1,w2) is the total number of senses exists within w1 and w2.
However, according to Nuno Seco the probability of existence of words depends on the number
of hyponyms that exists within the Wordnet. This is because, the Wordnet is semantically
structured rather than lexicographically structured. Therefore, the final measurement that can be
used in order to use the Resnik measure in to compute the similarity of w1 and w2 can be found
as follows:
ICwn(w)=1-‐
Where hypo(w) is the total number of hyponyms within the word, w.
2. Lin: Lin is a measure based on the information of content that two words have [30]. It discovers
the semantic similarity of two words by computing the amount of information that is contained in
the commonality between the two words, divided by the amount of information in the
descriptions of the objects. [22] The formula of the Lin measure is:
simlin(w1,w2) = sim
3. Jiang-Conrath: Jiang and Conrath suggested a measure that is based on the information of the
content by calculating the semantic similarity/distance between words and concepts and then the
semantic similarity of the commonality of the two words. [24] The formula they used for
calculating the distance is:
distjcn(w1,w2)=IC(w1)+IC(w2)-2.IC(LCS(w1,w2))
and they continued by calculating the semantic similarity that exists between the two
words by the formula:

22
simjcn=
4. Leacock-Chodorow (LCH) : is a measure that is based on the hierarchies’ is-kind-of that exists
in the WordNet English lexicographic database aiming to calculate the shortest path between two
synonym sets (synsets). The noun hierarchies that exist in the WordNet are assumed to have a
shared entity. That means, the two entities have at least one shared path. Aiming to determine
how semantically similar the two synsets are, this measurement uses the following formula:
LCH(w1,w2)=-log( )
In the above formula, the shortest_path(w1,w2) denotes the shortest path length between w1 and
w2 and LCH executes the Leacock & Chodorow measure The D is the maximum depth of
WordNet noun hierarchies. When this measure is applied, the weights of the hierarchy links are
assumed to be equal. According to [31,32], this assumption is incorrect. This is because, the
synsets that are at the top of the hierarchy, are more semantically similar than those are close to
the leaf of the hierarchy. However, this measure is very simple and that is its main advantage.
5. Hirst-St.Onge: is a measure, which is based on the WordNet Eglish Dictionary. The dictionary
is used in order to discover how semantically related two words are. The semantic relatedness
that is measured here focuses on the similarity of two words rather than their synsets. Hirst and
St.Onge propose that measure, in order to calculate the relatedness values that correspond to all
the possible concepts (i.e words) rather than only hybernyms and hyponyms. All the links of
WordNet, are clustered in three categories. Those are: the Upward: for representing the Part-Of
relations, the Downwards: for representing is-kind-of relations and finally the Horizontal: which
represents the opposite word meaning. In addition to those categories, three levels of links
relatedness exist.[26] Those are: extra-strong, strong and medium-strong.
For strong relations, the weight is assigned to be 2-C, but the weight of any medium-
strong path can be computed by:
Weight = C-Path_Length-k*Changes_in_Direction
In the above formula, C and k are constants. Therefore, the longest path between the two words
is, and the most exchanges on path’s directions performed, the smallest weight of the particular
semantic relatedness is [33].
6. Wu-Palmer: suggests a measure of semantic similarity, which is based on the distance and depth
of ontology. [27] The formula that is applied is:
simwup(w1,w2)=

23
From the above formula, which is discussed in [27], this measure takes into account the distance
between each of the two synsets with the support of the Least Common Subsume, LCS as well as
the distance of LCS from the root of the hierarchy. In the above formula, w1 and w2 are the two
synsets that are considered how similar they are. Moreover, lcs is the least common subsumer
(LCS) and root is the hierarchy root.
7. Banerjee-Pedersen: That is an extended overlap measure [29] where relatedness between two
input keyword synsets (k1,k2) computed and the glosses of those synsets that are related to k1
and k2 through explicit relations that are provided in WordNet compared. It starts by setting a
non-empty list (RELS) which consists of the set of relations that have either one or more
relations. That is set as follows:
RELS { r | r is a relation defined in WordNet}
The above formula, assumes that each relation exists (RELS) has a function which has the
same name where receives as input a synset and returns the gloss of one or more synsets that are
related to the input synset by the designated relation. Then, it continues by appending in the
RELS list set of pairs of relations retrieved from the relations of the above equation. That is pairs
where: pair (r1,r2) is chosen, (r1,r2 RELS) and thus, the pair (r1,r2) should also be chosen in
order to have a reflexive relatedness measure. The reflexive relatedness measure is defined as
relatetedness(k1,k2) = relatedness(k2,k1). Therefore, Banerjee and Pedersen in [29] define the
RELPAIRS set as follows:
RELPAIRS = {(R1,R2) | R1,R2 rels;
IF (R1,R2) RELPAIRS, then
(R1,R2) RELPAIRS}
They finally use a score() function which accepts as an input two glosses, then discovers all the
phrases that overlap between them and finally returns a score. Hence, the relatedness score for
k1, k2 found by [29]:
relatetedness(k1,k2) = score( R1(k1),r2(k2)) (r1,r2) RELPAIRS
8. Patwardhan-Pedersen: discussed in [28] the measure that computes the depth of the nodes
rather than the edges. It has been recently introduced from Patwardhan and Pedersen and is based
on the Gloss Vector measure. The vector measures incorporate information from WordNet
glosses. “Thus a co occurrence matrix for each word that used in the WordNet glosses from a
given corpus created, and then each gloss/concept with a vector that is the average of these co
occurrence vectors represented” [28].
24
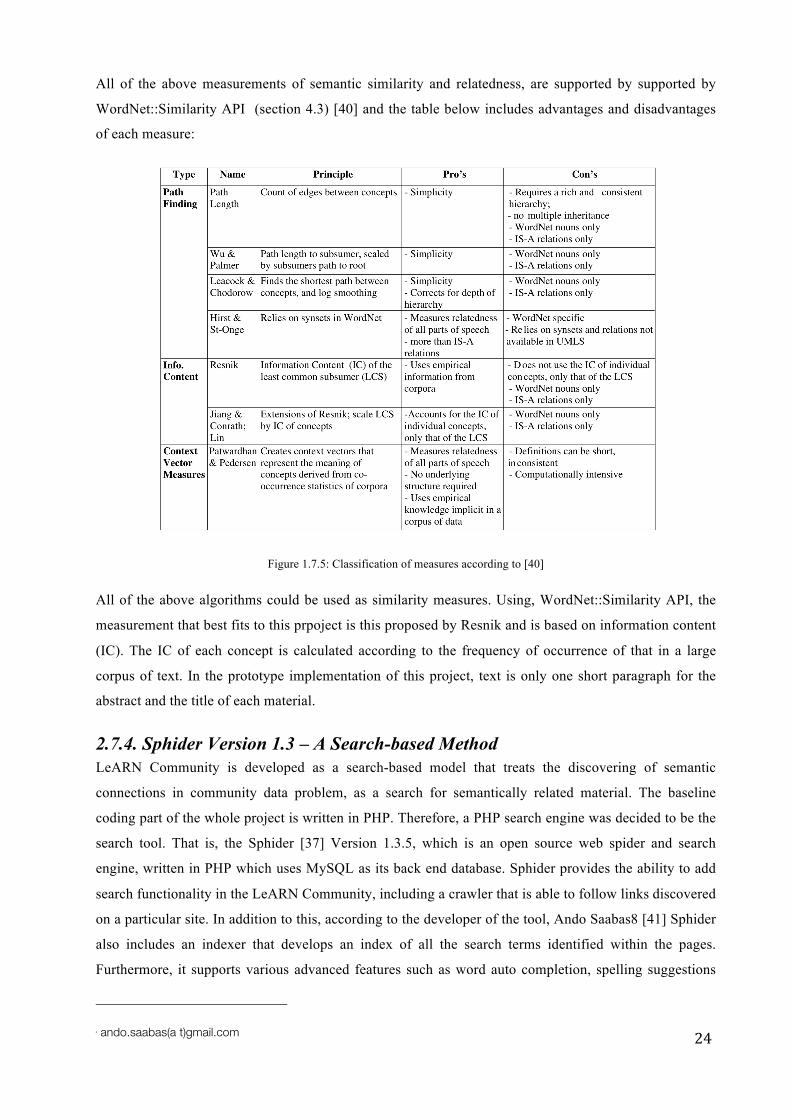
All of the above measurements of semantic similarity and relatedness, are supported by supported by
WordNet::Similarity API (section 4.3) [40] and the table below includes advantages and disadvantages
of each measure:
Figure 1.7.5: Classification of measures according to [40]
All of the above algorithms could be used as similarity measures. Using, WordNet::Similarity API, the
measurement that best fits to this prpoject is this proposed by Resnik and is based on information content
(IC). The IC of each concept is calculated according to the frequency of occurrence of that in a large
corpus of text. In the prototype implementation of this project, text is only one short paragraph for the
abstract and the title of each material.
2.7.4. Sphider Version 1.3 – A Search-based Method LeARN Community is developed as a search-based model that treats the discovering of semantic
connections in community data problem, as a search for semantically related material. The baseline
coding part of the whole project is written in PHP. Therefore, a PHP search engine was decided to be the
search tool. That is, the Sphider [37] Version 1.3.5, which is an open source web spider and search
engine, written in PHP which uses MySQL as its back end database. Sphider provides the ability to add
search functionality in the LeARN Community, including a crawler that is able to follow links discovered
on a particular site. In addition to this, according to the developer of the tool, Ando Saabas8 [41] Sphider
also includes an indexer that develops an index of all the search terms identified within the pages.
Furthermore, it supports various advanced features such as word auto completion, spelling suggestions
8 ando.saabas(a t)gmail.com

25
and many more. Sphider [37] was chosen as the LeARN community search tool due to the flexibility of
its search functions, which include:
• The ability to support multiple words in the search procedure
• Supports phrase search using “ ” characters
• The ability to support excluding words (such as web –based)
• The ability to perform word steaming (for example for “scheme” also finds “outline” , “schema” and many more)
• Is a really simple template system
Given the user’s desired keywords, the Sphider Version 1.3.5 PHP search engine, constructs search
queries in cooperation with Wordnet 3.0 MySQL [36] package, aiming to discover all the possible
connections which may exist in the LeARN community data. One of the major advantages of the Sphider
crawler is the fact that it returns all the results sorted. It measures how many times (frequency) the
keywords prompted by the user occur in each material and also shows the percentage of this frequency. It
first returns the material which has the maximum frequency of the keywords, second returns the material
in which the keywords exists less times etc, as shown in Appendix G. The title of each returning
publication is associated with a number that represents the frequency percentage of the keywords entered
in the particular material.
2.7.5 Ranking Algorithms “..Ranking of documents is a critical component for today’s search engines.” [42]. This part of the report
deals with the importance of the document ranking procedure in the LeARN Community and details the
ranking algorithm is used. The reason for using a Ranking algorithm is to give users the opportunity to
provide a satisfaction rating for materials of their interest. Therefore, the quality of the matching results
will be improved and more information about connections between the users will be available.
Consequently, semantic connections between users will be more accurate.
In the LeARN Community, the use of a Ranking Algorithm is important and is applied for various
reasons such as:
1. User’s opinions could affect other user’s decisions with regards to which other material to download. This is achieved by recommending materials to a user, based on what other users with similar interests (shared interests) users have ranked.
2. Helps to discover which users are interested in the same materials aiming to create a connection between them. (i.e: People rank the same materials with high score, could be related)

26
Figure 2.7.5a: Collaborative filtering [45]
According to Offer Drori [43], there are several ranking methods which sort results of a search engine
according to the number of appearances of the search terms, or the use of common keywords and many
more. In the LeARN Community approach, the Shpider crawler, is used as the search engine and
Wordnet 3.0 MySQL package, is used as the database and therefore, the ranking algorithm will not affect
the results of a search because this workload will be completed after deep semantic understanding by the
above tools. The central idea of the ranking algorithm is to improve the uncovering of small subgroups of
users that best reflect the user choices.
To begin with, materials are clustered and located in the database according to the subarea the KRR
Group (category) belongs to. Therefore, the algorithm should discover and recommend materials to the
user according to what other users have ranked. For example, if User-1 ranks Material-3 and Material-4
as a 5, then User-2 who also ranks Material-3 as a 5, may also find Material-4 to be interesting. This
could be achieved using explicit or implicit methods of collaborative filtering. However, in the LeARN
prototype, the category that a material belongs to is considered and materials are filtered taking this into
account. Only materials that belong to the same category would be recommended.
The main idea behind collaborative filtering in the LeARN application is to discover each material that is
downloaded and ranked with score grater than or equal to 4 (by users) aiming to match it with other,
similar materials. Each material that matches the input material will be stored in a recommended material
list that will be returned to the user. According to [45,47] this procedure could be distributed in three
phases:
1. Represent the Data
2. Define the neighborhood
3. Make the appropriate recommendations

27
Ranking Algorithm 1:
“Consider users opinions about materials in order to help other users make decisions about which other
material to download.”
Assuming that all user only rate materials they find interesting, the algorithm in Appendix H, selects the
number of distinct rankings of a material as a measure. The metric that is created by values represents the
independent opinions and is used in estimating the worth of a material [44]. Therefore, the analysis that
focuses on materials with the most ratings is completed and the particular Ranking algorithm finishes.
Ranking Algorithm 2:
“We consider rankings to the user based on the materials that have been downloaded together”
Aiming to match the most semantically similar set of a given publication, the algorithm builds a related
publications list. This can be achieved by finding materials that users tend to rank and consequently
download together. We use the algorithm shown in figure 2.7.4b in order to calculate the similarity
between a particular material and all semantically related materials.
Figure 2.7.4b: Ranking Algorithm 2 [46]
Given a similar publications list, the algorithm finds material similar to each of the user’s downloads and
ratings, aggregates these publications, and then recommends the most popular or correlated publications.
This computation is very quick [46], depending only on the number of publications the user downloaded.
For each material in material list, M1 For each user U who rank M1
For each material M2 rank by user U Record that a user rank M1 and M2
For each material M2 Compute the similarity between M1 and M2

28
3. Design Focusing on the research topics discussed in previous section, the intuition behind this part of the report
is to provide us with the main parts of the design process of the LeARN Community prototype, which
would enhance user’s experiences. Firstly, this section identifies the data sources are in the community
such as publications, authors and research groups are in the Knowledge Representation and Reasoning
(KRR) area. Secondly, it devises some scenarios explaining the basis for building the prototype. The
scenarios will also be used in the different phases of application aiming to refer to the various phases of
the LeARN Community application.
3.1. The LeARN Community Data The aim of the community data section is to give a brief overview about what data is available in the
LeARN Community, how it can be categorized and how data relates in the database.
To begin with, the initial idea was to use data from AWESOME or BRAIN existing projects. When
examining the suitability of the data in these existing projects to the LeARN Community, it was decided
that the data would not really be helpful for students of the University of Leeds. This is because the
information did not match material members of the community may search for when doing research.
Therefore, instead of using materials that can be found in the traditional search engines like Google,
Google Scholar, Yahoo and many more, data will be comprised of material written by Staff of the
University of Leeds only. The main concept behind this idea was to include distinguishable data rather
than material which is already available in traditional search engines and make the application more
relevant to students. As a result, the database behind the LeARN Community application will include
applicable ions; papers and articles whose authors are staff within the University of Leeds regardless of
the fact that they may or not be experienced members of the community.
The community environment consists of Users, Materials and Rankings of Materials. Users are registered
in a department of the University and interact in the LeARN community using some keywords and wait
for the material to be returned. According to semantic connections discussed in section 2.3, material may
also be related to the users downloads or ranks. Therefore, material is related to the user requests and the
research group it belongs to. The available research groups of KRR area are Qualitative Spatial
Reasoning, Foundational Ontology, User Modelling and User-Adaptive systems and finally, Program
Analysis. Authors could categorize each material or type (publication, book, paper, etc) depending on
what users prefer. Moreover, each user may want to rank a material, thus another relationship between
material and user’s rankings may exist.
Consequently, when the database is designed, all the above relations are taken into account. To get a view
of the fundamental structure of the LEARN community database, it is necessary to identify the required
information for each of the entities it uses. For example, Users, User Requests, Material, Author,
Assigned_Material, Research Group, Material Categories, Material_by_author, and finally user Roles are
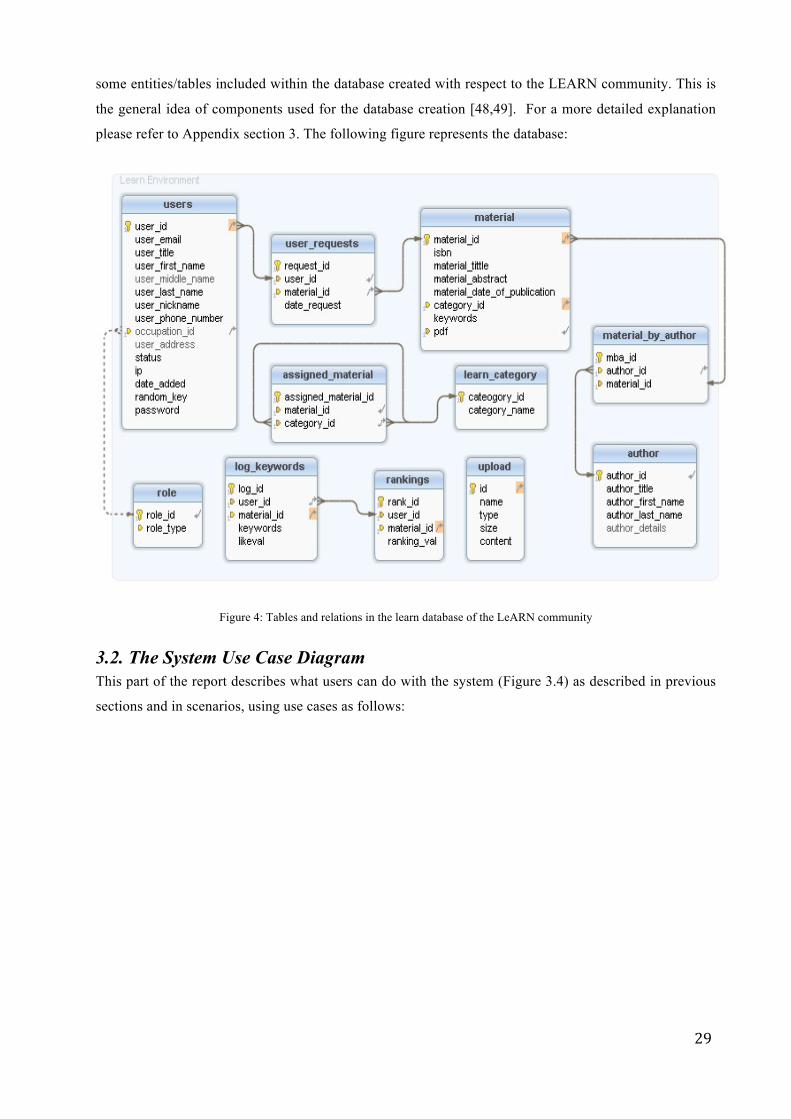
29
some entities/tables included within the database created with respect to the LEARN community. This is
the general idea of components used for the database creation [48,49]. For a more detailed explanation
please refer to Appendix section 3. The following figure represents the database:
Figure 4: Tables and relations in the learn database of the LeARN community
3.2. The System Use Case Diagram This part of the report describes what users can do with the system (Figure 3.4) as described in previous
sections and in scenarios, using use cases as follows:

30
Figure 3.4: System Use Cases
3.3. Application Scenarios Once the data and the data scheme representing the relations of the community data are identified, this
section of the report devises the requirements of the application needs. It was decided that one of the
most appropriate methods to describe the possible actions of users within the community is the use of
scenarios. According to John Wiley & Sons and LeARN environment approach, a scenario describes the
various human activities which are performed within the community in a story that explores and discuss

31
the contexts, the needs and the requirements of the application. Based on this idea, from John Wiley &
Sons point of view, a scenario does not necessarily describe how a software can be used but, considering
the vocabulary or phrases of users, a scenario can be completely understood by the stakeholders
(scenarios can best demonstrate the users view of interactions within the LeARN Community
Environment).
Scenario 1:
John is a new member who is student in the University of Leeds and is interested in finding
papers related to “Semantic Web”. John has no background of what was happening previously in the
community and therefore he is unsure as to whether there are any relevant materials on the research
area he is interested in. When he visits the LeARN Community environment, the system prompts for
username and password. John is not registered and as a result he selects the Membership option from the
options menu (i.e. Home, About, Services, Membership and Contact). The system displays a form
indicating with red stars all the required fields. John completes his details there and submits the form.
The system verifies the details submitted and displays a message confirming a successful submission of
registration. Then, he verifies his registration using the confirmation email received in his email box. He
returns to the homepage and enters his username and password into the system. The system verifies
John’s password and displays the menu of choices (i.e. Home, About, Services, Membership, and
Contact). John chooses the Services option and the system displays the search menu screen. He chooses
to search for publications and enters his keywords in the keywords-field “Modeling Analysis”, then
chooses the Go button. The system displays a list of publications relevant to the keywords but John finds
that none of these are what he was looking for. As such, he decides to select the advanced search button
which appears at the bottom of the search box. The system displays immediately a search menu screen
where John enters the desired keywords and selects Go. At that point, the system displays words onscreen
that are related (i.e. synonyms, morphs, etc) to the keywords entered. Then, John selects the 3-4 words
that he believes best match his search requirements and selects the Advance Search button. The system
then displays a list of publications and he chooses the required publication so that it displays the Title,
Author and Abstract of the particular publication. Finally, John selects the publication to be downloaded
and as soon the download is complete, we may choose to exit the LeARN Community System.
Scenario 2:
George is a researcher in the University of Leeds and he is an existing member of the LeARN
Community. He is interested in finding papers related on “Ontologies”. When he visits the LeARN
Community environment, the system prompts for username and password. George enters his username
and password into the system. The system verifies his password and displays a menu of choices (i.e.
Home, About, Services, Membership, and Contact). George chooses the Services option and system
displays the search menu screen. He chooses to search for publications and enters in the keywords-field
“Ontologies”, then chooses the Go button. The system displays the search results and he chooses the

32
required publication. The system displays the Title, Author and Abstract of the particular publication.
George read the details and decides that the paper is related to the research he is doing. Thus, he
chooses to download it. Waiting for paper to be downloaded he chooses Related_Users link from the
other available options (Related Users, Author Details, KRR Groups). The system then displays a list of
the Community Users who have already downloaded the particular publication. George chooses the first
user at random (Nicole) and notices that the system prompts all the profile details provided by Nicole
and all the materials she read are listed there. Therefore, George looks for more materials that are
related to his research in Nicole’s reading list aiming to discover related papers he was unaware of and
may be beneficial to him. He decides that nothing is related to the particular area of his interest at the
moment and he returns to the previous page and chooses the Author_Details link from the other available
options. The system displays the details available for the author as well as a list of all the papers he
wrote. George finds an interesting paper from the list of writings of that author and selects the download
option. At that time, the system prompts that both downloads are complete and then George exits the
LeARN Community system.
Scenario 3:
Dr. Peter is a Lecturer at the University of Leeds and an existing member of LeARN Community.
He is interested in uploading a paper. When he visits the LeARN Community environment, the system
prompts for username and password. Dr. Peter enters his username and password into the system
incorrectly. The system attempts to verify his password, identifies that the details given are invalid and
displays an error message. Dr. Peter correctly re-enters his username and password and attempts to
sign-in again. The system verifies his log-on details and displays a menu of choices (i.e. Home, About,
Services, Membership, and Contact). He selects the Services option and then from the listed choices he
selects to upload a material. The system displays a form indicating with red stars all the required fields.
Dr. Peter provides the details of the material (Title, Author, Abstract, Keywords, Date of Publication,
and Category) he will upload and then selects the Browse button in order to browse the material he
wants to upload from his computer. At the next stage he chooses submit and the system displays a
message confirming the success of the upload. Dr. Peter then exits the LeARN Community environment.
3.4. Prototype The prototype is a web-based client server application that uses the Wordnet 3.09 dictionary and its
MySQL ready-to-use database10 in order to discover the semantic similarities and relatedness that exists
in the community data. Moreover, it discovers the semantic relatedness of the individuals who are
registered in the community taking into account how semantically similar are the material the users are
interested in and how related their actions are. This prototype aims to give users the opportunity to search
for a particular publication and download it, rank it, find other publications by a particular author, 9 http://wordnet.princeton.edu/ 10 http://wnsql.sourceforge.net/

33
discover other users who are interested in the same material or research area and finally find all the
available semantically related materials. User will achieve all these actions by providing some keywords
to the system. The system analyzes the keywords used by each user aiming to record all the information
about the actions for each member and material. The LeARN Community application does not require
experienced users. This is due to the fact that apart from a Basic Search function, it also supports
Advance Search where it receives the keywords prompted by the user and does a deep semantic analysis
not only of the keywords but also of the materials that are available in the database so that it returns the
most related materials. The semantic search capability of the prototype is a ‘corporation’ of Sphider-
plus11 Crawler and Wordnet 3.0 MySQL package. In addition to this, the Wordnet::Similarity Java API
is also used as an external prototype in order to compute the semantic similarity of two words. All the
connections between users and between materials in this prototype are designed using MySQL queries.
This is because MySQL is a well known tool for the author and that is also the main reason it was
decided to use MySQL Wordnet::Similarity package. Further information about these tools can be found
in section 2.7.
The following figure shows the main functionality steps of the Advance Search function, are inspired by
[16] so that it is clear how the resulting publications are returned to the user:
Figure 3.3: Advance Search Architecture of LeARN prototype
11 http://www.sphider-plus.eu/

34
3.5. Data Selection Data Selection addresses the task of finding the desired material in the LeARN Community Environment.
Without useful data, the system will not be interesting to the members of the community. Since the data
is to be retrieved from the Knowledge Representation and Reasoning Group as discussed in section 3.1, it
was decided to look at the data format, the citation of a particular material and what information about
authors is available. First of all, all the data will be retrieved from the following sources:
Knowledge Representation and Reasoning Group (KRR)
Research Subareas Source
1 Qualitative Spatial
Reasoning
http://www.comp.leeds.ac.uk/qsr/
2 Foundational
Ontology
http://www.comp.leeds.ac.uk/ontology/FOGI-WS.htm
3 User modeling and
user-adaptive
systems
http://www.comp.leeds.ac.uk/umuas/publications.html
4 Program Analysis http://www.comp.leeds.ac.uk/hill/interests/publications.shtml
Figure 6: The table shows where the Community data are retrieved
In the sources shown in table 6, there is a large amount of publications, papers, articles, presentation
slides, notes and many more related to each research subarea. Despite the fact that Geotechnical &
Geoenvironmental Software Directory12 (2010) statistics shows that most the people tend to use word
files (.doc) rather than .pdf files, at the first stage, it was decided to only use data that is in .pdf format.
This is due to the fact that the vast majority of the materials available are in .pdf format. A problem arose
during prototype creation related to the size of each .pdf file. This is important in the uploading stage of a
file as scenario three describes, as soon as the .pdf files available in the sources shown above are too big.
Therefore, not only the data format but also the size of the materials are important and are taken into.
Furthermore, because the data used in the LeARN Community Environment at this stage will be used in
the evaluation stage through the scenarios; each subarea will have 5 papers. This is because we have a
limitation of the sizes of the data files and the data formats. In total, 20 papers will be available in the
community.
12 http://www.ggsd.com/ggsd/format_statistics.cfm

35
In addition to this, as soon as a second scenario presents the relationship of a particular publication and
its author as well as all the other related to that author materials, it is crucial to focus on the information
which can be found for each author and in each material. Usually, material citations in our sources
consists of Title, Category, Year of Publication, Abstract, sometimes Keywords and finally first name
and last name of each author. Therefore, with respect to the authors, the known information are their
Name and the materials they have written only, unless that author is an existing member of the
community, at which time more information could be found in his/her profile. In addition to the above
information, it is already known in which research area the material belongs to as soon as we take into
account from which research subgroup source it was retrieved. Moreover, Keywords are important
components of each material. This is because the tools and algorithms that discover the semantic
similarities and relatedness (section 2.7) of each word, initially use only the title and keywords of each
material. Therefore, in the initial stage of the application design, data that has associated keywords is
preferable to other materials that do not have keywords. In later stages, in the event material does not
have associated keywords a consideration would be to take into account its abstract using corpus
semantic correlations using the appropriate tools.
3.6. Client - Server Architecture Ian Summerville [13, page 249], points out that “The client- server architectural model is a system model
where the system is organized as a set of services and associated servers and clients that access and use
the services”. Based on the same expert, the basic components of the particular model are:
1. Servers, which are used in order to offer services to other sub-systems,
2. Clients, which are used in order to call on the services offered by the various servers,
3. A network, which gives all the clients the permissions to access these services.
The advent of the Internet and the growth of commerce on the World Wide Web have evolved into the
revolution of client-server architecture. According to F. Soesianto and Ismail K. Ibrahim, a web-based
system is a variation on the well known three tier architecture which is designed in order to support the
full advantages of cooperative processing as well as distributed computing. This is achieved using either
the Internet or the intercompany WAN (Wide Area Network) as a network (F. Soesianto and Ismail K.
Ibrahim, 2000). The three-tier architecture [21] supports the following three independent systems:
1. Client components running on local workstations (tier one)
2. Processes running on remote servers (tier two)
3. A discrete collection of databases, resource managers, and mainframe applications (tier three)
The above systems are the three tiers that represent the Presentation layer, the Business logic layer and
the Data/Resource layer respectively. Presentation logic layer in Web-based systems such as the LeARN
Community consist of the Web browser, which is the application interface. It is usually Internet Explorer,

36
Netscape Navigator or Mozilla. The Business logic layer is designed into the Web browser aiming to
interpret the HTML pages in corporation with scripting languages such as JavaScript and VBScript.
Data/Resource is the layer that is used to get or set the data to, or from the database. This layer interacts
only with the database. In the LeARN Community approach, the appropriate database queries are written
so that some information is retrieved and other information is set back to the database.
Based on the idea is supported by the Web Developers Notes, [50] there are three models of client server
architecture:
1. Model 1 of the client server architecture works with static HTML pages
2. Model 2 of the client server architecture works with CGI Scripts
3. Model 3 of the client server architecture works with server side scripting technologies.
The LeARN Community application uses model 3 with the server side scripting technologies (Appendix
K) because that is the most compatible architecture. It involves dynamic response that is generated using
Personal Home Pages (PHP) and Java Server Pages (jsp) technologies. This is due to the fact that PHP is
an open source technology that provides easy access to Internet service. Moreover, the coding part of this
model only embeds the server-side language inside the HTML page that it is interpreted and generates the
final HTML page that is displayed to the client by the browser. Finally, it is crucial to refer to the fact
that the embedded server-script code is not visible to the client because the server only submits the
HTML code. [50]
To describe how the Client Server Architecture is used in the design of the LeARN Community
application, the following scenario is considered:
A student writes 2 keywords (Query Input module) and requests a publication with the closest relation to
those keywords. The request sent from the client through the PHP page passes to the PHP interpreter by
the server along with various program variables. The semantic network (WordNet 3.0) does the similarity
computations and generates the appropriate concept. After this, the query is semantically expanded and
sent to the search engine (Sphider). The search engine discovers the related publications. Then, the
interpreter processes the PHP code and generates a dynamic HTML output. This is sent to the server,
which redirects it to the client. As the browser is unaware of the functioning of the server, it only receives
the HTML code, which it appropriately formats and displays the results on the screen.
3.7. General LeARN Community Architecture Since the essential components for the data of the LeARN Community have been identified in the
previous sections of the report, a proposed general architecture can be devised for prototype design, thus
the general architecture is discussed in this section. The scenarios discussed in section 3.3 are taken into
account and figure 3.7.a, which presents the interactions between Users, WordNet MySQL package and
Material Database Server as follows:

37
Figure 3.7.a: General Architecture of the LeARN Community search
The complete description of this diagram is described at the end of section 3.6 as a scenario. The user
initially prompts to the system some keywords using the web browser. The requested keywords are
passed to the scripting languages, which are clients (PHP and Javascript). Then, the algorithms that are
written as queries in WordNet MySQL package and MySQL server are used so that all the appropriate
synonym sets (synsets) of keywords which are in Wordnet English dictionary database are found. Then,
all the materials that are related to the keywords are passed from the database to the scripting languages.
The browser displays all the appropriate results to the user as HTML pages.
In other words, clients perform some actions through the Internet (HTTP and TCP/IP protocols) using a
web browser such as Internet Explorer, Mozilla, Safari or any other. The request that user/client enters to
the system is passed in the Apache Web Server where the various scripting languages such as PHP and
Javascript execute the appropriate scripts. All the information that is available for user are stored in the
LeARN database using MySQL as the database management system. Thus, by each user request, the
appropriate algorithm is executed and the appropriate information is retrieved form the database to pass it
to the user. This is the 3-tier architecture that is used in figure 3.7.b.
Figure 3.7.b presents the semantic connections in community data in the three layers of the client – server
process as follows:

38
Figure 3.7.b: The Three Layers Architecture of the community data
The main contribution of the illustration of the system in Figure 3.7.b is to show how the various jobs for
discovering the connections of not only users but also materials are distributed.
To begin with, the Business / Logic layer implements the functionality of the LeARN system. This is
achieved by the implementation of the algorithms, tools and methods described in previous sections.
Secondly, the Data Layer provides access to the various external systems. For example, in our prototype,
the data layer provides access to the database described in Appendix E and the core of WordNet 3.0
database. Therefore, this layer provides information such as user profiles, materials, synsets from the
dictionary of WordNet and many more. Finally, the presentation layer provides the system’s user
interface.
Therefore, through the Presentation layer a user enters keywords into the system. The Business layer
executes the appropriate algorithms, tools and methods and retrieves from the database the appropriate
synsets. After that, Sphider crawler searches the database by the queries described in section 2.7.2 for all
the publications (P) that are semantically related to the keywords. In the same layer, the appropriate
actions are performed and all the related materials are discovered in the Data Layer. If we assume that
Mr Orange and Mr Yellow are interested in materials P1 and P10 but Mr Green is interested only in P1 as
shown in the figure above, drawing a baseline about what concepts are considered so that we can
discover which users and which materials can semantically be connected.
These concepts are:
1. How related the keywords prompted by users are?
2. How related the abstracts of the P1 and P10 are?
3. Are the authors of materials the same?

39
4. Does user like the materials?
5. Does the user rank the material with a score greater than or equal to 4?
6. Does the user like the material or not?
All the above concepts are considered, aiming to filter users based on the similarity score they have. In
figure 8, despite the fact that all three users are interested in material P1, only users Mr. Orange and Mr.
Yellow connected because those two are more semantically similar.

