digital manufacturing technology and convenient access to ... · the abaqus integration through...
TRANSCRIPT


Digital manufacturing technology and convenient access to High Performance Computing (HPC) in industry R&D are essential to increase the quality of our products and the competitiveness of our companies. Progress can only be achieved by educating our engineers, especially those in the “missing middle,” and making HPC easier to access and use for everyone who can benefit from this advanced technology. The UberCloud HPC Experiment actively promotes the wider adoption of digital manufacturing technology. It is an example of a grass roots effort to foster collaboration among engineers, HPC experts, and service providers to address challenges at scale. The UberCloud HPC Experiment started in mid-2012 with the aim of exploring the end-to-end process employed by digital manufacturing engineers to access and use remote computing resources in HPC centers and in the cloud. In the meantime, the UberCloud HPC Experiment has achieved the participation of 500 organizations and individuals from 48 countries. Over 80 teams have been involved so far. Each team consists of an industry end-user and a software provider; the organizers match them with a well-suited resource provider and an HPC expert. Together, the team members work on the end-user’s application – defining the requirements, implementing the application on the remote HPC system, running and monitoring the job, getting the results back to the end-user, and writing a case study. Intel decided to sponsor a Compendium of 25 case studies, including the one you are reading, to raise awareness in the digital manufacturing community about the benefits and best practices of using remote HPC capabilities. This document is an invaluable resource for engineers, managers and executives who believe in the strategic importance of this technology for their organizations. You can download it at: http://tci.taborcommunications.com/UberCloud_HPC_Experiment Very special thanks to Wolfgang Gentzsch and Burak Yenier for making the UberCloud HPC Experiment possible. This HPC UberCloud Compendium of Case Studies has been sponsored by Intel and produced in conjunction with Tabor Communications Custom Publishing, which includes HPCwire, HPC in the Cloud, and Digital Manufacturing Report. If you are interested in participating in this experiment, either actively as a team member or passively as an observer, please register at http://www.hpcexperiment.com

CAE Simulation of Water Flow Around a Ship Hull
“The results of the simulation, performed in a wide range of towing speeds in the grid with
about 1 mln computational cells, showed good agreement with the experimental data.”
MEET THE TEAM End User – Andrew Pechenyuk, DMT Pechenyuk is with Digital Marine Technology (DMT). The company was established in 2002 by a group of specialists in the field of shipbuilding, ship repair and computer technologies. Today the main activities are: ship hydrodynamics, e.g. hull form design and ship propulsion calculations, cargo stowage and seafastening projects, e.g. heavy lift transportation projects, strength calculations, etc. Software Provider – Andrey Aksenov, TESIS Capvidia/ТЕСИС is an international company whose strategic goal is offering advanced and economically sound solutions on the market of engineering products and services. FlowVision CFD software has been developing since 1991 by the team from Russian Academy of Sciences, viz., Institute for Computer-Aided Design, Institute for Mathematical Modeling, and Computing Centre. In 1999, the team has joined Capvidia/ТЕСИС and formed the CFD department. At Capvidia/ТЕСИС, FlowVision is developed further and commercialized. The first commercial version of FlowVision was released in March 2000. Resource Provider – Jesus Lorenzana, FCSCL The Foundation of Supercomputing Center of Castile and León (FCSCL) is a public entity created by the Regional Government of Castile and León and the University of

León, which goal is the improvement in the research tasks of the university, the researching centers and the companies of Castile and León. HPC Expert – Adrian Jackson, EPCC, The University of Edinburgh EPCC is a leading European centre of excellence in advanced research, technology transfer and the provision of high-performance computing services to academia and industry. Based at The University of Edinburgh, it is one of Europe's leading supercomputing centers.
Fig. 1 - Wave pattern around the ship hull USE CASE The goal of this project was to run CAE simulations of water flow around the hull of a ship much more quickly than was possible using available resources. Current simulations took a long time to compute, limiting the usefulness and usability of CAE for this problem. For instance, on the resources currently available to the end user, a simulation of 50-60 seconds of real time water flow took two to three weeks of computational time. We decided to run the existing software on a HPC resource to realize whatever runtime gains might be achieved by using larger amounts of computing resources. Application software requirements This project required the TESIS FlowVision 3.08.xx software. FlowVision is already parallelized using MPI so we expected it to be able to utilize the HPC resources. However, it does require the ability to connect to the software from a remote location while the software is running in order to access the software licenses and steer the computation. For the license keys, see description in FlowVision installation and preferences on Calendula Cluster.docx,https://basecamp.com/2047282/projects/1610899-team-46-simulation/uploads/42… Custom code or configuration of end-user This project necessitated the upgrading of the operating system on the HPC system to

