direct kernel methods. data mining is the process of automatically extracting valid, novel,...
Post on 20-Dec-2015
217 views
TRANSCRIPT

Direct Kernel Methods
Intro To data Mining
Mark J. Embrechts ([email protected])
www.drugmining.com
Department of Decision Sciences and Engineering Systems Rensselaer Polytechnic Institute, Troy, New York, 12180

Data mining is the process of automatically extracting valid, novel, potentially useful and ultimately comprehensible information from very large databases

Direct Kernel Methods
database
data prospectingand surveying
selecteddata
select transformeddata
preprocess& transform make model
Interpretation&rule formulation
The Data Mining Process

How is Data Mining Different?
• Emphasis on large data sets - Not all data fit in memory (necessarily) - Outlier detection, rare events, errors, missing data, minority classes - Scaling of computation time with data size is an issue - Large data sets: i.e., large number of records and/or large number of attributes fusion of databases
• Emphasis on finding interesting, novel non-obvious information - It is not necessarily known what exactly one is looking for - Models can be highly nonlinear - Information nuggets can be valuable
• Different methods - Statistics - Association rules & Pattern recognition - AI - Computational intelligence (neural nets, genetic algorithms, fuzzy logic) - Support vector machines and kernel-based methods - Visualization (SOM, pharmaplots)
• Emphasis on explaining and feedback
• Interdisciplinary nature of data mining

Direct Kernel Methods
Data Mining Challenges
• Large data sets - Data sets can be rich in the number of data - Data sets can be rich in the number of attributes• Data preprocessing and feature definition - Data representation - Attribute/Feature selection - Transforms and scaling• Scientific data mining - Classification, multiple classes, regression - Continuous and binary attributes - Large datasets - Nonlinear Problems• Erroneous data, outliers, novelty, and rare events - Erroneous data - Outliers - Rare events - Novelty detection• Smart visualization techniques• Feature Selection & Rule formulation
Direct Kernel Methods
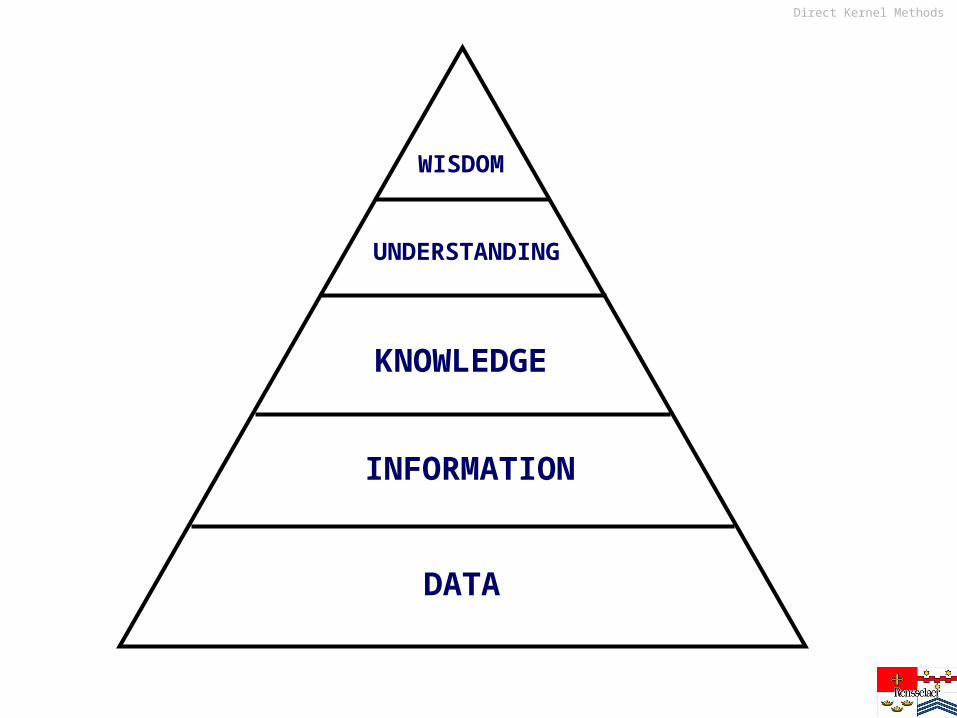
UNDERSTANDING
WISDOM
DATA
INFORMATION
KNOWLEDGE

