developing applications on gpus: discrete-event … · developing applications on gpus:...
TRANSCRIPT

Developing Applications on GPUs:
Discrete-Event Simulator
Implementation
A THESIS SUBMITTED TO THE UNIVERSITY OF MANCHESTER
FOR THE DEGREE OF MASTER OF SCIENCE
IN THE FACULTY OF ENGINEERING AND PHYSICAL SCIENCES
2011
By
Farhad Kajabadi
School of Computer Science

II | P a g e
Table of Contents
1. INTRODUCTION ..........................................................................................................................1
1.1. AIMS AND OBJECTIVES ........................................................................................................................ 2
1.2. STRUCTURE OF THE REPORT ................................................................................................................ 2
2. GPU COMPUTING .......................................................................................................................3
2.1. HETEROGENEOUS MASSIVELY PARALLEL ARCHITECTURES AND DATA PARALLEL TASKS .................................. 4
2.2. THE HISTORY OF GPU COMPUTING ...................................................................................................... 5
2.3. CUDA ARCHITECTURE ........................................................................................................................ 6
2.4. GENERAL PURPOSE GPU COMPUTING, OFFERINGS, AND TRADE-OFFS ....................................................... 7
3. DISCRETE EVENT SIMULATION ....................................................................................................9
3.1. DES ARCHITECTURE ........................................................................................................................... 9
3.2. PARALLEL DISCRETE EVENT SIMULATION ............................................................................................. 12
3.2.1. Conservative approach ........................................................................................................ 13
3.2.2. Optimistic Approach ............................................................................................................ 14
4. PDES IMPLEMENTATION ON GP-GPU ........................................................................................ 15
4.1. NEEDED INFRASTRUCTURES OF PDES AGAINST GP-GPUS’ CAPABILITIES .................................................. 15
4.1.1. Computational Capabilities ................................................................................................. 15
4.1.2. Synchronization and Communication Methods .................................................................. 16
4.1.3. Data Types........................................................................................................................... 16
4.2. PERFORMANCE TRADE-OFFS .............................................................................................................. 16
4.3. EXPECTATIONS OF THE RESULTS ......................................................................................................... 17
5. RESEARCH METHOD .................................................................................................................. 18
5.1. PROGRAMMING MODEL ................................................................................................................... 18
5.2. DEVELOPMENT PLATFORM ................................................................................................................ 18
5.3. CORRECTNESS VERIFICATION ............................................................................................................. 19
5.4. PERFORMANCE EVALUATION ............................................................................................................. 19
5.5. PROJECT PLAN ................................................................................................................................. 20
6. SUMMARY ............................................................................................................................... 20
APPENDIX A ..................................................................................................................................... 21
APPENDIX B ..................................................................................................................................... 22
REFERENCES .................................................................................................................................... 23

III | P a g e
Table of Figures
FIGURE 2.1: NVIDIA GEFORCE 8800 HARDWARE ARCHITECTURE ................................................... 6
FIGURE 3.1: THE FLOW CHART OF THE THREE PHASE METHOD FOR DISCRETE EVENT SIMULATION ...... 10

IV | P a g e
List of Abbreviations
ASIC Application Specific Integrated Circuit
API Application Programming Interface
CPU Central Processing Unit
CUDA Compute Unified Device Architecture
DES Discrete Event Simulator
DSP Digital Signal Processor
DX DirectX
FPGA Field Programmable Gate Array
GPU Graphics Processing Unit
GP-GPU General Purpose Graphics Processing Unit
HPC High Performance Computing
ILP Instruction Level Parallelism
PDES Parallel Discrete Event Simulator
PRNG Pseudo Random Number Generator
ROP Raster Operation Processor
SFU Special Function Units
SIMT Single Input Multiple Threads
SM Streaming Multiprocessor
SP Streaming Processor
TPC Texture/Processor Cluster

V | P a g e
Abstract
With the development of general purpose graphics processing unit (GP-GPU) in 2006, GPUs have
evolved into flexible and powerful parallel processors giving higher levels of parallel performance in
comparison with the conventional state of the art multi-core processors at lower costs. GP-GPUs are
widely used for general purpose and scientific computations; however, regarding their synchronous
organization and their single-instruction multiple-thread execution model, they are not the primary
target for task parallel applications.
Regarding the growing demand for the system simulation during the recent years, more efficient
simulation methods such as discrete event simulation (DES) have become the target of much research.
Discrete event simulation is widely used in science, military, and industry [5] as a powerful method of
determiningsystems’characteristics,andtheirneededresources.Thissimulationmethodisbasedon
reviewing the random occurrence of different independent instantaneous asynchronous events
changing the system state.
Most of the research done on carrying out simulations on GPUs has been based on the system
models that are using regular time increments. These increments can be accomplished either by adding
constant time deltas, like numerical integration, or event scheduling based on time deltas, as used in
discrete event approximations of continuous-time systems [14]. However, due to its asynchronous
nature, DES is characterized as not being efficient on GP-GPU architecture; as a result, to be able to map
the irregular time advances of discrete event models to the GPU’s many-core architecture efficiently a
new strategy should be devised. To achieve this goal, we aim to develop a new time approximation
mechanismusingtheNVIDIA’scomputeunifieddevice architecture (CUDA) platform.
The evaluation stage accounts for verifyingthecode’scorrectnessandmeasuringitsperformance.
After the code is developed its correctness and performance is going to be tested against several
independent parallel implementations of discrete event simulators. Also, a CPU-only version of the code
will be developed to be compared to the GPU version. Both performance and correctness verification
tests and benchmarks will be carried out on different scenarios based on different system models so
that the obtained results and drawn conclusions are reliable.
Although GP-GPUs are not originally compatible with the asynchronous nature of DES computations,
we expect to be able to exploit their massively parallel architecture to achieve satisfactory speed ups;
however, a very substantial level of performance is not expected to be achieved.

VI | P a g e
Declaration
No portion of the work referred to in this thesis has been submitted in
support of an application for another degree or qualification of this or
any other university or other institute of learning.

VII | P a g e
Copyright
I. The author of this thesis (including any appendices and/or schedules to this
thesis)ownsanycopyrightinit(the“Copyright”)ands/hehasgivenThe
University of Manchester the right to use such Copyright for any administrative,
promotional, educational and/or teaching purposes.
II. Copies of this thesis, either in full or in extracts, may be made only in
accordance with the regulations of the John Rylands University Library of
Manchester. Details of these regulations may be obtained from the Librarian.
This page must form part of any such copies made.
III. The ownership of any patents, designs, trademarks and any and all other
intellectual property rights except for the Copyright(the“IntellectualProperty
Rights”)andanyreproductionsofcopyrightworks,forexamplegraphsand
tables(“Reproductions”),whichmaybedescribedinthisthesis,maynotbe
owned by the author and may be owned by third parties. Such Intellectual
Property Rights and Reproductions cannot and must not be made available for
use without the prior written permission of the owner(s) of the relevant
Intellectual Property Rights and/or Reproductions.
IV. Further information on the conditions under which disclosure, publication and
exploitation of this thesis, the Copyright and any Intellectual Property Rights
and/or Reproductions described in it may take place is available from the Head
of School of School of Computer Science (or the Vice-President).

VIII | P a g e
Acknowledgements
I would like to take this opportunity to thank Dr. Christopher Kirkham for supervising, guiding, and
providing me with substantial and valuable information without which this project was not possible to
be accomplished.
I would like to thank all those who contributed to this research. Special thanks to Dr. Mikel Lujan for
providing me with the needed information and additional useful references.
Many thanks go to various people I met at the University of Manchester who assisted me in
developing my skills.
I gratefully thank my parents for their unconditional support and love during my life.

