designing evaluations gao/pemd-10.1 · pdf fileevaluation designs are characterized by the...
TRANSCRIPT

United States General Accounting Office
GAO Program Evalution and MethodologyDivision
March 1991
DesigningEvaluations
GAO/PEMD-10.1.4


Preface
GAO assists congressional decisionmakers in theirdeliberative process by furnishing analyticalinformation on issues and options underconsideration. Many diverse methodologies areneeded to develop sound and timely answers to thequestions that are posed by the Congress. To provideGAO evaluators with basic information about themore commonly used methodologies, GAO’s policyguidance includes documents such as methodologytransfer papers and technical guidelines.
This methodology transfer paper addresses the logicof program evaluation designs. It provides asystematic approach to designing evaluations thattakes into account the questions guiding a study, theconstraints evaluators face in conducting it, and theinformation needs of its intended user. Taking thetime to design evaluations carefully is a critical steptoward ensuring overall job quality. Indeed, the mostimportant outcome of a careful, sound design shouldbe an evaluation whose quality is high in quite specificways.
Evaluation designs are characterized by the manner inwhich the evaluators have
• defined and posed the evaluation questions for study,• developed a methodological approach for answering
those questions,• formulated a data collection plan that anticipates
problems, and• detailed an analysis plan for answering the study
questions with appropriate data.
Designing Evaluations is a guide to the successfulcompletion of these design tasks. It also provides adiscussion of three kinds of evaluationquestions—descriptive, normative, and causal—andvarious methodological approaches appropriate to
GAO/PEMD-10.1.4 Desiging EvaluationsPage 1

Preface
each one. For illustration, the paper contains anarration of a design undertaken by the ProgramEvaluation and Methodology Division (PEMD) inresponse to a congressional request. The originalpaper was authored by Ray Rist and Carl Wisler inJuly 1984. This reissued (1991) version, prepared byCarl Wisler, supersedes the earlier edition.
Designing Evaluations is one of a series of papersissued by the Program Evaluation and MethodologyDivision. The purpose of the series is to provide GAOevaluators with guides to various aspects of audit andevaluation methodology, to illustrate applications,and to indicate where more detailed information isavailable.
We look forward to receiving comments from thereaders of this paper. They should be addressed toEleanor Chelimsky at 202-275-1854.
Werner GrosshansAssistant Comptroller GeneralOffice of Policy
Eleanor ChelimskyAssistant Comptroller Generalfor Program Evaluation and Methodology
GAO/PEMD-10.1.4 Desiging EvaluationsPage 2
GAO/PEMD-10.1.4 Desiging EvaluationsPage 3

Contents
Preface 1
Chapter 1 Why Spend Timeon Design?
6
Chapter 2 The DesignProcess
12Asking the Right Question 12Considering the Evaluation’s Constraints 20Assessing the Design 26
Chapter 3 Types of Design
30The Sample Survey 33The Case Study 43The Field Experiment 50The Use of Available Data 61Linking a Design to the Evaluation Questions 67
Chapter 4 Developing aDesign: anExample
71The Context 71The Request 73Design Phase 1: Finding an Approach 74Design Phase 2: Assessing Alternatives 76Design Phase 3: Settling on a Strategy 82
Appendixes Bibliography 84Glossary 92Papers in This Series 95
Tables Table 3.1: Evaluation Strategies and Types ofDesign
30
Table 3.2: Characteristics of Four EvaluationStrategies
32
Table 3.3: Some Basic Contrasts BetweenThree Field Experiment Designs
52
GAO/PEMD-10.1.4 Desiging EvaluationsPage 4

Contents
Figure Figure 3.1: Linking a Design to theEvaluation Questions
68
Abbreviations
AFDC Aid to Families with Dependent ChildrenGAO U.S. General Accounting OfficeJSARP Job Search Assistance Research ProjectPEMD Program Evaluation and Methodology
DivisionWIN Work Incentive
GAO/PEMD-10.1.4 Desiging EvaluationsPage 5

Chapter 1
Why Spend Time on Design?
According to a Chinese adage, even a thousand-milejourney must begin with the first step. The likelihoodof reaching one’s destination is much enhanced if thefirst step and the subsequent steps take the traveler inthe correct direction. Wandering about here and therewithout a clear sense of purpose or directionconsumes time, energy, and resources. It alsodiminishes the possibility that one will ever arrive.One can be much more prepared for a journey bycollecting the necessary maps, studying alternativeroutes, and making informed estimates of the time,costs, and hazards one is likely to confront.
It is no less true that front-end planning is necessaryto designing and implementing an evaluationsuccessfully. Systematic attention to evaluationdesign is a safeguard against using time and resourcesineffectively. It is also a safeguard against performingan evaluation of poor quality and limited usefulness.
The goal of the evaluation design process is, ofcourse, to produce a design for a particularevaluation. But what exactly is an evaluation design?Because there may be different views about theanswer to this question, it is well to state what isunderstood in this paper. Evaluation pertains to thesystematic examination of events or conditions thathave (or are presumed to have) occurred at an earliertime or that are unfolding as the evaluation takesplace. But to be examined, these events or conditionsmust exist, must be describable, must have occurredor be occurring. Evaluation is, thus, retrospective inthat the emphasis is on what has been or is beingobserved, not on what is likely to happen (as inforecasting).1 The designs and the design processoutlined in this paper are focused on the observedperformance of completed or ongoing programs.
1Despite the retrospective character of evaluation, programevaluation findings can often be used as a sound basis forcalculating future costs or projecting the likely effects of a program.
GAO/PEMD-10.1.4 Desiging EvaluationsPage 6

Chapter 1
Why Spend Time on Design?
To further characterize evaluation design, it is usefulto look closely at the questions we pose and theanswers we seek. Evaluation questions can be dividedinto three kinds: descriptive questions, normativequestions, and impact (cause-and-effect) questions.The answers to descriptive questions provide, as thename implies, descriptive information about specificconditions or events—the number of people whoreceived Medicaid benefits in 1990, the constructioncost of a nuclear power plant, and so on. The answersto normative questions (which, unlike descriptivequestions, focus on what should be rather than whatis) compare an observed outcome to an expectedlevel of performance. An example is the comparisonbetween airline safety violations and the standard thathas been set for safety. The answers to impact(cause-and-effect) questions help reveal whetherobserved conditions or events can be attributed toprogram operations. For example, if we observechanges in the weight of newborns, what part of thosechanges is the effect of a federal nutrition program?In sum, the design ideas presented here are aimed atproducing answers to descriptive, normative, andimpact (cause-and-effect) questions.
Given these questions, what elements of a designshould be specified before information is collected?The most important elements can be listed as
• kind of information to be acquired,• sources of information (for example, types of
respondents),• methods to be used for sampling sources (for
example, random sampling),• methods of collecting information (for example,
structured interviews and self-administeredquestionnaires),
• timing and frequency of information collection,
GAO/PEMD-10.1.4 Desiging EvaluationsPage 7

Chapter 1
Why Spend Time on Design?
• basis for comparing outcomes with and without aprogram (for impact or cause-and-effect questions),and
• analysis plan.
They form the basis on which a design is constructed.As will be seen, the choices that are made for eachelement are major determinants of the quality of theinformation that can be acquired, the strength of theconclusion that can be drawn, and the evaluation’scost, timeliness, and usefulness.
Before each component in this design process isidentified and discussed, it would be well to addresssystematically why it is important to take the time tobe concerned with evaluation design. First, andprobably most importantly, careful, sound designenhances quality. But it is also likely to contain costsand ensure the timeliness of the findings, especiallywhen the evaluation questions are difficult andcomplex. Further, good design increases the strengthand specificity of findings and recommendations,decreases vulnerability to methodological criticism,and improves customer satisfaction.
In thinking about these reasons for taking time todesign an evaluation carefully, one may well find thatguaranteeing evaluation quality is the preeminentconcern, the critical dimension of the design effort.Stated differently, the most important outcome of acareful, sound design should be that the overallquality of the evaluation is enhanced in a number ofspecific ways.
An evaluation design can usually be recognized by theway it has
1. defined and posed the evaluation questions forstudy,
GAO/PEMD-10.1.4 Desiging EvaluationsPage 8

Chapter 1
Why Spend Time on Design?
2. developed the methodological strategies foranswering these questions,
3. formulated a data collection plan that anticipatesand addresses the problems and obstacles that arelikely to be encountered, and
4. detailed an analysis plan that will ensure that thequestions that are posed are answered with theappropriate data in the best possible fashion.
A well-designed evaluation will be more powerful andgermane than one in which attention has not beenpaid to laying out the methodological strategy andplanning the data collection and analysis carefully. Itwill also develop a stronger foundation and be moreconvincing in its conclusions and recommendations.Implementation also will be strengthened, becauseonce the design has been established, less time will belost in having to make ad hoc decisions about what todo next. Good front-end planning can substantiallyreduce the many uncertainties of an evaluation. Ithelps provide a clear sense of direction and purposeto the effort.
Similarly, good front-end planning contains evaluationcosts by preventing (1) “down time” from makingsporadic and episodic decisions on what to do next,(2) waste of staff time on the collection and analysisof data that are irrelevant to the question,(3) duplication of data collection, and (4) unplanneddata analysis in a search for relevant findings. It mustbe recognized that careful attention to design doestake time and does necessitate front-end costs.However, the investment can save time and costslater in the evaluation, and this is especially true forbig, complex projects. There is, of course, noassurance that careful work will require lessexpenditure of resources than ill-defined studies.
GAO/PEMD-10.1.4 Desiging EvaluationsPage 9

Chapter 1
Why Spend Time on Design?
Attention to the design process also makes for highquality by focusing on the usefulness of the product tothe intended recipient. If attention is paid to the needsof the user in terms of information orrecommendations, the design process cansystematically address these needs and make surethat they are integrated into the project. In this way,the relevance of an evaluation can be strengthened bytying it specifically to the concerns of its user. Inaddition, a concern with relevance is likely toincrease the user’s satisfaction with the product.
A sound design can help ensure timeliness. A tightand logical design can reduce the time thataccumulates on a project because of excessive orunnecessary data collection, the lack of a clear dataanalysis plan, or the constant “cooking” of the data, aswhen the omission of a sound methodologicalstrategy has made it impossible to answer theevaluation questions directly. The timeliness offindings with respect to the needs of the customer canmake or break a technically adequate approach. It isnot enough that a study be conducted with a highdegree of technical precision to argue for its quality;the study must also be conducted in time to allow thefindings to be of service to the user.
In summary, to spend the time to develop a sounddesign is to invest time in building high quality intothe effort. Devoting attention to evaluation designmeans that factors that will affect the quality of theresults can be addressed. Not allowing the time that isnecessary for this vital stage of the project is, in theend, self-defeating. It can be a crippling, if not a fatal,blow to any evaluation that skips quickly through thisstep. The pressure of wanting to get into the field assoon as possible has to be held in check whilesystematic planning takes place. The design is whatguides the data collection and analysis.
GAO/PEMD-10.1.4 Desiging EvaluationsPage 10

Chapter 1
Why Spend Time on Design?
Having looked at why it is important to designevaluations well, we can turn our attention to thevarious components and processes that are inherentin evaluation design. Our discussion is in five majorparts: asking the right question, adequatelyconsidering the constraints, assessing the design,settling on a strategy that considers strengths andweaknesses, and rigorously monitoring the design andincorporating it into the management strategies of thepersons who are responsible for the evaluation.
GAO/PEMD-10.1.4 Desiging EvaluationsPage 11

Chapter 2
The Design Process
Asking the RightQuestion
The first and surely the most fundamental aspect ofevery design effort is to ensure that the questions thatare posed for the evaluation are the correct ones.1
Posing a question incorrectly is an excellent way tolead a study in the wrong direction. It is obvious thatone must ask the right question, but deciding what isexactly the “right question” is not necessarily easy. Infact, reaching agreement with the sponsors, users,program operators, and others on the contents andimplications of a question can be difficult andchallenging. Among the several reasons for thestrenuousness of the task is that the formulation of aproblem has preeminent importance in the remainingphases of the evaluation. How a problem is stated hasimplications for the kinds of data to be collected, thesources of data, the analyses that will be necessary intrying to answer the question, and the conclusionsthat will be drawn.
Consider a brief example: juvenile delinquency andthe question of what motivates young people tocommit delinquent acts. The question aboutmotivation could be posed in a variety of ways. Onecould ask about the personality traits of youngpersons and whether particular traits are associatedwith differences in who does or does not commitcrimes. Asking the question this way entails data, datasources, and program initiatives that are differentfrom those that are required in examining, forexample, the social conditions of young persons;here, the focus might be on family life, schooling, peergroups, employment opportunities, or the like. Tostretch the example further, each of these two waysof posing the question about what motivates juvenilesto commit crime would lead to evaluations quitedifferent from either asking whether juveniles commitcrimes because of a temporary hormonal imbalance
1Often studies have more than one key question or a cluster ofquestions. Every question has to be given the same seriousattention.
GAO/PEMD-10.1.4 Desiging EvaluationsPage 12

Chapter 2
The Design Process
or asking whether a youth culture uses crime as a“rite of passage” into adulthood.
Posing a question in four quite different ways showsclearly how the way in which a problem is stated hasimplications for an evaluation design. How an issue isdefined influences directly how variables ordimensions are to be selected and examined and howthe analysis will test the strength of the relationshipbetween a cause and its expected consequence.
Question formulation is important also in that theconcerns of the customer must be attended to. How aquestion is framed has to take the information needsand spheres of influence of the intended audienceinto consideration. Does the customer need to knowthe general effectiveness of a nationwide program? Oris the concern limited, for example, to individualproblem sites and public attitudes to the program inthose sites? The difference of type in these twoquestions is extremely important for evaluationdesign, and attention to the difference allows theevaluator to help make the job useful to its sponsor.
Clarifying the Issue Working toward the formulation of the right questionhas two phases (Cronbach, 1982, pp. 210-44). In thefirst phase, the largest number and widest range ofpotential questions (and methods by which to addressthese questions) ought to be considered, even if theydo not seem especially plausible or defensible. Forexample, congressional staff often begin with a verybroad concern, so that it is necessary to try out anumber of less sweeping questions in order todetermine the priorities of the staff and to developresearchable questions. Thus, it is often useful for theevaluator and requester to work through in detailwhich questions can be answered easily, which aremore difficult, expensive, and time-consuming, and
GAO/PEMD-10.1.4 Desiging EvaluationsPage 13

Chapter 2
The Design Process
which cannot be answered at all and why. Theevaluator is in a much stronger position to defend thefinal phrasing of a question if it is apparent that anumber of alternatives have been systematicallyconsidered and rejected.
During this phase, the evaluator has several importantaids for developing a range of questions. One is toimagine the various stages of the program—its goals,objectives, start-up procedures, implementationprocesses, anticipated outcomes—and to ask all thequestions that could be asked about each stage. Forexample, in considering program objectives, theevaluator could ask questions about the clarity andprecision of those objectives, the criteria that havebeen developed for testing whether the objectiveshave been met, the relationship between theobjectives and program goals, and whether theobjectives have been clearly transmitted to andunderstood by the persons who are responsible forthe program’s implementation.
Another aid is to focus on the nature of the program’sobjectives—on whether they are short term or longterm, intense or weak, continuous or sporadic,behavioral or attitudinal, and so on. Yet another aid isto think of questions that would describe the programas it exists or that would judge the program against anexisting norm or that would point out the outcomesthat are a direct result of the program.
Each of these three kinds of question—descriptive,normative, and impact(cause-and-effect)—necessitates a different designconsideration. What is important for the evaluator isto separate a potential question into one of the threetypes and then to consider the implications of eachtype of question for the development of a design. Tochoose a set of evaluation questions is to choose a
GAO/PEMD-10.1.4 Desiging EvaluationsPage 14

