design and performance of the eclipse microprocessor ... · design and performance of the eclipse...
TRANSCRIPT

Page 1Eclipse Processor:Final Report (Group 7)
Design and Performance of theEclipse Microprocessor modeled in VHDL
Vickie ChanSID# 13422728 chanv@cory
Jason ChenSID# 12838890 jas_chen@uclink4
Jeff HermanSID# 13016674 jefe@csua
Brenda LiuSID# 13112442 brendal@csua
Carlo OrdonezSID# 12774233 cordonez@cory
December 9, 1999TA: Kelvin Lwin
Professor: John KubiatowiczCS152 Final Project; Group #7

Page 2Eclipse Processor:Final Report (Group 7)
1.0 Introduction: . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
2.0 Overview: . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 42.1 Block Level Description . . . . . . . . . . . . . . . . . . . . . . 42.2 Performance Summary . . . . . . . . . . . . . . . . . . . . . . . 6
3.0 Features: . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 73.1 Superscalar Datapath . . . . . . . . . . . . . . . . . . . . . . . . 83.2 Branch/Jump Prediction . . . . . . . . . . . . . . . . . . . . . . 93.3 Interleaved Memory . . . . . . . . . . . . . . . . . . . . . . . . 113.4 Fully Associative, Write-Back Cache . . . . . . . . . . . . . . . . . 123.5 Load Value Prediction . . . . . . . . . . . . . . . . . . . . . . 15
4.0 Performance: . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 154.1 Critical Path . . . . . . . . . . . . . . . . . . . . . . . . . . . 164.2 Performance . . . . . . . . . . . . . . . . . . . . . . . . . . 18
5.0 Testing/Validation: . . . . . . . . . . . . . . . . . . . . . . . . . . . 205.1 Monitor . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 205.2 Functional Verification . . . . . . . . . . . . . . . . . . . . . . 215.3 Progressive Verification . . . . . . . . . . . . . . . . . . . . . . 215.4 Bug Count Hysteresis . . . . . . . . . . . . . . . . . . . . . . . 21
6.0 Conclusion: . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
Appendix:Block Summary . . . . . . . . . . . . . . . . . . . . . . . . . . . ASchematics . . . . . . . . . . . . . . . . . . . . . . . . . . . . . BTest Programs . . . . . . . . . . . . . . . . . . . . . . . . . . . . CVHDL Components . . . . . . . . . . . . . . . . . . . . . . . . . . DReferences . . . . . . . . . . . . . . . . . . . . . . . . . . . . . EOnline Logs . . . . . . . . . . . . . . . . . . . . . . . . . . . . . F

Page 3Eclipse Processor:Final Report (Group 7)
The Eclipse processor is a two-way superscalar processor supporting non floating point MIPS R2000 instructions
designed in VHDL and simulated in Workview CAD. It serves as a learning tool designed to teach the fundamen-
tal principles of computer architecture as well as using a high level hardware description language. In addition to
the basic requirements set forth in this project, the following features were implemented: two-way superscalar
pipeline, branch/jump prediction, 64-bit interleaved memory bus, and a fully associative, write-back cache. These
optional features were chosen to improve the performance of Eclipse by reducing memory latency (through pre-
diction and caching), and increasing the datapath bandwidth (through larger busses and the superscalar architec-
ture). The addition of these features results in a 45% decrease in execution time, as comapred to the lab 6 datapath
reference, mainly due to our increased clock rate. This report discusses these design features in detail, as well as
provide an analysis of performance as compared to a reference design, testing methadology, and all schematics
and VHDL modules used to implement Eclipse. Additionally, all user journals are included as well.

