deepimage_gtc15_public
TRANSCRIPT

Deep Image: ���Scaling up Image Recognition
Ren Wu Distinguished Scientist, Baidu
[email protected] @韧在百度

The Color of the Dress

The Color of the Dress
Color Constancy Human vs. Artificial Intelligence


Summary @ GTC14
Big data + Deep learning + High performance computing =
Intelligence
Big data + Deep learning + Heterogeneous computing =
Success
GTC’14: Deep Learning Meets Heterogeneous Computing

Baidu Stock

Baidu Q2’14

Big Data
• >2000PB Storage • 10-100PB/day Processing • 100b-1000b Webpages • 100b-1000b Index • 1b-10b/day Update • 100TB~1PB/day Log
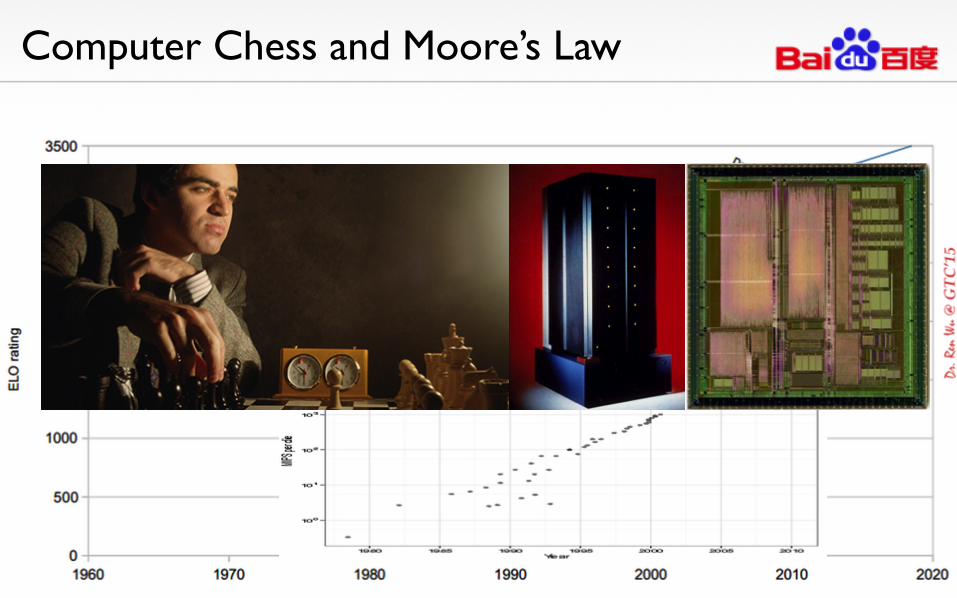
Computer Chess and Moore’s Law

Deep Blue
A classic example of application-specific system design comprised of an IBM supercomputer with 480 custom-made VLSI chess chips, running massively parallel search algorithm with highly optimized implementation.

Heterogeneous Computing
1993 world #1 Think Machine CM5/1024 131 GFlops
2013 Samsung Note 3 smartphone (Qualcomm SnapDragon 800) 129 Gflops
2000 world #1 ASCI White (IBM RS/6000SP) 6MW power, 106 tons 12.3 TFlops
2013 Two MacPro workstation (dual AMD GPUs each) 14 TFlops