Chapter 2
The Design Process
certain cluster of design options for answering them.Design options are discussed in chapter 3.
The second phase of formulating the right question isto match possible questions against the resources thatwill be available for the project. We discuss this in thefollowing section.
Deciding WhichQuestions AreFeasible to Answer
It is one thing to agree on which questions are mostimportant and have highest priority. It is quite anotherto know whether the questions are answerable and, ifso, at what costs in money, staff, and time. In thesecond phase of formulating the right question, theevaluator ought not to assume that a designdeveloped to answer questions of highest priority canbe implemented within the given constraints.
For example, the evaluator might determine that itwould be very informative to collect data over severalyears, but the requirements of money, staff, and timemight necessitate a less comprehensive or lesscomplex design that could answer fewer questions,less conclusively, within given constraints. Analternative design that might be appropriate couldfocus on what a particular group of peopleremembers about a program or service during theyears in which they were involved with it. Here, inplace of the long-term, objective monitoring of eventsduring years to come, the evaluator would substitutea look backward that is dependent on the memoryand attitudes of the people involved with the programin the past.
Another less comprehensive alternative, of lowerquality, would be to inquire of the group at only twofuture points in time rather than to make numerousinquiries over several points in time. In other words,the design option can influence the technical quality
GAO/PEMD-10.1.4 Desiging EvaluationsPage 15

Chapter 2
The Design Process
of the evidence and, hence, the expectations aboutwhat the evaluation can accomplish.
Meeting anInformation NeedReasonably
A large-scale and expensive evaluation is not likely toseem reasonable for a program that is small, diffuse,and short in duration. Similarly, a study that willallow national generalizability will probably requireeffort and resources quite different from those of anarrower study. To make national generalizationsfrom a single case study, for example, is difficult, ifnot impossible. That is, whether or not an informationneed can be reasonably met has to do with howconclusive the answer to the question beinginvestigated has to be. Questions that call for a highdegree of conclusiveness in the answers will, ofnecessity, require stronger designs than questions forwhich brief descriptions or quick assessments areadequate answers. For example, to ask for adescription of the children who receive services froman education program for migrants is quite differentfrom asking whether those services are affecting theirattendance in school, academic achievement, andproficiency in English. The first question could beanswered descriptively with the collection andtabulation of demographic data, but the second is animpact (cause-and-effect) question that demandsknowledge about, first, what is happening to similarchildren who are not in the program; second, how thechildren who are in the program were performingbefore they joined it; and third, whether otherpossible causes for how the children are performingthat have nothing to do with the program can bejustifiably excluded.
The “Strength VersusWeakness” Issue
Strong evaluations employ methods of analysis thatare appropriate to the question, support the answerwith evidence, document the assumptions,
GAO/PEMD-10.1.4 Desiging EvaluationsPage 16

Chapter 2
The Design Process
procedures, and modes of analysis, and rule out thecompeting evidence. Strong studies pose questionsclearly, address them appropriately, and drawinferences commensurate with the power of thedesign and the availability, validity, and reliability ofthe data. Strength should not be equated withcomplexity. Nor should strength be equated with thedegree of statistical manipulation of data.
Neither infatuation with complexity nor statisticalincantation makes an evaluation stronger.
The strength of an evaluation is not defined by aparticular method. Longitudinal, experimental,quasi-experimental, before-and-after, and case studyevaluations can be either strong or weak. A casestudy design will always be weaker than a samplesurvey design in terms of its external validity. Asimple before-and-after design without controls willalways present problems of internal validity. Yetsample surveys and control groups can be impossiblefor a variety of reasons. That is, the strength of anevaluation has to be judged within the context of thequestion, the time and cost constraints, the design,the technical adequacy of the data collection andanalysis, and the presentation of the findings. Astrong study is technically adequate and useful—inshort, it is high in quality (Chelimsky, 1983).
Evaluators have considered the concept of strength atsome length. Some argue that strong evaluationsemploy methods that allow the evaluator to makecausal, as opposed to correlational, statements abouta policy or program. It is argued that saying thatprogram intervention X caused outcome Y among theprogram’s participants is a stronger statement thansaying that X and Y are associated but it is not clearthat X caused Y. In this argument, the notion ofstrength is related to the judgment that causal
GAO/PEMD-10.1.4 Desiging EvaluationsPage 17

Chapter 2
The Design Process
statements are more powerful than correlationalstatements. Another argument is that the strength of astudy or a method can be determined by comparingwhat was done with what was possible.
Pilot Versus FullStudy
Formulating the right question is a necessary but nota sufficient condition for success. There is still thematter of translating the design and analyticassumptions into practice—into pragmatic decisionsand patterns of implementation that will allow theevaluator to find the stipulated data and analyze them.In short, the evaluator must ask whether the designmatches the area of inquiry. Answering this questionis a “reality check” on whether the assumptions aboutthe kinds and availability of data hold true, onwhether the legislation and regulations bearresemblance to what has been implemented, and onwhether the proposed analysis strategies will answerthe question conclusively.
At this stage of an evaluation, the entire endeavor isstill quite vulnerable and tentative. What if the dataare not available? What if the program is nothing likeits description in its documents or the grantapplication? What if the methodology will not allowfor sufficiently conclusive answers to the evaluationquestions? Any one of these situations could call anentire study into question.
That the condition of an evaluation can be precariousin these ways argues for a limited exploration of thequestion before a full-scale, perhaps expensive,evaluation is undertaken. This limited exploration isreferred to as a “pilot phase,” when the initialassumptions about the program, data, and evaluationmethodology can be tested in the field. Testing thework at one or more sites allows the evaluator to
GAO/PEMD-10.1.4 Desiging EvaluationsPage 18

Chapter 2
The Design Process
confirm that data are available, what their form willbe, and by what means they can be gathered.
Site selection for the pilot phase is important. Ratherthan choosing a site where the pilot could be easilyconducted, it is critical to choose a site thatrepresents an average, if not the worst, case.Choosing a noncontroversial site may hide theresistance an evaluator is likely to experience at othersites.
The pilot phase allows for a check on programoperations and delivery of services in order toascertain whether what is assumed to exist does.Finding that it does not may suggest a need to refocusthe question to ask why the program that has beenimplemented is so different from what was proposed.This phase allows also for limited data collection,which provides an opportunity to assess whether theanalysis methodology will be appropriate and whatalternative interpretations of the data may bepossible.
The study’s pilot phase is very useful. It is animportant opportunity to correct aspects of the designthat can determine the success or the failure of theoverall effort. To undertake a large-scale, full-blownstudy without this phase is a high-risk proposition. Toallocate staff and financial resources and engage thetime and cooperation of the persons in the programsto be studied without making as certain as possiblethat what is proposed will work is to court seriousproblems. It may well be that conducting a pilot willconfirm what was originally designed, but to moveahead with this confirmation is preferable to merelyassuming that everything will fall successfully intoplace.
GAO/PEMD-10.1.4 Desiging EvaluationsPage 19

Chapter 2
The Design Process
To be sure, there are instances when a pilot is notpossible: time pressures may not allow it, resourcesmay be so scarce that there is but one opportunity forfield work, or the availability of staff may beconstrained. Yet the evaluator ought to recognize thatnot performing a pilot test increases the likelihood ofproblems and difficulties, even to the degree that thestudy cannot be completed successfully. Theevaluator must give high priority to the pilot phasewhen considering time, resources, and staff.
A frequently posed question is how much pilot workis necessary before the large-scale evaluation isundertaken. There is no “cookbook” answer. The pilotis an evaluation tool that increases the odds that theeffort will be high in quality. By itself, the pilot cannotprovide a fail-safe guarantee. It can suggestalternative data collection and analysis strategies. Itcan also stimulate further thinking about andclarification of the evaluation. The pilot is a strategyfor reducing uncertainty. That uncertainty cannot bereduced to zero does not detract from the pilot’sutility.
Perhaps the best answer to how extensive a pilotought to be is a second question: How muchuncertainty is the evaluator willing to tolerate as theevaluation begins? Only the evaluator can make thetrade-off between the scope and resources of the pilotand problems on the project.
Considering theEvaluation’sConstraints
Time is a constraint. It shapes the scope of theevaluation question and the range of activities thatcan be undertaken to answer it. It demands trade-offsand establishes boundaries to what can beaccomplished. It continually forces the evaluator tothink in terms of what can be done versus what mightbe desirable. Because time is finite (and there is never
GAO/PEMD-10.1.4 Desiging EvaluationsPage 20

Chapter 2
The Design Process
enough of it), the evaluator has to plan the study in“real time” with its inevitable constraints on whatquestion can be posed, what data can be collected,and what analysis can be undertaken.
A rule of thumb is that the time for a study and thescope of the question being addressed ought to bedirectly related. Tightly structured and narrowinvestigations are more appropriate when time isshort. Any increase in the scope of a study should beaccompanied by a commensurate increase in theamount of time that is available for it. The failure torecognize and plan for this link between time andscope is the Achilles heel of evaluation.
Linking scope and time in the study design isimportant because the scope is determined by thedifficulty of the evaluation, the importance of thesubject, and the needs of the user, and these are alsodeterminants of time. Though it may be self-evident tosay so, difficult evaluations, important evaluations,and evaluations in which there is a great deal ofinterest have different demands with respect to timethan other evaluations. No project is “too long” or“too short” within this context.
The need of the study’s audience as a time constraintmerits additional comment. Evaluations are requestedand conducted because someone perceives a need forinformation. Producing that information without asensitivity to the user’s timetable diminishes itsusefulness. For example, a report to the Congressmay answer the questions correctly but will be oflittle or no use if it is delivered after the legislativehearings for which it is needed or after thepreparation of a new budget for the program.
Cost is a constraint. The financial resources availablefor conducting a study partly determine the limits of
GAO/PEMD-10.1.4 Desiging EvaluationsPage 21

Chapter 2
The Design Process
the study. Having very few resources means that theevaluator will have to consider tight limitations on thequestions, the modes of data collection, the numbersof sites and respondents, and the extent and eleganceof the analysis. As the resources expand, theconstraints on the study become less confining.Having more funds might mean, for example, eitherlonger time in the field or the opportunity to havemultiple interviews with respondents or to visit moresites or choose larger samples for sites. Each of theseitems has a price tag. What the evaluator is able topurchase depends on what funds are available.
It should be stressed that regardless of what funds areavailable, design alternatives should be considered.Cost is simply an important constraint within whichthe design work has to proceed. If only a stipulatedsum is available, the evaluator has to determine whatcan be done with that sum in order to provideinformation that is relevant to the questions. Thesame resources might allow three or four quitedistinct approaches to an evaluation. The challenge isto consider the strengths and weaknesses of thevarious approaches. Like the constraint of time, costdoes not determine the design. It helps establish therange of options that can be realistically examined.Even when resources can be expanded, cost is still aconstraint. However, the design problem thenbecomes one of cost-effectiveness, or getting valuefor the dollar, rather than one of what can be donewithin a stipulated sum.
One other point: the quality of an evaluation does notdepend on its cost. A $500,000 evaluation is notnecessarily five times more worthy than a $100,000evaluation. An expensive study poorly designed andexecuted is, in the end, worth less than one that costsless but addresses a significant question, is tightlyreasoned, and is carefully executed. A study should
GAO/PEMD-10.1.4 Desiging EvaluationsPage 22

Chapter 2
The Design Process
be costly only when the questions and the means ofanswering them necessitate a large expenditure. Aswith the constraint of time, there is a directcorrelation between the scope of a study and themoney available for conducting it.
Staff expertise is a constraint. The design for anevaluation ought not to be more intricate or complexthan what the staff can successfully execute.Developing highly sophisticated computersimulations or econometric models as part of anevaluation when the skills for using them are notavailable to the evaluation team is simply a grossmismatch of resources. The skills of the staff have tobe taken into account when the design is developed.
It is perhaps too negative to consider staff expertiseas only a constraint. In the alternative view, thedesign accounts for the range of available staffexpertise and plans a study that uses that expertise tothe maximum. It is just as much a mismatch to plan adesign that is pedantic, low in power, and completelyunsophisticated when the staff are capable of muchmore and the questions demand more as it is to createa design that is too complex for the expertiseavailable. In either instance, of course, a design isdetermined not by expertise but by the nature of thequestions.
A realistic understanding of the skills of the staff canplay an important role in the kinds of design optionsthat can be considered. An option that requires skillsthat the staff do not have will fail, no matter howappropriate the option may be to the evaluationquestions. A staff with a high degree of technicaltraining in a variety of evaluation strategies is atremendous asset and greatly expands the options.
GAO/PEMD-10.1.4 Desiging EvaluationsPage 23

Chapter 2
The Design Process
Some designs demand a level of expertise that is notavailable. When this happens, consultants can bebrought into the study or the staff can be given shortintensive courses or complex and difficult portions ofthe design can be isolated and performed undercontract by evaluators specializing in the appropriatetype of study. In other words, the stress is onconsidering the options available. Preference shouldbe given to building the capability of current staff.When this cannot be done, or time and cost do notallow it, expertise can be procured from outside inorder to fulfill the demands of the design.
Location and facilities are secondary constraints incomparison to the others we have discussed, but theydo impinge on the design process and influence theoptions. Location has to be considered from severalaspects. One is the location of the evaluator vis-a-viswhere the evaluation is to be conducted. Location isless critical for a national study, since most areas canbe reached by air within a few hours, but it increasesin importance if the study examines only a fewindividual projects. The accessibility and continuity ofdata collection may be jeopardized if the evaluator ison the east coast and the sites are in the South, in theMidwest, and on the west coast. A situation such asthis may have to incorporate local persons asmembers of the evaluation team and may increase theutility of a mail questionnaire or telephone interviewscompared to face-to-face interviews.
Another aspect of location has to do with the socialand cultural mores of the area where the evaluation isto be conducted. For example, to gain valid andinsightful data on attitudes toward rural mental healthclinics, it may be wise not to send interviewers fromurban areas. Good interviewing necessitates empathybetween the persons involved, and it may be hard to
GAO/PEMD-10.1.4 Desiging EvaluationsPage 24

Chapter 2
The Design Process
generate between an interviewer and a respondentwhose backgrounds are very different.
A third aspect of location is the stability of thepopulation being studied. A neighborhood whereresidence is transient may necessitate a differentstrategy from a neighborhood where most peoplehave lived in the same house for 40 years and have nointention of moving.
Finally, the evaluator must consider whether a trip toa site is justified at all. For example, if it costs $3,000to travel to a remote town to ascertain whether aschool there is using a $1,500-computer provided by aU.S. Department of Education grant, the choice of notgoing is defensible.
The constraint of facilities on the design options alsohas more than one aspect. One has to do with datacollection and data processing. For example, if thestudy involves entering large aggregates of data into acomputer, the equipment to do so must be available,or the money must be available for contracting thework. Similarly, if the design calls for data analysis atcomputer terminals with phone connections to themain computer, the equipment is a must. The absenceof such facilities limits both the kind and the extent ofthe data one can collect.
Another aspect is the need for periodic access tofacilities that are not under the auspices of the projector program being studied. For example, to interviewwelfare clients in a welfare office about the treatmentand service they are receiving there may be to riskhighly biased answers. How candid can a client be,knowing that the caseworker who has made decisionson food, clothing, and rental allowances for theclient’s family is in the next room? “Neutral turf”cannot guarantee candid answers, but it may lessen
GAO/PEMD-10.1.4 Desiging EvaluationsPage 25

Chapter 2
The Design Process
anxiety and it can contribute to the authenticity of theevaluator’s promise of anonymity and confidentiality.The example applies equally to interviews withpersons who hold positions of power and influence.
Assessing theDesign
Once a design has been selected, the impetus is tomove full steam ahead into the execution of the study.However, the evaluator must fight this impulse andtake time to look back on what has beenaccomplished, on the design that has finally beenselected, and on what the implications are for thesubsequent phases of the study.
The end of the design phase is an importantmilestone. It is here that the evaluator must have aclear understanding of what has been chosen, whathas been omitted, what strengths and weaknesseshave been embedded in the design, what the needs ofthe customer are, how usefully the design is likely tomeet those needs, and whether the constraints oftime, cost, staff, location, and facilities have beenfully and adequately addressed.
GAO’s Program Evaluation and Methodology Divisionhas developed and uses a job review system thatincludes a detailed and systematic assessment of thedesign phase. This system helps establish the basis formoving forward into implementation. It may be usefulto other evaluators in judging their own designs. Fivekey questions figure prominently in the reviewsystem.
1. How appropriate is the design for answering thequestions posed for the study? The evaluator ought tobe able to match the design componentssystematically to the study questions in order todemonstrate that all key questions are beingaddressed and that methods are available for doing
GAO/PEMD-10.1.4 Desiging EvaluationsPage 26