Page 4Eclipse Processor:Final Report (Group 7)
The Eclipse processor is based on the MIPS R2000 architecture, employing a standard, five-stage pipeline. It
includes a DRAM module that is substantially slower when reading/writing than the datapath, as shown in the
block diagram in figure 1. In addition, it supports the following four additional features:
A block diagram of the Eclipse processor is contained in figure 1 below. It consists of a 5 stage pipeline, with the
addition of a dram block, cache controller, branch/jump prediction, and standard datapath components.
Figure 1: An overall block diagram of the Eclipse pipeline. Because this is a superscalardatapath, there are two pipes, as shown in the EX stage with the double ALU units. Addi-tionally, the memory architecture, which consists of the cache in the MEM/WB stage, in-struction cache in the ID stage and other components have been updated to include a wide64 bit bus to keep both pipes fed, as well as associated arbiters to properly route this data.The branch/jump prediction unit is located in the IF stage and bypasses the pipeline stallthat would normally be needed to compute branch or jump (which occur in the ID stage).The branch/jump prediction unit is updated in the ID stage.

Page 5Eclipse Processor:Final Report (Group 7)
Superscalar Datapath:
To increase insruction throughput, thus lowering average CPI, a superscalar pipeline was created. As opposed to
a multi-processing or multi-threaded solution to the same problem, a superscalar architecture maintains the ab-
straction between the hardware and software so the programmers don't have to understand he underlying hard-
ware. Otherwise existing programs would have to be re-written to take advantage of multi-processing or multi-
threading. However, intelligent compiling can and will incraease performance on a superscalar pipeline by mini-
mizing data hazards.
Memory Architecture:
To decrease the time spent on accessing memory, we implemented a fully associative, write back cache. We
implemented an interleaved memory system with a 64 bit bus to fully utilize the two word block size of the cache.
Branch/Jump Prediction:
Branch and jump prediction was implemented to minimize pipeline stalls due to the extra stage required to calcu-
late a branch or jump. The predictors execute during the IF stage, preventing stalls in the pipeline. Since the
branch and jump predictors work in a similar fashion, we decided to combine them into one unit.
Load Value Prediction:
Also under consideration as an enhancement to the Eclipse processor is a load value predictor, which is designed
to further decrease CPI. However, upon implementation it was determined that the additional hardware necessary
to undo a misprediction would unduly increase cycle time, thus outweighing any potential decrease in CPI. Thus
load value prediction is not implemented in the Eclipse processor; however, this idea may be revisited in future
processors if it proves to be feasible and worthwhile.

Page 6Eclipse Processor:Final Report (Group 7)
Overall performance (as measured by average CPI and cycle time) information is contained in Table 1 below. This
is a approximately a 45% improvement over our reference processor design, which was the standard lab 6 proces-
sor also designed by us. We achieved an average CPI of 2.41, an 8.45% improvement over the reference CPI of
2.65, and a cycle time of 30ns, a 25% improvement over the orignal cycle time of 40ns. Using a quicksort test
program, our total execution time was 176.5 µs, a 45% improvement over our reference execution time of 255.2
µs. On the whole, most of our performance gain is derived from improvements in our datapath that lowered our
minimum clock cycle time. A more detailed analysis of our performance is in the performance section of this
report.
Quicksort Algorithm Instructions Cycles CPI Clock Time
Standard Pipeline 2436 6380 2.619 25 255.2 µsSuperscalar Pipeline 2436 5884 2.415 33.33 176.5 µs
% Improvement 0.00% 7.77% 7.79% 33.33% 44.59%
Table 1: A performance summary of our processor compared to the reference lab 6 proces-sor. Overall performance, as measured by execution time, increased 45%, mostly due toimprovements in the minimum cycle time of the new datapath.

