design and implementation of the ccc parallel programming language nai-wei lin department of...
TRANSCRIPT

Design and ImplementationDesign and Implementationof the CCC of the CCC
Parallel Programming LanguageParallel Programming Language
Nai-Wei Lin
Department of Computer Science and Information Engineering
National Chung Cheng University

ICS2004 2
OutlineOutline
Introduction
The CCC programming language
The CCC compiler
Performance evaluation
Conclusions

ICS2004 3
MotivationsMotivations
Parallelism is the future trendProgramming in parallel is much more
difficult than programming in serialParallel architectures are very diverseParallel programming models are very diverse

ICS2004 4
MotivationsMotivations
Design a parallel programming language that uniformly integrates various parallel programming models
Implement a retargetable compiler for this parallel programming language on various parallel architectures

ICS2004 5
Approaches to ParallelismApproaches to Parallelism
Library approach MPI (Message Passing Interface), pthread
Compiler approach HPF (High Performance Fortran), HPC++
Language approach Occam, Linda, CCC (Chung Cheng C)

ICS2004 6
Models of Parallel ArchitecturesModels of Parallel Architectures
Control Model SIMD: Single Instruction Multiple Data MIMD: Multiple Instruction Multiple Data
Data Model Shared-memory Distributed-memory

ICS2004 7
Models of Parallel ProgrammingModels of Parallel Programming
Concurrency Control parallelism: simultaneously execute
multiple threads of control
Data parallelism: simultaneously execute the same operations on multiple data
Synchronization and communication Shared variables
Message passing

ICS2004 8
Granularity of ParallelismGranularity of Parallelism
Procedure-level parallelism Concurrent execution of procedures on multiple
processors
Loop-level parallelism Concurrent execution of iterations of loops on
multiple processors
Instruction-level parallelism Concurrent execution of instructions on a single
processor with multiple functional units

ICS2004 9
The CCC Programming LanguageThe CCC Programming Language
CCC is a simple extension of C and supports both control and data parallelism
A CCC program consists of a set of concurrent and cooperative tasks
Control parallelism runs in MIMD mode and communicates via shared variables and/or message passing
Data parallelism runs in SIMD mode and communicates via shared variables
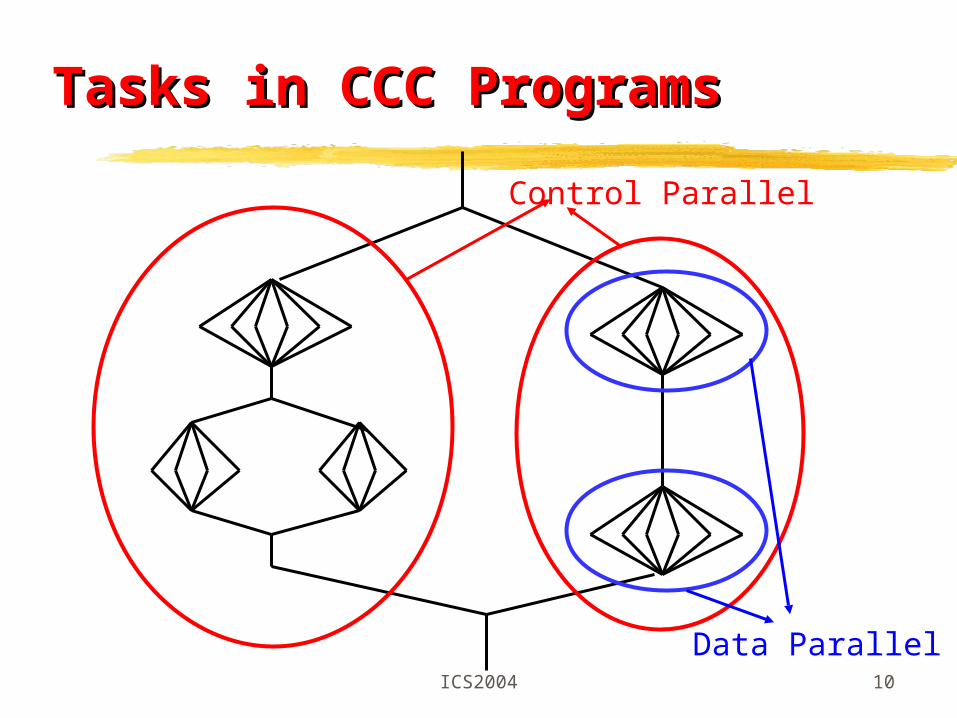
ICS2004 10
Tasks in CCC ProgramsTasks in CCC Programs
Control Parallel
Data Parallel

ICS2004 11
Control ParallelismControl Parallelism
Concurrency task par and parfor
Synchronization and communication shared variables – monitors message passing – channels