Direct Kernel Methods
A Brief History in Data Mining:Pascal Bayes Fisher Werbos Vapnik
• The meaning of “Data Mining” changed over time: - Pre 1993: “Data mining is art of torturing the data into a confession” - Post 1993: “Data mining is the art of charming the data into confession”
• From the supermarket scanner to the human genome - Pre 1998: Database marketing and marketing driven applications - Post 1998: The emergence of scientific data mining
• From AI expert systems data-driven expert systems: - Pre 1990: The experts speak (AI Systems) - Post 1995: Attempts to let the data to speak for themselves - 2000+: The data speak …
• A brief history of statistics and statistical learning theory: - From the calculus of chance to the calculus of probabilities (Pascal Bayes) - From probabilities to statistics (Bayes Fisher) - From statistics to machine learning (Fisher & Tuckey Werbos Vapnik)
• From theory to application
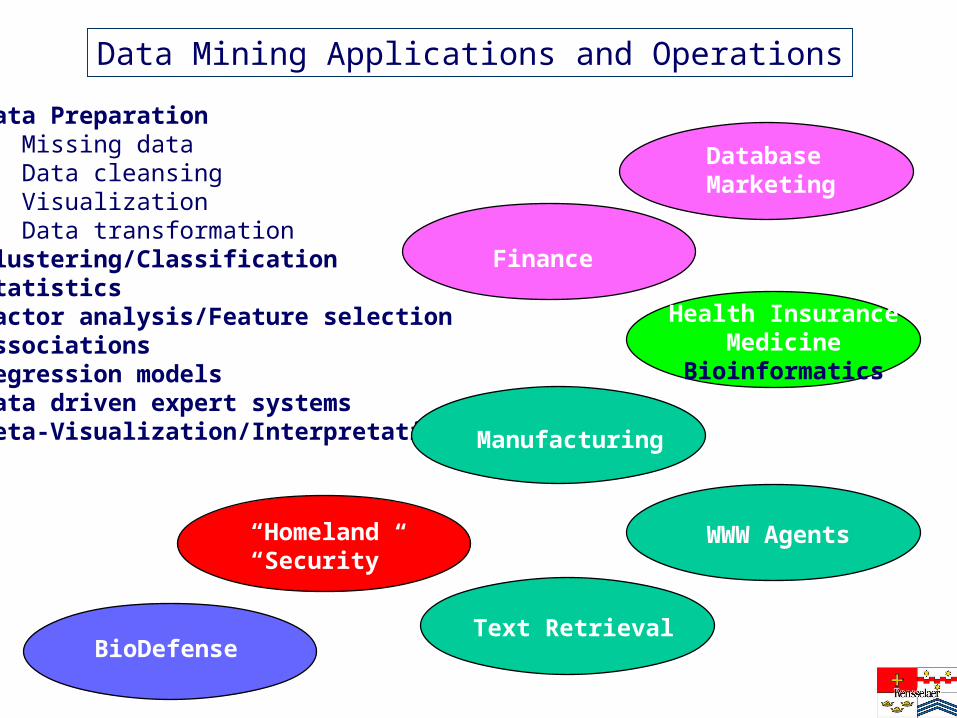
• Data Preparation - Missing data - Data cleansing - Visualization - Data transformation• Clustering/Classification• Statistics• Factor analysis/Feature selection• Associations• Regression models• Data driven expert systems• Meta-Visualization/Interpretation
Database Marketing
Finance
Health InsuranceMedicine
Bioinformatics
Manufacturing
WWW Agents
Text Retrieval
Data Mining Applications and Operations
“Homeland”
“Security”
BioDefense

Direct Kernel Methods
Direct Kernel Methods for Data Mining: Outline
• Classical (linear) regression analysis and the learning paradox
• Resolving the learning paradox by - Resolving the rank deficiency (e.g., PCA) - Regularization (e.g., Ridge Regression)
• Linear and nonlinear kernels
• Direct kernel methods for nonlinear regression - Direct Kernel Principal Component Analysis DK-PCA - (Direct) Kernel Ridge Regression Least Squares SVM (LS-SVM) - Direct Kernel Partial Least Squares Partial Least-Squares SVM - Direct Kernel Self-Organizing Maps DK-SOM
• Feature selection, memory requirements, hyperparameter selection
• Examples: - Nonlinear toy examples (DK-PCA Haykin’s Spiral, LS-SVM for Cherkassky data) - K-PLS for Time series data - K-PLS for QSAR drug design - LS-SVM Nerve agent classification with electronic nose - K-PLS with feature selection on microarray gene expression data (leukemia) - Direct Kernel SOM and DK-PLS for Magnetocardiogram data - Direct Kernel SOM for substance identification from spectrograms