support some libraries required by the FlowVision software. The Linux version on the system was not recent enough and one of the system main parts, glibc libraries, were not the correct version. We also had to open a number of ports to enable software to connect to and from specific external machines (specified by their IP address). Computing Resource: Resource requirement from the end-user: about 8-16 nodes for the HPC machine, used for 5 runs of 24 hours each. Resource details: There are two processors on each node, Intel Xeon E5450 @ 3.00GHz , with 4 real cores per processor, so each compute node has 8 real cores. Each node also has 16GB of memory and two 1Gb Ethernet cards and one Mellanox Infiniband card. This experiment had been assigned 32 nodes (so 256 cores) to use for simulations. How to request resources: To get access to the resources you e-mail the resource provider. They provide an account quickly (in around a day). How to access resources: The front end of the resource is accessed using ssh; you will need an account on the system to do this using a command such as this:
ssh -X [email protected] -p 2222 Once you have logged into the system. you can run jobs using the Open Grid Scheduler/Grid Engine batch system. To use that system you need to submit a job script using the qsub command. CHALLENGES Current simulations take a long time to compute, limiting the usefulness and usability of the CAE approach for this problem. For instance, on the resources currently available to the end user, a simulation of 50-60 seconds of real time water flow takes two to three weeks of computational time. To improve this time to solution we need to access to larger computational resources than we currently have available. Scientific Challenge Simulation of the viscous flow around the hull of a ship with the free surface was provided. The object of research was the hull of the river-sea dry-cargo vessel with extremely high block coefficient (Cb = 0.9). The hull flow included complex phenomena, e.g. wave pattern on the free surface, and fully developed turbulence flow in the boundary layer. The main purpose of the simulation was towing resistance determination. In general, dependence of towing resistance on the speed of the ship was used for the prime mover's power prediction at the design stage. The present case considered a test example for which there is reliable experimental data. In contrast to

the conventional method of model tests, the methods of CFD simulation have not been fully studied regarding the reliability of the results, as well as the computational resources and time costs, etc. For these reasons, the computational grid formation and the scalability of the solution were the focus of this research. Resources FCSCL, the Foundation of Supercomputing Center of Castile and León, Spain, provided HPC resources, in the form of a 288 HP blade nodes system with 8 cores and 16GB RAM per node. Software FlowVision is a new generation multi-purpose simulation system for solving practical CFD (computational fluid dynamics) problems. The modern C++ implementation offers modularity and flexibility that allows addressing the most complex CFD areas. A unique approach to grid generation (geometry fitted sub-grid resolution) provides a natural link with CAD geometry and FE mesh. The ABAQUS integration through Multi-Physics (MP) Manager supports the most complex fluid-structure interaction (FSI) simulations (e.g., hydroplaning of automotive tires). FlowVision integrates 3D partial differential equations (PDE) describing different flows, viz., the mass, momentum (Navier-Stokes), and energy conservation equations. The system of the governing equations is completed by state equations. If the flow is coupled with physical-chemical processes like turbulence, free surface evolution, combustion, etc., the corresponding PDEs are added to the basic equations. All together the PDEs, state equations, and closure correlations (e. g., wall functions) constitute the mathematical model of the flow. FlowVision is based on the finite-volume approach to discretization of the governing equations. Implicit velocity-pressure split algorithm is used for integration of the Navier-Stokes equations. FlowVision is integrated CFD software: its pre-processor, solver, and post-processor are combined into one system. A user sets the flow model(s), physical and method parameters, initial and boundary conditions, etc. (pre-processor), performs and controls calculations (solver), and visualizes the results (post-processor) in the same window. He can stop the calculations at any time to change the required parameters, and continue or recommence the calculations. Additional Challenges This project continued from the first round of the cloud experiment. In the first round we faced the challenge that the end user for this project had a particular piece of commercial simulation software they needed to use for this work. The software required a number of ports to be open from the front end of the HPC system to the end users