Page 7Eclipse Processor:Final Report (Group 7)
To enhance the performance of the Eclipse processor, the following features were implemented.
Superscalar Datapath:
This allows for higher throughput by issuing two instructions per clock cycle, thus lowering CPI. A major chal-
lenge in implementing this feature is resolving pipeline hazards and forwarding that is necessary to prevent unnec-
essary pipeline stalls.
Branch/Jump Prediction:
This minimizes pipeline stalls by predicting whether branch instructions are taken instead of stalling the pipeline
several cycles to determine whether a branch actually occurs. Likewise, jump prediction saves a pipeline stall by
determining a jump destination one stage earlier than a standard pipeline would. Typically, this prediction unit is
about 90% accurate. For the case when a prediction is wrong, a squash signal is necessary to "undo" instructions
that have been executed erroneously and to update the branch/jump prediction tables.
Interleaved Memory:
By doubling the memory bandwidth, dram access latencies can be minimized. There is no major challenges
involved in implementing this feature.
Fully Associative, Write-Back Cache:
A fully associative cache minimizes conflict errors, but adds significantly to silicon area cost. A write-back policy
instead of a write-through policy decreases average memory access time by minimizing dram accesses.
Load Value Prediction:
This feature was initially considered an implemented. However, upon further testing, it has been determined that the
gain of adding this feature is offset by increases in minimum cycle time, which adversely affected execution time. Thus,
the negatives outweighed any potential gain from load value prediction, and was thus not included in our final processor.

Page 8Eclipse Processor:Final Report (Group 7)
The superscalar pipeline was implemented using the standard pipeline duplicated twice. Both pipelines are sym-
metric allowing any instruction to execute in either pipeline as long as aligned instructions execute in pipeline B
while unaligned instructions execute in pipeline A. The following is a high level representation of the superscalar
pipeline.
For purposes of hazard detection and forwarding the B pipeline is skewed slightly ahead of the A pipeline. This
does not mean that B executes ahead of A but is used to relate modules to each other when data hazards arise in the
pipeline.
The vast majority of complexity arrises in the IF stage since this has to account for our branch prediction mecha-
nism. The superscalar PC increments by a double word and requires that they be double word aligned. This is
problematic during branches because target addresses can be non-double-word aligned, in which case, only the
second instruction gets executed. The PC is self correcting the realign itself against a double word boundry. The
IF module also needs to be self-correcting in order to handle branch mis-prediction recovery.
The ID stage was modified to account for 4 register reads and 2 register writes simultaneously. Similarly, the
MEM stage includes an arbitrator between the upper and lower portions of the pipeline in case multiple memory
accesses occur simultaneously. Memory RAW hazards (hazards that arise due to address location dependencies
and not register name dependencies such as a lw followed by a sw) do not exist because the MEM pipeline arbiter
insures that MEMB operations are serviced before MEMA operations.
Figure: Illustration of the superscalar pipeline.

Page 9Eclipse Processor:Final Report (Group 7)
This minimizes pipeline stalls by predicting whether branch instructions are taken instead of stalling the pipeline
several cycles to determine whether a branch actually occurs. Likewise, jump prediction saves a pipeline stall by
determining a jump destination one stage earlier than a standard pipeline would. Typically, this prediction unit is
about 90% accurate. For the case when a prediction is wrong, a squash signal is necessary to "undo" instructions
that have been executed erroneously and to update the branch/jump prediction tables.
Since jump prediction is so similar to branch prediction, in that a target address is associated with an instruction,
except in the case of a jump, the branch is always taken. Thus jump prediction should never predict a jump not
taken. Also, the jump target does not change once it is set for the j and jal instructions. We do not employ jump
prediction for the jr instruction, since the target is likely to change nearly ever iteration, negating any potential
benefit from using prediction.
Upon initial startup, the branch/jump table is completely empty. This table operates much like a cache, in that the
lower order bits of a lookup PC are used to select a direct mapped block. This block entry has a tag which is then
compared to the higher order bits of the PC to see if there is a match. Initially, upon startup, every entry in the
branch/jump prediction table has a tag initialized to 0. Thus there will be an initial misprediction at address 0.
This, however, is not a problem, as the datapath will recover by itself. For this misprediction will be detected
within a few clock cycles, the proper branch address will be placed in the branch/jump prediction table and all
erroneosly executed instructions squashed. All subsequent accesses to the branch/jump prediction table will then
be directed to the appropriateblock, and predictions will proceed as normally expected. Initially, this branch/jump
prediction unit always predicts a branch/jump. It utilizes a second-chance algorithm, in that there has to be two
consecutive mispredictions before the branch/jump prediction block changes its prediction. According to the
book, there is a 90% accuracy when using this algorithm.
The jump/branch prediction unit uses a 64 bit direct mapped table. Each block inside this table is 58 bits wide; 24
bits devoted to the tag, 2 bits devoted to the status bits (to implement a second chance algorithm), as well as the 32