40
4. Algorithms Used
4.1 Algorithm 1 Algorithm 1a: Related Users (based on Downloads) Goal:
The main concept behind this algorithm is to discover which users (two or more) have shared interests,
i.e they Download same material(s).
Usage:
A user of the LeARN Community can read the abstract, keywords and title of a material even if they are
not registered. However, only members of the community can have access to the functionality of the
system. Therefore, each registered user has a user_id and has the opportunity to Download a publication.
Two or more users are related if and only if they have Downloaded the same material.
Each user who accesses the full details of a material can identify which other users have downloaded the
particular publication. Thus, the user can navigate through the names of the Related Users displayed in
order to find what other materials they download, rate or rank. This could be helpful not only for
newcomers but also for experienced users who want to quickly discover more materials related to their
search based on other users preferences.
How is applied:
Each time a registered user (user_id) requests a material for Download, the material_id and user_id is
stored in the user_requests table of the LeARN database. Therefore, it is known who requests which
material. When a user downloads a publication (publ), this algorithm is run in order to find other users
that also downloaded it. Then, algorithm 1a creates a user_material_list for each user_id and stores all the
papers that are downloaded by the user_id. It continues by checking which materials of the
user_material_list are the same with the publication that the logged in user downloaded, aiming to create
the connection with all the users downloading the particular material (publ). The user_material_list
clears each time the user changes. The final list, which is the Rel_Users_List, is returned containing all
the users that have downloaded a particular publication.
Pseudo code:

41
Input: user_id, user_request, material_id , publ
//publ is the material_id of the material that algorithm checks to find other people that downloaded it
Output: List with all the Related Users (Rel_Users_List_D) based on downloads
//User_requests_list = [(material_id, user_id),….]
user_material_list = []
For each user_id in user_requests
{
// record that user_id Downloads material_id
add material_id in user_material_list // (user_id,material_id)
For each material_id in user_material_list
{
//check if material_id is the same to publ to create connection
If (material_id == publ) and (user_id not in Rel_Users_List) then
add user_id in Rel_Users_List
}
user_material_list = []
}
return Rel_Users_List

42
The Data Scheme:
In order to determine which fields of the LeARN database would be used for this algorithm, which fields
would be most useful by analyzing the data contained within them are assessed. The following table rows
from the learn database were chosen to be made available:
Table 1a: Table fields made available for query
Algorithm 1b: Related Users (based on Likes)
(Likes determines the Relevance of keywords entered by user with the returned publication)
Goal:
The main contribution behind this algorithm is to discover which users (two or more) have shared
interests, i.e they Like the same material(s). The criteria that should be fulfilled so that a user should Like
or Don’t Like a material are discussed in Algorithm 2. Briefly, a user does not vote as Like a material
according to her/his personal opinion but, according to how the keywords he/she entered to the search are
related to the publication returned.
Usage:
The complete description of Like or Don’t Like votes are described in Algorithm 2. However, this
algorithm, without taking into account how voting works, explains what the role of voting is, so that two
or more users are related. A connection between two or more users can be established not only if they
have download the same publication but also if they vote positively (Like) for the same publication. That
is because for people who Like a material, keywords they used are related to the publication returned to
them by the system. Consequently, it is undoubtedly true to say that those users who Like the same
materials are using shared keywords. Therefore, they search for common materials. As a result, a
connection between those keywords is created.
How is applied:

43
The input of this algorithm is a publication and its aim is to find all the users that Like the particular
publication. Moreover, any registered user of the LeARN Community can vote a material as Like or
Don’t Like. Algorithm 1b, creates a user_material_list2 that stores all the materials voted by each user
positively which means they Like them (likeval = 1). Then, it checks which of the materials in the
user_material_list2 has the same material_id with the material (publ) then the system tries to find which
users positively voted for it. The user_material_list2 deletes its elements each time the user_id changes in
order to store in the material_id’s that are voted for by the next user. The final result of this algorithm is
the Rel_Users_List that consists of all the users who Like the publication which was the input of the
algorithm.
Pseudo code:
The Data Scheme:
In order to determine which fields of the LeARN database would be used for this algorithm, an
assessment is made of which fields would be most useful by analysing the data contained within them.
The following table rows from the LeARN database were chosen to be made available:
Input: user_id, material_id , likeval, publ //publ is the material_id of the material that algorithm runs to find other people that Likes it // likeval =1 if material_id voted as Like or 0 if voted as Don’t Like Output: List with all the Related Users (Rel_Users_List_L) user_material_list2 = [] for each user_id in log_keywords { if likeval = 1 then // Record that user_id Likes the material_id
add material_id in user_material_list2 for each material_id in user_material_list2 { if (material_id == publ ) and (user_id not in Rel_Users_List_L) add user_id in Rel_Users_List_L } user_material_list2= []
} return Rel_Users_List_L

44
Table 1b: Table fields made available for query
4.2 Algorithm 2: User-Based Related Keywords Goal:
The aim of this algorithm is to find how many users gave a positive vote - Like (likeval =1) or negative
vote - Don’t Like( likeval = 0) for a particular material based on keywords prompted for search by each
user. This is employed so that the users discover what keywords are related with each material. Therefore
the appropriate keywords are displayed in the LeARN environment, followed by a score (%) representing
the keyword’s positive feedback. This aims to give users the opportunity to see all the related keywords
for a material and use them for further search.
Usage:
It is important to note that users can vote as many times as they want. The criteria for Like or Don’t Like
that should be fulfilled are:
1. Positive Vote (i.e: Like) should be assigned for a material if and only if user believe that the
keywords he/she prompts into the search box are closely related to the material returned.
For example, Natasha prompts in the search box: “Vague Adjectives”. The system returns the
publication with title: “A Theory of Vague Adjectives Grounded in Relevant Observables”.
Therefore, the keywords she prompted into the system are closely related to the resulting
publication and hence, she gives a positive vote (Like) to the material.
2. Negative vote ((i.e: Don’t Like) should be assigned for materials returned by the system and are
not related with the keywords prompted by the user. For example, Martin prompts to the system
the keywords “Semantic Web” and the resulting publications are 1) Integrating Open User
Modelling and Learning Content Management for the Semantic Web, 2) Towards automated
knowledge-based mapping between individual conceptualizations to empower personalization of
Geospatial Semantic Web. For the second paper, he decides that his keyword do not really

45
match the resulting material because the material is about Geospatial Semantic Web. Therefore,
the material gets a Don’t Like vote.
In both examples, the algorithm counts the positive and negative votes and displays these to the LeARN
environment as well as how many people Like or Don’t Like some materials based on the criteria
discussed above. A major problem of this algorithm is that noise exists in the results. This is because, if
User-1 searches for a set of keywords {k1,k2,k3}rather that one keyword and votes, then the vote is
assigned for all 3 keywords. Therefore, the set of keywords is accepted or rejected depending on the
likeval. Therefore in case k3 is (not) closely related with the material it is affected by the other two and
takes the appropriate likeval.
How it is applied:
Each time a user finds a material (material_id is retrieved from user_requests table) and wants to vote for
it, the keywords (keywords) he prompts to the system are stored in the log_keywords table of the learn
database. Then, it calculates how many Like votes exist ( rPlus), how many Don’t Like votes exist
(rMinus) and finally how many people have voted (counterAll). The algorithm returns the
like_persentage, the total number of people who voted and the keywords that correspond to the results.
Therefore, the appropriate result of the algorithm is displayed in the screen of the LeARN application
with the corresponding keyword.
Pseudo code:
Input: Keywords prompted to the system by user and likeval Output: keywords with the score liked or disliked and how many people vote for each material_id in material // material table contains all the info of the publications. {
for each material_id in log_keywords // if material_id exists in log_keywords table means paper voted (like or don’t like)
for each keywords in log_keywords // keyword likeval is 1 if liked or 0 if not { counterAll = counterAll +1 if likeval ==1 then rPlus = rPlus+1 else rMinus = rMinus + 1 // how % like the particular paper keyword like_percentage = (rPlus / (counterAll) *100)
} return like_percentage, counterAll, keywords
}

46
Figure ii: User-Based Related Keywords Algorithm

47
The Data Scheme:
Table 2: Table fields made available for query
4.3 Algorithm 3: Recommended Materials Based on Keywords Goal:
The main target of this algorithm is to match a user’s interested publications to similar materials so that a
recommendation material list (recc_mat_listKW) is created. The algorithm is executed taking into
account the keywords of each material. It aims to discover publications with semantically similar
keywords and recommends them in the recommendations list to a user. This list will be displayed next to
each publication in the Recommended materials Based on Keywords section of the LeARN prototype.
Usage:
It’s crucial to note that this algorithm focuses on:
3. The keywords already existing in the LeARN database for the particular publication (in the table material).
4. The keywords that corresponds to the publication voted as Liked, in table log_keywords and
hence have likeval =1.
User prompts to the system some keywords and the system returns the appropriate publication results.
Then, user selects one publication. Through that publication the user has the opportunity to find which
other materials are related to it. Rather than Algorithm 4, which is based on rankings, this algorithm uses
the keywords as described above (1,2) and calculates the value that corresponds to the semantic similarity
of those keywords with the keywords of the other publications. As shown in the pseudo code the
Sim(Kn,keywords) is used. Kn is the keywords existing for the selected publication and keywords are the
keywords stored in the database for each other material. However, that is a similarity measure which runs
by the Wordnet::Similarity API and gives the semantic similarity of the pair of keywords input. Each pair
that has high similarity value ( >=0.5) are set to be related and thus the algorithm sets the likeval = 1.
That means, the keywords prompted are related to the particular publication. Therefore, the publications
that have likeval = 1 and are not already in the recommendation list are added to it.
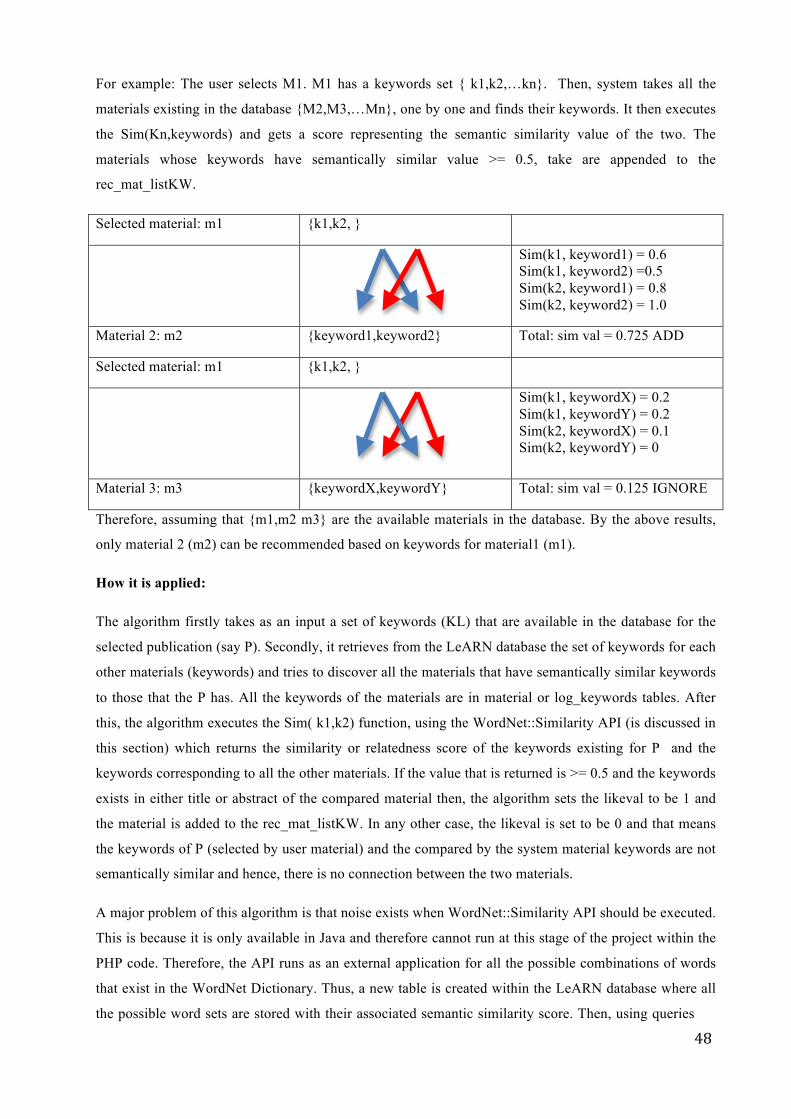
48
For example: The user selects M1. M1 has a keywords set { k1,k2,…kn}. Then, system takes all the
materials existing in the database {M2,M3,…Mn}, one by one and finds their keywords. It then executes
the Sim(Kn,keywords) and gets a score representing the semantic similarity value of the two. The
materials whose keywords have semantically similar value >= 0.5, take are appended to the
rec_mat_listKW.
Selected material: m1 {k1,k2, }
Sim(k1, keyword1) = 0.6 Sim(k1, keyword2) =0.5 Sim(k2, keyword1) = 0.8 Sim(k2, keyword2) = 1.0
Material 2: m2 {keyword1,keyword2} Total: sim val = 0.725 ADD
Selected material: m1 {k1,k2, }
Sim(k1, keywordX) = 0.2 Sim(k1, keywordY) = 0.2 Sim(k2, keywordX) = 0.1 Sim(k2, keywordY) = 0
Material 3: m3 {keywordX,keywordY} Total: sim val = 0.125 IGNORE
Therefore, assuming that {m1,m2 m3} are the available materials in the database. By the above results,
only material 2 (m2) can be recommended based on keywords for material1 (m1).
How it is applied:
The algorithm firstly takes as an input a set of keywords (KL) that are available in the database for the
selected publication (say P). Secondly, it retrieves from the LeARN database the set of keywords for each
other materials (keywords) and tries to discover all the materials that have semantically similar keywords
to those that the P has. All the keywords of the materials are in material or log_keywords tables. After
this, the algorithm executes the Sim( k1,k2) function, using the WordNet::Similarity API (is discussed in
this section) which returns the similarity or relatedness score of the keywords existing for P and the
keywords corresponding to all the other materials. If the value that is returned is >= 0.5 and the keywords
exists in either title or abstract of the compared material then, the algorithm sets the likeval to be 1 and
the material is added to the rec_mat_listKW. In any other case, the likeval is set to be 0 and that means
the keywords of P (selected by user material) and the compared by the system material keywords are not
semantically similar and hence, there is no connection between the two materials.
A major problem of this algorithm is that noise exists when WordNet::Similarity API should be executed.
This is because it is only available in Java and therefore cannot run at this stage of the project within the
PHP code. Therefore, the API runs as an external application for all the possible combinations of words
that exist in the WordNet Dictionary. Thus, a new table is created within the LeARN database where all
the possible word sets are stored with their associated semantic similarity score. Then, using queries

49
each time the algorithm requires the Sim(k1,k2) score the appropriate semantic similarity score is
retrieved and therefore the algorithm continues the execution. All the descriptions of how
WordNet::Similarity API works can be found in this section and all the WordNet::Similarity measures
have been discussed in section 2.7.3.
The Data Scheme
Table 3: Table fields made available for query Pseudo code:
Figure iii: Recommended Materials based on Keywords Algorithm
Input: Keywords, likeval, material_id, material_abstract, material_tittle Output: rec_mat_listKW // Keywords List (KL) from the publication selected KL = [ K1, K2, …. ,Kn ] for each Kn in KL { for each m in material //material is a table in learn db { likeval = 0
// keywords : are the keywords of the other materials for each((Kn and keywords) in material_keywords) or (Kn in
log_keywords) {
if (Sim(Kn,keywords) >= 0.5) or (Kn in material_abstract) or (Kn in material_tittle)) then
likeval = 1 } if likeval = 1 then add m to rec_mat_listKW }
} } return rec_mat_listKW

50
The Data Scheme:
Table 3: Table fields made available for query
WordNet::Similarity API
WordNet::Similarity proposed in section 2.7 and discussed in more detail here. It is a free for use object
oriented software package, under Gnu Public License. It is available from the Comprehensive Perl
Archive Network [19] as well as SourceForge, which is an Open Source development platform [51]. The
functionality of this software supports measurement of the semantic similarity and relatedness between a
pair of concepts (or synsets) [28].
This API is developed by Ted Pederson et al and implements not only various semantic similarity but
also semantic relatedness measures. All the measures that this API supports are based on the information
discovered in the lexical database of WordNet (section 2.7.2). Measures that are supported by
WordNet::Similarity API are those which described by:
Resnik (1995), Lin(1998), Jiang-Conrath (1997) , Leacock-Chodorow (1998), Hirst-St.Onge (1998), Wu-
Palmer (1993), Banerjee-Pedersen(2002), Patwardhan-Pedersen (recently] [19].
Algorithm 3, requires WordNet::Similarity API which was available in Perl and Java programming
languages. However, “the Perl library is being deprecated in favour of the Pure Java Version” [38] and
as a result is now supported only by Java. The problem that arises at this stage is the fact that the whole
LeARN Environment is designed using PHP Programming language and WordNet Java API cannot be
embedded in the PHP code at this stage of the project. It is assumed that it will be combined in future
work. Therefore, it was decided to execute API as an external part of the application and use its results in
Algorithm 3 as explained above.
4.4 Algorithm 4: Recommended Materials Based on Rankings Goal:
This algorithm is executed aiming to match each user’s downloaded and/or ranked materials to similar
materials in order to store those materials in a Recommendation List (recc_list_Rank) along with all

51
the similar materials. Taking into account the Ranking scores which will be assigned for each material by
users, this table is created. The algorithm, aggregates materials that have ranked with similar score,
eliminates materials that users have already download or voted, and recommends the remaining
publications in a recommendation list to the user. This list will be displayed next to each publication,
after users ranking. [446]
Usage:
It is crucial to note that a user could rank materials with a score 1 to 5 only once, based on their personal
opinion and interests. It is assumed that 1 is the less related material and 5 is the most related one.
Rankings greater than or equal to 4 are assumed to be very related.
For example: Nicole gave a 5 score for the book “Java and UML” and a 4.5 score for the book
“Twilight”. Then, Kristina ranks with a score of 5 the book “Programming in Java”. The
recommendation list for Kristina will contain only the book “Java and UML”.
This is because her interested area / category includes only this material because the other book is in a
different category.
By the above example, it is true to conclude that people can rank any material. However, aiming to avoid
inclusion of unrelated materials in the recommendation list, the category (table learn_categories in the
database) each material belongs to, is taken into account.
How is applied:
This algorithm requires a number of steps, but is ultimately relatively straightforward. It is an extension
of the algorithm proposed in Section 2.7.4. Each time a user ranks a material, the material_id and user_id
are stored in a table. Therefore the interested publications of each individual are known. Each time a new
material is ranked by the particular user, the algorithm tries to discover which are the other available
materials that best match with the user’s preferences. This is achieved by calculating the similarity score
of the existent interested materials of the user and the new material. This is the function Sim(M1,M2)
shown in the following pseudo code and first proposed in an example of section 2.5. The way that this
function returns the similarity score is discussed in the following paragraph (Cosine Similarity Function).
Furthermore, the algorithm checks if the result returned by the Sim(M1,M2) function is greater than or
equal than 4, which means the two materials are ranked with a rank value more than 4 then, algorithm is
executed by checking if the material is not in the recommendation list, it append it to it. The score 4 is
decided to be used in order to separate the well ranked with the non well ranked materials and create lists
with the materials best ranked from the user.

52
Pseudo code:
Figure iiii: Recommended materials based on Ranking Algorithm
Input: user_id, material_id, ranking_val, category_id ( from db tables: user, material, rankings, learn_categories) Output: recc_list_Rank score =0 ; rec_list = []; for each material_id in rankings, M1 {
for each user U who rank M1 {
for each material M2 rank by user U record that user rank M1 and M2
} for each material M2
{ // check that materials belongs to the same category if category_id(M1) == category_id(M2) then { score(M1,M2) = Sim(M1,M2) // the function Sim(M1,M2) is discussed in this section if score(M1,M2) >= 4 then { if M1 not in recc_list_Rank then add M1 to recc_list_Rank if M2 not in recc_list_Rank then add M2 to recc_list_Rank
} } } return recc_list_Rank
}

53
The Data Scheme:
Table 4: Table fields made available for query
Cosine Similarity Function:
Algorithm 4, use the cosine similarity function based on the cosine similarity rule. The use of this
function is inspired by the [46] and the tutorial by Dr. E. Garcia13. This function is based on the cosine
similarity rule that is a common vector space. Then, it determines the similarity using the Euclidean
cosine rule. The cosine similarity formula is the following:
Figure 4.4 : Cosine Similarity of vecors A and B 13
According to [46], the algorithms that generate recommendations and requires similarity of two objects
(sim(A,B)) measurements varies. At the same source it is pointed out that the most common method is to
measure the cosine of the angle between the two vectors. The final result that will be returned by the
above formula will be a number that represents how similar two vectors (A,B) are. In Algorithm 4, this
function is used and the target is to calculate the similarity of two materials based on the rankings given
for them. The data used for each material are their keywords (Sim (K1,K2)). Each vector corresponds to a
keyword and the vector’s M dimensions correspond to users that have ranked that material.
The final result that it will be returned by the above formula will be a number that represents how similar
two keywords (k1,k2) are. Therefore, it takes the keywords of two materials that have been ranked by the
same user and belong to the same category and then computes how similar those keywords are aiming, to
use this score. The score is checked and if it is greater than or equal to 4 then the two materials are
similar and thus are added in the user recommendation list based on rankings (recc_list_Rank).
13 http://www.miislita.com/information-retrieval-tutorial/cosine-similarity-tutorial.html

54
5. Implementation of the Application The System implementation chapter discuss the steps followed in order to successfully implement the
LeARN Community environment prototype. This chapter is divided in the four algorithms functionality
as discussed in chapter 4. The aim of the implementation phase is to implement what is discussed in the
design chapter, including the functionality of the user activities and system architecture diagrams used in
this report. In addition to this, this part of the report presents and discusses the queries and coding used in
the algorithms applied. It starts by showing some screenshots of the prototype aiming to illustrate exactly
how and where certain components are visible to the end users and how members of the community
interact with them.
5.1. Iteration 1: Feasibility of the LeARN prototype Architecture The initial set of functionalities as stated in the Minimum requirements (section 1.4) of this project,
provides basic knowledge functionality focusing on reading or downloading materials from the LeARN
Community. In addition to the minimum requirements, section 2.2 discusses the user activities and
furthermore section 2.6 discusses more precisely the user actions as discovered during the study and
analysis of the LeARN Community functional requirements. All the above, are set to be the objectives to
be achieved within the development of the prototype. However, the objectives of iteration 1 are:
Develop a web-based client server application: LeARN Community Environment
1. Sign_Up, Sign_In, Sign_Out
2. Search for a material using some keywords
3. Return to the user all the related to the keywords prompted, materials
4. Read the abstract, keywords and all the available information of a material
5. Download a material
System Specification and Environment:
The interface of the LeARN application was designed using PHP, CSS, Javascript and MySQL. The
LeARN database (section 3.1), has been designed as soon as the application interface was completed and
functional requirements analyzed, using the Navicat Premium 8.1.0 – Standard, tool. The whole
application is set up to work on the local machine of the author, and the web container that was selected
to be used is Apache, mainly because the author had worked with Apache Tomcat before, in the third
year module “Distributed Systems”. The objectives 3,4,5,6 were achieved using tools and methods
described in previous sections. For example, the Search, at this stage of the project is performed using the
Sphider crawler and objectives 4,5,6 achieved using MySQL queries. The figures in Appendix I (1)
illustrates how a user of the LeARN environment performs the actions proposed in this.