Deep Learning Applications
• Speech recognition
• Image recognition
• Optical character recognition (OCR)
• Language translation
• Web search
• Computational Ads (CTR)
• …
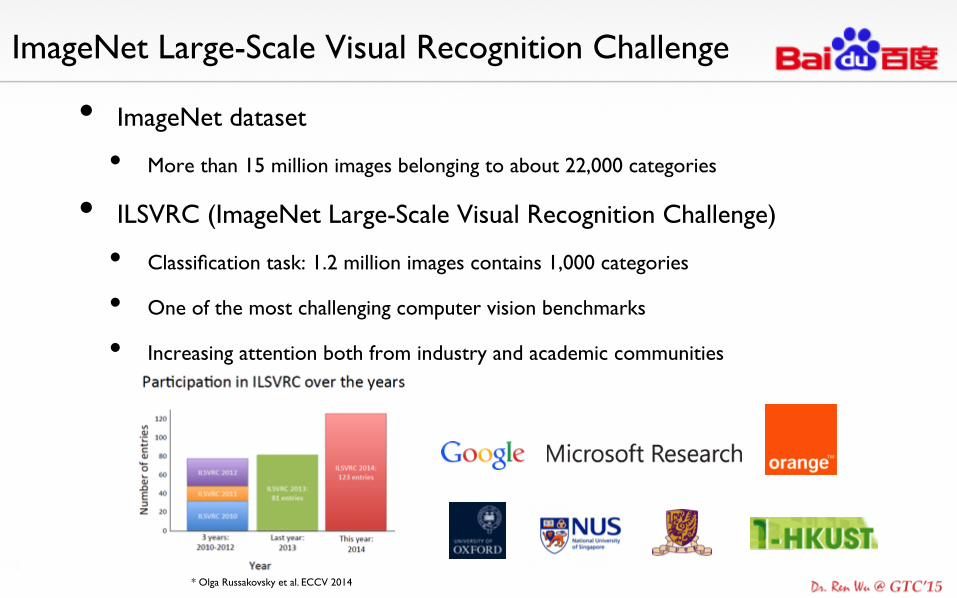
ImageNet Large-Scale Visual Recognition Challenge
• ImageNet dataset
• More than 15 million images belonging to about 22,000 categories
• ILSVRC (ImageNet Large-Scale Visual Recognition Challenge)
• Classification task: 1.2 million images contains 1,000 categories
• One of the most challenging computer vision benchmarks
• Increasing attention both from industry and academic communities
* Olga Russakovsky et al. ECCV 2014

ImageNet Classification Challenge���

ImageNet classification 2012-2014
Team Year Place Error (top-5) Uses external data
SuperVision 2012 - 16.4% no
SuperVision 2012 1st 15.3% ImageNet 22k
Clarifai 2013 - 11.7% no
Clarifai 2013 1st 11.2% ImageNet 22k
MSRA 2014 3rd 7.35% no
VGG 2014 2nd 7.32% no
GoogLeNet 2014 1st 6.67% no
Slide credit: Yangqing Jia, Google Invincible ?

Our approach – Insights and inspirations
多算胜少算不胜 孙⼦子 (544-496 BC) 计篇 More calculations win, few calculation lose
元元本本殚⻅见洽闻 班固 (32-92 AD) ⻄西都赋 Meaning the more you see the more you know
明⾜足以察秋毫之末 孟⼦子 (372-289 BC) 梁惠⺩王上 ability to see very fine details

Project Minwa – 百度敏娲 • Minerva + Athena + ⼥女娲 • Athena: Goddess of Wisdom, Warfare,
Divine Intelligence, Architecture, and Crafts • Minerva: Goddess of wisdom, magic,
medicine, arts, commerce and defense • ⼥女娲: 抟⼟土造⼈人, 炼⽯石补天, 婚姻, 乐器
World’s Largest Artificial Neural Networks
v Pushing the State-of-the-Art v ~ 100x bigger than previous ones v New kind of Intelligence?

Hardware/Software Co-design • Stochastic gradient decent (SGD)
• High compute density
• Scale up, up to 100 nodes
• High bandwidth low latency
• 36 nodes, 144 GPUs, 6.9TB Host, 1.7TB Device
• 0.6 PFLOPS
• Highly Optimized software stack
• RDMA/GPU Direct • New data partition and communication
strategies
GPUs
Infiniband

Minwa
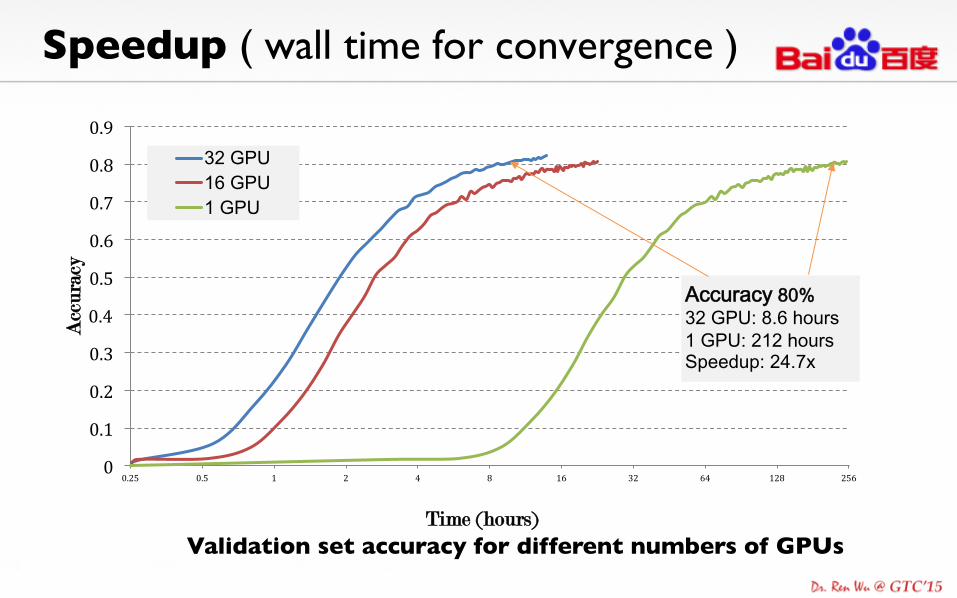
Speedup ( wall time for convergence )
Validation set accuracy for different numbers of GPUs
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
0.25 0.5 1 2 4 8 16 32 64 128 256
Acc
ura
cy
Time (hours)
32 GPU 16 GPU 1 GPU
Accuracy 80% 32 GPU: 8.6 hours 1 GPU: 212 hours Speedup: 24.7x