Page 10Eclipse Processor:Final Report (Group 7)
24 8
1BLOCK
0
…
BLOCK
63BLOCK
Tag BlockP C
Figure: In the lookup stage of our branch/jump prediction unit, the PC is split up into ablock and a tag. The block is used to mux in the appropriate entry, while the tag is used toverify the validity of the data inside the entry. If both these conditions are met, then abranch/jump to the target_address will be taken if branch_jump is asserted.
bit branch/jump target. Every clock cycle in the IF stage, the current PC is fed as an input into the branch/jump
prediction unit. If there is a match, then the branch/jump prediction table outputs a target address as well as a bit
signal called status1 that determines what the branch prediction is. A high value indicates a predicted branch,
while a low value indicates a non predicted branch.
Simultaenously, there is a second set of inputs with a PC_IN signal that automatically selects the appropriate block
that selects the approrpriate block that handles that PC, and checks to see if the tag matches. If these conditions
met, and the update signal is asserted, then the contents of that particular block gets updated with the new target,
tag and branch prediction.
A detailed block diagram of both branch/jump prediction lookup and updating are contained in the following two
figures below.

Page 11Eclipse Processor:Final Report (Group 7)
24 8
1BLOCK
0
…
BLOCK
63BLOCK
Tag BlockP C_I N
Figure: In the update stage of our branch/jump prediction unit, the update_PC is split upinto a block and a tag. The block is used to select the appropriate block entry. The tag,branch_jump, and target address are then updated into the block. Each block is written inVHDL to implement a second chance algorithm, whereby, there needs to be two consecutivemispredictions before the branch/jump prediction unit changes its prediction.
Dram is inherently slow. Each memory access, be it reading or writing, necessitates several hundred cycles. This
large latency inhibits processor performance by lowering CPI. Thus, methods of minimizing memory accesses
(through caching, to be discussed in the next section), and decreasing average memory access time are highly
desireable.
Interleaved memory helps decrease average memory access time. It allows for two words to be loaded at the same
time, instead of synchornously, in the case of non interleaved memory. To support this feature, we designed our
cache system to load in 2 words in each set per block. Thus all reads and writes to the cache (including loads and
evictions) are handled in 64 bit chunks instead of 32 bit chunks to take advantage of interleaved memory.

Page 12Eclipse Processor:Final Report (Group 7)
In addition to decreasing average memory access times, using a 2 word set takes advantage of spacial locality, in
that there is a high probabilty that once a particular word has been fetched from memory, other words close to the
address at which the original word was fetched from will also be required soon as well.
Dram
ControllerMEM
1
MEM 2
32
32Data
Cache
InstrCache
Data/Instr
Arbiter64
64 64
Dram32
32DramPipe-
lineArbiter
32
IF 1
IF 232
32
Figure: Interleaved memory reduces average memory access time by loading in consecutivewords in parralel from two adjacent DRAM blocks. Because of this interleaving, a two wordintruction and data cache were required, as well as the controller and arbiter necessary toffed these two caches.
Since the overall size of the cache is limited by project specifications, and is relatively small at only 16 entries, we
sought to maximize performance at the expense of complexity. Consequently, the cache system used in the
Eclipse processor has been designed to be fully associative to eliminate conflict misses. This was done through
adding 16 comparators so that every single block in the cache can be inspected each cycle. Because of the full
associativity, all tags are 32-bit. By maximizing the hit rate of our cache we hope to minimize the amount of
DRAM accesses necessary.