1. Introduction
As soon as processor performance started to be gained through adding multiple cores on a single
chip, a new trend toward developing new simpler, yet more powerful, parallel architectures started to
emerge. After the Microsoft DirectX 10 specification forced Graphics Processing Unit (GPU) developers
to develop new chips adopting unified graphics processors capable of doing both low-latency high-
precision, and high-latency integer and floating point operations, manufacturers came up with the idea
of using the newly developed chips for general computations [3]. To make their unified architecture
exploitable by general programmers, they needed to develop a programming model hiding the graphics
processing concepts; hence, they started to develop a new platform accessible through well known C
and C++ codes [1, 2]. Simplicity of the new programming model and its well known C syntax helped the
new platform to find its position in the competition of parallel architectures very quickly. The increasing
number of companies and applications making use of the new platform caused major hardware
manufacturers to invest more in the field; as a consequence, general code execution capabilities of the
GPUs started to increase very quickly to the point that new architectures allow GPU and CPU to be
integrated in a single chip. Integration of the GPU-CPU heterogeneous parallel architecture on a single
chip allows graphics processor to directly access the main memory through DMA without CPU
intervention, solving one of the main deficiencies of GPU computing namely indirect memory access.
Direction of the development of general purpose graphics processing units (GP-GPUs) and their
widespread use in different software domains shows that they are moving toward unification with
central processors. Furthermore, next generation operating systems are trying to exploit their power in
performing heavy data parallel tasks. Also, in the domain of scientific computing they have become
significantly successful and widely-used [2]. All the mentioned attributes of the GPU computing
architecture lead it to be referred to as one of the most significant blocks of the future of parallel
computing.
Nearly five decades ago, computer assisted design and modeling techniques started to show up,
since then, the presence of such techniques has significantly changed the process of designing and
testing new products before even the first prototype is made. According to heavy costs of producing and
testing a large number of real-world models, for most products, such as electronics, it is not efficient to
entirely carry out the verification process using prototypes. Also, in some fields, like the aero space
industry, it is not feasible to produce real world prototypes for different tests; as the real-world tests
might be very dangerous, sometimes even costing human lives. To design efficient systems and complex
structures besides verifying the produced design, computer simulation is widely trusted and used.
Its broad application in different industries makes discrete event simulation one of the most widely
used types of computer simulation and puts it at the centre of attention in much research. However, as
the systems that are going to be modeled get more complex, their simulation needs more time and
memory to complete. Due to the fact that the resources in sequential computers are physically limited
[12], to be able to reduce the simulation time, parallelizing the simulator is the main solution.

2 | P a g e
1.1. Aims and objectives
In spite of the widespread use of GP-GPUs in different scientific problem domains, there has not
been much work done in implementing parallel discrete event simulators (PDES) on this platform;
hence, this project aims to fill part of the gap by implementing PDES on NVIDIA’swidely-used GP-GPU
platform, namely Compute Unified Device Architecture (CUDA). The project starts with understanding
the CUDA architecture, its programming model, PDES architecture, and possible implementation
approaches, then, the research continues by starting the development of fundamental structures and
data types that a PDES needs. In the next stage, PDES will be developed and tested. Finally, a parallel
CPU version of PDES is developed and compared with the GPU version to verify the performance and
correctness achievements. Besides the developed CPU version of the simulator it will be, also, compared
to a number of other implementations so that more reliable conclusions can be drawn.
1.2. Structure of the Report
Chapter 2 reviews different aspects of GPU computing as the underlying architecture on which the
project is going to be developed. Initially, it describes the movement towards parallel computing
and the reasons behind it. It continues by depicting heterogeneous parallel architectures,
especially the CPU-GPU hybrid platform, and its potential to carry out heavy data parallel tasks
efficiently. A short history of GPUs’ development and the technologies that they used to exploit
will be surveyed to give an overview of the evolution of GPUs to their current state. Finally, their
strengths and weaknesses in performing general purpose computations are reviewed.
Chapter 3 is composed of general background information related to the structure and the
implementation of DES and PDES. To illustrate the different aspects of DES implementation and its
purposes in science and industry, this section starts with a short review. In the next section
parallelization of DES and different possible approaches are described. The last section reviews
the mentioned approaches of parallelization of DES based on their main proposed limitations and
trade-offs, also, some of the surveyed solutions for the main problems are discussed.
Chapter 4 tries to create a logical relation between two previous chapters so as to draw conclusions
about the needed infrastructure, possible trade-offs and bottlenecks, and the expected results.
The main difference between this chapter and the previous chapter is that it reviews the
implementation of PDES specifically on GPU; hence, there are different limitations, trade-offs, and
solutions in comparison with the previous chapter.
Chapter 5 involves the definition of the research methods that are going to be adopted for the project
so as to derive road map strategies for the tasks that are going to be carried out. The main tasks
are as follows: (a) Choosing the Suitable Development Platform, (b) Developing the Code, (c)
correctness verification, and (d) Performance Evaluation. Also, this section describes the
developed plan to clarify the scheme on which the tasks are scheduled to be done.

3 | P a g e
2. GPU Computing
For more than a decade, from the start of 90s until mid 2000s, it was a trend to increase the
processor’sperformancebyincreasingitsclockrate besides reaching a higher level of instruction level
parallelism in the processor design; however, this trend stopped continuing after the market leading
processor manufacturers faced several serious physical limitations in achieving more performance
following the old trend. As the main problem, power consumption and as a result heat dissipation of the
chip was shown to grow super-linearly with increasing the clock rate beyond some point around 4 GHz,
also, the complexity and cost of designing chips achieving higher levels of instruction level parallelism
on a single core started to grow exponentially. From another point of view, memory bandwidth, as one
of the most important factors affecting computer’sperformance, was limited; as a consequence,
memories were not abletokeepupwiththeprocessor’sperformance growth. All the mentioned
barriers, which are, also, referred to as: power wall, ILP wall, and memory wall, forced the computer
manufacturers to move to a multi-core processor design to be able to continue increasing their
products’performanceefficiently.
In multi-core architecture, the increasing number of available transistors on a specific surface of
silicon, as described by Moore’slaw,isusedtoaddmorecoresonasinglechip. In this approach each
core has a less complex architecture, as opposed to the previous trend of putting a single core with
much more complex design on the same surface. Benefiting from the new multi-core architecture
besides using multi channel memories, computer manufacturers are able to pass all the mentioned
barriers; however, the new parallel architecture introduces many new problems and bottlenecks for the
software developers.
Unlike the sequential execution, parallel execution of the code does not natively guarantee the
correct order of execution of the instructions, as the instructions are running on several independent
parallel cores simultaneously. To solve this problem, parallel units of execution should be synchronized
at certain points of execution to make sure that the code runs correctly. Synchronizations can be
significantly costly in terms of execution time; thus, it is a big trade-off to develop the correct code with
the least possible synchronization overheads. Also, by moving toward parallel computing, not all the
needed data is local anymore; hence, it is very important to design the code so that it keeps the locality
of data accesses as much as possible. Apart from the mentioned trade-offs there are a number of other
concerns with the parallel codes’ performance that are outside thisdiscussion’sborders;however,they
can be named as: load imbalance, deadlock and live lock, and scheduling overheads. In addition, it is
important to choose the correct sequential version of an algorithm to parallelize, as the best sequential
version is not always the best candidate for parallelization.
The Rise of the multi-core era has made the application’s performance more dependent on the
code’sdesignandits level of success in processor utilization; consequently, the performance, which
comes from the underlying hardware, is now more determined by the software.

