different classes of mutations – mutation detection vincenzo nigro dipartimento di patologia...
Post on 19-Dec-2015
214 views
TRANSCRIPT

Different classes of mutations –Different classes of mutations –mutation detectionmutation detection
Vincenzo NigroVincenzo Nigro
Dipartimento di Patologia Dipartimento di Patologia Generale, Seconda Università Generale, Seconda Università degli Studi di Napolidegli Studi di Napoli
Telethon Institute of Genetics and Telethon Institute of Genetics and Medicine (TIGEM)Medicine (TIGEM)

For mutations other than point mutations, For mutations other than point mutations, sex biases in the mutation rate are very sex biases in the mutation rate are very variable. However, small deletions are variable. However, small deletions are more frequent in females. more frequent in females.
The total rate of new deleterious mutations The total rate of new deleterious mutations for all genes is estimated to be about three for all genes is estimated to be about three per zygote. This value is uncertain, but it is per zygote. This value is uncertain, but it is likely that the number is greater than one. likely that the number is greater than one.

the number of male germ-cell divisionsthe number of male germ-cell divisions

Relative frequency of Relative frequency of de novode novo achondroplasia for achondroplasia for different paternal agesdifferent paternal ages


The effect of an alleleThe effect of an allele
null or amorph = no productnull or amorph = no product
hypomorph = reduced amount / activityhypomorph = reduced amount / activity
hypermorph = increased amount / activityhypermorph = increased amount / activity
neomorph = novel product / activityneomorph = novel product / activity
antimorph = antagonistic product / activityantimorph = antagonistic product / activity

amorph or hypomorph (1)amorph or hypomorph (1)
deletiondeletion the entire genethe entire gene part of the genepart of the gene
disruption of the gene structuredisruption of the gene structure by insertion, inversion, translocationby insertion, inversion, translocation
promoter inactivationpromoter inactivation mRNA destabilizationmRNA destabilization splicing mutationsplicing mutation
inactivating donor/acceptorinactivating donor/acceptor activating criptic splice sitesactivating criptic splice sites

Point mutations, Point mutations, which involve which involve alteration in a single alteration in a single base pair, and small base pair, and small deletions or deletions or insertions generally insertions generally directly affect the directly affect the function of only function of only one one genegene

amorph or hypomorph (2)amorph or hypomorph (2)
frame-shift in translationframe-shift in translation by insertion of n+1 or n+2 bases into the by insertion of n+1 or n+2 bases into the
coding sequencecoding sequence by deletion of n+1 or n+2 bases into the by deletion of n+1 or n+2 bases into the
coding sequencecoding sequence nonsense mutationnonsense mutation missense mutation / aa deletionmissense mutation / aa deletion
essential / conserved amino acidessential / conserved amino acid defect in post-transcriptional processingdefect in post-transcriptional processing defect in cellular localizationdefect in cellular localization

Loss of function mutations in the Loss of function mutations in the PAX3 gene (Waardenburg s.)PAX3 gene (Waardenburg s.)


Classical splicing: Classical splicing:
conserved motifs at or near the intron endsconserved motifs at or near the intron ends.



hypermorphhypermorph
trisomiatrisomia duplicationduplication amplification (cancer)amplification (cancer) Chromatin derepression (FSH)Chromatin derepression (FSH) trasposition under a strong promotertrasposition under a strong promoter
leukemialeukemia overactivity of an abnormal proteinoveractivity of an abnormal protein

neomorphneomorph
generation of chimeric proteinsgeneration of chimeric proteins duplicationduplication amplification (cancer)amplification (cancer) missense mutationsmissense mutations inclusion of coding cryptic exonsinclusion of coding cryptic exons usage of alternative ORFsusage of alternative ORFs overactivity of an abnormal proteinoveractivity of an abnormal protein

antimorphantimorph
missense mutationsmissense mutations inclusion of coding cryptic exonsinclusion of coding cryptic exons usage of alternative ORFsusage of alternative ORFs