Page 13Eclipse Processor:Final Report (Group 7)
A second method employed to reduce the number of DRAM accesses was to employ a writeback coherency policy
instead of a write through policy. In a write through policy, any time a cache entry is updated, it gets copied
immediately to DRAM. This can cause unnecessary DRAM accesses if a particular word in memory is repeatedly
overwritten (as could happen in a loop). A write-back policy on the other hand, only copies a given cache entry
into DRAM upon an eviction. Thus as long as a particular word in cache does not get evicted (as would happen if
it were to be repeatedly written to), then unnecessary DRAM accesses can be avoided further enhancing perfor-
mance.
Figure: Since our cache size is small (only 16 words, limited by project specifications),we chose to implement a fully associative cache to eliminate conflict misses. Whileexpensive in hardware, it is feasible given the small size of the cache. We used seperateinstruction and data caches. Since words in the data cache may change, we used awrite-back policy to ensure coherency between DRAM and cache.
Dram
ControllerMEM
1
MEM 2
32
32Data
Cache
InstrCache
Data/Instr
Arbiter64
64 64
Dram32
32DramPipe-
lineArbiter
32
IF 1
IF 232
32

Page 14Eclipse Processor:Final Report (Group 7)
Figure: Because of our seperate data and instruction caches, we need an arbiter tocontrol the flow of words from the dram controller. To prevent starvation, we alwaysgive higher priority to the data cache. This is because if there are a finite amount ofinstructions in the cache, then there is also a finite amount of data in the data cache.However, if priority is given to the instruction cache, then starvation is a possiblitywith the data cache, as there is an unbounded amount of instructions that could poten-tially be executed. Likewise, with a supserscalar pipeline, a second arbiter is needed toarbitrate data from the data cache to the two pipes. Again, to prevent starvation,priority is given to the first pipeline memory stage.
Dram
ControllerMEM
1
MEM 2
32
32Data
Cache
InstrCache
Data/Instr
Arbiter64
64 64
Dram32
32DramPipe-
lineArbiter
32
IF 1
IF 232
32
Because of the seperate instruction and data caches, as well as interleaved DRAM banks, arbiters are necessary to
control bus conflicts. To prevent starvation, we always give higher priority to the data cache. This is because if
there are a finite amount of instructions in the cache, then there is also a finite amount of data in the data cache.
However, if priority is given to the instruction cache, then starvation is a possiblity with the data cache, as there is
an unbounded amount of instructions that could potentially be executed. Likewise, with a supserscalar pipeline, a
second arbiter is needed to arbitrate data from the data cache to the two pipes. Again, to prevent starvation, priority
is given to the first pipeline memory stage.

Page 15Eclipse Processor:Final Report (Group 7)
A load value predictor, which is designed to further decrease CPI, was initially planned to be included in the
processor. However, upon implementation it was determined that the additional hardware necessary to undo a
misprediction would unduly increase cycle time, thus outweighing any potential decrease in CPI. Thus load value
prediction is not implemented in the Eclipse processor; however, this idea may be revisited in future processors if
it proves to be feasible and worthwhile.
The three components that dictate performance are instruction count, CPI, and cycle time. In this lab we do not
consider the instruction count since that is dependent on the ISA and compiler. However, we do have a fair amount
of control over the average CPI and cycle time but not without comprimises that effect both components.
We attacked the CPI problem by allowing multiple instructions to be issued simultaneously. Although superscalar
execution increases the maximum throughput of a program’s execution, maximum throughput may not be sus-
tained unless we have other mechanisms to allow non-interlocking execution. These mechanisms include branch
and jump target prediction, load value prediction, and good memory systems. The Tomasulo algorithm may also
be used to prevent certain operations from blocking superscalar execution.
However, due to the complexity of Tomasulo, the possibility that the algorithm will cut into the cycle time in-
creases drastically. For this reason, Tomasulo was not implemented and other options to sustain the high through-
put were looked into. Branch prediction on jump target prediction are key components to allowing instructions to
be issued before branch decisions are actually made at the ID stage. We also implemented load value prediction
(LVP). However, the actual use of LVP actually cut too deep into our processor’s cycle time so it was never
actually installed.