55
How to Sign_Up:
Users of the LeARN application have access to the functionality of the Community only if they are
registered. Therefore, people can sign up following the instructions of Membership that is available in the
menu or by selecting the Sign up which also directs the user to the Membership page. People who
correctly complete the form shown in Appendix I (2), should then receive a confirmation email at the
email address they provided. Therefore, by confirming their registration by the link sent to their email
inbox, they can then sign in to the Community and perform the actions they are interested in.
How to interact with the environment:
People that are logged into the community can Sign out when they want to. When they are logged in,
they have the opportunity to see the complete material list of the publications of the community, which
are retrieved (section 3.5) from the KRR Group database. Moreover, users can enter keywords and search
for a material. This actions illustrated in Appendix I(3).
How to Search and retrieve the desired results:
Author assumes that Eleni Yiangou is logged into the LeARN system and interested in finding
publications related to “models”. Therefore, she enters this keyword and searches following the steps
shown in Appendix I (4). The system returns the available materials. The materials are displayed in the
screen according to how many times the keyword exists within each material. Then, a percentage of
keyword frequency is presented for each material. At this stage, this helps users to identify which is the
most related material to the keywords prompt.
How to read information for a material and how to download it:
The user’s actions continue by selecting the second material so that she/he reads all the information that
is available for the particular publications as shown in Appendix I (5). User finally decides to download
the material.
5.2. Iteration 2: Algorithms Implementation The second set of functionalities relates to Algorithms 1, 2, 3 and 4, discussed in section 4 of this report.
The author has therefore set the following objectives of iteration 2, as follows:
1. Expand the interface so that Advance Search works correctly for the user,
2. Expand the interface so that user can rate a material from 1 to 5,
3. Expand the interface so that user can vote as Like or Don’t Like a material
4. Find connections between users based on materials downloaded and Liked (Algorithm 1)
5. Discover all the keywords prompted by users and are related to a publication (Algorithm 2)
6. Discover all the materials that have semantically related keywords and recommend them to a user

56
(Algorithm 3)
7. Recommend materials that have been rated with high scores and belongs to the same category to the users
Advance Search and Interface Expansion:
The way that Advance Search works is illustrated in section 3.3, figure 3.3. However, in the prototype
this can be used by any user who cannot find the materials he/she would like by the keywords he/she
enters and therefore, the system returns some semantically related words in order to choose similar words
and search again. Those actions are illustrated in Appendix I (6). The design of the Advance Search,
required WordNet 3.0 database to retrieve from it the synonym sets requested, the Sphider crawler to
assembly locally a collection of the publications and finally the queries to implement the search for the
data needed. The queries that are implemented for the advance search are illustrated and discussed in
section 2.7.2. The complete code can be found in the file advance.php, which is in the CD included with
this project.
Objectives 2 and 3 are performed together. The interface was extended and the results are displayed to
the user as shown in Appendix I (7). How those additional functionalities perform, have been discussed
in chapter 4 and the coding parts of their implementation will be proposed in Appendix J.
Algorithm 1:
Algorithm 1 is distributed in two sub algorithms in order to be implemented more practically. Both are
discussed in section 4 of this project report. Here, the author discusses how algorithm 1 is implemented
so that the system successfully discovers related users. A user could be related with any other user if
Downloads (algorithm 1 a) or Like’s the same material(s). To achieve this, the interface is extended as
shown in Appendix I (7). The actions that are performed by each user, are stored in the learn database
(section 3.1). To begin with, each time a user requests a material, the material_id and user_id are
recorded in the database. Therefore, the system knows which materials each user requests for Download.
Moreover, each time a user Likes a material, the likeval (log_keywords table) corresponds to the
particular material in the database, becomes 1 and thus the system can easily discover people who vote
positively for the particular materials. All users that are interested in download or vote positively for a
material are assumed to be related. Thus the system creates a Related Users part in the interface where it
shows the users corresponding with the criteria discussed in section 4, algorithms 1 a and 1 b.
The queries implemented to discover the related users(based on downloads and based on Likes) and
display them on the environment interface can be found in Appendix J.
Algorithm 2:

57
The implementation of this algorithm is designed using queries and php code as shown in Appendix J
(Alorithm 2). The interface has been extended and the User-Based related keywords list is shown in the
menu of the LeARN application.
Each time a user vote a material, Like or Don’t like, the appropriate likeval (0 or 1) is stored in the
database as shown in Appendix J (Alorithm 2). The likes are calculated and displayed in the user as
illustrated in the same appendix, using the calculatelikes function.
Algorithm 3:
This algorithm is designed in such a way that WordNet::Similarity functionality is used. However, at this
stage of the project it was not possible to embed the API that supports WordNet::Similarity due to the
fact that it is written in Java. The difficulty was the fact that PHP and this API were difficult to author to
be implemented in a single software. Therefore, WordNet::Similarity Java API is used as an extra tool,
outside of the LeARN Community and its results are used in Algorithm 3, in each iteration that
Sim(k1,k2) called. Dimoklis Despotakis, a PhD student of the KRR group designed this API that is used
to retrieve the appropriate results. This API, calculates the Semantic Similarity/Relatedness of two words.
Therefore, author created a new table in the learn database,
where all the possible keyword sets that can be created are
stored.
This table is the demoAPI and its entities are {demoAPI_id,
kw1, kw2, sim_score}.
Thus, within the PHP code, author uses MySQL queries and retrieves the similarity score of two
keywords each time the requested keyword set matches with one set of words that is available within the
demoAPI table of the database. The appropriate score is then passed to the algorithm so that the
procedure is completed. The figure at the left of this section of the report illustrates how the
WordNet::Similarity Java API works. One of the major problems of this API is the noise which is caused
in the data results of the community is that API is not powerful enough to calculate the similarity score of
more than one words. For example, if more than one keyword is prompted in Word1 (“semantic
connections”) field and 2 words (“semantic relatedness”) are entered in the Word2 field, then the API
will only find the semantic similarity score of the set of the 2 words entered initially (semantic, semantic)
to the system.
The final results of this algorithm are the information that is shown in the LeARN environment menu,
Recommended Materials based on Keywords, as shown in Appendix I (7) and the coding parts are
illustrated in Appendix J(Algorithm 3).
Algorithm 4:

58
This algorithm matches each user’s download or rated material to similar materials and then combines
those similar materials to the user recommendation materials based on keywords. The extension of the
interface of this algorithm and the way that ranking score is stored in the database are shown in figure
Appendix J (7). All the functionality of this part of the community implementation can be found in
Appendix I (Algorithm 4).
5.3 Implementation of Extension 1 – Include in Services Menu the Upload in the Prototype The first extension objective of the LeARN Community prototype was to extent the interface and gives
users the opportunity to upload a material. This is finally implemented in the Services option, which is
available in the top Menu. The Upload was implemented according to PHP MySQL Tutorial14. Firstly,
author creates a new table, upload, in the learn database as shown above:
The file that is uploaded could be of any type and is stored in the type, but the content of
the file is stored in the content entity. This entity, uses the BLOB (Binary Large
OBjects) data types which in LeARN web application is a collection of binary data that
stored in the content entity of the upload table of the learn database. Using PHP to
upload files in MySQL, is a procedure that is distributed in two steps: uploading the file
in the MySQL Server and then read the file and add it into the MySQL. The major
advantage of BLOB is that it stores up to 64 kilobytes of data but the use of different BLOB data type
such as MEDIUMBLOB, could give the chance to store up to 16 megabytes. However, for the LeARN
prototype, upload size is set up in such a way that it can stores up to 8 megabytes of any file format.
How it works:
User of LeARN application selects the Services tab from the menu. Then, browse the file from his/her
computer and completes the form displayed in the screen. The field of abstract has been implemented by
the use of ckeditor15, which is a text editor that can be used inside web pages. In addition to the
implementation parts, the tables that display the authors that has written materials that are available in the
community are designed by the use of DHTMLX UI Toolkit16 Standard edition, which is free. Using this
tool, users can drag and drop the authors wrote the material they want to upload, in the empty table that
follows rather than writing them again. New authors could also added. Moreover, those tables include a
search, thus users can write the initial letters of the author’s name and then select him/her. The noise
caused in this part of the application is that authors that added cannot be deleted. Therefore, users should
be very careful.
14 http://www.php-mysql-tutorial.com/wikis/mysql-tutorials/uploading-files-to-mysql-database.aspx 15 www.ckeditor.com 16 www.dhtmlx.com

59
6. Evaluation For the purposes of project evaluation, the Author tested the prototype with a set of virtual users
according to the scenarios discussed in section 3.2. This helped to identify any problem areas and also
served to propose potential improvements to the model. The evaluation phase then moved to a set of real
users who followed the various scenarios and presented their findings in a series of questionnaires.
Scenarios were employed in the evaluation process to enable users new to the system to navigate the
functionality of the system without any learning curve.
6.1 User Prototype Evaluation objectives: The main goals of the evaluation process were:
Goal 1: To examine how appropriate the scenarios were, with regards to the actual application and
measure the level of user satisfaction.
Goal 2: To identify any problems users may experience with the application
Goal 3: To examine if users retrieved the information they were expecting through the use of the
search and advanced search functions. The aim was to find if the appropriate publication,
recommendation lists, user connections and semantic keywords returned by the search
functions fulfilled user expectations.
Goal 4: To examine the feasibility of the interface architecture. This aimed to examine whether or not
users were able to find the recommendation and information sources easily and effectively.
Goal 5: To discover any functionality limitations of the system.
Goal 6: To examine the robustness of the system. This aimed to discover possible errors or
unexpected results within the system.
Goal 7: To identify any issues that a real life application should cope with. This aimed to compare
this web-based application to a real application according to user feedback.
6.2 Procedures, Participants and Materials: The evaluation teams were made up of a group of 3 people from the KRR Group and 3 students from the
School of Computing, none of which had any prior experience with the application. Members of the
evaluation team met with the Author at various locations within the School of Computing were they were
asked to follow a particular scenario and fill out a questionnaire with their feedback. During these
meetings, the Author provided instruction on how best to follow the particular scenario and conduct the
tests. This served to highlight how users new to the system would cope with the LeARN application.
The number of participants was limited, as the application was developed on a local server and
consequently only one user at a time could test the application on the Author’s computer. The evaluation
procedure took approximately half an hour for each individual. Due to time limitations, the application
couldn’t be evaluated by more real users and that is the main reason the Author decided to also employ
virtual users (created by the Author and following the scenarios of section 3.2) to test the prototype and

60
discover possible drawbacks of the application.
The question sets were designed according to the evaluation goals listed above. These consisted of two
questionnaires, each aiming to identify different items. The first aimed to examine the effort of users
when testing the prototype. This questionnaire can be found in Appendix L (1 and 2). The second
questionnaire, aimed to evaluate user opinions of the results returned not only by the prototype but also
from the external WordNet::Similarity Java API. This required the participants to grade the semantic
similarity of two keyword sets on a scale of 1 to 10. This questionnaire can be found in Appendix L(3).
6.3 User Result Analysis: The aim here was to evaluate the levels of user satisfaction with the end results produced by the
application, which is essentially an evaluation of the algorithms discussed in section 4. The evaluation
goals are reflected in the questionnaire and the results are analysed below:
First Questionnaire:
1. Goal 1: How appropriate do you find the application scenario (with regards to the LeARN
architecture)?
Most of the participants pointed out that the scenario was very appropriate and helpful and covered many
possibilities regarding to the usability of the system. One of the participants suggested that it would be
nice to provide a more open search but that was not possible at this stage of the project, due to the
limitation of the data existing in the database. Another suggestion was to give users different scenarios so
that the various actions between users would be better highlighted. One participant pointed out that
scenario was somewhat superficial.
2. Goal 2: Have you experienced any problems with the application?
Most of the users identified the same problem. That was confusion surrounding the Likes function. In the
interface, there is a Like button that should be selected by users who strongly believe the keywords
entered into the system are related to the resulting publications. Despite the fact that there is a clear note
about this in the interface, participants confused this function with the idea that “Like” corresponds to the
key idea “I like this paper”. One of the participants suggested that it would be better if “Like” was
replaced by “Related to the Keywords”. In addition to this, one participant noticed that as soon as the
Like function was used, his/her name was automatically added to the Related Keywords list without
explanation. This could be fixed by providing an additional notification to users as to the functionality of
the “Like” option and how this serves to establish possible relations between users.
One participant experienced difficulty in the “Upload” facility in the services option. All the participants
pointed out that the upload function worked as expected, but experienced some confusion when prompted
to add an author because this could only be done by dragging and dropping author names into an empty

61
table. This is a minor problem because if a user does not want to drag and drop an existing author name
he/she can search for it in the box that is available or scroll down to find it and add it directly.
3. Goal 3: How appropriate do you find the simulation (data used, components, etc)?
Most of the participants found the interface well structured, clear, easy to navigate and user friendly.
They also pointed out that the materials used are appropriate for the needs of the application but they
suggested adding more materials to the database so that further tests will show more related materials and
more accurate user connections. One participant said that he/she didn’t have enough time to check all the
possible connections he/she had with other users. In future, the Author aims to expand the application and
participants may have the opportunity to use it under real conditions, with more materials for as much
time as they need.
4. Goal 4: What is your opinion about the feasibility of the architecture?
On the one hand, some participants pointed out that the system architecture was very feasible, well
organized and noted that such a system would be a very useful tool. In addition the majority of
participants noted that relations were clearly displayed by the interface. On the other hand, one
participant pointed out that it was not clear what Related Users were and suggested adding a “help”
option after each relation status so that newcomers can select and find out what each relation means and
how it works. The Author believes that this suggestion could be very beneficial to the system, enabling
users to clearly understand why those relations exist and how this will help in their further selections.
5. Goal 5: Please note any missing functionality with regards to the system:
All participants were happy with the system functionality at this first stage. However they suggested
adding the ranking value given by each user to the appropriate publication. This is a really good
suggestion as real applications have recommendations but all will take into account what is the ranking
value for each book or paper based on people who have already read it. One participant noticed that the
discussion link existing in the menu, didn’t work. This was initially outside the scope of this project but it
could be implemented as an extension, time permitting. However, it will be completed in future versions,
aiming to provide a forum for semantically related users of the community to share ideas and questions.
Lastly, one participant suggested including fields for the publication information for each material.
6. Goal 6: Please write some short notes about the robustness of the web application:
All the participants were satisfied and pointed out that system worked well, without any errors. It was
also pointed out that the system worked as expected without any problems and both search and advanced
search returned appropriate results. One participant suggested that it would be beneficial if the same
scenario were repeated with a larger dataset at a future date, to test the scalability of the system. Another
participant noticed that keywords returned and selected by Advance Search, if voted as “Like” were
displayed in the Recommended keywords list one by one. That means the system splits possible

62
phrases or keyword sets that are word pairs. This is a drawback in the system and is caused because the
queries the Author selected to use in order to retrieve similar words from the WordNet dictionary, splits
those words in order to return the synonym set of each word rather than the synonym set of the phrase
entered. However, keyword pairs like “web-based” which includes the dash returns correct results.
7. Goal 7: Please identify any issues that a real life application should cope with:
One of the participants pointed out that it would be better if Advance Search were implemented in such a
way that the resulting words were more accurate with regards to the semantic similarity. This problem
exists because WordNet is domain-independent lexical resource therefore, if its set up change to domain-
specific measures will be more effective and as a result the resulting words of Advance Search will be
more semantically related. In addition participants suggested adding keyboard functionality to the search,
rather than solely through the Go button. One participant suggested increasing the security of the web
based application to reflect the security levels of a real application. The Author believes this would be a
wise step to take, if more materials added and more user profiles created.
Additional Comments from virtual users point of view:
Three virtual users followed the scenarios proposed in section 3.2 and consequently when real users
tested the prototype the possible connections with others were clear. All the feedback and comments from
those scenarios are very similar to those proposed by real users, except from the following:
• It would be a good idea if relations that exist in the LeARN Community could be presented
schematically by the use of a Visualization tool. This could be implemented by the use of
Touchgraph but due to time limitations, this will be implemented in a future version.
• If a user uploads material, it is presented directly in the Complete Material List. However, it is not
returned if the user immediately does a search. This is because the crawler is set up to perform re-
indexing once a week. This frequency could be changed.
• System could send a notification to the other users each time a new material is uploaded. This could
be implemented if the discussion board was complete. At this stage of the project, what can be done
is to use the link of Discussion as an Announcement board.
• If two different users use the same keywords but only one or none vote “Like” then there is no
measure of possible relations. This could be improved if the Author added a log table in the
database to store all the actions of each user.
• User profiles are not presented. Only materials read by a user are shown. The prototype could be
reformulated so that a user’s occupation, interested area, keywords most frequently used and other
information would be available to other users.
The second version of questionnaire:
The results of this questionnaire are presented in one table in Appendix L(4). The keywords (KL) that are

63
used are retrieved from material_id = 5 and category_id = 3, aiming to compaire human opinions about
semantic similarity score, with the API. All the results retrieved from participants that completed this
questionnaire concerned the WordNet::Similarity API that uses its results as an external API of the
LeARN Community. General analysis of the results retrieved showed that for most participants, precisely
setting a semantic similarity value for a pair of keywords proved to be difficult. However, one of the most
serious problems encountered was the fact that users were more able to set an accurate semantic
similarity value Sim(k1,k2) if input keywords of more than a single word were used (i.e.: Distance
Learning, Semantic Web). The API works perfectly only if it compares two keywords. In other cases it
returns the similarity of the first two only and therefore the result is incorrect. Despite this problem, this
questionnaire was used in order to compare the similarity value of some keywords from the user
perspective versus the API perspective. These results show that users tend to give high similarity value to
words that are synonyms or similar and low similarity value to words that are in actual fact semantically
similar. This proves the fact that people might be unable to use the correct keywords when they search
for a material. Thus tools examining semantic similarity become crucial in a search engine in order to
perform a deep semantic understanding of keywords prompted by users and returns the most appropriate
results
6.4 Project evaluation: The overall evaluation phase left the evaluation participants satisfied. The scenario was a good
introduction to the functionality of the LeARN environment for newcomers. Using the scenario,
participants were able to take a quick tour of the application. However, one of the participants expresses
his/her disappointment that the scenario was specific and therefore he/she wasn’t able to completely
understand the relations and connections existing. The same participant pointed out that some of the
questions asked needed clarification. The Author’s lack of English writing skills and the enthusiasm to
express in a short question all the power of the prototype developed may have caused this confusion.
However, if the Author had the opportunity to repeat the evaluation, the input of an expert combined with
more evaluation time would provide a solution to this point.
6.5 Further Work: The most critical tools that are available in the LeARN community are the Search and Advance Search
engines. Both are the tickets to navigate through the various links to find materials a user need and
discover the connections that may have with the others. Therefore, future works aims to focus on
expansion of the searching parts so that deeper semantic understanding of the keywords entered will be
achieved. The materials are in the database could increase significantly and all the user connections could
be displayed with some form of Visualization. As soon as the minimum requirements of the prototype are
completed and only one extension is completed, then all the other extensions could also be components
of author’s future work. Moreover, in a future work, the prototype could be improved according to the
evaluation feedback received. Finally, future work could include the completion of discussion forum

64
where all the related users would be grouped and share ideas, questions and many more. Users profiles
could also be constructed and used from other users.