Direct Kernel Methods
Outline
• Classical (linear) regression analysis and the learning paradox
• Resolving the learning paradox by - Resolving the rank deficiency (e.g., PCA) - Regularization (e.g., Ridge Regression)
• Linear and nonlinear kernels
• Direct kernel methods for nonlinear regression - Direct Kernel Principal Component Analysis DK-PCA - (Direct) Kernel Ridge Regression Least Squares SVMs (LS-SVM) - Direct Kernel Partial Least Squares Partial Least-Squares SVMs - Direct Kernel Self-Organizing Maps DK-SOM
• Feature selection, memory requirements, hyperparameter selection
• Examples: - Nonlinear toy examples (DK-PCA Haykin’s Spiral, LS-SVM for Cherkassky data) - K-PLS for Time series data - K-PLS for QSAR drug design - LS-SVM Nerve agent classification with electronic nose - K-PLS with feature selection on microarray gene expression data (leukemia) - Direct Kernel SOM and DK-PLS for Magnetocardiogram data

Direct Kernel Methods
Review: What is in a Kernel?
• A kernel can be considered as a (nonlinear) data transformation - Many different choices for the kernel are possible - The Radial Basis Function (RBF) or Gaussian kernel is an effective nonlinear kernel
• The RBF or Gaussian kernel is a symmetric matrix - Entries reflect nonlinear similarities amongst data descriptions
- As defined by:
22
2lj xx
ij ek
nnnn
inijii
n
n
nn
kkk
kkkk
kkk
kkk
K
...
...
...
21
21
22221
11211
�

Docking Ligands is a Nonlinear Problem

Direct Kernel Methods
• Surface properties are encoded on 0.002 e/au3 surface Breneman, C.M. and Rhem, M. [1997] J. Comp. Chem., Vol. 18 (2), p. 182-197
• Histograms or wavelet encoded of surface properties give Breneman’s TAE property descriptors
• 10x16 wavelet descriptore
Electron Density-Derived TAE-Wavelet Descriptors
PIP (Local Ionization Potential)
Histograms
Wavelet Coefficients

Direct Kernel Methods
• Binding affinities to human serum albumin (HSA): log K’hsa• Gonzalo Colmenarejo, GalaxoSmithKline J. Med. Chem. 2001, 44, 4370-4378
• 95 molecules, 250-1500+ descriptors• 84 training, 10 testing (1 left out)• 551 Wavelet + PEST + MOE descriptors• Widely different compounds• Acknowledgements: Sean Ekins (Concurrent) N. Sukumar (Rensselaer)

Direct Kernel Methods
Validation Model: 100x leave 10% out validations
Direct Kernel Methods
PLS, K-PLS, SVM, ANN
0.05
0.1
0.15
0.2
0.25
0.3
0.35
0.4
0.45
0 100 200 300 400 500 600
1 -
Q2
# Features
1 - Q2 versus # Features on Validation Set
Thu Mar 13 15:59:57 2003
'evolve.txt' using 1:2
Feature Selection (data strip mining)

Direct Kernel Methods
511 features
32 features
K-PLS Pharmaplots

Direct Kernel Methods
Microarray Gene Expression Data for Detecting Leukemia
• 38 data for training• 36 data for testing• Challenge: select ~10 out of 6000 genes used sensitivity analysis for feature selection
-1 -0.8 -0.6 -0.4 -0.2 0 0.2 0.4 0.6 0.8 1
-1
-0.8
-0.6
-0.4
-0.2
0
0.2
0.4
0.6
0.8
1
39
40
4142
4344
45
464748
49505152
53
54
55
56
5758
59
60
6162
63
64
65
66
67
68
69
70
71
72
SCATTERPLOT DATA ( results.ttt )
Observed Response
Pred
icte
d R
espo
nse
q2 = 0.405 Q2 = 0.447RMSE = 0.658
(with Kristin Bennett)

Direct Kernel Methods
-1.5
-1
-0.5
0
0.5
1
1.5
2
2.5
0 5 10 15 20 25 30 35
Targ
et
an
d P
redic
ted V
alu
es
Sorted Sequence Number
Errorplot for Test Data
Wed Apr 16 17:01:38 2003
targetpredicted

Direct Kernel Methods
0
0.2
0.4
0.6
0.8
1
0 0.2 0.4 0.6 0.8 1
Tru
e P
osi
tives
False Positives
ROC Curve
Wed Apr 16 17:02:35 2003
Direct Kernel Methods
with Wunmi Osadik and Walker Land (Binghamton University)Acknowledgement: NSF

Direct Kernel Methods
Magnetocardiography at CardioMag Imaging inc.