Chapter 2
The Design Process
so. Even though this entails a judgment, the evaluatorshould assess the match between the strength of thedesign and the information necessary to answer thestudy questions. If the design is either too weak or toostrong for the questions, serious consideration has tobe given to whether the design ought to beimplemented or whether the questions ought to bemodified. This judgment about the appropriateness ofthe design is critical, because if the study begins withan inappropriate design, it is difficult to compensatelater for the basic incongruity.
2. How adequate is the design for answering thequestions posed for the study? The emphasis here ison the completeness of the design, the expectedprecision of the answers, the tightness of the logic,the thought given to the limitations of the design, andthe implications for the analysis of the data. First, theevaluator should have reviewed the literature andshould give evidence of knowing what wasundertaken previously in the area from bothsubstantive and methodological viewpoints. That is,the evaluator should be aware of not only what kindsof questions have been asked and answered in thepast but also what designs, measures, and dataanalysis strategies have been used. A careful study ofthe literature prevents “rediscovering” or duplicatingexisting work. Thus, in judging the adequacy of thedesign, the evaluator must link it to previousevaluations.
Second, the design should explicitly state theevaluation questions that determined the selection ofthe design. Knowing the evaluation questions thatwere thought germane and those that were not givesthe reader a basis for assessing the strength of thedesign. Since every evaluation design is constrainedby a number of factors, recognizing them andcandidly describing their effect provides important
GAO/PEMD-10.1.4 Desiging EvaluationsPage 27

Chapter 2
The Design Process
clues to whether the design can adequately answerthe study questions.
Third, there is a need to be explicit about thelimitations of the study. How conclusive is the studylikely to be, given the design? How detailed are thedata collection and data analysis plans? Whattrade-offs were made in developing these plans? Theanswers to these questions provide data on thedesign’s adequacy.
3. How feasible is the execution of the design withinthe required time and proposed resources? Adequateand appropriate designs may not be feasible if theyignore time and cost—that is, if they are not practical.The completeness and elegance of a design can bequickly relegated to secondary importance if thedesign presents major obstacles in the execution.Further, asking about feasibility puts an importantcheck on studies that simply cannot be done. Forexample, discovering that a particular evaluation witha true experimental design cannot be executed mayprevent proceeding with a project that will fail.
4. How appropriate is the design with regard to theuser’s needs for information, conclusiveness, andtimeliness? What kind of information is needed? Howconclusive does it have to be? When does it have to bedelivered? Being able to determine how well thedesign responds to the user’s needs requires theevaluator and the user to be in close agreement andcontinuous consultation. In the absence ofcooperation, the evaluator is left to presume what willbe of relevance—and presumption is a poor substitutefor knowledge. Since evaluations are undertakenbecause of a need for information, the degree towhich they provide useful information is aninescapable and critical design consideration.
GAO/PEMD-10.1.4 Desiging EvaluationsPage 28

Chapter 2
The Design Process
5. How adequate were the negotiations with the userregarding the relationship between the informationneed and the study design? It is one thing to knowwhat the user needs and when it is needed. It is quiteanother to agree on how the questions ought to beframed so that the information can be gathered. If theuser has causal questions in mind while the evaluatorbelieves that only a descriptive study is feasible, andif the gap between these two perspectives is notresolved, the user’s satisfaction with the final study islikely to be quite low and the ensuing report may notbe used.
Further, the consideration of time is relevant to thesize, complexity, and completeness of the evaluationthat is finally undertaken. If the user is integrallyinvolved in determining the project’s timetables andproducts, the evaluator will know how to decidewhether what is proposed can be accomplished. Toignore, or only guess at, rather than negotiate andagree on a timetable would be to risk the relevance ofthe whole effort. The negotiations with the usershould be carefully scrutinized at the end of thedesign phase to make sure that there is commonunderstanding and agreement on what is beingproposed for the remaining phases of the evaluation.
GAO/PEMD-10.1.4 Desiging EvaluationsPage 29

Chapter 3
Types of Design
In chapter 2, we examined the factors to consider inarriving at an evaluation design. Here we take asystematic look at four major evaluation strategiesand several types of design that derive from them.(See table 3.1.) The discussion is brief andnontechnical. More details can be found in thereferences given under the heading “Where to Lookfor More Information” for each design type.
Table 3.1: EvaluationStrategies and Types ofDesign
Strategy Design
Sample survey Cross-sectionalPanelCriteria-referenced
Case study SingleMultipleCriteria-referenced
Field experiment True experimentNonequivalent comparison groupBefore-and-after (including timeseries)
Use of availabledata
Secondary data analysisEvaluation synthesis
Evaluation strategies and designs can be classified ina variety of ways, each with some advantages anddisadvantages in communicating a logical picture ofthe different forms of evaluation inquiry. We take theword “strategy,” as the broader of the two concepts,to connote a general approach to finding answers toevaluative questions. A strategy embraces severaltypes of design that have certain features in common.
Our classification scheme is similar to schemes usedby Runkel and McGrath (1972), Judd and Kidder(1986), and Black and Champion (1976), but it isadapted to the work of the U.S. General AccountingOffice. Sample surveys, case studies, fieldexperiments, and the use of available data are useful
GAO/PEMD-10.1.4 Desiging EvaluationsPage 30

Chapter 3
Types of Design
strategies because they can be readily linked to thetypes of evaluation questions that GAO is asked toanswer, and they explicitly accommodate evaluationstrategies that are prominent in GAO’s history.
For simplicity, we speak only of program evaluation,but we imply the evaluation of policies also.
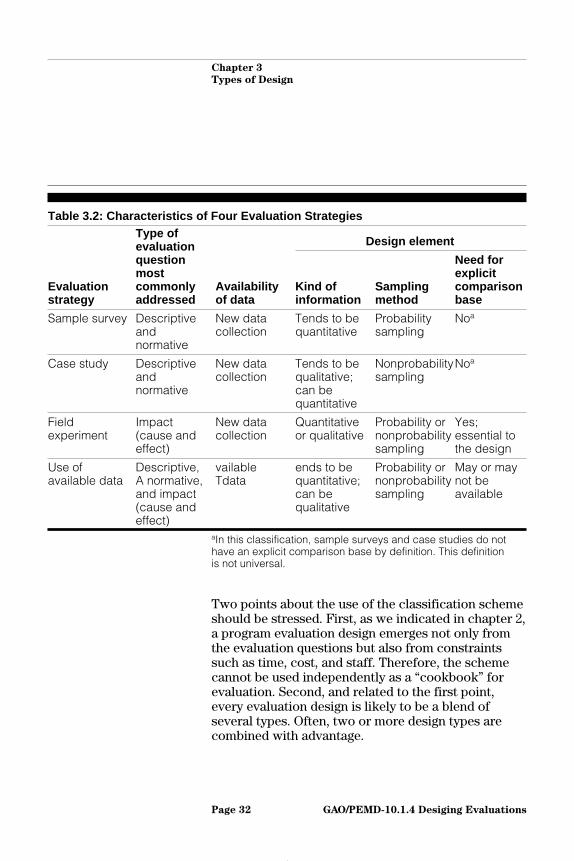
Some of the design elements we identified in chapter1—in particular, kinds of information, samplingmethods, and the comparison base—help distinguishthe evaluation strategies. Table 3.2 shows therelationship between these three design elements andthe four evaluation strategies, the types of questions,and the availability of data. In the rest of this chapter,we discuss this relationship in detail. Other designelements—information sources, informationcollection methods, the timing and frequency ofinformation collection, and information analysisplans—are essential in specifying a design but are lessuseful in making distinctions among the majorevaluation strategies.
GAO/PEMD-10.1.4 Desiging EvaluationsPage 31
Chapter 3
Types of Design
Table 3.2: Characteristics of Four Evaluation Strategies
Design element
Evaluationstrategy
Type ofevaluationquestionmostcommonlyaddressed
Availabilityof data
Kind ofinformation
Samplingmethod
Need forexplicitcomparisonbase
Sample survey Descriptiveandnormative
New datacollection
Tends to bequantitative
Probabilitysampling
Noa
Case study Descriptiveandnormative
New datacollection
Tends to bequalitative;can bequantitative
Nonprobabilitysampling
Noa
Fieldexperiment
Impact(cause andeffect)
New datacollection
Quantitativeor qualitative
Probability ornonprobabilitysampling
Yes;essential tothe design
Use ofavailable data
Descriptive,A normative,and impact(cause andeffect)
vailableTdata
ends to bequantitative;can bequalitative
Probability ornonprobabilitysampling
May or maynot beavailable
aIn this classification, sample surveys and case studies do nothave an explicit comparison base by definition. This definitionis not universal.
Two points about the use of the classification schemeshould be stressed. First, as we indicated in chapter 2,a program evaluation design emerges not only fromthe evaluation questions but also from constraintssuch as time, cost, and staff. Therefore, the schemecannot be used independently as a “cookbook” forevaluation. Second, and related to the first point,every evaluation design is likely to be a blend ofseveral types. Often, two or more design types arecombined with advantage.
GAO/PEMD-10.1.4 Desiging EvaluationsPage 32

Chapter 3
Types of Design
Each of this chapter’s sections on the four evaluationstrategies is broken down into subsections on specificdesign types that may be applicable in GAO. For eachtype of design, we give several kinds of information: adescription of the design, appropriate applications,planning and implementation considerations, andsources of more information. The last section of thechapter makes further connections betweenevaluation questions and the design types.
The SampleSurvey
In a sample survey, data are collected from a sampleof a population to determine the incidence,distribution, and interrelation of naturally occurringevents and conditions.1 The overriding concern in thesample survey strategy is to collect information insuch a way that conclusions can be drawn aboutelements of the population that are not in the sampleas well as about elements that are in the sample. Acharacteristic of the strategy is the use of probabilitysampling, which permits a generalization from thefindings about the sample to the population ofinterest. In probability sampling, each unit in thepopulation has a known, nonzero probability of beingselected for the sample by chance. The conclusionsfrom this kind of sample can be projected to thepopulation, within statistical limits of error.
Because of the aim to aggregate and generalize fromthe survey results, great importance is attached tocollecting uniform data from every unit in the sample.Consequently, survey information is usually acquiredthrough structured interviews or self-administeredquestionnaires. Most of the information is collected inclose-ended form, which means that the respondent
1The special case in which the sample equals the population iscalled a “census.” The word “survey” is sometimes used to describea structured method of data collection without the goal of drawingconclusions about what has not been observed. We do not use theterm in this narrow sense.
GAO/PEMD-10.1.4 Desiging EvaluationsPage 33

Chapter 3
Types of Design
chooses from among responses offered in thequestionnaire or by the interviewer. Designing aconsistent set of responses into the data collectionprocess helps establish the uniformity of data acrossunits in the sample.2 The three main ways of obtainingthe data are by mail, phone, and face-to-faceinterviews.
The sample’s units are frequently persons but may beorganizations such as schools, businesses, andgovernment agencies. A crucial matter in survey workis the quality of the “sampling frame” or list of unitsfrom which the sample will be drawn. Since the frameis the operational manifestation of the population, itdoes much to determine the generalizability andprecision of the survey results.
Sample surveys have been traditionally used todescribe events or conditions under investigation. Forexample, national opinion surveys report the opinionsof various segments of the population about politicalcandidates or current issues. A survey may showconditions such as the extent to which persons whosupport one side of an issue also tend to backcandidates who advocate that side of the issue. In theinterpretation of such relationships, there is usuallyno attempt to impute causality.
However, some analysts attempt to go beyond thepurely descriptive or normative interpretations ofsample surveys and draw causal inferences aboutrelationships between the events or conditions beingreported. The conclusions are frequently disputed,but there are circumstances in which causalinferences from sample survey data are warranted.Special data analysis methods are used to drawqualified causal interpretations but even these
2Open-ended questions may be used in sample surveys, but if theresults are to be aggregated across the sample, responses must becoded—placed into categories—after the data are collected.
GAO/PEMD-10.1.4 Desiging EvaluationsPage 34

Chapter 3
Types of Design
procedures may not silence methodological criticism.In the rest of this section, we describe the designs forcross-sectional, panel, and critera-referenced samplesurveys.
The Cross-SectionalSurvey
A cross-sectional design, in which measurements aremade at a single point in time, is the simplest form ofsample survey.
EXAMPLE: In 1971, a survey was made of 3,880families (11,619 persons) to provide descriptiveinformation on the use of and expenditures for healthservices. A probability sample was drawn from thetotal U. S. population not residing in institutions.Because of special interest in low-income, central-cityresidents, rural residents, and the elderly, thesegroups were sampled in numbers beyond theirproportion in the population so that sufficientlyprecise projections could be made for these groups.Data were collected by holding interviews in homes,and some of this information was verified by checkingother records such as those maintained by hospitalsand insurance companies. Information produced bythe survey, which was projected to the nationalpopulation, included the kind of health services thatpeople receive, where and why they receive them,how the services are paid for, and how much theycost.
Applications When the need for information is for a description ofa large population, a cross-sectional sample surveymay be the best approach. It can be used to acquirefactual information—such as the living conditions ofthe elderly or the costs of operating governmentprograms. It can also be used to determine attitudesand opinions—such as the degree of satisfactionamong the beneficiaries of a government program.
GAO/PEMD-10.1.4 Desiging EvaluationsPage 35

Chapter 3
Types of Design
Because the design requires rigorous samplingprocedures, the population must be well-defined. Thekind of information that is sought must be clearenough that structured forms of data collection canwork. A sample survey design cannot be used when itis not possible to settle on a particular sampling framebefore the data are collected. It is hard to use whenthe information that is sought must be acquired byunstructured, probing questions and when a fullunderstanding of events and conditions must bepieced together by asking different questions ofdifferent respondents.3
A cross-sectional design can sometimes be used forimputing causal relationships between conditions, asin inferring that educational attainment has an effecton income. Other evaluation designs, such as the trueexperiment or nonequivalent comparison groupdesigns, are ordinarily more appropriate, when theyare feasible. However, practical considerations mayrule out these and other designs, and thecross-sectional design may be chosen for lack of abetter alternative. When the cross-sectional design isused for causal inferences, the data must be analyzedby structural equation models and related techniques,although the data collection procedures are the sameas for descriptive applications (see, for example,Hayduk, 1987).
Planning andImplementation
Sampling. Having a sampling frame that closelyapproximates the population of interest and drawingthe sample in accordance with statisticalrequirements are crucial to the success of thecross-sectional sample survey. The size of a sample isdetermined by how statistically precise the findingsmust be when the sample results are used to estimate
3A procedure that is suitable for this situation, called “multiplematrix sampling,” applies to each respondent a subset of the totalnumber of questions.
GAO/PEMD-10.1.4 Desiging EvaluationsPage 36