Page 16Eclipse Processor:Final Report (Group 7)
In order to decrease our cycle time, we noticed what mistakes were made on lab6. The critical path in lab6
involved computations performed either at the EX stage (20 ns) or MEM stage (20.6 ns) whose data could be
forwarded back to the ID stage where branch decisions were made. As it turns out, much of the branch hardware
actually comprised a significant portion of the critical path.
critical path = tCKO (3 ns) + ALU logic (20 ns) + forwarding mux (2.5 ns) + comparator (10 ns) + branch hardware (6.5 ns) ————————————-
42 ns
Although we were able to cut down on the delay through our comparator by deisgning our own resulting in a 2.8
ns comparator, the branch hardware dramatically increased in complexity due to multiple issues with branch
prediction, mis-prediction detection and recovery hardware resulting in branch hardware that requires 14.5 ns.
The final breakdown of the branch hardware are as follows: 32-bit comparator (2.8 ns) + branch controller (3 ns)
RegPC =
Branch HW
IF ID EX
Figure: The critical path of our lab 6 processor with forwarding.
Page 17Eclipse Processor:Final Report (Group 7)
+ 5 input multiplexor (3.5 ns) + 32-bit comparator (2.8 ns) + nor/inv (0.7 ns) + 2-input multiplexor (1.5 ns) = 14.3
ns. We rounded it up to 14.5 ns for saftey margins.
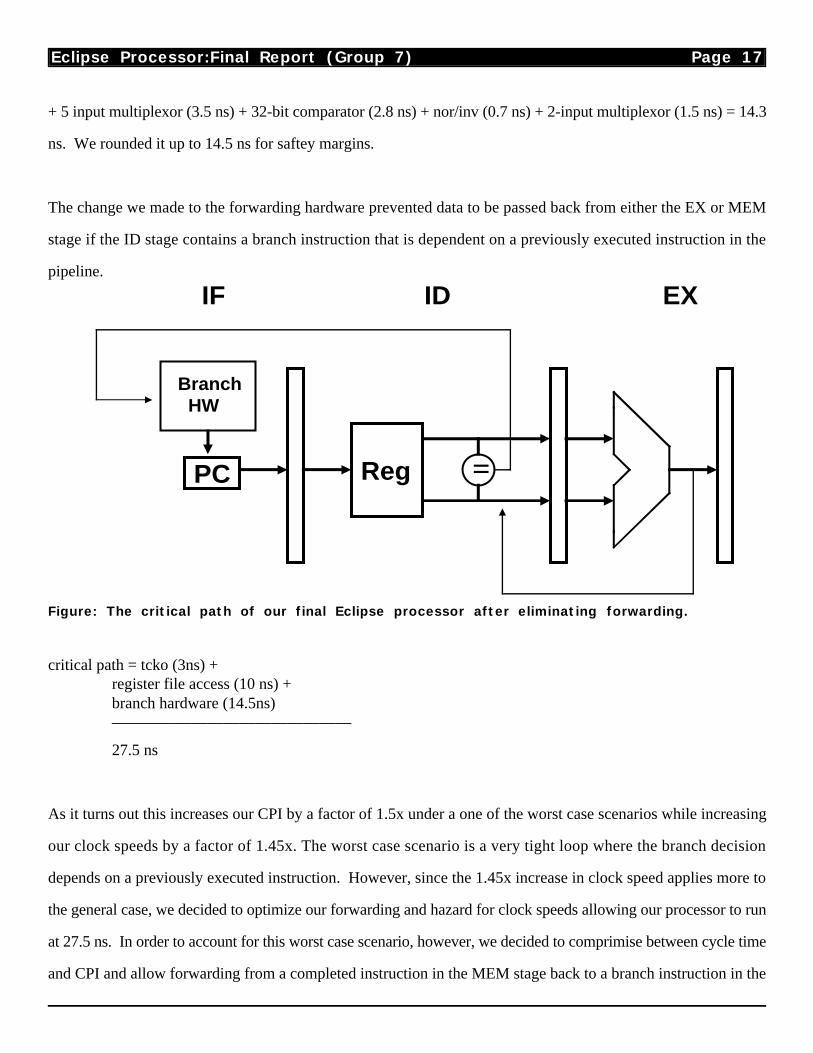
The change we made to the forwarding hardware prevented data to be passed back from either the EX or MEM
stage if the ID stage contains a branch instruction that is dependent on a previously executed instruction in the
pipeline.
critical path = tcko (3ns) + register file access (10 ns) + branch hardware (14.5ns) ———————————————
27.5 ns
As it turns out this increases our CPI by a factor of 1.5x under a one of the worst case scenarios while increasing
our clock speeds by a factor of 1.45x. The worst case scenario is a very tight loop where the branch decision
depends on a previously executed instruction. However, since the 1.45x increase in clock speed applies more to
the general case, we decided to optimize our forwarding and hazard for clock speeds allowing our processor to run
at 27.5 ns. In order to account for this worst case scenario, however, we decided to comprimise between cycle time
and CPI and allow forwarding from a completed instruction in the MEM stage back to a branch instruction in the
RegPC =
Branch HW
IF ID EX
Figure: The critical path of our final Eclipse processor after eliminating forwarding.

