database engines for bioscience john corwin avi silberschatz swathi yadlapalli yale university
TRANSCRIPT

Database Engines for Bioscience
John Corwin
Avi Silberschatz
Swathi Yadlapalli
Yale University

Database Engines for Bioscience
The Yale Center for Medical Informatics, led by Perry Miller, makes extensive use of biomedical and bioscience databases.
Large database projects include– Trial/DB– SenseLab

Trial/DB
Trial/DB is an open-source clinical study data management system– Manages patient data across multiple studies.– No limit on the number of patients per study.– No limit on the number of parameters that are
tracked in each study. – Currently used for a large number of clinical
studies at Yale and other universities.

SenseLab
Stores integrated, multidisciplinary models of neurons and neural systems.– Cell properties (receptors, currents, and
transmitters)– Neurons– Networks of neurons (computational neuron
models)

Database Engines for Bioscience
What’s different about these databases?– Sparse data– Frequent schema changes– Row-level security policies– Lots of metadata

EAV
Entity-Attribute-Value (EAV)– Also known as Object-Attribute-Value
Data is stored in 3-column tables– Column 1 stores the object name– Column 2 stores the attribute name– Column 3 stores the attribute value

EAV – Example
Suppose we’re building a database of fruit types
Entity Attribute Value
Apple Color Red
Apple AvgWeight 8.2
Banana AvgWeight 11.5
Banana Color Yellow
Apple Potassium 159

EAV/CR
EAV/CR: extends EAV with classes and relationships– Classes – the value field in each EAV triple may
contain complex, structured data– Relationships – values may refer to other objects
in the database, thus relationships in the database are stored explicitly

Drawbacks of EAV and EAV/CR
Since all data is conceptually in a single table, the only operations we can perform are filters and self-joins
Support for regular queries must be re-implemented on top of the EAV database
The performance of attribute-centered queries is significantly worse than a conventional database
High storage overhead for dense data

Our work
Extend a conventional database engine to better support the requirements of bioscience databases.– Take advantage of existing tools– Better performance– Better space-efficiency
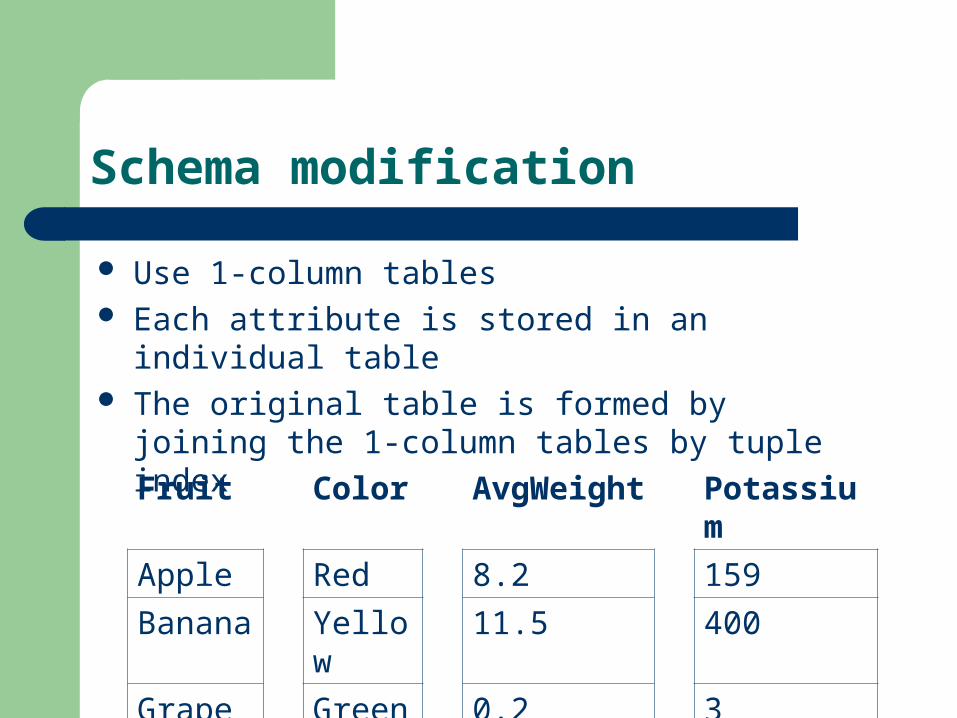
Schema modification
Use 1-column tables Each attribute is stored in an individual table The original table is formed by joining the 1-column
tables by tuple index
Fruit Color AvgWeight Potassium
Apple Red 8.2 159
Banana Yellow 11.5 400
Grape Green 0.2 3
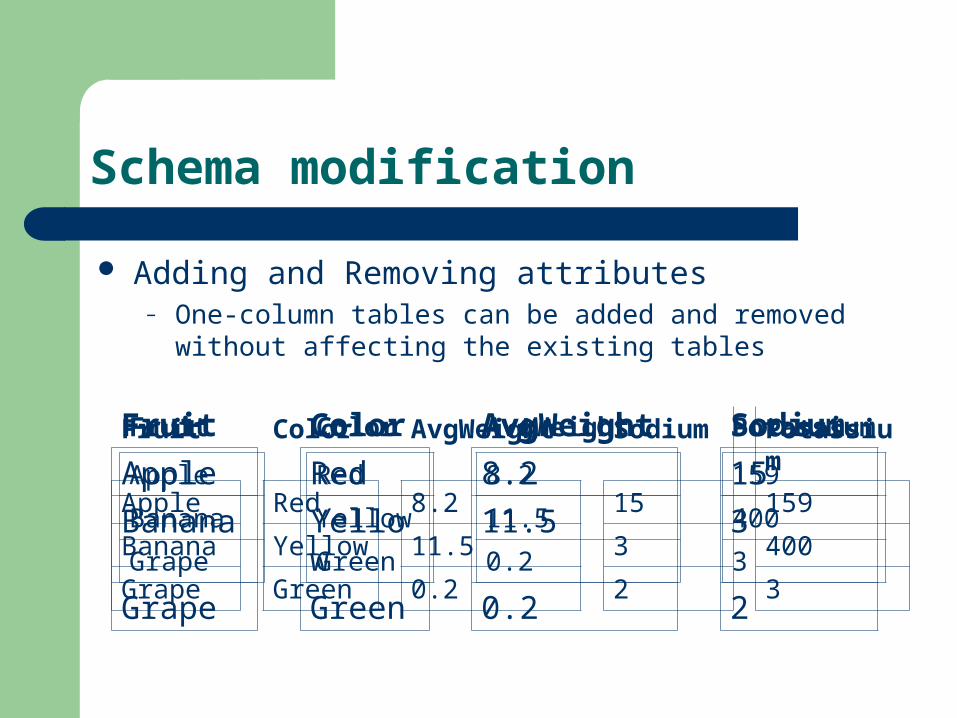
Schema modification
Adding and Removing attributes– One-column tables can be added and removed without
affecting the existing tables
Fruit Color AvgWeight Sodium
Apple Red 8.2 15
Banana Yellow 11.5 3
Grape Green 0.2 2
Fruit Color AvgWeight Sodium Potassium
Apple Red 8.2 15 159
Banana Yellow 11.5 3 400
Grape Green 0.2 2 3
Fruit Color AvgWeight Potassium
Apple Red 8.2 159
Banana Yellow 11.5 400
Grape Green 0.2 3