4 | P a g e
2.1. Heterogeneous Massively Parallel Architectures and Data Parallel Tasks
Facing the mentioned physical barriers in increasing the single core processor’sperformance,the
high performance computing (HPC) communitydevelopednewstrategiestoaugmentMoore’slawand
started exploring new techniques to tackle the problems of conventional systems. Besides the
innovation of multi-core processors, computer developers tried to also, invest on the development of
some specialized processors aiming to give more performance where conventional general purpose
multi-core processors had been shown to perform poorly. The development of the new specialized
processors, allowed HPC community to design new heterogeneous computer architectures, in which
conventional and specialized processors are integrated to work cooperatively [12]. In other words, the
need for heterogeneous platforms comes from the demand for high performance, highly responsive
systems capable of interacting with other environments more efficiently.
The new systems based on heterogeneous architectures have shown to be able to achieve better
performance characteristics while in many cases consuming less power, and having lower total
development costs. The mentioned attributes of these architectures attracted a lot of scientific interest;
in fact, “inthelongterm,it’sbelievedthatheterogeneouscomputing holds tremendous potential for
accelerating applications beyond what one would expect from Moore's Law, while overcoming many of
the barriers that can limit conventional architectures” [12].
In general, heterogeneous architectures are composed of processors with different instruction set
architectures, different application binary interfaces, different APIs, or different memory interfaces.
Normally, these processors involve general purpose processors covering single core and multi-core
processors, special purpose processors such as DSPs and GPUs, custom logic accelerators such as ASICs
and FPGAs, and some specialized on-chip computational units such as encryption co-processors, and on-
chip network processors.
Since the development of the first GPU, GPU-CPU heterogeneous architecture is widely used to
calculate the motion of and render high resolution graphics. By their nature, GPUs have a large number
of computational cores processing different types of graphics data at lower clock rates than the
conventional commodity multi-core processors; hence, exposing a higher level of parallel performance
while consuming less power due to their lower core clock rate. Nevertheless, their potential of being
used as a general-purpose massively parallel processor had never been widely exploited until the
development of the general purpose GPUs, as doing general computations with traditional GPUs needed
comprehensive knowledge of at least one of the graphical programming languages [2, 3]. However, with
the development of GP-GPUs, developers derived a new programming model allowing the programmer
to write the codes performing general computations on GPUs using extensions over conventional C and
C++ compilers. The new programming model brought about power and simplicity in GPU programming
and allowed software developers to develop their complex applications based on GPUs without having
to have the knowledge of OpenGL or DirectX programming. Regarding the proven capability of GP-GPUs
in providing high levels of parallel performance, their application in science and industry for solving
complex problems has shown significant growth during the recent years. In spite of the fact that GP-
GPUs are, also, capable of processing task parallel jobs, the synchronous nature of their underlying

5 | P a g e
hardware makes them good targets for data parallel tasks involving doing the same computations on
large sets of different data. In other words, GP-GPUs are natively designed and optimized to do heavy
data parallel tasks, such as rendering high resolution graphics. However, they are, also, capable of
running multi stream parallel tasks and task parallel applications, yet with less potential performance.
2.2. The History of GPU Computing
The first GPU, named GeForce 256, was developed by NVIDIA in 1999. In fact, the term GPU, is
defined by NVIDIA for the architecture that integrates transforming, lighting, triangle clipping, rendering
and other graphics processing engines on a single chip [4]. Prior to the development of the first GPU, for
more than a decade, the term, graphics accelerator, was being used for the2D/3D graphics processing
chipsets. Graphics accelerators used to make use of several different task specific graphics processing
chips together to be able to render the final image. The separation of different graphics processing
pipelines was making it necessary to go off-chip after each stage of the process to move to the next
stage by feeding the processed data into the next chip. The demand for going off chip several times to
finish rendering a single frame was one of the main drawbacks of the old graphics accelerators; hence,
NVIDIA tried to improve the graphicaccelerator’sdesignbyintegratingallthemajorgraphicsprocessing
hardware and components on a single chip called GPU.
With the start of the GPU era, lots of companies started to invest in graphics processors, leading to
an explosion in development of new technologies and standards in graphics processing. Modern GPUs
started utilizing a number of specialized vertex and pixel-fragment processors named shaders. Vertex
processors are in charge of carrying out the needed computations on primitives such as points, lines,
and triangles. The operations of vertex processors are mainly based on transformation of the
coordinates into the screen space, while pixel-fragment processors typically operate on filled primitives
and interpolated parameters which are fed to it by a rasterizer. According to the fact that GPUs typically
need to process a larger number of pixels than vertices, pixel fragment processors, normally, outnumber
the vertex processors by the ratio of about three to one [4]. Yet, workloads of graphics are not always
well balanced, leading to inefficiency in hardware utilization and performance. To root out these
inefficiencies, NVIDIA GeForce 8800 GPU was composed of several unified processors capable of
operating on both pixels and vertices.
Traditionally,“Vertexprocessorsweredesignedforlow-latency, high-precision math operations,
whereas pixel-fragment processors were optimized for high-latency, lower-precisiontexturefiltering”
[4]. The new unified processors were able to carry out both tasks efficiently; thus,NVIDIA’sdevelopers
decided to convert the new GPU architecture into a general purpose parallel processor capable of
carrying out many different general and scientific types of computations. To achieve this goal, also, a
new programming model allowing efficient parallel application development without having any
knowledge of graphics processing languages was needed; hence, they tried to develop and integrate
their general purpose GPU programming compiler, named CUDA, with C and C++ languages. Nowadays,
CUDA power is even accessible in other programming languages such as FORTRAN and Python.

6 | P a g e
2.3. CUDA Architecture
All CUDA-enabled GPUs, typically, follow the same fundamental architecture; however, based on
their feature sets and optimizations, such as the compute capability version, some architectural
differences are observed among different generations of NVIDIA GP-GPUs. To give a general overview,
basic CUDA architecture of GeForce 8800 GPU is reviewed as a reference; yet, newer generations of
CUDA-enabled chips may have some additional features and hardware resources.
Figure 2.1 [3]: NVIDIA GeForce 8800 Hardware Architecture
As figure 2.1 shows, a CUDA-enabled GPU is utilized with a large number of streaming processors
(SPs), also known as CUDA cores. A group of eight joint SPs with instruction and constants caches, two
special function units (SFUs), and a dedicated shared memory form a streaming multiprocessor (SM).
A texture/processor cluster (TPC) consists of two streaming multiprocessors in addition to Geometry
and SM controllers, and its dedicated texture unit containing the texture cache. All the TPCs are
connected to an interconnection network linking them together, and to other resources such as raster
operation processor (ROP), and DRAM memory banks [3]. Unlike the cores in the state of the art multi-
core processors, all the SPs in a single SM can only process the same code at a time; making GP-GPU
architecture a promising target for data parallel tasks.