Gene conversion

Human Gene Mutation DatabaseHuman Gene Mutation Database
The The HumanHuman Gene Gene MutationMutation Database (HGMD) Database (HGMD)
Locus-Specific Mutation Locus-Specific Mutation DatabasesDatabases SpringerSpringer LINK: LINK: HumanHuman GeneticsGenetics - -
MutationsMutations SubmissionSubmission FormForm Nomenclature Nomenclature forfor the the descriptiondescription of of
sequencesequence variationsvariations ( (mutationmutation nomenclature) nomenclature)

nucleotides are designated by the bases (in upper case); A (adenine), C (cytosine), G nucleotides are designated by the bases (in upper case); A (adenine), C (cytosine), G (guanine) and T (thymidine(guanine) and T (thymidine) )
nucleotide numbering;nucleotide numbering; nucleotide +1 is the A of the ATG-translation initiation codon, the nucleotide +1 is the A of the ATG-translation initiation codon, the
nucleotide 5' to +1 is numbered -1; there is no base 0 nucleotide 5' to +1 is numbered -1; there is no base 0 non-coding regions; non-coding regions;
• the nucleotide 5' of the ATG-translation initiation codon is -1 the nucleotide 5' of the ATG-translation initiation codon is -1 • the nucleotide 3' of the translation termination codon is *1 the nucleotide 3' of the translation termination codon is *1
intronic nucleotides; intronic nucleotides; • beginning of the intron:beginning of the intron: the number of the last nucleotide of the the number of the last nucleotide of the
preceeding exon, a plus sign and the position in the intron, e.g. preceeding exon, a plus sign and the position in the intron, e.g. 77+1G, 77+2T (when the exon number is known, IVS1+1G, 77+1G, 77+2T (when the exon number is known, IVS1+1G, IVS1+2T) IVS1+2T)
• end of the intron:end of the intron: the number of the first nucleotide of the following the number of the first nucleotide of the following exon, a minus sign and the position upstream in the intron, e.g. 78-exon, a minus sign and the position upstream in the intron, e.g. 78-2A, 78-1G (when the exon number is known, IVS1-2A, IVS1-2G)2A, 78-1G (when the exon number is known, IVS1-2A, IVS1-2G)

Description of nucleotide changesDescription of nucleotide changes substitutionssubstitutions are designated by a “>”-character are designated by a “>”-character
76A>C denotes that at nucleotide 76 a A is changed 76A>C denotes that at nucleotide 76 a A is changed to a C to a C
88+1G>T (alternatively IVS2+1G>T) denotes the G to 88+1G>T (alternatively IVS2+1G>T) denotes the G to T substitution at nucleotide +1of intron 2, relative to T substitution at nucleotide +1of intron 2, relative to the cDNA positioned between nucleotides 88 and 89 the cDNA positioned between nucleotides 88 and 89
89-2A>C (alternativelyIVS2-2A>C) denotes the A to C 89-2A>C (alternativelyIVS2-2A>C) denotes the A to C substitution at nucleotide -2 of intron 2, relative to the substitution at nucleotide -2 of intron 2, relative to the cDNA positioned between nucleotides 88 and 89cDNA positioned between nucleotides 88 and 89

deletions are designated by "del" after the nucleotide(s) flanking the deletion site
76_78del (alternatively 76_78delACT) denotes a ACT deletion from nucleotides 76 to 78
82_83del (alternatively 82_83delTG) denotes a TG deletion in the sequence ACTTTGTGCC (A is nucleotide 76) to ACTTTGCC
insertions are designated by "ins" after the nucleotides flanking the insertion site, followed by the nucleotides insertedNOTE: as separator the "^"-character is sometimes used but this is not recommened (e.g. 83^84insTG)
76_77insT denotes that a T was inserted between nucleotides 76 and 77
variability of short sequence repeats, e.g. in ACTGTGTGCC (A is nt 1991), are designated as 1993(TG)3-6 with nucleotide 1993 containing the first TG-dinucleotide which is found repeated 3 to 6 times in the population.

