dgiq 2015 the fundamentals of data quality
TRANSCRIPT

@joe_Caserta#DGIQ2015
The Fundamentals of Data Quality Understanding, Planning and Achieving
Data Quality in Your Organization
Joe Caserta

@joe_Caserta#DGIQ2015
Launched Big Data practice Co-author, with Ralph Kimball, The
Data Warehouse ETL Toolkit
Data Analysis, Data Warehousing and
Business Intelligence since 1996Began consulting database programing
and data modeling 25+ years hands-on experience
building database solutions
Founded Caserta Concepts in NYC
Web log analytics solution published in
Intelligent Enterprise
Launched Data Science, Data
Interaction and Cloud practices Laser focus on extending Data
Analytics with Big Data solutions
1986
2004
1996
2009
2001
2013
2012
2014
Dedicated to Data Governance
Techniques on Big Data (Innovation)
Top 20 Big Data
Consulting - CIO Review
Top 20 Most Powerful
Big Data consulting firms
Launched Big Data Warehousing
(BDW) Meetup NYC: 2,000+ Members
2015 Awarded for getting data out
of SAP for data analytics
Established best practices for big data
ecosystem implementations
Joe Caserta Timeline

@joe_Caserta#DGIQ2015
Data Quality
• Foremost reason for data warehouse failure is lack of data accuracyAccurate data means:
Correct
Unambiguous
Consistent
Complete
• Every Data Management system needs a data quality sub-system to some degree
@joe_Caserta#DGIQ2015
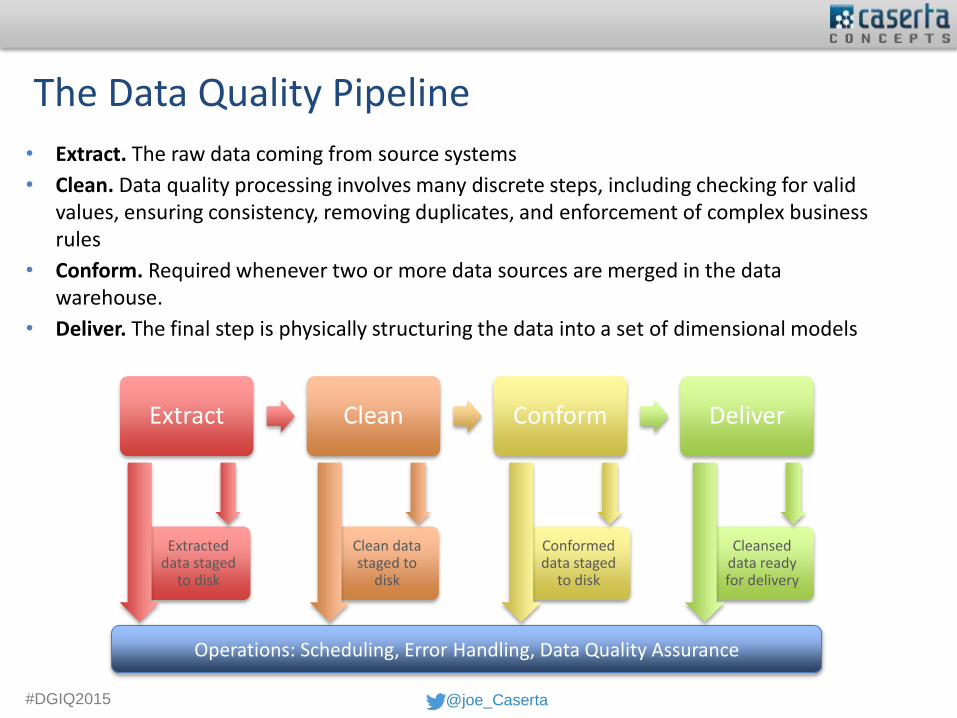
The Data Quality Pipeline
Extract Clean Conform Deliver
Extracted data staged
to disk
Clean data staged to
disk
Conformed data staged
to disk
Cleansed data ready for delivery
Operations: Scheduling, Error Handling, Data Quality Assurance
• Extract. The raw data coming from source systems
• Clean. Data quality processing involves many discrete steps, including checking for valid values, ensuring consistency, removing duplicates, and enforcement of complex business rules
• Conform. Required whenever two or more data sources are merged in the data warehouse.
• Deliver. The final step is physically structuring the data into a set of dimensional models

@joe_Caserta#DGIQ2015
• To trust your information a robust set of tools for continuous monitoring is needed
• Accuracy and completeness of data must be ensured
• Any piece of information in the data ecosystem must have monitoring:• Basic Stats: source to target counts• Error Events: did we trap any errors during processing• Business Checks: is the metric “within expectations”, How
does it compare with an abridged alternate calculation.
Data Quality Monitoring

@joe_Caserta#DGIQ2015
• Every data element has a System-of-Record
• The System-of-record is the originating source of data
• Data may be copied, moved, manipulated, transformed, altered, cleansed, or made corrupt throughout the enterprise
• If you don’t use the system-of-record data quality will be nearly impossible.
• The further downstream you go from the originating data source, you increase the risk of corrupt data.
• Barring rare exceptions, maintain the practice of sourcing data only from the system-of-record.
Determine the System of Record