machines, both for accessing the licenses for the software and to enable visualization, computational steering, and job preparation for the simulations. There were a number of issues to be resolved to enable these ports to be opened, including security issues for the resource provider (requiring the open ports to be restricted to a single IP address or small range of IP addresses), and educating the end user about the configuration of the HPC system (with front-end and back-end resources and a batch system to access the main back-end resources). These issues were successfully tackled. However, another issues was encountered – the Linux version of the operating system on the HPC resources was not recent enough and one of the system main parts, glibc libraries, were not the required version for the commercial software to be run. The resource provider was willing to upgrade the glibc libraries to the required version; however this impacted another team during the first round. At the start of this second round of the experiment this problem was resolved so simulations could be undertaken. Outcome The dependence of the towing resistance on the resolution of computational grid (grid convergence) was investigated. The results show that grid convergence becomes good when grids with a number of computational cells of more than 1 mln are used.
Fig. 2 - Grid convergence, speed 12.5 knots
The results of the simulation, performed in a wide range of towing speeds (Froude numbers) in the grid with about 1 mln computational cells, showed good agreement with the experimental data. CFD calculations were performed in full scale. The experimental results were obtained in the deep-water towing tank of Krylov State Research Centre (model scale is 1:18.7). The full-scale CFD results were compared to the recalculated
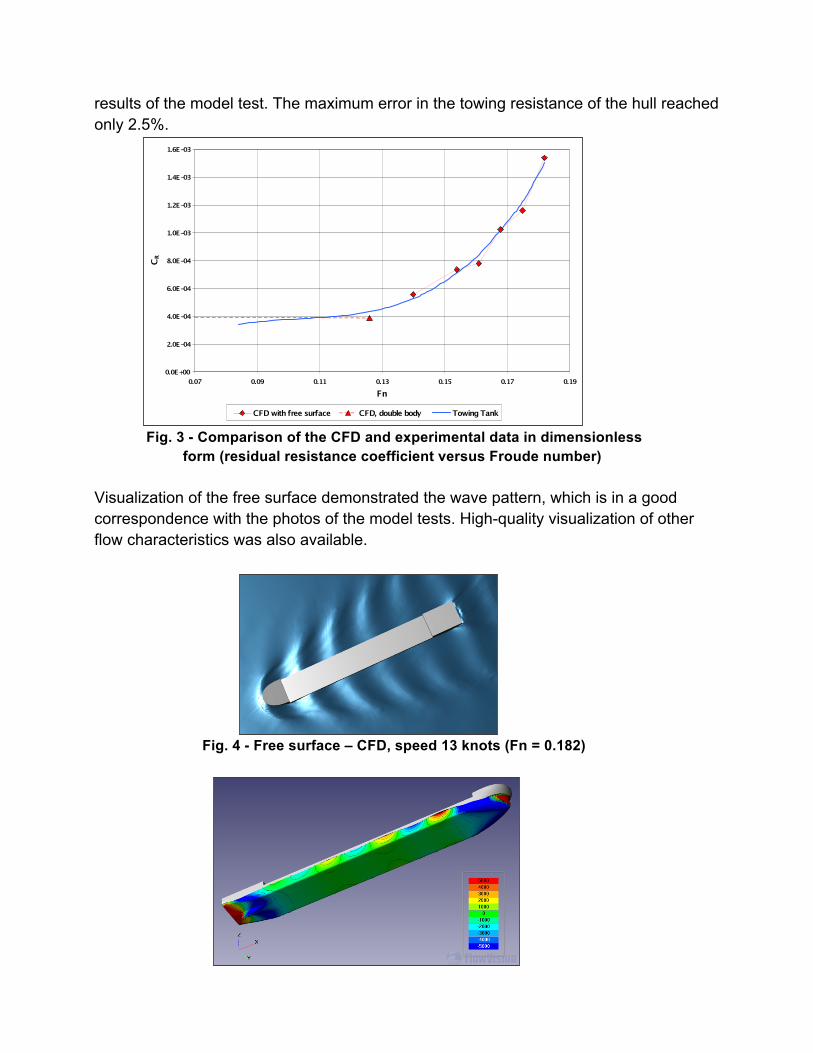
results of the model test. The maximum error in the towing resistance of the hull reached only 2.5%.
Fig. 3 - Comparison of the CFD and experimental data in dimensionless form (residual resistance coefficient versus Froude number)
Visualization of the free surface demonstrated the wave pattern, which is in a good correspondence with the photos of the model tests. High-quality visualization of other flow characteristics was also available.
Fig. 4 - Free surface – CFD, speed 13 knots (Fn = 0.182)
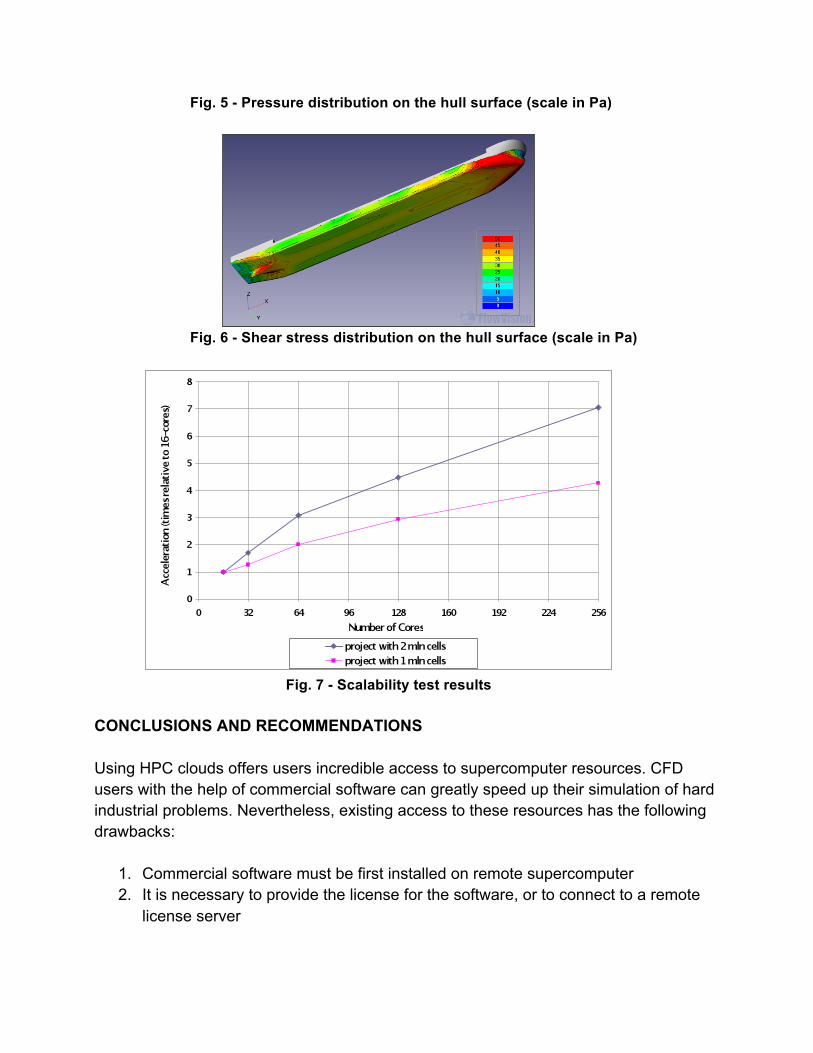
Fig. 5 - Pressure distribution on the hull surface (scale in Pa)
Fig. 6 - Shear stress distribution on the hull surface (scale in Pa)
Fig. 7 - Scalability test results
CONCLUSIONS AND RECOMMENDATIONS Using HPC clouds offers users incredible access to supercomputer resources. CFD users with the help of commercial software can greatly speed up their simulation of hard industrial problems. Nevertheless, existing access to these resources has the following drawbacks:
1. Commercial software must be first installed on remote supercomputer 2. It is necessary to provide the license for the software, or to connect to a remote
license server