ICS2004 12
MonitorsMonitors
The monitor construct is a modular and efficient construct for synchronizing shared variables among concurrent tasks
It provides data abstraction, mutual exclusion, and conditional synchronization

ICS2004 13
An Example - Barber Shop An Example - Barber Shop
Barber
Chair
Customer Customer Customer

ICS2004 14
An Example - Barber Shop An Example - Barber Shop
task::main( ){ monitor Barber_Shop bs; int i;
par { barber( bs ); parfor (i = 0; i < 10; i++) customer( bs ); }}

ICS2004 15
An Example - Barber Shop An Example - Barber Shop
task::barber(monitor Barber_Shop in bs){ while ( 1 ) { bs.get_next_customer( ); bs.finished_cut( ); }}
task::customer(monitor Barber_Shop in bs){ bs.get_haircut( ); }

ICS2004 16
An Example - Barber Shop An Example - Barber Shop
monitor Barber_Shop { int barber, chair, open; cond barber_available, chair_occupied; cond door_open, customer_left;
Barber_Shop( ); void get_haircut( ); void get_next_customer( ); void finished_cut( );};

ICS2004 17
An Example - Barber Shop An Example - Barber Shop
Barber_Shop( ){ barber = 0; chair = 0; open = 0;}
void get_haircut( ){ while (barber == 0) wait(barber_available); barber = 1; chair += 1; signal(chair_occupied); while (open == 0) wait(door_open); open = 1; signal(customer_left);}

ICS2004 18
An Example - Barber Shop An Example - Barber Shop
void get_next_customer( ){ barber += 1; signal(barber_available); while (chair == 0) wait(chair_occupied); chair = 1; }
void get_haircut( ){ open += 1; signal(door_open); while (open > 0) wait(customer_left);}

ICS2004 19
ChannelsChannels
The channel construct is a modular and efficient construct for message passing among concurrent tasks
Pipe: one to oneMerger: many to oneSpliter: one to manyMultiplexer: many to many

ICS2004 20
ChannelsChannels
Communication structures among parallel tasks are more comprehensive
The specification of communication structures is easier
The implementation of communication structures is more efficient
The static analysis of communication structures is more effective
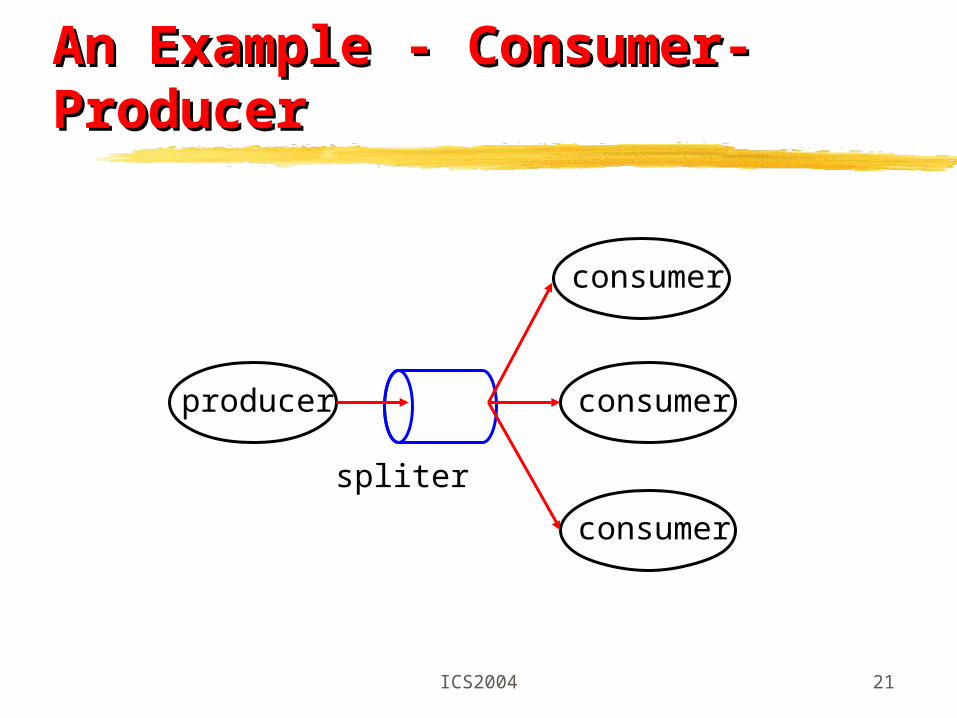
ICS2004 21
An Example - Consumer-Producer An Example - Consumer-Producer
producer consumer
consumer
consumer
spliter