65
7. Project Conclusion Completing a project of this magnitude has been a totally new concept for me. What at first seemed
like a mountain, soon developed into an ordered routine of planning, coding, checking and refining.
Developing specific methodologies and algorithms led to an application that is functional, easy to
use and above all, applicable to the specific problem the project set out to address.
Web based applications have become more and more complex and feature packed, as web user’s
expectations and demands have changed. My aim was to develop such a web based application to
cater to the specific needs of a specific community. My end result is a web based application that
successfully addresses these specific needs of this specific community, while maintaining all the
every-‐day functionality web users today have come to expect. This came as a result of solid
methodologies that have been proven to be functional.
Development of a successful application can never really be said to end. As user demands change,
so must applications evolve.
I am confident my methodologies and algorithms and indeed the whole plan of the project will
allow for future development to continue, fine-‐tuning the end results to reflect the changing
technologies and expectations.

66
8. References [1] Huh, M.M.H.a.P.-W.L.a.E.-N., A Grid-Enabled Framework of Expertise Search Engine Using
Web-Based Online Communities. Proceedings of International Workshop on Internet and
Distributed Computing Systems, 2008.
[2] Ueyama, R.I.a.H.T.a.K., Community Mining Tools using Bibliography Data. 2008, National
Institute of Informatics: Tokyo, Japan.
[3] Cook, J.B. Community Development. 1994 [cited February 2010; Available from:
http://extension.missouri.edu/publications/DisplayPub.aspx?P=MP568.
[4] Chavis, D.W.M.a.D.M., Sense of community: A definition and theory. 10 Feb 2006.
[5] Wenger, E., Communities of Practice: Learning as a Social System. 1988.
[6] Howard Rheingold, The Virtual Community, 1998;
from:
http://www.planetfreebook.com/Classic_collection/classic_books_author_R_PDF_edited_filena
mes/Rheingold.Howard%20!The%20Virtual%20Community.pdf
[7] Guidance for Implementing Net-Centric Data Sharing, DoD 8320.02-G, 12 April 2006, p. 11
[8] Wenger, J.L.a.E., Situated Learning: Legitimate Peripheral Participation. Learning in Doing:
Social, Cognitive and Computational Perspectives. 1985.
[9] Zhuge, H., Communities and Emerging Semantics in Semantic Link Network: Discovery and
Learning. IEEE TRANSACTIONS ON KNOWLEDGE AND DATA ENGINEERING, June
2009. 21
[10] Resnik, P., Using Inforamtion to Evaluate Semantic Similarity in a Taxonomy. 1995: USA.
[11] Budanitsky, G.H.a.A., Semantic distance inWordNet: An experimental, application-oriented
evaluation of five measures. 1999, University of Toronto: Toronto, Ontario, Canada M5S 3G4.
[12] Seco, N.A.L., Computational Models of Similarity in Lexical Ontologies, in Computer Science.
February 2005, University College Dublin: Dublin p. 151.
[13] Ian Sommerville , Software Engineering 8, 8th edition, 2007, England
[14] Seco, N.A.L., Computational Models of Similarity in Lexical Ontologies, in Computer Science.
February 2005, University College Dublin: Dublin
[15] Zavaracky, A., Glossary-Based Semantic Similarity
in the WordNet Ontology. Master’s thesis, 2003, University College Dublin : Dublin ,
Department of Computer Science.
[16] Pandey, K.S.a.L.T.a.S., Efficient Information Retrieval Using Measures of Semantic Similarity.
2005, Nepal Engineering College.
[17] Richard Bergmair and Software Competence Center Hagenberg GmbH (SCCH) "The semantilog
project" , 2007-2009, Accessed in: 26/4/10, from http://www.semantilog.org/wn2sql.html
[18] Princeton University, WordNet 3.0 database statistics, 2010, Last Update: April 13,2010,
Available at: http://wordnet.princeton.edu/wordnet/man/wnstats.7WN.html
[19] CPAN (17 Jun 2008), Ted Pedersen > WordNet-Similarity, Retrieved 2010, from

67
http://search.cpan.org/dist/WordNet-Similarity/ , http://www.d.umn.edu/~tpederse/similarity.html
[20] WARIN, H.O.a.M.V.a.M., Enriching an Ontology with WordNet based on Similarity Measures.
2005, Stockholm University: Stockholm.
[21] IBM , Three-tier architectures ,Last updated: Apr 7, 2010, from
http://publib.boulder.ibm.com/infocenter/wasinfo/v6r0/index.jsp?topic=/com.ibm.websphere.bas
e.doc/info/aes/ae/covr_3-tier.html
[22] Princeton University, WordNet a lexical database for the English language, 2007, Last Update: 4
May 2010, from: http://wordnet.princeton.edu
[22] D. Lin, An information-theoretic definition of similarity, In Proc. 15th Inter- national Conf. on
Machine Learning, 1998, p. 296–304. Morgan Kaufmann, San Francisco, CA.
[23] Philip Resnik, Using Information Content to evaluate semantic similarity in a taxonomy, In
IJCAI-95, p. 448–453, 1995, Montreal, Canada.
[24] J. J. Jiang, D. W. Conrath, Semantic similarity based on corpus statistics and lexical taxonomy,
In Proceedings of International Conference Research on Computational Linguistics, (ROCLING
X), 1997, Taiwan.
[25] Claudia Leacock and Martin Chodorow, Combining Local Context and WordNet Similarity for
Word Sense Identification, chapter 11, p. 265–283. MIT Press, 1998, Cambridge, MA.
[26] Alexander Budanitsky and Graeme Hirst. Evaluating WordNet-based measures of semantic
Distance, Submitted for publication.
[27] Z. Wu, M. Palmer, Verb semantics and lexical selection, In Proceedings of the 32nd Annual
Meeting of the Association for Computational Linguistics, p. 133–138, Las Cruces, New Mexico,
1994.
[28] Ted Pedersen, Siddharth Patwardhan, and Jason
Michelizzi, WordNet::Similarity - measuring the relatedness of concepts, 2004
[29] S. Banerjee, T. Pedersen, Extended Gloss Overlaps as a Measure of Semantic Relatedness, In
Proceedings of the Eighteenth International Joint Conference on Artificial Intelligence, p. 805–
810, 2003,Acapulco, Mexico.
[30] D. Lin, Automatic Retrieval and Clustering of Similar Words, Department of Computer Science,
University of Manitoba, Winnipeg, Manitoba, Canada R3T 2N2
[31] S. Patwardhan, S. Banerjee, T. Pedersen, Using Measures of Semantic relatedness for Word
Sense Disambiguation, In Proceedings of the Fourth International Conference on Intelligent Text
Processing and Computational Linguistics, pp 241–257, Mexico City, February 2003.
[32] S. Patwardhan, Incorporating Dictionary and Corpus Information into a Context Vector Measure
of Semantic Relatedness, Msc Thesis 2003, University of Minnesota.
[33] G. Hirst, D. St-Onge, Lexical Chains as Representations of Context for the Detection and
Correction of Malapropisms, In C. Fellbaum, editor, WordNet: An Electronic Lexical Database,
chapter 13, pp. 305–332, MIT Press, 1998.
[34] Pederson, T. Retrived 24/03,2010, from http://talisker.d.umn.edu/similarity/measures.html

68
[35] Boanerges Aleman-Meza, C. H., I. Budak Arpinar, and Amit Sheth (September 7,8 2003).
Context-Aware Semantic Association Ranking. Semantic Web and Databases Workshop
Proceedings. Belin, Large Scale Distributed Information Systems (LSDIS) Lab.
[36] Bou, B. ,2003, WordNet (wordnet sql). 2010, from http://wnsql.sourceforge.net/
[37] Saabas, A. , 2005-2007, Sphider PHP search engine. Retrieved 2010, 2010, from
http://www.sphider.eu/
[38] Sheffiled, T. U. o. , The RESuLT Project, 17/04/2007, from
http://nlp.shef.ac.uk/result/software.html.
[39] Bou, B. ,WordNet - wordnet sql builder, from http://wnsqlbuilder.sourceforge.net/sql.html
[40] Ted Pedersen , S. V. S. P., Siddharth Patwardhan, Christopher G. Chute (2007) Measures of
semantic similarity and relatedness in the biomedical domain. Journal of Biomedical Informatics
40, 2007, 288–299
[41] Saabas, A. (2005-2007), Ando Saabas, 2010, from http://www.cs.ioc.ee/~ando/
[42] Chris Halaschek, B. A.-M., I. Budak Arpinar, Amit P. Sheth, Discovering and Ranking Semantic
Associations over a Large RDF Metabase, Athens, GA 306 , USA Large Scale Distributed
Information Systems (LSDIS)
[43] Offer Drori, Algorithm for Documents Ranking- Idea and Simulation Results, The Hebrew
University of Jerusalem, School of Computer Science and Engineering. Israel, 2002
[44] Loren Terveen, W. H., Brian Amento, David McDonald and Josh Creter, PHOAKS: a system for
sharing recommendations, 1997
[45] Dimitrova, V. (2010). Ranking Algorithm. Knowledge Management and Adaptive Systems -
COMP3740, LN:28 , University of Leeds, School of Computing, 2010
[46] Amazon Recommendations, “ Item - to – Item Collaborative Filtering, Greg Linden, Brent Smith
and Jeremy York, IEEE Computer Society, 2003
[47] Knowledge Management and Adaptive Systems, Lecture 29: Recommender Systems (Part
2):Item-Item Collaborative Filtering, Amazon’s algorithm, Ronald Denaux and Vania
Dimitrova, School of Computing, University of Leeds, 2010
[48] Ltd, D.A. Database Answers, [cited February 2010]; Data Models Examples. Available from:
http://www.databaseanswers.org/data_models/
[49] Ltd, D.A. Database Answers. [cited 2010 February ]; Available from:
http://www.databaseanswers.org.
[50] Web Developers Notes , Article on client server architecture and how web pages, both static and
dynamic, are displayed on the client (browser) from the server, 2010, from
http://www.webdevelopersnotes.com/basics/client_server_architecture.php3
[51] Ted Pedersen , S. V. S. P., Siddharth Patwardhan, Christopher G. Chute. WordNet::Similarity,
from http://wn-similarity.sourceforge.net/.

69
9. Appendices
Appendix A. Personal Reflection Working as a computer scientist in a work environment and working for course-works and
assignments at a University are two completely different concepts. In my opinion however,
working on a Final Year project is an solid introduction to what a Computer Scientist can
expect in a real job.
Of course no one individual would be expected to complete all the stages of a project in a
commercial environment, but it is very good preparation for final year students. When I first
started project meetings with my supervisor, she asked me questions such as “What are your
interests and ambitions”, “What are your strengths and weaknesses”, “What do want to do
after your graduate” and so on. I wasn’t able to accurately answer those questions because at
that stage of my life, my academic career had consisted of following instructions from my
supervisors, lecturers and others. With the completion of this project however, I can
confidentially provide accurate answer to those questions.
Having never worked on such a project before, it was a challenging task. It took me 2 weeks
to realise that the project was my own work and it was completely up to me to decide what I
wanted to do. I decided then and there that this project should be completed at all costs. The
decision was, I believe, a good motivator.
I decide to set two goals. On the one hand, involve myself in something which would be
challenging enough to stretch me, and on the other, be of a standard acceptable for my
University Degree and also a good demo for my portfolio (for the real job mentioned above).
Thank God, I had continued and ongoing support and advice from my supervisor and
ultimately, I completed a project that I believe achieved both of my goals.
Working on the project gave me the opportunity to start coding my own applications in what
were completely new (for me at least) languages. For the last two months, the book “PHP and
MySQL Web Development” has been my best friend. My programming skills have improved
to the point where and I can now develop web-based client server applications using PHP,
HTML, Javascript and MySQL.
Having to come to grips with a range of new tools (Navicat Professional, Adobe
Dreamweaver, etc) did take up a lot of my time and made my project more complicated, but
did give me a very good grounding in these tools. In addition, I have developed an
understanding of the importance of semantic similarities between words and I discovered new

70
tools like WordNet::Similarity API, Disco, Weak, to name just a few, that have given me new
ideas and concepts to further develop my project and make it even more powerful and useful.
Despite gaining a considerable amount of knowledge during the implementation of the
project, I also had to overcome various obstacles. These were mainly the selection of the
correct tools and programming languages.
I would strongly recommend that all final year students make the right choices of tools and
languages as in my case, I faced a serious setback through choosing the wrong programming
language. This mistake seriously impacted the functionality of my prototype and ate into
precious time I could not afford.
In my opinion, I could have developed a better prototype, with many more semantic
connections rather than connections between users, if I had made the selection of the correct
tools and programming languages from the start. My supervisor did point this out, but as I
wasn’t experienced in PHP, I first selected the languages and then the tools.
Computer Science may be a universal discipline and I study at an English University, but my
native language is Greek. Compiling a detailed report in English was not something I’d done
before, but continued work over the life of the project and the continued feed-back from my
supervisor have make a marked improvement in my confidence in writing such reports.
I would like to conclude with a note that I strongly believe will be of value to all students
undertaking future projects: Time management, schedule, appropriate methodology, and a
good supervisor are the compulsory ingredients for the successful completion of a final year
project. These elements will help you design something worthwhile, functional, completed on
time and, why not, worthy of a good grade.

71
Appendix B1. Original Project Schedule
Appendix B2. Original Project Schedule

72
Appendix B3. Analysis of Schedule Final Report:
• Continues writing carried out simultaneously with Research and prototype
design, implementation
• A Draft submitted as mid-project report is revised and used in the final
report
• A Draft submitted to the supervisor is reconsidered and the appropriate
changes are completed.
Evaluation:
• Testing of the LeARN prototype
• Comparing user opinions and WordNet::Similarity API results for semantic
similarity of Keywords
• Comparing user opinions with the publications returned by the LeARN
prototype
• Feedback from potential users (KRR Group members, School of Computing
students)
Prototype Design:
• Implementation of Algorithms used
• Implementation of queries that discovers connections between users
• Implementation of queries that discovers connections between materials
Mid-Project Report:
• A brief write up of the Background Research done until 05/02/10.
Research:
• Connections / Relatedness
• Community
• Algorithms, tools and methods can be used
• Semantic Similarity
Research Plan:
• Organize in a Schedule what areas should be researched

73
• What the available tools and methods are
• What algorithms should be considered
• What are the tools can be used in the particular project
• What is the type of LeARN community
• What programming languages to used
Prototype Research:
• Client Server architecture
• Database design
• User interface design
• Connections using queries and WordNet::Similarity API
• Users possible connections
• Materials possible connections
Project Plan:
Clarify the requirement analysis by considering the following things:
• What the overall aim of this project is
• What the objectives of this project are
• What are the minimum requirements
• Use Mind map to design a project schedule
*Notes:
• Meetings with the supervisor started on 04/12/09 and completed on the
10/05/2010. (Things discussed are in a log book – can be submitted if
required)
• Seminars with Knowledge Representation and Reasoning (KRR) Group
started on the 29/01/10 and completed on the 18/03/10
• Two presentations completed in KRR Seminars (Slide used can be submitted
if required)
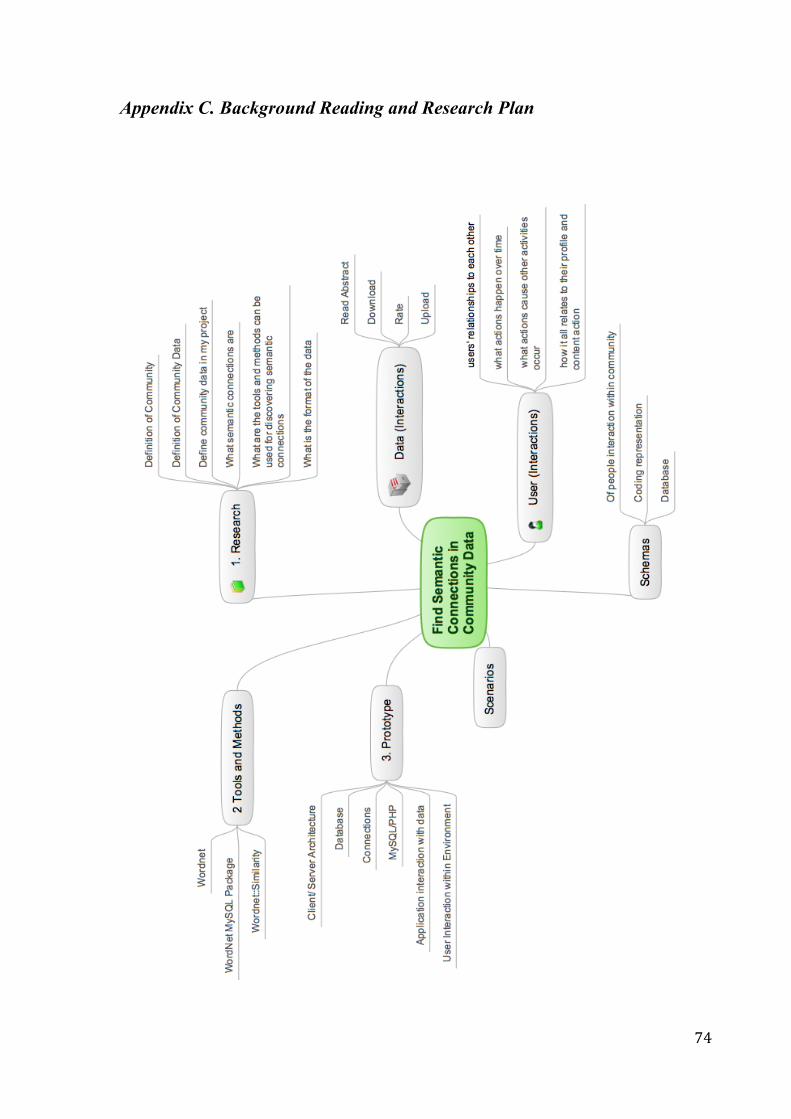
74
Appendix C. Background Reading and Research Plan