insertion/deletions (insertion/deletions (indelsindels)) are descibed as a deletion are descibed as a deletion followed by an insertion after the nucleotides afectedfollowed by an insertion after the nucleotides afected 112_117delinsTG (alternatively 112_117delinsTG (alternatively
112_117delAGGTCAinsTG or 112_117>TG) denotes the 112_117delAGGTCAinsTG or 112_117>TG) denotes the replacement of nucleotides 112 to 117 (AGGTCA) by TGreplacement of nucleotides 112 to 117 (AGGTCA) by TG
duplications are designated by "dup" after the nucleotides flanking the duplication site,
77_79dupCTG denotes that the nucleotides 77 to 79 were duplicated
inversionsinversions are designated by "inv" after the nucleotides are designated by "inv" after the nucleotides flanking the inversion siteflanking the inversion site 203_506inv (or 203_506inv304) denotes that the 304 203_506inv (or 203_506inv304) denotes that the 304
nucleotides from position 203 to 506 have been invertednucleotides from position 203 to 506 have been inverted

changes in different alleleschanges in different alleles (e.g. in recessive diseases) (e.g. in recessive diseases) are described as "[change allele 1] + [change allele 2]"are described as "[change allele 1] + [change allele 2]" [76A>C] + [76A>C] denotes a homozygous A to C [76A>C] + [76A>C] denotes a homozygous A to C
change at nucleotide 76change at nucleotide 76 [76A>C] + [?] denotes a A to C change at nucleotide [76A>C] + [?] denotes a A to C change at nucleotide
76 in one allele and an unknown change in the other 76 in one allele and an unknown change in the other alleleallele
two variations in one alleletwo variations in one allele are described as "[first are described as "[first change + second change]"change + second change]" [76A>C + 83G>C] denotes an A to C change at [76A>C + 83G>C] denotes an A to C change at
nucleotide 76 and a G to C change at nucleotide 83 in nucleotide 76 and a G to C change at nucleotide 83 in the same allelethe same allele
NOTE:NOTE: current recommendations use the ";"-character current recommendations use the ";"-character as a separator (i.e. [76A>C; 83G>C])as a separator (i.e. [76A>C; 83G>C])
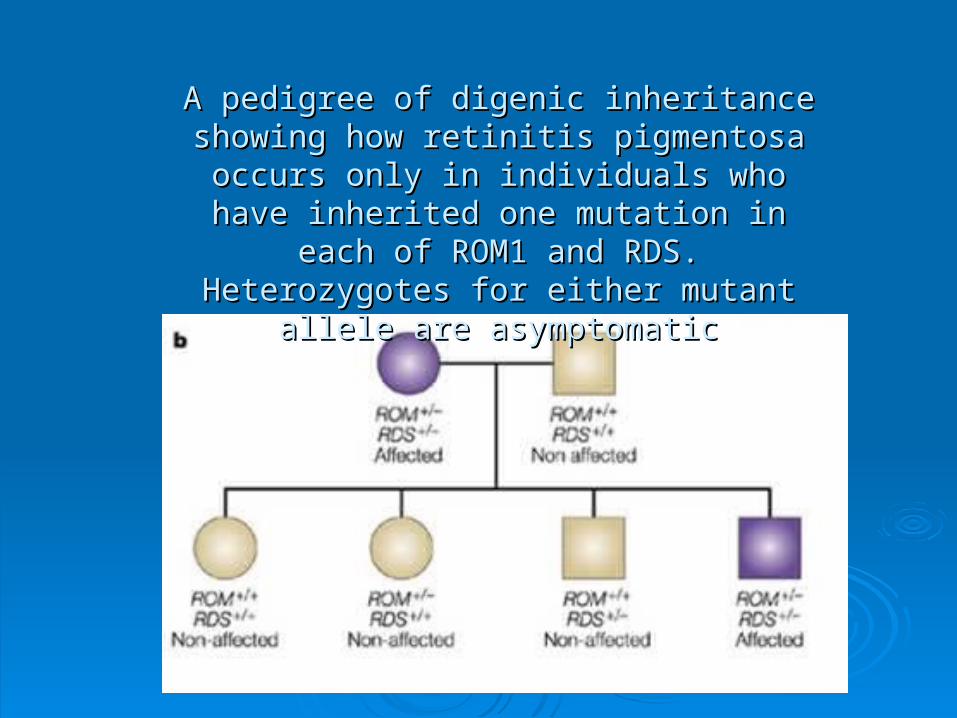
A pedigree of digenic inheritance showing how A pedigree of digenic inheritance showing how retinitis pigmentosa occurs only in individuals retinitis pigmentosa occurs only in individuals who have inherited one mutation in each of who have inherited one mutation in each of ROM1 and RDS. Heterozygotes for either ROM1 and RDS. Heterozygotes for either
mutant allele are asymptomaticmutant allele are asymptomatic