Never have enough training examples! Key observations • Invariant to illuminant of the
scene • Invariant to observers
Augmentation approaches • Color casting • Optical distortion • Rotation and cropping etc
Data Augmentation
“⻅见多识⼲⼴广”

And the Color Constancy Key observations • Invariant to illuminant of the scene • Invariant to observers
Augmentation approaches • Color casting • Optical distortion • Rotation and cropping etc
The color of the Dress
“Inspired by the color constancy principal. Essentially, this ‘forces’ our neural network to develop its own color constancy ability.”

Data Augmentation
Augmentation The number of possible changes Color casting 68920
Vignetting 1960 Lens distortion 260
Rotation 20 Flipping 2 Cropping 82944(crop size is 224x224, input image
size is 512x512)
Possible variations
The Deep Image system learned from ~2 billion examples, out of 90 billion possible candidates.
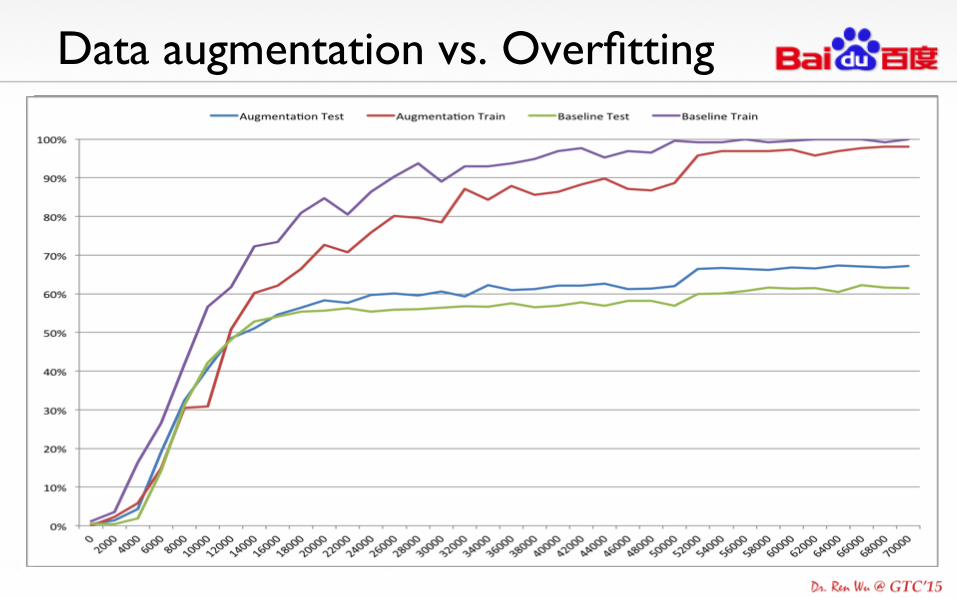
Data augmentation vs. Overfitting

Examples
Bathtub Isopod
Indian elephant Ice bear
Some hard cases addressed by adding our data augmentation.