75
Appendix D. The description of community data schema
There are many ways to represent the tables of the LeARN application database in a scheme.
The following are the most compatible. Each table formed as follows:
1. Users: The entity user is a vital component of the database and it should include details
such as Title, First Name, Last Name, Occupation, Work E-mail address and Username/
Nickname and password the user wants to use in the community but it can also provide
information such as Phone (office), Office Location / Address as well as Occupation.
(Navathe et al, 1982). Of course, there are some other details that could be included such as
Phone (home), private E-mail address, Postal address, interests, personal statement,Website
(office), Website (home) but for the needs of the community this extra information is not
needed due to the privacy of users as well as due to the needs of the specific requirements of
the community has. (BSCW,1995-2009)
2. Material: The entity material is designed based on the Bibtex database. Oren Patashnik
and Leslie Lamport (1985) points out that an article requires the following details: author,
title, journal, year and optional details could be: volume, number, pages, month, abstract and
key. Similarly, other fields are compulsory for books, other for journals, etc (Patanik.1988).In
our application, the required fields for the general types of material we will be are using are
the isbn, material_title, material_abstract, material_date_of_publication and category_id. Of
course, some other information could be included but we decide to use only those which best
fits the data we will use. According to some experts, bibliographic information varies
according to the type of material you have. Based on the “EndNote X3”, a book requires
different information than a journal or a newspaper. Although, in other papers and programs
some other information may appears as optional and some other as required. (Fenn, 2007)
Taking into account all the experts opinions, in this specific application we use only the
information shown above because these details are enough for each material so that the
community will function properly. Except from experts decisions, some online libraries such
as Portal (Machinery, 2010) and SpringerLink (SpringerLink, 2010) use specific details for
each particular material that are useful for our application material table. Furthermore, we are
using only the table material instead of using one table for papers, one for other publications,
etc and that is the main reason we are using the category_id. All the materials will be
available in table material and each material will be assigned to one category. If necessary
one material may be relate to more than one category. (For more details see part (5))
Moreover, instead of using author details and other similar information, we are using the isbn
(International Standard Book Number) which exists only once and it refers to only one unique

76
material. There is a relation between isbn of material table and isbn of author table. In the
case where a paper has more than one author then there is no need to save the material as
many times as the number of authors. We are using isbn to give us the authors material. This
will give a good normalization form within the database.
3. Author: The author entity is designed based on the Bibliographic information files
forBibTex. As a result, according to experts, this entity should include information such as
author_title,author_first_name, author_last_name, author_details, author_id and finally isbn
for the material.
All the other details such as occupation, middle_name, E-mail address (work) ,E-mail,
address (home), city , Phone(home), Postal address, interests, personal statement, Website
(office), Website (home) are not required in our application since authors will be staff within
the University of Leeds and for safety reasons we do not want to publish personal information
of staff online. If a person / author decides to provide his/her information, this can be
achieved during their registration in the community where he creates his profile as user and
some of this information could be submitted. Taking into account ACM Portal and
SpringerLink, details we are using for author are enough since the only available information
is the name and surname of author and sometimes its organization where in our approach,
organization is the University of Leeds and therefore is useless to include it.
4. Course: The table course, has been designed aiming to avoid repetition of the same
information within the database. The information in this entity are the course_code which is
unique and the course_name which is necessary to know. By using course_code of this table
and the course_code of assigned material we find which material is related to a specific
course. [48,49] We don’t include this information in table material because if we include it, it
will be stored too many times rending this redundant.
5. Categories: The entity categories are requires information such us category_id and
category_name only. Those 2 should be completed so that we can find which material is
related to a specific category (books, articles, etc). This aims to avoid repetition of
information in the database and the best normal form.
6. User_Request: The entity user_requests requires data such as request_id, and
date_request. According to Luke Welling and Laura Thomson (2009), this information is
sufficient for the purpose this table is designed for. There the only information will be saved
is which of the users requested a specific (isbn) material and when.
7. Assigned_Material: The entity assigned_material requires data such as

77
assigned_material_id, isbn and course_code. This table in designed in this database in order
to avoid repetition of storing the course_code as many times as a material exists. It is helpful
because it stores which material is related to which course as soon as course_code is its
foreign key.
8. Material_by author: The entity material_by_author requires mba_id (material by
author_id) , author_id and isbn. According to the information found in “Database Answers”
[48,49], by including this table in our data model the normalization form of the database is
improved. The materials are categorized here by author respect to author_id that is related to
the same attribute in the table author and to the isbn which is connected with the isbn of the
table material. Any other details such as date of publication, category, course, etc are not
included here as the relations between the tables helps to return this information without been
in this table and stored a lot of times.
9. Occupation: The table occupation includes the roles of the users and it requires an
occupation_id and occupation_type. It has been simple designed because it only stores the
possible occupations of users existing within the community. It aims to avoid repetition of
storing the same information more than once within the database.

78
Appendix E. The core tables of WorNet SQL database
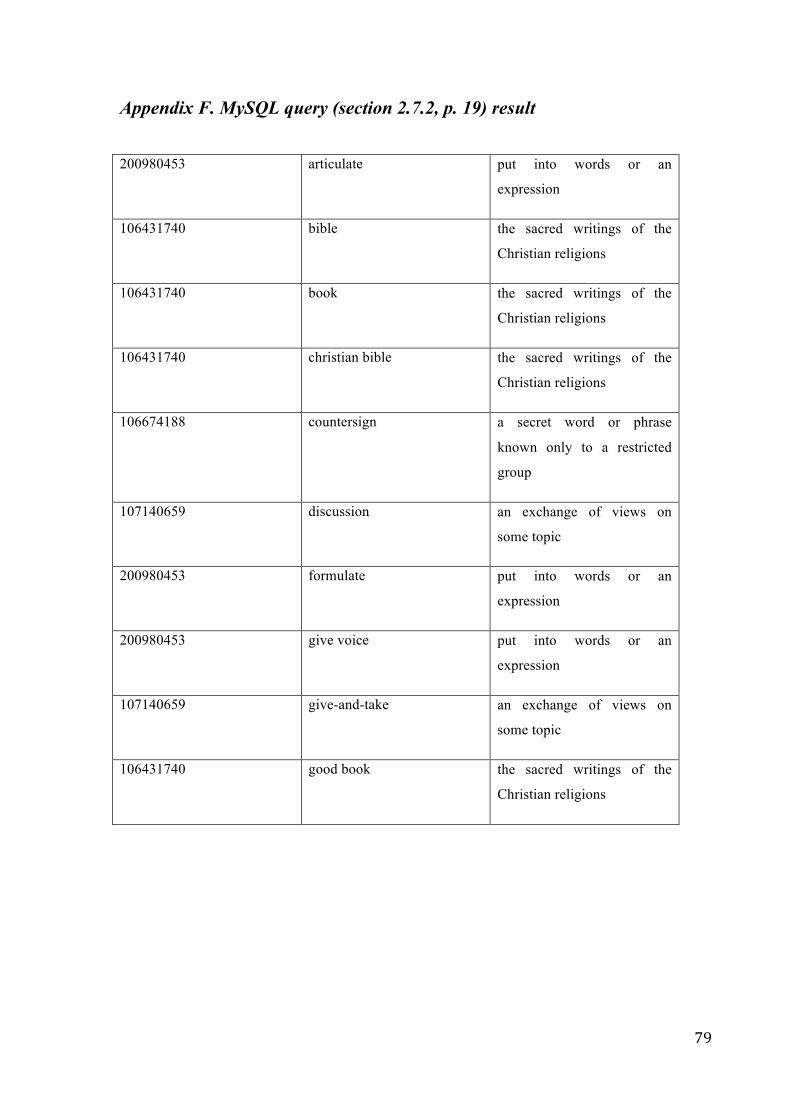
79
Appendix F. MySQL query (section 2.7.2, p. 19) result
200980453 articulate put into words or an
expression
106431740 bible the sacred writings of the
Christian religions
106431740 book the sacred writings of the
Christian religions
106431740 christian bible the sacred writings of the
Christian religions
106674188 countersign a secret word or phrase
known only to a restricted
group
107140659 discussion an exchange of views on
some topic
200980453 formulate put into words or an
expression
200980453 give voice put into words or an
expression
107140659 give-and-take an exchange of views on
some topic
106431740 good book the sacred writings of the
Christian religions
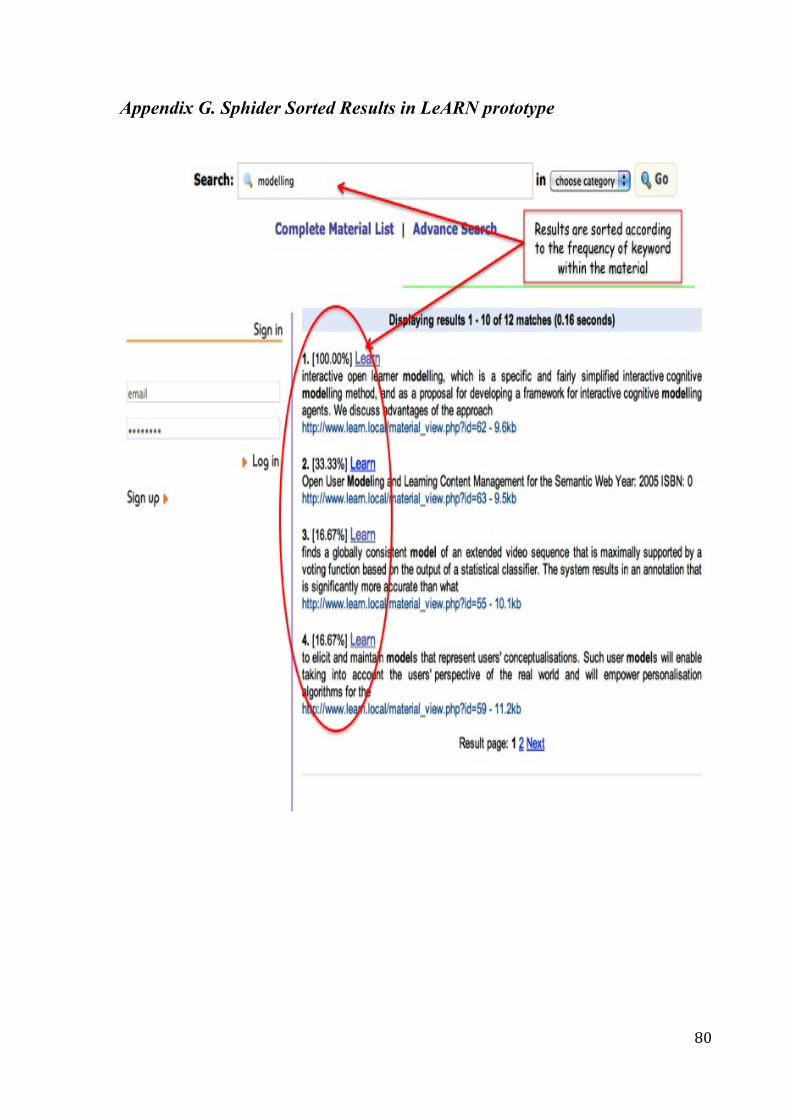
80
Appendix G. Sphider Sorted Results in LeARN prototype

81
Appendix H. Ranking Algorithm 1 [45]
Input: Data: Materials rated by each user
Output: Recommended material
1. Find nearest neighbors 1.1. Discover similarity with each user by calculating the similarity using cosine 1.2 Define neighborhood
i. Centre-‐based neighbourhood (size n) by sorting and choosing the first n
ii. Aggregated neighbourhood (size n) by taking the user closest to the centroid at each step and repeat (n-‐1) times
2. Weighted sum by 2.1 Scanning the neighborhood and calculating the frequency for each item 2.2 Can be Combined with the rating value
3. Association rules recommendation by 3.1 Expanding the number of materials based on association rules upon what has
been recommended by the neighbours
82
Appendix I. Prototype Environment Screenshots 1. A general preview of the prototype interface:
The home page of Leeds Academic Research Network
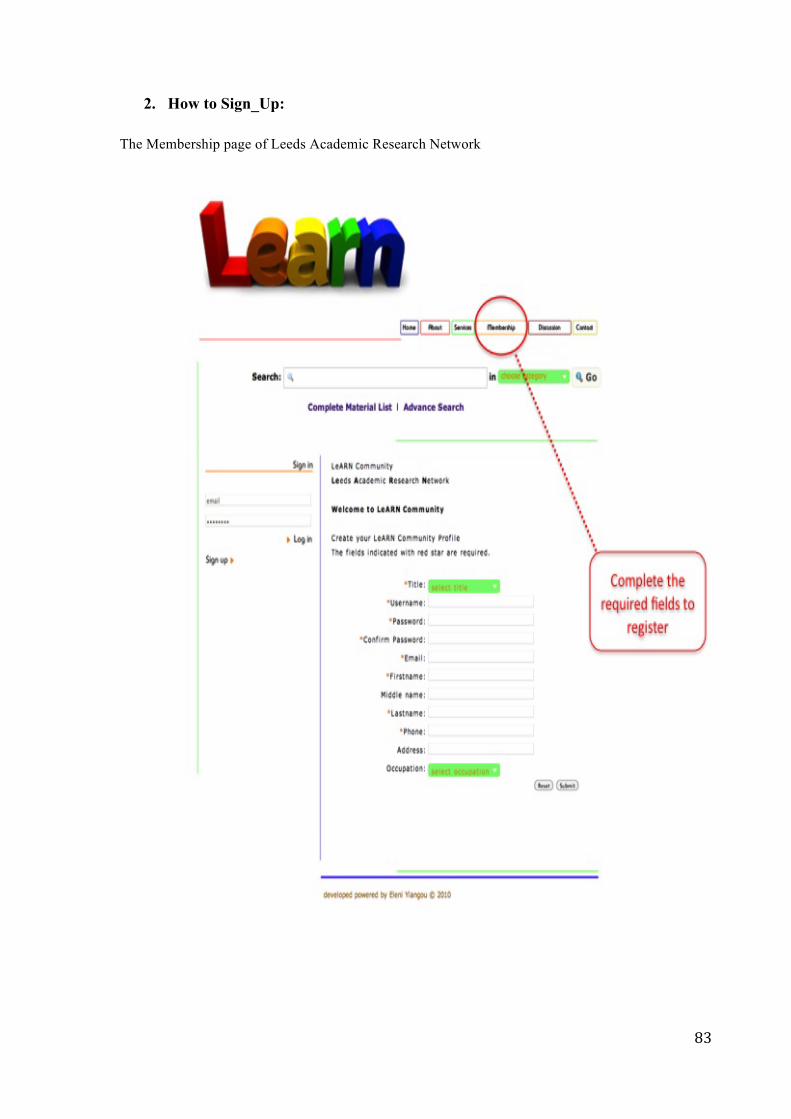
83
2. How to Sign_Up:
The Membership page of Leeds Academic Research Network