Chapter 3
Types of Design
population parameters such as the mean andvariance.
Pretesting the Instruments. To ensure the uniformityof the data, the data collection instruments must beunambiguous and likely to elicit complete, unbiasedanswers from the respondents. Pretesting theinstruments a number of times before using them inthe survey is an essential preparatory step.
Nonrespondent Follow-up. The failure of a samplingunit to respond to a data collection instrument or thefailure to respond to certain questions may distort theresults when the data are aggregated. Furtherattempts must be made to acquire missinginformation from the respondents, and the dataanalysis must adjust, as well as possible, forinformation that cannot be obtained.
Causal Inference. The procedures for making causalinferences from sample survey data requirehypotheses about how two or more factors may berelated to one another. Causal analysis methods usethe hypotheses to test the consistency of the data.That is, the credibility of causal inferences fromsample survey data rests heavily on the plausibility ofthe hypotheses. For plausible hypotheses, a premiumis placed on broad literature reviews and a thoroughunderstanding of the events and conditions inquestion.
Where to Look for MoreInformation
Babbie (1990), Bainbridge (1989), Fowler (1988), andWarwick and Lininger (1975) are general referenceson the sample survey strategy. Kish (1987) coversdesign issues for sample surveys as well as otherdesigns. Kish (1965) provides a comprehensivetreatment of sampling procedures, while Kalton(1983), Henry (1990), Scheaffer, Mendenhall, and Ott(1990), Sudman (1976), and U.S. General Accounting
GAO/PEMD-10.1.4 Desiging EvaluationsPage 37

Chapter 3
Types of Design
Office (1986a) give introductory treatments. Datacollection methods are the subject of Bradburn andSudman (1979), Converse and Presser (1986), Fowlerand Mangione (1990), Payne (1951), and U.S. GeneralAccounting Office (1985 and 1986b). Groves(1989) offers a broad look at survey errors and costs.Routine data analysis methods are covered innumerous texts on descriptive and inferentialstatistics, and the U.S. General Accounting Officeplans to issue an elementary introduction to suchmethods in 1991. Examples of advanced techniquesmay be found in Lee, Forthofer, and Lorimor(1989) and Hayduk (1987).
The Panel Survey A panel survey is similar to a cross-sectional surveybut has the added feature that information is acquiredfrom a given sample unit at two or more points intime.
EXAMPLE: The “panel study of income dynamics,”carried out by the Institute for Survey Research at theUniversity of Michigan, is based on annual interviewswith a nationally representative sample of 5,000families. The extensive economic and social data thatare collected can be used to answer many descriptivequestions about occupation, education, income, andfamily characteristics. Because follow-up interviewsare made with the same families, questions can alsobe asked about changes in their occupation,education, income, and activities.
Applications The panel design adds the important element of timeto the sample survey strategy. When the survey isused to provide descriptive information, the paneldesign makes it possible to measure changes in facts,
GAO/PEMD-10.1.4 Desiging EvaluationsPage 38

Chapter 3
Types of Design
attitudes, and opinions.4 For making decisions aboutgovernment programs and policies, dynamicinformation—that is, information about change—isfrequently more useful than static information.
The panel survey’s use of time is also important whenthe survey data are used for causal inference. In thisapplication, the panel design may help settle thequestion of whether, of two factors that appear to becausally related, one is the cause and the other is theeffect.
Planning andImplementation
Sampling, Pretesting the Instruments, NonrespondentFollow-Up, and Causal Inference. Panel surveydesigns are similar to cross-sectional designs in theneed for attention to these activities.
Panel Maintenance. To the extent that sample unitsleave the sample, changes in the sample may bemistaken for changes in the conditions beingassessed. Therefore, keeping the panel intact is animportant priority. When sample units areunavoidably lost, it is necessary to attemptadjustments to minimize distortion in the results.
Where to Look for MoreInformation
The references in the discussion on cross-sectionalsurvey designs are applicable.
TheCriteria-ReferencedSurvey
Sometimes the evaluation question is, How dooutcomes associated with participation in a programcompare to the program’s objectives? Often, anormative question like this is best answered with asample survey design (although a criteria-referencedcase study design may sometimes be used).
4Change can also be measured by two or more cross-sectional,time-separated surveys if the samples and data collectionprocedures are consistent (see Babbie, 1990, for details). However,it is possible to associate change on a measure not with anindividual but with populations, so that the kinds of questions thatcan be answered are more limited than with the panel design.
GAO/PEMD-10.1.4 Desiging EvaluationsPage 39

Chapter 3
Types of Design
EXAMPLE: A soil conservation program has theobjective of reducing soil loss by 2 tons per acre peryear in selected counties. A panel survey could bedesigned in which actual soil loss on the land that issubject to the program could be compared to thecriterion. That is, two measurements of soil depth 1year apart could be recorded for a probability sampleof locations in the targeted counties. Subject to thelimitations of measurement and sampling error, theamount of soil loss in the counties could be estimatedand then compared to the program objective.
This criteria-referenced survey design employs aprobability sample to acquire information on theprogram’s outcome because a conclusion is soughtabout a representative sample of the program’spopulation.
A normative evaluation question may also ask, Howdoes actual program implementation match what wasintended, or how well does it match a standard ofoperating performance? The attention is not onoutcomes but on processes and procedures.
EXAMPLE: Federal policies require that commercialairlines observe certain safety procedures. Acriteria-referenced design could produce informationon the extent to which actual procedures conform tothese criteria. A population of maintenanceactivities—engine overhauls, for example—could besampled to see if required steps were followed. Theinfraction rate, projected to the population, couldthen be compared to the standard rate, which mightbe zero.
In this example, the passengers’ safety—but theevaluation is focused not on the result but on theimplementation of the program’s policy on safety.
GAO/PEMD-10.1.4 Desiging EvaluationsPage 40

Chapter 3
Types of Design
Applications Whether dealing with outcomes or process,evaluators can use criteria-referenced designs toanswer normative questions, which always compareactual performance to an external standard ofperformance. However, criteria-referenced designs donot generally permit inferences about whether aprogram has caused the outcomes that have beenobserved. Causal inference is not possible, becausethe criteria-referenced model does not produce anestimate of what the outcomes would have been inthe absence of the program.
An audit model—the “criterion, condition, cause, andeffect” model—is a special case of thecriteria-referenced design that is widely used in GAO.5
Outcomes, the condition, are often compared to anobjective, or a criterion, and the difference is taken asan indication of the extent to which the objective hasbeen missed, achieved, or exceeded. However, it isnot ordinarily possible to link the achievement of theobjective to the program, because other factors notaccounted for may enter into failure or success inmeeting the objective.
A variety of evaluation questions lead to the choice ofthe criteria-referenced design. For service programs,examples are questions about whether the rightparticipants are being served, the intended servicesare being provided, the program is operating incompliance with legal requirements, and the serviceproviders are properly qualified. Regulatory programsgive rise to similar questions:
whether activities are being regulated in compliancewith the statutory requirements, inspections are beingcarried out, and due process is being followed.
5The word “cause” in the audit model has a different meaning fromthe usual notion of causation. “Purported cause” would be a moreaccurate term, because the criteria-referenced design does notpermit inference about causation.
GAO/PEMD-10.1.4 Desiging EvaluationsPage 41

Chapter 3
Types of Design
Sometimes outcome questions are framed in terms ofcriteria. Did the missile hit the right target? Did theparticipants of the training program get jobs? Did thesale of timber yield the expected return? Did suppliesof strategic minerals meet the quotas?
Whenever the evaluation questions are normative,criteria-referenced designs are called for. Frequently,but not always, a sample survey is embedded in acriteria-referenced design so that the conclusions canbe regarded as representative of the population.
Planning andImplementation
Consensus About the Criteria. It is often difficult togain consensus about the objectives of federalprograms. It follows that in those cases it is also hardto decide which criterion to use in an evaluation. Thebest way is usually to use not one criterion butseveral criteria, to allow for the objectives of theseveral interests in the program—legislators,participants, taxpayers, and so on. The problem ofconsensus is usually of less concern withimplementation criteria, because statutes andregulations are more likely to be specific aboutimplementation requirements.
Measuring Performance Against the Criteria. Just as itmay be difficult to reach consensus on the objectivesof a program, so there is likely to be debate about theprocedures for measuring performance against thecriteria. For example, Are tests of military weaponsagainst simulated enemy targets a satisfactory way ofestimating the probability that the weapons will hitreal enemy targets? Similarly, views may differ aboutthe appropriate way to measure performance againstimplementation criteria.
Where to Look for MoreInformation
Herbert (1979) outlines the normative design as usedby auditors. Provus (1971) covers the “discrepancymodel,” an early treatment of the normative approach
GAO/PEMD-10.1.4 Desiging EvaluationsPage 42

Chapter 3
Types of Design
in evaluation, and Steinmetz (1983) is a laterreference for the same model. Popham (1975) oneducational evaluation focuses on criteria-referencedevaluation. The performance-monitoring approach ofWholey (1979) includes the comparison of actualprogram performance to that which is expected.
The Case Study The case study strategy is less well defined than theother evaluation strategies we have identified and,indeed, different practitioners may use the term tomean quite different things. For GAO’s purposes, acase study is an analytic description of an event, aprocess, an institution, or a program (Hoaglin et al.,1982).
One of the most commonly given reasons forchoosing a case study design is that the thing to bedescribed is so complex that the data collection hasto probe deeply beyond the boundaries of a samplesurvey, for example. The information to be acquiredwill be similarly complex, especially when acomprehensive understanding is wanted about how aprocess works or when an explanation is sought for alarge pattern of events.
Case studies are frequently used successfully toaddress both descriptive and normative questionswhen there is no requirement to generalize from thefindings. Impact (cause-and-effect) questions are
GAO/PEMD-10.1.4 Desiging EvaluationsPage 43

Chapter 3
Types of Design
sometimes considered, but reasoning about causalityfrom case study evidence is much more debatable.6
We present three types of case study design: singlecase, multiple case, and criteria-referenced designs.Even in a study with multiple cases, the sample size isusually small. However, if the sample size is relativelylarge and data collection is at least partiallystructured, the case study strategy may be similar tothe sample survey strategy, except that the latterrequires a probability sample.
The Single Case In single case designs, information is acquired about asingle individual, entity, or process.
EXAMPLE: The Agency for InternationalDevelopment fostered the introduction of hybridmaize into Kenya. An evaluation using a single casedesign acquired detailed information about theprocesses of introducing the maize, cultivating it,making it known to the populace, and using it. Theevaluation report is a minihistory constructed frominterviews and archival documents.
Single case evaluations are valued especially for theirutility in answering certain kinds of descriptivequestions. Ordinarily, much attention is given to
6The use of case studies to draw inferences about causality hasbeen approached from diverse points of view. The scope of thispaper permits only two examples. One approach is called “analyticinduction” and involves establishing a hypothesis about the causeof an effect and then searching among cases for an instance thatrefutes the hypothesis. When one is found, a new hypothesis abouta new cause is established, and the cycle continues until ahypothesis cannot be refuted. The cause, or pattern of causes,associated with that hypothesis is then taken as a likely explanationfor the effect. Another is in “single case experimental” designs,originated largely in the area of psychology and related to fieldexperiments. With substantial control over and manipulation of thehypothesized cause in a single case, inferences can be made aboutcause-and-effect relationships.
GAO/PEMD-10.1.4 Desiging EvaluationsPage 44

Chapter 3
Types of Design
acquiring qualitative information that describesevents and conditions from many points of view.Interviewing and observing are the common datacollection techniques. The amount of structureimposed on the data collection may range from theflexibility of ethnography or investigative reporting tothe highly structured interviews of sample surveys.There is some tendency to use case studies inconjunction with another strategy. For example, casestudies providing qualitative data might be used alongwith a sample survey to provide quantitative data.However, case studies are also frequently used alone.
Applications Three applications of single case studies areillustrative, exploratory, and critical instance. Theseand other applications are described in detail in CaseStudy Evaluations (U.S. General Accounting Office,1990), another paper in this series.
An illustrative case study describes an event or acondition. A common application is to describe afederal program, which may be unfamiliar and seemabstract, in concrete terms and with examples. Theaim is to provide information to readers who lackpersonal experience of what the program is and howit works.
An exploratory case study can serve one or another ofat least two purposes. One is as a precursor to apossibly larger evaluation. The case study tellswhether a program can be evaluated on a larger scaleand how the evaluation might be designed and carriedout. For example, a single case study might test thefeasibility of measuring program outcomes, refine theevaluation questions, or help in choosing a method ofcollecting data for the larger study. The other purposeof an exploratory case study is to provide preliminaryinformation, with no further study necessarilyintended.
GAO/PEMD-10.1.4 Desiging EvaluationsPage 45

Chapter 3
Types of Design
A single case study may also be used to examine acritical instance closely. Most common is theinvestigation of one problem or event, such as a costoverrun on a nuclear reactor. In this example, thequestion is normative and the issue is probablycomplex, requiring an in-depth study.
Planning andImplementation
Selecting a Case. The choice of a case clearly presentsa problem, except for the critical instance case study,in which the instance itself prompts the study. Inother applications, the results depend to some degreeon the case that is chosen. If it is expected that theywill differ greatly from case to case, it may benecessary to use a multiple case design.
Information Collection. Because the goal is to collectin-depth information about a complex case, datacollection may be challenging. Although case studiestypically require a mix of quantitative and qualitativedata, particular care is required with the latterbecause there is a tendency to be less rigorous inobtaining qualitative information. For example, if thedata collection is unstructured, the reliability of thedata may be doubted. The question is whether twodata collection teams examining the same case couldend up with quite different findings. Steps must betaken in the planning stages to avoid this form ofunreliability. Yin (1989) suggests three principles tohelp establish construct validity and reliability in acase study: (1) use multiple sources of evidence,(2) create a case study data base, and (3) maintain achain of evidence.
Data Analysis and Reporting. Because analyzing andreporting qualitative data can be difficult, the designfor the single case study must have explicit plans forthese tasks. Miles and Huberman (1984) offer manysuggestions for manipulating and displayingqualitative information. Tesch (1990) describes
GAO/PEMD-10.1.4 Desiging EvaluationsPage 46

Chapter 3
Types of Design
computer programs that can be used to analyzequalitative data.
Where to Look for MoreInformation
Yin (1989) and U.S. General Accounting Office(1990) set forth general approaches to the case studystrategy. Hoaglin et al. (1982) devote a chapter to casestudies. Patton (1990) gives an overall approach to“qualitative” evaluation. In a somewhat broader socialscience context, Strauss and Corbin (1990) giveprescriptions for qualitative research and Marshalland Rossman (1989) cover the design of qualitativeresearch. With respect to analysis of qualitative data,Miles and Huberman (1984), Strauss (1987), andTesch (1990) offer many suggestions.
Multiple Cases Single case designs are weak when the evaluationquestion requires drawing an inference from one caseto a larger group. A multiple case study design mayproduce stronger conclusions. In our classification,an important distinction between the multiple casestudy design and sample survey designs is that thelatter require probability samples while the formerdoes not.
EXAMPLE: A program known popularly as the“general revenue sharing act” appropriated federalfunds for nearly 38,000 state and local jurisdictions.An evaluation intended to answer both descriptiveand impact (cause-and-effect) questions used themultiple case study design. Sixty-five jurisdictionswere chosen judgmentally for in-depth datacollection, including questionnaires, interviews,public records, and less formal observations. Inselecting the sample, the evaluators considered someof the nation’s most populous states, counties, andcities but also considered diversity in the types ofjurisdiction. Budget constraints required ageographically clustered sample.
GAO/PEMD-10.1.4 Desiging EvaluationsPage 47

Chapter 3
Types of Design
In this example, the evaluators weighed the need forin-depth information and the need to makegeneralizations, and they chose in-depth informationover a probability sample. They tried to minimize thelimitations of their data by using a relatively large anddiverse sample.
The multiple case study design may be appropriate inevaluating either program operations or programresults (and it can be useful for exploratoryapplications as described for single case designs). Theaim is usually to draw conclusions about a programfrom a study of cases within the program, butsometimes the conclusions must be limited tostatements about the cases. When the aim is to makeinferences about a program, the best application isprobably to base a description of the program’soperations on cases from a very homogeneousprogram. The least defensible application is to try todetermine a program’s results from cases taken froma heterogeneous program.
Planning andImplementation
Selecting Cases. Since the evaluation strategy doesnot involve probability sampling, the goal of samplingshifts from one of getting a statistically defensiblesample to something else, frequently one that involvesgetting variety among the cases.7 The hope is thatensuring variation in the cases will avoid bias in thepicture that is constructed of the program.
Information Collection. Even though the intent of theevaluation may not be to literally aggregateinformation from multiple cases, the frequent need tomake statements about a program as a whole or tocompare across cases suggests the need for
7Variety is not the only criterion. For other possibilities, see U.S.General Accounting Office (1990) and Patton (1990). Also, whenthe evaluation question is about cause and effect, see Yin (1989) orHersen and Barlow (1976) for a discussion of how the samplingproblem is analogous to the problem of replicating experiments.
GAO/PEMD-10.1.4 Desiging EvaluationsPage 48