ICS2004 22
An Example - Consumer-Producer An Example - Consumer-Producer
task::main( ){ spliter int chan; int i;
par { producer( chan ); parfor (i = 0; i < 10; i++) consumer( chan ); }}

ICS2004 23
An Example - Consumer-Producer An Example - Consumer-Producer
task::producer(spliter in int chan){ int i;
for (i = 0; i < 100; i++) put(chan, i); for (i = 0; i < 10; i++) put(chan, END);}

ICS2004 24
An Example - Consumer-Producer An Example - Consumer-Producer
task::consumer(spliter in int chan){ int data;
while ((data = get(chan)) != END) process(data);}

ICS2004 25
Data ParallelismData Parallelism
Concurrency domain – an aggregate of synchronous tasks
Synchronization and communication domain – variables in global name space
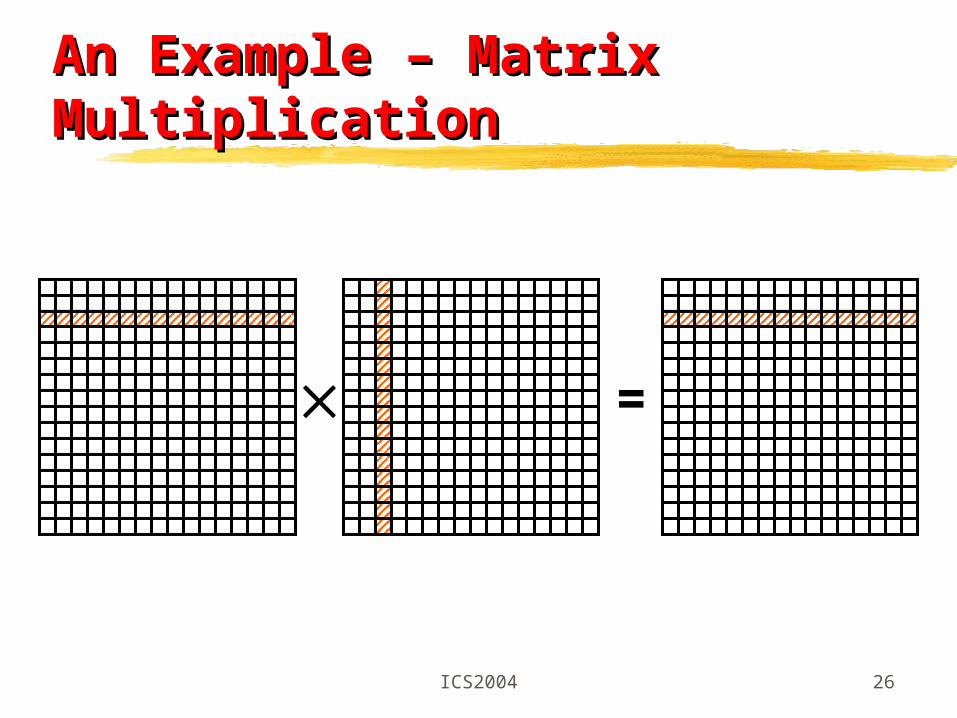
ICS2004 26
An Example – Matrix MultiplicationAn Example – Matrix Multiplication
=

ICS2004 27
An Example– Matrix MultiplicationAn Example– Matrix Multiplication
domain matrix_op[16] { int a[16], b[16], c[16]; multiply(distribute in int [16:block][16], distribute in int [16][16:block], distribute out int [16:block][16]);};

ICS2004 28
task::main( ) { int A[16][16], B[16][16], C[16][16]; domain matrix_op m;
read_array(A); read_array(B); m.multiply(A, B, C); print_array(C);}
An Example– Matrix MultiplicationAn Example– Matrix Multiplication

ICS2004 29
matrix_op::multiply(A, B, C) distribute in int [16:block][16] A;distribute in int [16][16:block] B;distribute out int [16:block][16] C;{ int i, j; a := A; b := B; for (i = 0; i < 16; i++) for (c[i] = 0, j = 0; j < 16; j++) c[i] += a[j] * matrix_op[i].b[j]; C := c;}
An Example– Matrix MultiplicationAn Example– Matrix Multiplication