Multi-scale training • Same crop size, different
resolution
• Fixed-size 224*224
• Downsized training images
• Reduces computational costs
• But not for state-of-the-art
• Different models trained by different image sizes
256*256
512*512
• High-resolution model works
• 256x256: top-5 7.96%
• 512x512: top-5 7.42%
• Multi-scale models are complementary
• Fused model: 6.97%
“明查秋毫”

Multi-scale training
Tricycle Washer
Backpack
Little blue heron

Tricycle
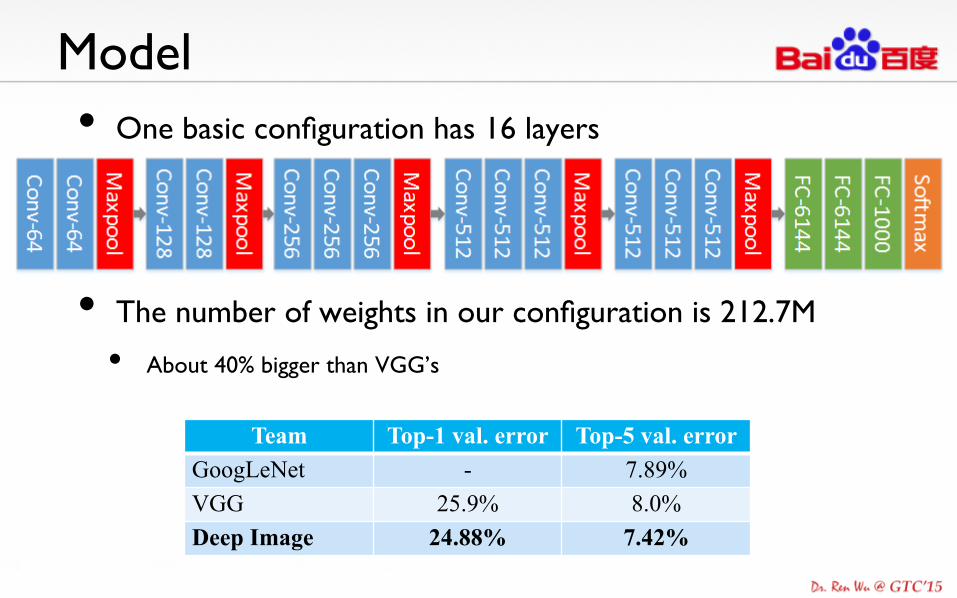
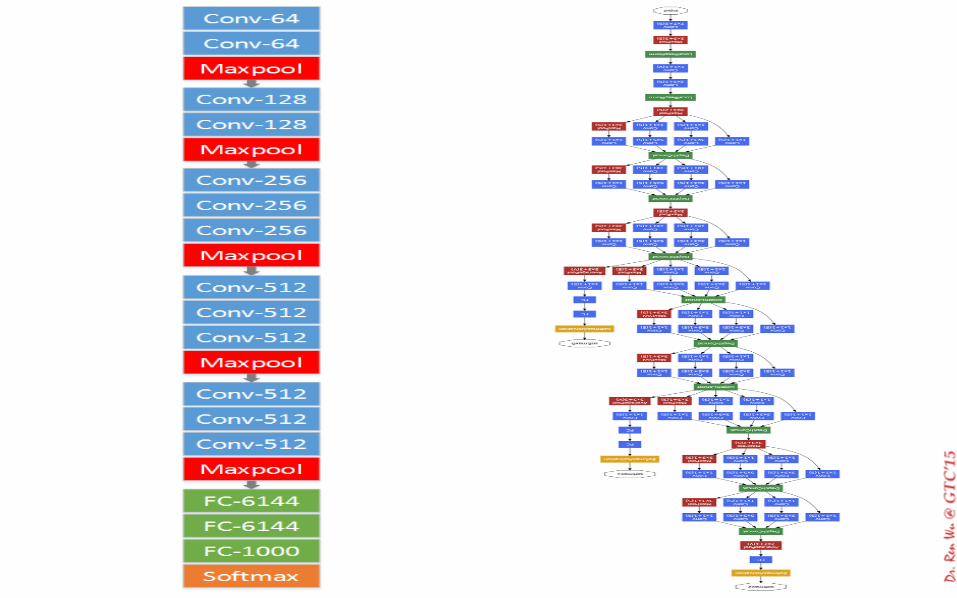
Model • One basic configuration has 16 layers
• The number of weights in our configuration is 212.7M
• About 40% bigger than VGG’s
Team Top-1 val. error Top-5 val. error GoogLeNet - 7.89% VGG 25.9% 8.0% Deep Image 24.88% 7.42%