Chapter 3
Types of Design
uniformity in the information collection. This mayconflict with the in-depth, unstructured mode ofinquiry that produces the rich, detailed informationthat may be sought with case studies. If there aremultiple data collection teams across cases, extraattention must be given to data reliability.
Data Analysis and Reporting. Multiple sites makeanalysis more complicated and reporting morevoluminous. The analysis techniques suggested byMiles and Huberman (1984), Strauss (1987), Straussand Corbin (1990) and the software described byTesch (1990) may be useful.
Where to Look for MoreInformation
The references in the section on single case designsapply.
TheCriteria-ReferencedCase
Case studies can be adapted for answering normativequestions about how well program operations oroutcomes meet their criteria.
EXAMPLE: Social workers must be able to rule outfraudulent claims under the Social Security DisabilityInsurance Program. To make sure of the uniformapplication of the law, program administrators havedeveloped standard procedures for substantiatingclaims for benefits under the program. A case studycould compare procedures actually used by socialworkers to those prescribed by the program’sadministrators.
The examination of a number of cases might exposeviolations of prescribed claims-verificationprocedures. Unlike the criteria-referenced surveydesign, the criteria-referenced case study would notpermit an estimate of the frequency with whichviolations occur. It could show only that violations door do not occur and, if they do, it might give a clue as
GAO/PEMD-10.1.4 Desiging EvaluationsPage 49

Chapter 3
Types of Design
to why. Of course, if the number of cases is small andviolations are rare, the fact that there are violationsmay go undetected with the case study approach.
Applications The applications of the criteria-referenced case studydesign are similar to those of the counterpart designunder the sample survey strategy. The majordifference stems from the fact that data from casestudies cannot be statistically projected to apopulation. However, for a fixed expenditure ofresources, the case study may allow deeperunderstanding of a program’s operations or outcomesand how these compare to the criteria that have beenset for the program. Since case studies can beexpensive, care must be taken to ensure the accuracyof cost estimates before choosing case studies overother designs. Two applications are likely: anexploration that looks forward to a morecomprehensive project and a determination of thepossibility, if not the probability, that a criterion hasnot been met.
Planning andImplementation
How to reach consensus on the criteria and how tomeasure performance against a criterion—issues thatare important in criteria-referenced samplesurveys—are considerations in criteria-referencedcase studies. In addition, the question of how tochoose cases for study is crucial because theconclusions may differ, depending on the sample ofcases.
Where to Look for MoreInformation
The references cited above for case studies and forcriteria-referenced survey designs are applicable.
The FieldExperiment
The main use of field experiment designs is to drawcausal inferences about programs—that is, to answerimpact (cause-and-effect) questions. These designsallow the evaluator to compare, for example, a group
GAO/PEMD-10.1.4 Desiging EvaluationsPage 50

Chapter 3
Types of Design
of persons who are possibly affected by a program toothers who have not been exposed to the program.The evaluation question might be, Does the NationalSchool Lunch Program improve children’s health? Toanswer the question, the evaluator could compare ameasurement of the health of children participating inthe program to a measurement of the health of similarchildren who are not participating.
Field experiments are distinguishable from laboratoryexperiments and experimental simulations in thatfield experiments take place in much less contrivedsettings. Conducting an inquiry in the field givesreality to the evaluation, but it is often at the expenseof some accuracy in the results. From a practicalpoint of view, GAO’s only plausible choice among thethree is usually experiments in the field. Trueexperiments, nonequivalent comparison groups, andbefore-and-after studies—the field experimentdesigns we outline below—have in common thatmeasurements are made after a program has beenimplemented. Their major difference is in the base towhich program participants’ outcomes are compared,as can be seen in the first row of table 3.3. Two otherimportant differences—the persuasiveness of causalarguments derived from the designs and the ease ofadministration—are shown in rows two and three.
GAO/PEMD-10.1.4 Desiging EvaluationsPage 51

Chapter 3
Types of Design
Table 3.3: Some Basic Contrasts Between Three Field Experiment DesignsDesign
Basis for contrast True experimentNonequivalentcomparison group Before and after
Measurements ofprogram participantsare compared tomeasurements of
others in a randomlyassignedcomparison group
others in anonequivalentcomparison group
same participantsbefore programimplementation
Persuasiveness ofargument about thecasual effect ofprogram onparticipant is
generally strong quite variable usually weak exceptfor interrupted seriessubtype
Administering thedesign is
usually difficult often difficult relatively easy
The TrueExperiment
The characteristic of a true experimental design isthat some units of study are randomly assigned to atreatment group and some are assigned to one ormore comparison groups.8 Random assignmentmeans that every unit available to the experiment hasa known probability of being assigned to each groupand that the assignment is made by chance, as in theflip of a coin. The program’s effects are estimated bycomparing outcomes for the treatment group withoutcomes for each comparison group.
EXAMPLE: The Emergency School Aid Act madegrants to school districts to ease the problems ofschool desegregation. An evaluation question was, Dochildren in schools participating in the program haveattitudes about desegregation that are different fromthose of children in schools that are desegregating butnot participating in the program? For each districtreceiving a grant, a list was formed of all schools
8In some experiments, units are assigned randomly to several levelsof treatment—for example, different guaranteed income levels.
GAO/PEMD-10.1.4 Desiging EvaluationsPage 52

Chapter 3
Types of Design
eligible to participate in the program. The unitsavailable to the evaluation consisted of the schoolseligible to participate in the program. Within eachschool district, some schools were randomly assignedto receive program funds in the treatment group, andthe remainder became the comparison group.
Although the true experimental design is unlikely tobe applied much by GAO evaluators, it is an importantdesign in other evaluation settings in that it is usuallythe strongest design for causal inference and providesa useful yardstick by which to assess weaknesses orpotential weaknesses in a cause-and-effect design.The great strength of the true experimental design isthat it ordinarily permits very persuasive statementsabout the cause of observed outcomes.
An outcome may have several causes. In evaluating agovernment program to find out whether it causes aparticular outcome, the simplest true experimentaldesign establishes one group that is exposed to theprogram and another that is not. The difference intheir outcomes is attributed, with some qualifications,to the program. The causal conclusion is justifiedbecause, under random assignment, most of thefactors that determine outcomes other than theprogram itself are evenly distributed between the twogroups; their effects tend to cancel one another out ina comparison of the two groups. Thus, only theprogram’s effect, if any, accounts for the difference.
Applications When the evaluation question is about cause andeffect and there is no ethical or administrativeobstacle to random assignment, the true experimentis usually the design of choice. The basic design isused frequently in many different forms in medicaland agricultural evaluations but less often in otherfields.
GAO/PEMD-10.1.4 Desiging EvaluationsPage 53

Chapter 3
Types of Design
The true experiment is seldom, if ever, feasible forGAO because evaluators must have control over theprocess by which participants in a program areassigned to it, and this control generally rests with theexecutive branch. Being able to make randomassignments is essential: the true experimental designis not possible without it. The obstacles might beovercome in a joint initiative between the executivebranch and the evaluators, making a true experimentpossible. Also, GAO occasionally reviews trueexperiments carried out by evaluators in theexecutive branch.
Planning andImplementation
Generalization. If the ability to generalize is a goal, atrue experimental design may be unwarranted.Generalization requires that the units in theexperiment be a probability sample drawn from apopulation of interest, but with a probability sample,more than a few units are likely to refuse toparticipate.9 Sometimes, as in the school exampleabove, this may not be a problem becauseparticipation in the experiment may be a condition ofprogram participation. In other true experiments,limitations in the available units may not be seriousbecause either generalization from the results to abroad population is not a goal or the effects oftreatment are expected to be reasonably uniformwithin the population. In the latter case, an attemptcan be made to generalize even without a probabilitysample from the population of interest. Such may belikely in some fields like medicine, where relativelyconstant treatment effects may be expected, but is
9It is important to bear in mind that a random sample from apopulation and random assignment to a treatment or comparisongroup are two quite different things. The first is for the purpose ofgeneralizing from a sample to a population; random sampling helpsensure external validity. The second is for inferringcause-and-effect relationships; random assignment helps ensureinternal validity.
GAO/PEMD-10.1.4 Desiging EvaluationsPage 54

Chapter 3
Types of Design
less likely in evaluating government programs andpolicies.
Maintenance of Experimental Conditions. In order toapply the logic of random assignment to reasoningabout cause and effect, the evaluator must ensure thatthe composition of the groups, and thus the integrityof the experiment, is maintained. One of the chiefthreats to causal reasoning from a true experiment isthat the members of the treatment and comparisongroups may drop out at different rates. If people dropout more from one group than from another—as theymight if they find the treatment disagreeable, forexample—then the evaluator’s estimate of treatmenteffects may be distorted. Likewise, if the treatment isallowed to weaken or to vary from participant toparticipant or to spill over to a comparison group, thefindings from the evaluation will be compromised.
Where to Look for MoreInformation
Judd and Kenny (1981) and Rossi and Freeman(1989) are general evaluation texts that giveconsiderable attention to the true experiment. Moreintensive treatments may be found in Boruch andWothke (1985), Hausman and Wise (1985), Keppel(1982), Keppel and Zedeck (1989), and Spector (1981).Many references listed under the nonequivalentcomparison group design apply here as well.
The NonequivalentComparison GroupDesign
As with the true experiment, the main purpose of thenonequivalent comparison group design is to answerimpact (cause-and-effect) questions. A further parallelis that both designs consist of a treatment group andone or more comparison groups. Unlike the groups inthe true experiment, however, membership innonequivalent comparison groups is not randomlyassigned. This difference is important because itimplies that, since the groups will not be equivalent,
GAO/PEMD-10.1.4 Desiging EvaluationsPage 55

Chapter 3
Types of Design
causal statements about treatment effects may besubstantially weakened.
EXAMPLE: Occupational training programs try toprovide people with skills to help them obtain andkeep good jobs. An evaluation question might be, Arethe average weekly earnings of program graduateshigher than would have been expected had they notparticipated in the training? Participants haveordinarily selected themselves for enrollment in suchprograms, which rules out random assignment. It maybe possible to compare the participants withmembers of another group, but the members of theparticipant group and the comparison group willalmost certainly not be equivalent in age, gender,race, and work motivation. Therefore, the rawdifference in their earnings would probably not be anappropriate indicator of the effect of the trainingprogram, but other comparisons might be suitable fordrawing cause-and-effect inferences.
This example is intended to show that whentreatment and comparison groups are not randomlyassigned, it is usually not possible to infer that the“raw” difference between the groups has been causedby the treatment. In other words, the two groupsprobably differ with regard to other factors that affectthe difference in outcome, so that the raw differenceshould be adjusted to compensate for the lack ofequivalence between the groups. Using adjustmentprocedures, including such statistical techniques asthe analysis of covariance, may strengthen theevaluation conclusions.
Applications Nonequivalent comparison group designs are widelyused to answer impact (cause-and-effect) questionsbecause they are administratively easier to implementthan true experiments and, in appropriatecircumstances, they permit relatively strong causal
GAO/PEMD-10.1.4 Desiging EvaluationsPage 56

Chapter 3
Types of Design
statements. Evaluations of health, education, andcriminal justice programs can generally collect datafrom untreated comparison groups but cannot, as wenoted above, easily assign subjects randomly togroups in a true experimental design. For example, anevaluation designed to look at the effects ofcorrectional treatment on the recidivism of releasedcriminals through a true experiment would probablynot be feasible, because judges base their sentenceson the severity of a crime, number of prior offenses,and similar factors, and they would not ordinarily bewilling to randomize the correctional treatment thatthey declare.
Planning andImplementation
Formation of Comparison Groups. The aim of anonequivalent comparison group design is to drawcausal inferences about a program’s effects. Theevaluator’s two most important considerations indoing this are the choice of the comparison groupsand the nature of the comparisons. In the absence ofrandom assignment, treatment groups andcomparison groups may differ substantially. Greatdissimilarity usually weakens the conclusions,because it is not possible to rule out factors otherthan the program as plausible causes for the results.For example, to evaluate a nutritional program forpregnant women, it might be administrativelyconvenient to compare program participants in anurban area with nonparticipants in a rural area. Thiswould be unwise, however, because dietary and othersuch differences between the two groups could easilyaccount for differences in the status of their healthand thereby exaggerate or conceal the effects of theprogram. Therefore, in most circumstances it isadvisable to form treatment and comparison groupsthat are as alike as possible.10
10The evaluator who has precise control over assignments to thegroup may prefer instead the “regression discontinuity,” or biasedassignment, design, in which the groups are distinctly different inknown ways that can be adjusted for by statistical procedures.
GAO/PEMD-10.1.4 Desiging EvaluationsPage 57

Chapter 3
Types of Design
Naturally Occurring Comparison Groups. For manyevaluations, the evaluator is not the one who formedthe treatment and comparison groups. Rather, theevaluator is often presented with a situation in whichsome people have been exposed to the program andothers have not. Although the presence of naturallyconstituted comparison groups somewhat limits theevaluator’s options, the general logic of the design isthe same.
Nature of the Comparisons. The way in whichtreatment groups are compared to comparison groupsinvolves statistical techniques beyond the scope ofthis paper. We can point out, however, that it isimportant that plans for the comparison be madeearly, because it will be necessary to collect data onprecisely how the groups are not equivalent.
Design Sensitivity. It is crucially important thatexperimental designs be sensitive enough to detecteffects if they exist. A number of factors, such assampling error, measurement error, subjectvariability, and the type of statistical analysis used,determine the likelihood that a given evaluation willreveal a true effect. Lipsey (1990) provides a broadoverview of the most important considerations indeveloping a design.
Where to Look for MoreInformation
Many design issues are covered by Cook andCampbell (1979), Cronbach (1982), Judd and Kenny(1981), Kish (1987), Mohr (1988), Posavac and Carey(1989), Rossi and Freeman (1989), and Saxe and Fine(1981). Design sensitivity and statistical power aretreated by Cohen (1988), Kraemer and Thiemann(1987), and Lipsey (1990). Achen (1986), Anderson etal. (1980), Keppel and Zedeck (1989), and Pedhazur(1982), as well as many of the preceding authors,address data analysis issues.
GAO/PEMD-10.1.4 Desiging EvaluationsPage 58

Chapter 3
Types of Design
TheBefore-And-AfterDesign
The distinguishing feature of before-and-after designsis that they compare outcomes for the units of studybefore the units were exposed to a program tooutcomes measured one or more times after theybegan to participate in it. There is no comparisongroup as it exists in the other designs.
EXAMPLE: A training program was established tohelp increase the earnings of workers who had fewjob skills. For a random sample of trainees, anevaluation reported their average weekly incomebefore and after their participation in the program.
Although this simple version of a before-and-afterdesign can be used to answer questions about theamount of change that has been observed, it does notallow the attribution of that change to exposure to theprogram. This is because it is not possible to separatethe effects of the training program from otherinfluences on the workers such as the availability ofjobs in the labor market, which would also affect theirearnings. The absence of a comparison group sharplyweakens the kinds of conclusions that can be drawnbecause comparison groups help rule out alternativeexplanations for the observed outcomes.
Before-and-after designs can be strengthened by theaddition of more observations on outcomes. That is,instead of looking at a given outcome at two points intime, the evaluator can take a look at many points intime; with a sufficient number of points, aninterrupted time series analysis can be applied to thebefore-and-after design to help draw causalinferences. (Such longitudinal data can also be usedto advantage with the nonequivalent comparisongroup design: comparisons can be made between twoor more time series.)
GAO/PEMD-10.1.4 Desiging EvaluationsPage 59