@joe_Caserta#DGIQ2015
Cleaning Data from Multiple Sources
Merge lists on multiple attributes
Department 1
Customer List
Department 3
Customer List
Department 3
Customer List
Revised Master
Customer List
Retrieve/Assign New Master
Customer Key
Remove Duplicates
• Identify the source systems
• Understand the source systems
• Create record matching logic
• Establish survivorship rules
• Establish non-key attribute business rules
• Assign Surrogate Keys
• Load conformed dimension

@joe_Caserta#DGIQ2015
Be Corrective
Be Fast
Be Transparen
t
Be Thorough
Data Quality Priorities
• Be Thorough
• Be Fast
• Be Corrective
• Be Transparent

@joe_Caserta#DGIQ2015
Completeness Versus Speed
Data Quality
Spee
d to V
alu
eFast
Slow
Transparent Corrective

@joe_Caserta#DGIQ2015
Corrective Versus Transparent
• Corrective
– Hides operational deficiencies
– ETL complex algorithms
– DW differs from OLTP
– Slows ETL Processes
• Transparent
– Highlight Issues
– Fast Delivery
– DW matches OLTP
– Forces source system cleanup

@joe_Caserta#DGIQ2015
Data Quality Issues Policy
• Category A Issues must be addressed at the data source
• Category B Issues should be addressed at the data source even if there might be creative ways of deducing or recreating the derelict information
• Category C Issues, for a host of reasons, are best addressed in the data-quality ETL rather than at the source
• Category D Data-quality issues can only be pragmatically resolved in the ETL system

@joe_Caserta#DGIQ2015
Data Quality Issues Bell Curve
MUST be addressed
at the SOURCE
BEST addressed
at the SOURCEBEST
Addressed
In ETL
MUST be
Addressed
In ETL
Category A Category B Category C Category D
Political DMZ
ETL Focus is here
Universe of Known Data Quality Issues

@joe_Caserta#DGIQ2015
Types of Data Quality Enforcement
• Column Property Enforcement
• Structure Enforcement
• Data Enforcement
• Value Enforcement

@joe_Caserta#DGIQ2015
Column Property Enforcement
• Null values in required columns
• Numeric values that fall outside of range
• Columns whose lengths are unexpected
• Columns that contain data outside of allowed values
• Adherence to a required pattern

@joe_Caserta#DGIQ2015
Structure Enforcement
• Consistent Data Types
• Functional Dependencies
• Referential Integrity
• Hierarchical Relationships
• Domain Sensibility

@joe_Caserta#DGIQ2015
Data and Value Enforcement
• Business Rules
• Missing Data Values
• Incorrect Data Values
• Embedded Meanings in Data Values
• Domain Redundancy

@joe_Caserta#DGIQ2015
Data Quality Failure Options
• 1. Pass the record with no errors
• 2. Pass the record, flag offending column values
• 3. Reject the record
• 4. Stop the ETL job stream
• 5. Fix on the Fly
@joe_Caserta#DGIQ2015
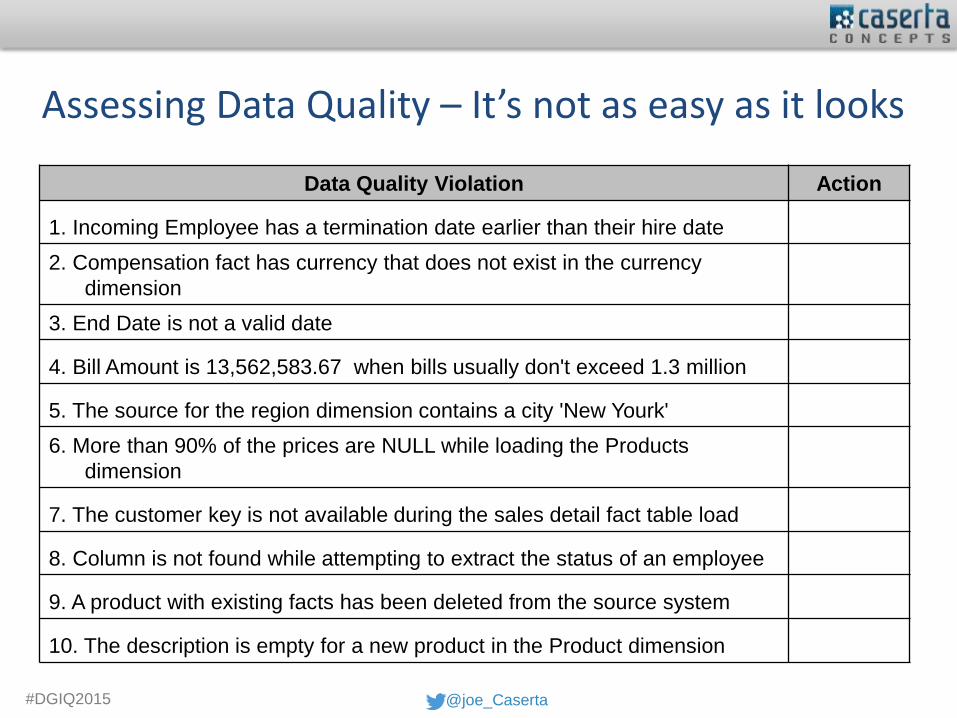
Assessing Data Quality – It’s not as easy as it looks
Data Quality Violation Action
1. Incoming Employee has a termination date earlier than their hire date
2. Compensation fact has currency that does not exist in the currency
dimension
3. End Date is not a valid date
4. Bill Amount is 13,562,583.67 when bills usually don't exceed 1.3 million
5. The source for the region dimension contains a city 'New Yourk'
6. More than 90% of the prices are NULL while loading the Products
dimension
7. The customer key is not available during the sales detail fact table load
8. Column is not found while attempting to extract the status of an employee
9. A product with existing facts has been deleted from the source system
10. The description is empty for a new product in the Product dimension