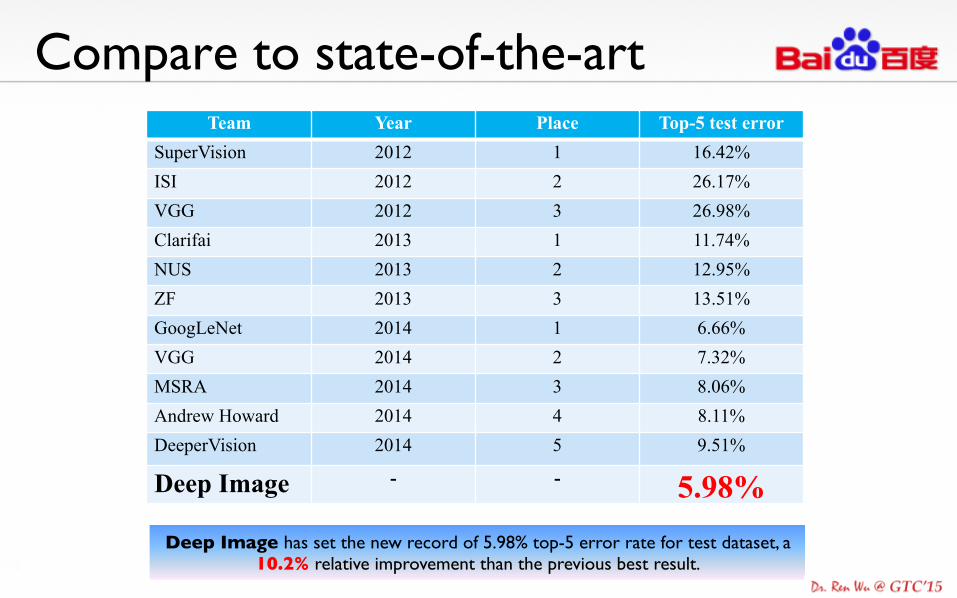
Compare to state-of-the-art
Deep Image has set the new record of 5.98% top-5 error rate for test dataset, a 10.2% relative improvement than the previous best result.
Team Year Place Top-5 test error SuperVision 2012 1 16.42% ISI 2012 2 26.17% VGG 2012 3 26.98% Clarifai 2013 1 11.74% NUS 2013 2 12.95% ZF 2013 3 13.51% GoogLeNet 2014 1 6.66% VGG 2014 2 7.32% MSRA 2014 3 8.06% Andrew Howard 2014 4 8.11% DeeperVision 2014 5 9.51%
Deep Image - - 5.98%
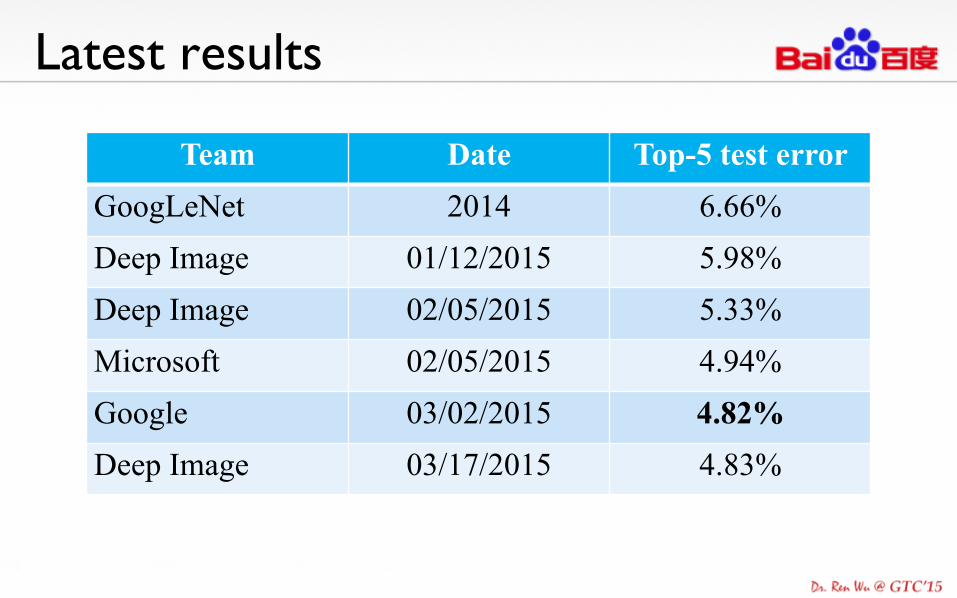
Latest results
Team Date Top-5 test error GoogLeNet 2014 6.66% Deep Image 01/12/2015 5.98% Deep Image 02/05/2015 5.33% Microsoft 02/05/2015 4.94% Google 03/02/2015 4.82% Deep Image 03/17/2015 4.83%