7 | P a g e
2.4. General Purpose GPU Computing, Offerings, and Trade-offs
Regarding the special architecture of GP-GPUs, they offer different opportunities, and potentials in
comparison with the conventional commodity multi-core processors. This section aims to give an
overview of different aspects of GPU computing; nevertheless, before starting the description, some
terms should be defined. The term host involves the entire hardware operating in the CPU side of the
system to run more critical parts of the code besides controlling the CPU-GPU interactions. The term
device refers to the GPU that is going to carry out part of the computations. CUDA- enabled GPUs use
the single-instruction, multiple-threads (SIMT) architecture in scheduling and processing the threads.
Warp is the smallest group of the threads that can be issued to a CUDA multiprocessor to be processed.
Warp size is a fixed number by which the threads executing the same instructions are grouped, in other
words, warp size is the smallest number of threads that can be issued to a streaming multiprocessor to
be processed, if a warp contains less than 32 threads, part of the computational resource assigned to
the code would remain idle. When switching threads, a complete warp of 32 threads is switched. Warps
together create larger groups of threads named blocks. Unlike the warp size, the block size is arbitrary.
Although, the block size limitations are hardware dependant, all the CUDA-enabled GPUs support three
dimensional blocks of the size, typically, 512 threads per dimension. The largest group of computational
threads in CUDA architecture is called a grid; it can accommodate up to 65536 blocks of the threads in
each of its two dimensions. This means that a grid can contain up to four billion threads in total.
Starting with their capabilities, it is needed to be mentioned that GP-GPUs, typically, spend a small
amount of die size implementing caches and branch predictors. The reason lies beneath their zero-
overhead hardware level support for thread scheduling. General purpose GPUs, typically use warp
switching to hide the effect of high latency operations such as global memory accesses. In other words,
whenever a group of the threads executing the same instructions reach a point that they need to
perform a high-latency operation, the scheduler automatically switches to the next available warp;
hence, while a group of the threads are waiting to finish a costly memory operation, another warp takes
their place and avoids the SM getting idle. The mentioned approach removes the need for adding large
cache memories or complex branch predictors to avoid processor clock waste; nevertheless, it is the
programmer’sdutytowritetheircodeso that it always offers at least an additional ready to be
processed warp to each of the used SMs to avoid streaming multiprocessors getting idle when a warp
performs a high-latency operation.
Besides the many-core architecture of GP-GPUs and their hardware level support for thread
scheduling, being the most prominent architectural achievement of such chips, there are a number of
additional architectural features allowing GPUs to perform general purpose integer and floating point
operations more efficiently. These facilities can be listed as follows: shared constant memory with
dedicated cache on each SM, 16KB of dedicated shared memory on each SM, dedicated texture unit
including the L1 texture cache on each SM, and dedicated instruction cache on each SM. These features
allow faster data access by decreasing the number of off-chip global memory accesses making the code
run more efficiently with a higher level of performance. To make coding the solutions to the special
multi-dimensional problem domains easier, GP-GPU platforms allow the thread blocks of up to three
dimensions to be defined, also, grids can be defined as one or two dimensional matrices of blocks;

8 | P a g e
hence, the programmer has more control to decide on the needed block and grid structure of the code
based on the domain of the problem that is going to be solved. In addition to all the mentioned
structural strengths of general purpose graphics processors, they, also, allow graphics interoperations
with CUDA functions, called kernels; thus, the result of the CUDA computations can be directly rendered
and drawn on the screen without host interference.
Despite the fact that GP-GPUs adopt many exclusive facilities to achieve higher levels of
performance in carrying out general computations, they lack many of the synchronization, control, and
communication capabilities that state of the art multi-core processors have. In fact, the only
synchronization facility that is natively implemented in CUDA architecture is the barrier. CUDA barriers
have a simple format and are called easily by calling the function __syncthreads() within the device
code; however, they do not give any options to choose the threads that are going to be synchronized.
This means that, with each call of the barrier all the threads in the grid would be synchronized.
Although, the needed operations for the barriers are implemented in hardware level, synchronizing a
large number of threads may put a significant amount of overhead on the system; to avoid this
inefficiency, the programmer should be careful in making use of the synchronizations.
As another downside of GPU computing, there is no way for the threads running on different SMs to
communicate efficiently, they can use the off-chip, high-latency global memory to exchange data,
though. In some applications, the threads need to repeatedly check one or more shared state variables.
In such cases, an attempt should be made to simulate the cache behavior by the means of on-chip
shared memory. In other words, all the threads should check their copy of the state variable located in
theSM’slocal shared memory. The shared memories should be updated with the global memory values
periodically. After each update operation, if any change in the value of the global memory is observed,
all the threads checking that shared memory should roll back and reprocess that iteration of the code.
State variable updates should be directly written back to the global memory using atomics.
Lack of the support for recursion is another noticeable drawback of GPU computing; however,
heterogeneity of the architecture allows parts of the code, such as recursive parts, to be run
sequentially on the CPU; resulting in less performance.
Another limitation of the CUDA architecture is that it does not allow any type of memory allocation
to be done within the device code; hence, the allocated memory for a device kernel is fixed unless it
returns and asks CPU to allocate a new memory of a different size to it. Even such strategy should be
implemented manually by the developer and there is no language intrinsic method for a kernel to ask
for more memory allocation.

9 | P a g e
3. Discrete Event Simulation
Having a long history in gambling, Monte Carlo, a city located in Monaco, has always had lots of
potential for the ambitious gamblers to show off their talents by developing new strategies in predicting
the random results of the games and earn large sums of money. More experienced gamblers usually
followed their instincts while some more talented beginners tried to make use of statistical strategies to
estimate when and how to play. Their approach in predicting the values of unknown variables inspired
statistics scientists to name a set of computational algorithms Monte Carlo methods after the city. These
methods are especially useful in simulation of complex systems with computers when application of
deterministic algorithms is infeasible [6]. Referring to Theodore Allen’sbook (2011) [5]: as a derivative
of, Monte Carlo simulation, Discrete Event Simulation tries to simulate the system model based on a
number of independent events changing the system state at different points of simulation time. In other
words, discrete event simulation is using the event-based model of the system besidesthesystem’s
initial state to predict thesystem’snewstateatanypointoftime;yet,itsmaingoalis,typically,
simulating the system behavior not only on independent specific points of time but also in periods to
help administrators make more rational decisions about the system.
Unlike most of the more complicated simulations, for less complex systems, discrete event
simulation can even be carried out manually on a number of spreadsheets [5]. This feature comes from
DES’s naturalapproachinmodelingthesystem’sbehavior,inspiring the widespread use of this method
in science and industry. The main application domains using DES are as follows: manufacturing, health
care, call centre support services, military, and logistics [5]. The mentioned list clearly specifies the
broad applicability and considerable significance of DES in different fields.
3.1. DES Architecture
There are several proposed approaches to implementation of the simulator; however, reviewing the
complete list of these strategies is beyond the boundaries of the context of this discussion; hence, only
the most widely trusted and used one, named the three-phase method, will be described in this section.
Michael Pidd, in his book (1998) [10] describes this powerful method for discrete event simulation.
As figure 3.1 shows, he suggests that after initializing the simulation with the initial state and the list of
initial events, phase A should find the time of the next event and advance the simulated clock to that
time. In the next phase, which is called phase B, all Bounded, or Booked, events that are scheduled
unconditionally are executed and the simulator advances to the next phase. In phase C Conditional
events, that involve state changes dependent on the conditions in the model, will be run. During the
execution of phase C, system conditions may change; hence, if any changes are observed in this phase,
simulator should iterate and check if any of the conditions of the remaining conditional events can be
met after the changes. This loop is repeated until no change to the system state is made in the last
iteration of phase C execution. As soon as the simulator observed no new event calls in the previous

10 | P a g e
iteration of C phase, it checks for the termination conditions, if the conditions are not met, it jumps back
to phase A and fetches the next event from the queue, otherwise the simulation terminates and the
results are returned.
Figure 3.1 [10]: The flow chart of the three phase method for discrete event simulation
Regardless of the execution model that the simulator follows, to achieve more reliable results, it
needs to schedule random events based on the suitable statistical distribution observed from the
original system. Research shows that a large number of the real world events follow one of the main
well-studied continuous distributions, namely: uniform distribution, triangular distribution, exponential
distribution, and normal distribution [5]. To mimic the real world random distribution of the events
based on the mentioned patterns, a sequence of uniformly distributed random numbers as long as the
number of events to be distributed is needed. The sequence of random numbers is then passed to the