84
3. How to interact with the environment
The first actions a user can perform.
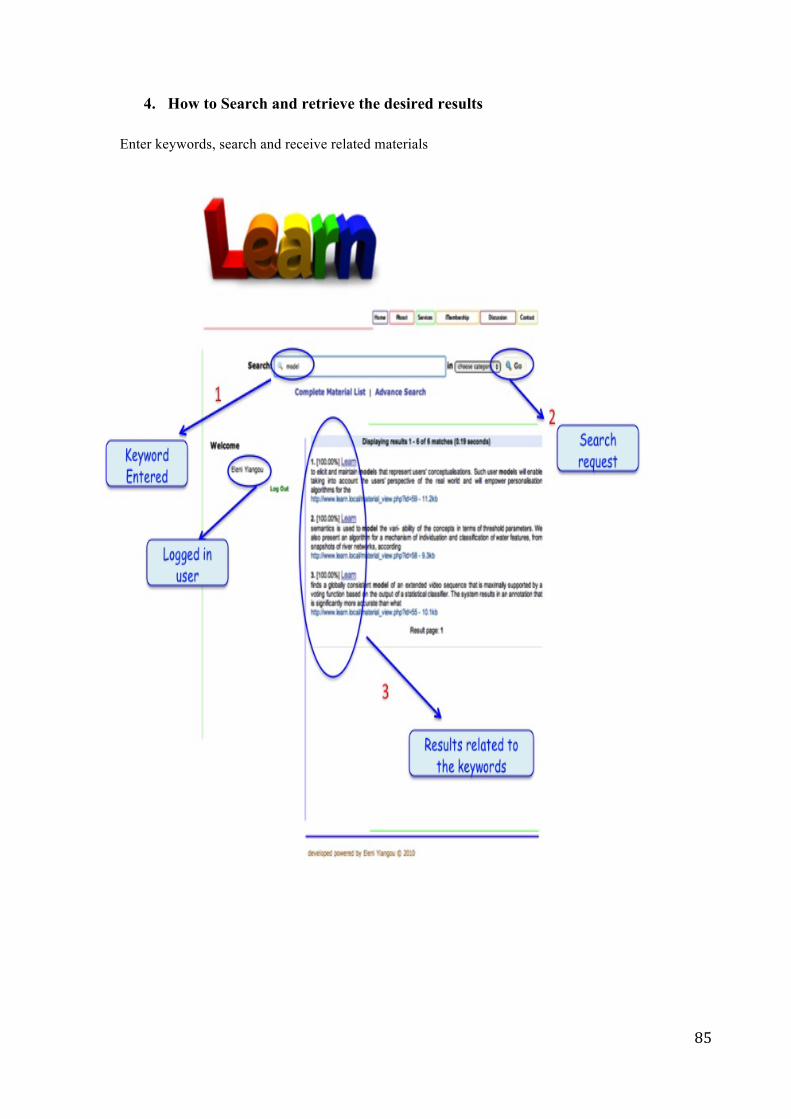
85
4. How to Search and retrieve the desired results
Enter keywords, search and receive related materials
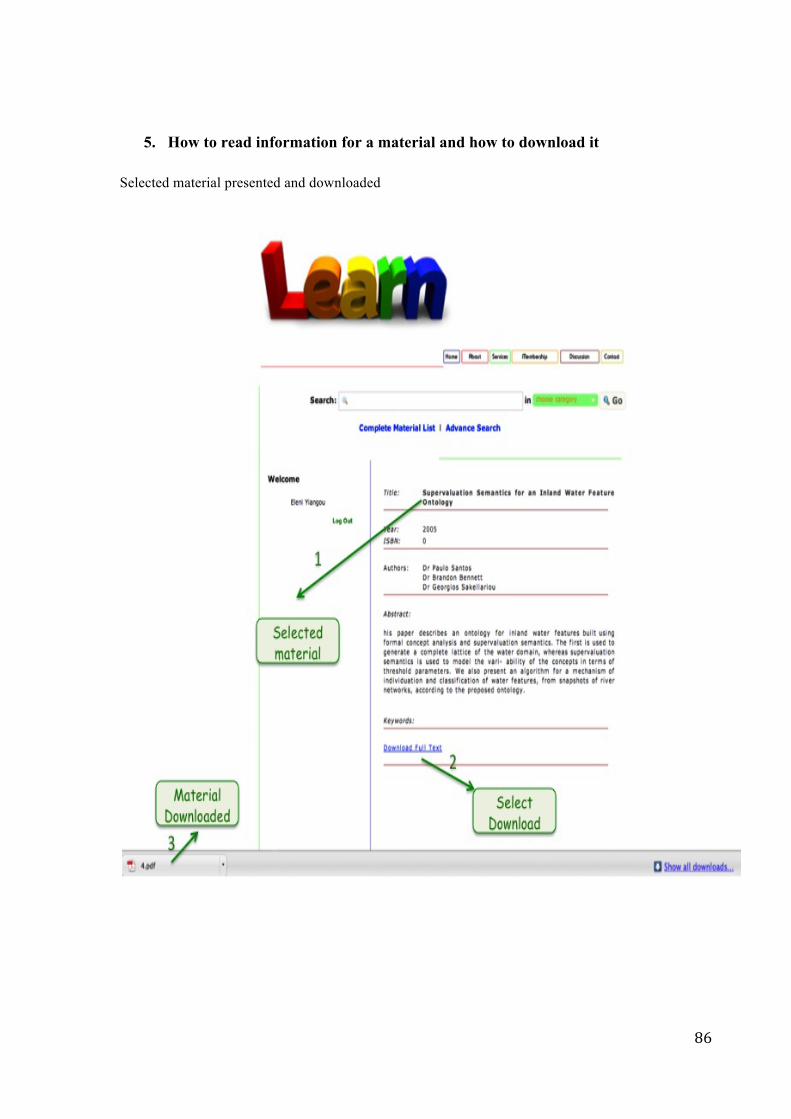
86
5. How to read information for a material and how to download it
Selected material presented and downloaded
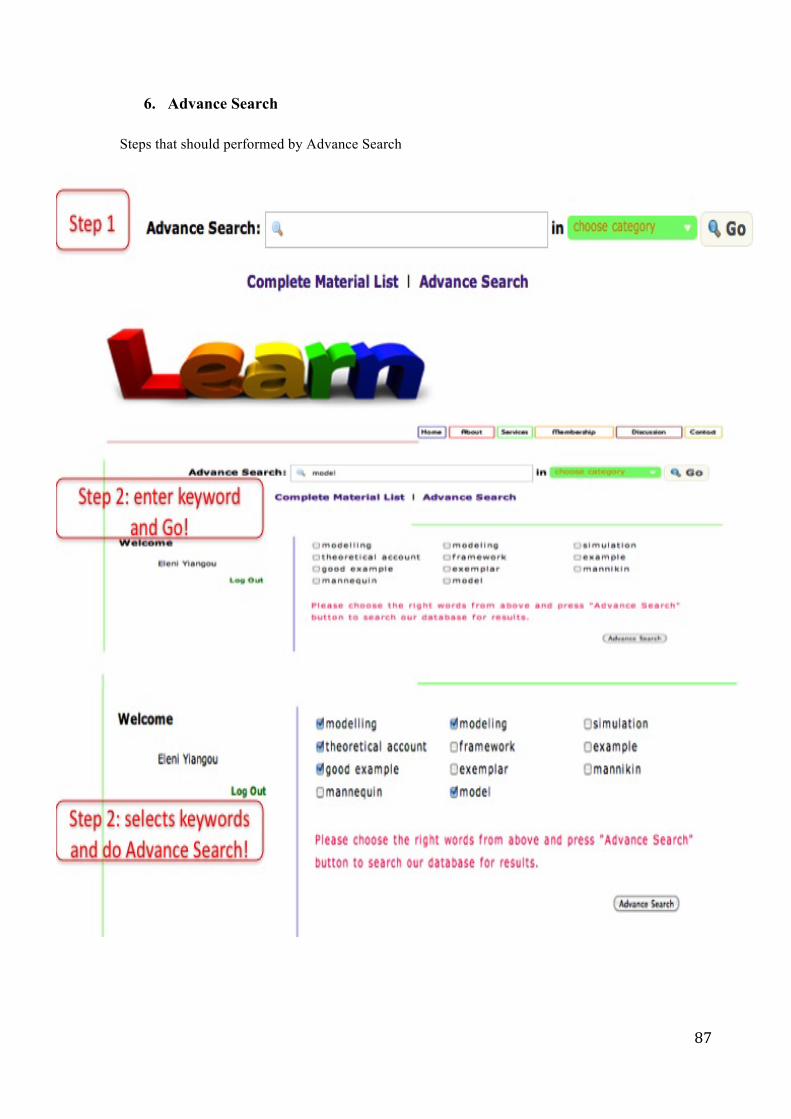
87
6. Advance Search
Steps that should performed by Advance Search
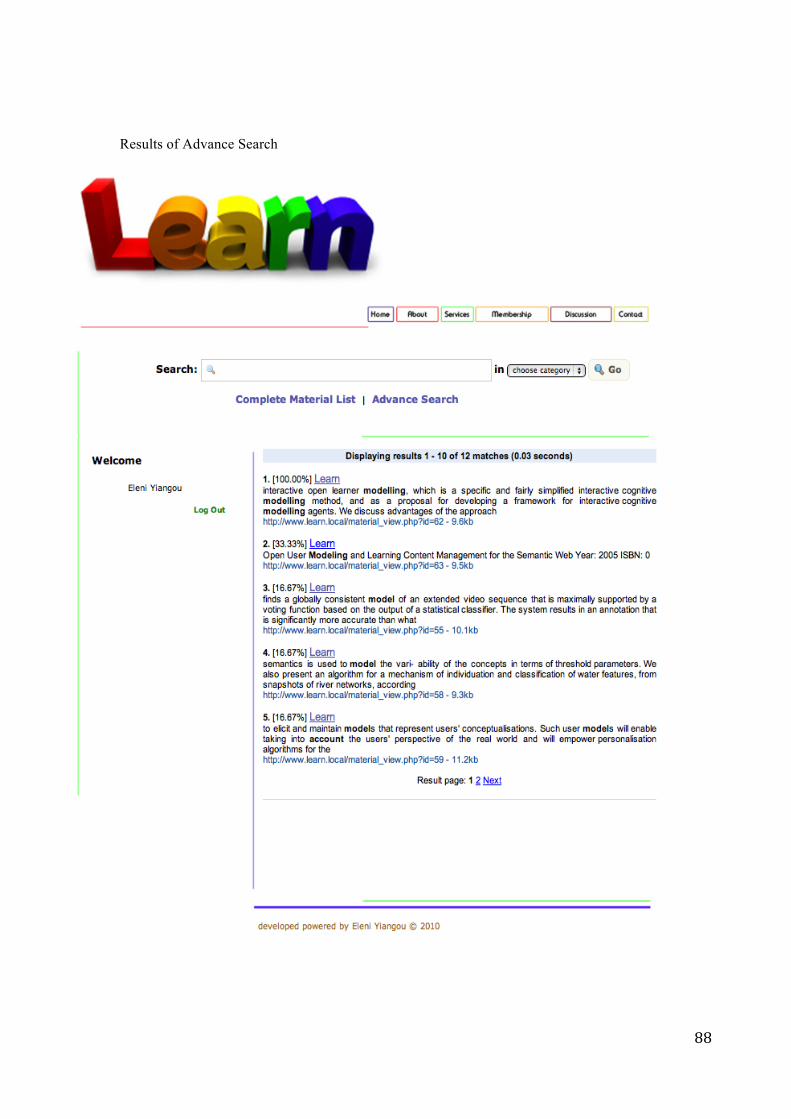
88
Results of Advance Search
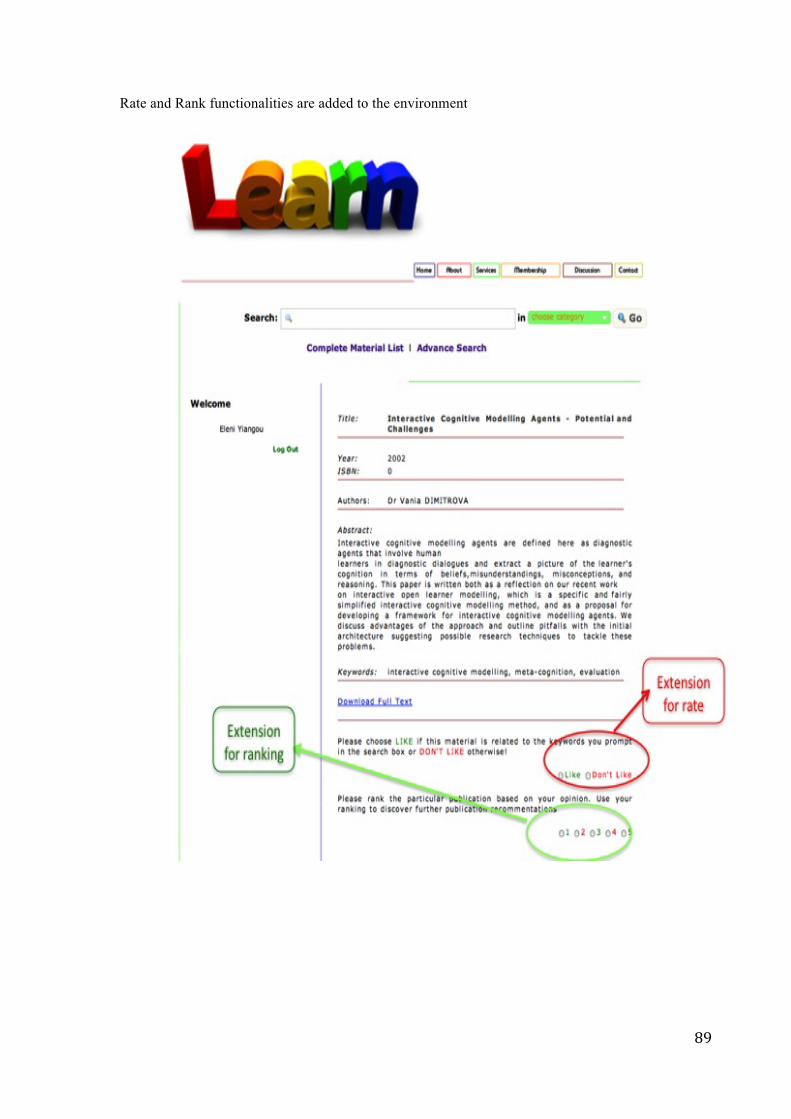
89
Rate and Rank functionalities are added to the environment
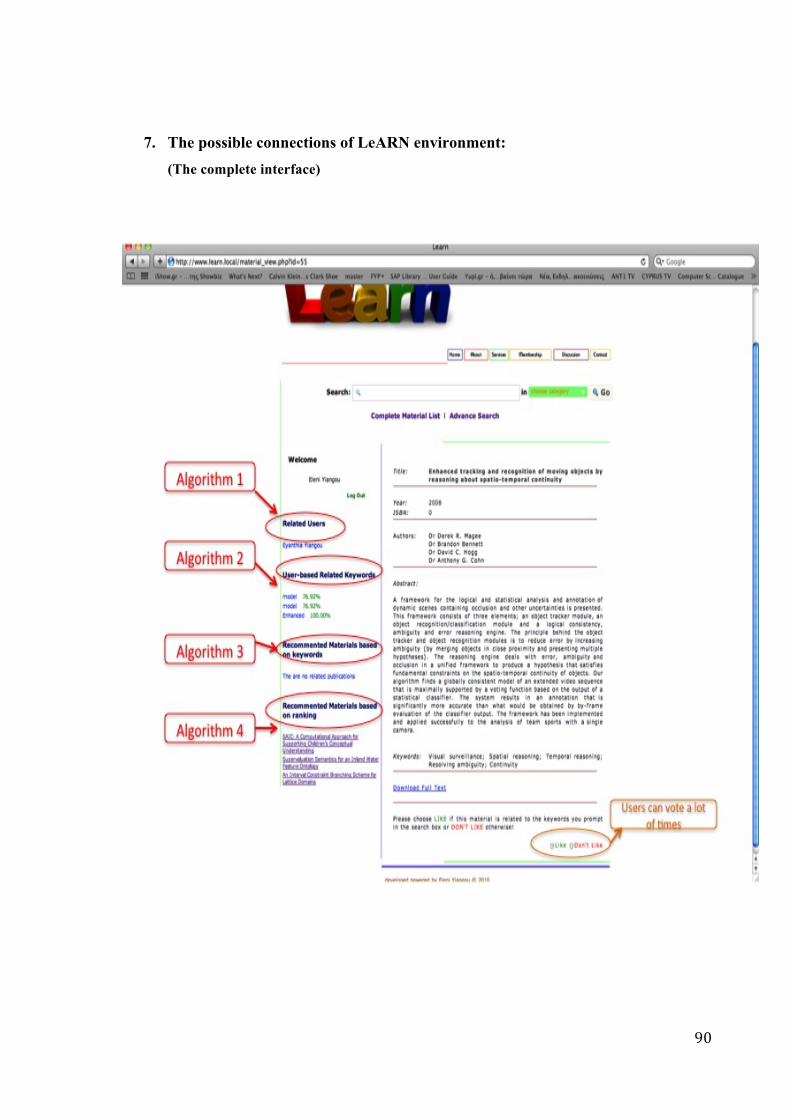
90
7. The possible connections of LeARN environment: (The complete interface)
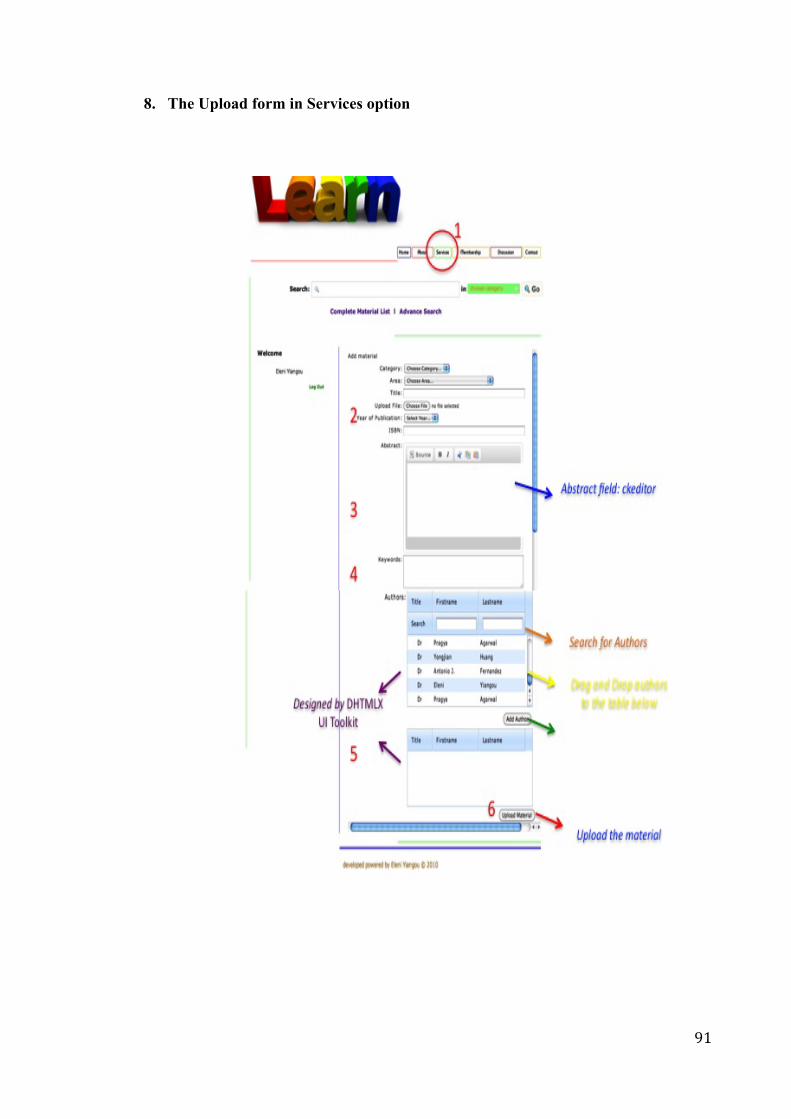
91
8. The Upload form in Services option

92
Appendix J. Algorithm implementation coding parts Algorithm 1:
Related users based on Downloads
Related users based on people Likes a material

93
Algorithm 2:
User-Based Related Keywords implementation
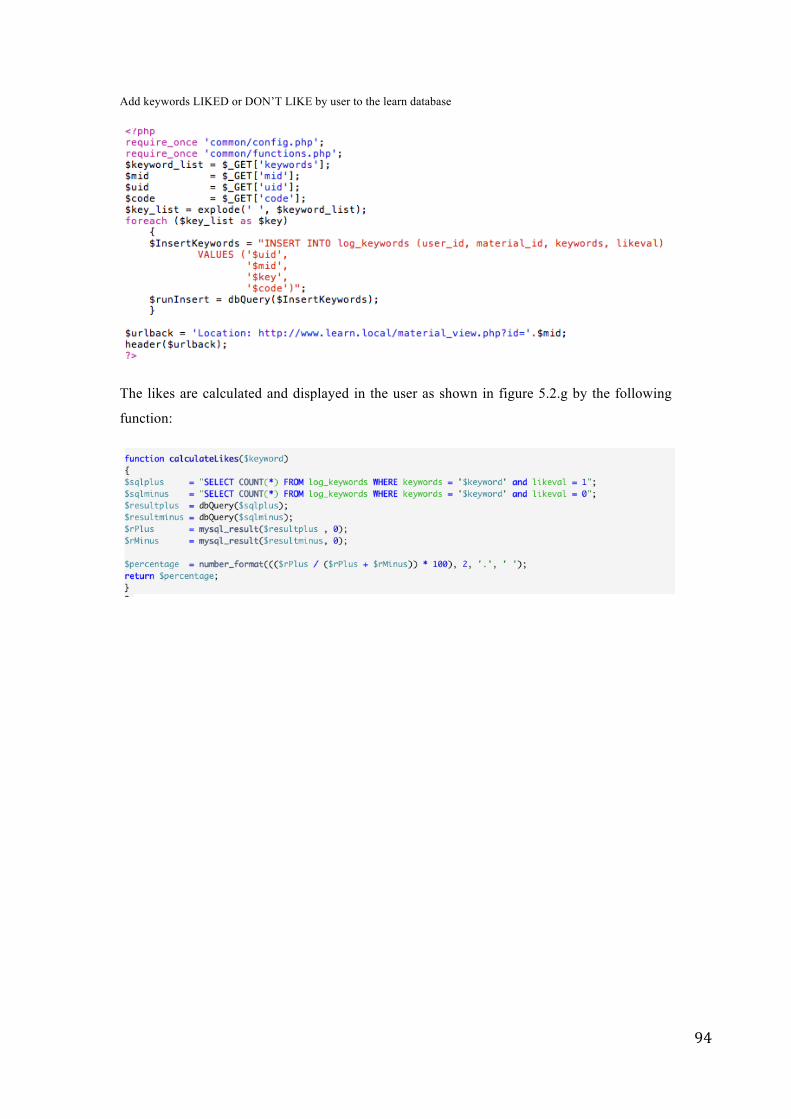
94
Add keywords LIKED or DON’T LIKE by user to the learn database
The likes are calculated and displayed in the user as shown in figure 5.2.g by the following
function:

95
Algorithm 3: How results of WordNet::Similarity API could be implemented in the
LeARN Environment if was available in PHP.