ICS2004 30
Platforms for the CCC CompilerPlatforms for the CCC Compiler
PCs and SMPs Pthread: shared memory + dynamic thread creat
ionPC clusters and SMP clusters
Millipede: distributed shared memory + dynamic remote thread creation
The similarities between these two classes of machines enable a retargetable compiler implementation for CCC
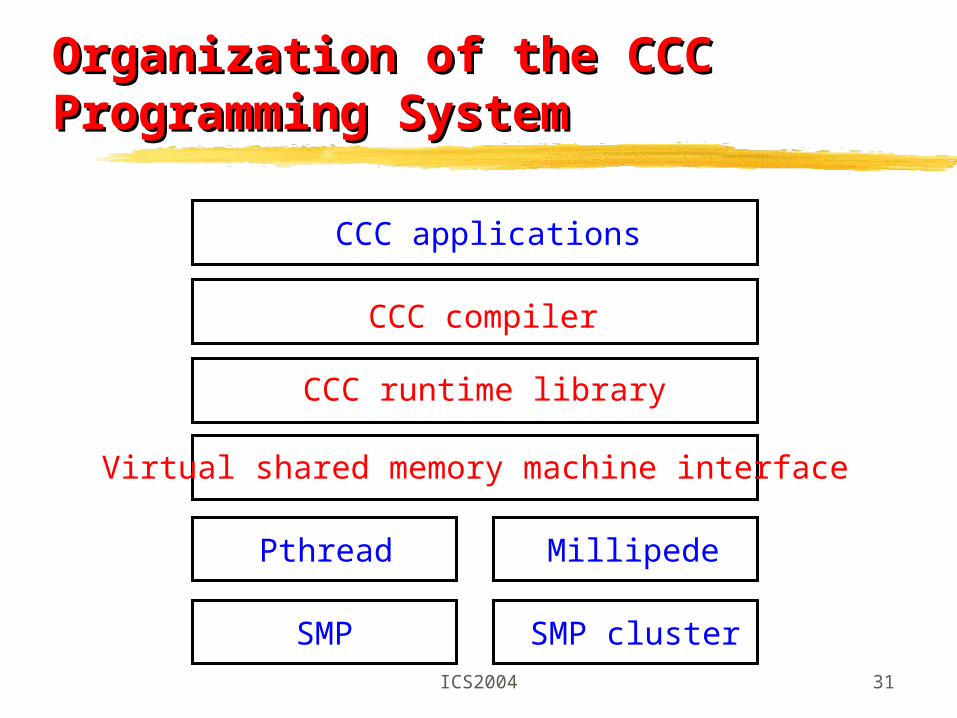
ICS2004 31
Organization of the CCC Organization of the CCC Programming System Programming System
CCC compiler
CCC runtime library
Virtual shared memory machine interface
CCC applications
Pthread Millipede
SMP SMP cluster

ICS2004 32
The CCC CompilerThe CCC Compiler
Tasks → threadsMonitors → mutex locks, read-write locks, an
d condition variablesChannels → mutex locks and condition variab
lesDomains → set of synchronous threadsSynchronous execution → barriers

ICS2004 33
Virtual Shared Memory Machine Virtual Shared Memory Machine InterfaceInterface
Processor managementThread managementShared memory allocationMutex locksRead-write locksCondition variablesBarriers

ICS2004 34
The CCC Runtime LibraryThe CCC Runtime Library
The CCC runtime library contains a collection of functions that implements the salient abstractions of CCC on top of the virtual shared memory machine interface

ICS2004 35
Performance EvaluationPerformance Evaluation
SMPs Hardware : an SMP machine with four CPUs, each CPU i
s an Intel PentiumII Xeon 450MHz, and cache is 512K Software : OS is Solaris 5.7 and library is pthread 1.26
SMP clusters Hardware : four SMP machines, each of which has two C
PUs, each CPU is Intel PentiumIII 500MHz, and cache is 512K
Software : OS is windows 2000 and library is millipede 4.0
Network : Fast ethernet network 100Mbps