@joe_Caserta#DGIQ2015
Tracking Data Quality Failures
• Error Event Star- Schema
– Enables trend analysis of errors and exceptions
• Audit Dimension
– Captures specific quality context of individual fact table records
• Refer to The Data Warehouse ETL Toolkit pp.126-129 for more information on tracking data quality errors

@joe_Caserta#DGIQ2015
Error Event Table Schema
• Each error instance of each data quality check is captured
• Implemented as sub-system of ETL
• Each fact stored unique identifier of the defective source system record

@joe_Caserta#DGIQ2015
Audit Dimension
• Fact table contains a foreign key to audit key
• Dummy (OK) row for records with no defects
• Audit dimensions can be unique to each fact table
• Error Event Fact can be used to fill in the measures of the audit dimension

@joe_Caserta#DGIQ2015
Data Quality Strategy
• 1. Perform Data Profiling
• 2. Document Data Defects
• 3. Determine Data Defect Responsibility
• 4. Define Data Quality Rules
• 5. Obtain Sign-off for Correction Logic
• 6. Integrate rules with Logical Data Mapping

@joe_Caserta#DGIQ2015
Enrollments
Claims
Finance
ETL
Horizontally Scalable Environment - Optimized for Analytics
NoSQLDatabases
ETL
Spark MapReduce Pig/Hive
N1 N2 N4N3 N5
Hadoop Distributed File System (HDFS)
Traditional EDW
Others…
The Evolution of the Enterprise Data Hub
Big Data Lake
ETL

@joe_Caserta#DGIQ2015
What’s Old is New Again
Before Data Warehousing DG/DQ Users trying to produce reports from raw source data
No Data Conformance
No Master Data Management
No Data Quality processes
No Trust: Two analysts were almost guaranteed to come up with two different sets of numbers!
Before Data Lake DG/DQ We can put “anything” in Hadoop We can analyze anything We’re scientists, we don’t need IT, we make the rules
Rule #1: Dumping data into Hadoop with no repeatable process, procedure, or data governance will create a mess Rule #2: Information harvested from an ungoverned systems will take us back to the old days:
No Trust = Not Actionable

@joe_Caserta#DGIQ2015
BigData
Warehouse
Data Science Workspace
Data Lake – Integrated Sandbox
Landing Area – Source Data in “Full Fidelity”
The Enterprise Data Pyramid
Metadata CatalogILM who has access,
how long do we “manage it”
Raw machine data collection, collect everything
Data is ready to be turned into information: organized, well defined, complete.
Agile business insight through data-munging, machine learning, blending with external data, development of to-be BDW facts
Metadata CatalogILM who has access, how long do we
“manage it”Data Quality and Monitoring
Monitoring of completeness of data
Metadata CatalogILM who has access, how long do we “manage it”
Data Quality and Monitoring Monitoring ofcompleteness of data
ETL cleans, conforms, consolidates, enriches each tier
Only top tier of the pyramid is fully governed
Fully Data Governed ( trusted)User community arbitrary queries and reporting
ETL/DQ
ETL/DQ
ETL/DQ
ETL

@joe_Caserta#DGIQ2015
Recommended Reading
Ralph Kimball
The Data Warehouse Lifecycle
Toolkit, 2nd Edition
Jack E Olson
Data Quality, the Accuracy
Dimension
Ralph Kimball, Joe Caserta
The Data Warehouse ETL
Toolkit

@joe_Caserta#DGIQ2015
Formal DW & ETL Training in NYC, 2015
Join us for one or both training courses combining two unique
workshops from international data warehousing veterans.
Workshops:
Sept 21-22 (2 days), Agile Data Warehousing with Lawrence Corr
Sept 23-24 (2 days), ETL Architecture and Design with Joe Caserta
SAVE $300 BY REGISTERING BEFORE JUNE 30TH!
Thanks! We look forward to seeing you there.

@joe_Caserta#DGIQ2015
Thank You / Q&A
Joe Caserta
President, Caserta Concepts
(914) 261-3648
@joe_Caserta