Direct Kernel Methods
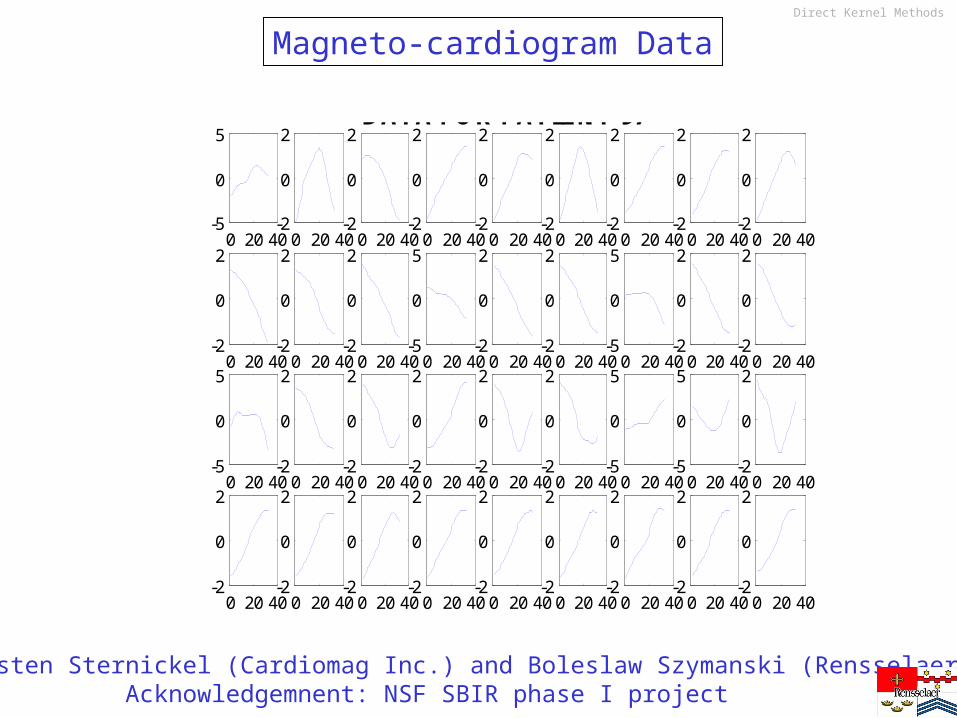
Left: Filtered and averaged temporal MCG traces for one cardiac cycle in 36 channels (the 6x6 grid).Right Upper: Spatial map of the cardiac magnetic field, generated at an instant within the ST interval. Right Lower: T3-T4 sub-cycle in one MCG signal trace
Direct Kernel Methods
Magneto-cardiogram Data
0 20 40-5
0
5
0 20 40-2
0
2
0 20 40-2
0
2
0 20 40-2
0
2
0 20 40-2
0
2
0 20 40-2
0
2
0 20 40-2
0
2
0 20 40-2
0
2
0 20 40-2
0
2
0 20 40-2
0
2
0 20 40-2
0
2
0 20 40-2
0
2
0 20 40-5
0
5
0 20 40-2
0
2
0 20 40-2
0
2
0 20 40-5
0
5
0 20 40-2
0
2
0 20 40-2
0
2
0 20 40-5
0
5
0 20 40-2
0
2
0 20 40-2
0
2
0 20 40-2
0
2
0 20 40-2
0
2
0 20 40-2
0
2
0 20 40-5
0
5
0 20 40-5
0
5
0 20 40-2
0
2
0 20 40-2
0
2
0 20 40-2
0
2
0 20 40-2
0
2
0 20 40-2
0
2
0 20 40-2
0
2
0 20 40-2
0
2
0 20 40-2
0
2
0 20 40-2
0
2
0 20 40-2
0
2
DATA FOR PATIENT 97
with Karsten Sternickel (Cardiomag Inc.) and Boleslaw Szymanski (Rensselaer)Acknowledgemnent: NSF SBIR phase I project