ICS2004 36
BenchmarksBenchmarks
Matrix multiplication (1024 x 1024)W arshall’s transitive closure (1024 x 1024)Airshed simulation (5)
ICS2004 37
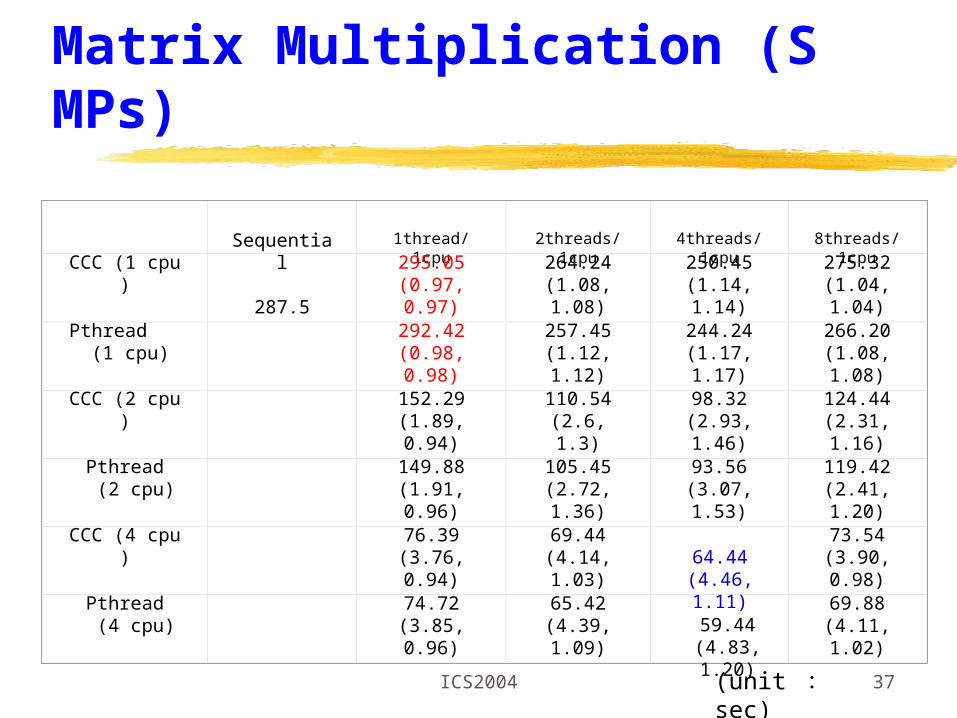
Matrix Multiplication (SMPs)
Sequential 1thread/1cpu 2threads/1cpu 4threads/1cpu 8threads/1cpu
CCC (1 cpu) 287.5
295.05(0.97, 0.97)
264.24(1.08, 1.08)
250.45(1.14, 1.14)
275.32(1.04, 1.04)
Pthread (1 cpu)
292.42
(0.98, 0.98)257.45
(1.12, 1.12)244.24
(1.17, 1.17)266.20
(1.08, 1.08)
CCC (2 cpu)
152.29(1.89, 0.94)
110.54(2.6, 1.3)
98.32(2.93, 1.46)
124.44(2.31, 1.16)
Pthread (2 cpu)
149.88
(1.91, 0.96)105.45
(2.72, 1.36)93.56
(3.07, 1.53)119.42
(2.41, 1.20)
CCC (4 cpu)
76.39(3.76, 0.94)
69.44(4.14, 1.03)
73.54(3.90, 0.98)
Pthread (4 cpu)
74.72
(3.85, 0.96)65.42
(4.39, 1.09)69.88
(4.11, 1.02)
64.44(4.46, 1.11)
59.44(4.83, 1.20)
(unit : sec)
ICS2004 38
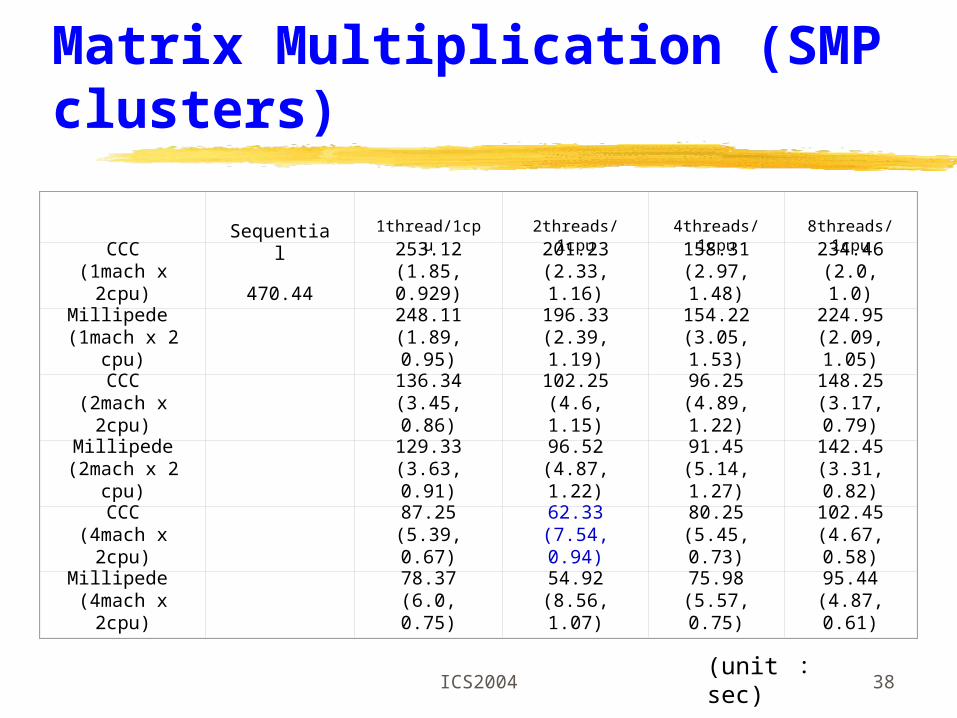
Matrix Multiplication (SMP clusters)
Sequential 1thread/1cpu 2threads/1cpu 4threads/1cpu 8threads/1cpu
CCC(1mach x 2cpu) 470.44
253.12(1.85, 0.929)
201.23(2.33, 1.16)
158.31(2.97, 1.48)
234.46(2.0, 1.0)
Millipede (1mach x 2cpu)
248.11(1.89, 0.95)
196.33(2.39, 1.19)
154.22(3.05, 1.53)
224.95(2.09, 1.05)
CCC(2mach x 2cpu)
136.34(3.45, 0.86)
102.25(4.6, 1.15)
96.25(4.89, 1.22)
148.25(3.17, 0.79)
Millipede(2mach x 2cpu)
129.33(3.63, 0.91)
96.52(4.87, 1.22)
91.45(5.14, 1.27)
142.45(3.31, 0.82)
CCC(4mach x 2cpu)
87.25(5.39, 0.67)
62.33(7.54, 0.94)
80.25(5.45, 0.73)
102.45(4.67, 0.58)
Millipede (4mach x 2cpu)
78.37(6.0, 0.75)
54.92(8.56, 1.07)
75.98(5.57, 0.75)
95.44(4.87, 0.61)
(unit : sec)

