data processing with spark in r & python
TRANSCRIPT

Data processing with Spark in R & Python
Maloy Manna
linkedin.com/in/maloy @itsmaloy biguru.wordpress.com

Abstract
With ever increasing adoption by vendors and enterprises, Spark is fast becoming the de facto big data platform.
As a general purpose data processing engine, Spark can be used in both R and Python programs.
In this webinar, we’ll see how to use Spark to process data from various sources in R and Python and how new tools like Spark SQL and data frames make it easy to perform structured data processing.

Speaker profile
Maloy Manna Data science engineering
AXA Data Innovation Lab
• Building data driven products and services for over 15 years
• Worked in Thomson Reuters, Infosys, TCS and data science startup Saama
linkedin.com/in/maloy @itsmaloy biguru.wordpress.com

Agenda
• Overview of Spark • Data processing operations • RDD operations
– Transformations, Actions
• Spark SQL – DataFrames – DataFrame operations
• Spark R • Useful Tips • References

Overview of Spark
• Fast, general-purpose engine for large-scale data processing
• Smarter than Hadoop in utilizing memory
• Faster than MapReduce in memory & on disk
• Can run on Hadoop, or standalone; can access data in HDFS, Cassandra, Hive / any Hadoop data source
• Provides high-level APIs in Scala, Java, Python & R
• Supports high-level tools like Spark SQL for structured data processing
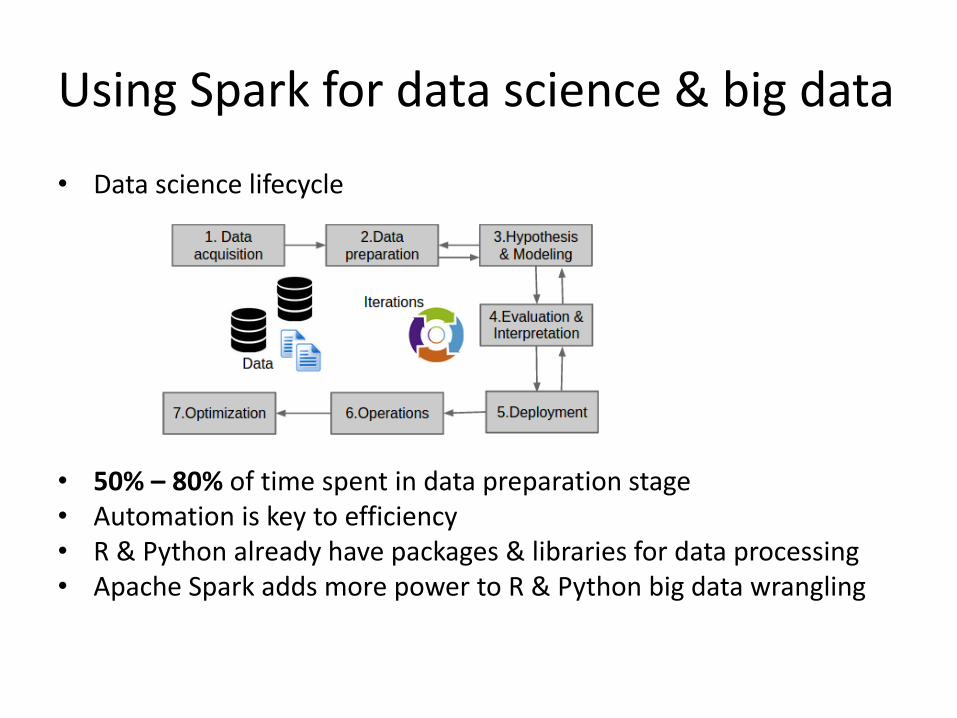
Using Spark for data science & big data
• Data science lifecycle
• 50% – 80% of time spent in data preparation stage • Automation is key to efficiency • R & Python already have packages & libraries for data processing • Apache Spark adds more power to R & Python big data wrangling

Data processing
Getting data to the right format for analysis: • Data manipulations • Data tidying • Data visualization
reshaping formatting
cleaning Transformations munging Wrangling carpentry
manipulation cleaning
processing

Data processing - operations
• Reshaping data Change layout (rows/columns “shape”) of dataset
• Subset data Select rows or columns
• Group data Group data by categories, summarize values
• Make new variables Compute and append new columns, drop old columns
• Combine data sets Joins, append rows/columns, set operations
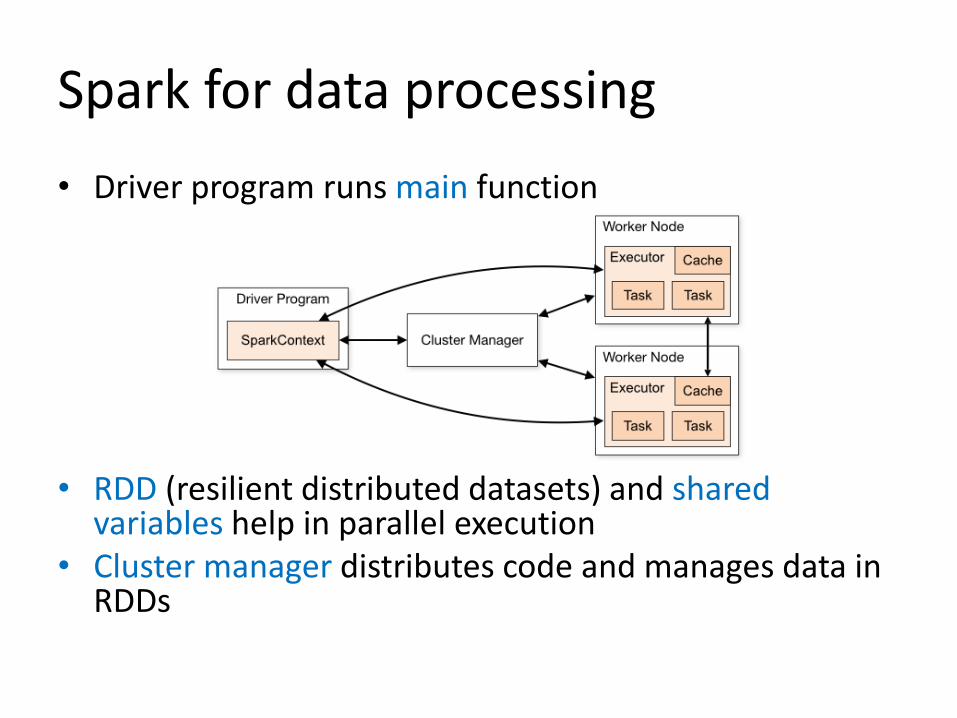
• Driver program runs main function
• RDD (resilient distributed datasets) and shared variables help in parallel execution
• Cluster manager distributes code and manages data in RDDs
Spark for data processing