Direct Kernel Methods
-1.5
-1
-0.5
0
0.5
1
1.5
2
0 5 10 15 20 25
Target
an
d P
redic
ted V
alu
es
Sorted Sequence Number
Errorplot for Test Data
Thu May 08 21:04:45 2003
targetpredicted
SVMLib
Linear PCA
Direct Kernel PLS
SVMLib
7 (TN) 0 (FN)3 (FN) 15 (TP)

Direct Kernel Methods
PharmaPlot
Wed Mar 19 15:23:32 2003
'negative''positive'
-0.08-0.06-0.04-0.02 0 0.02 0.04First PLS Component -0.06-0.04
-0.02 0
0.02 0.04
0.06 0.08
Second PLS Component
-0.08-0.06-0.04-0.02
0 0.02 0.04 0.06 0.08 0.1
Third PLS Component
Direct Kernel PLS with 3 Latent Variables

Direct Kernel Methods
Direct Kernel7 (TN) 0 (FN)4 (FN) 14 (TP)
with Robert Bress and Thanakorn Naenna

GATCAATGAGGTGGACACCAGAGGCGGGGACTTGTAAATAACACTGGGCTGTAGGAGTGA
TGGGGTTCACCTCTAATTCTAAGATGGCTAGATAATGCATCTTTCAGGGTTGTGCTTCTA
TCTAGAAGGTAGAGCTGTGGTCGTTCAATAAAAGTCCTCAAGAGGTTGGTTAATACGCAT
GTTTAATAGTACAGTATGGTGACTATAGTCAACAATAATTTATTGTACATTTTTAAATAG
CTAGAAGAAAAGCATTGGGAAGTTTCCAACATGAAGAAAAGATAAATGGTCAAGGGAATG
GATATCCTAATTACCCTGATTTGATCATTATGCATTATATACATGAATCAAAATATCACA
CATACCTTCAAACTATGTACAAATATTATATACCAATAAAAAATCATCATCATCATCTCC
ATCATCACCACCCTCCTCCTCATCACCACCAGCATCACCACCATCATCACCACCACCATC
ATCACCACCACCACTGCCATCATCATCACCACCACTGTGCCATCATCATCACCACCACTG
TCATTATCACCACCACCATCATCACCAACACCACTGCCATCGTCATCACCACCACTGTCA
TTATCACCACCACCATCACCAACATCACCACCACCATTATCACCACCATCAACACCACCA
CCCCCATCATCATCATCACTACTACCATCATTACCAGCACCACCACCACTATCACCACCA
CCACCACAATCACCATCACCACTATCATCAACATCATCACTACCACCATCACCAACACCA
CCATCATTATCACCACCACCACCATCACCAACATCACCACCATCATCATCACCACCATCA
CCAAGACCATCATCATCACCATCACCACCAACATCACCACCATCACCAACACCACCATCA
CCACCACCACCACCATCATCACCACCACCACCATCATCATCACCACCACCGCCATCATCA
TCGCCACCACCATGACCACCACCATCACAACCATCACCACCATCACAACCACCATCATCA
CTATCGCTATCACCACCATCACCATTACCACCACCATTACTACAACCATGACCATCACCA
CCATCACCACCACCATCACAACGATCACCATCACAGCCACCATCATCACCACCACCACCA
CCACCATCACCATCAAACCATCGGCATTATTATTTTTTTAGAATTTTGTTGGGATTCAGT
ATCTGCCAAGATACCCATTCTTAAAACATGAAAAAGCAGCTGACCCTCCTGTGGCCCCCT
TTTTGGGCAGTCATTGCAGGACCTCATCCCCAAGCAGCAGCTCTGGTGGCATACAGGCAA
CCCACCACCAAGGTAGAGGGTAATTGAGCAGAAAAGCCACTTCCTCCAGCAGTTCCCTGT
GATCAATGAGGTGGACACCAGAGGCGGGGACTTGTAAATAACACTGGGCTGTAGGAGTGA
TGGGGTTCACCTCTAATTCTAAGATGGCTAGATAATGCATCTTTCAGGGTTGTGCTTCTA
TCTAGAAGGTAGAGCTGTGGTCGTTCAATAAAAGTCCTCAAGAGGTTGGTTAATACGCAT
GTTTAATAGTACAGTATGGTGACTATAGTCAACAATAATTTATTGTACATTTTTAAATAG
CTAGAAGAAAAGCATTGGGAAGTTTCCAACATGAAGAAAAGATAAATGGTCAAGGGAATG
GATATCCTAATTACCCTGATTTGATCATTATGCATTATATACATGAATCAAAATATCACA
CATACCTTCAAACTATGTACAAATATTATATACCAATAAAAAATCATCATCATCATCTCC
ATCATCACCACCCTCCTCCTCATCACCACCAGCATCACCACCATCATCACCACCACCATC
ATCACCACCACCACTGCCATCATCATCACCACCACTGTGCCATCATCATCACCACCACTG
TCATTATCACCACCACCATCATCACCAACACCACTGCCATCGTCATCACCACCACTGTCA
TTATCACCACCACCATCACCAACATCACCACCACCATTATCACCACCATCAACACCACCA
CCCCCATCATCATCATCACTACTACCATCATTACCAGCACCACCACCACTATCACCACCA
CCACCACAATCACCATCACCACTATCATCAACATCATCACTACCACCATCACCAACACCA
CCATCATTATCACCACCACCACCATCACCAACATCACCACCATCATCATCACCACCATCA
CCAAGACCATCATCATCACCATCACCACCAACATCACCACCATCACCAACACCACCATCA
CCACCACCACCACCATCATCACCACCACCACCATCATCATCACCACCACCGCCATCATCA
TCGCCACCACCATGACCACCACCATCACAACCATCACCACCATCACAACCACCATCATCA
CTATCGCTATCACCACCATCACCATTACCACCACCATTACTACAACCATGACCATCACCA
CCATCACCACCACCATCACAACGATCACCATCACAGCCACCATCATCACCACCACCACCA
CCACCATCACCATCAAACCATCGGCATTATTATTTTTTTAGAATTTTGTTGGGATTCAGT
ATCTGCCAAGATACCCATTCTTAAAACATGAAAAAGCAGCTGACCCTCCTGTGGCCCCCT
TTTTGGGCAGTCATTGCAGGACCTCATCCCCAAGCAGCAGCTCTGGTGGCATACAGGCAA
CCCACCACCAAGGTAGAGGGTAATTGAGCAGAAAAGCCACTTCCTCCAGCAGTTCCCTGT
WORK IN PROGRESS