Page 18Eclipse Processor:Final Report (Group 7)
ID stage. Since lw values are forbidden to be forwarded no logic will cut into our cycle time other than some
simple forwarding logic. Our final cycle time is the following:
critical path = tcko (3ns) + register file access (10 ns) + forwarding from MEM stage (2.5 ns) + branch hardware (14.5ns) ———————————————
30 ns
This allows our processor to run at slightly past 33 MHz as opposed to 25 Mhz giving us a 33% performance gain
in terms of clock speed alone.
In order to optimize for CPI we included a branch and jump target predictor. The following shows an estimated
moving weighted average (EMWA, a = 0.25) of the unified branch/jump target predictor running against the
quicksort algorithm.
Branch Prediction Accuracy
20.00%
30.00%
40.00%
50.00%
60.00%
70.00%
80.00%
90.00%
100.00%
Number of Branch Predictions
Figure: Estimated Moving Weighted Average (EWMA) for the branch/jump prediction unit. Itaverages out to approximately 87%.

Page 19Eclipse Processor:Final Report (Group 7)
The prediction accuracy quickly rises to an acceptable rate. After completing the quicksort algorithm, the branch
and jump target prediction monitor reported an 87% rate of accuracy. The spikes that can be observed from the
graph are a result of the nature of the way the quicksort algorithm works in which there are many conditions that
do not stay constant as well as converging loop lengths causing loops to exit quickly.
However, for various reasons, our superscalar execution did not increase our CPI performace as much as we had
intended. The main reason being that the unresolvable hazards exists with the algorithms that we ran. This is
something we cannot deal with since we have no control over the compiler and are not allowing instructions to
execute out-of-order.
From running the quicksort algorithm be observe that the total perfomance increased by a factor of 44.6%. Most
of the improvement was a result of our increased clock rates whereas only a small factor of that performance gain
was a direct result of the CPI enhancements. The final results we obtained were that superscalar execution coupled
with branch and jump target prediction only resulted in an 8.45% gain in CPI performance. These results were
disappointing given that the pipeline can issue 2 instructions simultaneously. However, it should be noted that
without all the mechanisms required to sustain superscalar execution’s maximum throughput rate superscalar will
not decrease the CPI dramatically.
Quicksort Algorithm Instructions Cycles CPI Clock Time
Standard Pipeline 2436 6380 2.619 25 255.2 µsSuperscalar Pipeline 2436 5884 2.415 33.33 176.5 µs
% Improvement 0.00% 7.77% 7.79% 33.33% 44.59%
Table 2: A performance summary of our processor compared to the reference lab 6 proces-sor. Overall performance, as measured by execution time, increased 45%, mostly due toimprovements in the minimum cycle time of the new datapath.