ICS2004 39
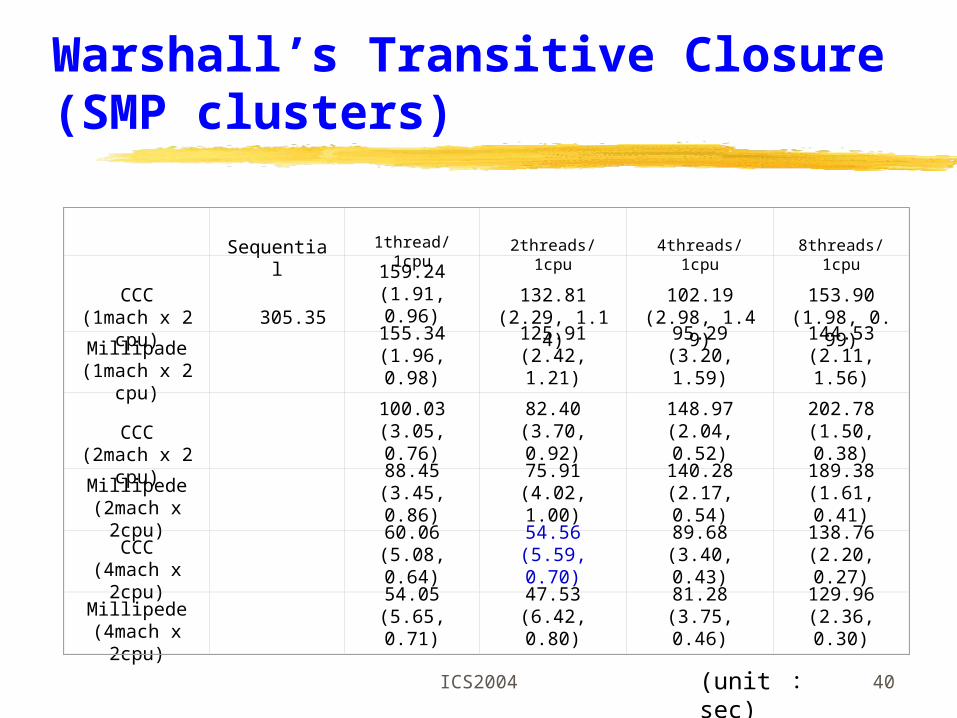
Warshall’s Transitive Closure (SMPs)
Sequtial 1thread/1cpu 2threads/1cpu 4threads/1cpu 8threads/1cpu
CCC (1 cpu) 150.32152.88
(0.98, 0.98)138.44
(1.08, 1.08)143.54
(1.05, 1.05)154.33
(0.97, 0.97)
Pthread (1 cpu)
151.25(0.99, 0.99)
135.45(1.11, 1.11)
139.21(1.07, 1.07)
152.44(0.99, 0.99)
CCC (2 cpu)
83.36(1.80, 0.90)
69.45(2.16, 1.08)
78.54(1.91, 0.96)
98.24(1.53, 0.77)
Pthread (2 cpu)
79.32(1.90, 0.95)
66.85(2.25, 1.12)
74.24(2.02, 1.01)
93.44(1.60, 0.80)
CCC (4 cpu)
49.43(3.04, 0.76)
43.19(3.48, 0.87)
58.44(2.57, 0.64)
77.42(1.94, 0.49)
Pthread (4 cpu)
44.14(3.40, 0.85)
40.89(3.68, 0.91)
55.23(2.72, 0.68)
74.21(2.02, 0.51)
(unit : sec)
ICS2004 40
Warshall’s Transitive Closure (SMP clusters)
Sequential 1thread/1cpu 2threads/1cpu 4threads/1cpu 8threads/1cpu
CCC(1mach x 2cpu) 305.35
159.24(1.91, 0.96)
132.81(2.29, 1.14)
102.19(2.98, 1.49)
153.90(1.98, 0.99)
Millipade(1mach x 2cpu)
155.34(1.96, 0.98)
125.91(2.42, 1.21)
95.29(3.20, 1.59)
144.53(2.11, 1.56)
CCC(2mach x 2cpu)
100.03(3.05, 0.76)
