database management 7. course. reminder disk and ram raid levels disk space management buffering...
TRANSCRIPT

Database Management
7. course

Reminder
• Disk and RAM• RAID Levels• Disk space management• Buffering• Heap files• Page formats• Record formats

Today
• System catalogue• Hash-based indexing– Static– Extendible– Linear
• Time-cost of operations

System catalogue
• Special table• Indexes
– Type of the data structure and search key• Tables
– Name, filename, file structure (e.g. heap)– Attribute names, types– Integrity constraints– Index names
• Views– Name and definition
• Statistics, permissions, buffer size, etc.

Attr_Cat(attr_name, rel_name, type, position)
attr_name rel_name type positionattr_name Attribute_Cat string 1rel_name Attribute_Cat string 2type Attribute_Cat string 3position Attribute_Cat integer 4sid Students string 1name Students string 2login Students string 3age Students integer 4gpa Students real 5fid Faculty string 1fname Faculty string 2sal Faculty real 3

Hash-based indexing

Basic thought
• Index for every search key• Hash function ( f ) between search key ( K )
and memory address ( A ): A = f ( K )• Ideally bijective: key is the address

Hashing
• Ideal for joining tables• Just for equality check• Many versions

Static hashing
• File~collection of buckets• Bucket: one primary page and overflow pages• File has N buckets: 0..N-1• Data entries– Data records with key k– <k, record ids with key k>– <k, list of records with key k>

• To identify the bucket hash function h is applied.
• In the bucket alternative search is applied• Insertion h is used to find the proper bucket• If there is not enough space, create an
overflow chain to the bucket

• In case of deletion h is used to locate tha bucket
• If the deleted was the last record, than page is removed
• Bucket number: h ( value ) mod N• h ( value ) = ( a * value + b )• a and b are constants


• Primary pages stored sequentially on the disk• If the file grows a lot– Long overflow chain– Worsens the search– Create new file with more buckets!
• If the file shrinks a lot– A lot of space is wasted– Merge buckets!

Solution
• Ideally– 80% of the buckets is used– no overflow
• Periodically rehash the file– Takes time– Index cannot be used during rehashing
• Use dynamic hashing– Extendible Hashing– Linear Hashing

Extendible hashing

• Like Static Hashing• If a new entry is to be inserted to a full bucket– Double the number of buckets– Use directory of pointers (only the directory file
has to be doubled)– Split only the overflowed bucket

Example

Insert 20*

Result

Insert 9*
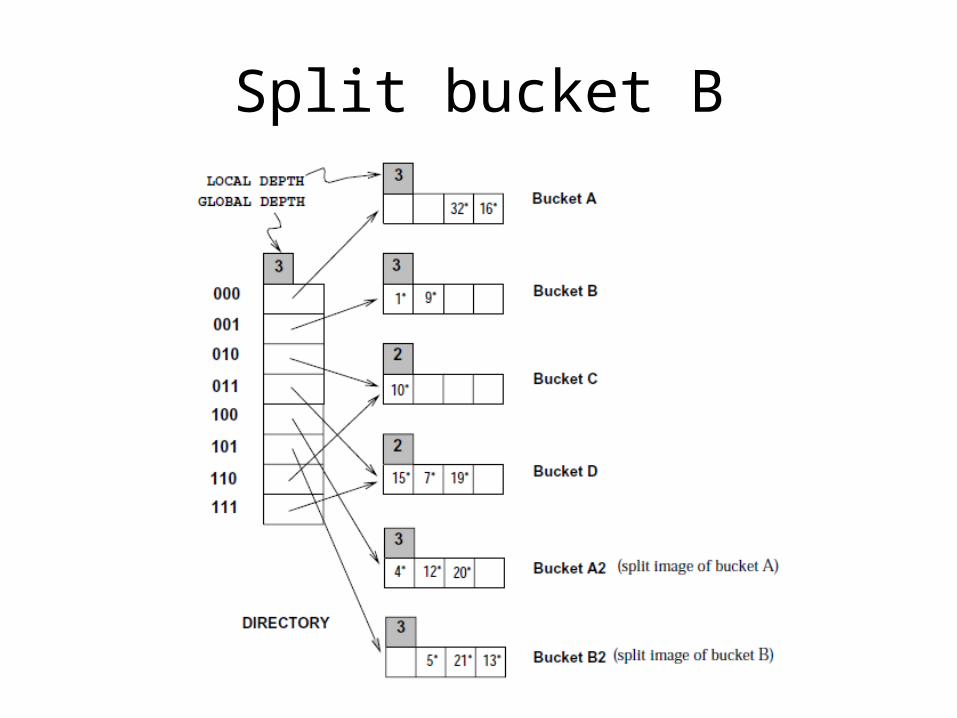
Split bucket B

If bucket gets empty
• Merging buckets is also possible• Not always done• Decrease local depth