Robustness

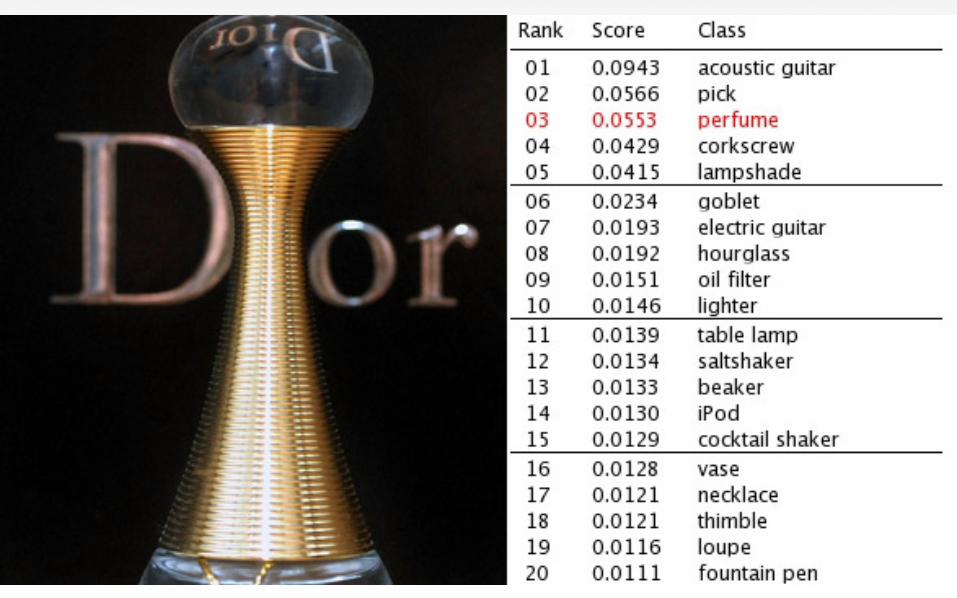


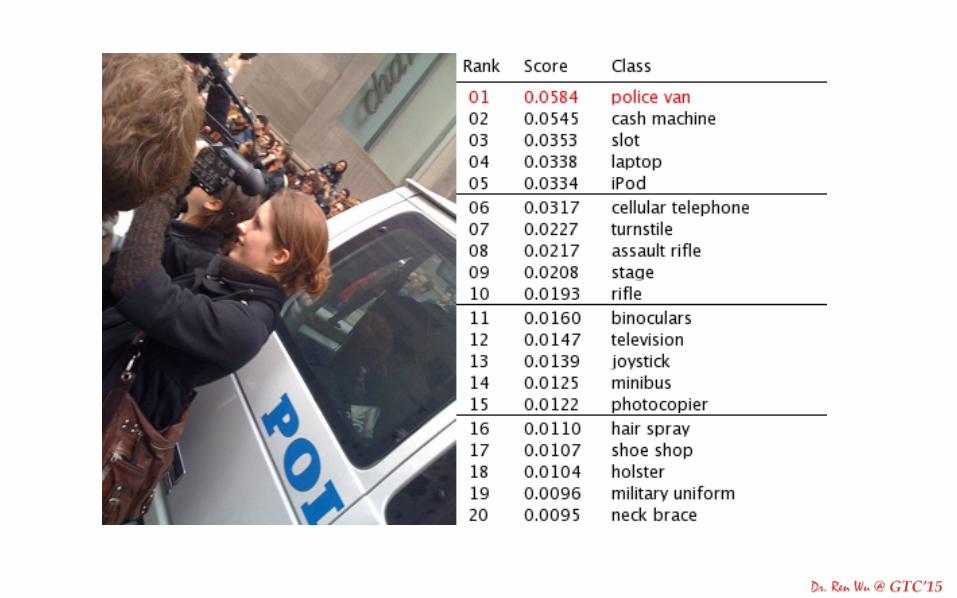



Major differentiators • Customized built supercomputer dedicated for DL
• Simple, scalable algorithm + Fully optimized software stack
• Larger models
• More Aggressive data augmentation
• Multi-scale, include high-resolution images
Brute force + Insights and push for extreme

Thank you!