82.40(3.70, 0.92)
148.97(2.04, 0.52)
202.78(1.50, 0.38)
Millipede(2mach x 2cpu)
88.45(3.45, 0.86)
75.91(4.02, 1.00)
140.28(2.17, 0.54)
189.38(1.61, 0.41)
CCC(4mach x 2cpu)
60.06(5.08, 0.64)
54.56(5.59, 0.70)
89.68(3.40, 0.43)
138.76(2.20, 0.27)
Millipede(4mach x 2cpu)
54.05(5.65, 0.71)
47.53(6.42, 0.80)
81.28(3.75, 0.46)
129.96(2.36, 0.30)
(unit : sec)
ICS2004 41
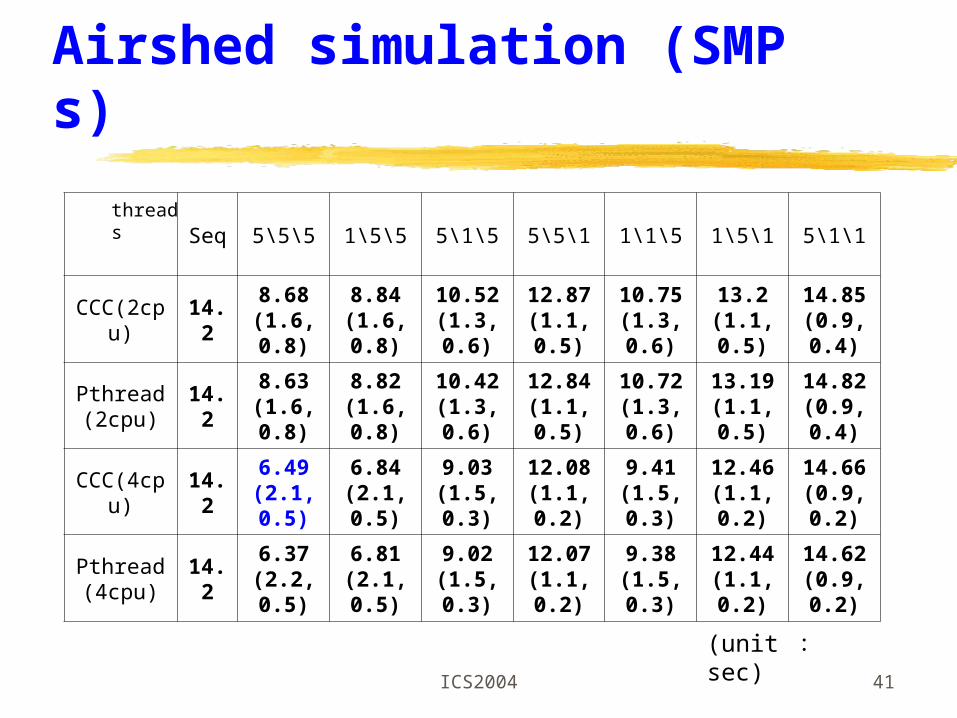
Seq 5\5\5 1\5\5 5\1\5 5\5\1 1\1\5 1\5\1 5\1\1
CCC(2cpu)
14.28.68
(1.6,0.8)8.84
(1.6,0.8)10.52
(1.3,0.6)12.87
(1.1,0.5)10.75
(1.3,0.6)13.2
(1.1,0.5)14.85
(0.9,0.4)
Pthread(2cpu)
14.28.63
(1.6,0.8)8.82
(1.6,0.8)10.42
(1.3,0.6)12.84
(1.1,0.5)10.72
(1.3,0.6)13.19
(1.1,0.5)14.82
(0.9,0.4)
CCC(4cpu)
14.26.49
(2.1,0.5)6.84
(2.1,0.5)9.03
(1.5,0.3)12.08
(1.1,0.2)9.41
(1.5,0.3)12.46
(1.1,0.2)14.66
(0.9,0.2)
Pthread(4cpu)
14.26.37
(2.2,0.5)6.81
(2.1,0.5)9.02
(1.5,0.3)12.07
(1.1,0.2)9.38
(1.5,0.3)12.44
(1.1,0.2)14.62
(0.9,0.2)
Airshed simulation (SMPs)
threads
(unit : sec)
ICS2004 42
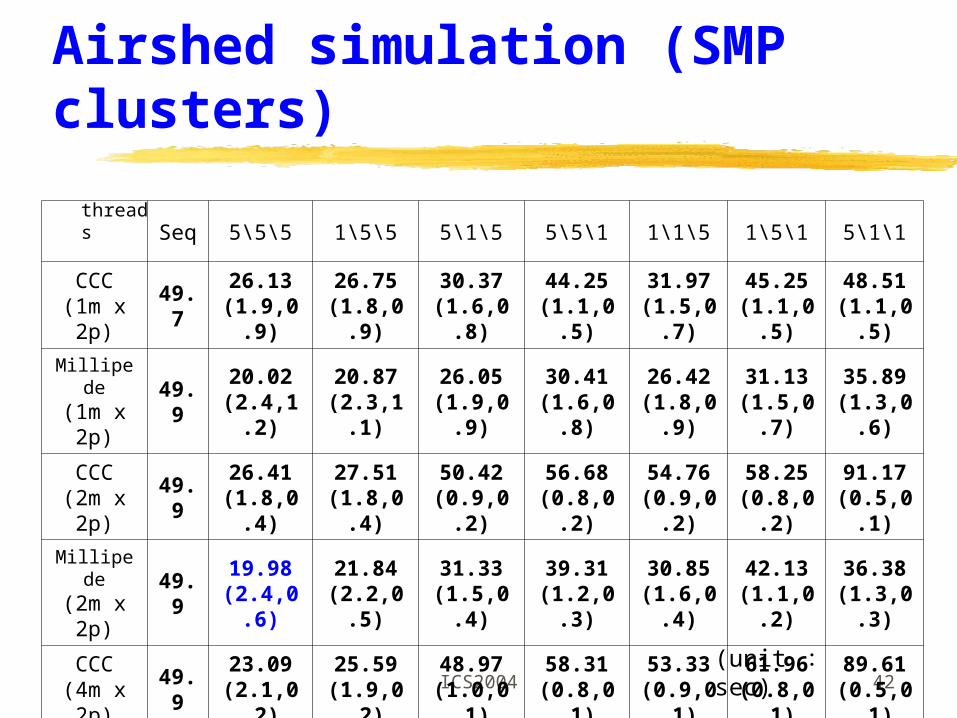
Seq 5\5\5 1\5\5 5\1\5 5\5\1 1\1\5 1\5\1 5\1\1