Chapter 3
Types of Design
EXAMPLE: After the development of a measlesvaccine early in the 1960’s, the Centers for DiseaseControl instituted a nationwide measles eradicationprogram. Grants were made to state and local healthauthorities to pay for immunization. By 1972, a longseries of data was available that reported cases ofmeasles by 4-week periods. The evaluation questionwas, What was the effect of the federal measleseradication program on the number of measles cases?The answer, provided by a before-and-after designusing interrupted time series analysis, requireddistinguishing the effects of the federal program fromthe effects of private physicians acting in concert withstate and local health authorities.
Before-and-after designs with a number ofobservations over time may provide defensibleanswers to impact (cause-and-effect) questions.Multiple observations before and after an event helprule out alternative explanations, just as comparisongroups do in other designs.
Applications GAO evaluators are most likely to applybefore-and-after designs that employ interrupted timeseries analysis to data either collected by GAO ormade available from other public sources. The Bureauof the Census, the National Center for HealthStatistics, the National Center for EducationalStatistics, the Bureau of Labor Statistics, and manyother such agencies may provide data forinvestigating the effects of introducing, withdrawing,or modifying national programs. Evaluators will findthat the best application is for studies in which a longseries of observations has been interrupted by a sharpchange in the operation of a federal program.
Planning andImplementation
Alternative Causal Explanations. The generalweakness of before-and-after designs arises from theabsence of comparison groups that could help rule
GAO/PEMD-10.1.4 Desiging EvaluationsPage 60

Chapter 3
Types of Design
out alternative causal explanations. However, usingan interrupted time series can often help make causalarguments relatively strong.
Number of Observations. The simple before-and-afterdesign is seldom satisfactory for cause-and-effectarguments, although it may suffice for measuringchange. The traditional rule of thumb for interruptedtime series analyses says that at least 50 observationsare required, but some analysis methods use fewer(Forehand, 1982).
Data Consistency. When measurements are maderepeatedly, definitions and procedures may change.Care must be taken to see that time series are free ofdefinitional and measurement changes, because thesecan be mistaken for program effects.
Where to Look for MoreInformation
Many of the references for design and analysis of thenonequivalent comparison group design cover thebefore-and-after design as well. In addition, Forehand(1982) and McCleary and Hay (1980) specificallyaddress the time-series design.
The Use ofAvailable Data
The evaluation strategies discussed above ofteninvolve the need to collect new data in order toanswer an evaluation question. Because datacollection is costly, it is always wise to see if availableinformation will suffice. Even if the conclusion is thatnew data should be acquired, the analysis of data thatare already available may be warranted for quick, iftentative, answers to questions that will be morecompletely addressed with new data at a later time.Available data may be used to address evaluationquestions not intended when the data were originallycollected. We discuss two approaches to the strategyof using available data: secondary data analysis andevaluation synthesis.
GAO/PEMD-10.1.4 Desiging EvaluationsPage 61

Chapter 3
Types of Design
In the first approach, the evaluator may have bothaccess to data and the need to analyze them afterothers have done so. For example, secondary dataanalysis might answer an evaluation question bylooking at decennial census data published by theBureau of the Census and widely used by others.
In an evaluation synthesis, the evaluator combines anumber of previous evaluations that more or lessaddress the current question. For example, it might bepossible to synthesize several evaluation findings onhow behavior-modification programs affect juveniledelinquents in such a way that the synthesized findingis more credible than the finding of any of the severalevaluations taken individually.
Secondary DataAnalysis
We refer to secondary data analysis as an approachrather than a design because the data that areinvolved have already been acquired under an originaldesign for data collection, using some technique suchas self-administered questionnaires. If the first designwas a sample survey, for example, the analysis mighthave produced descriptive statistics. The secondarydata analysis might produce causal inferences withanother method.
EXAMPLE: Data from 11 sample surveys were used ina major secondary analysis that sought to describethe effects of family background, cognitive skills,personality traits, and years of schooling on personaleconomic success. The data that were availablevaried from survey to survey, but overall theinvestigation focused on American men 25 to 54 yearsold, and economic success was expressed as eitherannual earnings or an index of occupational status.Multivariate statistical methods were used to drawinferences about cause-and-effect relationshipsamong the variables.
GAO/PEMD-10.1.4 Desiging EvaluationsPage 62

Chapter 3
Types of Design
Applications Probably the most common application of secondarydata analysis in GAO is in answering questions thatwere not posed when the data were collected. Manylarge data sets produced by sample surveys or as partof a program’s administrative procedures areavailable for secondary analysis. The most likelyanswers in secondary data analysis are descriptive,but normative and impact (cause-and-effect)questions can be considered.
Planning andImplementation
Access to Data. Some data bases, such as thoseproduced by the Bureau of the Census, are relativelyeasy to obtain. Others, such as those produced byprivate research firms, may be much more difficult oreven impossible to acquire. Confidentiality andprivacy restrictions may prevent access to certaindata.
Documentation of Data Bases. There are generallytwo kinds of documentation problems. Automateddata may be difficult to read if the information hasbeen recorded idiosyncratically. The second problemarises when it is hard to understand how the datawere collected. How were the variables defined?What was the sample? How were the data collected?How were the data processed and tabulated? Howwere composite variables, such as indexes, formedfrom the raw data? Misunderstanding such details canlead to a misuse of the data.
Data Mismatched to Questions. When the evaluatorwants to answer an evaluation question with datacollected for another purpose, it is very likely that thedata will not exactly meet the need. For example, apopulation may be a little different from the one theevaluator has in mind, or variables may have beendefined in a different way. The solution is to restatethe question or to state proper caveats about theconclusions.
GAO/PEMD-10.1.4 Desiging EvaluationsPage 63

Chapter 3
Types of Design
Where to Look for MoreInformation
Boruch (1978), Boruch et al. (1981), Bowering (1984),Cook (1974), Hoaglin et al. (1982), Hyman (1972),Jacob (1984), Kiecolt and Nathan (1985), and Stewart(1984) address a variety of issues pertaining tosecondary analysis.
The EvaluationSynthesis
Some evaluation questions may have been addressedalready with substantial research. The evaluationsynthesis aggregates the findings from individualstudies in order to provide a conclusion more crediblethan that of any one study.
EXAMPLE: Many studies have been made of theeffects of school desegregation. An evaluationsynthesis statistically aggregated the results of 93studies of students who had been reassigned fromsegregated to desegregated schools in order toanswer the question of how the achievement of blackstudents is affected when desegregation occurs bygovernment action. The evaluation combined 321samples of black students from 67 cities. Each of theoriginal studies used some type of field experimentdesign.
An evaluation synthesis may take any one of severalforms. At the opposite extreme of this example, asynthesis may be qualitative but beyond the limits of atypical literature review. The evidence is weighed andqualitatively combined, but there is no attempt tostatistically aggregate the results of individual studies.
A variety of synthesis procedures have been proposedfor statistically cumulating the results of severalstudies. Probably the most widely used procedure foranswering questions about program effects is“meta-analysis,” which is a way of averaging “effectsizes” from several studies. Effect size is proportional
GAO/PEMD-10.1.4 Desiging EvaluationsPage 64

Chapter 3
Types of Design
to the difference in outcome between a treatmentgroup and a comparison group.
Applications Some form of synthesis is appropriate when availableevidence can answer or partially answer an evaluationquestion. When there is much information of highquality, a synthesis alone may satisfactorily answerthe question. If the information falls considerablyshort, it may be useful to perform an evaluationsynthesis for a tentative, relatively quick answer andto follow some other strategy for a more definitiveanswer.
When an issue is highly controversial, the evaluationsynthesis may help resolve it, because the synthesistakes account of the variable quality of conflictingevidence. The evaluations being reviewed for thesynthesis may be graded for quality. Judgments maybe made about what to include from them in thesynthesis, or all usable information may be included,as in some forms of meta-analysis. For the latter, therelationship between quality and effect is statisticallyanalyzed.
Syntheses almost always identify gaps in availableinformation. Finding gaps is not the aim of theevaluation synthesis, but when a dedicated search forinformation reveals them, they can be useful inclarifying a debate. Of course, knowing aboutinformation gaps may usefully trigger the gathering ofnew evidence.
Planning andImplementation
Choice of Form. The nature of the evidencedetermines the appropriate form. Quantitativetechniques such as meta-analysis are probably themost stringent, but all syntheses require informationabout how the evaluations being examined wereconducted. This means that the evaluator must
GAO/PEMD-10.1.4 Desiging EvaluationsPage 65

Chapter 3
Types of Design
become familiar with the literature before settling ona form to use.
Selection of Studies. In synthesizing evaluations, theevaluator must make important decisions about howto define the population of applicable studies andhow to ensure that the population or an appropriatesample of it will be examined. Typically, the evaluatorsystematically screens the population, selectingspecific studies for consideration.
Reliability of Procedures. A synthesis typicallyinvolves the detailed review of many studies, whichmay be undertaken by several staff members. Whenthe work is divided among evaluators, attention mustbe given to the reliability of the synthesis proceduresthat the staff members use. Although consistency ofprocedure does not alone ensure sound conclusions,it is necessary. Uniform procedures, such as the useof codebooks, must be established and checks shouldbe made to verify their effectiveness.
Where to Look for MoreInformation
U.S. General Accounting Office (1983), Light andPillemer (1984), and Yeaton and Wortman (1984) giverelatively broad treatments of the evaluationsynthesis. Glass, McGaw, and Smith (1981), Hedgesand Olkin (1985), Hunter and Schmidt (1989), Hunter,Schmidt, and Jackson (1982), Rosenthal (1984),Wachter and Straf (1990), and Wolf (1986) are focusedon meta-analysis. Cooper (1984) and Jackson(1980) discuss integrative research reviews. Yin andHeald (1975) discuss a method for aggregating acrosscase studies, and Noblit and Hare (1988) treatconsiderations involved in synthesizing qualitativestudies.
GAO/PEMD-10.1.4 Desiging EvaluationsPage 66

Chapter 3
Types of Design
Linking a Designto the EvaluationQuestions
With particular strategies, designs, and approaches inmind, the evaluator should consider the type ofevaluation question being asked and a number ofdesign-screening questions in order to narrow thechoices. The point of departure is the evaluationquestion. Is it descriptive (about how a high-techtraining program was implemented)? Is it normative(about whether the job-placement goals of thehigh-tech training program were met)? Is it causal(about whether the high-tech training program had aneffect on job-placement rates)? The answer will partlydetermine the design or approach to choose.
The choice of what design or approach to settle on isfurther narrowed with the help of severaldesign-screening questions about the definitivenessneeded in the conclusions and the kind of constraintsthat are expected. An example of the former is, Mustwe be able to generalize from what we examine in theevaluation to some larger class of things? Examplesof the latter are, Can a comparison group be formed?Do we have 6 months or 18 months in which toperform the evaluation?
Figure 3.1 is a decision tree that illustrates thisprocess of choosing an evaluation design. Thebranches at the top of the figure point the way to theanswer about the type of evaluation question(descriptive, normative, or causal). Branches furtherdown in the figure point out the place at which to askdesign-screening questions (Do we want to generalizethe findings? Can a comparison group be found orformed? Can subjects be randomly assigned togroups? Can outcomes be measured over time?).
GAO/PEMD-10.1.4 Desiging EvaluationsPage 67

Chapter 3
Types of Design
Figure 3.1: Linking a Design to the Evaluation Questions
GAO/PEMD-10.1.4 Desiging EvaluationsPage 68

Chapter 3
Types of Design
GAO/PEMD-10.1.4 Desiging EvaluationsPage 69

Chapter 3
Types of Design
It must be stressed that the design-screeningquestions in the figure are illustrative and that thefigure presents only selected technical matters. Forexample, approaches using available data have beenomitted. Other, equally important factors in choosinga design have also been omitted. They include theavailability of resources, the intended use of theevaluation, and the date when the evaluation report isexpected. When these factors represent constraints,they put boundaries around what can be done.
As a design evolves, and as the evaluation questionsbecome more specific and research possibilities morenarrow, the evaluator must balance the technicalconsiderations against the constraints. For example,it might be necessary to choose between collectingnew data, which might answer the evaluationquestions comprehensively, and using available data,which is usually the least expensive course and thequickest but may leave some avenues unexplored.
The decision tree almost always ends with theinstruction to consider a particular type of design.However, we emphasize the tentativeness in“consider,” because we do not want to suggest thatthere is only one way of designing evaluations.Answers to design-screening questions are not usuallyas clear-cut as the decision tree suggests, and therelative importance of even these questions may bedebated. Furthermore, most evaluations must answerseveral questions, and where there are severalquestions, there may be several design types. Evenwith only one question, it may be advisable to employmore than one design. The strengths and theweaknesses of several designs may offset oneanother. Thus, the decision tree is not a rigidprocedure but a conceptual guide for a systematicconsideration of design alternatives (McGrath, Martin,and Kulka, 1982).
GAO/PEMD-10.1.4 Desiging EvaluationsPage 70

Chapter 4
Developing a Design: an Example
We have been stressing a consistent theme—that thedevelopment of an evaluation design is a systematicprocess that takes time, thought, and craft. Theevaluator must pay careful attention to theformulation of questions and the means of answeringthem. This painstaking work can be lengthy at thestart of a job, but postponing or eliminating it is aninvitation to costly delays, incomplete or mediocredata collection, and uncertain analysis. To generate adesign is to think strategically; it is to see the linkbetween the questions being asked and the way inwhich to collect and analyze the data for answeringthem. Our theme is exemplified in the narrative thatfollows about the development of a design for acongressionally requested evaluation of the effects of1981 changes to the Aid to Families with DependentChildren (AFDC) program.
The Context The Omnibus Budget Reconciliation Act of 1981mandated important changes to AFDC, a majorwelfare program at the center of debate about welfareand work. On the one hand were people whosuggested that providing welfare income reduces arecipient’s motivation to work and createsdependence on welfare and a permanent underclassof nonworkers; these people favored strict eligibilitycriteria for the program and work requirements forwelfare recipients. On the other hand were some whosuggested that work incentives and workrequirements are irrelevant to a welfare populationcomposed largely of households headed by womenwith small children, who either cannot find work orcannot find work that pays enough to meet theirdaycare, transportation, or medical expenses.
The AFDC program had grown during the 1960’s from3.0 million to 7.3 million in recipients and from $1.1billion to $3.5 billion in costs. By 1980, the caseload
GAO/PEMD-10.1.4 Desiging EvaluationsPage 71

Chapter 4
Developing a Design: an Example
was 11.1 million persons and the yearly costs$12.5 billion. Throughout the period, attempts weremade to slow the growth.
For example, AFDC’s expansion during the 1960’s,both in the level of benefits and in the categories ofeligibility, had been accompanied by a movement toencourage mothers who were receiving benefits towork. In 1962, a community work and trainingprogram had emphasized voluntary training andsocial services as an alternative to prolongedparticipation in AFDC.
Another strategy had been to reduce the 100-percentfederal tax on the earnings of AFDC families, a taxthat was seen as a “disincentive” to work becauseeach dollar earned was a welfare dollar lost.Modifying this strategy in 1967, the Congressincorporated an “earned-income disregard” provisioninto the AFDC program, allowing recipients to earn$30 each month with no reduction in benefits—a taxrate of 0 percent—and disregarding one third of alladditional earnings.
Along with this change, the Congress enacted theWork Incentive (WIN) program, in which AFDCrecipients could volunteer to receive training services.During the 1970’s, however, as the caseload continuedto grow, registration in WIN was made mandatory forsome AFDC households.
The changes in the AFDC regulations that werespecified in the 1981 Omnibus Budget ReconciliationAct focused again on work requirements by allowingthe states to operate mandatory “workfare” programs.Other amendments to the legislation changed thepolicy of allowing working welfare families toaccumulate more income than that available tononworking welfare families. One of the key
GAO/PEMD-10.1.4 Desiging EvaluationsPage 72