Triallelic inheritanceTriallelic inheritance
In the consanguineous pedigree NFB14 both the affected In the consanguineous pedigree NFB14 both the affected (03) and the unaffected (04) individuals carry the same (03) and the unaffected (04) individuals carry the same mutation (A242S) in the Bardet–Biedl syndrome gene, BBS6. mutation (A242S) in the Bardet–Biedl syndrome gene, BBS6. Only the affected sibling is homozygous for a nonsense Only the affected sibling is homozygous for a nonsense mutation (Y24X; X indicates a stop codon) in BBS2. mutation (Y24X; X indicates a stop codon) in BBS2.

Triallelic inheritanceTriallelic inheritance
Three mutations at two loci are necessary for pathogenesis Three mutations at two loci are necessary for pathogenesis in this pedigree, as the affected sibling (03) has three in this pedigree, as the affected sibling (03) has three nonsense mutations (Q147X in BBS6, and Y24X and Q59X in nonsense mutations (Q147X in BBS6, and Y24X and Q59X in BBS2) and the unaffected sibling (05) has two nonsense BBS2) and the unaffected sibling (05) has two nonsense BBS2 mutations, but is wild-type for BBS6.. BBS2 mutations, but is wild-type for BBS6..

A similar model involving proteins B and D, A similar model involving proteins B and D, which are members of the same multi-subunit which are members of the same multi-subunit complex but do not interact directlycomplex but do not interact directly

Non-allelic complementationNon-allelic complementation
Mutations at one locus (mutated proteins are indicated by Mutations at one locus (mutated proteins are indicated by asterisks) are not sufficient to disrupt the formation of the asterisks) are not sufficient to disrupt the formation of the complex between proteins A and B, although the strength of the complex between proteins A and B, although the strength of the interaction might be reduced (dashed line). A further mutation in interaction might be reduced (dashed line). A further mutation in protein B causes disruption of the complex (red cross), resulting protein B causes disruption of the complex (red cross), resulting in a detectable phenotypein a detectable phenotype

DNA analysisDNA analysis TodayToday, in most laboratories the identification of , in most laboratories the identification of
unknownunknown mutationsmutations in candidate genes, causing in candidate genes, causing human diseases, is performed through manual human diseases, is performed through manual scanning of PCR products in affected individuals, scanning of PCR products in affected individuals, often with accurate preliminary selectionoften with accurate preliminary selection
TomorrowTomorrow, after the identification of all human genes , after the identification of all human genes and the sequencing of the genome, DNA mutation and the sequencing of the genome, DNA mutation scanning in the population will have a significant role scanning in the population will have a significant role in identifying in identifying sequence variationssequence variations among among individualsindividuals

SequencingSequencing
With the ongoing With the ongoing reduction of costsreduction of costs (today (today about 5about 5€€/run), direct automated /run), direct automated sequencing of PCR products has already sequencing of PCR products has already been successfully applied for mutation been successfully applied for mutation detection.detection.
Sequencing is often thought of as the Sequencing is often thought of as the 'gold standard''gold standard' for mutation detection. for mutation detection.
This perception is distorted due to the fact This perception is distorted due to the fact that this is the only method of that this is the only method of mutation mutation identificationidentification, but this does not mean it is , but this does not mean it is the best for mutation detectionthe best for mutation detection