CCC(1m x 2p)
49.726.13
(1.9,0.9)26.75
(1.8,0.9)30.37
(1.6,0.8)44.25
(1.1,0.5)31.97
(1.5,0.7)45.25
(1.1,0.5)48.51
(1.1,0.5)
Millipede
(1m x 2p)
49.920.02
(2.4,1.2)20.87
(2.3,1.1)26.05
(1.9,0.9)30.41
(1.6,0.8)26.42
(1.8,0.9)31.13
(1.5,0.7)35.89
(1.3,0.6)
CCC(2m x 2p)
49.926.41
(1.8,0.4)27.51
(1.8,0.4)50.42
(0.9,0.2)56.68
(0.8,0.2)54.76
(0.9,0.2)58.25
(0.8,0.2)91.17
(0.5,0.1)
Millipede(2m x 2
p)49.9
19.98(2.4,0.6)
21.84(2.2,0.5)
31.33(1.5,0.4)
39.31(1.2,0.3)
30.85(1.6,0.4)
42.13(1.1,0.2)
36.38(1.3,0.3)
CCC(4m x 2p)
49.923.09
(2.1,0.2)25.59
(1.9,0.2)48.97
(1.0,0.1)58.31
(0.8,0.1)53.33
(0.9,0.1)61.96
(0.8,0.1)89.61
(0.5,0.1)
Millipede(4m x 2
p)49.9
16.72(2.9,0.3)
17.61(2.8,0.3)
35.11(1.4,0.2)
41.03(1.2,0.1)
33.95(1.4,0.2)
40.88(1.2,0.1)
36.07(1.3,0.1)
Airshed simulation (SMP clusters)
threads
(unit : sec)

ICS2004 43
ConclusionsConclusions
A high-level parallel programming language that uniformly integrates Both control and data parallelism Both shared variables and message passing
A modular parallel programming languageA retargetable compiler