Chapter 4
Developing a Design: an Example
provisions limited the earned-income disregard to 4months and the total income of an AFDC householdto 150 percent of the AFDC need standardsestablished by each of the states.
The Request In June 1982, the House Committee on Ways andMeans asked GAO to study the 1981 modifications ofthe AFDC program. The changes were expected toremove many working AFDC families from theprogram’s rolls, causing many of them to lose theireligibility for Medicaid. Other families would be ableto remain on the rolls but with significantly reducedbenefits. One concern of the committee was that,faced with the prospect of losing benefits or seeingthem greatly diminished, the families would simplychoose to work less or quit working entirely. Bycutting back on work, they could retain theireligibility for AFDC and Medicaid. However, facedwith the loss of benefits, families might insteadincrease their work effort in order to compensate forthe loss.
The committee specifically asked GAO to ascertain(1) the economic well-being, 6 to 12 months after theact’s effective date, of the AFDC families that hadbeen removed from the rolls and that had had theirbenefits reduced and (2) whether families losingbenefits had returned to the rolls or compensated fortheir welfare losses by cutting back on work.
If working families who would lose AFDC or havetheir grants reduced were to lessen their work effortin order to stay on the rolls, projected budget savingsfrom the legislated changes would be negated ordiminished. Therefore, GAO was asked to estimatethe budgetary effect of the program changes. Therequest also required GAO to find out whether thechanges had affected family or household
GAO/PEMD-10.1.4 Desiging EvaluationsPage 73

Chapter 4
Developing a Design: an Example
composition and to provide information about thedemographic, income, and resource characteristics ofthe AFDC families both before and after the changeand the frequency with which they moved on and offthe rolls. The committee asked GAO to make itsreport early in 1984, which it did with the April 2report entitled An Evaluation of the 1981 AFDCChanges: Initial Analyses (PEMD-84-6), issued by theProgram Evaluation and Methodology Division. Thefinal report entitled An Evaluation of the 1981 AFDCChanges: Final Report (PEMD-85-4) was issued onJuly 2, 1985.
Design Phase 1:Finding anApproach
The evaluators began by exploring ways of stating thekey questions and strategies for answering them.They reviewed the substantive and themethodological literature and acquired informationon the program’s operations. They explored therelevance of available data, and they consulted withthe committee’s staff and other experts.
The literature review centered on welfaredependence, the effects of earlier changes in theprogram, and the methods other researchers had usedto address questions of similar scope and complexity.A systematic reading of the voluminous literature onthese topics generated a number of important insightsthat guided further thinking and refinement of thestudy. For example, the reading on welfaredependence led to three hypotheses on the 20-yeargrowth of the AFDC caseload. Similarly, the reviewpointed out areas where information is lacking, suchas on the rate at which people leave welfare programsand do not return within a specified time.
The evaluators found that the literature on programeffects stressed the need for a longitudinalperspective. They found that the reports relating work
GAO/PEMD-10.1.4 Desiging EvaluationsPage 74

Chapter 4
Developing a Design: an Example
to changes in the AFDC tax rates were informative ondesign approaches as well as on findings. In reviewingthe earlier research methods, the evaluators wereinterested in identifying both designs and measuresthat fell short or were especially vulnerable and thosethat were successful. Thus, the review indicated whatnot to do and suggested strategies that werepromising and worth further consideration.
The evaluators also explored the relevance ofavailable data. The ability to make use of existing datasets has the advantage of cutting the cost ofcollecting, organizing, verifying, and automatinginformation. Five data sets were identified andcarefully scrutinized.
The consultation with experts included contact withcommittee staff, economists, political scientists,social welfare analysts, policy analysts, evaluationspecialists, and statisticians. Discussions ranged overa wide number of substantive and methodologicalissues, and they were held frequently to allow anongoing critique of the design as it was beingformulated. The consultation continued throughoutthe study, suggesting valuable leads to pursue anddead ends to avoid.
In acquiring information on the operation of theAFDC program, the evaluators paid attention to broadoperational procedures but also concentrated onthree areas. The first was how the states determinedAFDC benefits before and after the 1981 act and whenand how the changes were implemented. The secondwas how the program was related to other programsfrom state to state. The third was the relationship inthe states between the participation of AFDC familiesand local economic conditions. Clearly germane tothe questions posed by the committee, these interestswere stated as questions in language sufficiently
GAO/PEMD-10.1.4 Desiging EvaluationsPage 75

Chapter 4
Developing a Design: an Example
general to allow the exploration of multiple ideas andsources of information. The goal was not to forecloseprematurely on potentially useful material that mightlead to a thorough understanding of the program’shistory, how it changed when federal policy wastranslated to the local level, and whatever wouldincrease the possibility of making cause-and-effectstatements.
After about 6 weeks, this group of evaluators, as adesign team, began to feel confident about two ofseveral possible designs. Then they began to linkalternative designs to evaluation questions.
Design Phase 2:AssessingAlternatives
The constraints that came to light in phase 1 shapedsubsequent thinking about the job and sharpened theassessment of various alternatives. This allowed theevaluators to refine the evaluation questions, whichthey did in phase 2, so that they could settle on astrategy and a final design.
The first of the constraints began to influence thedesign when the discussions with experts andnumerous visits to the states made it readily apparentthat the “national” AFDC program is actually 50different AFDC programs, one for each state. Theheterogeneity was evident in the fact that each statedevelops its own payment levels and procedures forsetting work and child-care expense deductionswithin the framework of the federal regulations.
For example, the evaluators found considerablevariation with respect to two-parent families inrequirements about the presence of an unemployedparent, “need” standards, the percentage of the needstandard being paid to recipients, and deductionsallowable for child-care and work expenses. Thevariations meant that quite dissimilar grant payments
GAO/PEMD-10.1.4 Desiging EvaluationsPage 76

Chapter 4
Developing a Design: an Example
were being made to families whose composition andfinancial circumstances were identical. Thecircumstance placed pronounced limitations on theevaluators’ ability to generalize from individual statesto the nation.
A second constraint was that the states had not timedtheir implementation of the changes uniformly. Moststates began to implement most of the changes inOctober 1981, but some states did not implementsome provisions until 6 months later, in spring 1982.The variation meant that an aggregation of data fromall states would be problematic and thatgeneralizations would be limited. Consequently, thebaseline for making comparisons would have to shiftfrom state to state.
Another constraint was that the study could not bepredicated on the simple assumption that AFDCrecipients would make choices between welfarefunds and employment funds. AFDC provides directincome support but also enables the recipients todraw on a number of services, most notably healthcare under the Medicaid program. Any study of whypeople choose to stay in or leave the AFDC programhas to account for the other benefits. They could playan important, if not decisive, role in influencingfinancial decisions.
A constraint of a different type had to do with the sizeof the population of working AFDC recipients. Thechanges in the legislation were of immediaterelevance to working families, but their proportion issmall in relation to the total caseload. Nationally, the1979 figure was about 14 percent, but in some states itwas as low as 6 or 7 percent. The small percentagesmeant that data would have to be collected in a waysuch that the numbers of earners would be highenough to make statistical projections meaningful.
GAO/PEMD-10.1.4 Desiging EvaluationsPage 77

Chapter 4
Developing a Design: an Example
These and other constraints told the evaluators thatto refine the evaluation questions, they would have topose a study within, rather than between, the states.Similarly, the evaluators began to see the degree towhich the study would be able to isolate the effect ofthe legislative changes from other causal factors,particularly when addressing AFDC recipients’decisions to stop working and stay on the rolls or toremain off the rolls and seek to support themselvesthrough their own earnings. That is, the 1981 changesto the program were initiated at a time when stateeconomies varied widely, so that the economy couldnot be “held constant,” or presumed to be comparableamong the states. Thus, it had to be considered apossible cause in earners’ decisions. The evaluatorsalso found that their questions would have to accountfor reductions in other social welfare programs.
As the design team refined the questions, given theconstraints on answering them, it was able toexamine data collection and analysis strategies. Thatis, what the evaluators had learned about thequestions, and the considerations of time, cost, staffavailability, and user needs, enabled the design teamto pull together and assess methods for gathering andanalyzing data. The evaluators saw two broadstrategies, one that would primarily analyze availabledata and one that would require the collection oforiginal data.
It was thought that using one of the five available datasets would be an economical and quick way to reportearly findings to the Congress. A data set called the“Job Search Assistance Research Project” (JSARP)was the most promising for a study of the effects ofthe changes in the legislation. JSARP was begun bythe U.S. Department of Labor late in 1978 as alarge-scale effort to measure the effects of job-searchassistance, public-service employment, and job
GAO/PEMD-10.1.4 Desiging EvaluationsPage 78

Chapter 4
Developing a Design: an Example
training on the employment, earnings, and welfaredependence of low-income persons (not all of whomwere AFDC participants). Ten jurisdictions under theComprehensive Employment and Training Act of 1973were chosen as “treatment” sites, where specialdemonstration programs were established to improvethe employment opportunities of the targetpopulation. Each site was matched with a comparisonsite as similar as possible in racial and ethniccomposition, unemployment rate, primary industriesand occupations, size, and location. The researchersinterviewed 30,000 respondents in spring 1979, whenthe demonstration programs were being initiated.Slightly fewer than 3,000 of the respondents had beenAFDC recipients for at least part of the year prior tothe interview. In 1980, a follow-up interview with5,700 of the original respondents used substantiallythe same interviewing instrument; among theserespondents were all who had indicated earlier thatthey had AFDC support, and a large proportion hadincomes below 225 percent of the poverty line. Thus,JSARP provides a lengthy record of earnings, otherincome, work behavior, job search, job training, andfamily composition for a large sample prior to theinstitution of the 1981 changes to AFDC.
The evaluators therefore thought that using abefore-and-after design and the JSARP data, theycould interview the same respondents (or othersselected for their similarity to the JSARPrespondents) with the same or nearly the same datacollection instrument to find out their experiences ofthe 1981 changes. This would provide for acomparison of work and welfare patterns before andafter the program change, although it would notestablish with certainty whether the 1981 act was thesole cause of any difference between the twointerview periods. Nevertheless, statistical analysesmight lead to defensible conclusions about cause.
GAO/PEMD-10.1.4 Desiging EvaluationsPage 79

Chapter 4
Developing a Design: an Example
The alternative strategy, the one that was eventuallyselected, involved collecting before-and-after data atfive sites across the country, making interviews at thefive sites with members of working AFDC householdswho were terminated from AFDC when the 1981 actwas implemented, and analyzing nationalbefore-and-after data on AFDC caseloads and costs.Of the designs we discussed in chapter 3, thisapproach included three designs—a nonequivalentcomparison group design, a one-groupbefore-and-after design, and a national interruptedtime series design.
The plan for the nonequivalent comparison groupdesign was to identify at each site two samples ofAFDC recipients, one from a year and a month beforethe changes and one from the month immediatelypreceding them. The earlier group would provide abaseline from which to look at the dynamics of workand welfare both immediately before and after theimplementation of the act. Both samples would allowfor separate subsamples of working and nonworkingAFDC recipients. Depending on the completeness ofcase records at the sites, the following informationcould be compared: length of participation in AFDC,percentage of AFDC households with earnings atdifferent times, percentage of households leaving andthen returning to the rolls, average dollar amounts ofAFDC benefits and earned income, percentage ofhouseholds drawing on various other welfarebenefits, and reasons for the termination of AFDCpayments. Thus, the comparisons could be bothwithin and between groups and of several typesacross three points in time (the baseline and beforeand after implementation). The evaluators couldcompare the static characteristics of earners andnonearners, the employment status of the variousgroups, and the relationship between changes inadministrative practices and the behavior of the
GAO/PEMD-10.1.4 Desiging EvaluationsPage 80

Chapter 4
Developing a Design: an Example
respondents in terms of the time they spent onAFDC’s rolls, their average net earnings, and whatthey did because of changes in AFDC benefits.
Having decided on this approach, the evaluatorsconstructed interviews within the case studycomponent that were intended to collect data on andassess the economic well-being of the persons whowere removed from the rolls, how they coped withthe loss of benefits, and whether they worked more tokeep up an income. Here, the comparisons were to bewithin groups of households before and after theprogram changes. For example, the evaluators couldcompare household composition, employment status,earnings, and total disposable income. Of particularinterest would be data on whether people increasedtheir work effort or shifted their reliance for supportto other programs such as General Assistance orUnemployment Insurance.
The national analysis component, with its interruptedtime series analysis, would rely on data provided bythe U.S. Department of Health and Human Servicesand by state welfare departments on the operation ofAFDC programs, including the implementation of the1981 provisions, and on caseloads and outlays forAFDC and related programs. The objectives that wereplanned were to document the degree to which the1981 AFDC provisions represented change from pastpractices, to explore their effects on national AFDCcaseloads and costs, and to determine whether somestates tried to negate or reduce the effects of certainprovisions. The design team planned for a request ofall the states to provide GAO with the results of theirown independent evaluations.
Two smaller and complementary components werealso posited. One would use archival data and theother would require conducting interviews with state
GAO/PEMD-10.1.4 Desiging EvaluationsPage 81

Chapter 4
Developing a Design: an Example
and local program officials and staff. The archivaldata would include information on AFDC caseloadfluctuations and local economic conditions.Collecting these data would explore the degree towhich different patterns of dependence on AFDC inthree periods might be the product of events otherthan the AFDC changes, such as a deteriorating labormarket.
Design Phase 3:Settling on aStrategy
In the end, a choice has to be made betweencompeting design options. The difficulty for theevaluator making this choice is in assessing thealternatives. Each one will have strengths andweaknesses, so that the decision comes to what willbe both most feasible and most defensible. In theAFDC study, the choice was made in favor of themultistrategy approach. The JSARP approach usingavailable data and interviewing a sample of theoriginal respondents was dropped.
To be sure, both approaches had strengths, andstrong arguments were made for both. The scalestipped against the simpler approach when it came toweaknesses. There were several reservations aboutusing the JSARP data. There were problems ofaccuracy, precision, and completeness (largelybecause the respondents’ report of AFDCparticipation were retrospective to as far as 18months).
There was a possibility of bias, since 23 percent of theoriginal respondents did not turn up for the secondset of interviews, and the difficulty of finding therespondents for the new study could be even greater.There were not enough earners in the sample. And,finally, practical problems included the fact that theJSARP data were not for public use and might not beobtainable.
GAO/PEMD-10.1.4 Desiging EvaluationsPage 82

Chapter 4
Developing a Design: an Example
In light of all this, the multistrategy approach wasadopted. Even with it, there was concern about theavailability of case records, finding respondents whohad left the AFDC program, the extensive timerequired to code case records at sites that did nothave automated data, the ability to control fordisparate economic conditions site by site, and thesheer volume of data that would have to be gathered,coded, analyzed, and reported. However, compared tothe concern about JSARP, which tended to beanalytical, these problems were more simplyprocedural. In the end, it was concluded that theanalytical problems were a greater threat to theability to answer the study questions than theprocedural ones.
GAO/PEMD-10.1.4 Desiging EvaluationsPage 83

Bibliography
Achen, C. H. The Statistical Analysis ofQuasi-Experiments. Berkeley, Calif.: University ofCalifornia Press, 1986.
Anderson, S., et al. Statistical Methods forComparative Studies. New York: John Wiley andSons, 1980.
Babbie, E. R. The Practice of Social Research, 5th ed.Belmont, Calif.: Wadsworth, 1989.
Babbie, E. R. Survey Research Methods, 2nd ed.Belmont, Calif.: Wadsworth, 1990.
Bainbridge, W. S. Survey Research: AComputer-Assisted Introduction. Belmont, Calif.:Wadsworth, 1989.
Black, J. A., and D. J. Champion. Methods and Issuesin Social Research. New York: John Wiley and Sons,1976.
Boruch, R. F. (ed.) Secondary Analysis. SanFrancisco: Jossey-Bass, 1978.
Boruch, R. F., et al. Reanalyzing Program Evaluations:Policies and Practices for Secondary Analysis ofSocial and Educational Programs. San Francisco:Jossey-Bass, 1981.
Boruch, R. F., and W. Wothke (eds.). Randomizationand Field Experimentation. San Francisco:Jossey-Bass, 1985.
Bowering, D. J. (ed.) Secondary Analysis of AvailableData Bases. San Francisco: Jossey-Bass, 1984.
GAO/PEMD-10.1.4 Desiging EvaluationsPage 84