Sequencing problemsSequencing problems
FALSE POSITIVEFALSE POSITIVEwhen searching for when searching for heterozygous DNA heterozygous DNA differencesdifferences there are a number of potential there are a number of potential mutations, together with sequence artifacts, mutations, together with sequence artifacts, compressions and differences in peak intensities compressions and differences in peak intensities that must be re-checked by sequencing with that must be re-checked by sequencing with additional primers and increased costsadditional primers and increased costs
FALSE NEGATIVEFALSE NEGATIVE loss of information farther away or closer to the loss of information farther away or closer to the primerprimer
sequencing does not detect a minority of mutant sequencing does not detect a minority of mutant molecules in a wild-type environmentmolecules in a wild-type environment

Strategy for mutation detectionStrategy for mutation detection
The gene is known or unknown?The gene is known or unknown? Which is the size of the gene?Which is the size of the gene? How many patients must be examined? How many patients must be examined? Expected mutations are dominant or Expected mutations are dominant or
recessive?recessive? Mutations have already been identified in Mutations have already been identified in
this gene?this gene? There are other members of the same gene There are other members of the same gene
families (or pseudogenes) in the genome?families (or pseudogenes) in the genome?

Gene size
Number ofpatients
XXNumber ofcontrols
Dimension of the mutation detection study

frequent mutations
are known?
mutationmutationscanningscanning
SEQUENCINGSEQUENCING
screeningscreeningof recurrentof recurrent mutationsmutations YESYES NONO
mutationsare identified?
YESYES
NONO
General strategy for mutation detectionGeneral strategy for mutation detection

5’ OH
5’ OH
each primer allele specific contains:
•an obligate mismatch in the last but two 3’- OH base
•a specific mismatch in the last 3’- OH base
5’ OH
5’ OH

MIX 2
Mut 1Mut 1
Wt 2Wt 2
Mut 3Mut 3
Wt 4Wt 4
Mut 5Mut 5
Wt 6Wt 6
Mut 7Mut 7
Wt 8Wt 8
Mut 9Mut 9
Wt 10Wt 10
Mut 11Mut 11
Wt 12Wt 12
Wt 1Wt 1
Mut 2Mut 2
Wt 3Wt 3
Mut 4Mut 4
Wt 5Wt 5
Mut 6Mut 6
Wt 7Wt 7
Mut 8Mut 8
Wt 9Wt 9
Mut 10Mut 10
Wt 11Wt 11
Mut 12Mut 12
MIX 1MIX 1 MIX 2
*
Multiplex ARMSMultiplex ARMS

Current mutation detection Current mutation detection techniquestechniques
SSCP (single strand conformation polymorphism) SSCP (single strand conformation polymorphism) HA (heteroduplex analysis)HA (heteroduplex analysis) CCM (chemical cleavage of mismatch)CCM (chemical cleavage of mismatch) CSGE (conformation sensitive gel CSGE (conformation sensitive gel
electrophoresis)electrophoresis) DGGE (denaturing gradient gel electrophoresis)DGGE (denaturing gradient gel electrophoresis) DHPLC (denaturing HPLC)DHPLC (denaturing HPLC) PTT (protein truncation test)PTT (protein truncation test) direct sequencingdirect sequencing

SSCPSSCP(single-strand conformation polymorphism)(single-strand conformation polymorphism)
Single-stranded DNA when placed in a non-Single-stranded DNA when placed in a non-denaturing solution folds into a specific structure denaturing solution folds into a specific structure determined by its sequencedetermined by its sequence
Differences Differences as little as 1 baseas little as 1 base can generate can generate different conformationsdifferent conformations
This is visualized by a difference in This is visualized by a difference in electrophoretic mobilityelectrophoretic mobility of at least one strandof at least one strand
Structure of ss DNA Structure of ss DNA changes under different changes under different physical and chemical conditionsphysical and chemical conditions e.g. e.g. temperature, ionic strength, presence of temperature, ionic strength, presence of denaturing agents, etc. denaturing agents, etc.