11 | P a g e
distribution function to be mapped into the desired distribution of the events in the system. Even in
casesthattheevents’distributiondoesnotsatisfyanyofthementionedpatterns,it can be modeled
using new hybrid patterns derived from other main distribution functions; hence, regardless of the
events’distributionpattern,thesimulationalwaysneedstobeabletogeneratesequencesofrandom,
or pseudo random, numbers toreproducethelistofeventsresemblingtheoriginalsystem’sevent
distribution. For this purpose, pseudo random number generators (PRNG) are widely used in simulators;
yet, as there are a number of different types of PRNGs with varying levels of performance, choosing the
suitable generator algorithm has always been a trade-off in implementing such simulators.
From another point of view, to be able to serve the events separately in a chronological order,
implementation of a discrete event simulator is strongly relying on implementation of the ordered
queues. There are different types of queues proposed for simulation purposes; however, based on the
specific structural details of the simulator and the targeted underlying hardware, the suitable solution to
implement the underlying queue varies. Making a poor decision about the queue implementation
methodmayseriouslyaffectthesimulator’sperformance, making the simulator impractical; in
consequence, implementation of the underlying queue is one of the most challenging parts of the
simulator implementation. Some of the most widely adopted approaches to the queue implementation
for the simulation purposes are as follows: implicit lists, linear lists, leftist trees, two lists, binomial
queues,Henriksen’s,pagodas, skew heaps, splay trees, and pairing heaps [7]. Also, there are more
recent implementations of DES aiming at higher levels of performance using highly optimized versions of
calendar queues, and skip lists [8].
In addition to the mentioned infrastructure, an event server is needed to fetch the events from the
queue and process them, applying the needed state changes to the system model after processing each
event. As the core of simulator, event server is, also, in charge of managing the queue and controlling
the generation of random numbers based on the simulation needs. In fact, it is a supervisor, controlling
all the simulator resources along with the simulation’s flow. Having the initial state of the system and its
statistical model, the server asks for the generation of an initial list of events, then, it starts the
simulation by picking up the first event from the queue and processing it. During the process of each
event two main changes may happen; the system state may change, and new events may be created.
The event server should be able to effectively deal with all the mentioned changes so as to reflect the
observed changes in the simulated system model. The server is also in charge of detecting the
termination of simulation. Naturally, discrete event simulations have the potential to run infinitely; thus,
the termination conditions should be defined based on the value of simulation variables such as
simulation time, or some specific statistics of the model. Also, the termination can be scheduled based
on the occurrence of specific events or system state conditions.
As the last vital part of DES architecture, an automated reporting mechanism is needed to gather
thesystemmodel’sstatisticsduringthesimulation.Also,attheendofthesimulationitshouldbeable
to sum up the gathered statistics and derive the universal simulation statistics, forming the final
simulation outcomes. It needs to be mentioned that there are different approaches in gathering the
information; however, most of the simulators either gather the statistics after the occurrence of each
event or after specific time intervals. Some implementations integrate this mechanism into the event

12 | P a g e
server; this integration, allows seamless operation of event processing and reporting, leading to a higher
level of performance.
To clarify the defined concepts, a simple customer service desk is going to be described as an event-
based model. Assume a service desk serving a single queue of customers. Costumers arrive at random
points of time, notwithstanding the fact that their average rate of arrival over the specified period of
time is constant. The arrival of customers can be assumed as a bounded event, as its occurrence is not
dependant on any external conditions. From another aspect, the service desk calls and serves the clients
one by one based on their order in the queue. The action of serving a customer can be assumed as a
conditional event, as it can happen only if there is a customer in the queue waiting for the service. The
main possible events in a service desk model can be named as: customer arrival, customer departure,
starting the service, and finishing the service.
3.2. Parallel Discrete Event Simulation
As the physical systems get bigger and more complex it gets substantially harder to simulate them
with the level of resources available in sequential systems, in a reasonable amount of time; processor
clock and system memory are two major bottlenecks of sequential simulation making the simulation of
large systems nearly impossible. To avoid this problem and ensure the future of discrete event
simulation, it should be parallelized. From another standpoint, parallel discrete event simulation is
academically important due to the considerable amount of parallelism that its underlying concept
represents; yet, it is one of the most challenging tasks to parallelize a simulator so that it achieves
substantial levels of performance while keeping its original level of accuracy and correctness [11].
As Fujimotodefines;“Parallel Discrete Event Simulation (PDES) refers to the execution of a single
discreteeventsimulationonaparallelcomputer”*11+.A parallel version of the simulator demands
simultaneous execution of the events during the simulation; however, this parallel execution leads to a
number of very challenging problems. Although creating a strong initial impression about being an ideal
target for parallelization, discrete event simulation has, paradoxically, shown to be substantially hard to
be parallelized so that it can achieve remarkable speedups by effectively utilizing the parallel processors.
In this section an attempt is made to define the main problems in parallelizing the simulation, and
review some of the proposed solutions.
In a sequential execution of the simulation, it is naturally guaranteed that the events will be
executed in a chronological order based on their timestamps while in the parallel simulation several
parallel processors are executing the events simultaneously; hence, there is no guarantee that a state
change to the system caused by event B, having a bigger timestamp than event A, does not affect the
execution of event A. If this happens, it can be concluded that a future event has affected the system’s
past, which is not acceptable. This group of problems is categorized as causality problems by Fujimoto in
his paper (1989) [11]. Running events with different timestamps in parallel does not always directly lead
to causality problems; in some cases while two events are executing in parallel, the event with the
smaller timestamp creates a new event with a timestamp bigger than that of the parent event, yet

13 | P a g e
smaller than the timestamp of the other parallel event. In such case, to guarantee the correct execution
of the simulation, it should be ensured that the newly created event is run before the other parallel
event; however, as the other event with the higher timestamp is already executing it is really challenging
to develop a mechanism to postpone its execution without making its dedicated computational
resources idle. From another standpoint, the difficulty in dealing with causality problems is not only to
solve them without decreasing processor utilization, but also to minimize the synchronization
overheads.
Parallel discrete event simulators, normally, divide the job among several processes using the
shared queues. To avoid causality problems, most of the existing parallelization strategies provide a
mechanism to prevent the processes from having direct access to the shared state variables [13]. In
general, solutions to parallelizing the simulation can be categorized in two main categories: conservative
approaches and optimistic approaches.
3.2.1. Conservative approach
The first implementations of parallel discrete event simulation were based on the conservative
approach. Conservative techniques try to strictly avoid the possibility of causality errors by using some
mechanism to find safe points in time to execute an event without facing causality problems. For these
types of strategies to work correctly the safe time detection mechanism should verify that all the events
with the potential to affect the current event execution are already executed. The main strategy of
conservative approaches can be clarified by a simple example; assume that a process contains an event,
say E1, with the assigned timestamp T1 being the smallest timestamp among all the events that are
contained in the process. Based on the conservative approach the process can start executing the event
only if it can determine that it is impossible for it to later receive another event with the smaller
timestamp than T1. Following this technique local causality will be preserved and it can safely execute E1.
In conservative strategies processes with no safe event must block until one is available; this may
lead to a deadlock in which a circular chain is formed of processes waiting for each other to execute
their events first. There are two main proposed solutions to the deadlock problem in the conservative
approach; deadlock avoidance, and deadlock detection and recovery. Although dealing with the
possibility of the deadlocks is a substantial problem in conservative methods, it is not the main
drawback of such strategies. While guaranteeing the correct execution of the simulation, conservative
strategies maysignificantlyaffectthecode’sperformancebycausing a great portion of the total
processor time to be spent waiting for other possibly dependant events on other processes to finish
execution. Research shows that in some cases optimizing the simulator based on application specific
knowledge may lead to a substantial performance gain [11]. In spite of their poor general performance,
conservative approaches have been shown to give the same level of accuracy as the equivalent
sequential methods. Such approaches are mainly involved with different concepts, some of which are
listed by Fujimoto as follows: deadlock avoidance, deadlock detection and recovery, synchronous
operation, conservative time windows, improving lookahead, and conditional knowledge [11]. For each
of these concepts he has referred to one or more prior works describing their progress in practical use;
nevertheless, full description of the concepts and their significance is beyond the scope of this context.