Storage
• Typical: 100 MB file• 100 bytes/data entry• Page size: 4KB• 1,000,000 data entries• 25,000 elements in the directory• High chance that it will fit in memory speed=speed of
Static Hashing• Otherwise twice slow• Collision: entries with the same hash values (overflow
pages are needed)

Linear Hashing
• Family of hash functions: h0, h1, …• Each function's range is twice that of its
predecessor• E.g. hi(value) = h(value) mod (2i N).
• do:number of bits of N’s representation
• di:do+i
• Example: N=32, do=5, h1 is h mod (2*32), d1=6

Basic idea
• Rounds of splitting• Number of actual round is Level• Only hLevel and are hLevel+1 in use• At any given point within a round we have– splitted buckets– buckets yet to be splitted– buckets created by splits in this round


Searching
• hLevel is applied– If it leads to an unsplitted bucket, we look there– If it leads to a splitted bucket, we apply hLevel+1 to
decide in which bucket our data is• Insertion may need overflow page• If the overflow chain gets big then split is
triggered

Example
Level=0 round numberNLevel=N*2Level number of buckets at the beginning of the Lth round (N0=N)

• If split is triggered, actual (Next) bucket is split and redistributed by hL+1
• The new bucket gets to the end of the buckets• Next is incremented by 1• Apply hLevel and if the searched hash value is
before Next then apply hLevel+1
• Continue: insert 43*, 37*, 29*, 22*, 66*, 34*, and 50*.

43

37

29

22, 66, 34

50

Deletion
• If the last bucket is empty, it can be removed• Merging can be triggered for not empty
buckets• New round, merging: empty buckets are
removed, Level is decrementedNext=NLevel/2-1

Comparison
• If Linear hashing is stored as Extendible• Hashing function is similar to Extendible
hashing (hi hi+1 ~ doubling the directory)• Extendible hashing: reduced number of splits
and higher bucket occupancy

• Linear hashing– Avoids directory structure– Primary pages are stored consecutively. Quicker
equality selection.– Skewed distribution results in almost empty
buckets

• If directory structure for Linear hashing: one bucket=one directory
• Overflow pages are stored easily• Overhead of a directory level• Costly for large, uniformly distributed files• Improves space occupancy

File organizations

Cost model
• To analyze the (time) cost of the DB operations• No. of data pages: B• Records/page: R• Time of reading/writing: D=15ms (dominant)• Time of record processing: C=100nanos• Time of hashing: H=100nanos

• Reduced calculation just for the I/O time• 3 basic file organization:– Heap files– Sorted files– Hashed files

File operations
• Scan• Search with equality selection (=)• Search with range selection (>,<)• Insert• Delete

Heap files
• Scan the file: B ( D + RC )• Search with equality selection:– One result: in average B ( D + RC ) / 2– Several results: search the entire file, B ( D + RC )
• Search with range selection: B ( D + RC )• Insert: fetch the last page, add record, write
back, 2D + C• Delete: find record, delete, write page,
cost of searching + C + D
B data pagesR records/pageD time of reading/writingC time of record processing

Sorted files
• Scan: B ( D + RC )• Search with equality selection:
– One result: D log2B + C log2R
– Several results: D log2B + C log2R + no. of results
• Search with range selection:D log2B + C log2R + no. of results
• Insert: find place, insert, move the rest, write pages,search position + B ( D + RC ) in average
• Delete: find record, delete, move the rest, write pages,cost of searching + B ( D + RC )
B data pagesR records/pageD time of reading/writingC time of record processing

Hashed files
• No overflow pages• 80% occupancy of buckets• Scan the file: 1.25 * B ( D + RC )• Search with equality selection:
in average H + D + RC/2• Search with range selection: 1.25 * B ( D + RC )• Insert: locate page, add record, write back,
search + D + C• Delete: find record, delete, write page,
cost of searching + C + D
B data pagesR records/pageD time of reading/writingC time of record processingH time of hashing

Summary
• Heap file: Storage +, modifying +, searching -• Sorted file: Searching +, modifying -• Hashed file: Modifying +, range selection --,
storage -
Type Scan Eq. Search Range search
Insert Delete
Heap BD BD/2 BD 2D Search + DSorted BD Dlog2B Dlog2B +
#matchesSearch + BD
Search + BD
Hashed 1.25BD D 1.25 BD 2D Search + D

Thank you for your attention!
• Book is uploaded:• R. Ramakrishnan, J. Gehrke: Database
Management Systems, 2nd edition