SSCPSSCPsingle strand conformation polymorphismsingle strand conformation polymorphism
Sensitivity Sensitivity 150-bp fragment > 85%150-bp fragment > 85%400-bp fragment > 60% (75% with two gels)400-bp fragment > 60% (75% with two gels)
Detects both missense and nonsense mutationsDetects both missense and nonsense mutations Post PCR time: 36-72 hours Post PCR time: 36-72 hours
(gel preparation, loading and run; autoradiography, (gel preparation, loading and run; autoradiography, analysis of results)analysis of results)
Use of radioactivity preferredUse of radioactivity preferred No special equipment requiredNo special equipment required DNA or mRNA as starting templatesDNA or mRNA as starting templates

SSCPSSCP The simplest and fastest PCR product The simplest and fastest PCR product
screening techniques, like screening techniques, like SSCPSSCP (single strand (single strand conformation polymorphism) often gives conformation polymorphism) often gives unsatisfactory results for its low sensitivitiesunsatisfactory results for its low sensitivities ((when testing G/C-rich and/or long PCR fragments, when testing G/C-rich and/or long PCR fragments, when using one condition of gel)when using one condition of gel)
The recurrence of The recurrence of false negativesfalse negatives may may invalidate the screening efforts, since invalidate the screening efforts, since mutations can bemutations can be
truly absenttruly absent
unnoticed in any of the fragments under studyunnoticed in any of the fragments under study
Thus, it could be necessary to re-screen all Thus, it could be necessary to re-screen all samples using a different techniquesamples using a different technique

SSCP

Variations of SSCPVariations of SSCP
DOVAM-SDOVAM-SDetection of virtually all mutationsDetection of virtually all mutations Selected 5 different SSCP conditions with Selected 5 different SSCP conditions with
different buffers and gel matricesdifferent buffers and gel matrices
ddFddFDideoxy fingerprintingDideoxy fingerprinting Sequencing followed by non-denaturing Sequencing followed by non-denaturing
electrophoresiselectrophoresis

Mutation detection by Mutation detection by
heteroduplex analysis: heteroduplex analysis:
the the mutant DNAmutant DNA must must
first be hybridized with first be hybridized with
the the wild-type DNAwild-type DNA
to form a mixture of to form a mixture of
two homoduplexes and two homoduplexes and
two two hheetteerroodduupplleexxeess

Heteroduplex analysisHeteroduplex analysis

Variations of HAVariations of HA
CSGECSGEconformation sensitive gel electrophoresisconformation sensitive gel electrophoresis Mildly denaturing conditions induce Mildly denaturing conditions induce
conformational changes (bends) in ds DNAconformational changes (bends) in ds DNA This increase differential migration patterns for This increase differential migration patterns for
homo- and heteroduplexeshomo- and heteroduplexes
UHGUHGuniversal heteroduplex generatoruniversal heteroduplex generator with multiple mismatches to have an higher with multiple mismatches to have an higher
chance of detectionchance of detection

CSGECSGEconformation sensitive gel electrophoresisconformation sensitive gel electrophoresis
Sensitivity Sensitivity 300-bp fragment > 95%300-bp fragment > 95%500-bp fragment > 80% 500-bp fragment > 80%
Detects both missense and nonsense mutationsDetects both missense and nonsense mutations Post PCR time: 24-36 hours Post PCR time: 24-36 hours
(gel preparation, loading and run; staining, (gel preparation, loading and run; staining, analysis of results)analysis of results)
Use of radioactivity not necessaryUse of radioactivity not necessary No special equipment requiredNo special equipment required DNA or mRNA as starting templatesDNA or mRNA as starting templates