96

97
Algorithm 4:
Recommended materials based on ranking
Add keywords ranked in the learn database:
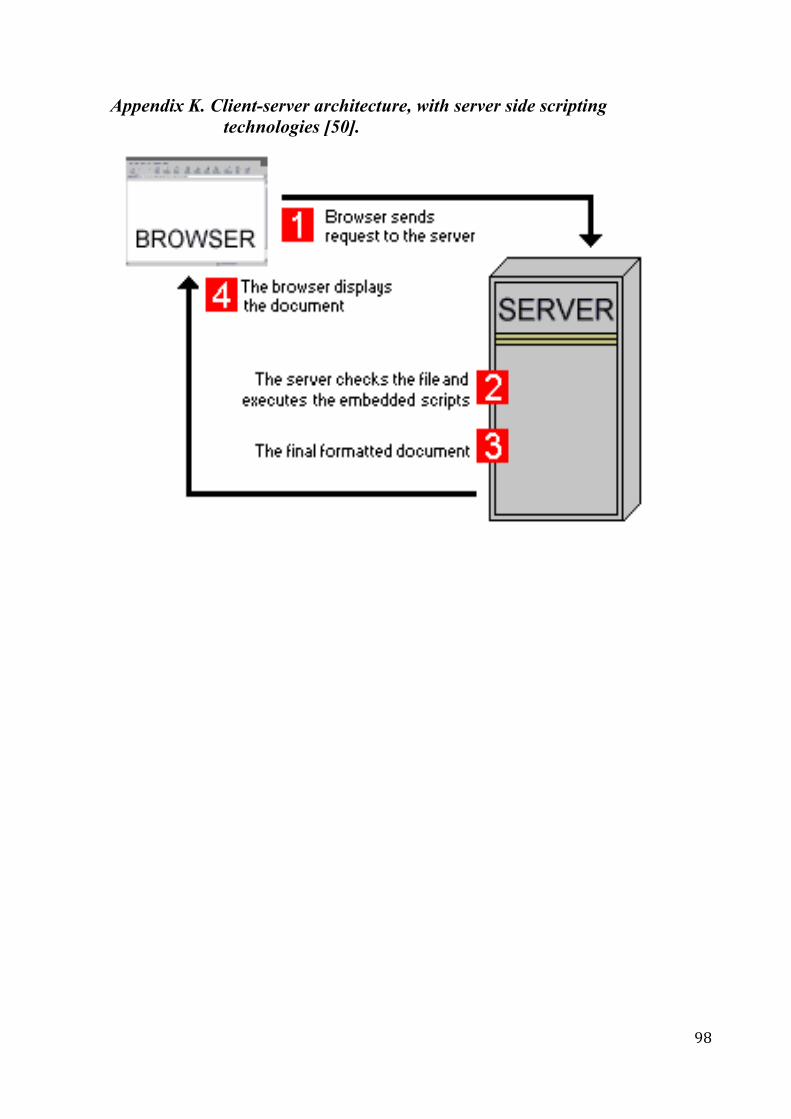
98
Appendix K. Client-server architecture, with server side scripting technologies [50].

99
Appendix L.
1. Scenario Used for evaluation
Please follow the scenario below and leave your commends:
User is registered in the School of Computing at the University of Leeds. User decides to use
LeARN Community in order to upload a material user found interesting, and might be helpful
for others. Before uploading the material, user decides to search if there are any materials
related to “Modeling method” in the community.
User uses the email and password given by author. As soon as user logged in, enters in the
search box “Modeling method” keywords and she press GO button. Then, the system return
all the available materials based on the keywords she prompt. User selects the first material
because that has the highest score (its keywords exists in that material more times than at the
other materials). Therefore, user read the title and abstract of this publication and decides that
this material is not what exactly user expected to find. However user notices that the
particular material is related to the keywords user entered. Thus user leaves a Like vote to the
material. User proceeds by selecting one of the papers that exists in the Recommended
Materials based on keywords list that is displayed at the left column of the page. That
material seems to be related to her interested area; hence user Downloads it by selecting the
Download Full Text link and user also rank it with a 4 score as soon as the publication is
really interested for her. After that, user decides to discover what other materials author of
her interested material wrote. Therefore, user selects author’s name and the publications
written by the selected user are displayed on the screen. However, user doesn’t find
something related to what user want. Thus, user chooses the Advance Search from the menu
and user rewrites the “Modeling method” keywords and Go.
As a result system returns to the screen all the words that are related to the keywords
prompted and Katja selects some words that thinks is most related to her research area and
proceed by selecting the Advance Search button. The available to the selected words
materials are returned and user chooses the first one. That material which is returned by the
keywords selected from the advance search seems to be very related to her interested area and
therefore user vote as Like the material. Moreover, user gave a 5 rank to that material and
user Downloads it.
As soon as user found the materials user is interested in, user finally selects Services button
from the menu and user completes all the required fields of the form. Then user selects the

100
Upload Material button. In order to check that the material is uploaded correctly, user selects
the Complete Material List at the top of the application. User notices that material user
uploads exists in the complete material list and therefore user logged out from the community
2. Questionnaire participants complete after the competition of the scenario:
1. How appropriate do you find the application scenario (with regards to the LeARN
architecture)?
2. Have you experienced any problems with the application?
3. How appropriate do you find the simulation (data used, components , etc)?
4. What is your opinion about the feasibility of the architecture?
5. Please note any missing functionality with regards to the system:
6. Please write some short notes about the robustness of the web application:
7. Please identify any issues that a real life application should cope with:

101
3.WordNet::Similarity Java API questionnaire The table below contains word pairs that exists in the learn database. Please complete the
Sim(keywords, KL) column by giving the semantic similarity/relatedness value you think best
matches to the keyword sets. Value can be 0.0 to 1.0. Please note that 0.0 means there is no
relation between keywords and KL and 1.0 means keyword sets are very semantically related:
material_id Keywords KL={k1,..kn} Sim( keywords, KL) Semantic Web Geospatial
Ontologies
User
Web-based distance
education;
Personalization
Semantic Web
Geospatial
Ontologies
User
Student tracking;
Personalisation
Semantic Web
Geospatial
Ontologies
User
7
Information visualization
Personalisation
Semantic Web
Geospatial
Ontologies
User
Interactive cognitive modeling;
Personalisation
Semantic Web
Geospatial
Ontologies
User
8
meta-cognition;
Personalisation

102
Semantic Web
Geospatial
Ontologies
User
Evaluation
Personalisation
Semantic Web
Geospatial
Ontologies
User
Abstract interpretation;
Personalisation
Semantic Web
Geospatial
Ontologies
User
Abstract domain Refinement;
Personalisation
Semantic Web
Geospatial
Ontologies
User
Powersets;
Personalisation
Semantic Web
Geospatial
Ontologies
User
widening operators;
Personalisation
Semantic Web
Geospatial
Ontologies
User
10
Convex polyhedra
Personalisation

103
The data (material, category, keywords) used to create the above table retrieved from the
materials illustrated in the following tables:
material_id category_id keywords
7 3 Web-based distance education; Student tracking; Information visualization
8 3 interactive cognitive modelling, meta-cognition, evaluation
10 4
Abstract interpretation, abstract domain refinement, powersets, widening operators, convex polyhedra.
KL Semantic Web, Geospatial, Ontologies, User, Personalisation
4. WordNet::Similarity Java API judgments according to human
Judgments and application results – the questionnaire results
The results by participants and WordNet::Similarity API are:
Sim( keywords, KL) (Participants Results (P)) Keywords KL={k1,..kn}
Sim( keywords, KL) WordNet::Similarity Java API Results
P1 P2 P3 P4 P5
Semantic Web 1.0 0.5 0.3 0.3 0.3 0.5
Geospatial Error 0 0 0 0 0
Ontologies 0 0.1 0.5 0.8 0.5 0.3
User 0.136 0.1 0 1.0 0 0
Web-based distance education;
Personalization 0 0.1 0.5 0.8 0.8 0.6
Semantic Web 0.298 0 0.3 0.6 0 05
Geospatial Error 0 0 0 0.2 0
Ontologies 0 0 0.7 0.5 1.0 0
Student tracking;
User 0.347 0.1 0.5 1.0 0.8 1.0
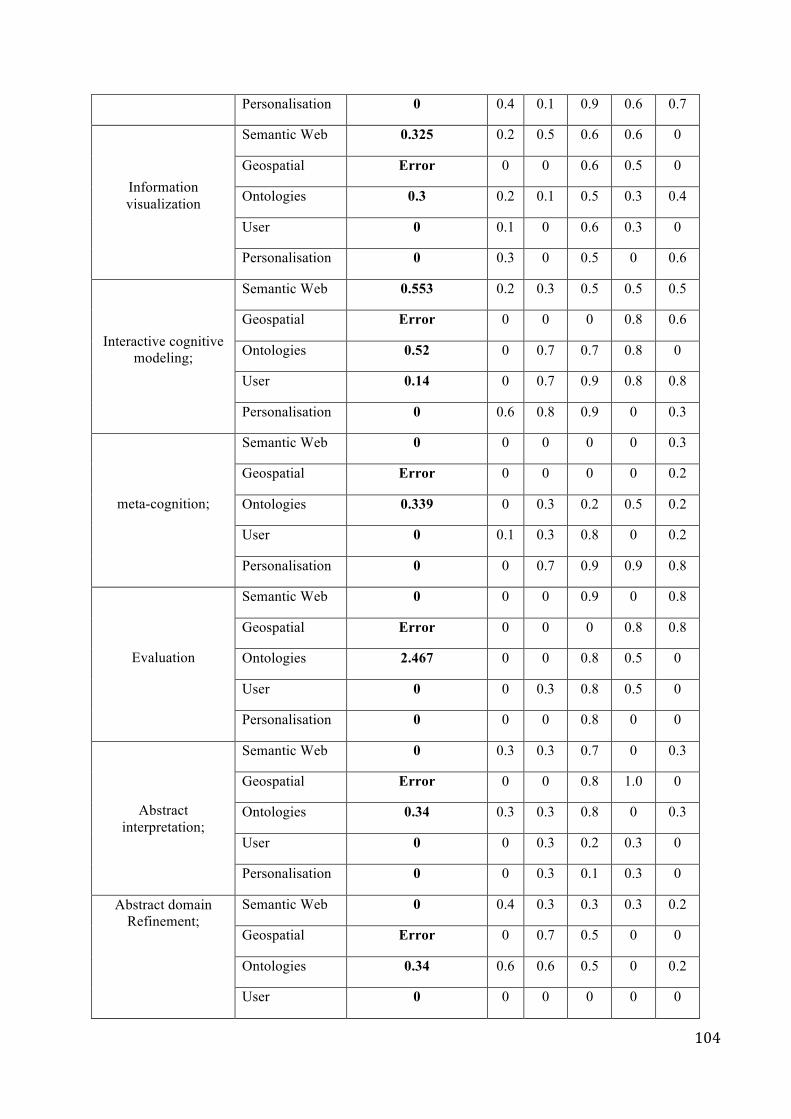
104
Personalisation 0 0.4 0.1 0.9 0.6 0.7
Semantic Web 0.325 0.2 0.5 0.6 0.6 0
Geospatial Error 0 0 0.6 0.5 0
Ontologies 0.3 0.2 0.1 0.5 0.3 0.4
User 0 0.1 0 0.6 0.3 0
Information visualization
Personalisation 0 0.3 0 0.5 0 0.6
Semantic Web 0.553 0.2 0.3 0.5 0.5 0.5
Geospatial Error 0 0 0 0.8 0.6
Ontologies 0.52 0 0.7 0.7 0.8 0
User 0.14 0 0.7 0.9 0.8 0.8
Interactive cognitive modeling;
Personalisation 0 0.6 0.8 0.9 0 0.3
Semantic Web 0 0 0 0 0 0.3
Geospatial Error 0 0 0 0 0.2
Ontologies 0.339 0 0.3 0.2 0.5 0.2
User 0 0.1 0.3 0.8 0 0.2
meta-cognition;
Personalisation 0 0 0.7 0.9 0.9 0.8
Semantic Web 0 0 0 0.9 0 0.8
Geospatial Error 0 0 0 0.8 0.8
Ontologies 2.467 0 0 0.8 0.5 0
User 0 0 0.3 0.8 0.5 0
Evaluation
Personalisation 0 0 0 0.8 0 0
Semantic Web 0 0.3 0.3 0.7 0 0.3
Geospatial Error 0 0 0.8 1.0 0
Ontologies 0.34 0.3 0.3 0.8 0 0.3
User 0 0 0.3 0.2 0.3 0
Abstract interpretation;
Personalisation 0 0 0.3 0.1 0.3 0
Semantic Web 0 0.4 0.3 0.3 0.3 0.2
Geospatial Error 0 0.7 0.5 0 0
Ontologies 0.34 0.6 0.6 0.5 0 0.2
Abstract domain Refinement;
User 0 0 0 0 0 0
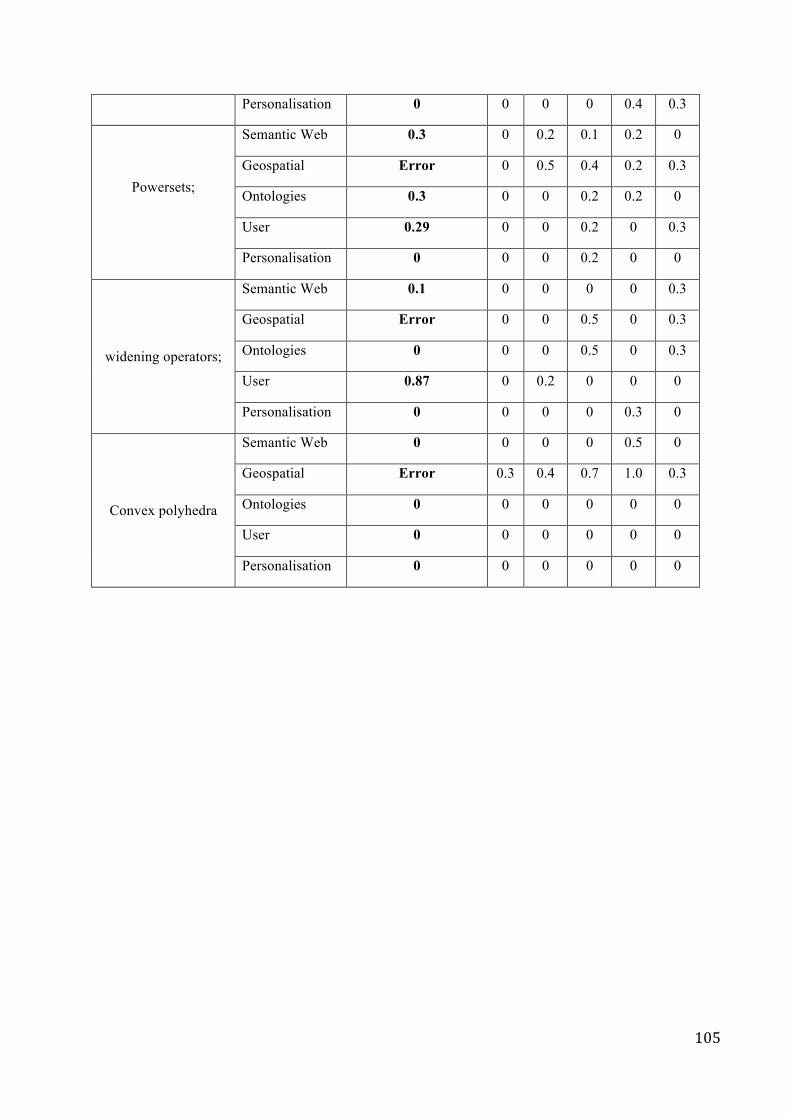
105
Personalisation 0 0 0 0 0.4 0.3
Semantic Web 0.3 0 0.2 0.1 0.2 0
Geospatial Error 0 0.5 0.4 0.2 0.3
Ontologies 0.3 0 0 0.2 0.2 0
User 0.29 0 0 0.2 0 0.3
Powersets;
Personalisation 0 0 0 0.2 0 0
Semantic Web 0.1 0 0 0 0 0.3
Geospatial Error 0 0 0.5 0 0.3
Ontologies 0 0 0 0.5 0 0.3
User 0.87 0 0.2 0 0 0
widening operators;
Personalisation 0 0 0 0 0.3 0
Semantic Web 0 0 0 0 0.5 0
Geospatial Error 0.3 0.4 0.7 1.0 0.3
Ontologies 0 0 0 0 0 0
User 0 0 0 0 0 0
Convex polyhedra
Personalisation 0 0 0 0 0 0

106