Direct Kernel Methods
Santa Fe Time Series Prediction Competition
• 1994 Santa Fe Institute Competition: 1000 data chaotic laser data, predict next 100 data• Competition is described in Time Series Prediction: Forecasting the Future and Understanding the Past, A. S. Weigend & N. A. Gershenfeld, eds., Addison-Wesley, 1994• Method: - K-PLS with = 3 and 24 latent variables - Used records with 40 past data for training for next point - Predictions bootstrap on each other for 100 real test data
REM TIME SERIES EVOLUTION FOR SANTA FE LASER DATAREM GENERATE DATA (1200)
tms num_eg.txt 305copy laser.txt a.txt > embrex.log
REM CONVERT TO LEGITIMATE TIME SERIEStms a.txt 1 < no.dbdcopy a.txt.txt a_ori.dat >> embrex.logREM MAKE DIFFERENTIAL TIME SERIES for LEARNING (1 40)tms a_ori.dat 12copy a_ori.dat.txt a.dat >> embrex.log
REM MAKE GENERIC LABELSanalyze a.dat 116copy sel_lbls.txt label.txt >> embrex.log
REM SPLIT IN TRAINING AND TEST SET (960)tms a.dat 20copy cmatrix.txt a.pat >> embrex.logcopy dmatrix.txt a.tes >> embrex.log
REM MAHALANOBIS SCALE TRAINING AND TEST DATAanalyze a.pat 3314159analyze a.tes 314159 < no.dbdcopy a.pat.txt b.pat >> embrex.logcopy a.tes.txt b.tes >> embrex.log
REM K-PLS (24 3)analyze num_eg.dbd 105analyze b.pat 5936
REM EVOLVE PREDICTIONS (3 1 100 b.tes)tms b.pat 31
REM DESCALE EVOLUTION PREDICTIONanalyze resultss.xxx 4copy results.ttt results.xxx >> embrex.loganalyze evolve.txt 4
REM JAVA PLOTanalyze results.ttt 3313pause
• Entry “would have won” the competition

Direct Kernel Methods
www.drugmining.com
Kristin Bennett and Mark Embrechts