Schema modification
Query– Original table is formed by joining each one-
column table by tuple index

Schema modification
To test this new storage mechanism, we implemented it in PostgreSQL
PostgreSQL is an open-source relational database engine
– Based on the original Postgres engine developed at Berkeley
– Supports modern database features such as complex queries, transactional integrity, and extensible functions and data types
– 500,000 lines of C code

Dynamic Tables: Interface
Create an extension of the SQL syntax All other table operations work normally on dynamic
tables – the implementation of dynamic tables is transparent to the database user
CREATE DYNAMIC TABLE fruit_table (fruit string,avgWeight float,potassium int);

Dynamic Tables: Implementation
Original statement:CREATE DYNAMIC TABLE t(c1 t1, c2 t2, ..., cn tn);
Create individual tables, for 1 ≤ i ≤ n:CREATE TABLE dyn_t_i(ci ti);
Expose original table as a view:CREATE VIEW t AS (SELECT c1, c2, ..., cn FROM
dyn_t_1, dyn_t_2, ..., dyn_t_n WHERE (c1.ctid = c2.ctid) AND ... AND (cn-1.ctid = cn.ctid));

Dynamic Tables: Implementation
Override implementation of insert, update, and delete
Insert: Given the queryINSERT INTO t VALUES (v1, ..., vn);
Translates to
INSERT INTO dyn_t_i VALUES (v_i);
for 1 ≤ i ≤ n

Dynamic Tables: Implementation
Update and Delete: take advantage of PostgreSQL’s rule system to translate operations to individual tables
Must maintain the invariant that each table has the same number of entries

Sparse Data
Make the column index explicit Change our one-column tables to two-
column tables– Column 1: row-index of this tuple– Column 2: data value
Table is exposed by joining sub-tables by explicit row index
Dense and sparse attributes can be mixed within the same relation

Database Engines for Bioscience
Future work:– Row-level security– Metadata– Implement SenseLab database and compare
performance

Database Engines for Bioscience
Questions?