Installing and using Spark
• Install pre-compiled package http://spark.apache.org/downloads.html
• Build from source code http://spark.apache.org/docs/latest/building-spark.html
• Run Spark on Amazon EC2 or use Databricks Spark notebooks (Python / R) http://spark.apache.org/docs/latest/ec2-scripts.html | www.databricks.com/registration
• Run as Docker image https://hub.docker.com/r/sequenceiq/spark/

• Download pre-compiled release version
• Choose “pre-built for Hadoop 2.6 and later”
• Unpack/untar package
• Try out the Python interactive shell
bin/pyspark
• Ensure JAVA_HOME is set
bin/sparkR
Installing Spark

Using Spark in Python
• Import Spark classes
• Create SparkContext object (driver program) and initialize it
• In practice, use the spark-submit script to launch applications on a cluster, using configurable options and including dependencies
• Once a SparkContext is available, it can be used to build RDDs.

RDD: Transformations & Actions
• RDD is immutable, distributed data structure
– Each RDD is split into multiple partitions
• Can be created in 2 ways:
– Loading external dataset or
– Distributing a collection of objects in driver
• RDDs support 2 different types of operations:
– Transformations (construct new RDD)
– Actions (compute result based on RDD)

RDD: Transformations & Actions Transformations
No (lazy) evaluations
New RDD returned
Examples:
⁻ map
⁻ filter
⁻ flatMap
⁻ groupByKey
⁻ reduceByKey
⁻ aggregateByKey
⁻ union
⁻ join
⁻ coalesce
Actions
Evaluations done
New value returned
Examples:
⁻ reduce
⁻ collect
⁻ count
⁻ first
⁻ take
⁻ countByKey
⁻ foreach
⁻ saveAsTextFile
⁻ saveAsSequenceFile

Create RDDs
• Creating distributed datasets
– From any storage source supported by Hadoop
• Use SparkContext methods:
– Support directories, compressed files, wildcards

Loading data
• Loading text files
• Loading unstructured JSON files
• Loading sequence files

Loading data
• Loading csv files
• Loading csv files in full

Saving data
• Saving text files
• Saving unstructured JSON files
• Saving csv files

Spark SQL
• Spark’s interface for working with structured and semi-structured data
• Can load data from JSON, Hive, Parquet
• Can query using SQL
• Can be combined with regular code e.g. Python / Java inside Spark application
• Provides “DataFrames” (SchemaRDD < v1.3)
• Like RDDs, DataFrames are evaluated “lazily”

Using Spark SQL
• HiveContext (or SQLContext for a stripped-down version) based on SparkContext
• Construct a SQLContext:
• Basic query:

Spark SQL: DataFrames
• Spark SQL provides DataFrames as programming abstractions
• A DataFrame is a distributed collection of data organized into named columns
• Conceptually equivalent to relational table
• Familiar syntax (R dplyr / Pandas) but scales to PBs
• Entry-point remains SQLContext

Spark SQL: DataFrame Operations
• Selecting rows, columns
• Grouping / aggregation
• Running SQL queries
• Window functions

• Reading JSON data into dataframe in Python
• Reading JSON data into dataframe in R
DataFrames – Data Operations

• Generic load/save
– Python
– R
• Default data source parquet
– Can be changed by manually specifying format
DataFrames – Saving data

SparkR
• R package providing light-weight front-end to use Apache Spark from R
• Entry point in SparkContext
• With SQLContext, dataframes can be created from local R data frames, Hive tables or other Spark data sources
• Introduced with Spark 1.4

SparkR: Creating DataFrames
• From local data frames
• From data sources like JSON
• From Hive tables

Useful tips
• Use Spark SQL dataframes to write less code. Easier to avoid closure problems.
• Be aware of closure issues while working in cluster mode. Use accumulator variables instead of locally defined methods
• Utilize Spark SQL capability to automatically infer schema of JSON datasets
SQLContext.read.json
• Other than using command-line, IDEs like IntelliJ IDEA community edition can be used for free

References
• Spark pages: http://spark.apache.org/ • Databricks blog: https://databricks.com/blog • Spark summit: https://spark-summit.org/ • Additional Spark packages at: http://spark-packages.org/ • Example scripts: • https://github.com/apache/spark/blob/master/examples/src/main/pytho
n/sql.py • https://github.com/apache/spark/blob/master/examples/src/main/r/data
-manipulation.R • https://github.com/apache/spark/blob/master/examples/src/main/r/data
frame.R • API docs: http://spark.apache.org/docs/latest/api/python/index.html • http://spark.apache.org/docs/latest/api/R/index.html • Using SparkR in Rstudio: http://www.r-bloggers.com/how-to-use-sparkr-
within-rstudio/