Bibliography
Bradburn, N. M., and S. Sudman and Associates.Improving Interview Method and QuestionnaireDesign. San Francisco: Jossey-Bass, 1979.
Chelimsky, E. “The Definition and Measurement ofEvaluation Quality as a Management Tool.” In R. G.St. Pierre (ed.). Management and Organization ofProgram Evaluation, pp. 113-26. San Francisco:Jossey-Bass, 1983.
Cohen, J. Statistical Power Analysis for theBehavioral Sciences, 2nd ed. Hillsdale, N.J.: LawrenceErlbaum, 1988
Converse, J. M. and S. Presser. Survey Questions:Handcrafting the Standardized Questionnaire.Newbury Park, Calif.: Sage, 1986.
Cook, T. D. “The Potential and Limitations ofSecondary Data Analysis.” In M. W. Apple, M. J.Subkoviak, and H. S. Lufler, Jr. (eds.). EducationalEvaluation: Analysis and Responsibility, pp. 155-222.Berkeley, Calif.: McCutchan, 1974.
Cook, T. D., and D. T. Campbell.Quasi-Experimentation: Design and Analysis Issuesfor Field Settings. Chicago: Rand McNally, 1979.
Cooper, H. M. The Integrative Research Review: ASystematic Approach, 2nd ed. Newbury Park, Calif.:Sage 1989.
Cronbach, L. J. Designing Evaluations of Educationaland Social Programs. San Francisco: Jossey-Bass,1982.
Forehand, G. A. (ed.). Applications of Time SeriesAnalysis to Evaluation. San Francisco: Jossey-Bass,1982.
GAO/PEMD-10.1.4 Desiging EvaluationsPage 85

Bibliography
Fowler, F. J., Jr. Survey Research Methods, rev. ed.Newbury Park, Calif.: Sage, 1988.
Fowler, F. J., Jr., and T. W. Mangione. StandardizedSurvey Interviewing: Minimizing Interviewer-RelatedError. Newbury Park, Calif.: Sage, 1990.
Glass, G. V, B. McGaw, and M. L. Smith. Meta-Analysisin Social Research. Newbury Park, Calif.: Sage, 1981.
Groves, R. M. Survey Errors and Survey Costs. NewYork: John Wiley and Sons, 1989.
Hausman, J. A., and D. A. Wise (eds.). SocialExperimentation. Chicago: University of ChicagoPress, 1985.
Hayduk, L. A. Structural Equation Modeling withLISREL. Baltimore: Johns Hopkins University Press,1987.
Hedges, L. V., and I. Olkin. Statistical Methods forMeta- Analysis. New York: Academic Press, 1985.
Henry, G. T. Practical Sampling. Newbury Park, Calif.:Sage, 1990.
Herbert, L. Auditing the Performance of Management.Belmont, Calif.: Lifetime Learning Publications, 1979.
Hersen, M., and D. H. Barlow. Single CaseExperimental Designs. New York: Pergamon, 1976.
Hoaglin, D. C., et al. Data for Decisions. Cambridge,Mass.: Abt Books, 1982.
Hunter, J. E., and F. L. Schmidt. Methods ofMeta-Analysis: Correcting Error and Bias in ResearchFindings. Newbury Park, Calif.: Sage, 1989.
GAO/PEMD-10.1.4 Desiging EvaluationsPage 86

Bibliography
Hunter, J. E., F. L. Schmidt, and G. B. Jackson. Meta-Analysis: Cumulating Research Findings AcrossStudies. Newbury Park, Calif.: Sage, 1982.
Hyman, H. H. Secondary Analysis of Sample Surveys.Middletown, Conn.: Wesleyan University Press, 1972.
Jackson, G. B. “Methods for Integrative Reviews.”Review of Educational Research, 50 (1980), 438-60.
Jacob, H. Using Published Data: Errors and Remedies.Newbury Park, Calif.: Sage, 1984.
Judd, C. M., and D. A. Kenny. Estimating the Effectsof Social Interventions. Cambridge, Eng.: CambridgeUniversity Press, 1981.
Judd, C. M., and L. H. Kidder. Research Methods inSocial Relations, 5th ed. New York: Holt, Rinehart andWinston, 1986.
Kalton, G. Introduction to Survey Sampling. NewburyPark, Calif.: Sage, 1983.
Keppel, G. Design and Analysis: A Researcher’sHandbook, 2nd ed. Englewood Cliffs, N.J.:Prentice-Hall, 1982.
Keppel, G., and S. Zedeck. Data Analysis for ResearchDesigns. New York: W. H. Freeman, 1989.
Kiecolt, K. J., and L. E. Nathan. Secondary Analysis ofSurvey Data. Newbury Park, Calif.: Sage, 1985.
Kish, L. Survey Sampling. New York: John Wiley andSons, 1965.
Kish, L. Statistical Design for Research. New York:John Wiley and Sons, 1987.
GAO/PEMD-10.1.4 Desiging EvaluationsPage 87

Bibliography
Kraemer, H. C., and S. Thiemann. How ManySubjects? Statistical Power Analysis in Research.Newbury Park, Calif.: Sage, 1987.
Lee, E. S., R. N. Forthofer, and R. J. Lorimor.Analyzing Complex Survey Data. Newbury Park,Calif.: Sage, 1989.
Light, R. J., and D. B. Pillemer. Summing Up: TheScience of Reviewing Research. Cambridge, Mass.:Harvard University Press, 1984.
Lipsey, M. Design Sensitivity: Statistical Power forExperimental Research. Newbury Park, Calif.: Sage,1990.
Marshall, C., and G. G. Rossman. DesigningQualitative Research. Newbury Park, Calif.: Sage,1989.
McCleary, R., and R. A. Hay. Applied Time SeriesAnalysis for the Social Sciences. Newbury Park, Calif.:Sage, 1980.
McGrath, J. E., J. Martin, and R. A. Kulka. JudgmentCalls in Research. Newbury Park, Calif.: Sage, 1982.
Miles, M. B., and M. Huberman. Qualitative DataAnalysis. Newbury Park, Calif.: Sage, 1984.
Mohr, L. B. Impact Analysis for Program Evaluation.Chicago: Dorsey, 1988.
Noblit, G. W., and R. D. Hare. Meta-Ethnography:Synthesizing Qualitative Studies. Newbury Park,Calif.: Sage, 1988.
Patton, M. Q. Qualitative Evaluation and ResearchMethods, 2nd ed. Newbury Park, Calif.: Sage, 1990.
GAO/PEMD-10.1.4 Desiging EvaluationsPage 88

Bibliography
Payne, S. L. The Art of Asking Questions. Princeton,N.J.: Princeton University Press, 1951.
Pedhazur, E. L. Mulitple Regression in BehavioralResearch, 2nd ed. New York: Holt, Rinehart andWinston, 1982.
Popham, W. J. Educational Evaluation. EnglewoodCliffs, N.J.: Prentice-Hall, 1975.
Posavac, E. J., and R. G. Carey. Program Evaluation:Methods and Case Studies, 3rd ed. Englewood Cliffs,N.J.: Prentice-Hall, 1989.
Provus, M. M. Discrepancy Evaluation. Berkeley,Calif.: McCutchan, 1971.
Rosenthal, R. Meta-Analytic Procedures for SocialResearch. Newbury Park, Calif.: Sage, 1984.
Rossi, P. H., and H. E. Freeman. Evaluation: ASystematic Approach, 4th ed. Newbury Park, Calif.:Sage, 1989.
Runkel, P. J., and J. E. McGrath. Research on HumanBehavior: A Systematic Guide to Method. New York:Holt, Rinehart, and Winston, 1972.
Saxe, L., and M. Fine. Social Experiments: Methodsfor Design and Evaluation. Newbury Park, Calif.:Sage, 1981.
Scheaffer, R. L., W. Mendenhall, and L. Ott.Elementary Survey Sampling, 4th ed. Boston:PWS-Kent, 1990.
Spector, P. E. Research Designs. Newbury Park,Calif.: Sage, 1981.
GAO/PEMD-10.1.4 Desiging EvaluationsPage 89

Bibliography
Steinmetz, A. “The Discrepancy Evaluation Model.”In: G. F. Madaus, M. Scriven, and D. L. Stufflebeam(eds.) Evaluation Models: Viewpoints on Educationaland Human Services Evaluation. Boston:Kluwer-Nijhoff, 1983.
Stewart, D. W. Secondary Research: InformationSources and Methods. Newbury Park, Calif.: Sage,1984.
Strauss, A. L. Qualitative Analysis for SocialScientists. Cambridge, Eng.: Cambridge UnviersityPress, 1987.
Strauss, A. L., and J. Corbin. Basics of QualitativeResearch. Newbury Park, Calif.: Sage, 1990.
Sudman, S. Applied Sampling. New York: AcademicPress, 1976.
Tesch, R. Qualitative Research: Analysis Types andSoftware Tools. New York: Taylor and Francis, 1990.
U.S. General Accounting Office. The EvaluationSynthesis, methods paper I. Washington, D.C.:April 1983.
U.S. General Accounting Office. Using StructuredInterviewing Techniques, methodology transfer paper5. Washington, D.C.: July 1985.
U.S. General Accounting Office. Using StatisticalSampling, transfer paper 6. Washington, D.C.:April 1986a.
U.S. General Accounting Office. Developing and UsingQuestionnaires, transfer paper 7. Washington, D.C.:July 1986b.
GAO/PEMD-10.1.4 Desiging EvaluationsPage 90

Bibliography
U.S. General Accounting Office. Case StudyEvaluations, transfer paper 10.1.9. Washington, D.C.:November 1990.
Wachter, K. W., and M. L. Straf (eds.). The Future ofMeta- Analysis. New York: The Russell SageFoundation, 1990.
Warwick, D. P., and C. A. Lininger. The SampleSurvey: Theory and Practice. New York: McGraw-Hill,1975.
Wholey, J. S. Evaluation: Promise and Performance.Washington, D.C.: Urban Institute, 1979.
Wolf, F. M. Meta-Analysis: Quantitative Methods forResearch Synthesis. Newbury Park, Calif.: Sage, 1986.
Yeaton, W. H., and P. M. Wortman (eds.). Issues inData Synthesis. San Francisco: Jossey-Bass, 1984.
Yin, R. K. Case Study Research: Design and Methods.rev. ed. Newbury Park, Calif.: Sage, 1989.
Yin, R. K., and K. A. Heald. “Using the Case SurveyMethod to Analyze Policy Studies.” AdministrativeScience Quarterly, 20 (September 1975), 371-81.
GAO/PEMD-10.1.4 Desiging EvaluationsPage 91

Glossary
Bias The extent to which a measurement or a sampling oranalytic method systematically underestimates oroverestimates a value.
Construct An attribute, usually unobservable, such aseducational attainment or socioeconomic status, thatis represented by an observable measure.
Construct Validity The extent to which a measurement methodaccurately represents a construct and produces anobservation distinct from that produced by a measureof another construct.
Covariation The degree to which two measures vary together.
Cross-Sectional Data Observations collected on subjects or events at asingle point in time.
External Validity The extent to which a finding applies (or can begeneralized) to persons, objects, settings, or timesother than those that were the subject of study.
Generalizability Used interchangeably with “external validity.”
Internal Validity The extent to which the causes of an effect areestablished by an inquiry.
Longitudinal Data Sometimes called “time series data,” observationscollected over a period of time; the sample (instancesor cases) may or may not be the same each time butthe population remains constant.
GAO/PEMD-10.1.4 Desiging EvaluationsPage 92

Glossary
Measurement A procedure for assigning a number to an observedobject or event.
Panel Data A special form of longitudinal data in whichobservations are collected on the same sample ofrespondents over a period of time.
Probability Sampling A method for drawing a sample from a populationsuch that all possible samples have a known andspecified probability of being drawn.
ProgramEffectivenessEvaluation
The application of scientific research methods toestimate how much observed results, intended or not,are caused by program activities. Effect is linked tocause by design and analysis that compare observedresults with estimates of what might have beenobserved in the absence of the program.
Program Evaluation The application of scientific research methods toassess program concepts, implementation, andeffectiveness.
Qualitative Data Information expressed in the form of words. (Notethat in some of the references cited, qualitative datameans numerical information in which the amount ofthe difference between two numbers is notmeaningful.)
Quantitative Data Information expressed in the form of numbers.Measurement gives a procedure for assigningnumbers to observations. See Measurement.
GAO/PEMD-10.1.4 Desiging EvaluationsPage 93

Glossary
Random Assignment A method for assigning subjects to two or moregroups by chance.
Reliability The quality of a measurement process that wouldproduce similar results on (1) repeated observationsof the same condition or event or (2) multipleobservations of the same condition or event bydifferent observers.
RepresentativeSample
A sample that has approximately the samedistribution of characteristics as the population fromwhich it was drawn.
Simple RandomSample
A method for drawing a sample from a populationsuch that all samples of a given size have equalprobability of being drawn.
StatisticalConclusion Validity
The extent to which the observed statisticalsignificance (or the lack of statistical significance) ofthe covariation between two or more variables isbased on a valid statistical test of that covariation.
Structured Interview An interview in which questions to be asked, theirsequence, and the detailed information to be gatheredare all predetermined; used where maximumconsistency across interviews and interviewees isneeded.
Treatment Group The subjects of the intervention being studied.
GAO/PEMD-10.1.4 Desiging EvaluationsPage 94

Papers in This Series
This is a flexible series continually being added to andupdated. The interested reader should inquire aboutthe possibility of additional papers in the series.
The Evaluation Synthesis. Transfer paper 10.1.2,formerly methods paper I.
Content Analysis: A Methodology for Structuring andAnalyzing Written Material. Transfer paper 10.1.3,formerly methodology transfer paper 3.
Designing Evaluations. Transfer paper 10.1.4,formerly methodology transfer paper 4.
Using Structured Interviewing Techniques. Transferpaper 10.1.5, formerly methodology transfer paper 5.
Using Statistical Sampling. Transfer paper 10.1.6,formerly methodology transfer paper 6.
Developing and Using Questionnaires. Transfer paper10.1.7, formerly methodology transfer paper 7.
Case Study Evaluations. Transfer paper 10.1.9,formerly methodology transfer paper 9.
Prospective Evaluation Methods: The ProspectiveEvaluation Synthesis. Transfer paper 10.1.10, formerlymethodology transfer paper 10.
(973317) GAO/PEMD-10.1.4 Desiging EvaluationsPage 95

Ordering Information
The first copy of each GAO report and testimony
is free. Additional copies are $2 each. Orders
should be sent to the following address,
accompanied by a check or money order made
out to the Superintendent of Documents, when
necessary. VISA and MasterCard credit cards
are accepted, also. Orders for 100 or more
copies to be mailed to a single address are
discounted 25 percent.
Orders by mail:
U.S. General Accounting Office
P.O. Box 6015
Gaithersburg, MD 20884-6015
or visit:
Room 1100
700 4th St. NW (corner of 4th & G Sts. NW)
U.S. General Accounting Office
Washington, DC
Orders may also be placed by calling
(202) 512-6000 or by using fax number
(301) 258-4066, or TDD (301) 413-0006.
Each day, GAO issues a list of newly available
reports and testimony. To receive facsimile
copies of the daily list or any list from the past
30 days, please call (202) 512-6000 using a
touchtone phone. A recorded menu will provide
information on how to obtain these lists.
For information on how to access GAO reports
on the INTERNET, send an e-mail message with
"info" in the body to:

United States
General Accounting Office
Washington, D.C. 20548-0001
Official Business
Penalty for Private Use $300
Address Correction Requested
Bulk Rate
Postage & Fees Paid
GAO
Permit No. G100