Page 20Eclipse Processor:Final Report (Group 7)
Extensive testing was performed to very the proper operation of the Eclipse processor. In any large-scale design,
it becomes nearly impossible to test and account for every possible combination of test cases that may occur on a
given processor design. Indeed, recent processors have all contained errata in them that slipped through testing.
Multiple testing procedures are relied upon to predict proper operation of the CPU and are summarized below.
To help understand what is actually happening inside the Eclipse pipeline, monitor modules written in VHDL
were inserted inside every pipeline stage as well as inside the branch/jump prediction unit. The purpose of the
monitor is to log all relevant control signals, and output important bus values. This data is then later analyzed
against expected output from a fully functioning processor to ensure accuracy. The branch/jump prediction moni-
tor additionally outputs statistics on the accuracy of branch and jump predictions, and was used as well with the
load value prediction. It was because of data collected from the load value prediction monitor that caused us to
omit that feature from the processor because of adverse effects on performance. The instruction fetch (IF) stage
monitor is most important since it can record cycle count and the current PC, which is then used to verify proper
program flow operation.
The monitor from lab 6 was modified to monitor signals and values coming from all eight (2 x 4) pipeline stages.
Each monitor behaved similarly to the lab 6 monitor, with a few changes. For example, the Instruction Fetch (IF)
monitor only watches the instruction and which registers (rs, rt, rd) will be used. Register values aren't monitored
here since they are unknown in the IF stage. More values are monitored further down the pipe.
The branch/jump prediction monitor also collated prediction statistics. It displays when a branch is being pre-
dicted, whether that prediction is correct, and the Estimated Moving Weighted Average (EMWA) to determine the
accuracy of the branch/jump prediction unit using the following formula:
EMWA(n) = A x BranchCorrect<1 or 0> + (1 - A) * EMWA(n - 1), A < 1

Page 21Eclipse Processor:Final Report (Group 7)
A is a weighting value that is controllable by the processor designers. A large A results in a spikey EMWA, while
a small A results in a smoother EMWA, similar to the effects of a low pass filter).
The EMWA can then be plotted as a function of number of branch predictions for a particular program (e.g.
QuickSort), as was done in section 4 in the performance summary.
With the monitors in place at various points in the datapath, we then proceeded to perform functional testing. We
begin by verifying each subcomponent, such as the branch prediction unit, functions as expected in isolation. To
do this, we manually assert control and data signals for the newly-designed block, and ensure the block performs
the correct operations given the set of inputs. Next corner cases are evaluated. Once functional verificaoin on a
given sub-block is completed, that block is placed inside the full datapath, and functional verification is then
repeated for the entire datapath.
For example, in lab7, we had separate teams working on the superscalar datapath and the branch/jump prediction
unit. The branch/jump prediction unit was added to the datapath only when functional verification was completed
on that datapath.
Once initial functional verification was completed, progressive testing using increasingly more complicated test
cases was performed. Initially, test vectors that do not contain hazardous conditions (from lab 5) was tested. Once
our datapath passed that test case, we then proceeded to run increasingly more complicated test cases, especially
those that excercised various hazard conditions. Lastly, we included test cases that involve two dependent instruc-
tions in the pipeline to test for hazards introduced by our superscalar architecture.
Since it is not possible to isolate all bugs in a reasonable amount of time, a wide variety of test cases are run to

Page 22Eclipse Processor:Final Report (Group 7)
ensure that the Eclipse processor is robust. Following Clark's suggestion for random testing, we use bug counts as
an indication of debugging completeness.
We implemented the features we had hoped to and tested our final product using various test programs. After all
these implementations and tests, we learned many things. Perhaps the most important lesson we learned was that
a superscalar architecture only improves performance to a certain degree. We found that more hazards appeared,
including ones inherent to superscalar computing. These hazards caused more stalls, which increased our final
CPI. We also observed that CPI and cycle time are always in contention; we could not improve one without
affecting the other. Finally, we gained experience in testing our components and the final product. This includes
progressive testing, random testing, and checking for mislabellings and mispellings.
If given the chance to redo this project, our group might consider implementing a Tomasulo processor instead of a
superscalar one. We would hope that the Tomasulo implementation would take less of a performance hit from
hazards and stalls than what we saw in the superscalar implementation. Additionally, we would budget our time
more wisely, taking into account tasks like proper documentation and a complete and understandable presentation.
We would also consider uncontrollable factors like network congestion, faulty software, and dead servers in our
time management, giving ourselves more time to finish our work despite these hardships.