14 | P a g e
3.2.2. Optimistic Approach
Unlike conservative strategies, optimistic techniques do not impair thesimulator’sperformanceby
preventing all potentially dependant events to execute in parallel. They reach this goal by employing the
mechanisms that detect the effect of causality conflicts on execution of the events. One of the most
effective proposed methods for doing this is time warping. In this method all the processes start
executingtheirstaticallyassignedeventsinparallelmarkingthestatechangeswiththerelevantevent’s
timestamp. If later an event is observed with the timestamp smaller than that of the last state change of
the system, the process in charge of executing the previous event should roll-back and change the
system’s state to its state before the last change and restart processing the conflicted event. Execution
of a conflicting event may make two types of change in the system; it may change the system state, and
also, it may send wrong messages to other processes. To deal with the first problem optimistic methods,
such as Time Warping, must periodically backup the system state to be able to roll it back when
necessary. In case of wrong messages the process should send a counteracting message so as to tell the
recipient process to ignore the previous message; however, if the message is already processed the
recipient process, also, must roll back. This chain must continue recursively until all the changes related
to the execution of the conflicting event are completely rolled back.
From the performance standpoint, optimistic methods have great potential for achieving higher
levels of performance than the conventional conservative strategies. Fujimoto reports that in many of
the prior works, researchers were able to achieve significant levels of speedups, for example 56 using 64
processors in one of the cases [11]. However, optimistic approaches generally consume more memory
to save the system state, leading to a trade-off between performance and memory consumption. It
needs to be mentioned that, although much work has been done about optimistic methods the space-
time trade-offs in these methods are not fully understood yet [11].
From another perspective, unlike conservative approaches, optimistic strategies must be able to
recover from the arbitrary errors that may arise during the execution; otherwise, the errors may be
erased by roll-backs causing the computations to be trapped in infinite loops. In such cases the Time
Warp executive must intervene and recover the computation.
It is proposed that to get the best possible results the optimistic approach should have dedicated
hardware support allowing it to do the roll-backs and error recoveries more efficiently.

15 | P a g e
4. PDES Implementation on GP-GPU
This chapter involves the conclusions and expectations about the GP-GPU implementation of PDES
based on the surveyed literature. As there has not been much prior work done in the field, most of the
information in this chapter is not directly extracted from any available source, yet concluded
and /or derived by reviewing the gathered data. To draw more realistic conclusions and create sensible
expectations an effort is made to overview the entire gathered data attempting to discover the rational
relationships between the surveyed subjects from the contexts.
This chapter starts by describing the relationship between the needed PDES infrastructures and GP-
GPU capabilities. Its Next section will focus on illustrating the different expected performance trade-offs
concerning PDES implementation on GP-GPUs. Finally, it is attempted to converge from the entire
surveyed literature and make the final conclusions about our expectations of the project results.
4.1. Needed Infrastructures of PDES against GP-GPUs’ Capabilities
The main facilities that are needed to be able to implement PDES on a parallel hardware structure
can be listed as follows: (1) computational capabilities, (2) synchronization and communication
methods, and (3) data types.
4.1.1. Computational Capabilities
Most of the computations that are involved with PDES do not, normally, need 64bit integer or
double precision floating point operations; as a result, all the generations of CUDA cards support most of
the computations that are needed by PDESs; yet, some of the newer generations provide capabilities
yielding new potential to increase the simulator’s performance. If used properly, some of these
capabilities such as atomic operations on shared memory may significantlyimprovethecode’s
performance by avoiding off-chip global memory accesses. Apart from atomics and double precision
floating point operations, different generations of CUDA cards do not significantly vary based on their
computational capabilities; nevertheless, as we shall see soon, different generations of CUDA-enabled
GPUs have fundamental differences in their synchronization and thread management capabilities
resulting in totally different expectations of the simulator performance.
All CUDA-enabled GP-GPUs have a compute capability version reflecting their underlying hardware
architecture’s generation and its computational capabilities. To be able to choose a suitable and
affordable target card, Appendix B provides a table of different CUDA cards and their compute capability
versions. It must be clarified that the cards with the compute capability version 1.3 or higher are
assumedtobeabletocompletelymeetthesimulator’scomputationalneeds.

16 | P a g e
4.1.2. Synchronization and Communication Methods
Due to its special approach in processing heavy data parallel tasks, CUDA architecture does not
provide any type of inter-thread communication; to compensate for the lack of inter-thread
communications, two main solutions are proposed; the first one is returning control to the host
whenever a communication is needed and continuing the process when the needed synchronizations
are done. This strategy is not efficient and puts a significant amount of overhead on the system,
especially when the code needs to communicate frequently. A better approach is implementing
communications in the device code; for example, the code can check a shared variable, or a set of
shared variables, periodically to see the other threads’ message, if there is any. Similar to the previous
case, the latter strategy is not efficient; however, having some knowledge about the system model that
is going to be simulated, this strategy can get optimized significantly minimizing its overheads. From
another perspective, CUDA architecture does not natively support locks and some other
synchronizations that are needed for the implementation of fundamental parallel data types of PDES;
yet, as CUDA cards with the compute capability version of 1.3 or above support different types of basic
atomic operations on different on-chip and off-chip memories, it is possible to implement these
synchronizations efficiently. In other words, the reason making software level implementation of the
needed synchronizations, possibly, efficient is that they can be done locally on each stream
multiprocessor using the atomic operations on the on-chip shared memory. If more than a single SM is
processing the same code, their shared memories can be synchronized with the global memory
periodically; however, implementing the algorithm that controls the global-shared memory
synchronization is very challenging as it should deal with correctness problems besides a complicated
trade-off between correctness and performance.
4.1.3. Data Types
All the needed basic data types of PDES, such as integer and floating point, are natively supported by
CUDA architecture; yet, the needed parallel data types such as the shared ordered queues should be
implemented in software by the programmer. Implementation of these parallel data types is crucially
dependent on the availability of the synchronizations that are discussed in the previous section. As the
mentioned parallel data types are going to be used as an ordered queue containing the simulation
events based on their chronological order, it is extremely important that the data type be chosen based
on the specific target GP-GPU architecture and its properties; otherwise, either it might not be feasible
to be implemented on the device or, in a less complicated case, it might perform poorly.
4.2. Performance trade-offs
Despite the fact that GP-GPUs support the execution of multi stream task parallel applications, they
are not mainly built and optimized for this purpose; hence, their real underlying performance potentials
can be fully exploited only while executing the codes that are developed based on low-dependency data
parallel strategies. Unfortunately, the nature of discrete event simulation does not allow it to be defined
as a massively data parallel task; yet, it does not necessarily mean that achieving an acceptable level of

17 | P a g e
speed up is infeasible when it is implemented on GPU. From another perspective, depending on how
well the GPU architecture potentials are exploited by the code, its achieved level of performance may
differ. It should be clarified that, there exist some methods achieving speedups of up to 10x using an
approximate time-based event scheduling approach; however, these methods may decrease the
simulator’sflexibilityand accuracy [14]. The main trade-offsaffectingthecode’sperformance can be
categorized as follows: synchronization-correctness trade-offs, accuracy-performance trade-offs, and
finally, performance-code simplicity trade-offs. It can be added that, in comparison with the state of the
art multi-core computing, GPU computing is just in its infancy; thus, it is not mature enough for many
types of complex fine grain computations; however, this Achilles tendon of GPU programming models
can be expected to be cured in the future with software and hardware level advances in GPU
computing. Yet, these advances need lots of research, endeavor, and creativity to be made.
4.3. Expectations of the Results
While, GP-GPUs are known as flexible and powerful processors exposing high levels of parallelism,
they have been shown to perform poorly when executing the parallel tasks that are not naturally
adaptable to the special GP-GPUarchitecture.AsmentionedbyParkandFishwick;“discreteevent
simulation has been characterized as being an inefficient application for the GPU primarily due to the
inherent synchronicity of the GPU organization and an apparent mismatch between the classic event
schedulingcycleandtheGPU’sbasicfunctionality”*14+.Inspiteofits inadaptable nature to the GP-GPU
processing architecture, a parallel discrete event simulator can be implemented on GPUs; however, not
always a satisfactory level of speedup can be expected.
From an academic standpoint, the significance of implementing parallel simulators on GPUs is not
only their potential in gaining higher levels of performance, but also, their problem domain that
introduces substantial levels of potential parallelism, yet, paradoxically, incurs in lots of challenging sub-
problems. Regardless of the performance achievements, a correct implementation of PDES on GP-GPUs
is especially important because it addresses many of the general problems that are faced with GPU
computing and derives new solutions for them.