DGGEDGGEdenaturing gradient gel electrophoresis
Sensitivity Sensitivity 300-bp fragment > 98%300-bp fragment > 98%500-bp fragment > 90% 500-bp fragment > 90%
Detects both missense and nonsense mutationsDetects both missense and nonsense mutations Post PCR time: 24-36 hours Post PCR time: 24-36 hours
(gel preparation, loading and run; staining, analysis (gel preparation, loading and run; staining, analysis of results)of results)
Use of radioactivity excludedUse of radioactivity excluded Special equipment requiredSpecial equipment required Cumbersome preparation of the gelCumbersome preparation of the gel


DGGEDGGE
The sensitivity is adequate, but the set-up work The sensitivity is adequate, but the set-up work load is much heavierload is much heavier
DGGE is thus well suited for the DGGE is thus well suited for the repetitive analysis repetitive analysis of a given DNA regionof a given DNA region, following a careful , following a careful optimization optimization
The ideal application for DGGE is the diagnosis of The ideal application for DGGE is the diagnosis of a monogenic disorder in many patients by testing a monogenic disorder in many patients by testing a small gene (i.e., beta globin)a small gene (i.e., beta globin)
For most research projects this technique is For most research projects this technique is unsatisfactory, since too many PCR products must unsatisfactory, since too many PCR products must be optimized to test a few genesbe optimized to test a few genes

Chemical cleavage of mismatchChemical cleavage of mismatch

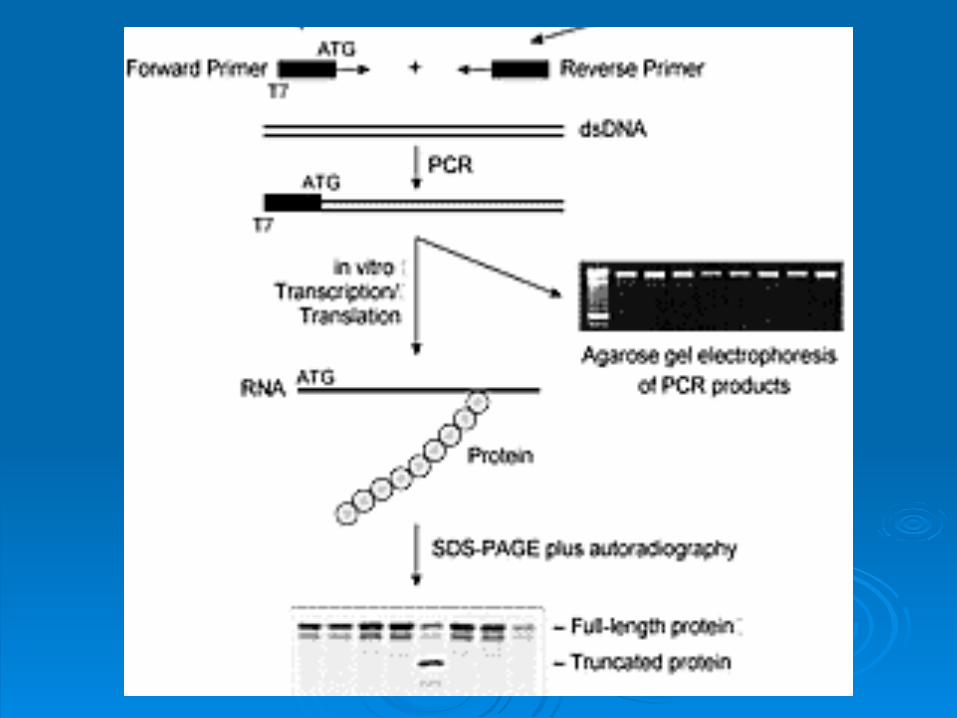
PTTPTTprotein truncation testprotein truncation test
Sensitivity Sensitivity 1000-bp fragment > 85% 1000-bp fragment > 85%
Detects only nonsense mutationsDetects only nonsense mutations Post PCR time: 48-72 hours Post PCR time: 48-72 hours
(translation/trascription, gel preparation, loading and (translation/trascription, gel preparation, loading and run, analysis of results)run, analysis of results)
Use of 35S radioactivityUse of 35S radioactivity No special equipment requiredNo special equipment required mRNA as starting templatemRNA as starting template