3. User can be faced with a lot of problems during installation process: e.g., incompatibility of the software with the operation system, and incompatibility of additional 3rd-party software like MPI, TBB libraries, etc.
4. All these steps require that the user be in contact with the software vendor or cluster administrator for technical support
From our point of view, it is necessary to overcome all these problems in order to use commercial software on HPC clouds. Commercial software packages used for simulation often have requirements for licensing and operation that either means the resources they are being run on need to access external machines or software needs to be installed locally to handle licenses, etc. New users to HPC resources often require education in the general setup and use of such systems (e.g., the fact you generally access the computational resources through a batch system rather than logging on directly). Basecamp has been useful to enable communication between the project partners, sharing information, and ensuring that one person is does not hold up the whole project. Communication between the client side and the solver side of modern CAE systems ordinarily uses network protocol. Thus the organization of work over SSH protocol requires additional operations, including port forwarding and data translation. On the other hand, when properly configured, the client interface is able to manage the solving in the same manner as in local network.
Case Study Authors – Adrian Jackson, Jesus Lorenzana, Andrew Pechenyuk, and Andrey Aksenov.

Thank you for your interest in the free and voluntary UberCloud HPC Experiment. To download similar case studies go to: http://tci.taborcommunications.com/UberCloud_HPC_Experiment If you, or your organization would like to participate in this Experiment to explore hands-on the end-to-end process of HPC as a Service for your business then please register at: http://www.hpcexperiment.com/why-participate If you are interested in promoting your service/product at the UberCloud Exhibit then please register at http://www.exhibit.hpcexperiment.com/