18 | P a g e
5. Research Method
In this chapter, the research method that is adopted for the project in order to achieve a general-
purpose implementation of discrete event simulator running on GPU is defined. To reach this goal, in
the first step, a framework of the program that is going to be developed is established. In the next
place, mandatory infrastructures and tools for the development phase are specified based on the
information that is obtained from the surveyed literature. Finally, the strategies for performance and
accuracy evaluation of the code are devised.
5.1. Programming Model
A general-purpose discrete event simulator is targeted to be developed on top of the GP-GPU
architecture; to achieve this goal, its demanding fundamental infrastructures such as parallel data types
and pseudo random number generator functions should be developed and verified so that their correct
implementation is ensured. As GPUs have different underlying hardware architecture in comparison
with the conventional CPU-based parallel systems, the entire implementation phase is concerned with
developing new application specific methods to exploit the GP-GPU programming model attributes in a
more optimized way. Memory access is planned to be optimized by making use of cached constant
memory and fast on-chip shared memory, also, cached texture memory is planned to be used for multi
dimensional domains of the simulation. To achieve higher levels of accuracy and correctness GP-GPUs
offer different types of hardware supported atomic actions on integers and floating points, yet, the
availability of these atomics differs in different generations of GP-GPUs. Other planned mechanisms to
obtain a more practical implementation of the targeted application can be listed as follows: minimizing
global memory access, minimizing Host-Device data transfer, preserving locality of the threads, and
minimizing the synchronization overheads; nevertheless, there is a trade-off between the needed
synchronizations and the achievable level of accuracy.
5.2. Development platform
Among different types of versatile graphics processor architectures and their relevant programming
languages, CUDA-enabled NVIDIA GPU architecture and the CUDA C compiler are chosen as the targeted
development platform. The reason behind this selection can be reviewed from different aspects:
1. Unlike other GP-GPU programming languages, CUDA C compiler is specifically developed and
optimized for programming NVIDIA GPUs; as a result, it gives a very powerful integrated
environment in which hardware and software are tightly coupled and optimized.
2. CUDA C compiler uses the conventional C and C++ code syntax; in consequence, coding CUDA
applications is easier for the programmers with a background in C and C++ programming.

19 | P a g e
3. CUDA architecture gives many hardware level facilities to help making performance evaluation and
debugging simpler, yet more powerful.
4. Both CUDA compiler and C compiler are available for several different operating systems and
platforms; this gives the programmer the ability to write a single code and then compile it for
different target platforms without making any changes to the code.
5. NVIDIA is the pioneer company in developing GP-GPUs. As previously mentioned it has introduced
GeForce 8800 as the first GP-GPU in the world in 2006.
5.3. Correctness Verification
To verify the correctness of the code several different specific system models should be chosen and
simulated on, both, the developed application, and the other trusted versions of the application
available in the market, then, the results should be compared and the level of errors should be
evaluated. Also, the correctness of the application can be verified in smaller scales using Excel
spreadsheets. In other words, simulation of a smaller system model should be done manually using
Excel and then the results should be compared to those of the developed application. Benefit of the
latter approach of correctness verification is that handcrafted simulation using spreadsheets gives you
the entire generated numbers and statistics, making the comparison easier and more reliable; however,
as in this approach simulated systems are simple, a number of different simulations on different system
models should be done and their results should be compared with those of the developed application to
make sure that the correspondence of the results is not random.
5.4. Performance evaluation
To achieve the most reliable results the GPU side code performance is targeted to be measured
using the highly accurate CUDA events. These events are hardware driven and allow automated event
triggering based on the occurrence of other events, also, these timers are synchronized in hardware;
hence, they offer simplicity of implementation besides high levels of accuracy.
To evaluate the application’sperformanceasimilarCPUonlyversionoftheapplicationisgoingto
be developed and compared to the original application to verify its strengths and weaknesses from a
performance standpoint. Also the developed application will be benchmarked by some of the available
standardbenchmarkingtoolsforGPUs.Finally,thecode’sperformancewillbecompared to that of the
other available real-world implementations of the application so as to fundamentally verify the position
that the developed code stands up against the more sophisticated implementations that are highly
optimized.