Applications of PTTApplications of PTT(% of truncating mutations)(% of truncating mutations)
Polycystic Kidney Disease Polycystic Kidney Disease PKD1PKD1 95% 95% Familial Adenomatous Polyposis Familial Adenomatous Polyposis APC APC 95% 95%
Ataxia telangiectasia Ataxia telangiectasia ATM ATM 90%90% Hereditary breast and ovarian cancer Hereditary breast and ovarian cancer BRCA1-2BRCA1-2 90%90% Duchenne Muscular Dystrophy Duchenne Muscular Dystrophy DMDDMD 90%?90%? Fanconi anemia Fanconi anemia FAAFAA 80%80% Hereditary non-polyposis colorectal cancer Hereditary non-polyposis colorectal cancer hMSH1-2hMSH1-2 70%-80% 70%-80% Neurofibromatosis type 2 Neurofibromatosis type 2 NF2NF2 65%65% Hunter Syndrome Hunter Syndrome IDSIDS 50%50% Neurofibromatosis type 1 Neurofibromatosis type 1 NF1 NF1 50% 50% Cystic Fibrosis Cystic Fibrosis CFTRCFTR 15%15%

Gene size
Number ofpatients
XXNumber ofcontrols
Dimension of the mutation detection study
Number ofadditionalcontrols
Number ofadditionalcontrols Number of
additionalcontrols

TMHA DHPLCTMHA DHPLCtemperature modulated heteroduplex analysistemperature modulated heteroduplex analysis
denaturing HPLCdenaturing HPLC Fully automaticFully automatic Sensitivity for a 300-bp fragment: > 99%Sensitivity for a 300-bp fragment: > 99% Detects both missense and nonsense Detects both missense and nonsense
mutationsmutations Post PCR time: 3-40 minutes Post PCR time: 3-40 minutes
(annealing of samples, machine set up, (annealing of samples, machine set up, analysis of results)analysis of results)
Use of radioactivity excludedUse of radioactivity excluded Requires a special expensive deviceRequires a special expensive device

DHPLC strategyDHPLC strategy
Integrated analysis by PCR and DHPLC of Integrated analysis by PCR and DHPLC of all all DNADNA samples from both isolated and familial samples from both isolated and familial cases of muscular dystrophycases of muscular dystrophy
It is convenient to carry out simultaneous It is convenient to carry out simultaneous analysis of many samples, including controlsanalysis of many samples, including controls
All DNA are checked for mutations in a single All DNA are checked for mutations in a single DNA fragment, then we proceed to study DNA fragment, then we proceed to study another fragmentanother fragment
The costs of the analysis can be reduced to The costs of the analysis can be reduced to 1/10 of the cheapest sequencing procedure 1/10 of the cheapest sequencing procedure with comparable sensitivitywith comparable sensitivity

POOLED PLATESA+B
PLATE A PLATE B
DHPLC analysis

Case 1Case 1
The gene isThe gene is known known It is composed ofIt is composed of 5 small size exons5 small size exons There areThere are 10 patients, 10 patients, sons of sons of
consanguineous parentsconsanguineous parents Expected mutations areExpected mutations are homozygoushomozygous Mutations haveMutations have nevernever been identified in this been identified in this
genegene There isThere is nono other memberother member of the same gene of the same gene
families (or pseudogenes) in the genomefamilies (or pseudogenes) in the genome

Case 2Case 2
The gene isThe gene is known known The putative function of the gene product is The putative function of the gene product is
to serve as a to serve as a transcription factortranscription factor Expected mutations are Expected mutations are dominantdominant Mutations have Mutations have nevernever been identified in this been identified in this
genegene There are There are other membersother members of the same gene of the same gene
families (or pseudogenes) in the genomefamilies (or pseudogenes) in the genome