20 | P a g e
5.5. Project plan
The project is divided into a number of tasks so that the progress is more manageable based on the
project schedule. These tasks can be named as follows: (1) background research, (2) writing the
background report, (3) understanding the CPU implementations of PDES, (4) developing the needed
data types and synchronizations, (5) developing the simulator, (6) correctness verification and
performance evaluation, (7) writing the final project report. Appendix A shows the Gantt chart depicting
the project plan with more details.
6. Summary
This report illustrates the reviewed literature for the purpose of developing a parallel discrete event
simulator on GP-GPU. Understating the significance of discrete event simulators in science and industry
motivates this project to try implementing it on a general purpose GPU as a many-core processor based
on a heterogeneous parallel architecture.
The report was started by describing the main motivations of the project and generalizes about GP-
GPUs and their significance in parallel computing. It was then narrowed down to the specific NVIDIA
CUDA architecture and its provided programming model. It showed the devotion of GP-GPU hardware
architecture to the execution of data parallel tasks and demonstrated its capabilities and drawbacks
from different aspects. Then, DES was described and the subject was narrowed down to parallel types of
DES. Main motivations and the most significant problems of parallelizing the simulator were clarified.
After reviewing GP-GPUs and DESs individually, different aspects of the surveyed information were
taken into account and put together to make the final conclusions about the expectations of the project
results. In the next step, drawn conclusions were discussed. At the end, research methods and chosen
strategies that are adopted for the project were discussed and the described approaches and strategies
were justified.
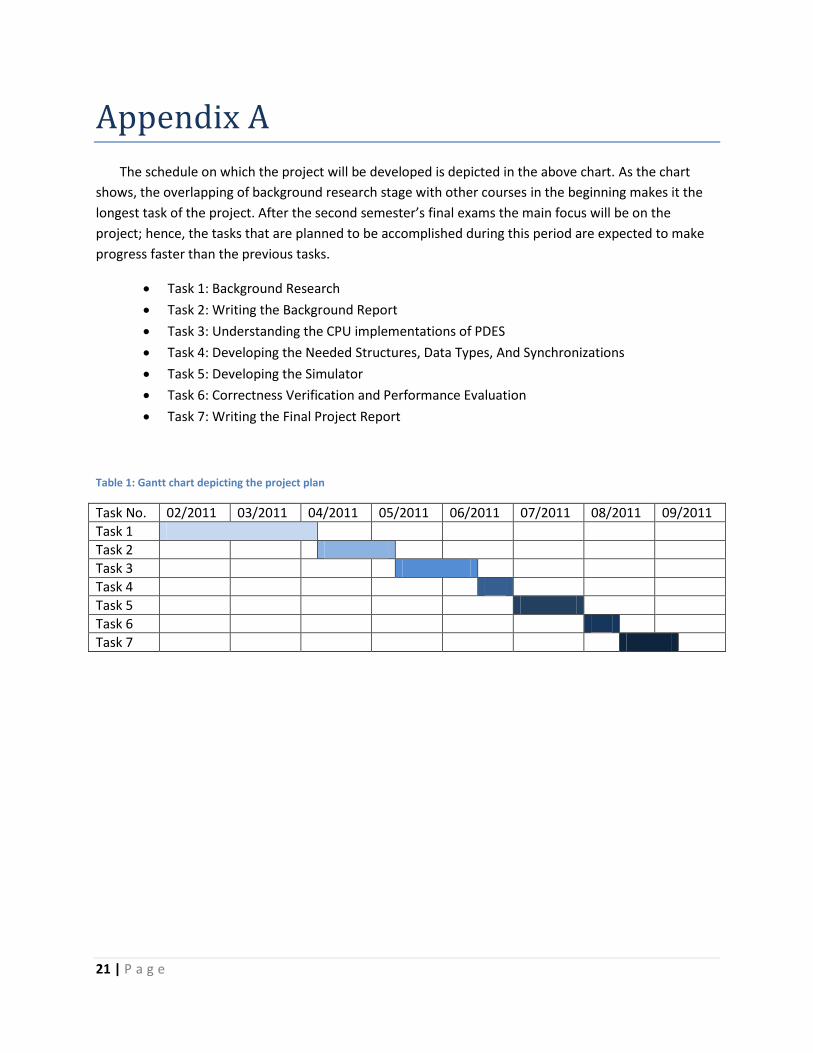
21 | P a g e
Appendix A
The schedule on which the project will be developed is depicted in the above chart. As the chart
shows, the overlapping of background research stage with other courses in the beginning makes it the
longest task of the project. After the second semester’s final exams the main focus will be on the
project; hence, the tasks that are planned to be accomplished during this period are expected to make
progress faster than the previous tasks.
Task 1: Background Research
Task 2: Writing the Background Report
Task 3: Understanding the CPU implementations of PDES
Task 4: Developing the Needed Structures, Data Types, And Synchronizations
Task 5: Developing the Simulator
Task 6: Correctness Verification and Performance Evaluation
Task 7: Writing the Final Project Report
Table 1: Gantt chart depicting the project plan
Task No. 02/2011 03/2011 04/2011 05/2011 06/2011 07/2011 08/2011 09/2011
Task 1
Task 2
Task 3
Task 4
Task 5
Task 6
Task 7
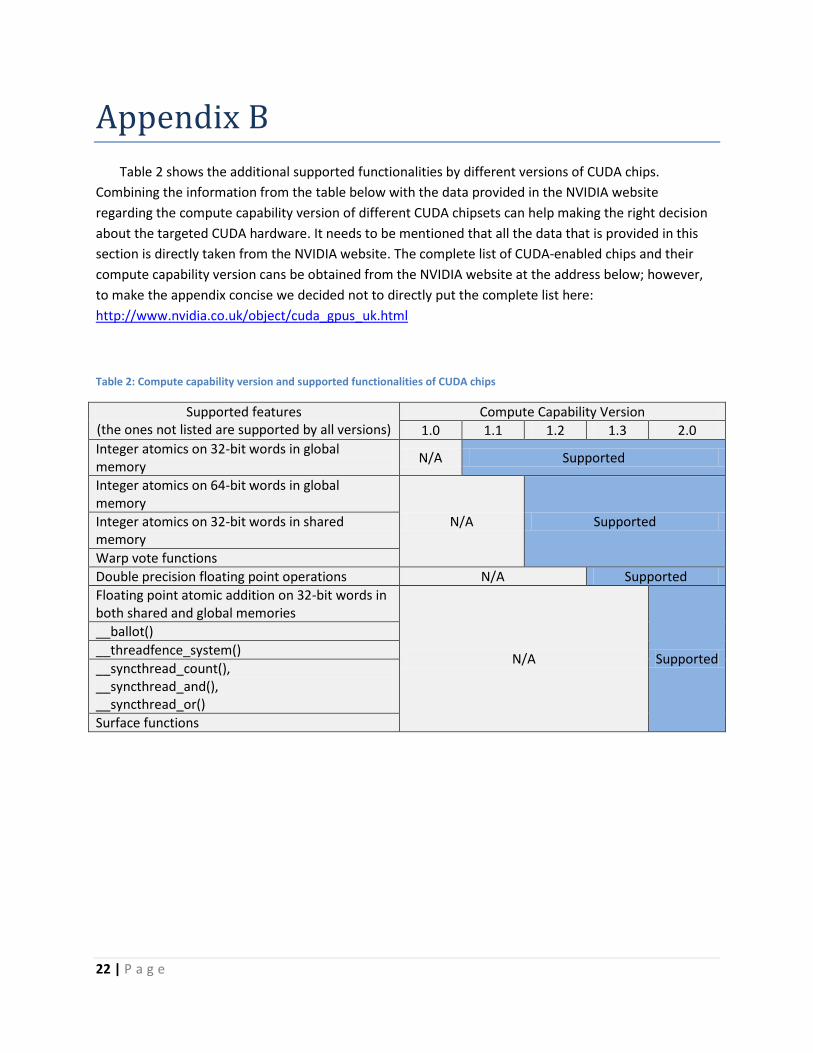
22 | P a g e
Appendix B
Table 2 shows the additional supported functionalities by different versions of CUDA chips.
Combining the information from the table below with the data provided in the NVIDIA website
regarding the compute capability version of different CUDA chipsets can help making the right decision
about the targeted CUDA hardware. It needs to be mentioned that all the data that is provided in this
section is directly taken from the NVIDIA website. The complete list of CUDA-enabled chips and their
compute capability version cans be obtained from the NVIDIA website at the address below; however,
to make the appendix concise we decided not to directly put the complete list here:
http://www.nvidia.co.uk/object/cuda_gpus_uk.html
Table 2: Compute capability version and supported functionalities of CUDA chips
Supported features (the ones not listed are supported by all versions)
Compute Capability Version
1.0 1.1 1.2 1.3 2.0
Integer atomics on 32-bit words in global memory
N/A Supported
Integer atomics on 64-bit words in global memory
N/A Supported Integer atomics on 32-bit words in shared memory
Warp vote functions
Double precision floating point operations N/A Supported
Floating point atomic addition on 32-bit words in both shared and global memories
N/A Supported
__ballot()
__threadfence_system()
__syncthread_count(), __syncthread_and(), __syncthread_or()
Surface functions

23 | P a g e
References
[1] D. B. Kirk and W. W. Hwu, Programming massively parallel processors: a hands-on approach, Morgan
Kaufmann, 2010
[2] J. Sanders, et al., CUDA by example: an introduction to general-purpose GPU programming, Addison-
Wesley, 2011.
[3] E. Lindholm, et al., NVIDIA Tesla: A Unified Graphics and Computing Architecture, 2007
[4] R. Borgo & K. Brodlie,“State of the Art Report on GPU Visualization”,The University of Leeds, 2009
Available on: http://www.viznet.ac.uk/reports/gpu/1 [accessed Apr 2011]
[5] T. T. Allen, Introduction to discrete event simulation and agent-based modeling voting systems,
health care, military, and manufacturing. London New York: Springer, 2011
[6] H. Douglas, How to measure anything: finding the value of "intangibles" in business, John Wiley &
Sons, 2007
[7] D. W. Jones, An empirical comparison of priority-queue and event-set implementations,
Communications of the ACM, 1986
[8] K. L. Tan & L. J. Thng, SNOOPy Calendar Queue, Proceedings of the 32nd Winter Simulation
Conference, 2000
[9] S. Robinson, Simulation: the practice of model development and use, John Wiley & Sons, 2004
[10] M. Pidd, Computer simulation in management science, John Wiley & Sons, 1998
[11] R. M. Fujimoto, Parallel Discrete Event Simulation, Proceedings of the 1989 Winter Simulation
Conference, 1989
[12] A. Shan, Heterogeneous Processing: a Strategy for Augmenting Moore's Law, Linux journal, Jan 02, 2006.
[13] R. M. Fujimoto, The Virtual Time Machine, International Symposium on parallel algorithms and
architectures, 1989
[14] H. Park and P. A. Fishwick, A GPU-Based Application Framework Supporting Fast Discrete-Event
Simulation, Simulation journal, Vol. 86, Issue 10, 2010